Transformers documentation
ConvNeXT
ConvNeXT
Overview
The ConvNeXT model was proposed in A ConvNet for the 2020s by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
The abstract from the paper is the following:
The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
Tips:
- See the code examples below each model regarding usage.
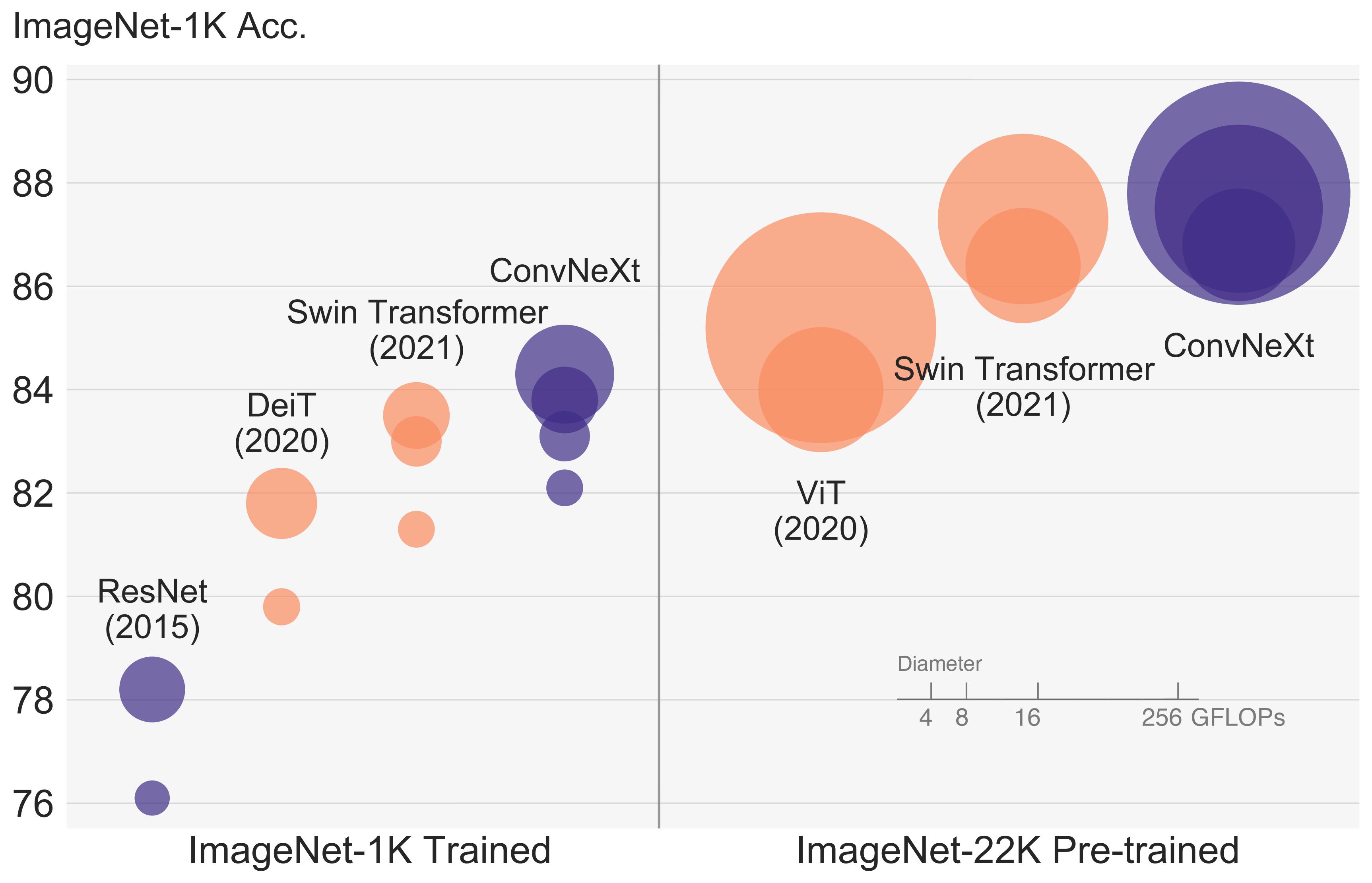 ConvNeXT architecture. Taken from the original paper.
ConvNeXT architecture. Taken from the original paper.
This model was contributed by nielsr. TensorFlow version of the model was contributed by ariG23498, gante, and sayakpaul (equal contribution). The original code can be found here.
ConvNextConfig
class transformers.ConvNextConfig
< source >( num_channels = 3 patch_size = 4 num_stages = 4 hidden_sizes = None depths = None hidden_act = 'gelu' initializer_range = 0.02 layer_norm_eps = 1e-12 is_encoder_decoder = False layer_scale_init_value = 1e-06 drop_path_rate = 0.0 image_size = 224 **kwargs )
Parameters
-
num_channels (
int, optional, defaults to 3) — The number of input channels. -
patch_size (
int, optional, defaults to 4) — Patch size to use in the patch embedding layer. -
num_stages (
int, optional, defaults to 4) — The number of stages in the model. -
hidden_sizes (
List[int], optional, defaults to [96, 192, 384, 768]) — Dimensionality (hidden size) at each stage. -
depths (
List[int], optional, defaults to [3, 3, 9, 3]) — Depth (number of blocks) for each stage. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in each block. If string,"gelu","relu","selu"and"gelu_new"are supported. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
layer_scale_init_value (
float, optional, defaults to 1e-6) — The initial value for the layer scale. -
drop_path_rate (
float, optional, defaults to 0.0) — The drop rate for stochastic depth.
This is the configuration class to store the configuration of a ConvNextModel. It is used to instantiate an ConvNeXT model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the ConvNeXT facebook/convnext-tiny-224 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ConvNextModel, ConvNextConfig
>>> # Initializing a ConvNext convnext-tiny-224 style configuration
>>> configuration = ConvNextConfig()
>>> # Initializing a model from the convnext-tiny-224 style configuration
>>> model = ConvNextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configConvNextFeatureExtractor
class transformers.ConvNextFeatureExtractor
< source >( do_resize = True size = 224 resample = <Resampling.BICUBIC: 3> crop_pct = None do_normalize = True image_mean = None image_std = None **kwargs )
Parameters
-
do_resize (
bool, optional, defaults toTrue) — Whether to resize (and optionally center crop) the input to a certainsize. -
size (
int, optional, defaults to 224) — Resize the input to the given size. If 384 or larger, the image is resized to (size,size). Else, the smaller edge of the image will be matched to int(size/crop_pct), after which the image is cropped tosize. Only has an effect ifdo_resizeis set toTrue. -
resample (
int, optional, defaults toPIL.Image.BICUBIC) — An optional resampling filter. This can be one ofPIL.Image.NEAREST,PIL.Image.BOX,PIL.Image.BILINEAR,PIL.Image.HAMMING,PIL.Image.BICUBICorPIL.Image.LANCZOS. Only has an effect ifdo_resizeis set toTrue. -
crop_pct (
float, optional) — The percentage of the image to crop. IfNone, then a cropping percentage of 224 / 256 is used. Only has an effect ifdo_resizeis set toTrueandsize< 384. -
do_normalize (
bool, optional, defaults toTrue) — Whether or not to normalize the input with mean and standard deviation. -
image_mean (
List[int], defaults to[0.485, 0.456, 0.406]) — The sequence of means for each channel, to be used when normalizing images. -
image_std (
List[int], defaults to[0.229, 0.224, 0.225]) — The sequence of standard deviations for each channel, to be used when normalizing images.
Constructs a ConvNeXT feature extractor.
This feature extractor inherits from FeatureExtractionMixin which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
ConvNextModel
class transformers.ConvNextModel
< source >( config )
Parameters
- config (ConvNextConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare ConvNext model outputting raw features without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ConvNextConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state after a pooling operation on the spatial dimensions. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
The ConvNextModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import ConvNextFeatureExtractor, ConvNextModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
>>> model = ConvNextModel.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 768, 7, 7]ConvNextForImageClassification
class transformers.ConvNextForImageClassification
< source >( config )
Parameters
- config (ConvNextConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ConvNext Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for ImageNet.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor = None
labels: typing.Optional[torch.LongTensor] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ConvNextConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, num_channels, height, width). Hidden-states (also called feature maps) of the model at the output of each stage.
The ConvNextForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
>>> model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catTFConvNextModel
class transformers.TFConvNextModel
< source >( *args **kwargs )
Parameters
- config (ConvNextConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare ConvNext model outputting raw features without any specific head on top. This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TF 2.0 models accepts two formats as inputs:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional arguments.
This second option is useful when using tf.keras.Model.fit method which currently requires having all the
tensors in the first argument of the model call function: model(inputs).
call
< source >(
pixel_values: typing.Union[typing.List[tensorflow.python.framework.ops.Tensor], typing.List[numpy.ndarray], typing.List[tensorflow.python.keras.engine.keras_tensor.KerasTensor], typing.Dict[str, tensorflow.python.framework.ops.Tensor], typing.Dict[str, numpy.ndarray], typing.Dict[str, tensorflow.python.keras.engine.keras_tensor.KerasTensor], tensorflow.python.framework.ops.Tensor, numpy.ndarray, tensorflow.python.keras.engine.keras_tensor.KerasTensor, NoneType] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
training: bool = False
)
→
transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or tuple(tf.Tensor)
Parameters
-
pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using ConvNextFeatureExtractor. SeeConvNextFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True.
Returns
transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (ConvNextConfig) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
tf.Tensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) further processed by a Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence prediction (classification) objective during pretraining.This output is usually not a good summary of the semantic content of the input, you’re often better with averaging or pooling the sequence of hidden-states for the whole input sequence.
-
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFConvNextModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ConvNextFeatureExtractor, TFConvNextModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextModel.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = feature_extractor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFConvNextForImageClassification
class transformers.TFConvNextForImageClassification
< source >( *args **kwargs )
Parameters
- config (ConvNextConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ConvNext Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for ImageNet.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TF 2.0 models accepts two formats as inputs:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional arguments.
This second option is useful when using tf.keras.Model.fit method which currently requires having all the
tensors in the first argument of the model call function: model(inputs).
call
< source >(
pixel_values: typing.Union[typing.List[tensorflow.python.framework.ops.Tensor], typing.List[numpy.ndarray], typing.List[tensorflow.python.keras.engine.keras_tensor.KerasTensor], typing.Dict[str, tensorflow.python.framework.ops.Tensor], typing.Dict[str, numpy.ndarray], typing.Dict[str, tensorflow.python.keras.engine.keras_tensor.KerasTensor], tensorflow.python.framework.ops.Tensor, numpy.ndarray, tensorflow.python.keras.engine.keras_tensor.KerasTensor, NoneType] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
labels: typing.Union[numpy.ndarray, tensorflow.python.framework.ops.Tensor, NoneType] = None
training: typing.Optional[bool] = False
)
→
transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
Parameters
-
pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using ConvNextFeatureExtractor. SeeConvNextFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. -
labels (
tf.Tensorornp.ndarrayof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFSequenceClassifierOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (ConvNextConfig) and inputs.
-
loss (
tf.Tensorof shape(batch_size, ), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
tf.Tensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFConvNextForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ConvNextFeatureExtractor, TFConvNextForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = feature_extractor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = tf.math.argmax(logits, axis=-1)[0]
>>> print("Predicted class:", model.config.id2label[int(predicted_class_idx)])