Transformers documentation
Mistral
Mistral
개요
미스트랄은 Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed가 작성한 이 블로그 포스트에서 소개되었습니다.
블로그 포스트의 서두는 다음과 같습니다:
미스트랄 AI팀은 현존하는 언어 모델 중 크기 대비 가장 강력한 미스트랄7B를 출시하게 되어 자랑스럽습니다.
미스트랄-7B는 mistral.ai에서 출시한 첫 번째 대규모 언어 모델(LLM)입니다.
아키텍처 세부사항
미스트랄-7B는 다음과 같은 구조적 특징을 가진 디코더 전용 트랜스포머입니다:
- 슬라이딩 윈도우 어텐션: 8k 컨텍스트 길이와 고정 캐시 크기로 훈련되었으며, 이론상 128K 토큰의 어텐션 범위를 가집니다.
- GQA(Grouped Query Attention): 더 빠른 추론이 가능하고 더 작은 크기의 캐시를 사용합니다.
- 바이트 폴백(Byte-fallback) BPE 토크나이저: 문자들이 절대 어휘 목록 외의 토큰으로 매핑되지 않도록 보장합니다.
더 자세한 내용은 출시 블로그 포스트를 참조하세요.
라이선스
미스트랄-7B는 아파치 2.0 라이선스로 출시되었습니다.
사용 팁
미스트랄 AI팀은 다음 3가지 체크포인트를 공개했습니다:
- 기본 모델인 미스트랄-7B-v0.1은 인터넷 규모의 데이터에서 다음 토큰을 예측하도록 사전 훈련되었습니다.
- 지시 조정 모델인 미스트랄-7B-Instruct-v0.1은 지도 미세 조정(SFT)과 직접 선호도 최적화(DPO)를 사용한 채팅에 최적화된 기본 모델입니다.
- 개선된 지시 조정 모델인 미스트랄-7B-Instruct-v0.2는 v1을 개선한 버전입니다.
기본 모델은 다음과 같이 사용할 수 있습니다:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"My favourite condiment is to ..."지시 조정 모델은 다음과 같이 사용할 수 있습니다:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
>>> messages = [
... {"role": "user", "content": "What is your favourite condiment?"},
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"Mayonnaise can be made as follows: (...)"지시 조정 모델은 입력이 올바른 형식으로 준비되도록 채팅 템플릿을 적용해야 합니다.
플래시 어텐션을 이용한 미스트랄 속도향상
위의 코드 스니펫들은 어떤 최적화 기법도 사용하지 않은 추론 과정을 보여줍니다. 하지만 모델 내부에서 사용되는 어텐션 메커니즘의 더 빠른 구현인 플래시 어텐션2을 활용하면 모델의 속도를 크게 높일 수 있습니다.
먼저, 슬라이딩 윈도우 어텐션 기능을 포함하는 플래시 어텐션2의 최신 버전을 설치해야 합니다.
pip install -U flash-attn --no-build-isolation
하드웨어와 플래시 어텐션2의 호환여부를 확인하세요. 이에 대한 자세한 내용은 플래시 어텐션 저장소의 공식 문서에서 확인할 수 있습니다. 또한 모델을 반정밀도(예: torch.float16)로 불러와야합니다.
플래시 어텐션2를 사용하여 모델을 불러오고 실행하려면 아래 코드 스니펫을 참조하세요:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"My favourite condiment is to (...)"기대하는 속도 향상
다음은 mistralai/Mistral-7B-v0.1 체크포인트를 사용한 트랜스포머의 기본 구현과 플래시 어텐션2 버전 모델 사이의 순수 추론 시간을 비교한 예상 속도 향상 다이어그램입니다.
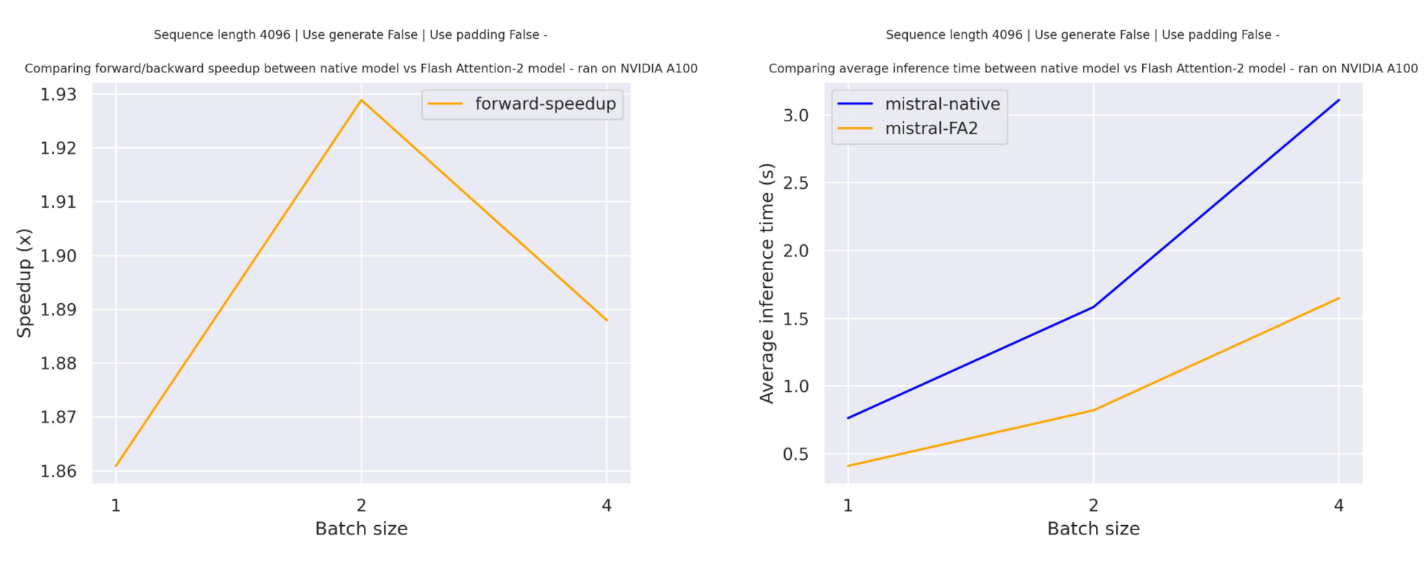
슬라이딩 윈도우 어텐션
현재 구현은 슬라이딩 윈도우 어텐션 메커니즘과 메모리 효율적인 캐시 관리 기능을 지원합니다. 슬라이딩 윈도우 어텐션을 활성화하려면, 슬라이딩 윈도우 어텐션과 호환되는flash-attn(>=2.3.0)버전을 사용하면 됩니다.
또한 플래시 어텐션2 모델은 더 메모리 효율적인 캐시 슬라이싱 메커니즘을 사용합니다. 미스트랄 모델의 공식 구현에서 권장하는 롤링 캐시 메커니즘을 따라, 캐시 크기를 고정(self.config.sliding_window)으로 유지하고, padding_side="left"인 경우에만 배치 생성(batch generation)을 지원하며, 현재 토큰의 절대 위치를 사용해 위치 임베딩을 계산합니다.
양자화로 미스트랄 크기 줄이기
미스트랄 모델은 70억 개의 파라미터를 가지고 있어, 절반의 정밀도(float16)로 약 14GB의 GPU RAM이 필요합니다. 각 파라미터가 2바이트로 저장되기 때문입니다. 하지만 양자화를 사용하면 모델 크기를 줄일 수 있습니다. 모델을 4비트(즉, 파라미터당 반 바이트)로 양자화하면 약 3.5GB의 RAM만 필요합니다.
모델을 양자화하는 것은 quantization_config를 모델에 전달하는 것만큼 간단합니다. 아래에서는 BitsAndBytes 양자화를 사용하지만, 다른 양자화 방법은 이 페이지를 참고하세요:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
>>> # specify how to quantize the model
>>> quantization_config = BitsAndBytesConfig(
... load_in_4bit=True,
... bnb_4bit_quant_type="nf4",
... bnb_4bit_compute_dtype="torch.float16",
... )
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", quantization_config=True, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
>>> prompt = "My favourite condiment is"
>>> messages = [
... {"role": "user", "content": "What is your favourite condiment?"},
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"이 모델은 Younes Belkada와 Arthur Zucker가 기여했습니다. 원본 코드는 이곳에서 확인할 수 있습니다.
리소스
미스트랄을 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰해 드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
- 미스트랄-7B의 지도형 미세조정(SFT)을 수행하는 데모 노트북은 이곳에서 확인할 수 있습니다. 🌎
- 2024년에 Hugging Face 도구를 사용해 LLM을 미세 조정하는 방법에 대한 블로그 포스트. 🌎
- Hugging Face의 정렬(Alignment) 핸드북에는 미스트랄-7B를 사용한 지도형 미세 조정(SFT) 및 직접 선호 최적화(DPO)를 수행하기 위한 스크립트와 레시피가 포함되어 있습니다. 여기에는 단일 GPU에서 QLoRa 및 다중 GPU를 사용한 전체 미세 조정을 위한 스크립트가 포함되어 있습니다.
- 인과적 언어 모델링 작업 가이드
MistralConfig
class transformers.MistralConfig
< source >( vocab_size = 32000 hidden_size = 4096 intermediate_size = 14336 num_hidden_layers = 32 num_attention_heads = 32 num_key_value_heads = 8 head_dim = None hidden_act = 'silu' max_position_embeddings = 131072 initializer_range = 0.02 rms_norm_eps = 1e-06 use_cache = True pad_token_id = None bos_token_id = 1 eos_token_id = 2 tie_word_embeddings = False rope_theta = 10000.0 sliding_window = 4096 attention_dropout = 0.0 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 32000) — Vocabulary size of the Mistral model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling MistralModel - hidden_size (
int, optional, defaults to 4096) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to 14336) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to 32) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 32) — Number of attention heads for each attention layer in the Transformer encoder. - num_key_value_heads (
int, optional, defaults to 8) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details, check out this paper. If it is not specified, will default to8. - head_dim (
int, optional, defaults tohidden_size // num_attention_heads) — The attention head dimension. - hidden_act (
strorfunction, optional, defaults to"silu") — The non-linear activation function (function or string) in the decoder. - max_position_embeddings (
int, optional, defaults to4096*32) — The maximum sequence length that this model might ever be used with. Mistral’s sliding window attention allows sequence of up to 4096*32 tokens. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - rms_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True. - pad_token_id (
int, optional) — The id of the padding token. - bos_token_id (
int, optional, defaults to 1) — The id of the “beginning-of-sequence” token. - eos_token_id (
int, optional, defaults to 2) — The id of the “end-of-sequence” token. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether the model’s input and output word embeddings should be tied. - rope_theta (
float, optional, defaults to 10000.0) — The base period of the RoPE embeddings. - sliding_window (
int, optional, defaults to 4096) — Sliding window attention window size. If not specified, will default to4096. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities.
This is the configuration class to store the configuration of a MistralModel. It is used to instantiate an Mistral model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Mistral-7B-v0.1 or Mistral-7B-Instruct-v0.1.
mistralai/Mistral-7B-v0.1 mistralai/Mistral-7B-Instruct-v0.1
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
>>> from transformers import MistralModel, MistralConfig
>>> # Initializing a Mistral 7B style configuration
>>> configuration = MistralConfig()
>>> # Initializing a model from the Mistral 7B style configuration
>>> model = MistralModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configMistralModel
class transformers.MistralModel
< source >( config: MistralConfig )
Parameters
- config (MistralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Mistral Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length.
Returns
transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MistralConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MistralModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
MistralForCausalLM
class transformers.MistralForCausalLM
< source >( config )
Parameters
- config (MistralForCausalLM) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Mistral Model for causal language modeling.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MistralConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MistralForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, MistralForCausalLM
>>> model = MistralForCausalLM.from_pretrained("meta-mistral/Mistral-2-7b-hf")
>>> tokenizer = AutoTokenizer.from_pretrained("meta-mistral/Mistral-2-7b-hf")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."MistralForSequenceClassification
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values).
Returns
transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (None) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GenericForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
MistralForTokenClassification
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None **kwargs ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values).
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (None) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GenericForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
FlaxMistralModel
class transformers.FlaxMistralModel
< source >( config: MistralConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (MistralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16, orjax.numpy.bfloat16.This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
The bare Mistral Model transformer outputting raw hidden-states without any specific head on top.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_ids attention_mask = None position_ids = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None dropout_rng: <function PRNGKey at 0x7f3b79040430> = None train: bool = False output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
numpy.ndarrayof shape(batch_size, input_ids_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
numpy.ndarrayof shape(batch_size, input_ids_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
dict[str, np.ndarray], optional, returned byinit_cacheor when passing previouspast_key_values) — Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast auto-regressive decoding. Pre-computed key and value hidden-states are of shape [batch_size, max_length]. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MistralConfig) and inputs.
-
last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
past_key_values (
dict[str, jnp.ndarray]) — Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast auto-regressive decoding. Pre-computed key and value hidden-states are of shape [batch_size, max_length]. -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The FlaxMistralPreTrainedModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
This example uses a random model as the real ones are all very big. To get proper results, you should use
mistralai/Mistral-7B-v0.1 instead of ksmcg/Mistral-tiny. If you get out-of-memory when loading that checkpoint, you can try
adding device_map="auto" in the from_pretrained call.
Example:
>>> from transformers import AutoTokenizer, FlaxMistralModel
>>> tokenizer = AutoTokenizer.from_pretrained("ksmcg/Mistral-tiny")
>>> model = FlaxMistralModel.from_pretrained("ksmcg/Mistral-tiny")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxMistralForCausalLM
class transformers.FlaxMistralForCausalLM
< source >( config: MistralConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (MistralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16, orjax.numpy.bfloat16.This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
The Mistral Model transformer with a language modeling head (linear layer) on top.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_ids attention_mask = None position_ids = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None dropout_rng: <function PRNGKey at 0x7f3b79040430> = None train: bool = False output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)
Parameters
- input_ids (
numpy.ndarrayof shape(batch_size, input_ids_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
numpy.ndarrayof shape(batch_size, input_ids_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
dict[str, np.ndarray], optional, returned byinit_cacheor when passing previouspast_key_values) — Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast auto-regressive decoding. Pre-computed key and value hidden-states are of shape [batch_size, max_length]. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)
A transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MistralConfig) and inputs.
-
logits (
jnp.ndarrayof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Cross attentions weights after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
past_key_values (
tuple(tuple(jnp.ndarray)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple ofjnp.ndarraytuples of lengthconfig.n_layers, with each tuple containing the cached key, value states of the self-attention and the cross-attention layers if model is used in encoder-decoder setting. Only relevant ifconfig.is_decoder = True.Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.
The FlaxMistralPreTrainedModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
This example uses a random model as the real ones are all very big. To get proper results, you should use
mistralai/Mistral-7B-v0.1 instead of ksmcg/Mistral-tiny. If you get out-of-memory when loading that checkpoint, you can try
adding device_map="auto" in the from_pretrained call.
Example:
>>> from transformers import AutoTokenizer, FlaxMistralForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("ksmcg/Mistral-tiny")
>>> model = FlaxMistralForCausalLM.from_pretrained("ksmcg/Mistral-tiny")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]TFMistralModel
class transformers.TFMistralModel
< source >( config: MistralConfig *inputs **kwargs )
Parameters
- config (MistralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Mistral Model outputting raw hidden-states without any specific head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in model accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None attention_mask: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None position_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None past_key_values: typing.Optional[list[tensorflow.python.framework.tensor.Tensor]] = None inputs_embeds: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
tf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(tf.Tensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.One formats is allowed:
- Tuple of
tuple(tf.Tensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - Tuple of
- inputs_embeds (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The TFMistralModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
TFMistralForCausalLM
call
< source >( input_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None attention_mask: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None position_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None past_key_values: typing.Optional[list[tensorflow.python.framework.tensor.Tensor]] = None inputs_embeds: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None labels: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
tf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(tf.Tensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.One formats is allowed:
- Tuple of
tuple(tf.Tensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - Tuple of
- inputs_embeds (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
tf.Tensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].
The TFMistralForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
TFMistralForSequenceClassification
class transformers.TFMistralForSequenceClassification
< source >( config *inputs **kwargs )
Parameters
- config (MistralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Mistral Model transformer with a sequence classification head on top (linear layer).
MistralForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
pad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If
no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in
each row of the batch).
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in model accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None attention_mask: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None position_ids: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None past_key_values: typing.Optional[list[tensorflow.python.framework.tensor.Tensor]] = None inputs_embeds: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None labels: typing.Optional[tensorflow.python.framework.tensor.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
tf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(tf.Tensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.One formats is allowed:
- Tuple of
tuple(tf.Tensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - Tuple of
- inputs_embeds (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
tf.Tensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].
The TFMistralForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.