Transformers documentation
Create a custom architecture
Create a custom architecture
An AutoClass automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an AutoClass to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an AutoClass. Learn how to:
- Load and customize a model configuration.
- Create a model architecture.
- Create a slow and fast tokenizer for text.
- Create an image processor for vision tasks.
- Create a feature extractor for audio tasks.
- Create a processor for multimodal tasks.
Configuration
A configuration refers to a model’s specific attributes. Each model configuration has different attributes; for instance, all NLP models have the hidden_size, num_attention_heads, num_hidden_layers and vocab_size attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
Get a closer look at DistilBERT by accessing DistilBertConfig to inspect it’s attributes:
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}DistilBertConfig displays all the default attributes used to build a base DistilBertModel. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
- Try a different activation function with the
activationparameter. - Use a higher dropout ratio for the attention probabilities with the
attention_dropoutparameter.
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}Pretrained model attributes can be modified in the from_pretrained() function:
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)Once you are satisfied with your model configuration, you can save it with save_pretrained(). Your configuration file is stored as a JSON file in the specified save directory:
>>> my_config.save_pretrained(save_directory="./your_model_save_path")To reuse the configuration file, load it with from_pretrained():
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the configuration documentation for more details.
Model
The next step is to create a model. The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like num_hidden_layers from the configuration are used to define the architecture. Every model shares the base class PreTrainedModel and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a torch.nn.Module, tf.keras.Model or flax.linen.Module subclass. This means models are compatible with each of their respective framework’s usage.
Load your custom configuration attributes into the model:
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)This creates a model with random values instead of pretrained weights. You won’t be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with from_pretrained():
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you’d like:
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)Load your custom configuration attributes into the model:
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)This creates a model with random values instead of pretrained weights. You won’t be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with from_pretrained():
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you’d like:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)Model heads
At this point, you have a base DistilBERT model which outputs the hidden states. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can’t use DistilBERT for a sequence-to-sequence task like translation).
For example, DistilBertForSequenceClassification is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the DistilBertForQuestionAnswering model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")For example, TFDistilBertForSequenceClassification is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the TFDistilBertForQuestionAnswering model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")Tokenizer
The last base class you need before using a model for textual data is a tokenizer to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
- PreTrainedTokenizer: a Python implementation of a tokenizer.
- PreTrainedTokenizerFast: a tokenizer from our Rust-based 🤗 Tokenizer library. This tokenizer type is significantly faster - especially during batch tokenization - due to its Rust implementation. The fast tokenizer also offers additional methods like offset mapping which maps tokens to their original words or characters.
Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
Not every model supports a fast tokenizer. Take a look at this table to check if a model has fast tokenizer support.
If you trained your own tokenizer, you can create one from your vocabulary file:
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model’s tokenizer. You need to use a pretrained model’s vocabulary if you are using a pretrained model, otherwise the inputs won’t make sense. Create a tokenizer with a pretrained model’s vocabulary with the DistilBertTokenizer class:
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")Create a fast tokenizer with the DistilBertTokenizerFast class:
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")By default, AutoTokenizer will try to load a fast tokenizer. You can disable this behavior by setting use_fast=False in from_pretrained.
Image processor
An image processor processes vision inputs. It inherits from the base ImageProcessingMixin class.
To use, create an image processor associated with the model you’re using. For example, create a default ViTImageProcessor if you are using ViT for image classification:
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}If you aren’t looking for any customization, just use the from_pretrained method to load a model’s default image processor parameters.
Modify any of the ViTImageProcessor parameters to create your custom image processor:
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}Backbone
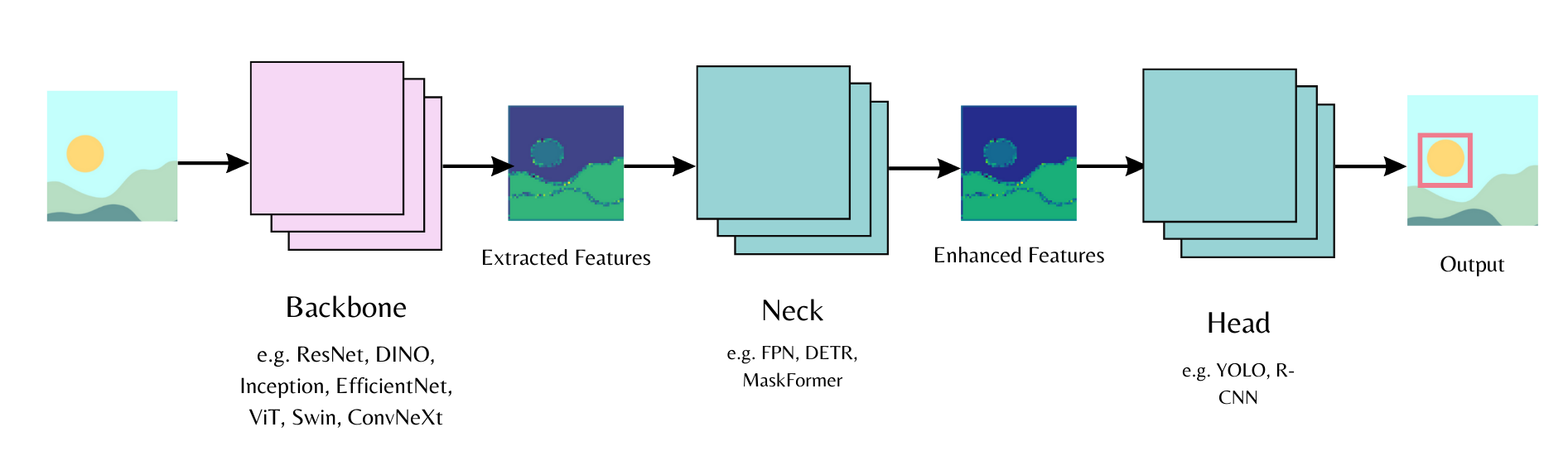
Computer vision models consist of a backbone, neck, and head. The backbone extracts features from an input image, the neck combines and enhances the extracted features, and the head is used for the main task (e.g., object detection). Start by initializing a backbone in the model config and specify whether you want to load pretrained weights or load randomly initialized weights. Then you can pass the model config to the model head.
For example, to load a ResNet backbone into a MaskFormer model with an instance segmentation head:
<hfoptions id="backbone"> <hfoption id="pretrained weights">Set use_pretrained_backbone=True to load pretrained ResNet weights for the backbone.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # headSet use_pretrained_backbone=False to randomly initialize a ResNet backbone.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=False) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # headYou could also load the backbone config separately and then pass it to the model config.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
backbone_config = ResNetConfig()
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)timm models are loaded within a model with use_timm_backbone=True or with TimmBackbone and TimmBackboneConfig.
Use use_timm_backbone=True and use_pretrained_backbone=True to load pretrained timm weights for the backbone.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=True, use_timm_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # headSet use_timm_backbone=True and use_pretrained_backbone=False to load a randomly initialized timm backbone.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=False, use_timm_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # headYou could also load the backbone config and use it to create a TimmBackbone or pass it to the model config. Timm backbones will load pretrained weights by default. Set use_pretrained_backbone=False to load randomly initialized weights.
from transformers import TimmBackboneConfig, TimmBackbone
backbone_config = TimmBackboneConfig("resnet50", use_pretrained_backbone=False)
# Create a backbone class
backbone = TimmBackbone(config=backbone_config)
# Create a model with a timm backbone
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)Feature extractor
A feature extractor processes audio inputs. It inherits from the base FeatureExtractionMixin class, and may also inherit from the SequenceFeatureExtractor class for processing audio inputs.
To use, create a feature extractor associated with the model you’re using. For example, create a default Wav2Vec2FeatureExtractor if you are using Wav2Vec2 for audio classification:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}If you aren’t looking for any customization, just use the from_pretrained method to load a model’s default feature extractor parameters.
Modify any of the Wav2Vec2FeatureExtractor parameters to create your custom feature extractor:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}Processor
For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps processing classes such as a feature extractor and a tokenizer into a single object. For example, let’s use the Wav2Vec2Processor for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
Create a feature extractor to handle the audio inputs:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)Create a tokenizer to handle the text inputs:
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")Combine the feature extractor and tokenizer in Wav2Vec2Processor:
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, image processor, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
< > Update on GitHub