Transformers documentation
Text generation strategies
Text generation strategies
テキスト生成は、オープンエンドのテキスト生成、要約、翻訳など、多くの自然言語処理タスクに不可欠です。また、テキストを出力とするさまざまな混在モダリティアプリケーションにも影響を与えており、例えば音声からテキストへの変換や画像からテキストへの変換などがあります。テキストを生成できるいくつかのモデルには、GPT2、XLNet、OpenAI GPT、CTRL、TransformerXL、XLM、Bart、T5、GIT、Whisperが含まれます。
generate() メソッドを使用して、異なるタスクのテキスト出力を生成するいくつかの例をご紹介します:
generateメソッドへの入力は、モデルのモダリティに依存します。これらの入力は、AutoTokenizerやAutoProcessorなどのモデルのプリプロセッサクラスによって返されます。モデルのプリプロセッサが複数の種類の入力を生成する場合は、すべての入力をgenerate()に渡します。各モデルのプリプロセッサについての詳細は、対応するモデルのドキュメンテーションで確認できます。
テキストを生成するためのトークンの選択プロセスはデコーディングとして知られ、generate()メソッドが使用するデコーディング戦略をカスタマイズできます。デコーディング戦略を変更することは、訓練可能なパラメータの値を変更しませんが、生成されるテキストの品質に顕著な影響を与えることがあります。これにより、テキスト内の繰り返しを減少させ、より一貫性のあるテキストを生成するのに役立ちます。
このガイドでは以下の内容が説明されています:
- デフォルトのテキスト生成設定
- 一般的なデコーディング戦略とその主要なパラメータ
- 🤗 Hubのあなたのファインチューンモデルとカスタム生成設定の保存と共有
Default text generation configuration
モデルのデコーディング戦略は、その生成設定で定義されています。pipeline() 内で推論に事前訓練モデルを使用する際には、モデルはデフォルトの生成設定を内部で適用する PreTrainedModel.generate() メソッドを呼び出します。デフォルトの設定は、モデルにカスタム設定が保存されていない場合にも使用されます。
モデルを明示的に読み込む場合、それに付属する生成設定を model.generation_config を介して確認できます。
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}model.generation_config を出力すると、デフォルトの生成設定から異なる値のみが表示され、デフォルトの値はリストされません。
デフォルトの生成設定では、出力のサイズは入力プロンプトとの組み合わせで最大20トークンに制限されており、リソース制限に達しないようにしています。デフォルトのデコーディング戦略は貪欲探索で、最も確率の高いトークンを次のトークンとして選択する最も単純なデコーディング戦略です。多くのタスクや小さな出力サイズの場合、これはうまく機能します。ただし、長い出力を生成するために使用される場合、貪欲探索は高度に繰り返される結果を生成し始めることがあります。
Customize text generation
generate メソッドに直接パラメータとその値を渡すことで、generation_config を上書きできます。
>>> my_model.generate(**inputs, num_beams=4, do_sample=True)デフォルトのデコーディング戦略がほとんどのタスクでうまく機能する場合でも、いくつかの設定を微調整できます。一般的に調整されるパラメータには次のものがあります:
max_new_tokens: 生成するトークンの最大数。つまり、出力シーケンスのサイズであり、プロンプト内のトークンは含まれません。num_beams: 1よりも大きなビーム数を指定することで、貪欲検索からビームサーチに切り替えることができます。この戦略では、各時間ステップでいくつかの仮説を評価し、最終的に全体のシーケンスに対する最も高い確率を持つ仮説を選択します。これにより、初期の確率が低いトークンで始まる高確率のシーケンスが貪欲検索によって無視されることがなくなります。do_sample: このパラメータをTrueに設定すると、多項分布サンプリング、ビームサーチ多項分布サンプリング、Top-Kサンプリング、Top-pサンプリングなどのデコーディング戦略が有効になります。これらの戦略は、各戦略固有の調整を含む単語彙全体の確率分布から次のトークンを選択します。num_return_sequences: 各入力に対して返すシーケンス候補の数。これは、複数のシーケンス候補をサポートするデコーディング戦略(ビームサーチやサンプリングのバリエーションなど)にのみ適用されます。貪欲検索や対照的な検索など、単一の出力シーケンスを返すデコーディング戦略では使用できません。
Save a custom decoding strategy with your model
特定の生成構成で調整したモデルを共有したい場合、以下の手順を実行できます:
- GenerationConfig クラスのインスタンスを作成する
- デコーディング戦略のパラメータを指定する
- GenerationConfig.save_pretrained() を使用して生成構成を保存し、
config_file_name引数を空にすることを忘れないでください push_to_hubをTrueに設定して、構成をモデルのリポジトリにアップロードします
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True)1つのディレクトリに複数の生成設定を保存することもでき、GenerationConfig.save_pretrained() の config_file_name
引数を使用します。後で GenerationConfig.from_pretrained() でこれらをインスタンス化できます。これは、1つのモデルに対して複数の生成設定を保存したい場合に便利です
(例:サンプリングを使用したクリエイティブなテキスト生成用の1つと、ビームサーチを使用した要約用の1つ)。モデルに設定ファイルを追加するには、適切な Hub 権限が必要です。
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']Streaming
generate() は、その streamer 入力を介してストリーミングをサポートしています。streamer 入力は、次のメソッドを持つクラスのインスタンスと互換性があります:put() と end()。内部的には、put() は新しいトークンをプッシュするために使用され、end() はテキスト生成の終了をフラグ付けするために使用されます。
ストリーマークラスのAPIはまだ開発中であり、将来変更される可能性があります。
実際には、さまざまな目的に対して独自のストリーミングクラスを作成できます!また、使用できる基本的なストリーミングクラスも用意されています。例えば、TextStreamer クラスを使用して、generate() の出力を画面に単語ごとにストリームすることができます:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,Decoding strategies
特定の generate() パラメータの組み合わせ、そして最終的に generation_config は、特定のデコーディング戦略を有効にするために使用できます。このコンセプトが新しい場合、このブログポストを読むことをお勧めします。このブログポストでは、一般的なデコーディング戦略がどのように動作するかが説明されています。
ここでは、デコーディング戦略を制御するいくつかのパラメータを示し、それらをどのように使用できるかを説明します。
Greedy Search
generate はデフォルトで貪欲探索デコーディングを使用するため、有効にするためにパラメータを渡す必要はありません。これは、パラメータ num_beams が 1 に設定され、do_sample=False であることを意味します。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilbert/distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']Contrastive search
コントラスティブ検索デコーディング戦略は、2022年の論文A Contrastive Framework for Neural Text Generationで提案されました。 これは、非反復的でありながら一貫性のある長い出力を生成するために優れた結果を示しています。コントラスティブ検索の動作原理を学ぶには、このブログポストをご覧ください。 コントラスティブ検索の動作を有効にし、制御する2つの主要なパラメータは「penalty_alpha」と「top_k」です:
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']Multinomial sampling
常に最高確率のトークンを次のトークンとして選択する貪欲検索とは異なり、多項分布サンプリング(または祖先サンプリングとも呼ばれます)はモデルによって提供される語彙全体の確率分布に基づいて次のトークンをランダムに選択します。ゼロ以外の確率を持つすべてのトークンには選択される可能性があり、これにより繰り返しのリスクが減少します。
多項分布サンプリングを有効にするには、do_sample=True および num_beams=1 を設定します。
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']Beam-search decoding
貪欲探索とは異なり、ビームサーチデコーディングは各時間ステップでいくつかの仮説を保持し、最終的にシーケンス全体で最も確率が高い仮説を選択します。これにより、貪欲探索では無視されてしまう初期トークンの確率が低い高確率のシーケンスを特定する利点があります。
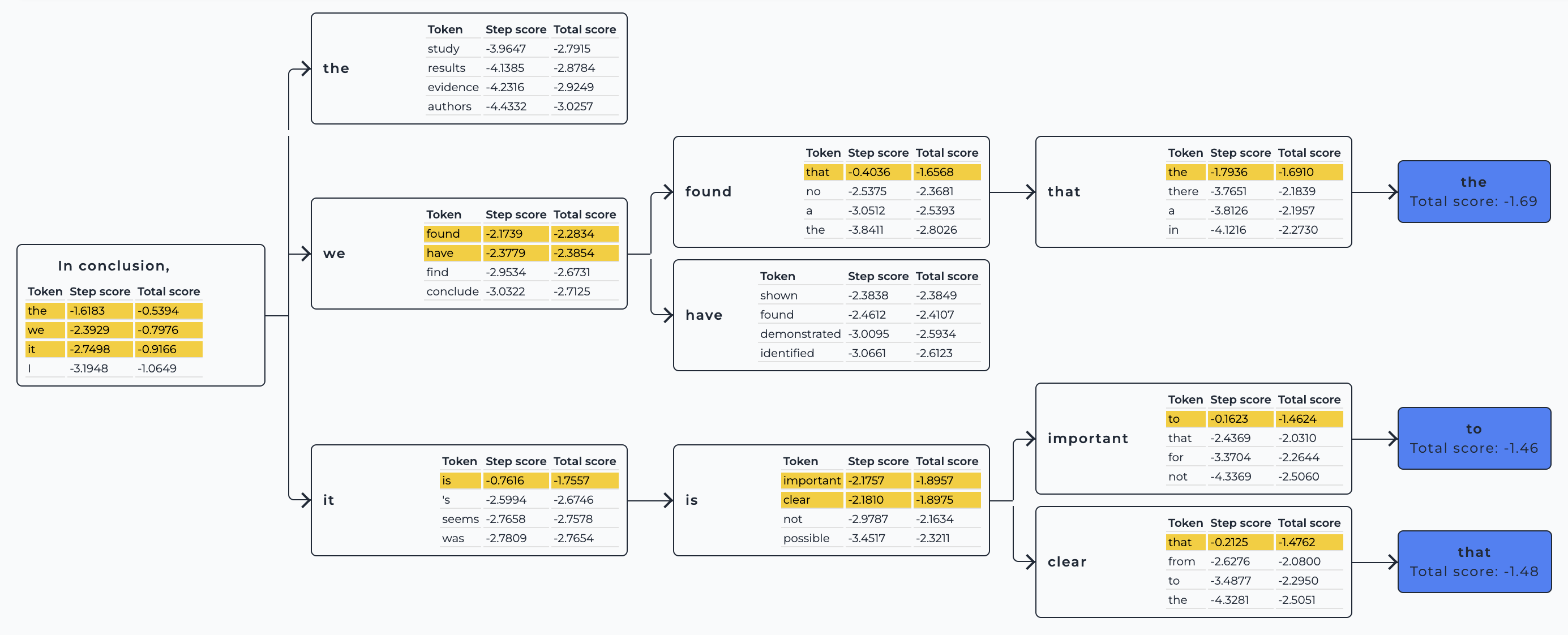
ビームサーチデコーディングの動作をこのインタラクティブデモで確認することができます。文章を入力し、パラメータをいじることでデコーディングビームがどのように変化するかを知ることができます。
このデコーディング戦略を有効にするには、num_beams(追跡する仮説の数)を1よりも大きな値に指定します。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "openai-community/gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']Beam-search multinomial sampling
その名前からもわかるように、このデコーディング戦略はビームサーチと多項サンプリングを組み合わせています。このデコーディング戦略を使用するには、num_beams を1より大きな値に設定し、do_sample=True を設定する必要があります。
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "google-t5/t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'Diverse beam search decoding
多様なビームサーチデコーディング戦略は、ビームサーチ戦略の拡張であり、選択肢からより多様なビームシーケンスを生成できるようにします。この仕組みの詳細については、Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models をご参照ください。このアプローチには、num_beams、num_beam_groups、および diversity_penalty という3つの主要なパラメータがあります。多様性ペナルティは、出力がグループごとに異なることを保証し、ビームサーチは各グループ内で使用されます。
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'Assisted Decoding
アシストデコーディングは、上記のデコーディング戦略を変更したもので、同じトークナイザー(理想的にははるかに小さなモデル)を使用して、いくつかの候補トークンを貪欲に生成するアシスタントモデルを使用します。その後、主要なモデルは候補トークンを1つの前向きパスで検証し、デコーディングプロセスを高速化します。現在、アシストデコーディングでは貪欲検索とサンプリングのみがサポートされており、バッチ入力はサポートされていません。アシストデコーディングの詳細については、このブログ記事 をご覧ください。
アシストデコーディングを有効にするには、assistant_model 引数をモデルで設定します。
このガイドは、さまざまなデコーディング戦略を可能にする主要なパラメーターを説明しています。さらに高度なパラメーターは generate メソッドに存在し、generate メソッドの動作をさらに制御できます。使用可能なパラメーターの完全なリストについては、APIドキュメント を参照してください。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']サンプリング方法を使用する場合、アシストデコーディングでは temperature 引数を使用して、多項サンプリングと同様にランダム性を制御できます。ただし、アシストデコーディングでは、温度を低くすることで遅延の改善に役立ちます。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']