Transformers documentation
Pipelines pour l’inférence
Pipelines pour l’inférence
L’objet pipeline() rend simple l’utilisation de n’importe quel modèle du Hub pour l’inférence sur n’importe quelle langue, tâches de vision par ordinateur, d’audio et multimodales. Même si vous n’avez pas d’expérience avec une modalité spécifique ou si vous n’êtes pas familier avec le code ci-dessous des modèles, vous pouvez toujours les utiliser pour l’inférence avec la pipeline() ! Ce tutoriel vous apprendra à :
- Utiliser un
pipeline()pour l’inférence. - Utiliser un tokenizer ou modèle spécifique.
- Utiliser un
pipeline()pour des tâches audio, de vision et multimodales.
Consultez la documentation du
pipeline()pour une liste complète des tâches prises en charge et des paramètres disponibles.
Utilisation du pipeline
Bien que chaque tâche ait son propre pipeline(), il est plus simple d’utiliser le pipeline() générale qui inclut tous les pipelines spécifiques aux différentes tâches. Cette approche charge automatiquement un modèle par défaut et une classe de prétraitement adaptée à votre tâche, simplifiant ainsi votre utilisation. Prenons l’exemple de l’utilisation du pipeline() pour la reconnaissance automatique de la parole (ASR) ou de la transcription de la parole en texte.
- Commencez par créer un
pipeline()et spécifiez la tâche d’inférence :
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")- Passez votre entrée au
pipeline(). Dans le cas de la reconnaissance vocale, il s’agit d’un fichier audio :
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}Pas le résultat que vous aviez en tête ? Consultez certains des modèles de reconnaissance vocale automatique les plus téléchargés sur le Hub pour voir si vous pouvez obtenir une meilleure transcription.
Essayons le modèle Whisper large-v2 de OpenAI. Whisper a été publié 2 ans après Wav2Vec2 et a été entraîné sur près de 10 fois plus de données. En tant que tel, il surpasse Wav2Vec2 sur la plupart des benchmarks en aval. Il a également l’avantage supplémentaire de prédire la ponctuation et la casse, ce qui n’est pas possible avec Wav2Vec2.
Essayons-le ici pour voir comment il fonctionne :
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}Maintenant, ce résultat semble plus précis ! Pour une comparaison approfondie entre Wav2Vec2 et Whisper, consultez le cours Audio Transformers. Nous vous encourageons vraiment à consulter le Hub pour des modèles dans différentes langues, des modèles spécialisés dans votre domaine, et plus encore. Vous pouvez consulter et comparer les résultats des modèles directement depuis votre navigateur sur le Hub pour voir s’ils conviennent ou gèrent mieux les cas particuliers que d’autres. Et si vous ne trouvez pas de modèle pour votre cas d’utilisation, vous pouvez toujours commencer à entraîner le vôtre !
Si vous avez plusieurs entrées, vous pouvez passer votre entrée sous forme de liste :
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)Les pipelines sont excellents pour l’expérimentation car passer d’un modèle à un autre est trivial ; cependant, il existe des moyens de les optimiser pour des charges de travail plus importantes que l’expérimentation. Consultez les guides suivants qui expliquent comment itérer sur des ensembles de données complets ou utiliser des pipelines dans un serveur web : de la documentation :
Paramètres
pipeline() prend en charge de nombreux paramètres ; certains sont spécifiques à la tâche et d’autres sont généraux pour tous les pipelines.
En général, vous pouvez spécifier les paramètres où vous le souhaitez :
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.Voyons 3 paramètres importants :
Device
Si vous utilisez device=n, le pipeline met automatiquement le modèle sur l’appareil spécifié.
Cela fonctionnera que vous utilisiez PyTorch ou Tensorflow.
transcriber = pipeline(model="openai/whisper-large-v2", device=0)Si le modèle est trop grand pour un seul GPU et que vous utilisez PyTorch, vous pouvez définir device_map="auto" pour déterminer automatiquement comment charger et stocker les poids du modèle. L’utilisation de l’argument device_map nécessite le package 🤗 Accelerate :
pip install --upgrade accelerate
Le code suivant charge et stocke automatiquement les poids du modèle sur plusieurs appareils :
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")Notez que si device_map="auto" est passé, il n’est pas nécessaire d’ajouter l’argument device=device lors de l’instanciation de votre pipeline car vous pourriez rencontrer des comportements inattendus !
Batch size
Par défaut, les pipelines ne feront pas d’inférence en batch pour des raisons expliquées en détail ici. La raison est que le batching n’est pas nécessairement plus rapide, et peut en fait être beaucoup plus lent dans certains cas.
Mais si cela fonctionne dans votre cas d’utilisation, vous pouvez utiliser :
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)Cela exécute le pipeline sur les 4 fichiers audio fournis, mais les passera par batch de 2 au modèle (qui est sur un GPU, où le batching est plus susceptible d’aider) sans nécessiter de code supplémentaire de votre part. La sortie doit toujours correspondre à ce que vous auriez reçu sans batching. Il s’agit uniquement d’un moyen de vous aider à obtenir plus de vitesse avec un pipeline.
Les pipelines peuvent également atténuer certaines des complexités du batching car, pour certains pipelines, un seul élément (comme un long fichier audio) doit être divisé en plusieurs parties pour être traité par un modèle. Le pipeline effectue ce batching par morceaux pour vous.
Paramètres spécifiques à la tâche
Toutes les tâches fournissent des paramètres spécifiques à la tâche qui permettent une flexibilité et des options supplémentaires pour vous aider à accomplir votre travail.
Par exemple, la méthode transformers.AutomaticSpeechRecognitionPipeline.__call__() dispose d’un paramètre return_timestamps qui semble prometteur pour le sous-titrage des vidéos :
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}Comme vous pouvez le voir, le modèle a inféré le texte et a également indiqué quand les différentes phrases ont été prononcées.
Il existe de nombreux paramètres disponibles pour chaque tâche, alors consultez la référence API de chaque tâche pour voir ce que vous pouvez ajuster !
Par exemple, le AutomaticSpeechRecognitionPipeline dispose d’un paramètre chunk_length_s qui est utile pour travailler sur des fichiers audio très longs (par exemple, le sous-titrage de films entiers ou de vidéos d’une heure) qu’un modèle ne peut généralement pas gérer seul :
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}Si vous ne trouvez pas un paramètre qui vous aiderait vraiment, n’hésitez pas à le demander !
Utilisation des pipelines sur un ensemble de données
Le pipeline peut également exécuter des inférences sur un grand ensemble de données. Le moyen le plus simple que nous recommandons pour cela est d’utiliser un itérateur :
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])L’itérateur data() génère chaque résultat, et le pipeline reconnaît automatiquement que l’entrée est itérable et commencera à récupérer les données tout en continuant à les traiter sur le GPU (cela utilise DataLoader sous le capot).
C’est important car vous n’avez pas besoin d’allouer de mémoire pour l’ensemble de données complet et vous pouvez alimenter le GPU aussi rapidement que possible.
Étant donné que le lotissement pourrait accélérer les choses, il peut être utile d’essayer de régler le paramètre batch_size ici.
La façon la plus simple d’itérer sur un ensemble de données est d’en charger un depuis 🤗 Datasets :
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)Utilisation des pipelines pour un serveur web
Créer un moteur d'inférence est un sujet complexe qui mérite sa propre page.
Pipeline de vision
Utiliser un pipeline() pour les tâches de vision est pratiquement identique.
Spécifiez votre tâche et passez votre image au classificateur. L’image peut être un lien, un chemin local ou une image encodée en base64. Par exemple, quelle espèce de chat est montrée ci-dessous ?

>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]Pipeline de texte
Utiliser un pipeline() pour les tâches de NLP est pratiquement identique.
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}Pipeline multimodal
Le pipeline() prend en charge plus d’une modalité. Par exemple, une tâche de réponse à des questions visuelles (VQA) combine texte et image. N’hésitez pas à utiliser n’importe quel lien d’image que vous aimez et une question que vous souhaitez poser à propos de l’image. L’image peut être une URL ou un chemin local vers l’image.
Par exemple, si vous utilisez cette image de facture :
{kind=link}
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]Pour exécuter l’exemple ci-dessus, vous devez avoir
pytesseractinstallé en plus de 🤗 Transformers :sudo apt install -y tesseract-ocr pip install pytesseract
Utilisation de pipeline sur de grands modèles avec 🤗 accelerate :
Vous pouvez facilement exécuter pipeline sur de grands modèles en utilisant 🤗 accelerate ! Assurez-vous d’abord d’avoir installé accelerate avec pip install accelerate.
Chargez d’abord votre modèle en utilisant device_map="auto" ! Nous utiliserons facebook/opt-1.3b pour notre exemple.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)Vous pouvez également passer des modèles chargés en 8 bits si vous installez bitsandbytes et ajoutez l’argument load_in_8bit=True
Notez que vous pouvez remplacer le point de contrôle par n’importe quel modèle.
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)Création de démonstrations web à partir de pipelines avec gradio
Hugging Face prenant en charge le chargement de grands modèles, comme BLOOM. Les pipelines sont automatiquement pris en charge dans Gradio, une bibliothèque qui facilite la création d’applications d’apprentissage automatique belles et conviviales sur le web. Tout d’abord, assurez-vous que Gradio est installé :
pip install gradioEnsuite, vous pouvez créer une démonstration web autour d’un pipeline de classification d’images (ou tout autre pipeline) en une seule ligne de code en appelant la fonction Interface.from_pipeline de Gradio pour lancer le pipeline. Cela crée une interface intuitive de glisser-déposer dans votre navigateur :
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()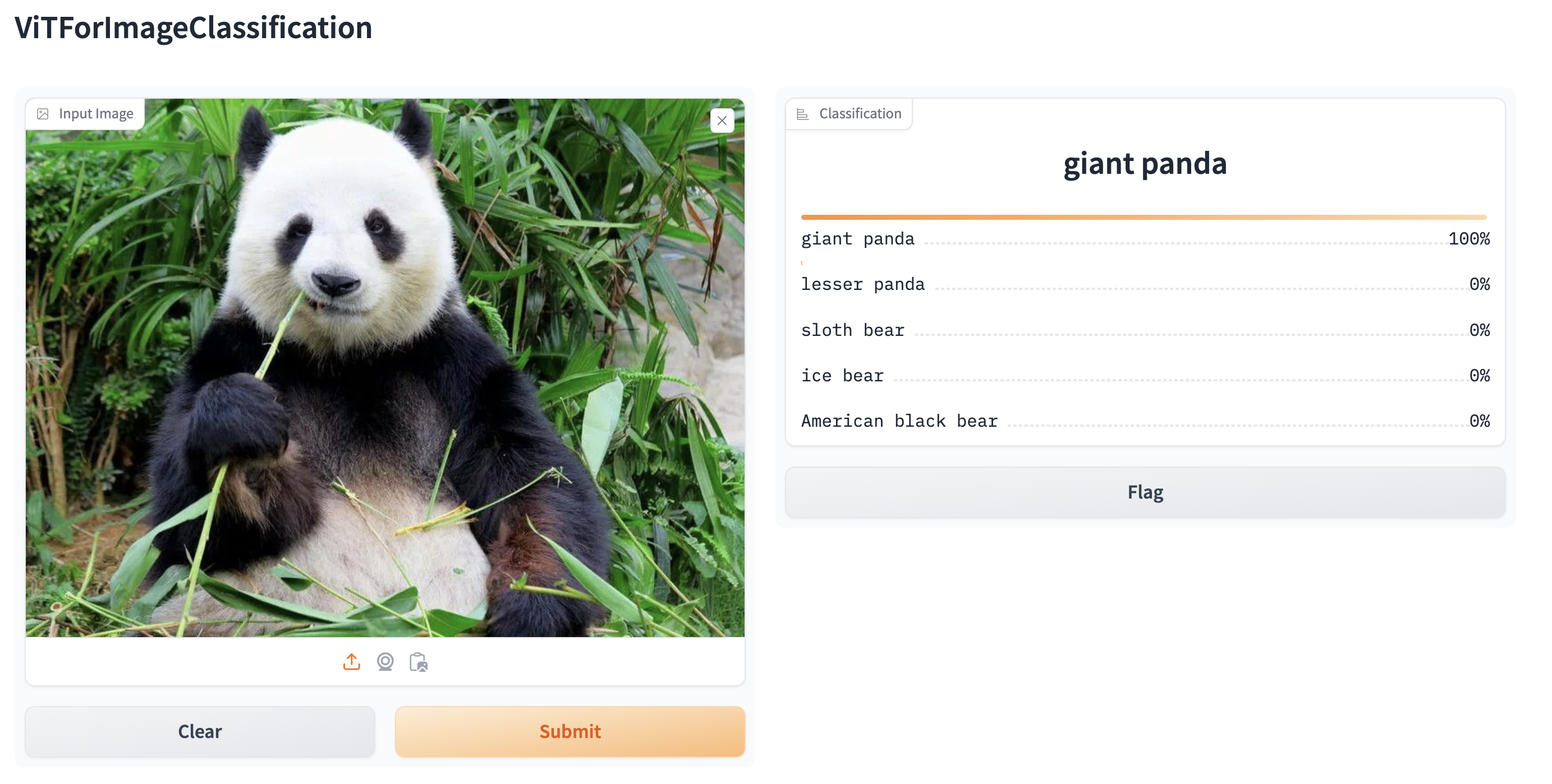
Par défaut, la démonstration web s’exécute sur un serveur local. Si vous souhaitez la partager avec d’autres, vous pouvez générer un lien public temporaire en définissant share=True dans launch(). Vous pouvez également héberger votre démonstration sur Hugging Face Spaces pour obtenir un lien permanent.