Optimum documentation
AMD Instinct GPU connectivity
AMD Instinct GPU connectivity
When using Hugging Face libraries with AMD Instinct MI210 or MI250 GPUs in a multi-GPU settings where collective operations are used, training and inference performance may vary depending on which devices are used together on a node. Some use cases are for example tensor parallelism, pipeline paralellism or data parallelism.
Dual-die topology
Using several devices on an AMD Instinct machine through torchrun on a single node? We recommend using amdrun --ngpus <num_gpus> <script> <script_args> instead to automatically dispatch to the best num_gpus available for maximum performance.
Let’s take an MI250 machine for example. As rocm-smi shows, 8 devices are available:
========================= ROCm System Management Interface =========================
=================================== Concise Info ===================================
GPU Temp (DieEdge) AvgPwr SCLK MCLK Fan Perf PwrCap VRAM% GPU%
0 35.0c 90.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0%
1 34.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0%
2 31.0c 95.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0%
3 37.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0%
4 35.0c 99.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0%
5 31.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0%
6 38.0c 94.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0%
7 39.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0%
====================================================================================However, as can be seen on the description of the machine architecture, some devices effectively have a privileged connection and two devices (two GCDs, Graphics Compute Die) from rocm-smi actually correspond to one MI250 (one OAM, OCP Accelerator Module).

This can be checked by running rocm-smi --shownodesbw: some device <-> device link have a higher maximum bandwith. For example, from the table below, we can conclude that:
- If using two devices, using
CUDA_VISIBLE_DEVICES="0,1", or"2,3", or"4,5"or"6,7"should be privileged. - If using three devices,
CUDA_VISIBLE_DEVICES="0,1,6"is a good option. - If using four devices
CUDA_VISIBLE_DEVICES="0,1,6,7"or"2,3,4,5"is a good option.
========================= ROCm System Management Interface =========================
==================================== Bandwidth =====================================
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7
GPU0 N/A 50000-200000 50000-50000 0-0 0-0 0-0 50000-100000 0-0
GPU1 50000-200000 N/A 0-0 50000-50000 0-0 50000-50000 0-0 0-0
GPU2 50000-50000 0-0 N/A 50000-200000 50000-100000 0-0 0-0 0-0
GPU3 0-0 50000-50000 50000-200000 N/A 0-0 0-0 0-0 50000-50000
GPU4 0-0 0-0 50000-100000 0-0 N/A 50000-200000 50000-50000 0-0
GPU5 0-0 50000-50000 0-0 0-0 50000-200000 N/A 0-0 50000-50000
GPU6 50000-100000 0-0 0-0 0-0 50000-50000 0-0 N/A 50000-200000
GPU7 0-0 0-0 0-0 50000-50000 0-0 50000-50000 50000-200000 N/A
Format: min-max; Units: mps
"0-0" min-max bandwidth indicates devices are not connected directlyThis table only gives theoretical minimum/maximum bandwidth. A good option to validate which devices to use together is to run the rocm_bandwidth_test on your device.
NUMA nodes
On certain AMD machines as seen in the figure below, some devices may have a privileged connectivity with certain CPU cores.
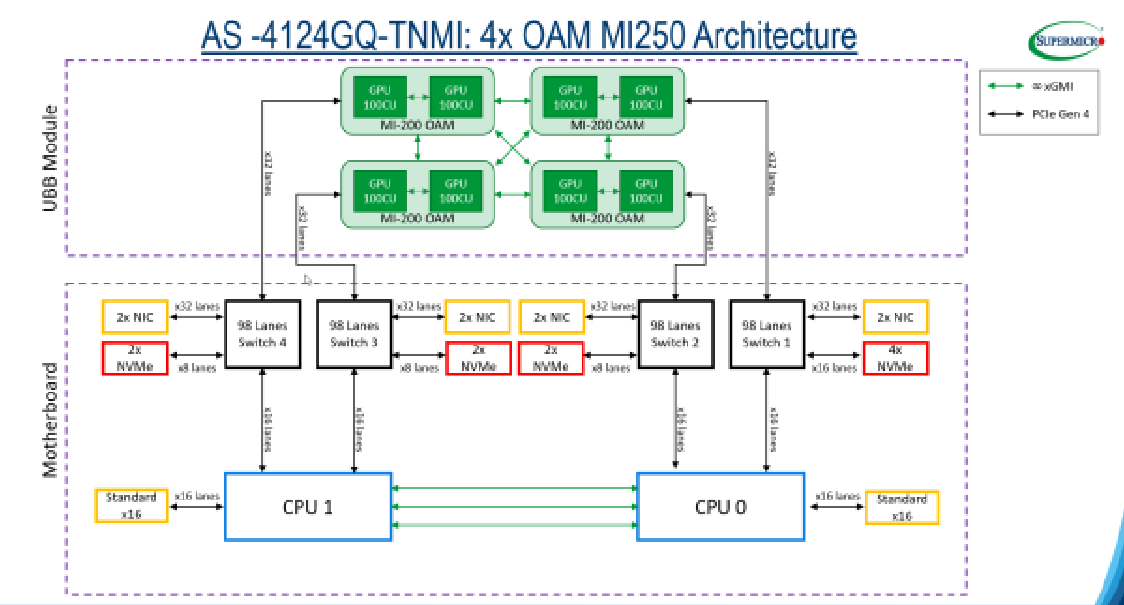
This can be checked using rocm-smi --showtoponuma that gives the NUMA topology:
==================================== Numa Nodes ====================================
GPU[0] : (Topology) Numa Node: 0
GPU[0] : (Topology) Numa Affinity: 0
GPU[1] : (Topology) Numa Node: 0
GPU[1] : (Topology) Numa Affinity: 0
GPU[2] : (Topology) Numa Node: 0
GPU[2] : (Topology) Numa Affinity: 0
GPU[3] : (Topology) Numa Node: 0
GPU[3] : (Topology) Numa Affinity: 0
GPU[4] : (Topology) Numa Node: 1
GPU[4] : (Topology) Numa Affinity: 1
GPU[5] : (Topology) Numa Node: 1
GPU[5] : (Topology) Numa Affinity: 1
GPU[6] : (Topology) Numa Node: 1
GPU[6] : (Topology) Numa Affinity: 1
GPU[7] : (Topology) Numa Node: 1
GPU[7] : (Topology) Numa Affinity: 1and the difference in bandwidth can be checked using rocm_bandwidth_test (redacted):
Bidirectional copy peak bandwidth GB/s
D/D cpu0 cpu1
cpu0 N/A N/A
cpu1 N/A N/A
0 47.763 38.101
1 47.796 38.101
2 47.732 36.429
3 47.709 36.330
4 36.705 47.468
5 36.725 47.396
6 35.605 47.294
7 35.377 47.233When benchmarking for optimal performances, we advise testing both without/with NUMA balancing at /proc/sys/kernel/numa_balancing, which may impact performances. The table below shows the difference in performance of Text Generation Inference in a specific case where disabling NUMA balancing greatly increased performances.

An alternative can be to use numactl --membind, binding a process using a GPU to its corresponding NUMA node cores. More details here.
Infinity Fabric
As seen on the below architecture for an MI210 machine, some GPU devices may be linked by an Infinity Fabric link that typically has a higher bandwidth than PCIe switch (up to 100 GB/s per Infinity Fabric link).
In fact measuring unidirectional copy peak bandwidth, we see that MI210 GPUs linked by Infinity Fabric can communicate ~1.7x times faster than through PCIe switch.
