Multi-node Training
Using several Gaudi servers to perform multi-node training can be done easily. This guide shows how to:
- set up several Gaudi instances
- set up your computing environment
- launch a multi-node run
Setting up several Gaudi instances
Two types of configurations are possible:
- scale-out using Gaudi NICs or Host NICs (on-premises)
- scale-out using AWS DL1 instances
On premises
To set up your servers on premises, check out the installation and distributed training pages of Habana Gaudi’s documentation.
AWS DL1 instances
Proceed with the following steps to correctly set up your DL1 instances.
1. Set up an EFA-enabled security group
To allow all instances to communicate with each other, you need to set up a security group as described by AWS in step 1 of this link. Once this is done, it should look as follows:
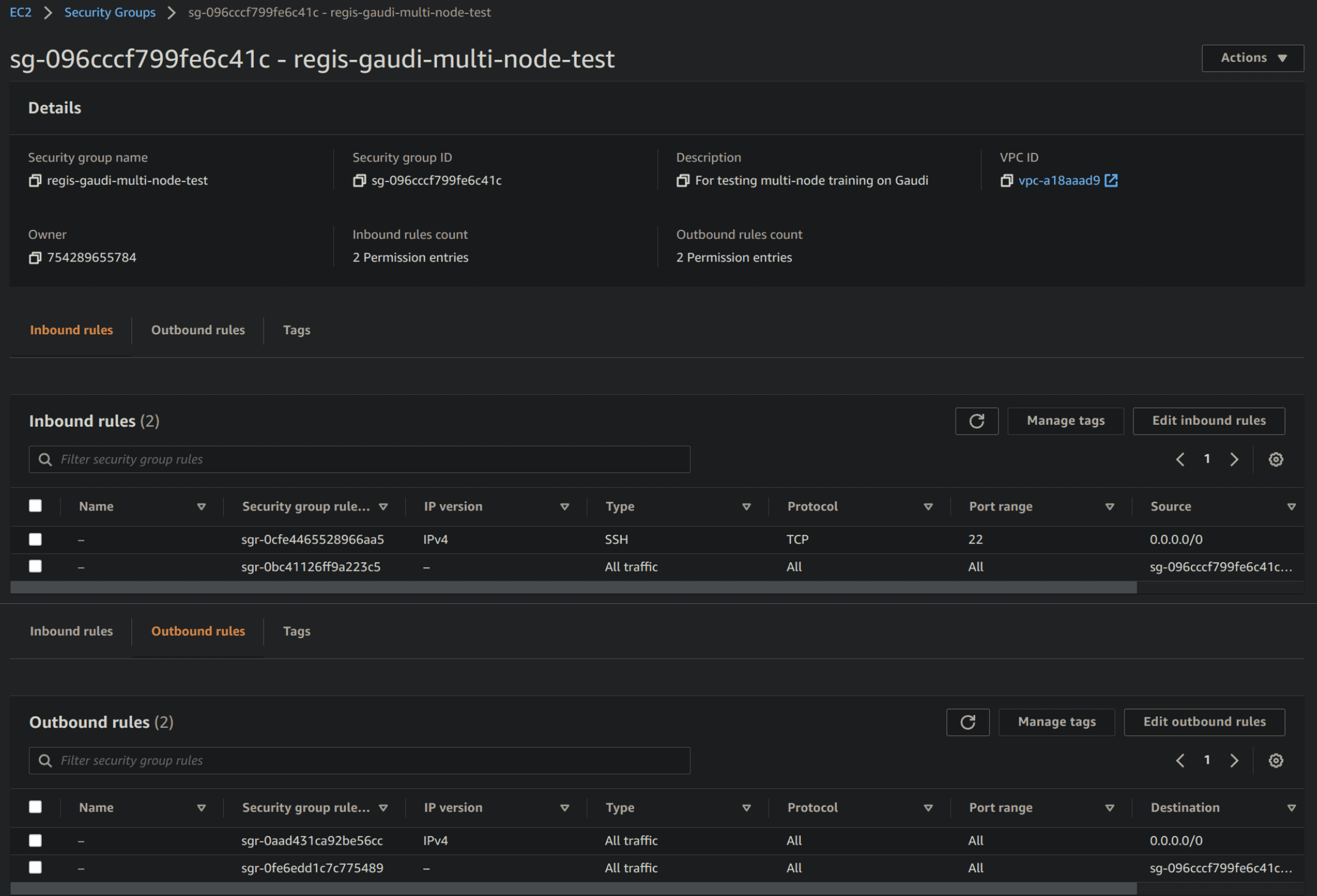 Security group for multi-node training on AWS DL1 instances
Security group for multi-node training on AWS DL1 instances
2. Launching instances
When you launch instances from the AWS EC2 console, you can choose the number of nodes to set up.
We recommend using the Habana Deep Learning Base AMI for your AWS DL1 instances. It is an EFA-enabled AMI so you do not need to install the EFA software (which may be necessary if you use a different AMI, installation instructions here).
Then, in the Network settings, select the security group you created in the previous step. You also have to select a specific subnet to unlock the Advanced network configuration in which you can enable the Elastic Fabric Adapter.
The last parameter to set is the Placement group in the Advanced details. You can create one if you do not have any. The placement strategy should be set to cluster.
Here is how it should look:
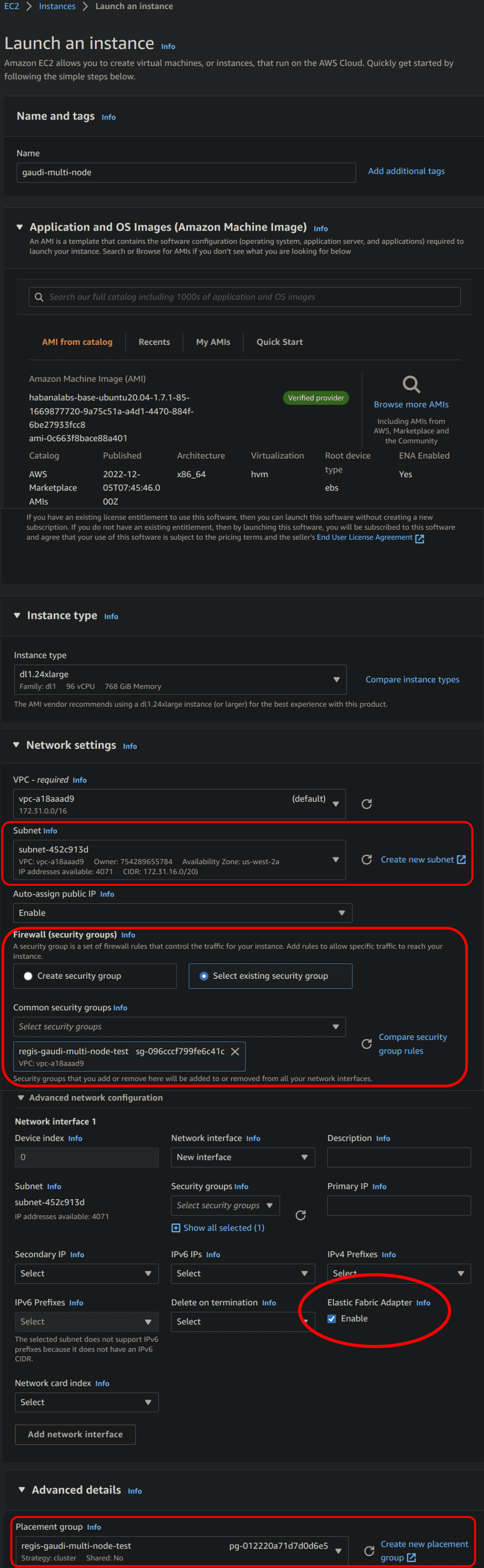 Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
More information here.
Launching a Multi-node Run
Once your Gaudi instances are ready, you need to:
- Enable password-less SSH on your instances so that they can communicate with each other. This explains how to do it.
- On AWS, to train through EFA,
hccl_ofi_wrappershould be installed. Here is how to do it. - On AWS, you need to set the following environment variables (the easiest way is to write a
.deepspeed_envfile as described here):
HCCL_OVER_OFI=1LD_LIBRARY_PATH=path_to_hccl_ofi_wrapper:/opt/amazon/openmpi/lib:/opt/amazon/efa/libwherepath_to_hccl_ofi_wrapperis the path to thehccl_ofi_wrapperfolder which you installed in the previous step.- (optional)
HCCL_SOCKET_IFNAME=my_network_interface. If not set, the first network interface with a name that does not start withloordockerwill be used. More information here.
To make this easier, we provide a Dockerfile here.
You will just have to copy the public key of the leader node in the ~/.ssh/authorized_keys file of all other nodes to enable password-less SSH.
Then, you need to write a hostfile with the addresses and the numbers of devices of your nodes as follows:
ip_1 slots=8
ip_2 slots=8
...
ip_n slots=8Finally, there are two possible ways to run your training script on several nodes:
- With the
gaudi_spawn.pyscript, you can run the following command:
python gaudi_spawn.py \
--hostfile path_to_my_hostfile --use_deepspeed \
path_to_my_script.py --args1 --args2 ... --argsN \
--deepspeed path_to_my_deepspeed_configwhere --argX is an argument of the script to run.
- With the
DistributedRunner, you can add this code snippet to a script:
from optimum.habana.distributed import DistributedRunner
distributed_runner = DistributedRunner(
command_list=["path_to_my_script.py --args1 --args2 ... --argsN"],
hostfile=path_to_my_hostfile,
use_deepspeed=True,
)Environment Variables
If you need to set environment variables for all nodes, you can specify them in a .deepspeed_env file which should be located in the local path you are executing from or in your home directory. The format is the following:
env_variable_1_name=value
env_variable_2_name=value
...You can find an example for AWS instances here.
Recommendations
- It is strongly recommended to use gradient checkpointing for multi-node runs to get the highest speedups. You can enable it with
--gradient_checkpointingin these examples or withgradient_checkpointing=Truein yourGaudiTrainingArguments. - Larger batch sizes should lead to higher speedups.
- Multi-node inference is not recommended and can provide inconsistent results.
- On AWS DL1 instances, run your Docker containers with the
--privilegedflag so that EFA devices are visible.
Example
In this example, we fine-tune a pre-trained GPT2-XL model on the WikiText dataset. We are going to use the causal language modeling example which is given in the Github repository.
The first step consists in training the model on several nodes with this command:
python ../gaudi_spawn.py \
--hostfile path_to_hostfile --use_deepspeed run_clm.py \
--model_name_or_path gpt2-xl \
--gaudi_config_name Habana/gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--output_dir /tmp/gpt2_xl_multi_node \
--learning_rate 4e-04 \
--per_device_train_batch_size 16 \
--gradient_checkpointing \
--num_train_epochs 1 \
--use_habana \
--use_lazy_mode \
--throughput_warmup_steps 3 \
--deepspeed path_to_deepspeed_configEvaluation is not performed in the same command because we do not recommend performing multi-node inference at the moment.
Once the model is trained, we can evaluate it with the following command.
The argument --model_name_or_path should be equal to the argument --output_dir of the previous command.
python run_clm.py \
--model_name_or_path /tmp/gpt2_xl_multi_node \
--gaudi_config_name Habana/gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_eval \
--output_dir /tmp/gpt2_xl_multi_node \
--per_device_eval_batch_size 8 \
--use_habana \
--use_lazy_mode