optimum-onnx documentation
Accelerated inference on NVIDIA GPUs
Accelerated inference on NVIDIA GPUs
By default, ONNX Runtime runs inference on CPU devices. However, it is possible to place supported operations on an NVIDIA GPU, while leaving any unsupported ones on CPU. In most cases, this allows costly operations to be placed on GPU and significantly accelerate inference.
This guide will show you how to run inference on two execution providers that ONNX Runtime supports for NVIDIA GPUs:
CUDAExecutionProvider: Generic acceleration on NVIDIA CUDA-enabled GPUs.TensorrtExecutionProvider: Uses NVIDIA’s TensorRT inference engine and generally provides the best runtime performance.
Due to a limitation of ONNX Runtime, it is not possible to run quantized models on
CUDAExecutionProviderand only models with static quantization can be run onTensorrtExecutionProvider.
CUDAExecutionProvider
CUDA installation
Provided the CUDA and cuDNN requirements are satisfied, install the additional dependencies by running
pip install optimum[onnxruntime-gpu]
To avoid conflicts between onnxruntime and onnxruntime-gpu, make sure the package onnxruntime is not installed by running pip uninstall onnxruntime prior to installing Optimum.
Checking the CUDA installation is successful
Before going further, run the following sample code to check whether the install was successful:
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "philschmid/tiny-bert-sst2-distilled",
... export=True,
... provider="CUDAExecutionProvider",
... )
>>> tokenizer = AutoTokenizer.from_pretrained("philschmid/tiny-bert-sst2-distilled")
>>> inputs = tokenizer("expectations were low, actual enjoyment was high", return_tensors="pt", padding=True)
>>> outputs = ort_model(**inputs)
>>> assert ort_model.providers == ["CUDAExecutionProvider", "CPUExecutionProvider"]In case this code runs gracefully, congratulations, the installation is successful! If you encounter the following error or similar,
ValueError: Asked to use CUDAExecutionProvider as an ONNX Runtime execution provider, but the available execution providers are ['CPUExecutionProvider'].then something is wrong with the CUDA or ONNX Runtime installation.
Use CUDA execution provider with floating-point models
For non-quantized models, the use is straightforward. Simply specify the provider argument in the ORTModel.from_pretrained() method. Here’s an example:
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english",
... export=True,
... provider="CUDAExecutionProvider",
... )The model can then be used with the common 🤗 Transformers API for inference and evaluation, such as pipelines.
When using Transformers pipeline, note that the device argument should be set to perform pre- and post-processing on GPU, following the example below:
>>> from optimum.onnxruntime import pipeline
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
>>> pipe = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
>>> result = pipe("Both the music and visual were astounding, not to mention the actors performance.")
>>> print(result)
# printing: [{'label': 'POSITIVE', 'score': 0.9997727274894714}]Additionally, you can pass the session option log_severity_level = 0 (verbose), to check whether all nodes are indeed placed on the CUDA execution provider or not:
>>> import onnxruntime
>>> session_options = onnxruntime.SessionOptions()
>>> session_options.log_severity_level = 0
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english",
... export=True,
... provider="CUDAExecutionProvider",
... session_options=session_options
... )You should see the following logs:
2022-10-18 14:59:13.728886041 [V:onnxruntime:, session_state.cc:1193 VerifyEachN
odeIsAssignedToAnEp] Provider: [CPUExecutionProvider]: [Gather (Gather_76), Uns
queeze (Unsqueeze_78), Gather (Gather_97), Gather (Gather_100), Concat (Concat_1
10), Unsqueeze (Unsqueeze_125), ...]
2022-10-18 14:59:13.728906431 [V:onnxruntime:, session_state.cc:1193 VerifyEachN
odeIsAssignedToAnEp] Provider: [CUDAExecutionProvider]: [Shape (Shape_74), Slic
e (Slice_80), Gather (Gather_81), Gather (Gather_82), Add (Add_83), Shape (Shape
_95), MatMul (MatMul_101), ...]In this example, we can see that all the costly MatMul operations are placed on the CUDA execution provider.
Use CUDA execution provider with quantized models
Due to current limitations in ONNX Runtime, it is not possible to use quantized models with CUDAExecutionProvider. The reasons are as follows:
When using 🤗 Optimum dynamic quantization, nodes as
MatMulInteger,DynamicQuantizeLinearmay be inserted in the ONNX graph, that cannot be consumed by the CUDA execution provider.When using static quantization, the ONNX computation graph will contain matrix multiplications and convolutions in floating-point arithmetic, along with Quantize + Dequantize operations to simulate quantization. In this case, although the costly matrix multiplications and convolutions will be run on the GPU, they will use floating-point arithmetic as the
CUDAExecutionProvidercan not consume the Quantize + Dequantize nodes to replace them by the operations using integer arithmetic.
Reduce memory footprint with IOBinding
IOBinding is an efficient way to avoid expensive data copying when using GPUs. By default, ONNX Runtime will copy the input from the CPU (even if the tensors are already copied to the targeted device), and assume that outputs also need to be copied back to the CPU from GPUs after the run. These data copying overheads between the host and devices are expensive, and can lead to worse inference latency than vanilla PyTorch especially for the decoding process.
To avoid the slowdown, 🤗 Optimum adopts the IOBinding to copy inputs onto GPUs and pre-allocate memory for outputs prior the inference. When instantiating the ORTModel, set the value of the argument use_io_binding to choose whether to turn on the IOBinding during the inference. use_io_binding is set to True by default, if you choose CUDA as execution provider.
And if you want to turn off IOBinding:
>>> from transformers import AutoTokenizer, pipeline
>>> from optimum.onnxruntime import ORTModelForSeq2SeqLM
# Load the model from the hub and export it to the ONNX format
>>> model = ORTModelForSeq2SeqLM.from_pretrained("t5-small", export=True, use_io_binding=False)
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
# Create a pipeline
>>> onnx_translation = pipeline("translation_en_to_fr", model=model, tokenizer=tokenizer, device="cuda:0")For the time being, IOBinding is supported for task-defined ORT models, if you want us to add support for custom models, file us an issue on the Optimum’s repository.
Observed time gains
We tested three common models with a decoding process: GPT2 / T5-small / M2M100-418M, and the benchmark was run on a versatile Tesla T4 GPU (more environment details at the end of this section).
Here are some performance results running with CUDAExecutionProvider when IOBinding has been turned on. We have tested input sequence length from 8 to 512, and generated outputs both with greedy search and beam search (num_beam=5):
|
|
|
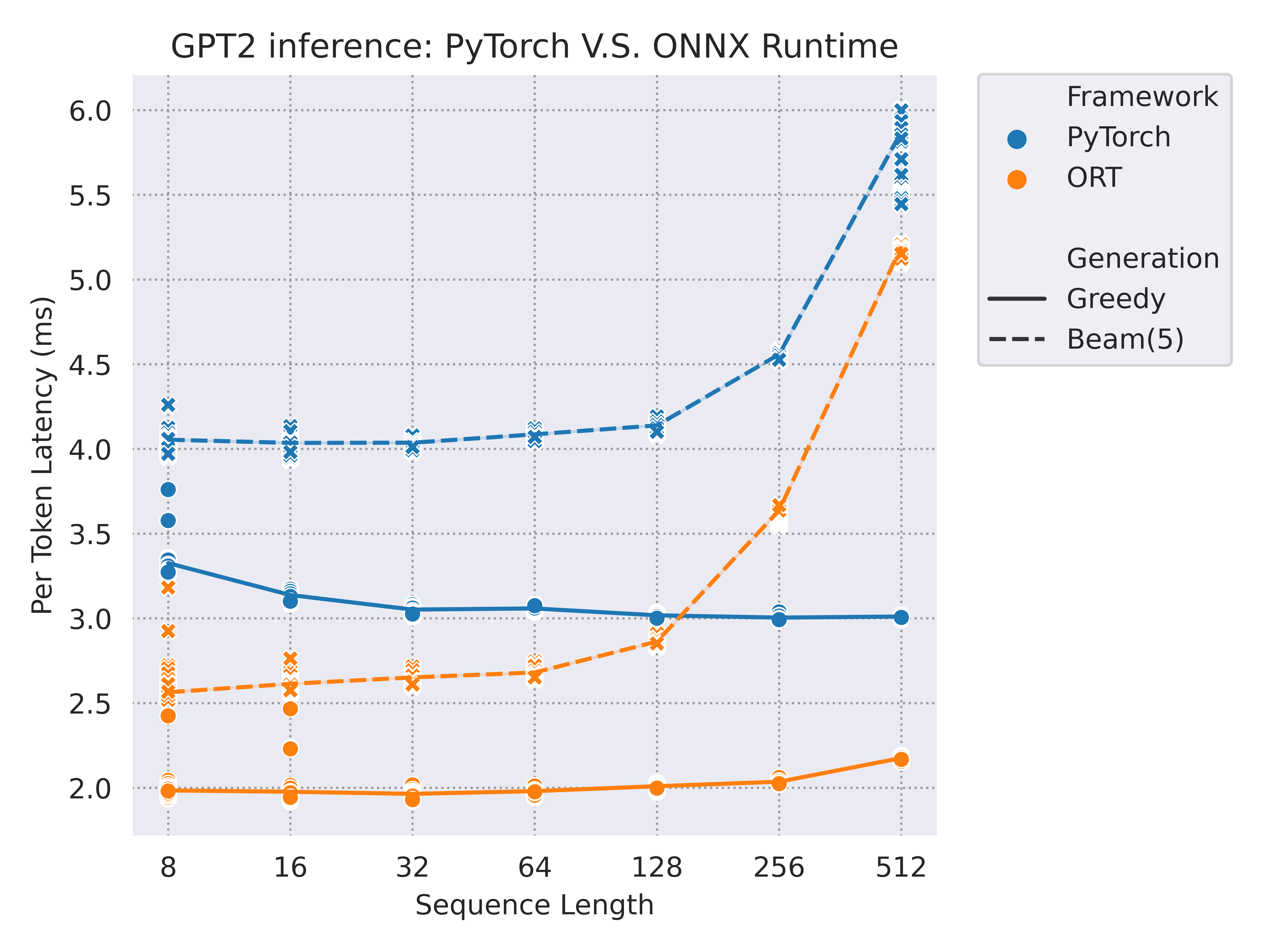
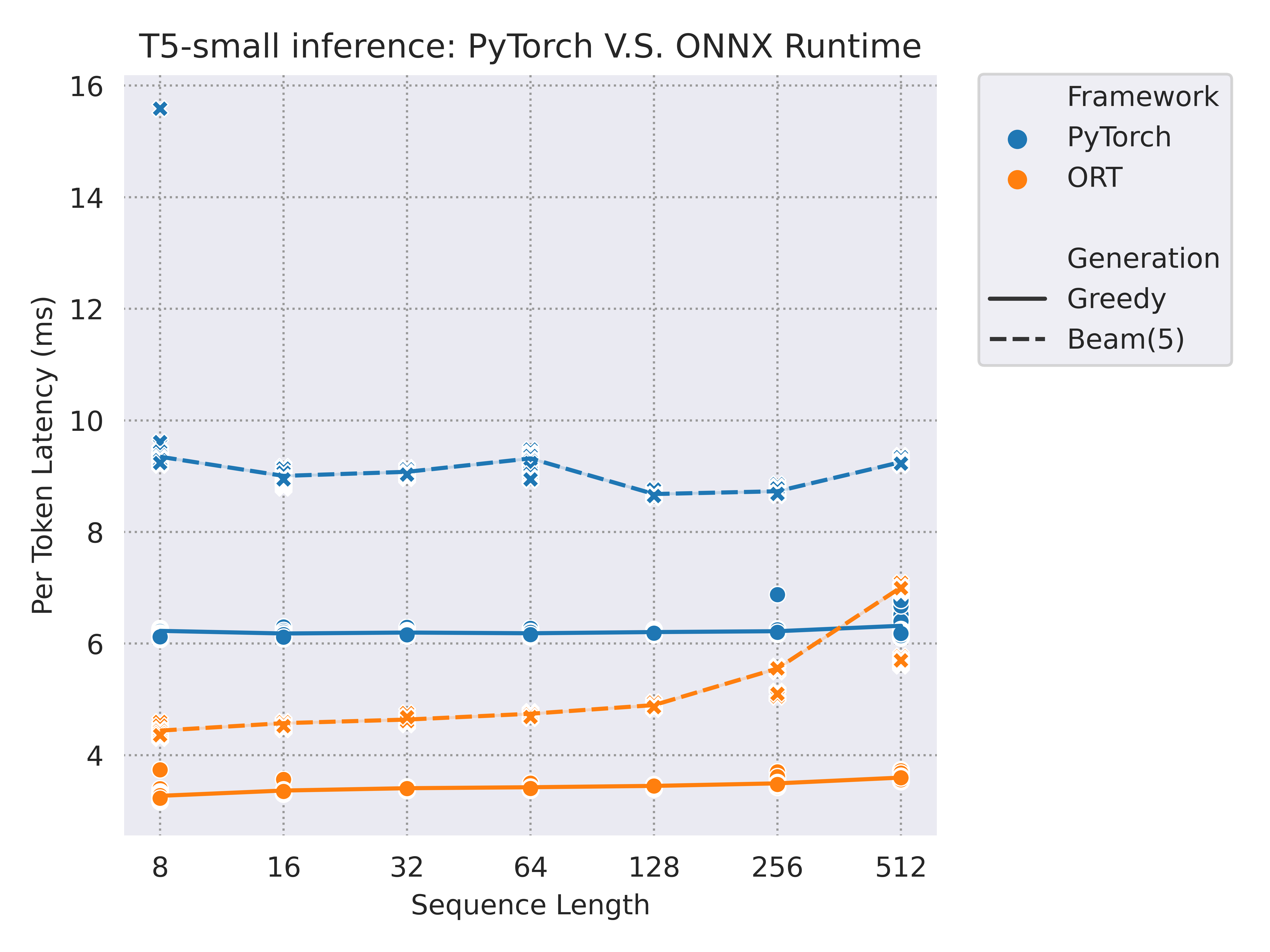
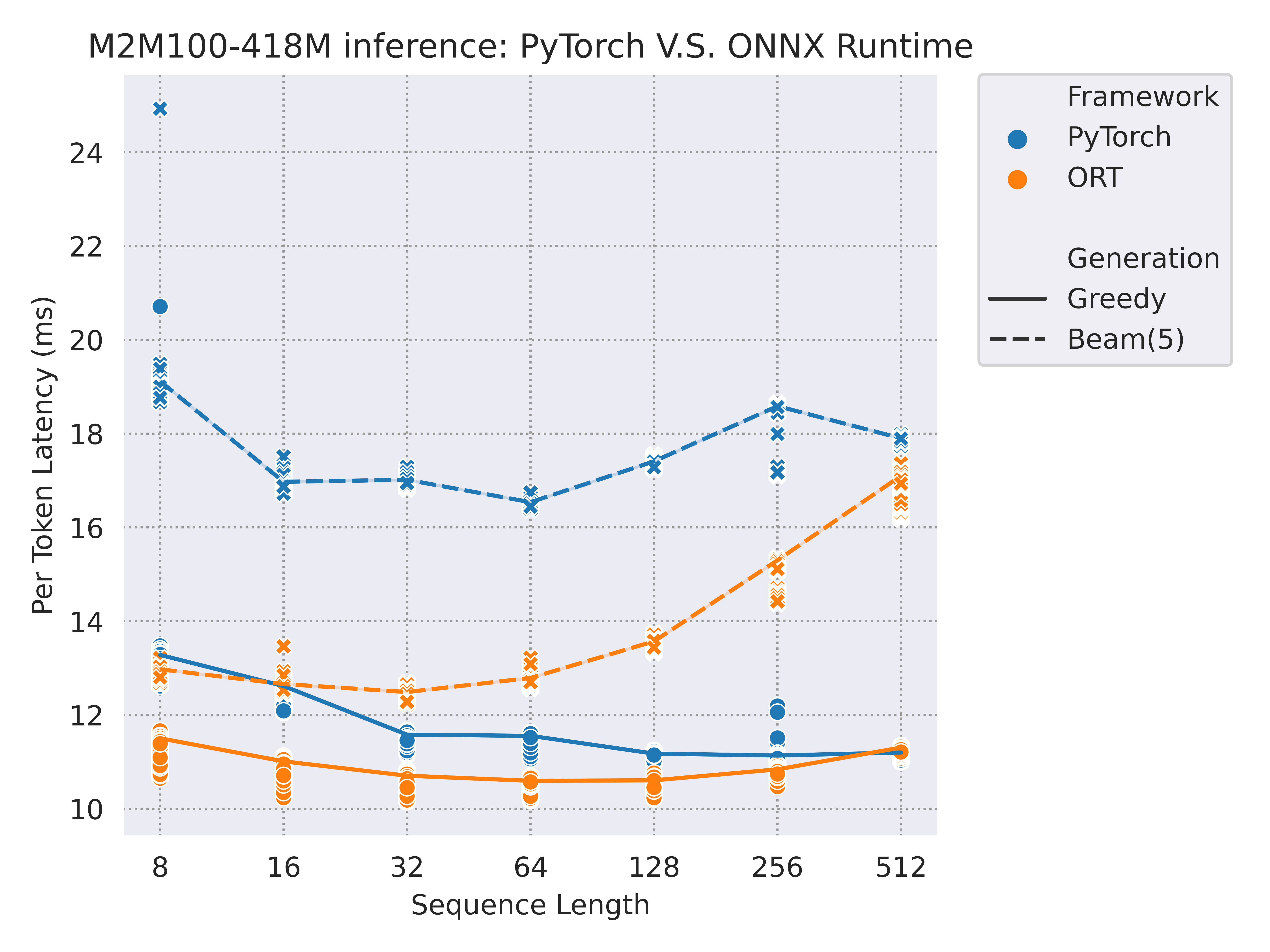
And here is a summary for the saving time with different sequence lengths (32 / 128) and generation modes(greedy search / beam search) while using ONNX Runtime compared with PyTorch:
|
|
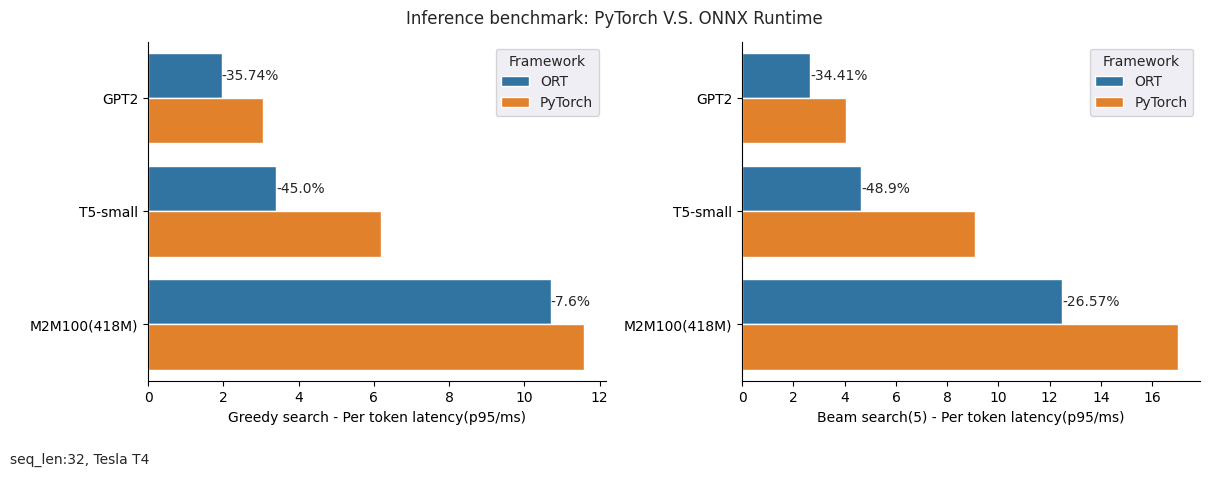
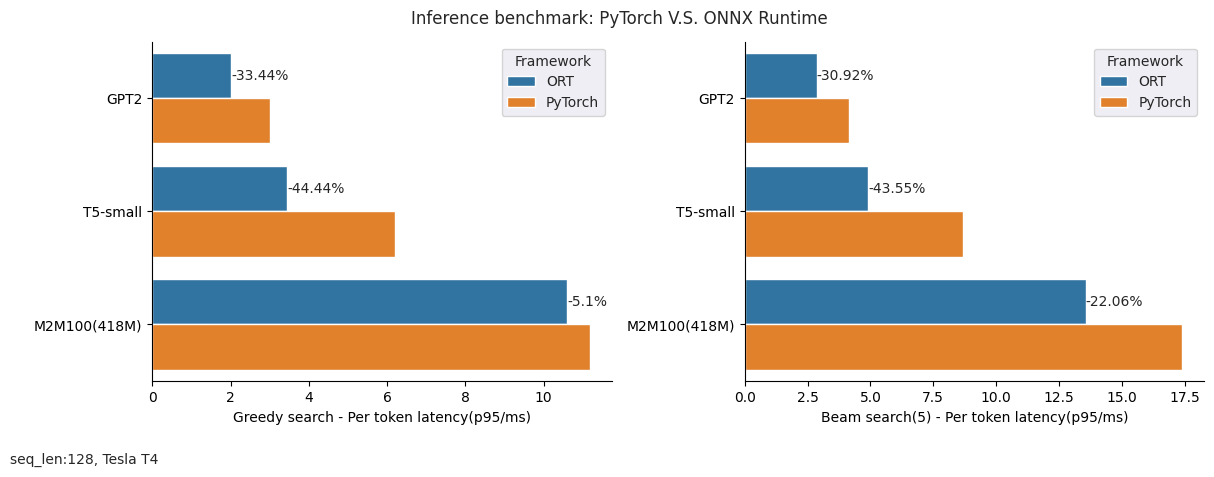
Environment:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 28C P8 8W / 70W | 0MiB / 15109MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
- Platform: Linux-5.4.0-1089-aws-x86_64-with-glibc2.29
- Python version: 3.8.10
- `transformers` version: 4.24.0
- `optimum` version: 1.5.0
- PyTorch version: 1.12.0+cu113Note that previous experiments are run with vanilla ONNX models exported directly from the exporter. If you are interested in further acceleration, with ORTOptimizer you can optimize the graph and convert your model to FP16 if you have a GPU with mixed precision capabilities.
TensorrtExecutionProvider
TensorRT uses its own set of optimizations, and generally does not support the optimizations from ORTOptimizer. We therefore recommend to use the original ONNX models when using TensorrtExecutionProvider (reference).
TensorRT installation
The easiest way to use TensorRT as the execution provider for models optimized through 🤗 Optimum is with the available ONNX Runtime TensorrtExecutionProvider.
In order to use 🤗 Optimum with TensorRT in a local environment, we recommend following the NVIDIA installation guides:
- CUDA toolkit: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- cuDNN: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
- TensorRT: https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html
For TensorRT, we recommend the Tar File Installation method. Alternatively, TensorRT may be installable with pip by following these instructions.
Once the required packages are installed, the following environment variables need to be set with the appropriate paths for ONNX Runtime to detect TensorRT installation:
export CUDA_PATH=/usr/local/cuda
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-x.x/lib64:/path/to/TensorRT-8.x.x/libChecking the TensorRT installation is successful
Before going further, run the following sample code to check whether the install was successful:
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "philschmid/tiny-bert-sst2-distilled",
... export=True,
... provider="TensorrtExecutionProvider",
... )
>>> tokenizer = AutoTokenizer.from_pretrained("philschmid/tiny-bert-sst2-distilled")
>>> inp = tokenizer("expectations were low, actual enjoyment was high", return_tensors="pt", padding=True)
>>> result = ort_model(**inp)
>>> assert ort_model.providers == ["TensorrtExecutionProvider", "CUDAExecutionProvider", "CPUExecutionProvider"]In case this code runs gracefully, congratulations, the installation is successful!
In case the above assert fails, or you encounter the following warning
Failed to create TensorrtExecutionProvider. Please reference https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html#requirements to ensure all dependencies are met.something is wrong with the TensorRT or ONNX Runtime installation.
TensorRT engine build and warmup
TensorRT requires to build its inference engine ahead of inference, which takes some time due to the model optimization and nodes fusion. To avoid rebuilding the engine every time the model is loaded, ONNX Runtime provides a pair of options to save the engine: trt_engine_cache_enable and trt_engine_cache_path.
We recommend setting these two provider options when using the TensorRT execution provider. The usage is as follows, where optimum/gpt2 is an ONNX model converted from PyTorch using the Optimum ONNX exporter:
>>> from optimum.onnxruntime import ORTModelForCausalLM
>>> provider_options = {
... "trt_engine_cache_enable": True,
... "trt_engine_cache_path": "tmp/trt_cache_gpt2_example"
... }
# the TensorRT engine is not built here, it will be when doing inference
>>> ort_model = ORTModelForCausalLM.from_pretrained(
... "optimum/gpt2",
... use_cache=False,
... provider="TensorrtExecutionProvider",
... provider_options=provider_options
... )TensorRT builds its engine depending on specified input shapes. One big issue is that building the engine can be time consuming, especially for large models. Therefore, as a workaround, one recommendation is to build the TensorRT engine with dynamic shapes. This allows to avoid rebuilding the engine for new small and large shapes, which is unwanted once the model is deployed for inference.
To do so we use the provider’s options trt_profile_min_shapes, trt_profile_max_shapes and trt_profile_opt_shapes to specify the minimum, maximum and optimal shapes for the engine. For example, for GPT2, we can use the following shapes:
provider_options = {
"trt_profile_min_shapes": "input_ids:1x1,attention_mask:1x1,position_ids:1x1",
"trt_profile_opt_shapes": "input_ids:1x1,attention_mask:1x1,position_ids:1x1",
"trt_profile_max_shapes": "input_ids:1x64,attention_mask:1x64,position_ids:1x64",
}Passing the engine cache path in the provider options, the engine can therefore be built once for all and used fully for inference thereafter.
For example, for text generation, the engine can be built with:
>>> import os
>>> from optimum.onnxruntime import ORTModelForCausalLM
>>> os.makedirs("tmp/trt_cache_gpt2_example", exist_ok=True)
>>> provider_options = {
... "trt_engine_cache_enable": True,
... "trt_engine_cache_path": "tmp/trt_cache_gpt2_example",
... "trt_profile_min_shapes": "input_ids:1x1,attention_mask:1x1,position_ids:1x1",
... "trt_profile_opt_shapes": "input_ids:1x1,attention_mask:1x1,position_ids:1x1",
... "trt_profile_max_shapes": "input_ids:1x64,attention_mask:1x64,position_ids:1x64",
... }
>>> ort_model = ORTModelForCausalLM.from_pretrained(
... "optimum/gpt2",
... use_cache=False,
... provider="TensorrtExecutionProvider",
... provider_options=provider_options,
... )The engine is stored as:

Once the engine is built, the cache can be reloaded and generation does not need to rebuild the engine:
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForCausalLM
>>> provider_options = {
... "trt_engine_cache_enable": True,
... "trt_engine_cache_path": "tmp/trt_cache_gpt2_example"
... }
>>> ort_model = ORTModelForCausalLM.from_pretrained(
... "optimum/gpt2",
... use_cache=False,
... provider="TensorrtExecutionProvider",
... provider_options=provider_options,
... )
>>> tokenizer = AutoTokenizer.from_pretrained("optimum/gpt2")
>>> text = ["Replace me by any text you'd like."]
>>> encoded_input = tokenizer(text, return_tensors="pt").to("cuda")
>>> for i in range(3):
... output = ort_model.generate(**encoded_input)
... print(tokenizer.decode(output[0])) # doctest: +IGNORE_RESULTWarmup
Once the engine is built, it is recommended to do before inference one or a few warmup steps, as the first inference runs have some overhead.
Use TensorRT execution provider with floating-point models
For non-quantized models, the use is straightforward, by simply using the provider argument in ORTModel.from_pretrained(). For example:
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english",
... export=True,
... provider="TensorrtExecutionProvider",
... )As previously for CUDAExecutionProvider, by passing the session option log_severity_level = 0 (verbose), we can check in the logs whether all nodes are indeed placed on the TensorRT execution provider or not:
2022-09-22 14:12:48.371513741 [V:onnxruntime:, session_state.cc:1188 VerifyEachNodeIsAssignedToAnEp] All nodes have been placed on [TensorrtExecutionProvider]The model can then be used with the common 🤗 Transformers API for inference and evaluation, such as pipelines.
Use TensorRT execution provider with quantized models
When it comes to quantized models, TensorRT only supports models that use static quantization with symmetric quantization for weights and activations.
🤗 Optimum provides a quantization config ready to be used with ORTQuantizer with the constraints of TensorRT quantization:
>>> from optimum.onnxruntime import AutoQuantizationConfig
>>> qconfig = AutoQuantizationConfig.tensorrt(per_channel=False)Using this qconfig, static quantization can be performed as explained in the static quantization guide.
In the code sample below, after performing static quantization, the resulting model is loaded into the ORTModel class using TensorRT as the execution provider. ONNX Runtime graph optimization needs to be disabled for the model to be consumed and optimized by TensorRT, and the fact that INT8 operations are used needs to be specified to TensorRT.
>>> import onnxruntime
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> session_options = onnxruntime.SessionOptions()
>>> session_options.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_DISABLE_ALL
>>> tokenizer = AutoTokenizer.from_pretrained("fxmarty/distilbert-base-uncased-sst2-onnx-int8-for-tensorrt")
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "fxmarty/distilbert-base-uncased-sst2-onnx-int8-for-tensorrt",
... provider="TensorrtExecutionProvider",
... session_options=session_options,
... provider_options={"trt_int8_enable": True},
>>> )
>>> inp = tokenizer("TensorRT is a bit painful to use, but at the end of day it runs smoothly and blazingly fast!", return_tensors="np")
>>> res = ort_model(**inp)
>>> print(res)
>>> print(ort_model.config.id2label[res.logits[0].argmax()])
>>> # SequenceClassifierOutput(loss=None, logits=array([[-0.545066 , 0.5609764]], dtype=float32), hidden_states=None, attentions=None)
>>> # POSITIVEThe model can then be used with the common 🤗 Transformers API for inference and evaluation, such as pipelines.
TensorRT limitations for quantized models
As highlighted in the previous section, TensorRT supports only a limited range of quantized models:
- Static quantization only
- Weights and activations quantization ranges are symmetric
- Weights need to be stored in float32 in the ONNX model, thus there is no storage space saving from quantization. TensorRT indeed requires to insert full Quantize + Dequantize pairs. Normally, weights would be stored in fixed point 8-bits format and only a
DequantizeLinearwould be applied on the weights.
In case provider="TensorrtExecutionProvider" is passed and the model has not been quantized strictly following these constraints, various errors may be raised, where error messages can be unclear.
Observed time gains
Nvidia Nsight Systems tool can be used to profile the execution time on GPU. Before profiling or measuring latency/throughput, it is a good practice to do a few warmup steps.
Coming soon!