Hub Python Library documentation
Verwalten des huggingface_hub Cache-Systems
Verwalten des huggingface_hub Cache-Systems
Caching verstehen
Das Hugging Face Hub Cache-System wurde entwickelt, um der zentrale Cache zu sein, der zwischen Bibliotheken geteilt wird, welche vom Hub abhängen. Es wurde in v0.8.0 aktualisiert, um das erneute Herunterladen von Dateien zwischen Revisionen zu verhindern.
Das Cache-System ist wie folgt aufgebaut:
<CACHE_DIR>
├─ <MODELS>
├─ <DATASETS>
├─ <SPACES>Der <CACHE_DIR> ist normalerweise das Home-Verzeichnis Ihres Benutzers. Es kann jedoch mit dem
cache_dir-Argument in allen Methoden oder durch Angabe der Umgebungsvariablen
HF_HOME oder HF_HUB_CACHE angepasst werden.
Modelle, Datensätze und Räume teilen eine gemeinsame Wurzel. Jedes dieser Repositories enthält den Repository-Typ, den Namensraum (Organisation oder Benutzername), falls vorhanden, und den Repository-Namen:
<CACHE_DIR>
├─ models--julien-c--EsperBERTo-small
├─ models--lysandrejik--arxiv-nlp
├─ models--bert-base-cased
├─ datasets--glue
├─ datasets--huggingface--DataMeasurementsFiles
├─ spaces--dalle-mini--dalle-miniInnerhalb dieser Ordner werden nun alle Dateien vom Hub heruntergeladen. Das Caching stellt sicher, dass eine Datei nicht zweimal heruntergeladen wird, wenn sie bereits existiert und nicht aktualisiert wurde; wurde sie jedoch aktualisiert und Sie fordern die neueste Datei an, wird die neueste Datei heruntergeladen (während die vorherige Datei intakt bleibt, falls Sie sie erneut benötigen).
Um dies zu erreichen, enthalten alle Ordner dasselbe Grundgerüst:
<CACHE_DIR>
├─ datasets--glue
│ ├─ refs
│ ├─ blobs
│ ├─ snapshots
...Jeder Ordner ist so gestaltet, dass er das Folgende enthält:
Refs
Der Ordner refs enthält Dateien, die die neueste Revision des gegebenen Verweises anzeigen.
Zum Beispiel, wenn wir zuvor eine Datei aus dem main-Branch eines Repositories abgerufen haben,
wird der Ordner refs eine Datei namens main enthalten, die selbst den Commit-Identifikator der aktuellen HEAD-Branch enthält.
Wenn der neueste Commit von main den Identifikator aaaaaa hat, dann enthält er aaaaaa.
Wenn derselbe Zweig mit einem neuen Commit aktualisiert wird, der den Identifikator bbbbbb hat,
wird das erneute Herunterladen einer Datei von diesem Verweis die Datei refs/main aktualisieren, um bbbbbb zu enthalten.
Blobs
Der Ordner blobs enthält die tatsächlichen Dateien, die wir heruntergeladen haben. Der Name jeder Datei ist ihr Hash.
Snapshots
Der Ordner snapshots enthält Symlinks zu den oben erwähnten Blobs.
Er besteht selbst aus mehreren Ordnern: einem pro bekannter Revision!
In der obigen Erklärung hatten wir zunächst eine Datei von der Revision aaaaaa abgerufen, bevor wir eine Datei
von der Revision bbbbbb abgerufen haben. In dieser Situation hätten wir jetzt zwei Ordner im Ordner snapshots: aaaaaa und bbbbbb.
In jedem dieser Ordner leben Symlinks, die die Namen der Dateien haben, die wir heruntergeladen haben.
Wenn wir zum Beispiel die Datei README.md in der Revision aaaaaa heruntergeladen hätten, hätten wir den folgenden Pfad:
<CACHE_DIR>/<REPO_NAME>/snapshots/aaaaaa/README.mdDiese README.md-Datei ist tatsächlich ein Symlink, der auf den Blob verweist, der den Hash der Datei hat.
Durch das Erstellen des Grundgerüsts auf diese Weise ermöglichen wir den Mechanismus der Dateifreigabe:
Wenn dieselbe Datei in der Revision bbbbbb abgerufen wurde, hätte sie denselben Hash und die Datei müsste nicht erneut heruntergeladen werden.
.no_exist (fortgeschritten)
Zusätzlich zu den Ordnern blobs, refs und snapshots könnten Sie in Ihrem Cache auch einen .no_exist Ordner finden.
Dieser Ordner hält fest, welche Dateien Sie einmal versucht haben herunterzuladen, die jedoch nicht auf dem Hub vorhanden sind.
Seine Struktur ist dieselbe wie der snapshots Ordner mit einem Unterordner pro bekannter Revision:
<CACHE_DIR>/<REPO_NAME>/.no_exist/aaaaaa/config_that_does_not_exist.jsonIm Gegensatz zum snapshots Ordner handelt es sich bei den Dateien um einfache leere Dateien (keine Symlinks).
In diesem Beispiel existiert die Datei "config_that_does_not_exist.json" nicht auf dem Hub für die Revision "aaaaaa".
Da dieser Ordner nur leere Dateien speichert, ist sein Speicherplatzverbrauch vernachlässigbar.
Sie fragen sich jetzt vielleicht, warum diese Information überhaupt relevant ist?
In einigen Fällen versucht ein Framework, optionale Dateien für ein Modell zu laden.
Das Speichern der Nicht-Existenz optionaler Dateien beschleunigt das Laden eines Modells, da 1 HTTP-Anfrage pro möglicher optionaler Datei gespart wird.
Dies ist zum Beispiel bei transformers der Fall, wo jeder Tokenizer zusätzliche Dateien unterstützen kann. Beim ersten Laden des Tokenizers
auf Ihrem Gerät wird im Cache gespeichert, welche optionalen Dateien vorhanden sind (und welche nicht), um die Ladezeit bei den nächsten Initialisierungen zu beschleunigen.
Um zu testen, ob eine Datei lokal im Cache gespeichert ist (ohne eine HTTP-Anfrage zu senden), können Sie die try_to_load_from_cache() Hilfsfunktion verwenden.
Sie gibt entweder den Dateipfad zurück (falls vorhanden und im Cache gespeichert), das Objekt _CACHED_NO_EXIST (wenn die Nicht-Existenz im Cache gespeichert ist)
oder None (wenn wir es nicht wissen).
from huggingface_hub import try_to_load_from_cache, _CACHED_NO_EXIST
filepath = try_to_load_from_cache()
if isinstance(filepath, str):
# file exists and is cached
...
elif filepath is _CACHED_NO_EXIST:
# non-existence of file is cached
...
else:
# file is not cached
...In der Praxis
In der Praxis sollte Ihr Cache folgendermaßen aussehen:
[ 96] .
└── [ 160] models--julien-c--EsperBERTo-small
├── [ 160] blobs
│ ├── [321M] 403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bd
│ ├── [ 398] 7cb18dc9bafbfcf74629a4b760af1b160957a83e
│ └── [1.4K] d7edf6bd2a681fb0175f7735299831ee1b22b812
├── [ 96] refs
│ └── [ 40] main
└── [ 128] snapshots
├── [ 128] 2439f60ef33a0d46d85da5001d52aeda5b00ce9f
│ ├── [ 52] README.md -> ../../blobs/d7edf6bd2a681fb0175f7735299831ee1b22b812
│ └── [ 76] pytorch_model.bin -> ../../blobs/403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bd
└── [ 128] bbc77c8132af1cc5cf678da3f1ddf2de43606d48
├── [ 52] README.md -> ../../blobs/7cb18dc9bafbfcf74629a4b760af1b160957a83e
└── [ 76] pytorch_model.bin -> ../../blobs/403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bdEinschränkungen
Um ein effizientes Cache-System zu haben, verwendet huggingface-hub Symlinks. Allerdings
werden Symlinks nicht auf allen Maschinen unterstützt. Dies ist eine bekannte Einschränkung,
insbesondere bei Windows. Wenn dies der Fall ist, verwendet huggingface_hub nicht das blobs/ Verzeichnis,
sondern speichert die Dateien direkt im snapshots/ Verzeichnis. Dieser Workaround ermöglicht es den Nutzern,
Dateien vom Hub auf genau die gleiche Weise herunterzuladen und zu cachen.
Auch Werkzeuge zur Überprüfung und Löschung des Caches (siehe unten) werden unterstützt.
Allerdings ist das Cache-System weniger effizient, da eine einzelne Datei möglicherweise mehrmals heruntergeladen wird,
wenn mehrere Revisionen des gleichen Repos heruntergeladen werden.
Wenn Sie von dem Symlink-basierten Cache-System auf einem Windows-Gerät profitieren möchten, müssen Sie entweder den Entwicklermodus aktivieren oder Python als Administrator ausführen.
Wenn Symlinks nicht unterstützt werden, wird dem Nutzer eine Warnmeldung angezeigt, um ihn darauf hinzuweisen,
dass er eine eingeschränkte Version des Cache-Systems verwendet. Diese Warnung kann durch Setzen der
Umgebungsvariable HF_HUB_DISABLE_SYMLINKS_WARNING auf true deaktiviert werden.
Assets zwischenspeichern
Zusätzlich zum Zwischenspeichern von Dateien aus dem Hub benötigen nachgelagerte Bibliotheken
oft das Zwischenspeichern von anderen Dateien, die in Verbindung mit HF stehen, aber nicht
direkt von huggingface_hub behandelt werden (zum Beispiel: Dateien, die von GitHub heruntergeladen werden,
vorverarbeitete Daten, Protokolle,…). Um diese Dateien, die als assets bezeichnet werden, zwischenzuspeichern,
kann man cached_assets_path() verwenden. Dieser kleine Helfer generiert Pfade im HF-Cache auf eine einheitliche Weise,
basierend auf dem Namen der anfragenden Bibliothek und optional auf einem Namensraum und einem Unterordnernamen.
Das Ziel ist, dass jede nachgelagerte Bibliothek ihre Assets auf ihre eigene Weise verwaltet
(z.B. keine Regelung über die Struktur), solange sie im richtigen Assets-Ordner bleibt.
Diese Bibliotheken können dann die Werkzeuge von huggingface_hub nutzen, um den Cache zu verwalten,
insbesondere um Teile der Assets über einen CLI-Befehl zu scannen und zu löschen.
from huggingface_hub import cached_assets_path
assets_path = cached_assets_path(library_name="datasets", namespace="SQuAD", subfolder="download")
something_path = assets_path / "something.json" # Machen Sie, was Sie möchten, in Ihrem Assets-Ordner!cached_assets_path() ist der empfohlene Weg, um Assets zu speichern, ist jedoch nicht verpflichtend.
Wenn Ihre Bibliothek bereits ihren eigenen Cache verwendet, können Sie diesen gerne nutzen!
Assets in der Praxis
In der Praxis sollte Ihr Assets-Cache wie der folgende Verzeichnisbaum aussehen:
assets/
└── datasets/
│ ├── SQuAD/
│ │ ├── downloaded/
│ │ ├── extracted/
│ │ └── processed/
│ ├── Helsinki-NLP--tatoeba_mt/
│ ├── downloaded/
│ ├── extracted/
│ └── processed/
└── transformers/
├── default/
│ ├── something/
├── bert-base-cased/
│ ├── default/
│ └── training/
hub/
└── models--julien-c--EsperBERTo-small/
├── blobs/
│ ├── (...)
│ ├── (...)
├── refs/
│ └── (...)
└── [ 128] snapshots/
├── 2439f60ef33a0d46d85da5001d52aeda5b00ce9f/
│ ├── (...)
└── bbc77c8132af1cc5cf678da3f1ddf2de43606d48/
└── (...)Cache scannen
Derzeit werden zwischengespeicherte Dateien nie aus Ihrem lokalen Verzeichnis gelöscht:
Wenn Sie eine neue Revision eines Zweiges herunterladen, werden vorherige Dateien aufbewahrt,
falls Sie sie wieder benötigen. Daher kann es nützlich sein, Ihr Cache-Verzeichnis zu scannen,
um zu erfahren, welche Repos und Revisionen den meisten Speicherplatz beanspruchen.
huggingface_hub bietet einen Helfer dafür, der über huggingface-cli oder in einem Python-Skript verwendet werden kann.
Cache vom Terminal aus scannen
Die einfachste Möglichkeit, Ihr HF-Cache-System zu scannen, besteht darin, den Befehl scan-cache
aus dem huggingface-cli-Tool zu verwenden. Dieser Befehl scannt den Cache und gibt einen Bericht
mit Informationen wie Repo-ID, Repo-Typ, Speicherverbrauch, Referenzen und vollständigen lokalen Pfad aus.
Im folgenden Ausschnitt wird ein Scan-Bericht in einem Ordner angezeigt, in dem 4 Modelle und 2 Datensätze gecached sind.
➜ huggingface-cli scan-cache REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH --------------------------- --------- ------------ -------- ------------- ------------- ------------------- ------------------------------------------------------------------------- glue dataset 116.3K 15 4 days ago 4 days ago 2.4.0, main, 1.17.0 /home/wauplin/.cache/huggingface/hub/datasets--glue google/fleurs dataset 64.9M 6 1 week ago 1 week ago refs/pr/1, main /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs Jean-Baptiste/camembert-ner model 441.0M 7 2 weeks ago 16 hours ago main /home/wauplin/.cache/huggingface/hub/models--Jean-Baptiste--camembert-ner bert-base-cased model 1.9G 13 1 week ago 2 years ago /home/wauplin/.cache/huggingface/hub/models--bert-base-cased t5-base model 10.1K 3 3 months ago 3 months ago main /home/wauplin/.cache/huggingface/hub/models--t5-base t5-small model 970.7M 11 3 days ago 3 days ago refs/pr/1, main /home/wauplin/.cache/huggingface/hub/models--t5-small Done in 0.0s. Scanned 6 repo(s) for a total of 3.4G. Got 1 warning(s) while scanning. Use -vvv to print details.
Um einen detaillierteren Bericht zu erhalten, verwenden Sie die Option --verbose.
Für jedes Repository erhalten Sie eine Liste aller heruntergeladenen Revisionen.
Wie oben erläutert, werden Dateien, die sich zwischen 2 Revisionen nicht ändern,
dank der symbolischen Links geteilt. Das bedeutet, dass die Größe des Repositorys
auf der Festplatte voraussichtlich kleiner ist als die Summe der Größe jeder einzelnen Revision.
Zum Beispiel hat hier bert-base-cased 2 Revisionen von 1,4G und 1,5G,
aber der gesamte Festplattenspeicher beträgt nur 1,9G.
➜ huggingface-cli scan-cache -v REPO ID REPO TYPE REVISION SIZE ON DISK NB FILES LAST_MODIFIED REFS LOCAL PATH --------------------------- --------- ---------------------------------------- ------------ -------- ------------- ----------- ---------------------------------------------------------------------------------------------------------------------------- glue dataset 9338f7b671827df886678df2bdd7cc7b4f36dffd 97.7K 14 4 days ago main, 2.4.0 /home/wauplin/.cache/huggingface/hub/datasets--glue/snapshots/9338f7b671827df886678df2bdd7cc7b4f36dffd glue dataset f021ae41c879fcabcf823648ec685e3fead91fe7 97.8K 14 1 week ago 1.17.0 /home/wauplin/.cache/huggingface/hub/datasets--glue/snapshots/f021ae41c879fcabcf823648ec685e3fead91fe7 google/fleurs dataset 129b6e96cf1967cd5d2b9b6aec75ce6cce7c89e8 25.4K 3 2 weeks ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs/snapshots/129b6e96cf1967cd5d2b9b6aec75ce6cce7c89e8 google/fleurs dataset 24f85a01eb955224ca3946e70050869c56446805 64.9M 4 1 week ago main /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs/snapshots/24f85a01eb955224ca3946e70050869c56446805 Jean-Baptiste/camembert-ner model dbec8489a1c44ecad9da8a9185115bccabd799fe 441.0M 7 16 hours ago main /home/wauplin/.cache/huggingface/hub/models--Jean-Baptiste--camembert-ner/snapshots/dbec8489a1c44ecad9da8a9185115bccabd799fe bert-base-cased model 378aa1bda6387fd00e824948ebe3488630ad8565 1.5G 9 2 years ago /home/wauplin/.cache/huggingface/hub/models--bert-base-cased/snapshots/378aa1bda6387fd00e824948ebe3488630ad8565 bert-base-cased model a8d257ba9925ef39f3036bfc338acf5283c512d9 1.4G 9 3 days ago main /home/wauplin/.cache/huggingface/hub/models--bert-base-cased/snapshots/a8d257ba9925ef39f3036bfc338acf5283c512d9 t5-base model 23aa4f41cb7c08d4b05c8f327b22bfa0eb8c7ad9 10.1K 3 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-base/snapshots/23aa4f41cb7c08d4b05c8f327b22bfa0eb8c7ad9 t5-small model 98ffebbb27340ec1b1abd7c45da12c253ee1882a 726.2M 6 1 week ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/98ffebbb27340ec1b1abd7c45da12c253ee1882a t5-small model d0a119eedb3718e34c648e594394474cf95e0617 485.8M 6 4 weeks ago /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d0a119eedb3718e34c648e594394474cf95e0617 t5-small model d78aea13fa7ecd06c29e3e46195d6341255065d5 970.7M 9 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d78aea13fa7ecd06c29e3e46195d6341255065d5 Done in 0.0s. Scanned 6 repo(s) for a total of 3.4G. Got 1 warning(s) while scanning. Use -vvv to print details.
Grep-Beispiel
Da die Ausgabe im Tabellenformat erfolgt, können Sie sie mit grep-ähnlichen Tools kombinieren,
um die Einträge zu filtern. Hier ein Beispiel, um nur Revisionen vom Modell “t5-small”
auf einem Unix-basierten Gerät zu filtern.
➜ eval "huggingface-cli scan-cache -v" | grep "t5-small" t5-small model 98ffebbb27340ec1b1abd7c45da12c253ee1882a 726.2M 6 1 week ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/98ffebbb27340ec1b1abd7c45da12c253ee1882a t5-small model d0a119eedb3718e34c648e594394474cf95e0617 485.8M 6 4 weeks ago /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d0a119eedb3718e34c648e594394474cf95e0617 t5-small model d78aea13fa7ecd06c29e3e46195d6341255065d5 970.7M 9 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d78aea13fa7ecd06c29e3e46195d6341255065d5
Den Cache von Python aus scannen
Für eine erweiterte Nutzung verwenden Sie scan_cache_dir(), welches das von dem CLI-Tool
aufgerufene Python-Dienstprogramm ist.
Sie können es verwenden, um einen detaillierten Bericht zu erhalten, der um 4 Datenklassen herum strukturiert ist:
HFCacheInfo: vollständiger Bericht, der vonscan_cache_dir()zurückgegeben wirdCachedRepoInfo: Informationen über ein gecachtes RepoCachedRevisionInfo: Informationen über eine gecachtes Revision (z.B. “snapshot) in einem RepoCachedFileInfo: Informationen über eine gecachte Datei in einem Snapshot
Hier ist ein einfaches Anwendungs-Beispiel in Python. Siehe Referenz für Details.
>>> from huggingface_hub import scan_cache_dir
>>> hf_cache_info = scan_cache_dir()
HFCacheInfo(
size_on_disk=3398085269,
repos=frozenset({
CachedRepoInfo(
repo_id='t5-small',
repo_type='model',
repo_path=PosixPath(...),
size_on_disk=970726914,
nb_files=11,
last_accessed=1662971707.3567169,
last_modified=1662971107.3567169,
revisions=frozenset({
CachedRevisionInfo(
commit_hash='d78aea13fa7ecd06c29e3e46195d6341255065d5',
size_on_disk=970726339,
snapshot_path=PosixPath(...),
# No `last_accessed` as blobs are shared among revisions
last_modified=1662971107.3567169,
files=frozenset({
CachedFileInfo(
file_name='config.json',
size_on_disk=1197
file_path=PosixPath(...),
blob_path=PosixPath(...),
blob_last_accessed=1662971707.3567169,
blob_last_modified=1662971107.3567169,
),
CachedFileInfo(...),
...
}),
),
CachedRevisionInfo(...),
...
}),
),
CachedRepoInfo(...),
...
}),
warnings=[
CorruptedCacheException("Snapshots dir doesn't exist in cached repo: ..."),
CorruptedCacheException(...),
...
],
)Cache leeren
Das Durchsuchen Ihres Caches ist interessant, aber was Sie normalerweise als Nächstes tun möchten, ist
einige Teile zu löschen, um etwas Speicherplatz auf Ihrem Laufwerk freizugeben. Dies ist möglich mit dem
delete-cache CLI-Befehl. Man kann auch programmatisch den
delete_revisions() Helfer vom HFCacheInfo Objekt verwenden, das beim
Durchsuchen des Caches zurückgegeben wird.
Löschstrategie
Um einige Cache zu löschen, müssen Sie eine Liste von Revisionen übergeben, die gelöscht werden sollen. Das Tool wird
eine Strategie definieren, um den Speicherplatz auf der Grundlage dieser Liste freizugeben. Es gibt ein
DeleteCacheStrategy Objekt zurück, das beschreibt, welche Dateien und Ordner gelöscht werden. Die
DeleteCacheStrategy zeigt Ihnen, wie viel Speicherplatz voraussichtlich frei wird.
Sobald Sie mit der Löschung einverstanden sind, müssen Sie sie ausführen, um die Löschung wirksam zu machen.
Um Abweichungen zu vermeiden, können Sie ein Strategieobjekt nicht manuell bearbeiten.
Die Strategie zur Löschung von Revisionen ist folgende:
- Der Ordner
snapshot, der die Revisions-Symlinks enthält, wird gelöscht. - Blob-Dateien, die nur von zu löschenden Revisionen verlinkt werden, werden ebenfalls gelöscht.
- Wenn eine Revision mit 1 oder mehreren
refsverknüpft ist, werden die Referenzen gelöscht. - Werden alle Revisionen aus einem Repo gelöscht, wird das gesamte zwischengespeicherte Repository gelöscht.
Revisions-Hashes sind eindeutig über alle Repositories hinweg. Das bedeutet, dass Sie keine repo_id oder repo_type
angeben müssen, wenn Sie Revisionen entfernen.
Wenn eine Revision im Cache nicht gefunden wird, wird sie stillschweigend ignoriert. Außerdem wird, wenn eine Datei
oder ein Ordner beim Versuch, ihn zu löschen, nicht gefunden wird, eine Warnung protokolliert, aber es wird kein
Fehler ausgelöst. Die Löschung wird für andere Pfade im
DeleteCacheStrategy Objekt fortgesetzt.
Cache vom Terminal aus leeren
Der einfachste Weg, einige Revisionen aus Ihrem HF-Cache-System zu löschen, ist die Verwendung des
delete-cache Befehls vom huggingface-cli Tool. Der Befehl hat zwei Modi. Standardmäßig wird dem Benutzer
eine TUI (Terminal User Interface) angezeigt, um auszuwählen, welche Revisionen gelöscht werden sollen. Diese TUI
befindet sich derzeit in der Beta-Phase, da sie nicht auf allen Plattformen getestet wurde. Wenn die TUI auf Ihrem
Gerät nicht funktioniert, können Sie sie mit dem Flag --disable-tui deaktivieren.
Verwendung der TUI
Dies ist der Standardmodus. Um ihn zu nutzen, müssen Sie zuerst zusätzliche Abhängigkeiten installieren, indem Sie den folgenden Befehl ausführen:
pip install huggingface_hub["cli"]Führen Sie dann den Befehl aus:
huggingface-cli delete-cacheSie sollten jetzt eine Liste von Revisionen sehen, die Sie auswählen/abwählen können:
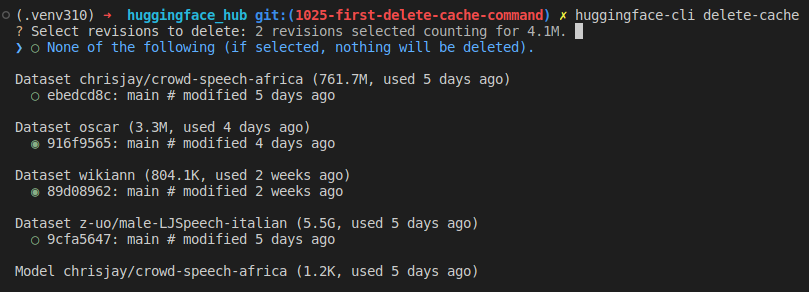
Anleitung:
- Drücken Sie die Pfeiltasten
Hoch>und<Runter>auf der Tastatur, um den Cursor zu bewegen. - Drücken Sie
<Leertaste>, um einen Eintrag zu wechseln (auswählen/abwählen). - Wenn eine Revision ausgewählt ist, wird die erste Zeile aktualisiert, um Ihnen anzuzeigen, wie viel Speicherplatz freigegeben wird.
- Drücken Sie
<Enter>, um Ihre Auswahl zu bestätigen. - Wenn Sie den Vorgang abbrechen und beenden möchten, können Sie den ersten Eintrag
(“None of the following”) auswählen. Wenn dieser Eintrag ausgewählt ist, wird der Löschvorgang abgebrochen,
unabhängig davon, welche anderen Einträge ausgewählt sind. Alternativ können Sie auch
<Ctrl+C>drücken, um die TUI zu verlassen.
Nachdem Sie die Revisionen ausgewählt haben, die Sie löschen möchten, und <Enter> gedrückt haben, wird eine
letzte Bestätigungsnachricht angezeigt. Drücken Sie erneut <Enter>, und die Löschung wird wirksam. Wenn Sie
abbrechen möchten, geben Sie n ein.
✗ huggingface-cli delete-cache --dir ~/.cache/huggingface/hub ? Select revisions to delete: 2 revision(s) selected. ? 2 revisions selected counting for 3.1G. Confirm deletion ? Yes Start deletion. Done. Deleted 1 repo(s) and 0 revision(s) for a total of 3.1G.
Ohne TUI
Wie bereits erwähnt, befindet sich der TUI-Modus derzeit in der Beta-Phase und ist optional. Es könnte sein, dass er auf Ihrem Gerät nicht funktioniert oder dass Sie ihn nicht als praktisch finden.
Ein anderer Ansatz besteht darin, das Flag --disable-tui zu verwenden. Der Vorgang ähnelt sehr dem vorherigen,
da Sie aufgefordert werden, die Liste der zu löschenden Revisionen manuell zu überprüfen.
Dieser manuelle Schritt findet jedoch nicht direkt im Terminal statt, sondern in einer temporären Datei,
die ad hoc generiert wird und die Sie manuell bearbeiten können.
Diese Datei enthält alle erforderlichen Anweisungen im Kopfteil. Öffnen Sie sie in Ihrem bevorzugten Texteditor.
Um eine Revision auszuwählen/abzuwählen, kommentieren Sie sie einfach mit einem # aus oder ein.
Sobald die manuelle Überprüfung abgeschlossen ist und die Datei bearbeitet wurde, können Sie sie speichern.
Gehen Sie zurück zu Ihrem Terminal und drücken Sie <Enter>. Standardmäßig wird berechnet,
wie viel Speicherplatz mit der aktualisierten Revisionsliste freigegeben würde.
Sie können die Datei weiter bearbeiten oder mit "y" bestätigen.
huggingface-cli delete-cache --disable-tui
Beispiel für eine Befehlsdatei:
# INSTRUCTIONS
# ------------
# This is a temporary file created by running `huggingface-cli delete-cache` with the
# `--disable-tui` option. It contains a set of revisions that can be deleted from your
# local cache directory.
#
# Please manually review the revisions you want to delete:
# - Revision hashes can be commented out with '#'.
# - Only non-commented revisions in this file will be deleted.
# - Revision hashes that are removed from this file are ignored as well.
# - If `CANCEL_DELETION` line is uncommented, the all cache deletion is cancelled and
# no changes will be applied.
#
# Once you've manually reviewed this file, please confirm deletion in the terminal. This
# file will be automatically removed once done.
# ------------
# KILL SWITCH
# ------------
# Un-comment following line to completely cancel the deletion process
# CANCEL_DELETION
# ------------
# REVISIONS
# ------------
# Dataset chrisjay/crowd-speech-africa (761.7M, used 5 days ago)
ebedcd8c55c90d39fd27126d29d8484566cd27ca # Refs: main # modified 5 days ago
# Dataset oscar (3.3M, used 4 days ago)
# 916f956518279c5e60c63902ebdf3ddf9fa9d629 # Refs: main # modified 4 days ago
# Dataset wikiann (804.1K, used 2 weeks ago)
89d089624b6323d69dcd9e5eb2def0551887a73a # Refs: main # modified 2 weeks ago
# Dataset z-uo/male-LJSpeech-italian (5.5G, used 5 days ago)
# 9cfa5647b32c0a30d0adfca06bf198d82192a0d1 # Refs: main # modified 5 days agoCache aus Python leeren
Für mehr Flexibilität können Sie auch die Methode delete_revisions() programmatisch verwenden.
Hier ist ein einfaches Beispiel. Siehe Referenz für Details.
>>> from huggingface_hub import scan_cache_dir
>>> delete_strategy = scan_cache_dir().delete_revisions(
... "81fd1d6e7847c99f5862c9fb81387956d99ec7aa"
... "e2983b237dccf3ab4937c97fa717319a9ca1a96d",
... "6c0e6080953db56375760c0471a8c5f2929baf11",
... )
>>> print("Will free " + delete_strategy.expected_freed_size_str)
Will free 8.6G
>>> delete_strategy.execute()
Cache deletion done. Saved 8.6G.