Hub Python Library documentation
Den Hub durchsuchen
Den Hub durchsuchen
In diesem Tutorial lernen Sie, wie Sie Modelle, Datensätze und Spaces auf dem Hub mit huggingface_hub durchsuchen können.
Wie listet man Repositories auf?
Die huggingface_hub-Bibliothek enthält einen HTTP-Client HfApi, um mit dem Hub zu interagieren.
Unter anderem kann er Modelle, Datensätze und Spaces auflisten, die auf dem Hub gespeichert sind:
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> models = api.list_models()Die Ausgabe von list_models() ist ein Iterator über die auf dem Hub gespeicherten Modelle.
Ähnlich können Sie list_datasets() verwenden, um Datensätze aufzulisten und list_spaces(), um Spaces aufzulisten.
Wie filtert man Repositories?
Das Auflisten von Repositories ist großartig, aber jetzt möchten Sie vielleicht Ihre Suche filtern. Die List-Helfer haben mehrere Attribute wie:
filterauthorsearch- …
Zwei dieser Parameter sind intuitiv (author und search), aber was ist mit diesem filter?
filter nimmt als Eingabe ein ModelFilter-Objekt (oder DatasetFilter) entgegen.
Sie können es instanziieren, indem Sie angeben, welche Modelle Sie filtern möchten.
Hier ist ein Beispiel, um alle Modelle auf dem Hub zu erhalten, die Bildklassifizierung durchführen,
auf dem Imagenet-Datensatz trainiert wurden und mit PyTorch laufen.
Das kann mit einem einzigen ModelFilter erreicht werden. Attribute werden als “logisches UND” kombiniert.
models = hf_api.list_models(
filter=ModelFilter(
task="image-classification",
library="pytorch",
trained_dataset="imagenet"
)
)Während des Filterns können Sie auch die Modelle sortieren und nur die Top-Ergebnisse abrufen. Zum Beispiel holt das folgende Beispiel die 5 am häufigsten heruntergeladenen Datensätze auf dem Hub:
>>> list_datasets(sort="downloads", direction=-1, limit=5)
[DatasetInfo: {
id: glue
downloads: 897789
(...)Wie erkundet man Filteroptionen?
Jetzt wissen Sie, wie Sie Ihre Liste von Modellen/Datensätzen/Räumen filtern können. Das Problem könnte sein, dass Sie nicht genau wissen, wonach Sie suchen. Keine Sorge! Wir bieten auch einige Hilfsprogramme an, mit denen Sie entdecken können, welche Argumente Sie in Ihrer Abfrage übergeben können.
ModelSearchArguments und DatasetSearchArguments sind geschachtelte Namespace-Objekte,
die jede einzelne Option auf dem Hub haben und die zurückgeben, was an filter übergeben werden sollte.
Das Beste von allem ist: Es hat Tab-Vervollständigung 🎊.
>>> from huggingface_hub import ModelSearchArguments, DatasetSearchArguments
>>> model_args = ModelSearchArguments()
>>> dataset_args = DatasetSearchArguments()Bevor Sie weitermachen, beachten Sie bitte, dass ModelSearchArguments und DatasetSearchArguments
veraltete Hilfsprogramme sind, die nur zu Erkundungszwecken gedacht sind.
Ihre Initialisierung erfordert das Auflisten aller Modelle und Datensätze auf dem Hub, was sie zunehmend langsamer macht,
je mehr Repos auf dem Hub vorhanden sind. Für produktionsbereiten Code sollten Sie in Erwägung ziehen,
rohe Zeichenketten (raw strings) zu übergeben, wenn Sie eine gefilterte Suche auf dem Hub durchführen.
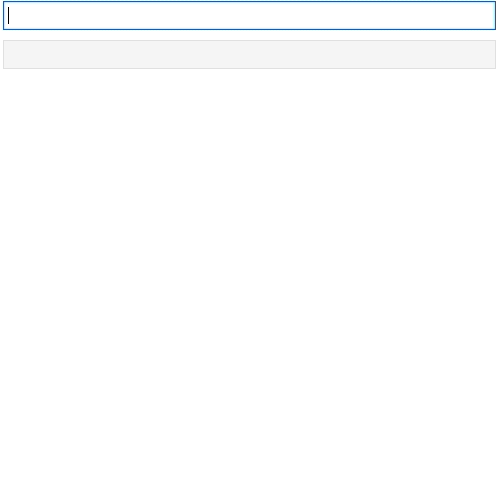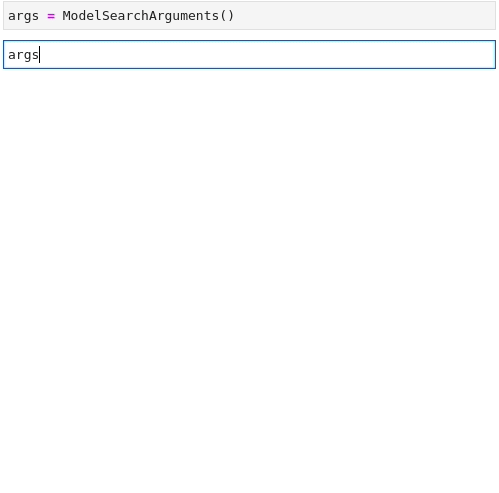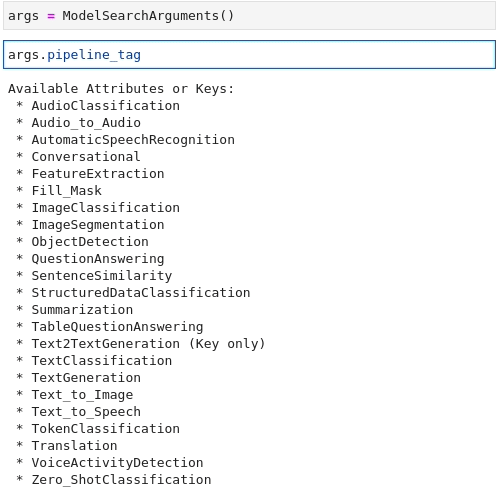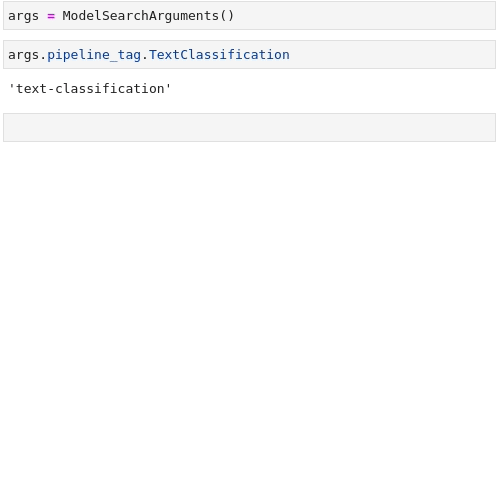
Sehen wir uns nun an, was in model_args verfügbar ist, indem wir seine Ausgabe überprüfen:
>>> model_args
Available Attributes or Keys:
* author
* dataset
* language
* library
* license
* model_name
* pipeline_tagEs stehen Ihnen eine Vielzahl von Attributen oder Schlüsseln zur Verfügung.
Dies liegt daran, dass es sowohl ein Objekt als auch ein Wörterbuch ist.
Daher können Sie entweder model_args["author"] oder model_args.author verwenden.
Das erste Kriterium besteht darin, alle PyTorch-Modelle zu erhalten.
Dies wäre unter dem Attribut library zu finden, schauen wir also, ob es da ist:
>>> model_args.library
Available Attributes or Keys:
* AdapterTransformers
* Asteroid
* ESPnet
* Fairseq
* Flair
* JAX
* Joblib
* Keras
* ONNX
* PyTorch
* Rust
* Scikit_learn
* SentenceTransformers
* Stable_Baselines3 (Key only)
* Stanza
* TFLite
* TensorBoard
* TensorFlow
* TensorFlowTTS
* Timm
* Transformers
* allenNLP
* fastText
* fastai
* pyannote_audio
* spaCy
* speechbrainEs ist da! Der Name PyTorch ist vorhanden, daher müssen Sie model_args.library.PyTorch verwenden:
>>> model_args.library.PyTorch
'pytorch'Im Folgenden finden Sie eine Animation, die den Vorgang zur Suche nach den Anforderungen Textklassifizierung (Text Classification) and glue wiederholt:
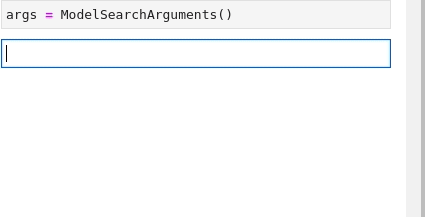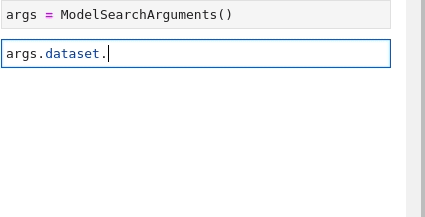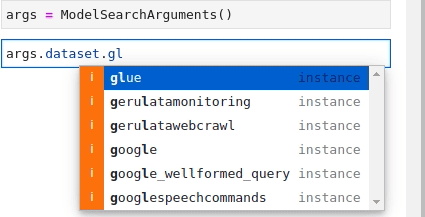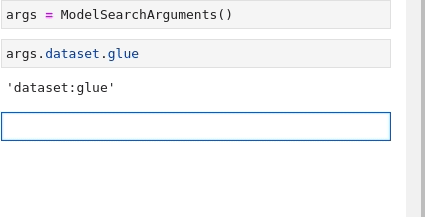
Jetzt, da alle Teile vorhanden sind, besteht der letzte Schritt darin, sie alle für etwas zu kombinieren,
das die API über die Klassen ModelFilter und DatasetFilter verwenden kann (d.h. Zeichenketten / strings).
>>> from huggingface_hub import ModelFilter, DatasetFilter
>>> filt = ModelFilter(
... task=model_args.pipeline_tag.TextClassification,
... trained_dataset=dataset_args.dataset_name.glue,
... library=model_args.library.PyTorch
... )
>>> api.list_models(filter=filt)[0]
ModelInfo: {
modelId: Jiva/xlm-roberta-large-it-mnli
sha: c6e64469ec4aa17fedbd1b2522256f90a90b5b86
lastModified: 2021-12-10T14:56:38.000Z
tags: ['pytorch', 'xlm-roberta', 'text-classification', 'it', 'dataset:multi_nli', 'dataset:glue', 'arxiv:1911.02116', 'transformers', 'tensorflow', 'license:mit', 'zero-shot-classification']
pipeline_tag: zero-shot-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='sentencepiece.bpe.model'), ModelFile(rfilename='special_tokens_map.json'), ModelFile(rfilename='tokenizer.json'), ModelFile(rfilename='tokenizer_config.json')]
config: None
id: Jiva/xlm-roberta-large-it-mnli
private: False
downloads: 11061
library_name: transformers
likes: 1
}Wie Sie sehen können, wurden die Modelle gefunden, die allen Kriterien entsprechen. Sie können es sogar noch weiter bringen,
indem Sie ein Array für jeden der vorherigen Parameter übergeben.
Zum Beispiel, schauen wir uns dieselbe Konfiguration an, aber schließen auch TensorFlow in den Filter ein:
>>> filt = ModelFilter(
... task=model_args.pipeline_tag.TextClassification,
... library=[model_args.library.PyTorch, model_args.library.TensorFlow]
... )
>>> api.list_models(filter=filt)[0]
ModelInfo: {
modelId: distilbert-base-uncased-finetuned-sst-2-english
sha: ada5cc01a40ea664f0a490d0b5f88c97ab460470
lastModified: 2022-03-22T19:47:08.000Z
tags: ['pytorch', 'tf', 'rust', 'distilbert', 'text-classification', 'en', 'dataset:sst-2', 'transformers', 'license:apache-2.0', 'infinity_compatible']
pipeline_tag: text-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='map.jpeg'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='rust_model.ot'), ModelFile(rfilename='tf_model.h5'), ModelFile(rfilename='tokenizer_config.json'), ModelFile(rfilename='vocab.txt')]
config: None
id: distilbert-base-uncased-finetuned-sst-2-english
private: False
downloads: 3917525
library_name: transformers
likes: 49
}Diese Abfrage entspricht streng:
>>> filt = ModelFilter(
... task="text-classification",
... library=["pytorch", "tensorflow"],
... )Hier war ModelSearchArguments ein Helfer, um die auf dem Hub verfügbaren Optionen zu erkunden.
Es ist jedoch keine Voraussetzung für eine Suche. Eine andere Möglichkeit, dies zu tun,
besteht darin, die Modelle und Datensätze Seiten
in Ihrem Browser zu besuchen, nach einigen Parametern zu suchen und die Werte in der URL anzusehen.