Diffusers documentation
Accelerate inference of text-to-image diffusion models
Accelerate inference of text-to-image diffusion models
Diffusion models are slower than their GAN counterparts because of the iterative and sequential reverse diffusion process. There are several techniques that can address this limitation such as progressive timestep distillation (LCM LoRA), model compression (SSD-1B), and reusing adjacent features of the denoiser (DeepCache).
However, you don’t necessarily need to use these techniques to speed up inference. With PyTorch 2 alone, you can accelerate the inference latency of text-to-image diffusion pipelines by up to 3x. This tutorial will show you how to progressively apply the optimizations found in PyTorch 2 to reduce inference latency. You’ll use the Stable Diffusion XL (SDXL) pipeline in this tutorial, but these techniques are applicable to other text-to-image diffusion pipelines too.
Make sure you’re using the latest version of Diffusers:
pip install -U diffusers
Then upgrade the other required libraries too:
pip install -U transformers accelerate peft
Install PyTorch nightly to benefit from the latest and fastest kernels:
pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121
The results reported below are from a 80GB 400W A100 with its clock rate set to the maximum.
If you’re interested in the full benchmarking code, take a look at huggingface/diffusion-fast.
Baseline
Let’s start with a baseline. Disable reduced precision and the scaled_dot_product_attention (SDPA) function which is automatically used by Diffusers:
from diffusers import StableDiffusionXLPipeline
# Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
).to("cuda")
# Run the attention ops without SDPA.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
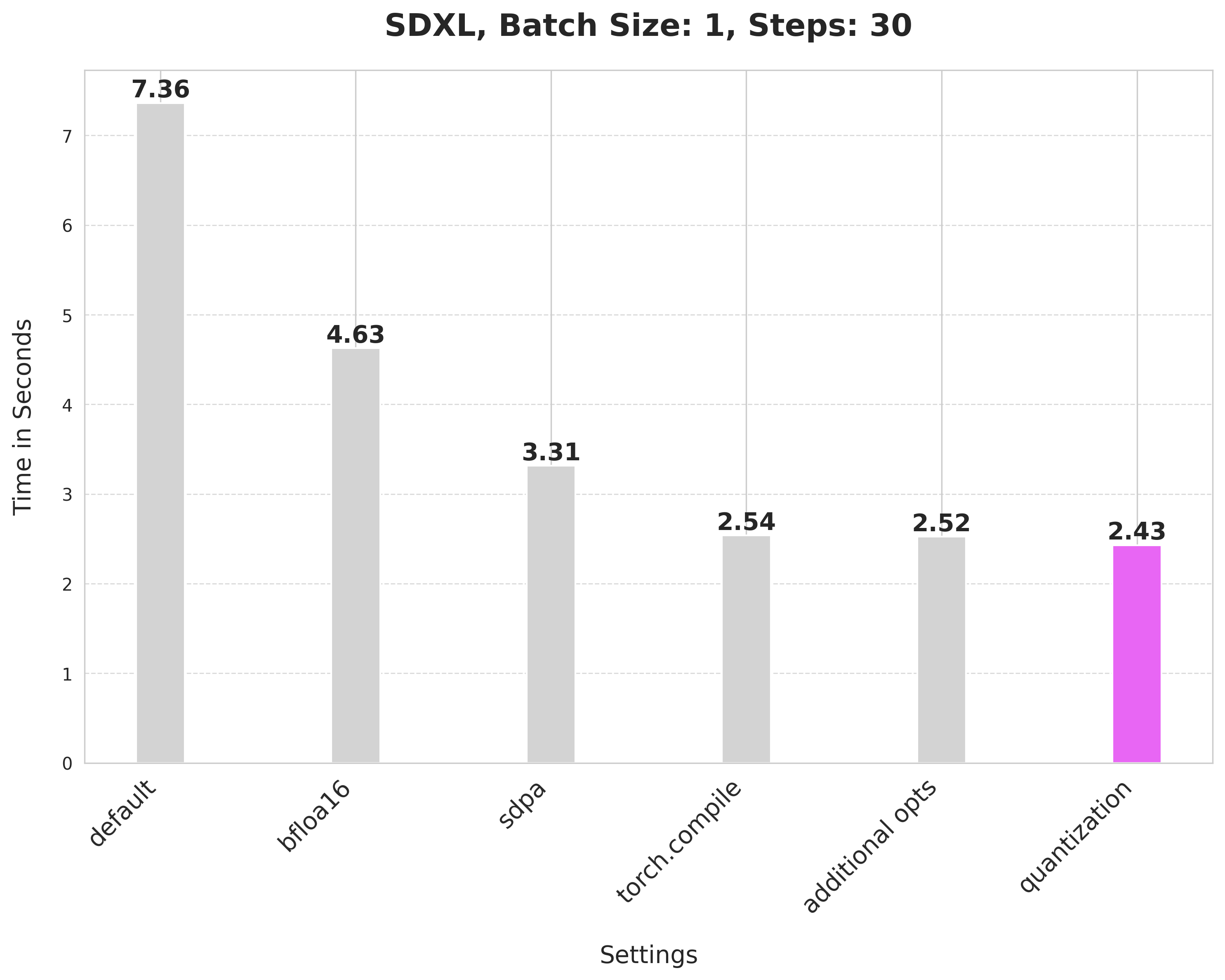
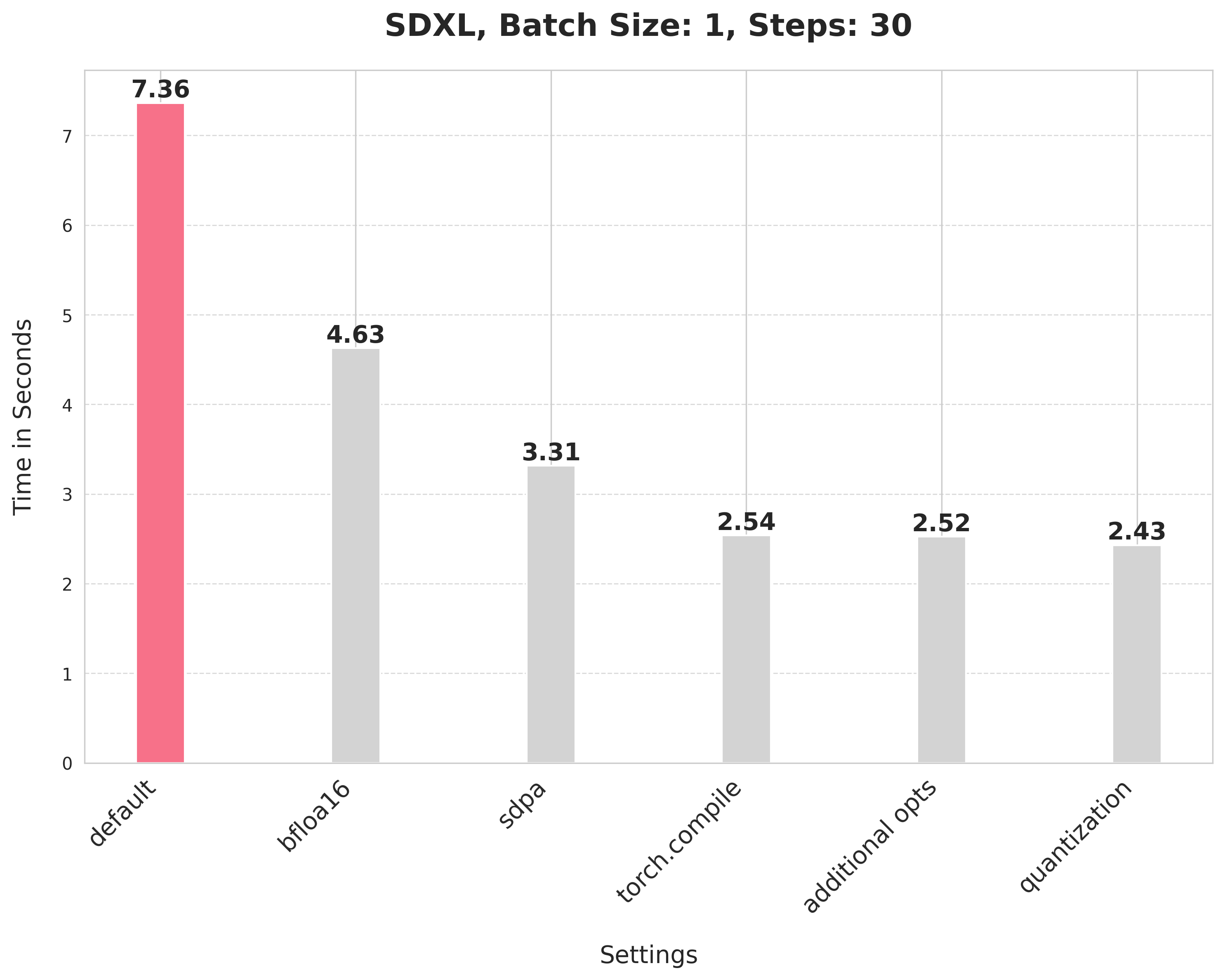
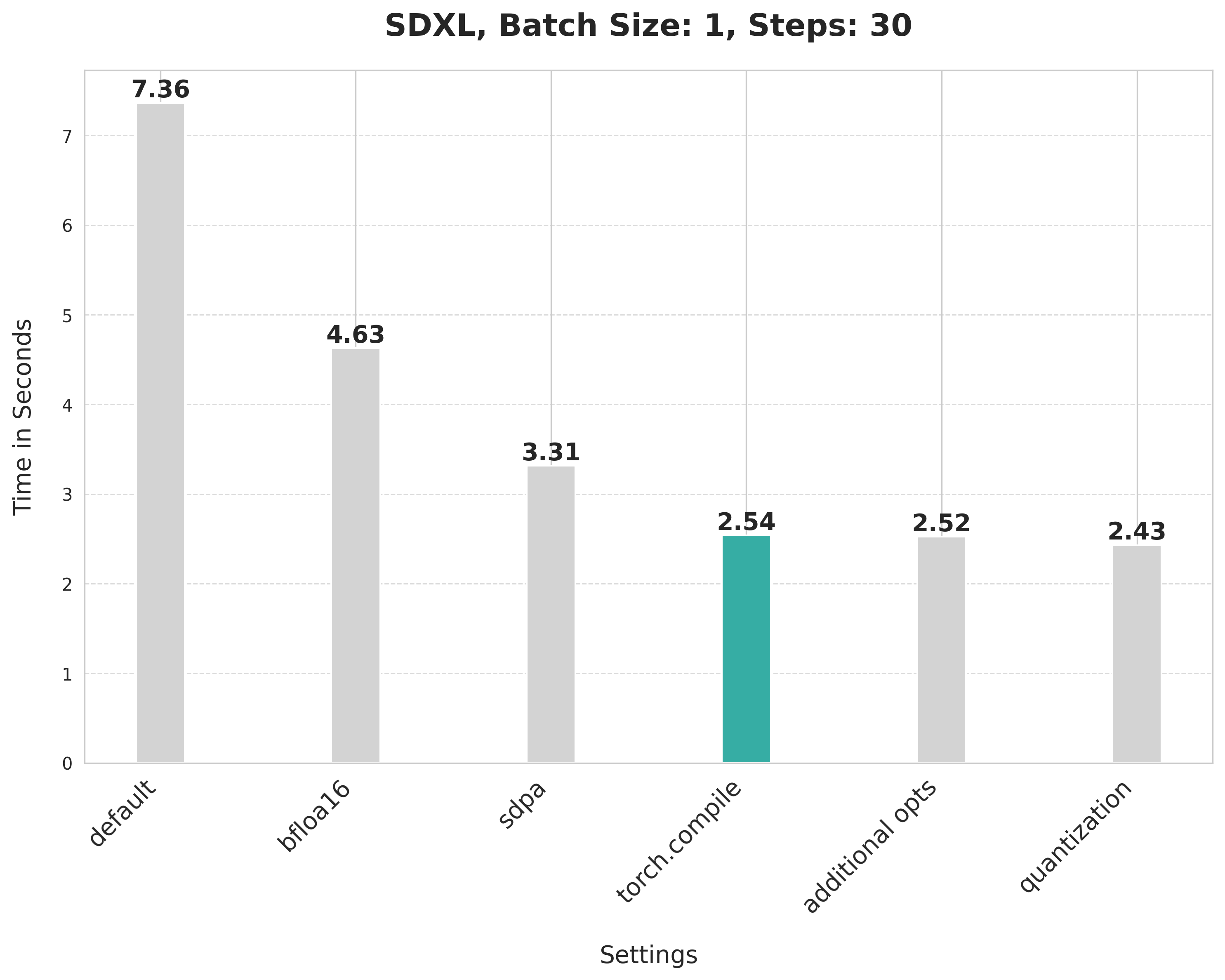
image = pipe(prompt, num_inference_steps=30).images[0]This default setup takes 7.36 seconds.
bfloat16
Enable the first optimization, reduced precision or more specifically bfloat16. There are several benefits of using reduced precision:
- Using a reduced numerical precision (such as float16 or bfloat16) for inference doesn’t affect the generation quality but significantly improves latency.
- The benefits of using bfloat16 compared to float16 are hardware dependent, but modern GPUs tend to favor bfloat16.
- bfloat16 is much more resilient when used with quantization compared to float16, but more recent versions of the quantization library (torchao) we used don’t have numerical issues with float16.
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Run the attention ops without SDPA.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
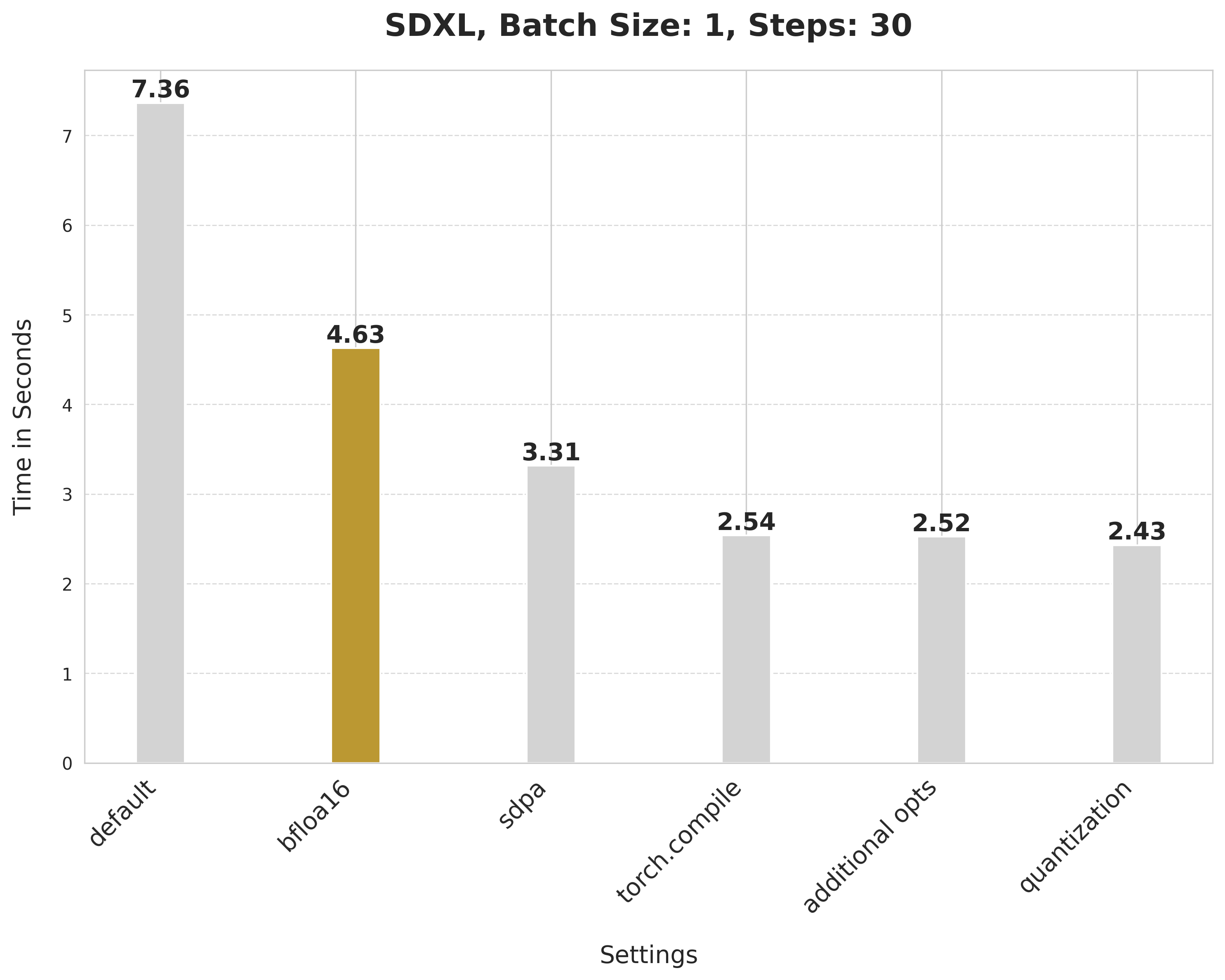
image = pipe(prompt, num_inference_steps=30).images[0]bfloat16 reduces the latency from 7.36 seconds to 4.63 seconds.
In our later experiments with float16, recent versions of torchao do not incur numerical problems from float16.
Take a look at the Speed up inference guide to learn more about running inference with reduced precision.
SDPA
Attention blocks are intensive to run. But with PyTorch’s scaled_dot_product_attention function, it is a lot more efficient. This function is used by default in Diffusers so you don’t need to make any changes to the code.
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
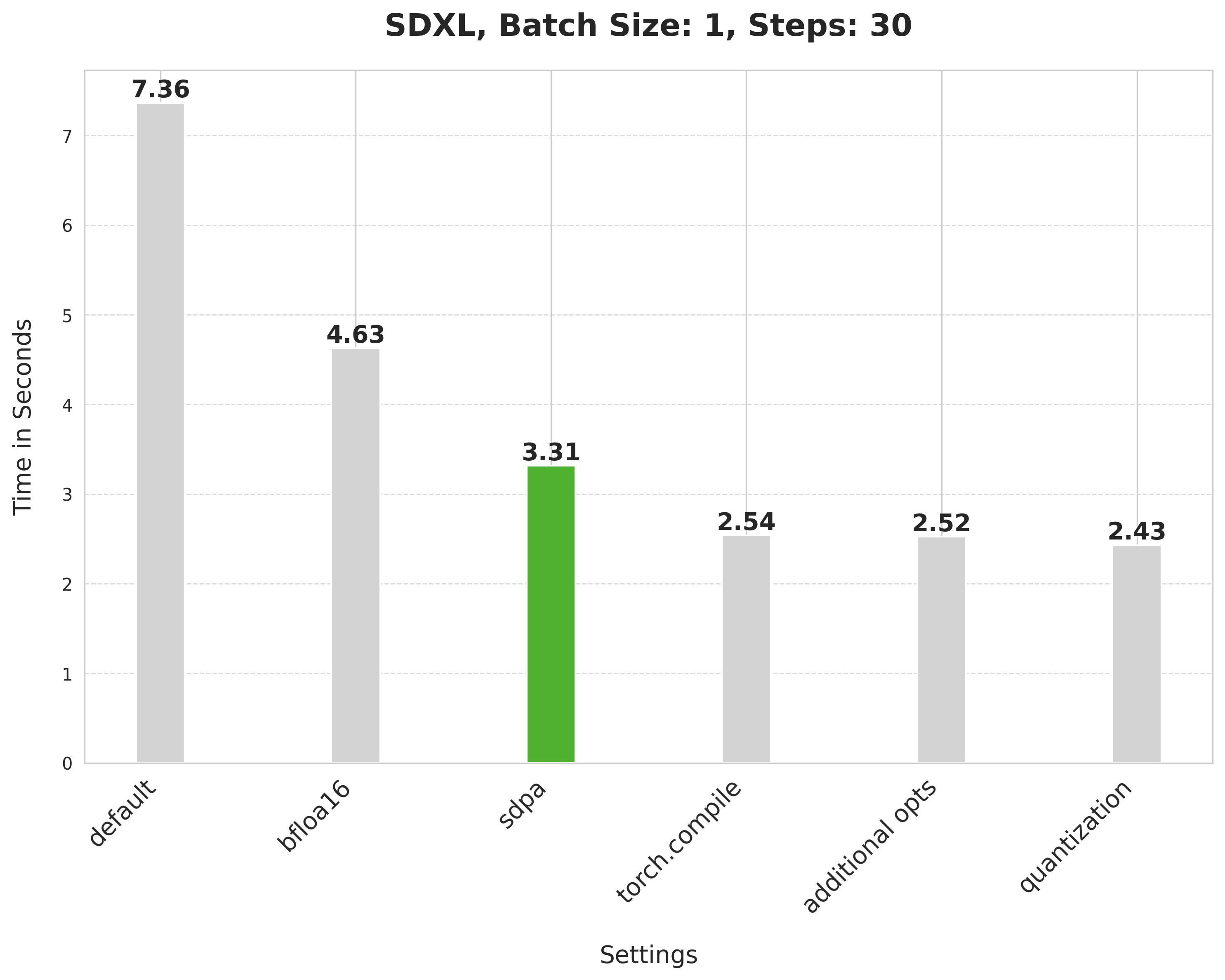
image = pipe(prompt, num_inference_steps=30).images[0]Scaled dot product attention improves the latency from 4.63 seconds to 3.31 seconds.
torch.compile
PyTorch 2 includes torch.compile which uses fast and optimized kernels. In Diffusers, the UNet and VAE are usually compiled because these are the most compute-intensive modules. First, configure a few compiler flags (refer to the full list for more options):
from diffusers import StableDiffusionXLPipeline
import torch
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = TrueIt is also important to change the UNet and VAE’s memory layout to “channels_last” when compiling them to ensure maximum speed.
pipe.unet.to(memory_format=torch.channels_last) pipe.vae.to(memory_format=torch.channels_last)
Now compile and perform inference:
# Compile the UNet and VAE.
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` is slow, subsequent ones are faster.
image = pipe(prompt, num_inference_steps=30).images[0]torch.compile offers different backends and modes. For maximum inference speed, use “max-autotune” for the inductor backend. “max-autotune” uses CUDA graphs and optimizes the compilation graph specifically for latency. CUDA graphs greatly reduces the overhead of launching GPU operations by using a mechanism to launch multiple GPU operations through a single CPU operation.
Using SDPA attention and compiling both the UNet and VAE cuts the latency from 3.31 seconds to 2.54 seconds.
Prevent graph breaks
Specifying fullgraph=True ensures there are no graph breaks in the underlying model to take full advantage of torch.compile without any performance degradation. For the UNet and VAE, this means changing how you access the return variables.
- latents = unet(
- latents, timestep=timestep, encoder_hidden_states=prompt_embeds
-).sample
+ latents = unet(
+ latents, timestep=timestep, encoder_hidden_states=prompt_embeds, return_dict=False
+)[0]Remove GPU sync after compilation
During the iterative reverse diffusion process, the step() function is called on the scheduler each time after the denoiser predicts the less noisy latent embeddings. Inside step(), the sigmas variable is indexed which when placed on the GPU, causes a communication sync between the CPU and GPU. This introduces latency and it becomes more evident when the denoiser has already been compiled.
But if the sigmas array always stays on the CPU, the CPU and GPU sync doesn’t occur and you don’t get any latency. In general, any CPU and GPU communication sync should be none or be kept to a bare minimum because it can impact inference latency.
Combine the attention block’s projection matrices
The UNet and VAE in SDXL use Transformer-like blocks which consists of attention blocks and feed-forward blocks.
In an attention block, the input is projected into three sub-spaces using three different projection matrices – Q, K, and V. These projections are performed separately on the input. But we can horizontally combine the projection matrices into a single matrix and perform the projection in one step. This increases the size of the matrix multiplications of the input projections and improves the impact of quantization.
You can combine the projection matrices with just a single line of code:
pipe.fuse_qkv_projections()
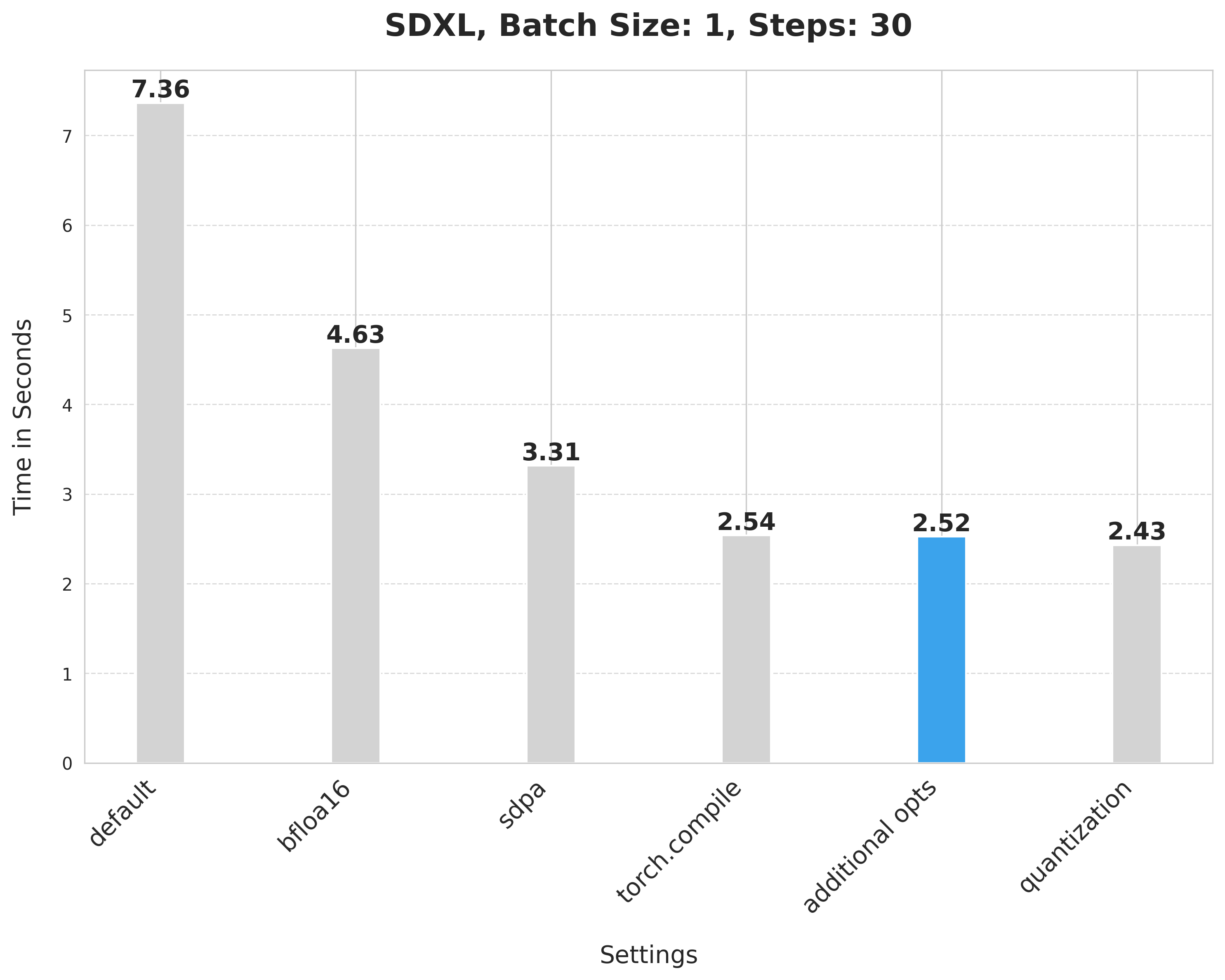
This provides a minor improvement from 2.54 seconds to 2.52 seconds.
Support for fuse_qkv_projections() is limited and experimental. It’s not available for many non-Stable Diffusion pipelines such as Kandinsky. You can refer to this PR to get an idea about how to enable this for the other pipelines.
Dynamic quantization
You can also use the ultra-lightweight PyTorch quantization library, torchao (commit SHA 54bcd5a10d0abbe7b0c045052029257099f83fd9), to apply dynamic int8 quantization to the UNet and VAE. Quantization adds additional conversion overhead to the model that is hopefully made up for by faster matmuls (dynamic quantization). If the matmuls are too small, these techniques may degrade performance.
First, configure all the compiler tags:
from diffusers import StableDiffusionXLPipeline
import torch
# Notice the two new flags at the end.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = TrueCertain linear layers in the UNet and VAE don’t benefit from dynamic int8 quantization. You can filter out those layers with the dynamic_quant_filter_fn shown below.
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)Finally, apply all the optimizations discussed so far:
# SDPA + bfloat16.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Change the memory layout.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)Since dynamic quantization is only limited to the linear layers, convert the appropriate pointwise convolution layers into linear layers to maximize its benefit.
from torchao import swap_conv2d_1x1_to_linear
swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)Apply dynamic quantization:
from torchao import apply_dynamic_quant
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)Finally, compile and perform inference:
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]Applying dynamic quantization improves the latency from 2.52 seconds to 2.43 seconds.