Datasets documentation
Upload a dataset to the Hub
Upload a dataset to the Hub
In the last section of the tutorials, you will learn how to upload a dataset to the Hugging Face Hub. 🤗 Datasets aims to provide the largest collection of datasets that anyone can use to train their models. We welcome all dataset contributions from the NLP community, and we have made it very simple for you to add a dataset. Even if you don’t have a lot of developer experience, you can still contribute!
Start by creating a Hugging Face Hub account at hf.co if you don’t have one yet.
Create a repository
A repository hosts all your dataset files, including the revision history, making it possible to store more than one dataset version.
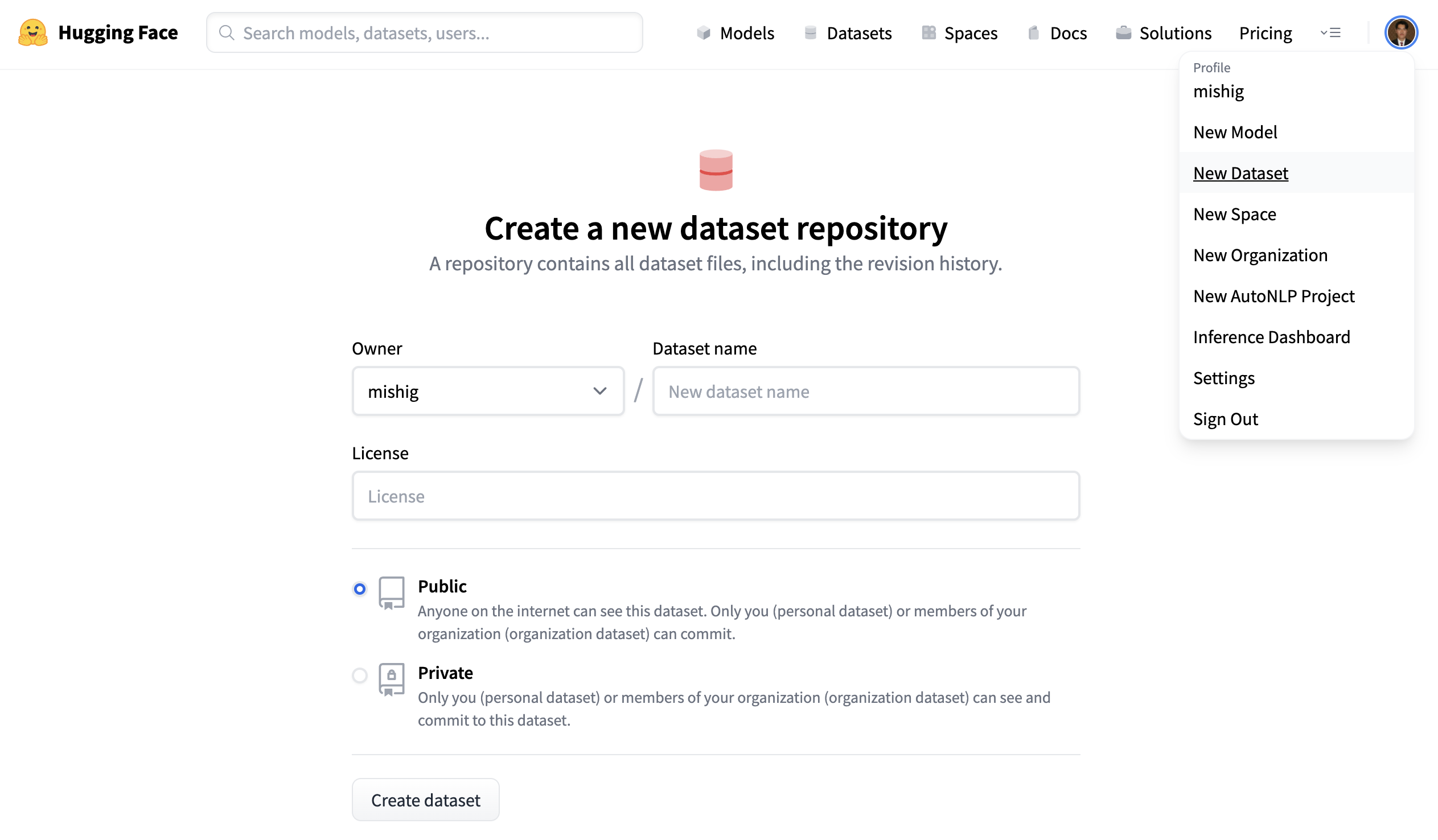
- Click on your profile and select New Dataset to create a new dataset repository.
- Give your dataset a name, and select whether this is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
Upload your files
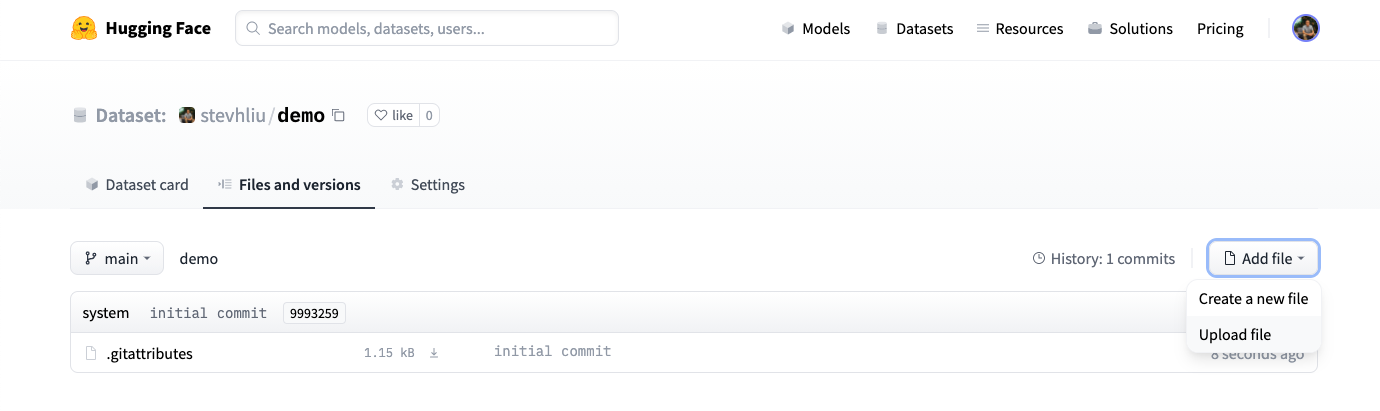
- Once you have created a repository, navigate to the Files and versions tab to add a file. Select Add file to upload your dataset files. We currently support the following data formats: CSV, JSON, JSON lines, text, and Parquet.
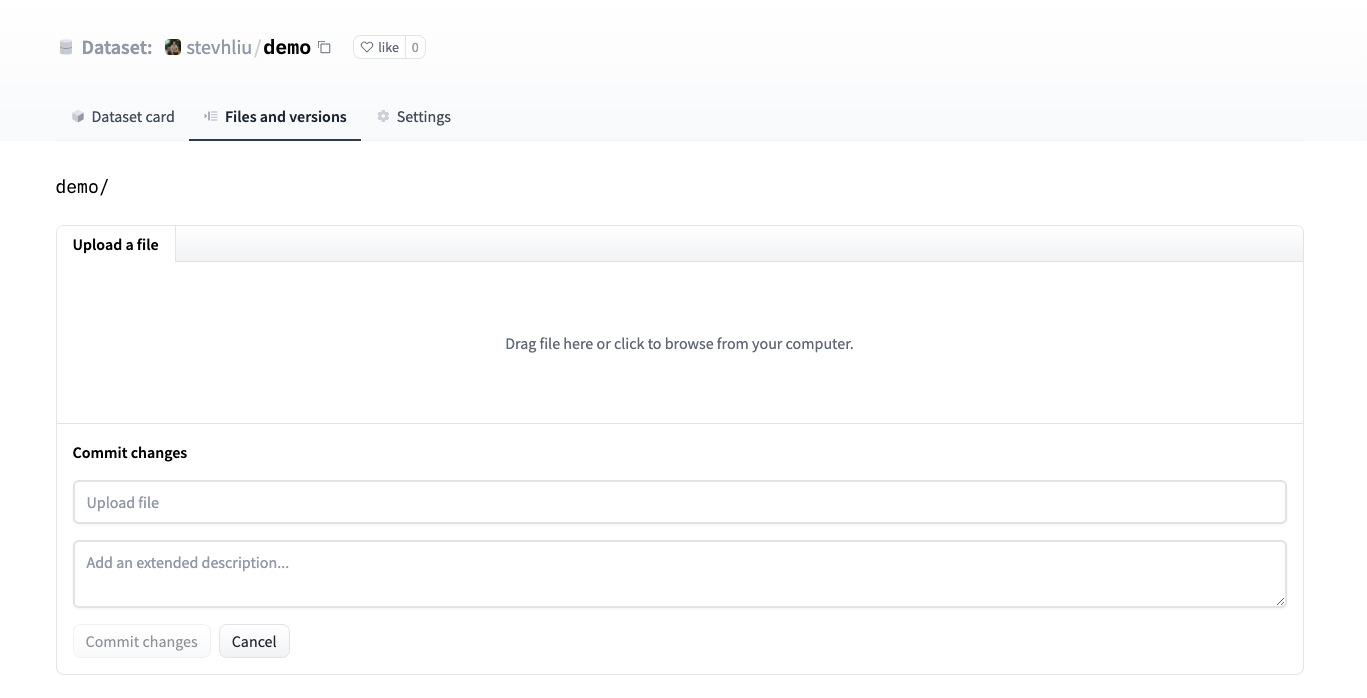
- Drag and drop your dataset files here, and add a brief descriptive commit message.
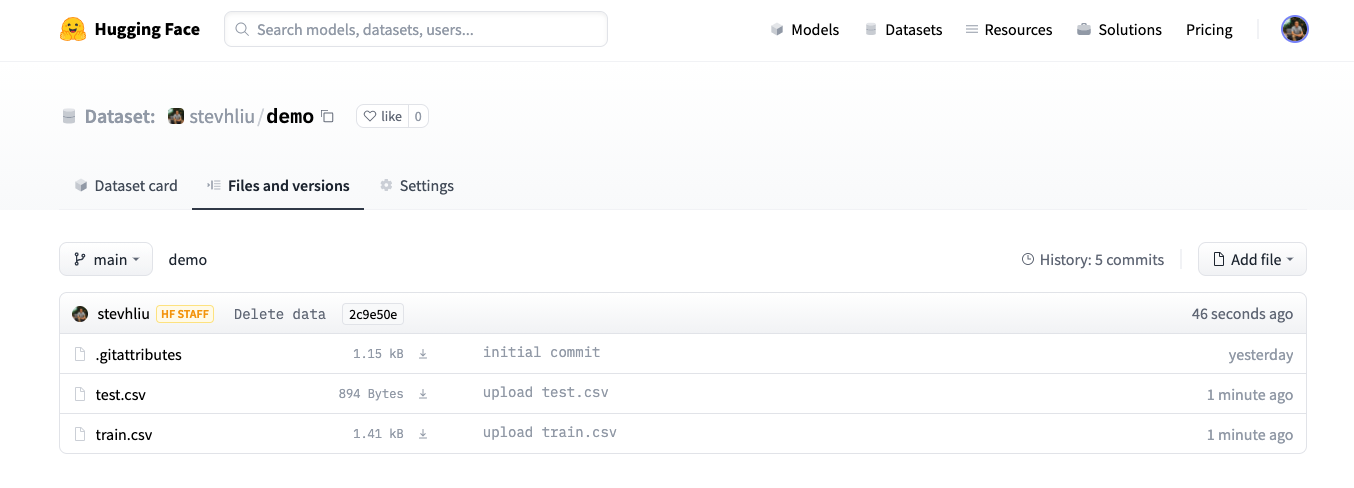
- Once you have uploaded your dataset files, they are now stored in your dataset repository.
Create a Dataset card
The last step is to create a Dataset card. The Dataset card is essential for helping users find your dataset and understand how to use it responsibly.
- Click on the Create Dataset Card to create a Dataset card.
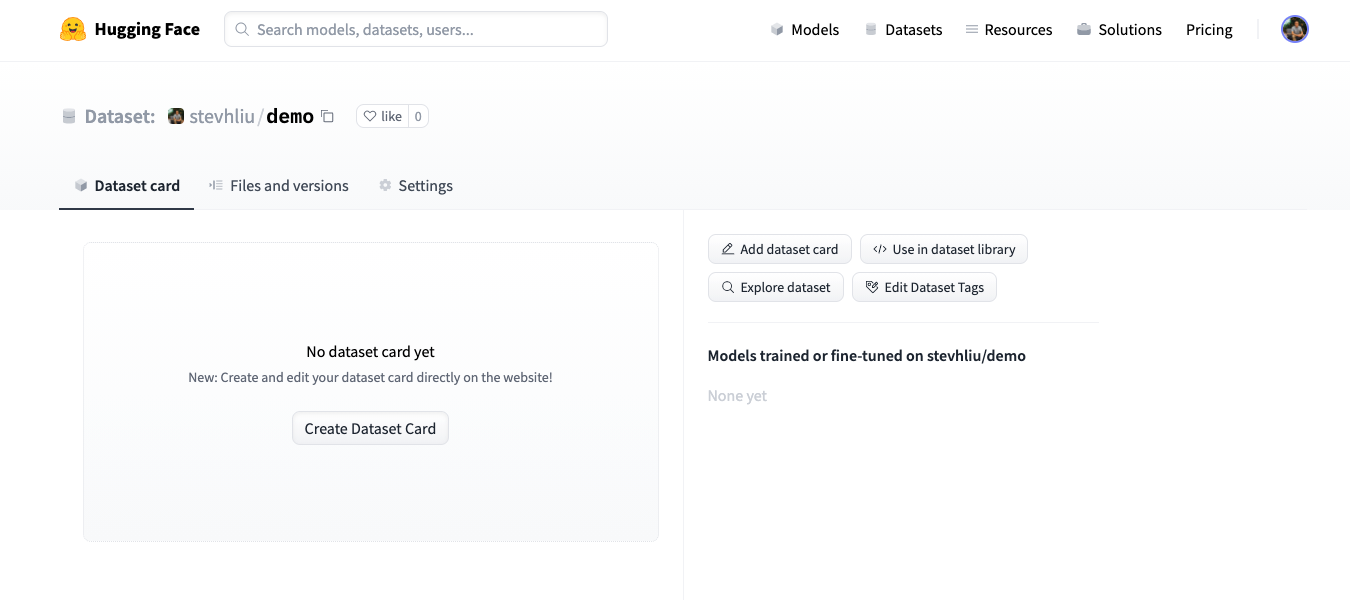
Get a quick start with our Dataset card template to help you fill out all the relevant fields.
The Dataset card uses structured tags to help users discover your dataset on the Hub. Use the online Datasets Tagging application to help you generate the appropriate tags.
Copy the generated tags and paste them at the top of your Dataset card, then commit your changes.
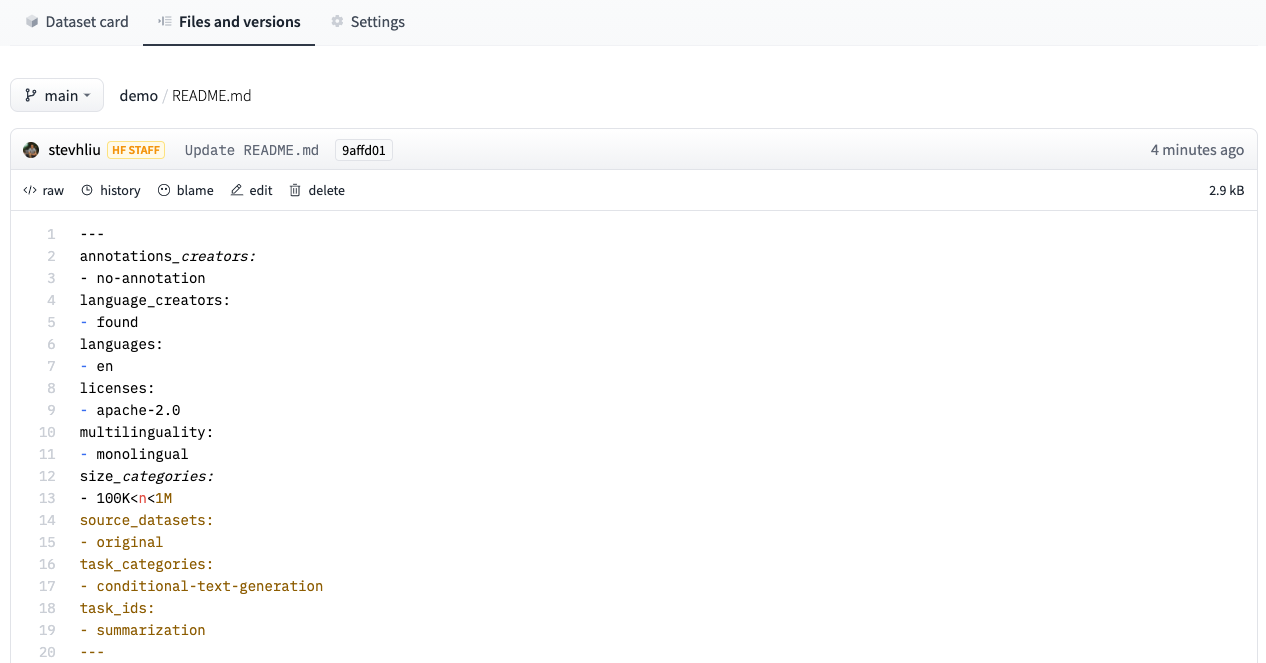
For a detailed example of what a good Dataset card should look like, refer to the CNN DailyMail Dataset card.
Load dataset
Your dataset can now be loaded by anyone in a single line of code!
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")
>>> dataset
DatasetDict({
train: Dataset({
features: ['id', 'package_name', 'review', 'date', 'star', 'version_id'],
num_rows: 5
})
test: Dataset({
features: ['id', 'package_name', 'review', 'date', 'star', 'version_id'],
num_rows: 5
})
})Upload from Python
To upload a datasets.DatasetDict on the Hugging Face Hub in Python, you can login and use the datasets.DatasetDict.push_to_hub() method:
- Login from the command line:
huggingface-cli login- Upload the dataset:
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")
>>> # dataset = dataset.map(...) # do all your processing here
>>> dataset.push_to_hub("stevhliu/processed_demo")With the private parameter you can choose whether your dataset is public or private:
>>> dataset.push_to_hub("stevhliu/private_processed_demo", private=True)Privacy
If your uploaded dataset is private, only you can access it:
- Login from the command line:
huggingface-cli login- Load the dataset with your authentication token:
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo", use_auth_token=True)Similarly, share a private dataset within your organization by uploading a dataset as Private to your organization. Then members of the organization can load the dataset like:
- Login from the command line:
huggingface-cli login- Load the dataset with your authentication token:
>>> from datasets import load_dataset
>>> dataset = load_dataset("organization/dataset_name", use_auth_token=True)What's next?
Congratulations, you have completed all of the 🤗 Datasets tutorials!
Throughout these tutorials, you learned the basic steps of using 🤗 Datasets. You loaded a dataset from the Hub and learned how to access the information stored inside the dataset. Next, you tokenized the dataset into sequences of integers and formatted it so you can use it with PyTorch or TensorFlow. Then you loaded a metric to evaluate your model’s predictions. Finally, you uploaded a dataset to the Hub without writing a single line of code. This is all you need to get started with 🤗 Datasets!
Now that you have a solid grasp of what 🤗 Datasets can do, you can begin formulating your own questions about how you can use it with your dataset. Please take a look at our How-to guides for more practical help on solving common use-cases, or read our Conceptual guides to deepen your understanding about 🤗 Datasets.