course documentation
Masked Language Model တစ်ခုကို Fine-tuning လုပ်ခြင်း
Masked Language Model တစ်ခုကို Fine-tuning လုပ်ခြင်း

Transformer models တွေပါဝင်တဲ့ NLP applications အများအပြားအတွက်၊ သင်ဟာ Hugging Face Hub ကနေ pretrained model တစ်ခုကို ယူပြီး သင်ရဲ့ data ပေါ်မှာ လက်ရှိ task အတွက် တိုက်ရိုက် fine-tune လုပ်နိုင်ပါတယ်။ pretraining အတွက် အသုံးပြုခဲ့တဲ့ corpus က fine-tuning အတွက် အသုံးပြုခဲ့တဲ့ corpus နဲ့ သိပ်မကွာခြားဘူးဆိုရင်၊ transfer learning က များသောအားဖြင့် ကောင်းမွန်တဲ့ ရလဒ်တွေ ထုတ်ပေးပါလိမ့်မယ်။
သို့သော်လည်း၊ task-specific head တစ်ခုကို train မလုပ်ခင်၊ သင်ရဲ့ data ပေါ်မှာ language models တွေကို အရင် fine-tune လုပ်ချင်တဲ့ ကိစ္စအချို့ရှိပါတယ်။ ဥပမာ၊ သင်၏ dataset မှာ ဥပဒေဆိုင်ရာ စာချုပ်တွေ ဒါမှမဟုတ် သိပ္ပံနည်းကျ ဆောင်းပါးတွေ ပါဝင်တယ်ဆိုရင်၊ BERT လို vanilla Transformer model တစ်ခုက သင်၏ corpus ထဲက domain-specific words တွေကို rare tokens တွေအဖြစ် သတ်မှတ်မှာဖြစ်ပြီး၊ ရလဒ်စွမ်းဆောင်ရည်က ကျေနပ်စရာ ကောင်းချင်မှ ကောင်းပါလိမ့်မယ်။ in-domain data ပေါ်မှာ language model ကို fine-tune လုပ်ခြင်းဖြင့် downstream tasks များစွာရဲ့ စွမ်းဆောင်ရည်ကို မြှင့်တင်နိုင်ပါတယ်၊ ဒါက သင်ဒီအဆင့်ကို တစ်ခါပဲ လုပ်ဖို့ လိုတယ်လို့ ဆိုလိုတာပါ။
pretrained language model တစ်ခုကို in-domain data ပေါ်မှာ fine-tune လုပ်တဲ့ ဒီလုပ်ငန်းစဉ်ကို များသောအားဖြင့် domain adaptation လို့ခေါ်ပါတယ်။ ဒါကို ၂၀၁၈ ခုနှစ်မှာ ULMFiT က လူသိများအောင် လုပ်ဆောင်ခဲ့ပါတယ်။ ULMFiT ဟာ NLP အတွက် transfer learning ကို တကယ်အလုပ်ဖြစ်စေခဲ့တဲ့ ပထမဆုံး neural architectures (LSTMs ပေါ် အခြေခံထားတာ) တွေထဲက တစ်ခုဖြစ်ပါတယ်။ ULMFiT နဲ့ domain adaptation ဥပမာကို အောက်ပါပုံမှာ ပြသထားပါတယ်၊ ဒီအပိုင်းမှာ ကျွန်တော်တို့ အဲဒါနဲ့ ဆင်တူတာတစ်ခု လုပ်ဆောင်ပါမယ်၊ ဒါပေမယ့် LSTM အစား Transformer နဲ့ပါ။


ဒီအပိုင်းရဲ့ အဆုံးမှာ သင်ဟာ အောက်မှာ ပြသထားတဲ့အတိုင်း စာကြောင်းတွေကို autocomplete လုပ်နိုင်မယ့် masked language model တစ်ခု Hub မှာ ရရှိပါလိမ့်မယ်။
စတင်လိုက်ရအောင်!
🙋 “masked language modeling” နဲ့ “pretrained model” ဆိုတဲ့ စကားလုံးတွေက သင့်အတွက် မရင်းနှီးဘူးဆိုရင်၊ Chapter 1 ကို သွားကြည့်ပါ။ အဲဒီမှာ ဒီအဓိက သဘောတရားတွေအားလုံးကို ဗီဒီယိုတွေနဲ့တကွ ရှင်းပြထားပါတယ်။
Masked Language Modeling အတွက် Pretrained Model တစ်ခုကို ရွေးချယ်ခြင်း
စတင်ဖို့အတွက်၊ masked language modeling အတွက် သင့်လျော်တဲ့ pretrained model တစ်ခုကို ရွေးချယ်ကြရအောင်။ အောက်ပါ screenshot မှာ ပြသထားတဲ့အတိုင်း၊ Hugging Face Hub မှာ “Fill-Mask” filter ကို အသုံးပြုပြီး candidates တွေကို ရှာဖွေနိုင်ပါတယ်။
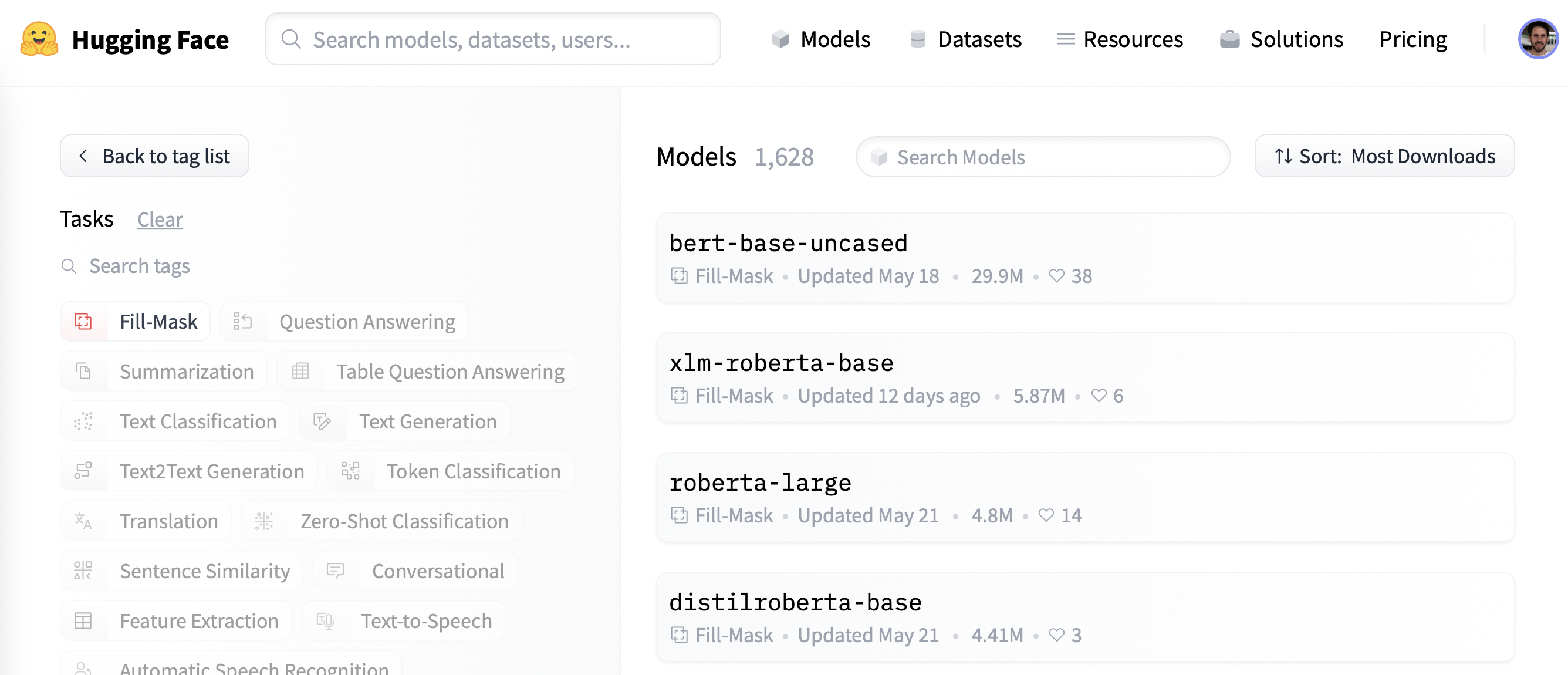
BERT နဲ့ RoBERTa family models တွေက အများဆုံး download လုပ်ထားကြပေမယ့်၊ ကျွန်တော်တို့က DistilBERT လို့ခေါ်တဲ့ model ကို အသုံးပြုပါမယ်။ ဒီ model က downstream performance မှာ အနည်းငယ်မျှသာ ဆုံးရှုံးမှုနဲ့ အများကြီး ပိုမြန်မြန် train လုပ်နိုင်ပါတယ်။ ဒီ model ကို knowledge distillation](https://en.wikipedia.org/wiki/Knowledge_distillation) လို့ခေါ်တဲ့ အထူးနည်းလမ်းတစ်ခု အသုံးပြုပြီး train လုပ်ခဲ့တာပါ။ အဲဒီမှာ BERT လို ကြီးမားတဲ့ “teacher model” ကို parameters အများကြီး နည်းပါးတဲ့ “student model” ရဲ့ training ကို လမ်းညွှန်ဖို့ အသုံးပြုခဲ့တာပါ။ knowledge distillation ရဲ့ အသေးစိတ်အချက်အလက်တွေကို ရှင်းပြတာက ဒီအပိုင်းမှာ အလွန်အကျွံ ဖြစ်သွားပါလိမ့်မယ်၊ ဒါပေမယ့် သင်စိတ်ဝင်စားတယ်ဆိုရင် Natural Language Processing with Transformers ( colloquially Transformers textbook လို့ သိကြပါတယ်) မှာ ဖတ်ရှုနိုင်ပါတယ်။
AutoModelForMaskedLM class ကို အသုံးပြုပြီး DistilBERT ကို download လုပ်လိုက်ရအောင်…
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)ဒီ model မှာ parameters ဘယ်လောက်ရှိတယ်ဆိုတာကို num_parameters() method ကို ခေါ်ခြင်းဖြင့် ကြည့်နိုင်ပါတယ်။
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'parameters ၆၇ သန်းလောက်နဲ့ DistilBERT က BERT base model ထက် နှစ်ဆခန့် ပိုသေးငယ်ပြီး၊ ဒါက training speed ကို နှစ်ဆမြှင့်တင်ပေးနိုင်ပါတယ်။ ကောင်းပါပြီ! ဒီ model က text အပိုင်းအစလေးတစ်ခုကို ဘယ်လိုဖြည့်စွက်ပေးနိုင်မလဲဆိုတာ ကြည့်ရအောင်-
text = "This is a great [MASK]."လူသားတွေအနေနဲ့ [MASK] token အတွက် “day”, “ride”, ဒါမှမဟုတ် “painting” လို ဖြစ်နိုင်ခြေများစွာကို စဉ်းစားနိုင်ပါတယ်။ pretrained models တွေအတွက်ကတော့၊ ခန့်မှန်းချက်တွေဟာ model ကို train လုပ်ခဲ့တဲ့ corpus ပေါ်မှာ မူတည်ပါတယ်၊ ဘာလို့လဲဆိုတော့ model က data ထဲမှာရှိတဲ့ statistical patterns တွေကို ကောက်ယူတတ်အောင် သင်ယူထားလို့ပါပဲ။ BERT လိုပဲ၊ DistilBERT ကို English Wikipedia နဲ့ BookCorpus datasets တွေပေါ်မှာ pretrained လုပ်ခဲ့တာကြောင့်၊ [MASK] အတွက် ခန့်မှန်းချက်တွေဟာ ဒီ domains တွေကို ထင်ဟပ်မယ်လို့ ကျွန်တော်တို့ မျှော်လင့်ပါတယ်။ mask ကို ခန့်မှန်းဖို့ DistilBERT ရဲ့ tokenizer က model အတွက် inputs တွေကို ထုတ်လုပ်ပေးဖို့ လိုအပ်တာကြောင့်၊ အဲဒါကို Hub ကနေ download လုပ်လိုက်ရအောင်။
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)tokenizer နဲ့ model တစ်ခုရှိပြီဆိုတာနဲ့၊ ကျွန်တော်တို့ရဲ့ text ဥပမာကို model ကို ပေးပို့နိုင်ပြီး logits တွေကို ထုတ်ယူကာ ထိပ်တန်း ၅ ခုသော candidates တွေကို print ထုတ်နိုင်ပါတယ်။
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# [MASK] ၏ နေရာကို ရှာဖွေပြီး ၎င်း၏ logits များကို ထုတ်ယူပါ
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# အမြင့်ဆုံး logits ရှိသော [MASK] candidates များကို ရွေးချယ်ပါ
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'outputs တွေကနေ model ရဲ့ ခန့်မှန်းချက်တွေက နေ့စဉ်သုံး စကားလုံးတွေကို ရည်ညွှန်းနေတာကို ကျွန်တော်တို့ မြင်နိုင်ပါတယ်။ ဒါဟာ English Wikipedia ရဲ့ အခြေခံကြောင့် အံ့သြစရာ မဟုတ်ပါဘူး။ ဒီ domain ကို နည်းနည်းပို niche ဖြစ်တဲ့ အရာတစ်ခုဆီ ဘယ်လိုပြောင်းမလဲဆိုတာ ကြည့်ရအောင် — အလွန်အမင်း အမြင်ကွဲလွဲနေတဲ့ ရုပ်ရှင် reviews တွေဆီကိုပါ။
Dataset
domain adaptation ကို ပြသဖို့၊ ကျွန်တော်တို့ဟာ နာမည်ကျော် Large Movie Review Dataset (အတိုကောက် IMDb) ကို အသုံးပြုပါမယ်။ ဒါက sentiment analysis models တွေကို benchmark လုပ်ဖို့ မကြာခဏ အသုံးပြုတဲ့ ရုပ်ရှင် reviews corpus တစ်ခုပါ။ DistilBERT ကို ဒီ corpus ပေါ်မှာ fine-tune လုပ်ခြင်းဖြင့်၊ language model က ၎င်းရဲ့ vocabulary ကို pretrained လုပ်ခဲ့တဲ့ Wikipedia ရဲ့ factual data ကနေ movie reviews တွေရဲ့ ပိုပြီး subjective elements တွေဆီ လိုက်လျောညီထွေဖြစ်အောင် လုပ်မယ်လို့ ကျွန်တော်တို့ မျှော်လင့်ပါတယ်။ 🤗 Datasets ကနေ load_dataset() function နဲ့ data တွေကို Hugging Face Hub ကနေ ရယူနိုင်ပါတယ်။
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})train နဲ့ test splits တွေမှာ review ပေါင်း ၂၅,၀၀၀ စီ ပါဝင်နေတာကို ကျွန်တော်တို့ တွေ့နိုင်ပြီး၊ unsupervised လို့ခေါ်တဲ့ label မပါတဲ့ split တစ်ခုမှာ reviews ၅၀,၀၀၀ ပါဝင်ပါတယ်။ ဘယ်လို text မျိုးနဲ့ အလုပ်လုပ်နေတယ်ဆိုတာ သိရအောင် samples အချို့ကို ကြည့်ရအောင်။ သင်တန်းရဲ့ ယခင်အခန်းတွေမှာ လုပ်ခဲ့သလိုပဲ၊ random sample တစ်ခု ဖန်တီးဖို့ Dataset.shuffle() နဲ့ Dataset.select() functions တွေကို ဆက်တိုက်အသုံးပြုပါမယ်။
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'ဟုတ်ပါတယ်၊ ဒါတွေက ရုပ်ရှင် reviews တွေ ဖြစ်ပါတယ်။ သင်အသက်ကြီးပြီဆိုရင် နောက်ဆုံး review ထဲက VHS version ပိုင်ဆိုင်မှုနဲ့ ပတ်သက်တဲ့ မှတ်ချက်ကိုတောင် နားလည်နိုင်ပါလိမ့်မယ် 😜! language modeling အတွက် labels တွေ မလိုအပ်ပေမယ့်၊ 0 က negative review ကို ရည်ညွှန်းပြီး 1 က positive review ကို ကိုယ်စားပြုတာကို ကျွန်တော်တို့ တွေ့မြင်နိုင်ပါတယ်။
✏️ စမ်းသပ်ကြည့်ပါ။
unsupervisedsplit ရဲ့ random sample တစ်ခုကို ဖန်တီးပြီး labels တွေဟာ0ဒါမှမဟုတ်1မဟုတ်ဘူးဆိုတာ စစ်ဆေးပါ။ ဒီလိုလုပ်ရင်း၊trainနဲ့testsplits တွေထဲက labels တွေဟာ တကယ်ပဲ0ဒါမှမဟုတ်1ဟုတ်မဟုတ် စစ်ဆေးကြည့်နိုင်ပါတယ် — ဒါက NLP practitioner တိုင်း project အသစ်တစ်ခုရဲ့ အစမှာ လုပ်ဆောင်သင့်တဲ့ အသုံးဝင်တဲ့ sanity check တစ်ခုပါ!
data ကို အမြန်ကြည့်ပြီးပြီဆိုတော့၊ masked language modeling အတွက် ပြင်ဆင်တာကို ဆက်လုပ်ရအောင်။ Chapter 3 မှာ ကျွန်တော်တို့ တွေ့ခဲ့ရတဲ့ sequence classification tasks တွေနဲ့ နှိုင်းယှဉ်ရင်၊ လုပ်ဆောင်ရမယ့် ထပ်ဆောင်းအဆင့်အချို့ ရှိတာကို မြင်တွေ့ရပါလိမ့်မယ်။ စလိုက်ရအောင်!
Data ကို Preprocess လုပ်ခြင်း
auto-regressive နဲ့ masked language modeling နှစ်ခုလုံးအတွက်၊ common preprocessing step ကတော့ examples အားလုံးကို concatenate လုပ်ပြီးမှ corpus တစ်ခုလုံးကို အရွယ်အစားတူ chunks တွေအဖြစ် ခွဲထုတ်တာပါ။ ဒါက ကျွန်တော်တို့ရဲ့ ပုံမှန်ချဉ်းကပ်မှုနဲ့ အတော်လေး ကွာခြားပါတယ်။ ပုံမှန်အားဖြင့်တော့ individual examples တွေကို ရိုးရှင်းစွာ tokenize လုပ်တာပါ။ ဘာကြောင့် အရာအားလုံးကို concatenate လုပ်ရတာလဲ။ အကြောင်းရင်းကတော့ individual examples တွေက အရှည်လွန်ကဲရင် truncate လုပ်ခံရနိုင်ပြီး၊ ဒါက language modeling task အတွက် အသုံးဝင်နိုင်တဲ့ အချက်အလက်တွေ ဆုံးရှုံးစေနိုင်လို့ပါပဲ!
ဒါကြောင့် စတင်ဖို့၊ ကျွန်တော်တို့ corpus ကို ပုံမှန်အတိုင်း tokenize လုပ်ပါမယ်၊ ဒါပေမယ့် tokenizer မှာ truncation=True option ကို မသတ်မှတ်ပါဘူး။ word IDs တွေ ရနိုင်တယ်ဆိုရင်လည်း (Chapter 6 မှာ ဖော်ပြထားတဲ့အတိုင်း fast tokenizer ကို အသုံးပြုနေရင် ရနိုင်ပါတယ်) အဲဒါတွေကို ယူပါမယ်၊ ဘာလို့လဲဆိုတော့ နောက်ပိုင်းမှာ whole word masking လုပ်ဖို့ လိုအပ်မှာမို့လို့ပါ။ ဒါကို ရိုးရှင်းတဲ့ function တစ်ခုထဲမှာ ထည့်သွင်းပါမယ်၊ ပြီးတော့ text နဲ့ label columns တွေကို ကျွန်တော်တို့ မလိုအပ်တော့တဲ့အတွက် ဖယ်ရှားလိုက်ပါမယ်။
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Fast multithreading ကို activate လုပ်ဖို့ batched=True ကို အသုံးပြုပါ။
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})DistilBERT က BERT-like model တစ်ခုဖြစ်တဲ့အတွက်၊ encoded texts တွေဟာ အခြားအခန်းတွေမှာ ကျွန်တော်တို့ တွေ့ခဲ့ရတဲ့ input_ids နဲ့ attention_mask တွေအပြင် ကျွန်တော်တို့ ထည့်သွင်းခဲ့တဲ့ word_ids တွေ ပါဝင်နေတာကို တွေ့နိုင်ပါတယ်။
ကျွန်တော်တို့ movie reviews တွေကို tokenize လုပ်ပြီးပြီဆိုတော့၊ နောက်တစ်ဆင့်ကတော့ အားလုံးကို အတူတကွ group လုပ်ပြီး ရလဒ်ကို chunks တွေအဖြစ် ခွဲထုတ်တာပါ။ ဒါပေမယ့် ဒီ chunks တွေ ဘယ်လောက်ကြီးသင့်လဲ။ ဒါကို သင်ရရှိနိုင်တဲ့ GPU memory ပမာဏက အဆုံးအဖြတ်ပေးမှာဖြစ်ပေမယ့်၊ ကောင်းမွန်တဲ့ စတင်အမှတ်တစ်ခုက model ရဲ့ maximum context size ကို ကြည့်တာပါပဲ။ ဒါကို tokenizer ရဲ့ model_max_length attribute ကို စစ်ဆေးခြင်းဖြင့် ကောက်ချက်ချနိုင်ပါတယ်-
tokenizer.model_max_length
512ဒီတန်ဖိုးက checkpoint နဲ့ ဆက်စပ်နေတဲ့ tokenizer_config.json file ကနေ ဆင်းသက်လာတာပါ။ ဒီကိစ္စမှာ context size ဟာ BERT နဲ့ အတူတူ 512 tokens ဖြစ်တာကို တွေ့နိုင်ပါတယ်။
✏️ စမ်းသပ်ကြည့်ပါ။ BigBird နဲ့ Longformer လို Transformer models အချို့မှာ BERT နဲ့ အခြားအစောပိုင်း Transformer models တွေထက် အများကြီး ပိုရှည်တဲ့ context length ရှိပါတယ်။ ဒီ checkpoints တွေထဲက တစ်ခုအတွက် tokenizer ကို instantiate လုပ်ပြီး
model_max_lengthက ၎င်းရဲ့ model card မှာ ဖော်ပြထားတာနဲ့ ကိုက်ညီခြင်းရှိမရှိ စစ်ဆေးပါ။
ဒါကြောင့်၊ Google Colab မှာ တွေ့ရတဲ့ GPU တွေလိုမျိုးပေါ်မှာ ကျွန်တော်တို့ရဲ့ experiments တွေကို run ဖို့အတွက်၊ memory ထဲမှာ ဆံ့ဝင်နိုင်မယ့် နည်းနည်းပိုသေးငယ်တဲ့ အရာတစ်ခုကို ရွေးချယ်ပါမယ်-
chunk_size = 128သေးငယ်သော chunk size ကို အသုံးပြုခြင်းက လက်တွေ့ကမ္ဘာအခြေအနေများတွင် ဆိုးကျိုးဖြစ်စေနိုင်ကြောင်း သတိပြုပါ၊ ထို့ကြောင့် သင်၏ model ကို အသုံးချမည့် use case နှင့် ကိုက်ညီသော အရွယ်အစားကို အသုံးပြုသင့်ပါသည်။
အခုမှ ပျော်စရာအပိုင်းရောက်ပြီ။ concatenation ဘယ်လိုအလုပ်လုပ်လဲဆိုတာ ပြသဖို့၊ ကျွန်တော်တို့ရဲ့ tokenized training set ကနေ reviews အချို့ကို ယူပြီး review တစ်ခုစီအတွက် tokens အရေအတွက်ကို print ထုတ်ရအောင်-
# Slicing လုပ်ခြင်းက feature တစ်ခုစီအတွက် list of lists တွေကို ထုတ်ပေးပါတယ်
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'ပြီးရင် ဒီ examples တွေအားလုံးကို ရိုးရှင်းတဲ့ dictionary comprehension နဲ့ concatenate လုပ်နိုင်ပါတယ်-
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")'>>> Concatenated reviews length: 951'ကောင်းပါပြီ၊ စုစုပေါင်းအရှည် မှန်ကန်ပါတယ် — ဒါဆို အခု concatenated reviews တွေကို chunk_size က ပေးထားတဲ့ အရွယ်အစား chunks တွေအဖြစ် ခွဲထုတ်ရအောင်။ ဒါကိုလုပ်ဖို့၊ concatenated_examples ထဲက features တွေကို iterate လုပ်ပြီး list comprehension ကို အသုံးပြုကာ feature တစ်ခုစီရဲ့ slices တွေကို ဖန်တီးပါမယ်။ ရလဒ်ကတော့ feature တစ်ခုစီအတွက် chunks dictionary တစ်ခုပါပဲ-
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'ဒီဥပမာမှာ သင်တွေ့ရတဲ့အတိုင်း၊ နောက်ဆုံး chunk က အများအားဖြင့် maximum chunk size ထက် သေးငယ်ပါလိမ့်မယ်။ ဒါကို ဖြေရှင်းဖို့ အဓိကနည်းလမ်းနှစ်ခုရှိပါတယ်။
- နောက်ဆုံး chunk က
chunk_sizeထက် သေးငယ်ရင် ဖယ်ရှားပါ။ - နောက်ဆုံး chunk ကို ၎င်း၏အရှည်
chunk_sizeနဲ့ တူညီသည်အထိ padding လုပ်ပါ။
ဒီနေရာမှာ ပထမနည်းလမ်းကို ကျွန်တော်တို့ အသုံးပြုပါမယ်၊ ဒါကြောင့် အထက်ပါ logic အားလုံးကို ကျွန်တော်တို့ရဲ့ tokenized datasets တွေပေါ်မှာ အသုံးပြုနိုင်မယ့် function တစ်ခုတည်းမှာ ထည့်သွင်းလိုက်ရအောင်။
def group_texts(examples):
# စာသားများအားလုံးကို concatenate လုပ်ပါ
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# concatenate လုပ်ထားသော စာသားများ၏ အရှည်ကို တွက်ချက်ပါ
total_length = len(concatenated_examples[list(examples.keys())[0]])
# chunk_size ထက် သေးငယ်သော နောက်ဆုံး chunk ကို ဖယ်ရှားပါ
total_length = (total_length // chunk_size) * chunk_size
# max_len chunks များဖြင့် ပိုင်းခြားပါ
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# labels column အသစ်တစ်ခု ဖန်တီးပါ
result["labels"] = result["input_ids"].copy()
return resultgroup_texts() ရဲ့ နောက်ဆုံးအဆင့်မှာ ကျွန်တော်တို့ဟာ input_ids ရဲ့ copy ဖြစ်တဲ့ labels column အသစ်တစ်ခုကို ဖန်တီးတာကို သတိပြုပါ။ မကြာခင်မှာ ကျွန်တော်တို့ တွေ့ရမယ့်အတိုင်း၊ masked language modeling မှာ objective က input batch ထဲက ကျပန်း mask လုပ်ထားတဲ့ tokens တွေကို ခန့်မှန်းဖို့ဖြစ်ပြီး၊ labels column တစ်ခု ဖန်တီးခြင်းဖြင့် ကျွန်တော်တို့ရဲ့ language model ကို သင်ယူဖို့အတွက် ground truth ကို ပံ့ပိုးပေးပါတယ်။
အခု group_texts() ကို ကျွန်တော်တို့ရဲ့ သစ္စာရှိ Dataset.map() function ကို အသုံးပြုပြီး tokenized datasets တွေပေါ်မှာ အသုံးပြုရအောင်-
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})texts တွေကို group လုပ်ပြီးမှ chunk လုပ်ခြင်းက ကျွန်တော်တို့ရဲ့ မူရင်း train နဲ့ test splits တွေအတွက် ၂၅,၀၀၀ ထက် ပိုများတဲ့ examples တွေ ထုတ်ပေးခဲ့တာကို သင်တွေ့နိုင်ပါတယ်။ ဒါက မူရင်း corpus ကနေ examples များစွာကို ဖြန့်ကျက်ထားတဲ့ contiguous tokens တွေပါဝင်တဲ့ examples တွေ အခု ကျွန်တော်တို့မှာ ရှိနေလို့ပါပဲ။ chunk တစ်ခုထဲက special [SEP] နဲ့ [CLS] tokens တွေကို ရှာဖွေခြင်းဖြင့် ဒါကို ရှင်းရှင်းလင်းလင်း မြင်နိုင်ပါတယ်။
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"ဒီဥပမာမှာ high school ရုပ်ရှင်တစ်ခုနဲ့ homelessness အကြောင်း ရုပ်ရှင် reviews နှစ်ခု ထပ်နေတာကို သင်တွေ့နိုင်ပါတယ်။ masked language modeling အတွက် labels တွေက ဘယ်လိုပုံစံရှိလဲဆိုတာလည်း စစ်ဆေးကြည့်ရအောင်။
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"ကျွန်တော်တို့ရဲ့ group_texts() function ကနေ မျှော်လင့်ထားတဲ့အတိုင်း၊ ဒါက decode လုပ်ထားတဲ့ input_ids နဲ့ တူညီနေပါတယ်။ — ဒါပေမယ့် ကျွန်တော်တို့ရဲ့ model က ဘာမှ သင်ယူနိုင်မှာ မဟုတ်ဘူးလား။ ကျွန်တော်တို့ အဓိကအဆင့်တစ်ခု လွဲနေပါတယ်။ input တွေထဲမှာ [MASK] tokens တွေကို ကျပန်းနေရာတွေမှာ ထည့်သွင်းရပါမယ်။ fine-tuning လုပ်နေစဉ်မှာ အထူး data collator တစ်ခုကို အသုံးပြုပြီး ဒါကို ဘယ်လိုလုပ်ရမလဲဆိုတာ ကြည့်ရအောင်။
Trainer API ဖြင့် DistilBERT ကို Fine-tuning လုပ်ခြင်း
masked language model တစ်ခုကို fine-tuning လုပ်တာဟာ Chapter 3 မှာ ကျွန်တော်တို့ လုပ်ခဲ့တဲ့ sequence classification model တစ်ခုကို fine-tuning လုပ်တာနဲ့ လုံးဝနီးပါး တူညီပါတယ်။ တစ်ခုတည်းသော ကွာခြားချက်ကတော့ text အုပ်စုတစ်ခုစီမှာ tokens အချို့ကို ကျပန်း mask လုပ်နိုင်တဲ့ special data collator တစ်ခု လိုအပ်တာပါပဲ။ ကံကောင်းစွာနဲ့ပဲ၊ 🤗 Transformers က ဒီ task အတွက် သီးသန့် DataCollatorForLanguageModeling နဲ့အတူ ထွက်ရှိလာပါတယ်။ ကျွန်တော်တို့က tokenizer နဲ့ mask လုပ်မယ့် tokens ရဲ့ အချိုးကို သတ်မှတ်ပေးမယ့် mlm_probability argument ကိုပဲ ပေးဖို့လိုပါတယ်။ BERT အတွက် အသုံးပြုခဲ့တဲ့ ပမာဏနဲ့ literature မှာ အသုံးများတဲ့ ၁၅% ကို ရွေးချယ်ပါမယ်။
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)random masking ဘယ်လိုအလုပ်လုပ်လဲဆိုတာ ကြည့်ဖို့၊ data collator ကို ဥပမာအချို့ ပေးကြည့်ရအောင်။ ၎င်းက dict များ၏ list တစ်ခုကို မျှော်လင့်ထားတာကြောင့် (အဲဒီ dict တစ်ခုစီက contiguous text တစ်ခုရဲ့ chunk တစ်ခုကို ကိုယ်စားပြုပါတယ်)၊ ကျွန်တော်တို့ဟာ batch ကို collator ကို မပေးပို့ခင် dataset ကို အရင် iterate လုပ်ပါတယ်။ ဒီ data collator အတွက် "word_ids" key ကို ဖယ်ရှားလိုက်ပါတယ်၊ ဘာလို့လဲဆိုတော့ ၎င်းက ဒါကို မမျှော်လင့်ထားလို့ပါ။
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'ကောင်းပါပြီ၊ အလုပ်ဖြစ်ပါတယ်။ [MASK] token ကို ကျွန်တော်တို့ရဲ့ text ထဲမှာ ကျပန်းနေရာအမျိုးမျိုးမှာ ထည့်သွင်းထားတာကို ကျွန်တော်တို့ မြင်နိုင်ပါတယ်။ ဒါတွေက training လုပ်နေစဉ်မှာ ကျွန်တော်တို့ model က ခန့်မှန်းရမယ့် tokens တွေ ဖြစ်ပါလိမ့်မယ် — data collator ရဲ့ ကောင်းကွက်ကတော့ batch တိုင်းမှာ [MASK] ထည့်သွင်းမှုကို random လုပ်ပေးမှာပါပဲ!
✏️ စမ်းသပ်ကြည့်ပါ။ အပေါ်က code snippet ကို အကြိမ်ပေါင်းများစွာ run ပြီး random masking ဘယ်လိုဖြစ်လဲဆိုတာ သင့်မျက်စိနဲ့ မြင်တွေ့ပါ။
tokenizer.decode()method ကိုtokenizer.convert_ids_to_tokens()နဲ့ အစားထိုးပြီး တခါတလေ စကားလုံးတစ်ခုကနေ single token တစ်ခုပဲ mask လုပ်ခံရပြီး တခြား tokens တွေက mask လုပ်မခံရဘူးဆိုတာကို ကြည့်ပါ။
random masking ရဲ့ ဘေးထွက်ဆိုးကျိုးတစ်ခုကတော့ ကျွန်တော်တို့ရဲ့ evaluation metrics တွေက Trainer ကို အသုံးပြုတဲ့အခါ deterministic ဖြစ်မှာ မဟုတ်ပါဘူး။ ဘာလို့လဲဆိုတော့ training နဲ့ test sets တွေအတွက် data collator တူတူကို အသုံးပြုလို့ပါ။ နောက်ပိုင်းမှာ 🤗 Accelerate နဲ့ fine-tuning လုပ်တာကို ကြည့်တဲ့အခါ၊ randomness ကို ဘယ်လို freeze လုပ်နိုင်မလဲဆိုတာကို custom evaluation loop ရဲ့ flexibility ကို အသုံးပြုပြီး ကြည့်ရပါမယ်။
masked language modeling အတွက် models တွေကို train လုပ်တဲ့အခါ အသုံးပြုနိုင်တဲ့ နည်းလမ်းတစ်ခုကတော့ တစ်ဦးချင်းစီ tokens တွေကို mask လုပ်ရုံသာမကဘဲ စကားလုံးတစ်ခုလုံးကို အတူတကွ mask လုပ်တာပါ။ ဒီချဉ်းကပ်မှုကို whole word masking လို့ခေါ်ပါတယ်။ whole word masking ကို အသုံးပြုချင်တယ်ဆိုရင်၊ ကျွန်တော်တို့ကိုယ်တိုင် data collator တစ်ခု တည်ဆောက်ဖို့ လိုအပ်ပါလိမ့်မယ်။ data collator ဆိုတာ samples list တစ်ခုကို ယူပြီး batch တစ်ခုအဖြစ် ပြောင်းလဲပေးတဲ့ function တစ်ခုသာ ဖြစ်ပါတယ်။ ဒါကြောင့် အခု ဒါကို လုပ်ဆောင်လိုက်ရအောင်။ ကျွန်တော်တို့ဟာ word indices တွေနဲ့ သက်ဆိုင်ရာ tokens တွေကြား map တစ်ခု ဖန်တီးဖို့အတွက် အရင်က တွက်ချက်ထားတဲ့ word IDs တွေကို အသုံးပြုပါမယ်။ ပြီးရင် ဘယ်စကားလုံးတွေကို mask လုပ်ရမယ်ဆိုတာ ကျပန်းဆုံးဖြတ်ပြီး အဲဒီ mask ကို inputs တွေပေါ်မှာ အသုံးပြုပါမယ်။ labels တွေက mask words တွေနဲ့ ကိုက်ညီတဲ့ အရာတွေကလွဲလို့ အားလုံး -100 ဖြစ်နေတာကို သတိပြုပါ။
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# စကားလုံးတွေနဲ့ သက်ဆိုင်ရာ token indices တွေကြား map တစ်ခု ဖန်တီးပါ
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# စကားလုံးတွေကို ကျပန်း mask လုပ်ပါ
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)နောက်တစ်ခုကတော့ ယခင်ကလိုပဲ တူညီတဲ့ samples တွေပေါ်မှာ စမ်းကြည့်နိုင်ပါတယ်-
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ စမ်းသပ်ကြည့်ပါ။ အပေါ်က code snippet ကို အကြိမ်ပေါင်းများစွာ run ပြီး random masking ဘယ်လိုဖြစ်လဲဆိုတာ သင့်မျက်စိနဲ့ မြင်တွေ့ပါ။
tokenizer.decode()method ကိုtokenizer.convert_ids_to_tokens()နဲ့ အစားထိုးပြီး စကားလုံးတစ်ခုကနေ tokens တွေဟာ အမြဲတမ်း အတူတကွ mask လုပ်ခံရတယ်ဆိုတာ ကြည့်ပါ။
အခု ကျွန်တော်တို့မှာ data collators နှစ်ခုရှိပြီဆိုတော့၊ ကျန်တဲ့ fine-tuning အဆင့်တွေကတော့ ပုံမှန်အတိုင်းပါပဲ။ ကံကောင်းစွာနဲ့ P100 GPU 😭😭 မရရင် Google Colab မှာ training က အချိန်အတော်ကြာနိုင်တာကြောင့်၊ training set ရဲ့ အရွယ်အစားကို ထောင်ဂဏန်းအနည်းငယ်လောက်အထိ downsample လုပ်ပါမယ်။ စိတ်မပူပါနဲ့၊ ကျွန်တော်တို့ ကောင်းမွန်တဲ့ language model တစ်ခုတော့ ရရှိဦးမှာပါ။ 🤗 Datasets မှာ dataset တစ်ခုကို မြန်မြန်ဆန်ဆန် downsample လုပ်နိုင်တဲ့ နည်းလမ်းတစ်ခုက Chapter 5 မှာ ကျွန်တော်တို့ တွေ့ခဲ့ရတဲ့ Dataset.train_test_split() function ကို အသုံးပြုခြင်းပါပဲ။
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})ဒါက အလိုအလျောက် train နဲ့ test splits အသစ်တွေ ဖန်တီးပေးခဲ့ပြီး၊ training set အရွယ်အစားကို examples ၁၀,၀၀၀ အဖြစ် သတ်မှတ်ထားကာ validation set ကို အဲဒီရဲ့ ၁၀% အဖြစ် သတ်မှတ်ထားပါတယ် — သင့်မှာ အားကောင်းတဲ့ GPU ရှိရင် ဒါကို ပိုတိုးမြှင့်နိုင်ပါတယ်။ နောက်တစ်ခုလုပ်ရမှာက Hugging Face Hub ကို login ဝင်တာပါပဲ။ သင် ဒီ code ကို notebook တစ်ခုထဲမှာ run နေတယ်ဆိုရင်၊ အောက်ပါ utility function နဲ့ လုပ်နိုင်ပါတယ်။
from huggingface_hub import notebook_login
notebook_login()ဒါက သင်ရဲ့ credentials တွေ ထည့်သွင်းနိုင်မယ့် widget တစ်ခုကို ပြသပါလိမ့်မယ်။ ဒါမှမဟုတ်၊ သင်အကြိုက်ဆုံး terminal မှာ အောက်ပါအတိုင်း run နိုင်ပါတယ်။
huggingface-cli loginပြီးတော့ အဲဒီမှာ login ဝင်ပါ။
ကျွန်တော်တို့ login ဝင်ပြီးတာနဲ့၊ Trainer အတွက် arguments တွေကို သတ်မှတ်နိုင်ပါတယ်။
from transformers import TrainingArguments
batch_size = 64
# epoch တိုင်းမှာ training loss ကို ပြသပါ
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)ဒီနေရာမှာ ကျွန်တော်တို့ဟာ default options အချို့ကို ပြောင်းလဲခဲ့ပါတယ်၊ logging_steps အပါအဝင် ဒါက epoch တိုင်းမှာ training loss ကို ခြေရာခံဖို့ သေချာစေပါတယ်။ mixed-precision training ကို ဖွင့်ဖို့ fp16=True ကိုလည်း အသုံးပြုခဲ့ပါတယ်၊ ဒါက ကျွန်တော်တို့ကို speed ကို ထပ်တိုးပေးပါတယ်။ default အားဖြင့်၊ Trainer က model ရဲ့ forward() method ရဲ့ အစိတ်အပိုင်းမဟုတ်တဲ့ columns တွေကို ဖယ်ရှားပါလိမ့်မယ်။ ဒါက whole word masking collator ကို အသုံးပြုနေတယ်ဆိုရင်၊ training လုပ်နေစဉ် word_ids column ကို မဆုံးရှုံးစေဖို့ remove_unused_columns=False ကိုလည်း သတ်မှတ်ဖို့ လိုအပ်တယ်လို့ ဆိုလိုတာပါ။
သင် push လုပ်ချင်တဲ့ repository နာမည်ကို hub_model_id argument နဲ့ သတ်မှတ်နိုင်တာကို သတိပြုပါ (အထူးသဖြင့် organization တစ်ခုကို push လုပ်ဖို့ ဒီ argument ကို အသုံးပြုရပါလိမ့်မယ်)။ ဥပမာ၊ ကျွန်တော်တို့ model ကို huggingface-course organization ကို push လုပ်တဲ့အခါ၊ TrainingArguments မှာ hub_model_id="huggingface-course/distilbert-finetuned-imdb" ကို ထည့်သွင်းခဲ့ပါတယ်။ default အားဖြင့်၊ အသုံးပြုတဲ့ repository က သင့် namespace ထဲမှာရှိပြီး သင်သတ်မှတ်ထားတဲ့ output directory အမည်အတိုင်း ဖြစ်ပါလိမ့်မယ်၊ ဒါကြောင့် ကျွန်တော်တို့ ကိစ္စမှာတော့ "lewtun/distilbert-finetuned-imdb" ဖြစ်ပါလိမ့်မယ်။
အခု Trainer ကို instantiate လုပ်ဖို့ အရာအားလုံး အသင့်ပါပဲ။ ဒီနေရာမှာ standard data_collator ကိုပဲ အသုံးပြုပါမယ်၊ ဒါပေမယ့် whole word masking collator ကို စမ်းပြီး ရလဒ်တွေကို နှိုင်းယှဉ်နိုင်ပါတယ်။
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)ကျွန်တော်တို့ အခု trainer.train() ကို run ဖို့ အဆင်သင့်ပါပြီ — ဒါပေမယ့် ဒါကို မလုပ်ခင်၊ language models တွေရဲ့ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ဖို့ အသုံးများတဲ့ metric တစ်ခုဖြစ်တဲ့ perplexity အကြောင်း အတိုချုံး ကြည့်ရအောင်။
Language Models များအတွက် Perplexity
text classification ဒါမှမဟုတ် question answering လို အခြား tasks တွေနဲ့မတူဘဲ (အဲဒီ tasks တွေမှာ training လုပ်ဖို့ labeled corpus တစ်ခု ပေးထားပါတယ်)၊ language modeling မှာတော့ ကျွန်တော်တို့မှာ explicit labels တွေ မရှိပါဘူး။ ဒါဆို ဘယ်အရာက ကောင်းမွန်တဲ့ language model တစ်ခုကို ဖြစ်စေသလဲဆိုတာ ဘယ်လို ဆုံးဖြတ်မလဲ။ သင့်ဖုန်းထဲက autocorrect feature လိုပဲ၊ ကောင်းမွန်တဲ့ language model ဆိုတာ သဒ္ဒါမှန်ကန်တဲ့ စာကြောင်းတွေကို မြင့်မားတဲ့ probabilities တွေ သတ်မှတ်ပေးပြီး၊ အဓိပ္ပာယ်မရှိတဲ့ စာကြောင်းတွေကို နိမ့်ကျတဲ့ probabilities တွေ သတ်မှတ်ပေးတဲ့ model တစ်ခုပါပဲ။ ဒါက ဘယ်လိုပုံစံရှိလဲဆိုတာ ပိုကောင်းကောင်း သိရအောင်၊ အွန်လိုင်းမှာ “autocorrect fails” တွေ အများကြီး တွေ့နိုင်ပါတယ်။ အဲဒီမှာ လူတစ်ယောက်ရဲ့ ဖုန်းထဲက model က ရယ်စရာကောင်းပြီး (မကြာခဏ မသင့်လျော်တဲ့) ဖြည့်စွက်မှုတွေကို ထုတ်လုပ်ပေးခဲ့တာပါ။
ကျွန်တော်တို့ရဲ့ test set မှာ သဒ္ဒါမှန်ကန်တဲ့ စာကြောင်းတွေ အများစု ပါဝင်တယ်လို့ ယူဆရင်၊ ကျွန်တော်တို့ရဲ့ language model ရဲ့ အရည်အသွေးကို တိုင်းတာတဲ့ နည်းလမ်းတစ်ခုကတော့ test set ထဲက စာကြောင်းအားလုံးရဲ့ နောက်လာမယ့် စကားလုံးအတွက် model က သတ်မှတ်ပေးတဲ့ probabilities တွေကို တွက်ချက်တာပါပဲ။ မြင့်မားတဲ့ probabilities တွေက model ဟာ မမြင်ဖူးသေးတဲ့ examples တွေကြောင့် “အံ့သြ” ခြင်း ဒါမှမဟုတ် “တွေဝေ” ခြင်း မဖြစ်ဘူးဆိုတာကို ပြသပြီး၊ language ထဲက grammar ရဲ့ အခြေခံ patterns တွေကို သင်ယူပြီးပြီဆိုတာကို အကြံပြုပါတယ်။ perplexity ရဲ့ သင်္ချာဆိုင်ရာ အဓိပ္ပာယ်ဖွင့်ဆိုချက်အမျိုးမျိုး ရှိပေမယ့်၊ ကျွန်တော်တို့ အသုံးပြုမယ့် တစ်ခုကတော့ cross-entropy loss ရဲ့ exponential အဖြစ် သတ်မှတ်ထားပါတယ်။ ဒါကြောင့်၊ ကျွန်တော်တို့ရဲ့ pretrained model ရဲ့ perplexity ကို Trainer.evaluate() function ကို အသုံးပြုပြီး test set ပေါ်က cross-entropy loss ကို တွက်ချက်ကာ ရလဒ်ရဲ့ exponential ကို ယူခြင်းဖြင့် တွက်ချက်နိုင်ပါတယ်။
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 21.75Perplexity score နိမ့်လေ၊ language model ပိုကောင်းလေပါပဲ။ ဒီနေရာမှာ ကျွန်တော်တို့ရဲ့ စတင်တဲ့ model မှာ အတော်လေး မြင့်မားတဲ့ တန်ဖိုးရှိတာကို တွေ့နိုင်ပါတယ်။ fine-tuning လုပ်ခြင်းဖြင့် ဒါကို လျှော့ချနိုင်မလား ကြည့်ရအောင်။ ဒါကို လုပ်ဖို့၊ ပထမဆုံး training loop ကို run ပါ။
trainer.train()
ပြီးရင် ယခင်ကအတိုင်း test set ပေါ်က ရလဒ် perplexity ကို တွက်ချက်ပါ။
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 11.32ကောင်းပါပြီ — ဒါက perplexity မှာ အတော်လေး လျှော့ချနိုင်ခဲ့တာဖြစ်ပြီး၊ model က movie reviews domain အကြောင်း တစ်ခုခု သင်ယူခဲ့ပြီးပြီဆိုတာ ပြောပြနေတာပါပဲ!
training ပြီးသွားတာနဲ့၊ training information ပါတဲ့ model card ကို Hub ကို push လုပ်နိုင်ပါတယ် (checkpoints တွေကို training လုပ်နေစဉ်မှာပဲ save လုပ်ပါတယ်)။
trainer.push_to_hub()
✏️ သင့်အလှည့်ပါ! data collator ကို whole word masking collator သို့ ပြောင်းလဲပြီး အထက်ပါ training ကို run ပါ။ ပိုကောင်းတဲ့ ရလဒ်တွေ ရပါသလား။
ကျွန်တော်တို့ရဲ့ use case မှာ training loop နဲ့ ပတ်သက်ပြီး ထူးခြားတဲ့ အရာတစ်ခုခု လုပ်ဖို့ မလိုအပ်ခဲ့ပါဘူး၊ ဒါပေမယ့် တချို့ကိစ္စတွေမှာတော့ custom logic အချို့ကို implement လုပ်ဖို့ လိုအပ်နိုင်ပါတယ်။ ဒီ applications တွေအတွက် 🤗 Accelerate ကို အသုံးပြုနိုင်ပါတယ် — ကြည့်ရအောင်!
🤗 Accelerate ဖြင့် DistilBERT ကို Fine-tuning လုပ်ခြင်း
Trainer နဲ့ တွေ့ခဲ့ရတဲ့အတိုင်း၊ masked language model တစ်ခုကို fine-tuning လုပ်တာဟာ Chapter 3 က text classification ဥပမာနဲ့ အလွန်ဆင်တူပါတယ်။ တကယ်တော့၊ တစ်ခုတည်းသော အသေးစိတ်အချက်ကတော့ special data collator ကို အသုံးပြုတာဖြစ်ပြီး၊ ဒါကို ဒီအပိုင်းရဲ့ အစောပိုင်းမှာ ကျွန်တော်တို့ ဖော်ပြခဲ့ပြီးပါပြီ!
သို့သော်လည်း၊ DataCollatorForLanguageModeling က evaluation တစ်ခုစီနဲ့ random masking ကို အသုံးပြုတယ်ဆိုတာ ကျွန်တော်တို့ တွေ့ခဲ့ရပါတယ်၊ ဒါကြောင့် ကျွန်တော်တို့ရဲ့ perplexity scores တွေမှာ training run တစ်ခုစီနဲ့ အတူ အပြောင်းအလဲအချို့ တွေ့ရမှာပါ။ randomness ရဲ့ ဒီအရင်းအမြစ်ကို ဖယ်ရှားဖို့ နည်းလမ်းတစ်ခုကတော့ test set တစ်ခုလုံးပေါ်မှာ masking ကို တစ်ကြိမ် အသုံးပြုပြီး၊ ပြီးရင် evaluation လုပ်နေစဉ် batches တွေကို စုစည်းဖို့ 🤗 Transformers က default data collator ကို အသုံးပြုတာပါပဲ။ ဒါဘယ်လိုအလုပ်လုပ်လဲဆိုတာ မြင်ရအောင်၊ DataCollatorForLanguageModeling နဲ့ ပထမဆုံးတွေ့ဆုံခဲ့တာနဲ့ ဆင်တူတဲ့ batch ပေါ်မှာ masking ကို အသုံးပြုတဲ့ ရိုးရှင်းတဲ့ function တစ်ခုကို implement လုပ်ရအောင်။
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# dataset ထဲက column တစ်ခုစီအတွက် "masked_" prefix ပါတဲ့ column အသစ်တစ်ခု ဖန်တီးပါ
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}နောက်တစ်ခုကတော့ ဒီ function ကို ကျွန်တော်တို့ test set ပေါ်မှာ အသုံးပြုပြီး unmasked columns တွေကို ဖယ်ရှားကာ masked columns တွေနဲ့ အစားထိုးပါမယ်။ အထက်ပါ data_collator ကို သင့်လျော်တဲ့ တစ်ခုနဲ့ အစားထိုးခြင်းဖြင့် whole word masking ကို အသုံးပြုနိုင်ပါတယ်၊ ဒီကိစ္စမှာ ပထမဆုံး line ကို ဒီနေရာမှာ ဖယ်ရှားသင့်ပါတယ်။
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)ပြီးရင် dataloaders တွေကို ပုံမှန်အတိုင်း တည်ဆောက်နိုင်ပါတယ်၊ ဒါပေမယ့် evaluation set အတွက် 🤗 Transformers က default_data_collator ကို အသုံးပြုပါမယ်။
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)ဒီနေရာကစပြီး 🤗 Accelerate နဲ့ standard steps တွေကို လိုက်နာရပါမယ်။ ပထမဆုံးလုပ်ရမှာက pretrained model ရဲ့ အသစ် version တစ်ခုကို load လုပ်တာပါပဲ။
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)ပြီးရင် optimizer ကို သတ်မှတ်ဖို့ လိုအပ်ပါတယ်၊ standard AdamW ကို အသုံးပြုပါမယ်။
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)ဒီ objects တွေနဲ့၊ Accelerator object နဲ့ training အတွက် အရာအားလုံးကို အခု ကျွန်တော်တို့ ပြင်ဆင်နိုင်ပါပြီ။
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)ကျွန်တော်တို့ရဲ့ model, optimizer, နဲ့ dataloaders တွေ configure လုပ်ပြီးပြီဆိုတော့၊ learning rate scheduler ကို အောက်ပါအတိုင်း သတ်မှတ်နိုင်ပါတယ်။
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)training မလုပ်ခင် နောက်ဆုံးလုပ်စရာတစ်ခုပဲ ရှိပါတယ်။ Hugging Face Hub ပေါ်မှာ model repository တစ်ခု ဖန်တီးတာပါ။ Hugging Face Hub library ကို အသုံးပြုပြီး ကျွန်တော်တို့ရဲ့ repo ရဲ့ နာမည်အပြည့်အစုံကို အရင်ဆုံး generate လုပ်နိုင်ပါတယ်။
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'ပြီးရင် 🤗 Hub က Repository class ကို အသုံးပြုပြီး repository ကို ဖန်တီးပြီး clone လုပ်ပါ။
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)ဒါတွေ လုပ်ဆောင်ပြီးပြီဆိုတာနဲ့၊ training နဲ့ evaluation loop အပြည့်အစုံကို ရေးရုံပါပဲ။
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409ကောင်းပါပြီ၊ epoch တိုင်းမှာ perplexity ကို အကဲဖြတ်နိုင်ခဲ့ပြီး multiple training runs တွေ reproducible ဖြစ်အောင် သေချာစေခဲ့ပါတယ်။
ကျွန်တော်တို့ရဲ့ Fine-tuned Model ကို အသုံးပြုခြင်း
သင်ရဲ့ fine-tuned model နဲ့ Hub ပေါ်က ၎င်းရဲ့ widget ကို အသုံးပြုခြင်းဖြင့် ဒါမှမဟုတ် 🤗 Transformers က pipeline နဲ့ locally အသုံးပြုခြင်းဖြင့် အပြန်အလှန်ဆက်သွယ်နိုင်ပါတယ်။ fill-mask pipeline ကို အသုံးပြုပြီး ကျွန်တော်တို့ရဲ့ model ကို download လုပ်ဖို့ နောက်ဆုံးနည်းလမ်းကို အသုံးပြုရအောင်။
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)ပြီးရင် pipeline ကို ကျွန်တော်တို့ရဲ့ sample text ဖြစ်တဲ့ “This is a great [MASK]” ကို ပေးပို့ပြီး ထိပ်တန်း ၅ ခုသော predictions တွေက ဘာတွေလဲဆိုတာ ကြည့်နိုင်ပါတယ်။
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'ကောင်းပါပြီ။ ကျွန်တော်တို့ model က movie တွေနဲ့ ပိုမိုဆက်စပ်နေတဲ့ စကားလုံးတွေကို ခန့်မှန်းဖို့ ၎င်းရဲ့ weights တွေကို ရှင်းရှင်းလင်းလင်း လိုက်လျောညီထွေဖြစ်အောင် လုပ်ခဲ့တာကို တွေ့နိုင်ပါတယ်။
ဒါက language model တစ်ခုကို train လုပ်ခြင်းနဲ့ ပတ်သက်တဲ့ ကျွန်တော်တို့ရဲ့ ပထမဆုံး experiment ကို နိဂုံးချုပ်လိုက်ပါပြီ။ section 6 မှာ GPT-2 လို auto-regressive model တစ်ခုကို အစကနေ ဘယ်လို train လုပ်ရမယ်ဆိုတာ သင်ယူရမှာပါ၊ သင့်ကိုယ်ပိုင် Transformer model ကို ဘယ်လို pretrain လုပ်နိုင်မလဲဆိုတာ ကြည့်ချင်တယ်ဆိုရင် အဲဒီကို သွားပါ။
✏️ သင့်အလှည့်ပါ! data collator ကို whole word masking collator သို့ ပြောင်းလဲပြီးနောက် အထက်ပါ training ကို run ပါ။ pretrained နဲ့ fine-tuned DistilBERT checkpoints နှစ်ခုလုံးအတွက် IMDb labels တွေပေါ်မှာ classifier တစ်ခုကို fine-tune လုပ်ခြင်းဖြင့် domain adaptation ရဲ့ အကျိုးကျေးဇူးတွေကို quantification လုပ်ကြည့်ပါ။ text classification အကြောင်း ပြန်လည်လေ့လာဖို့ လိုအပ်ရင် Chapter 3 ကို ကြည့်ပါ။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- Masked Language Model (MLM): စာကြောင်းတစ်ခုထဲမှ စကားလုံးအချို့ကို ဝှက်ထားပြီး ၎င်းတို့ကို ခန့်မှန်းစေခြင်းဖြင့် model ကို လေ့ကျင့်သော task (BERT ကဲ့သို့)။
- Fine-tuning: ကြိုတင်လေ့ကျင့်ထားပြီးသား (pre-trained) မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခု (specific task) အတွက် အနည်းငယ်သော ဒေတာနဲ့ ထပ်မံလေ့ကျင့်ပေးခြင်းကို ဆိုလိုပါတယ်။
- Transformer Models: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။
- Pretrained Model: အကြီးစား ဒေတာအမြောက်အမြားဖြင့် ကြိုတင်လေ့ကျင့်ထားပြီးဖြစ်သော AI (Artificial Intelligence) မော်ဒယ်။
- Hugging Face Hub: AI မော်ဒယ်တွေ၊ datasets တွေနဲ့ demo တွေကို အခြားသူတွေနဲ့ မျှဝေဖို့၊ ရှာဖွေဖို့နဲ့ ပြန်လည်အသုံးပြုဖို့အတွက် အွန်လိုင်း platform တစ်ခု ဖြစ်ပါတယ်။
- Downstream Performance: Model တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခု (downstream task) ပေါ်တွင် fine-tune လုပ်ပြီးနောက် ရရှိသော စွမ်းဆောင်ရည်။
- Corpus: စာသား (သို့မဟုတ် အခြားဒေတာ) အစုအဝေးကြီးတစ်ခု။
- Transfer Learning: ကြိုတင်လေ့ကျင့်ထားသော model ၏ ဗဟုသုတကို အခြားဆက်စပ် task သို့ လွှဲပြောင်းအသုံးပြုခြင်း။
- Language Models: လူသားဘာသာစကား၏ ဖြန့်ဝေမှုကို နားလည်ရန် လေ့ကျင့်ထားသော AI မော်ဒယ်တစ်ခု။
- Task-specific Head: Transformer မော်ဒယ်၏ အဓိကကိုယ်ထည် (body) အပေါ်တွင် ထည့်သွင်းထားသော အပိုအစိတ်အပိုင်း (layer တစ်ခု သို့မဟုတ် နှစ်ခု) ဖြစ်ပြီး သီးခြားလုပ်ငန်း (task) တစ်ခုအတွက် မော်ဒယ်၏ output များကို ချိန်ညှိပေးသည်။
- Legal Contracts: ဥပဒေရေးရာ စာချုပ်များ။
- Scientific Articles: သိပ္ပံနည်းကျ ဆောင်းပါးများ။
- Vanilla Transformer Model: အထူးပြုပြင်မွမ်းမံမှုများမရှိသော အခြေခံ Transformer model။
- BERT (Bidirectional Encoder Representations from Transformers): Google မှ တီထွင်ခဲ့သော Transformer-based language model တစ်ခု။
- Domain-specific Words: သီးခြားနယ်ပယ်တစ်ခုအတွက်သာ အဓိပ္ပာယ်ရှိသော စကားလုံးများ။
- Rare Tokens: မကြာခဏမပေါ်ပေါက်သော tokens များ။
- In-domain Data: Model ကို အသုံးပြုမည့် အဓိကနယ်ပယ်နှင့် သက်ဆိုင်သော data။
- Domain Adaptation: Pretrained model တစ်ခုကို သီးခြား domain တစ်ခုရှိ data များနှင့် လိုက်လျောညီထွေဖြစ်အောင် ထပ်မံ fine-tune လုပ်ခြင်း။
- ULMFiT (Universal Language Model Fine-tuning for Text Classification): Matthew Howard နှင့် Sebastian Ruder တို့က ၂၀၁၈ ခုနှစ်တွင် တင်ပြခဲ့သော Transfer Learning နည်းလမ်းတစ်ခု။
- Neural Architectures: Artificial Neural Networks ၏ ဖွဲ့စည်းတည်ဆောက်ပုံ။
- LSTMs (Long Short-Term Memory): Recurrent Neural Networks (RNNs) ရဲ့ အထူးပြုပုံစံတစ်ခုဖြစ်ပြီး အချိန်ကြာမြင့်စွာ တည်ရှိနေတဲ့ မှတ်ဉာဏ် (long-term dependencies) တွေကို သင်ယူနိုင်စွမ်းရှိပါတယ်။
- Autocomplete: စာရိုက်နေစဉ် စကားလုံးများ သို့မဟုတ် စာကြောင်းများကို အလိုအလျောက် ဖြည့်ဆည်းပေးသည့် လုပ်ဆောင်ချက်။
[MASK]Token: Masked Language Modeling (MLM) တွင် ဝှက်ထားသော စကားလုံးကို ကိုယ်စားပြုရန် အသုံးပြုသော special token။[CLS]Token: BERT model တွင် sequence ၏ အစကို ကိုယ်စားပြုသော special token။[SEP]Token: BERT model တွင် sentence တစ်ခု၏ အဆုံး သို့မဟုတ် sentence နှစ်ခုကြား ပိုင်းခြားရန် အသုံးပြုသော special token။- Fill-Mask Filter: Hugging Face Hub တွင် masked language modeling task အတွက် models များကို ရှာဖွေရာတွင် အသုံးပြုသော filter။
- RoBERTa (Robustly Optimized BERT Pretraining Approach): BERT ကို ပိုမိုကောင်းမွန်အောင် ပြုပြင်ထားသော model တစ်ခု။
- DistilBERT: BERT ၏ သေးငယ်ပြီး ပိုမိုမြန်ဆန်သော version တစ်ခု။
- Knowledge Distillation: ကြီးမားသော “teacher model” မှ ဗဟုသုတများကို သေးငယ်သော “student model” သို့ လွှဲပြောင်းပေးသည့် training နည်းလမ်း။
- Teacher Model: Knowledge distillation တွင် အသုံးပြုသော ကြီးမားပြီး စွမ်းဆောင်ရည်မြင့်မားသော model။
- Student Model: Knowledge distillation တွင် teacher model မှ သင်ယူသော သေးငယ်ပြီး မြန်ဆန်သော model။
- Parameters: Model ၏ လုပ်ဆောင်ချက်ကို သတ်မှတ်ပေးသော အတွင်းပိုင်းတန်ဖိုးများ။
AutoModelForMaskedLMClass: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး မော်ဒယ်အမည်ကို အသုံးပြုပြီး Masked Language Modeling အတွက် သက်ဆိုင်ရာ model ကို အလိုအလျောက် load လုပ်ပေးသည်။model_checkpoint: pretrained model ၏ နာမည် (ဥပမာ- “distilbert-base-uncased”)။num_parameters()Method: model ၏ parameter အရေအတွက်ကို ပြန်ပေးသော method (PyTorch တွင်)။summary()Method: model ၏ layers များ၊ output shapes များ၊ parameter အရေအတွက်များ စသည်တို့ကို အကျဉ်းချုပ်ပြသသော method (TensorFlow/Keras တွင်)။- Statistical Patterns: ဒေတာများတွင် တွေ့ရသော မှန်မှန်ကန်ကန် ဖြစ်ပေါ်နေသော ပုံစံများ။
- English Wikipedia: အင်္ဂလိပ်ဘာသာစကားဖြင့် ရေးသားထားသော Wikipedia စွယ်စုံကျမ်း။
- BookCorpus: စာအုပ်များစွာပါဝင်သော text corpus။
AutoTokenizerClass: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး မော်ဒယ်အမည်ကို အသုံးပြုပြီး သက်ဆိုင်ရာ tokenizer ကို အလိုအလျောက် load လုပ်ပေးသည်။- Logits: Neural network ၏ output layer မှ ထုတ်ပေးသော raw, unnormalized prediction scores များ။
tokenizer()Function: tokenizer ကို အသုံးပြုပြီး text ကို input IDs အဖြစ် ပြောင်းလဲခြင်း။return_tensors="pt"/"np": PyTorch (pt) သို့မဟုတ် NumPy (np) tensors များကို ပြန်ပေးရန် သတ်မှတ်ခြင်း။- `model(inputs).logits`**: model ကို inputs များပေးပြီး logits များကို ထုတ်ယူခြင်း။
torch.where(): PyTorch tensor တစ်ခုအတွင်း အခြေအနေတစ်ခုနှင့် ကိုက်ညီသော elements များ၏ index များကို ရှာဖွေသော function။tokenizer.mask_token_id: tokenizer ၏[MASK]token ၏ ID။mask_token_index:[MASK]token ၏ index။token_logits: model မှ ထုတ်ပေးသော tokens အားလုံးအတွက် logits။mask_token_logits:[MASK]token ၏ နေရာအတွက် logits။torch.topk(): PyTorch tensor တစ်ခု၏ ထိပ်တန်း k ခုသော တန်ဖိုးများနှင့် ၎င်းတို့၏ index များကို ရယူသော function။np.argwhere(): NumPy array တစ်ခုအတွင်း အခြေအနေတစ်ခုနှင့် ကိုက်ညီသော elements များ၏ index များကို ရှာဖွေသော function။np.argsort(): NumPy array တစ်ခု၏ တန်ဖိုးများကို စီထားပြီးနောက် ၎င်းတို့၏ original index များကို ပြန်ပေးသော function။tokenizer.mask_token: tokenizer ၏[MASK]token (string ပုံစံ)။tokenizer.decode()Method: token IDs များကို မူရင်း string အဖြစ် ပြန်ပြောင်းပေးသော tokenizer method။- Large Movie Review Dataset (IMDb): ရုပ်ရှင် reviews များစွာပါဝင်သော dataset တစ်ခုဖြစ်ပြီး sentiment analysis အတွက် အသုံးပြုသည်။
- Sentiment Analysis Models: စာသားတစ်ခု၏ စိတ်ခံစားမှု (အပြုသဘော၊ အနုတ်သဘော၊ ကြားနေ) ကို ခွဲခြမ်းစိတ်ဖြာရန် လေ့ကျင့်ထားသော models။
load_dataset()Function: Hugging Face Datasets library မှ dataset များကို download လုပ်ပြီး cache လုပ်ရန် အသုံးပြုသော function။imdb_dataset: IMDb dataset ကို load လုပ်ပြီးနောက် ရရှိသောDatasetDictobject။trainsplit: Model ကို လေ့ကျင့်ရန်အတွက် အသုံးပြုသော dataset အပိုင်း။testsplit: Model ၏ နောက်ဆုံး စွမ်းဆောင်ရည်ကို တိုင်းတာရန် အသုံးပြုသော dataset အပိုင်း။unsupervisedsplit: labels မပါဝင်သော dataset အပိုင်း။Dataset.shuffle()Method: dataset အတွင်းရှိ elements များကို ကျပန်းရောနှော (shuffle) ရန် အသုံးပြုသော method။Dataset.select()Function: dataset မှ သတ်မှတ်ထားသော index များရှိ elements များကို ရွေးထုတ်ရန် အသုံးပြုသော method။seed: ကျပန်းထုတ်လုပ်ခြင်းလုပ်ငန်းစဉ်များတွင် ရလဒ်များကို reproducibility ဖြစ်စေရန် သတ်မှတ်သော တန်ဖိုး။- VHS Version: ဗီဒီယိုခွေ (Video Home System) version။
- Labels: Model ကို သင်ကြားပေးရန်အတွက် data နှင့် တွဲဖက်ထားသော အဖြေများ သို့မဟုတ် အမျိုးအစားများ။
- Sanity Check: ပရိုဂရမ် သို့မဟုတ် ဒေတာတစ်ခု မှန်ကန်စွာ အလုပ်လုပ်ခြင်းရှိမရှိ စစ်ဆေးခြင်း။
- Auto-regressive Language Modeling: စာကြောင်းတစ်ခု၏ နောက်ဆက်တွဲ token (စကားလုံး) ကို ခန့်မှန်းခြင်းဖြင့် model ကို လေ့ကျင့်သော task။
- Concatenate: အရာများစွာကို တစ်ခုတည်းအဖြစ် ပေါင်းစပ်ခြင်း။
- Truncate: စာသား သို့မဟုတ် sequence တစ်ခုကို သတ်မှတ်ထားသော အရှည်အထိ ဖြတ်တောက်ခြင်း။
tokenizer(examples["text"]):examplesdictionary မှtextkey ၏ value ကို tokenizer ဖြင့် လုပ်ဆောင်ခြင်း။tokenizer.is_fast: tokenizer သည် fast tokenizer (Rust-based) ဟုတ်မဟုတ် စစ်ဆေးသော property။result.word_ids(i):ith sequence ရှိ token တစ်ခုစီအတွက် ၎င်းတို့သက်ဆိုင်သော word ၏ ID များကို ထုတ်ပေးသော tokenizer method။batched=True:map()method မှာ အသုံးပြုသော argument တစ်ခုဖြစ်ပြီး function ကို dataset ရဲ့ element အများအပြားပေါ်မှာ တစ်ပြိုင်နက်တည်း အသုံးပြုစေသည်။remove_columns=["text", "label"]:map()method တွင် မလိုအပ်သော columns များကို ဖယ်ရှားရန် argument။input_ids: Tokenizer မှ ထုတ်ပေးသော tokens တစ်ခုစီ၏ ထူးခြားသော ဂဏန်းဆိုင်ရာ ID များ။attention_mask: မော်ဒယ်ကို အာရုံစိုက်သင့်သည့် tokens များနှင့် လျစ်လျူရှုသင့်သည့် (padding) tokens များကို ခွဲခြားပေးသည့် binary mask။word_ids: tokenizer မှ ထုတ်ပေးသော word ID များ (token တစ်ခုစီသည် မည်သည့် word နှင့် သက်ဆိုင်သည်ကို ပြသသည်)။- GPU Memory: GPU တွင် ပါဝင်သော မှတ်ဉာဏ်။
- Maximum Context Size: Model တစ်ခုက တစ်ချိန်တည်းမှာ လုပ်ဆောင်နိုင်သော tokens များ၏ အများဆုံးအရေအတွက်။
model_max_lengthAttribute: tokenizer က သတ်မှတ်ထားသော model ၏ အများဆုံး input sequence length။tokenizer_config.jsonFile: tokenizer ၏ configuration အချက်အလက်များကို သိမ်းဆည်းထားသော file။- BigBird: Google မှ တီထွင်ခဲ့သော Transformer model တစ်ခုဖြစ်ပြီး ပိုမိုရှည်လျားသော sequence များကို ကိုင်တွယ်နိုင်ရန် “sparse attention” ကို အသုံးပြုသည်။
- Longformer: AllenAI မှ တီထွင်ခဲ့သော Transformer model တစ်ခုဖြစ်ပြီး ပိုမိုရှည်လျားသော sequence များကို ကိုင်တွယ်နိုင်ရန် “dilated sliding window attention” ကို အသုံးပြုသည်။
- Contiguous Tokens: ကပ်လျက်တည်ရှိနေသော tokens များ။
- Ground Truth: Training လုပ်ငန်းစဉ်တွင် model ကို သင်ယူရန်အတွက် အသုံးပြုသော အမှန်တကယ် မှန်ကန်သော တန်ဖိုးများ သို့မဟုတ် labels များ။
- Data Collator:
DataLoaderတစ်ခုမှာ အသုံးပြုတဲ့ function တစ်ခုဖြစ်ပြီး batch တစ်ခုအတွင်း samples တွေကို စုစည်းပေးသည်။ DataCollatorForLanguageModeling: 🤗 Transformers library မှ Masked Language Modeling (MLM) အတွက် အထူးဒီဇိုင်းထုတ်ထားသော data collator။ ၎င်းသည် input tokens များကို ကျပန်း mask လုပ်ပြီး သက်ဆိုင်ရာ labels များကို ဖန်တီးပေးသည်။mlm_probabilityArgument:DataCollatorForLanguageModelingတွင် mask လုပ်မည့် tokens ရဲ့ ရာခိုင်နှုန်းကို သတ်မှတ်ရန် အသုံးပြုသော argument။- Batch: မတူညီသော input များစွာကို တစ်ပြိုင်နက်တည်း လုပ်ဆောင်နိုင်ရန် အုပ်စုဖွဲ့ခြင်း။
tokenizer.convert_ids_to_tokens()Method: input IDs များကို tokens များအဖြစ် ပြန်ပြောင်းပေးသော tokenizer method။- Deterministic: ရလဒ်များသည် အမြဲတမ်း တူညီနေခြင်း။
- Randomness: ကျပန်းဖြစ်ခြင်း။
- Freeze the Randomness: ကျပန်းထုတ်လုပ်ခြင်းကို ရပ်ဆိုင်းခြင်း သို့မဟုတ် အပြောင်းအလဲမရှိစေရန် ထိန်းချုပ်ခြင်း။
- Whole Word Masking: Masked Language Modeling (MLM) တွင် token တစ်ခုစီကို mask လုပ်မည့်အစား စကားလုံးတစ်လုံးလုံးကို mask လုပ်သော နည်းလမ်း။
collections.defaultdict(list): dictionary တစ်ခုဖြစ်ပြီး key မရှိသေးပါက default value အဖြစ် empty list တစ်ခုကို ဖန်တီးပေးသည်။np.random.binomial(1, wwm_probability, (len(mapping),)): binomial distribution ကို အသုံးပြုပြီး mask လုပ်မည့် word များကို ကျပန်းရွေးချယ်ရန် NumPy function။np.where(mask)[0]:maskarray ထဲကTrueဖြစ်တဲ့ (mask လုပ်ခံရမယ့်) နေရာတွေရဲ့ index တွေကို ပြန်ပေးသော NumPy function။feature["input_ids"][idx] = tokenizer.mask_token_id: သတ်မှတ်ထားသော index ရှိ input ID ကို[MASK]token ၏ ID ဖြင့် အစားထိုးခြင်း။new_labels[idx] = labels[idx]: mask လုပ်ခံရသော token အတွက် label ကို မူရင်း label ဖြင့် ထားရှိခြင်း (မ mask လုပ်ခံရသော tokens များအတွက်-100ဖြစ်သည်)။-100: language modeling task များတွင် ignore လုပ်ရမည့် labels များကို ကိုယ်စားပြုသော တန်ဖိုး (PyTorch တွင်)။default_data_collator: 🤗 Transformers library မှ ပံ့ပိုးပေးသော default data collator။- P100 GPU: NVIDIA Tesla P100 ကဲ့သို့ အစွမ်းထက်သော GPU။
- Downsample: dataset ၏ အရွယ်အစားကို လျှော့ချခြင်း။
Dataset.train_test_split()Function: 🤗 Datasets library မှ dataset ကို training set နှင့် test set အဖြစ် ပိုင်းခြားရန် အသုံးပြုသော function။train_size: training set အတွက် examples အရေအတွက်။test_size: test set အတွက် examples အရေအတွက်။- Validation Set: Training လုပ်နေစဉ် model ၏ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန် အသုံးပြုသော dataset အပိုင်း။
- Beefy GPU: စွမ်းဆောင်ရည်မြင့်မားသော GPU။
notebook_login()Utility Function: Jupyter/Colab Notebooks များတွင် Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော function။- Credentials: အကောင့်ဝင်ရန် လိုအပ်သော အချက်အလက်များ (ဥပမာ- username, password, token)။
huggingface-cli login: Hugging Face CLI (Command Line Interface) မှ Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော command။tf.dataDatasets: TensorFlow framework တွင် efficient data pipelines များကို တည်ဆောက်ရန် အသုံးပြုသော dataset format။prepare_tf_dataset()Method: model ၏ input format နှင့် ကိုက်ညီသောtf.data.Datasetကို ဖန်တီးရန်AutoModelclass တွင်ပါဝင်သော method။Dataset.to_tf_dataset()Method: 🤗 Datasets library မှ dataset ကိုtf.data.Datasetအဖြစ် ပြောင်းလဲရန် method။collate_fnArgument:DataLoaderသို့မဟုတ်prepare_tf_dataset()တွင် batch တစ်ခုကို စုစည်းရန် အသုံးပြုသော function။shuffle=True: dataset ကို training မလုပ်ခင် shuffle လုပ်ရန် သတ်မှတ်ခြင်း။batch_size: training လုပ်ငန်းစဉ်တစ်ခုစီတွင် model သို့ ပေးပို့သော input samples အရေအတွက်။- Training Hyperparameters: Training လုပ်ငန်းစဉ်၏ behavior ကို ထိန်းချုပ်သော parameters များ (ဥပမာ- learning rate, batch size)။
- Compile Model: TensorFlow/Keras တွင် model ကို training အတွက် ပြင်ဆင်ခြင်း (optimizer, loss function, metrics သတ်မှတ်ခြင်း)။
create_optimizer()Function: 🤗 Transformers library မှAdamWoptimizer နှင့် learning rate scheduler ကို ဖန်တီးသော function။AdamWOptimizer: Adam optimizer ၏ weight decay ကို ပြုပြင်ထားသော version။- Linear Learning Rate Decay: Training လုပ်ငန်းစဉ်တစ်လျှောက် learning rate ကို ဖြည်းဖြည်းချင်း လျှော့ချသော နည်းလမ်း။
init_lr: အစောပိုင်း learning rate။num_warmup_steps: learning rate ကို ဖြည်းဖြည်းချင်း မြှင့်တင်ရန် steps အရေအတွက်။num_train_steps: training steps စုစုပေါင်းအရေအတွက်။weight_decay_rate: weight decay (regularization) ၏ ပမာဏ။- Built-in Loss: Model ၏ internal loss function။
- Training Precision: Training လုပ်ရာတွင် အသုံးပြုသော floating point precision (ဥပမာ-
float32,mixed_float16)။ mixed_float16: Training လုပ်ရာတွင်float16နှင့်float32ကို ပေါင်းစပ်အသုံးပြုခြင်းဖြင့် memory အသုံးပြုမှုကို လျှော့ချပြီး speed ကို မြှင့်တင်ခြင်း။- Accelerated Float16 Support: GPU ဟာ float16 precision နဲ့ computation တွေကို မြန်မြန်ဆန်ဆန် လုပ်ဆောင်နိုင်ခြင်း။
PushToHubCallback: TensorFlow/Keras မှာ model ကို Hugging Face Hub ကို push လုပ်ရန်အတွက် callback။hub_model_idArgument:TrainingArgumentsသို့မဟုတ်PushToHubCallbackတွင် model ကို push လုပ်မည့် Hugging Face Hub repository ၏ ID ကို သတ်မှတ်ရန် argument။- Organization: Hugging Face Hub တွင် models များကို မျှဝေရန် အသုံးပြုနိုင်သော အဖွဲ့အစည်းအကောင့်။
- Namespace: Hugging Face Hub တွင် အသုံးပြုသူအမည် သို့မဟုတ် organization အမည်။
- Output Directory: training results များကို သိမ်းဆည်းမည့် directory။
model.fit()Method: TensorFlow/Keras တွင် model ကို train လုပ်ရန် method။validation_data:model.fit()တွင် validation set ကို ပေးပို့ရန် argument။callbacks: Training လုပ်ငန်းစဉ်အတွင်း သတ်မှတ်ထားသော အချိန်များတွင် run နိုင်သော functions များ။- Perplexity: Language model တစ်ခု၏ စွမ်းဆောင်ရည်ကို တိုင်းတာသော metric တစ်ခု။ နိမ့်လေ ကောင်းလေ။
- Cross-entropy Loss: Classification tasks များတွင် အသုံးပြုသော common loss function တစ်ခု။
- Exponential: သင်္ချာ function
exp(x)သို့မဟုတ်e^x။ Trainer.evaluate()Function: Hugging Face Trainer တွင် model ကို evaluation set ပေါ်တွင် အကဲဖြတ်ရန် method။math.exp()Function: Python ၏mathmodule မှ exponential function။eval_results['eval_loss']: evaluation loss တန်ဖိုး။trainer.train(): Hugging Face Trainer ဖြင့် model ကို train လုပ်ရန် method။Trainer.push_to_hub(): training ပြီးနောက် model card နှင့် checkpoints များကို Hub သို့ push လုပ်ရန် method။- Autoregressive Model: အနာဂတ် tokens များကို ယခင် tokens များကို အခြေခံ၍ ခန့်မှန်းသော model အမျိုးအစား (ဥပမာ- GPT-2)။
- GPT-2 (Generative Pre-trained Transformer 2): OpenAI မှ ထုတ်လုပ်သော autoregressive language model တစ်ခု။
- Classifier: ဒေတာအချက်အလက်များကို သတ်မှတ်ထားသော အမျိုးအစားများ သို့မဟုတ် အတန်းများထဲသို့ ခွဲခြားသတ်မှတ်သော model။
- Text Classification: စာသားကို သတ်မှတ်ထားသော အမျိုးအစားများထဲသို့ ခွဲခြားသတ်မှတ်ခြင်းနှင့် သက်ဆိုင်သော ပြဿနာ။
- Custom Logic: စံလုပ်ဆောင်မှုများထက် ကျော်လွန်သော ကိုယ်ပိုင်ရေးသားထားသည့် လုပ်ဆောင်ချက်များ။
insert_random_mask()Function: batch တစ်ခုအတွင်း tokens များကို ကျပန်း mask လုပ်ရန် ကိုယ်တိုင်ရေးသားထားသော function။zip(*batch.values()): dictionary ၏ values များကို unzipping လုပ်ပြီး ၎င်းတို့၏ elements များကို pair လုပ်ခြင်း။dict(zip(batch, t)):batchdictionary ၏ keys များကိုtရှိ values များနှင့် pair လုပ်ခြင်းဖြင့် dictionary အသစ်တစ်ခု ဖန်တီးခြင်း။v.numpy(): PyTorch tensor ကို NumPy array အဖြစ် ပြောင်းလဲခြင်း။Dataset.remove_columns(): dataset မှ columns များကို ဖယ်ရှားရန် method။downsampled_dataset["test"].column_names: dataset ၏ test split တွင်ရှိသော columns များ၏ နာမည်များ။Dataset.rename_columns(): dataset ရှိ columns များကို အမည်ပြောင်းရန် method။- Dataloaders: dataset မှ data များကို batch အလိုက် load လုပ်ပေးသော utility (PyTorch တွင်
DataLoader, TensorFlow တွင်tf.data.Dataset)။ torch.utils.data.DataLoader: PyTorch တွင် dataset မှ data များကို batch အလိုက် load လုပ်ပေးသော class။shuffle=True:DataLoaderတွင် data ကို shuffle လုပ်ရန် သတ်မှတ်ခြင်း။collate_fn:DataLoaderတွင် batch တစ်ခုကို စုစည်းရန် အသုံးပြုသော function။AcceleratorObject: 🤗 Accelerate library မှ distributed training, mixed-precision training စသည်တို့ကို လွယ်ကူစေရန် အသုံးပြုသော object။AdamW: PyTorch မှာ အသုံးပြုတဲ့ AdamW optimizer။ Model ၏ parameters များကို training လုပ်ရာမှာ အသုံးပြုသည်။model.parameters(): model ၏ လေ့ကျင့်နိုင်သော parameters (weights နှင့် biases) များကို ပြန်ပေးသော method။lr: learning rate။accelerator.prepare(): model, optimizer, dataloaders များကို distributed training အတွက် ပြင်ဆင်ရန်Acceleratormethod။- Learning Rate Scheduler: training လုပ်နေစဉ်အတွင်း learning rate ကို အချိန်နှင့်အမျှ ပြောင်းလဲရန် အသုံးပြုသော function။
get_scheduler()Function: 🤗 Transformers library မှ learning rate scheduler ကို ဖန်တီးသော function။"linear"(Scheduler Type): learning rate ကို linear နည်းဖြင့် လျှော့ချသော scheduler အမျိုးအစား။num_warmup_steps: learning rate ကို ဖြည်းဖြည်းချင်း မြှင့်တင်ရန် steps အရေအတွက်။num_training_steps: training steps စုစုပေါင်းအရေအတွက်။- Model Repository: Hugging Face Hub တွင် model files များကို သိမ်းဆည်းထားသော နေရာ။
get_full_repo_name()Function: Hugging Face Hub library မှ repository ၏ နာမည်အပြည့်အစုံကို ရယူသော function။RepositoryClass:huggingface_hublibrary မှ Git repository များကို ကိုင်တွယ်ရန်အတွက် class။output_dir: training results များကို သိမ်းဆည်းမည့် directory။clone_from: repository ကို clone လုပ်ရန်အတွက် remote repository ၏ URL သို့မဟုတ် နာမည်။tqdm.auto.tqdm: Python loop များကို progress bar ဖြင့် ပြသရန် library။progress_bar: training progress ကို ပြသသော progress bar object။model.train(): PyTorch model ကို training mode သို့ ပြောင်းလဲခြင်း။- `model(batch)`**: PyTorch model ကို input batch ပေးပြီး output ရယူခြင်း။
outputs.loss: model မှ ထုတ်ပေးသော loss တန်ဖိုး။accelerator.backward(loss): distributed training တွင် loss ကို backpropagate လုပ်ရန်Acceleratormethod။optimizer.step(): တွက်ချက်ထားသော gradients များကို အသုံးပြုပြီး model ၏ parameters များကို update လုပ်သော optimizer method။lr_scheduler.step(): learning rate scheduler ၏ learning rate ကို update လုပ်ရန် method။optimizer.zero_grad(): gradients များကို zero သို့ ပြန်လည်သတ်မှတ်ခြင်း။progress_bar.update(1): progress bar ကို 1 step တိုးမြှင့်ခြင်း။model.eval(): PyTorch model ကို evaluation mode သို့ ပြောင်းလဲခြင်း။torch.no_grad(): PyTorch တွင် gradient computation ကို disable လုပ်ရန် context manager (evaluation လုပ်နေစဉ် အသုံးပြုသည်)။accelerator.gather(): distributed training တွင် processes များစွာမှ tensors များကို စုစည်းရန်Acceleratormethod။loss.repeat(batch_size): loss တန်ဖိုးကိုbatch_sizeအကြိမ် ထပ်ခါတလဲလဲ ပြုလုပ်ခြင်း။torch.cat(): PyTorch တွင် tensors များကို ပေါင်းစပ်ခြင်း။torch.mean(): PyTorch tensor ၏ mean (ပျမ်းမျှ) ကို တွက်ချက်ခြင်း။float("inf"): သင်္ချာဆိုင်ရာ infinity တန်ဖိုး။accelerator.wait_for_everyone(): distributed training တွင် processes အားလုံး အလုပ်ပြီးဆုံးရန် စောင့်ဆိုင်းခြင်း။accelerator.unwrap_model(model): distributed training အတွက် wrap လုပ်ထားသော model ကို မူရင်း model အဖြစ် ပြန်လည်ထုတ်ယူခြင်း။unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save): model ကို output directory တွင် save လုပ်ရန် method။accelerator.is_main_process: လက်ရှိ process သည် distributed training ၏ main process ဟုတ်မဟုတ် စစ်ဆေးသော property။tokenizer.save_pretrained(output_dir): tokenizer ကို output directory တွင် save လုပ်ရန် method။repo.push_to_hub(commit_message=..., blocking=False): repository ကို Hugging Face Hub သို့ push လုပ်ရန် method။blocking=Falseဆိုသည်မှာ push လုပ်ငန်းစဉ် ပြီးဆုံးရန် စောင့်ဆိုင်းမည်မဟုတ်ပါ။- Widget: Hugging Face Hub ပေါ်ရှိ model demo ကို အပြန်အလှန်ဆက်သွယ်နိုင်သော အစိတ်အပိုင်း။
pipeline()Function: Hugging Face Transformers library မှာ ပါဝင်တဲ့ လုပ်ဆောင်ချက်တစ်ခုဖြစ်ပြီး မော်ဒယ်တွေကို သီးခြားလုပ်ငန်းတာဝန်များ (ဥပမာ- စာသားခွဲခြားသတ်မှတ်ခြင်း၊ စာသားထုတ်လုပ်ခြင်း) အတွက် အသုံးပြုရလွယ်ကူအောင် ပြုလုပ်ပေးပါတယ်။- Classifier: ဒေတာအချက်အလက်များကို သတ်မှတ်ထားသော အမျိုးအစားများ သို့မဟုတ် အတန်းများထဲသို့ ခွဲခြားသတ်မှတ်သော model။
- Quantify: အတိုင်းအတာတစ်ခုဖြင့် တန်ဖိုးဖြတ်ခြင်း။