
license: apache-2.0
task_categories:
- multiple-choice
- question-answering
- visual-question-answering
language:
- en
size_categories:
- 100B<n<1T
MME-RealWorld Data Card
Dataset details
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
- small data scale leading to large performance variance;
- reliance on model-based annotations, resulting in significant model bias;
- restricted data sources, often overlapping with existing benchmarks and posing a risk of data leakage;
- insufficient task difficulty and discrimination, especially the limited image resolution.
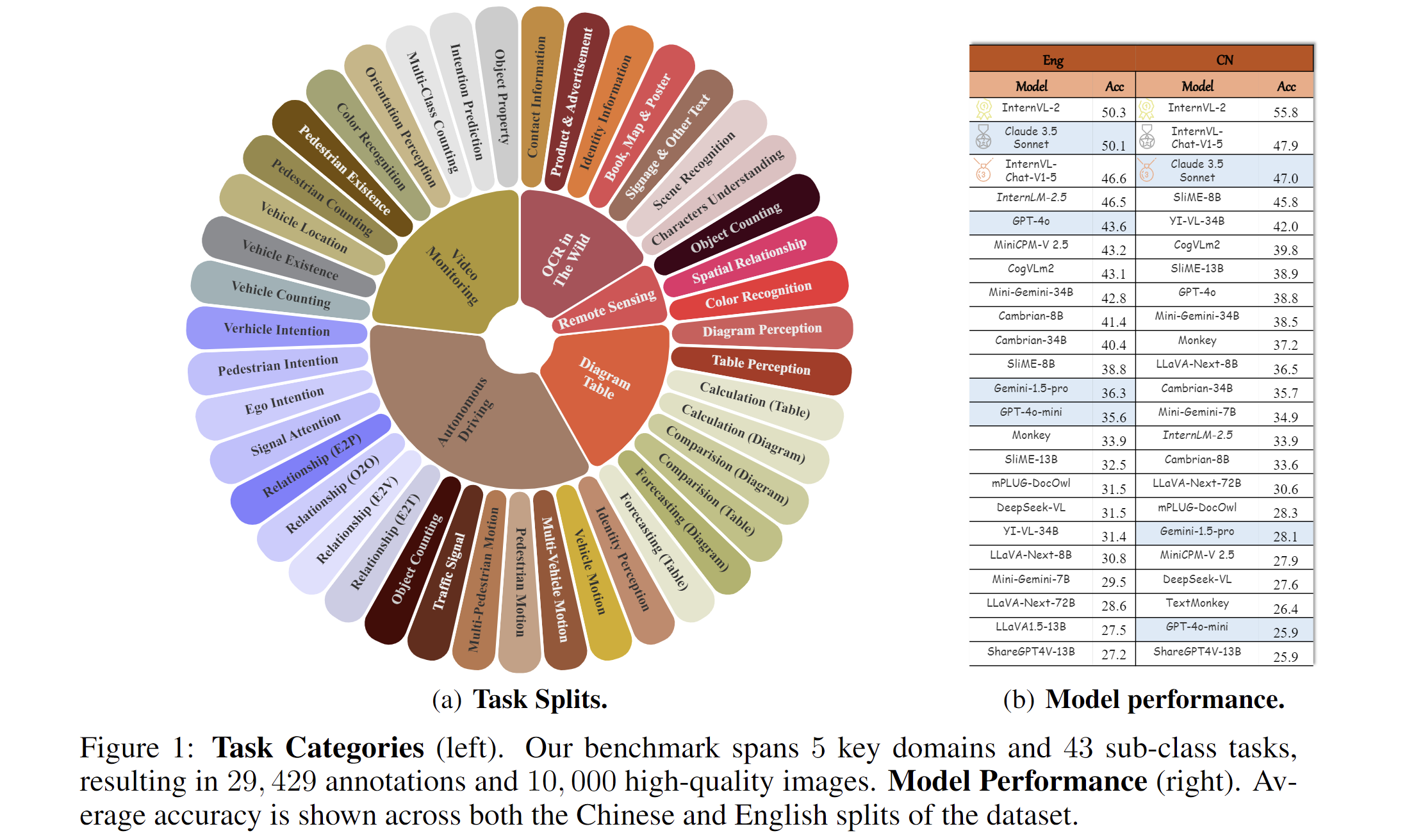
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 1,734 × 1,734 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
Scale, Diversity, and Real-World Utility: MME-RealWord is the largest fully human-annotated MLLM benchmark, covering 6 domains and 14 sub-classes, closely tied to real-world tasks.
Quality: The dataset features high-resolution images with crucial details and manual annotations verified by experts to ensure top-notch data quality.
Safety: MME-RealWord avoids data overlap with other benchmarks and relies solely on human annotations, eliminating model biases and personal bias.
Difficulty and Distinguishability: The dataset poses significant challenges, with models struggling to achieve even 55% accuracy in basic tasks, clearly distinguishing between different MLLMs.
MME-RealWord-CN: The dataset includes a specialized Chinese benchmark with images and questions tailored to Chinese contexts, overcoming issues in existing translated benchmarks.
How to use?
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
#!/bin/bash
# Navigate to the directory containing the split files
cd TARFILES
# Loop through each set of split files
for part in *.tar.gz.part_aa; do
# Extract the base name of the file
base_name=$(basename "$part" .tar.gz.part_aa)
# Merge the split files into a single archive
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
# Extract the merged archive
tar -xzf "${base_name}.tar.gz"
# Optional: Remove the temporary merged archive
rm "${base_name}.tar.gz"
done