Datasets:

Tasks:
Visual Question Answering
Formats:
parquet
Languages:
English
Size:
1M - 10M
ArXiv:
DOI:
License:

Update README.md
Browse files
README.md
CHANGED
|
@@ -15,10 +15,10 @@ dataset_info:
|
|
| 15 |
sequence: string
|
| 16 |
splits:
|
| 17 |
- name: test
|
| 18 |
-
num_bytes: 897447182
|
| 19 |
num_examples: 5000
|
| 20 |
- name: validation
|
| 21 |
-
num_bytes: 903394782
|
| 22 |
num_examples: 5000
|
| 23 |
- name: train
|
| 24 |
num_bytes: 378131774488.5
|
|
@@ -34,4 +34,131 @@ configs:
|
|
| 34 |
path: data/validation-*
|
| 35 |
- split: train
|
| 36 |
path: data/train-*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
sequence: string
|
| 16 |
splits:
|
| 17 |
- name: test
|
| 18 |
+
num_bytes: 897447182
|
| 19 |
num_examples: 5000
|
| 20 |
- name: validation
|
| 21 |
+
num_bytes: 903394782
|
| 22 |
num_examples: 5000
|
| 23 |
- name: train
|
| 24 |
num_bytes: 378131774488.5
|
|
|
|
| 34 |
path: data/validation-*
|
| 35 |
- split: train
|
| 36 |
path: data/train-*
|
| 37 |
+
license: cc-by-sa-4.0
|
| 38 |
+
source_datasets:
|
| 39 |
+
- wikimedia/wit_base
|
| 40 |
+
task_categories:
|
| 41 |
+
- visual-question-answering
|
| 42 |
+
language:
|
| 43 |
+
- en
|
| 44 |
+
pretty_name: VCR
|
| 45 |
+
arxiv: 2406.06462
|
| 46 |
+
size_categories:
|
| 47 |
+
- 1M<n<10M
|
| 48 |
---
|
| 49 |
+
# The VCR-Wiki Dataset for Visual Caption Restoration (VCR)
|
| 50 |
+
|
| 51 |
+
🏠 [Paper](https://arxiv.org/abs/2406.06462) | 👩🏻💻 [GitHub](https://github.com/tianyu-z/vcr) | 🤗 [Huggingface Datasets](https://huggingface.co/vcr-org) | 📏 [Evaluation with lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval)
|
| 52 |
+
|
| 53 |
+
This is the official Hugging Face dataset for VCR-Wiki, a dataset for the [Visual Caption Restoration (VCR)](https://arxiv.org/abs/2406.06462) task.
|
| 54 |
+
|
| 55 |
+
VCR is designed to measure vision-language models' capability to accurately restore partially obscured texts using pixel-level hints within images. text-based processing becomes ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts.
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
We found that OCR and text-based processing become ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts. We develop a pipeline to generate synthetic images for the VCR task using image-caption pairs, with adjustable caption visibility to control the task difficulty. However, this task is generally easy for native speakers of the corresponding language. Initial results indicate that current vision-language models fall short compared to human performance on this task.
|
| 60 |
+
|
| 61 |
+
## Dataset Description
|
| 62 |
+
|
| 63 |
+
- **GitHub:** [VCR GitHub](https://github.com/tianyu-z/vcr)
|
| 64 |
+
- **Paper:** [VCR: Visual Caption Restoration](https://arxiv.org/abs/2406.06462)
|
| 65 |
+
- **Point of Contact:** [Tianyu Zhang](mailto:tianyu.zhang@mila.quebec)
|
| 66 |
+
|
| 67 |
+
## Evaluation
|
| 68 |
+
|
| 69 |
+
We recommend you to evaluate your model with [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval). Before evaluating, please refer to the doc of `lmms-eval`.
|
| 70 |
+
|
| 71 |
+
```console
|
| 72 |
+
pip install git+https://github.com/EvolvingLMMs-Lab/lmms-eval.git
|
| 73 |
+
|
| 74 |
+
# We use MiniCPM-Llama3-V-2_5 and vcr_wiki_en_easy as an example
|
| 75 |
+
python3 -m accelerate.commands.launch \
|
| 76 |
+
--num_processes=8 \
|
| 77 |
+
-m lmms_eval \
|
| 78 |
+
--model minicpm_v \
|
| 79 |
+
--model_args pretrained="openbmb/MiniCPM-Llama3-V-2_5" \
|
| 80 |
+
--tasks vcr_wiki_en_easy \
|
| 81 |
+
--batch_size 1 \
|
| 82 |
+
--log_samples \
|
| 83 |
+
--log_samples_suffix MiniCPM-Llama3-V-2_5_vcr_wiki_en_easy \
|
| 84 |
+
--output_path ./logs/
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
`lmms-eval` supports the following VCR `--tasks` settings:
|
| 88 |
+
|
| 89 |
+
* English
|
| 90 |
+
* Easy
|
| 91 |
+
* `vcr_wiki_en_easy` (full test set, 5000 instances)
|
| 92 |
+
* `vcr_wiki_en_easy_500` (first 500 instances in the vcr_wiki_en_easy setting)
|
| 93 |
+
* `vcr_wiki_en_easy_100` (first 100 instances in the vcr_wiki_en_easy setting)
|
| 94 |
+
* Hard
|
| 95 |
+
* `vcr_wiki_en_hard` (full test set, 5000 instances)
|
| 96 |
+
* `vcr_wiki_en_hard_500` (first 500 instances in the vcr_wiki_en_hard setting)
|
| 97 |
+
* `vcr_wiki_en_hard_100` (first 100 instances in the vcr_wiki_en_hard setting)
|
| 98 |
+
* Chinese
|
| 99 |
+
* Easy
|
| 100 |
+
* `vcr_wiki_zh_easy` (full test set, 5000 instances)
|
| 101 |
+
* `vcr_wiki_zh_easy_500` (first 500 instances in the vcr_wiki_zh_easy setting)
|
| 102 |
+
* `vcr_wiki_zh_easy_100` (first 100 instances in the vcr_wiki_zh_easy setting)
|
| 103 |
+
* Hard
|
| 104 |
+
* `vcr_wiki_zh_hard` (full test set, 5000 instances)
|
| 105 |
+
* `vcr_wiki_zh_hard_500` (first 500 instances in the vcr_wiki_zh_hard setting)
|
| 106 |
+
* `vcr_wiki_zh_hard_100` (first 100 instances in the vcr_wiki_zh_hard setting)
|
| 107 |
+
|
| 108 |
+
## Dataset Statistics
|
| 109 |
+
|
| 110 |
+
We show the statistics of the original VCR-Wiki dataset below:
|
| 111 |
+
|
| 112 |
+

|
| 113 |
+
|
| 114 |
+
## Dataset Construction
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
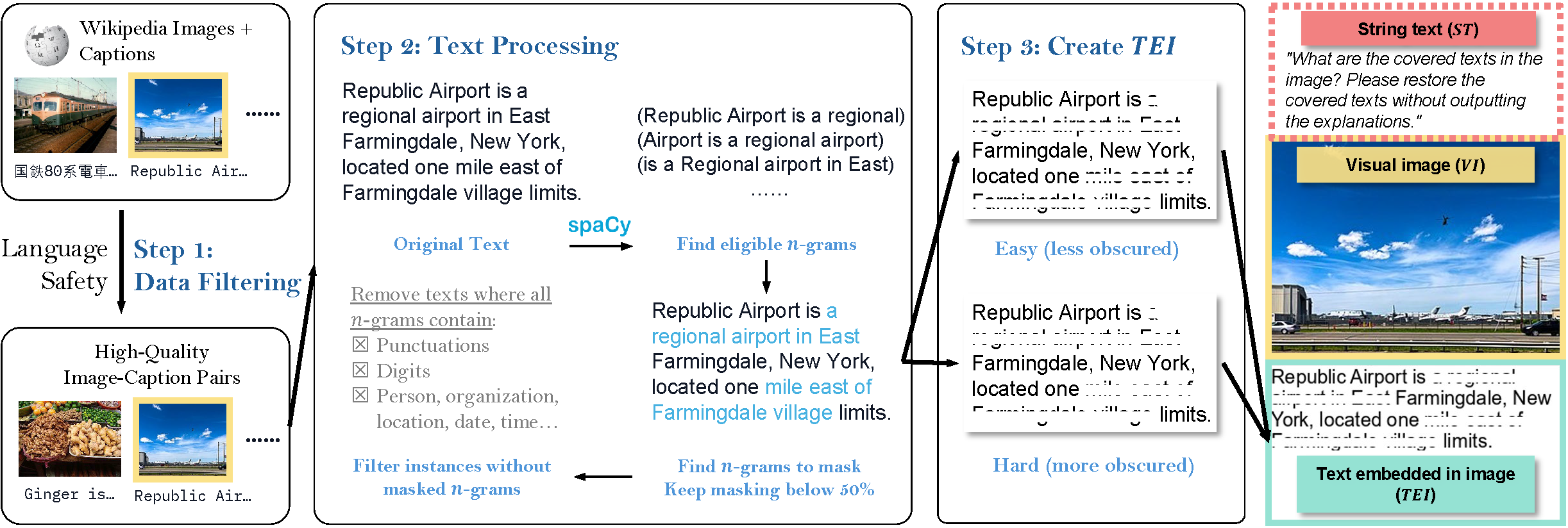
* **Data Collection and Initial Filtering**: The original data is collected from [wikimedia/wit_base](https://huggingface.co/datasets/wikimedia/wit_base). Before constructing the dataset, we first filter out the instances with sensitive content, including NSFW and crime-related terms, to mitigate AI risk and biases.
|
| 119 |
+
|
| 120 |
+
* **N-gram selection**: We first truncate the description of each entry to be less than 5 lines with our predefined font and size settings. We then tokenize the description for each entry with spaCy and randomly mask out 5-grams, where the masked 5-grams do not contain numbers, person names, religious or political groups, facilities, organizations, locations, dates and time labeled by spaCy, and the total masked token does not exceed 50\% of the tokens in the caption.
|
| 121 |
+
|
| 122 |
+
* **Create text embedded in images**: We create text embedded in images (TEI) for the description, resize its width to 300 pixels, and mask out the selected 5-grams with white rectangles. The size of the rectangle reflects the difficulty of the task: (1) in easy versions, the task is easy for native speakers but open-source OCR models almost always fail, and (2) in hard versions, the revealed part consists of only one to two pixels for the majority of letters or characters, yet the restoration task remains feasible for native speakers of the language.
|
| 123 |
+
|
| 124 |
+
* **Concatenate Images**: We concatenate TEI with the main visual image (VI) to get the stacked image.
|
| 125 |
+
|
| 126 |
+
* **Second-round Filtering**: We filter out all entries with no masked n-grams or have a height exceeding 900 pixels.
|
| 127 |
+
|
| 128 |
+
## Data Fields
|
| 129 |
+
|
| 130 |
+
* `question_id`: `int64`, the instance id in the current split.
|
| 131 |
+
* `image`: `PIL.Image.Image`, the original visual image (VI).
|
| 132 |
+
* `stacked_image`: `PIL.Image.Image`, the stacked VI+TEI image containing both the original visual image and the masked text embedded in image.
|
| 133 |
+
* `only_id_image`: `PIL.Image.Image`, the masked TEI image.
|
| 134 |
+
* `caption`: `str`, the unmasked original text presented in the TEI image.
|
| 135 |
+
* `crossed_text`: `List[str]`, the masked n-grams in the current instance.
|
| 136 |
+
|
| 137 |
+
## Disclaimer for the VCR-Wiki dataset and Its Subsets
|
| 138 |
+
|
| 139 |
+
The VCR-Wiki dataset and/or its subsets are provided under the Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) license. This dataset is intended solely for research and educational purposes in the field of visual caption restoration and related vision-language tasks.
|
| 140 |
+
|
| 141 |
+
Important Considerations:
|
| 142 |
+
|
| 143 |
+
1. **Accuracy and Reliability**: While the VCR-Wiki dataset has undergone filtering to exclude sensitive content, it may still contain inaccuracies or unintended biases. Users are encouraged to critically evaluate the dataset's content and applicability to their specific research objectives.
|
| 144 |
+
|
| 145 |
+
2. **Ethical Use**: Users must ensure that their use of the VCR-Wiki dataset aligns with ethical guidelines and standards, particularly in avoiding harm, perpetuating biases, or misusing the data in ways that could negatively impact individuals or groups.
|
| 146 |
+
|
| 147 |
+
3. **Modifications and Derivatives**: Any modifications or derivative works based on the VCR-Wiki dataset must be shared under the same license (CC BY-SA 4.0).
|
| 148 |
+
|
| 149 |
+
4. **Commercial Use**: Commercial use of the VCR-Wiki dataset is permitted under the CC BY-SA 4.0 license, provided that proper attribution is given and any derivative works are shared under the same license.
|
| 150 |
+
|
| 151 |
+
By using the VCR-Wiki dataset and/or its subsets, you agree to the terms and conditions outlined in this disclaimer and the associated license. The creators of the dataset are not liable for any direct or indirect damages resulting from its use.
|
| 152 |
+
|
| 153 |
+
## Citation
|
| 154 |
+
|
| 155 |
+
If you find VCR useful for your research and applications, please cite using this BibTeX:
|
| 156 |
+
|
| 157 |
+
```bibtex
|
| 158 |
+
@article{zhang2024vcr,
|
| 159 |
+
title = {VCR: Visual Caption Restoration},
|
| 160 |
+
author = {Tianyu Zhang and Suyuchen Wang and Lu Li and Ge Zhang and Perouz Taslakian and Sai Rajeswar and Jie Fu and Bang Liu and Yoshua Bengio},
|
| 161 |
+
year = {2024},
|
| 162 |
+
journal = {arXiv preprint arXiv: 2406.06462}
|
| 163 |
+
}
|
| 164 |
+
```
|