

421f803355974a702f7603a70074546b87af62b9a352b2c06bd834024cd5af7b
Browse files- langchain_md_files/integrations/providers/dingo.mdx +31 -0
- langchain_md_files/integrations/providers/discord.mdx +38 -0
- langchain_md_files/integrations/providers/docarray.mdx +37 -0
- langchain_md_files/integrations/providers/doctran.mdx +37 -0
- langchain_md_files/integrations/providers/docugami.mdx +21 -0
- langchain_md_files/integrations/providers/docusaurus.mdx +20 -0
- langchain_md_files/integrations/providers/dria.mdx +25 -0
- langchain_md_files/integrations/providers/dropbox.mdx +21 -0
- langchain_md_files/integrations/providers/duckdb.mdx +19 -0
- langchain_md_files/integrations/providers/duckduckgo_search.mdx +25 -0
- langchain_md_files/integrations/providers/e2b.mdx +20 -0
- langchain_md_files/integrations/providers/edenai.mdx +62 -0
- langchain_md_files/integrations/providers/elasticsearch.mdx +108 -0
- langchain_md_files/integrations/providers/elevenlabs.mdx +27 -0
- langchain_md_files/integrations/providers/epsilla.mdx +23 -0
- langchain_md_files/integrations/providers/etherscan.mdx +18 -0
- langchain_md_files/integrations/providers/evernote.mdx +20 -0
- langchain_md_files/integrations/providers/facebook.mdx +93 -0
- langchain_md_files/integrations/providers/fauna.mdx +25 -0
- langchain_md_files/integrations/providers/figma.mdx +21 -0
- langchain_md_files/integrations/providers/flyte.mdx +153 -0
- langchain_md_files/integrations/providers/forefrontai.mdx +16 -0
- langchain_md_files/integrations/providers/geopandas.mdx +23 -0
- langchain_md_files/integrations/providers/git.mdx +19 -0
- langchain_md_files/integrations/providers/gitbook.mdx +15 -0
- langchain_md_files/integrations/providers/github.mdx +22 -0
- langchain_md_files/integrations/providers/golden.mdx +34 -0
- langchain_md_files/integrations/providers/google_serper.mdx +74 -0
- langchain_md_files/integrations/providers/gooseai.mdx +23 -0
- langchain_md_files/integrations/providers/gpt4all.mdx +55 -0
- langchain_md_files/integrations/providers/gradient.mdx +27 -0
- langchain_md_files/integrations/providers/graphsignal.mdx +44 -0
- langchain_md_files/integrations/providers/grobid.mdx +46 -0
- langchain_md_files/integrations/providers/groq.mdx +28 -0
- langchain_md_files/integrations/providers/gutenberg.mdx +15 -0
- langchain_md_files/integrations/providers/hacker_news.mdx +18 -0
- langchain_md_files/integrations/providers/hazy_research.mdx +19 -0
- langchain_md_files/integrations/providers/helicone.mdx +53 -0
- langchain_md_files/integrations/providers/hologres.mdx +23 -0
- langchain_md_files/integrations/providers/html2text.mdx +19 -0
- langchain_md_files/integrations/providers/huawei.mdx +37 -0
- langchain_md_files/integrations/providers/ibm.mdx +59 -0
- langchain_md_files/integrations/providers/ieit_systems.mdx +31 -0
- langchain_md_files/integrations/providers/ifixit.mdx +16 -0
- langchain_md_files/integrations/providers/iflytek.mdx +38 -0
- langchain_md_files/integrations/providers/imsdb.mdx +16 -0
- langchain_md_files/integrations/providers/infinispanvs.mdx +17 -0
- langchain_md_files/integrations/providers/infinity.mdx +11 -0
- langchain_md_files/integrations/providers/infino.mdx +35 -0
- langchain_md_files/integrations/providers/intel.mdx +108 -0
langchain_md_files/integrations/providers/dingo.mdx
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DingoDB
|
| 2 |
+
|
| 3 |
+
>[DingoDB](https://github.com/dingodb) is a distributed multi-modal vector
|
| 4 |
+
> database. It combines the features of a data lake and a vector database,
|
| 5 |
+
> allowing for the storage of any type of data (key-value, PDF, audio,
|
| 6 |
+
> video, etc.) regardless of its size. Utilizing DingoDB, you can construct
|
| 7 |
+
> your own Vector Ocean (the next-generation data architecture following data
|
| 8 |
+
> warehouse and data lake). This enables
|
| 9 |
+
> the analysis of both structured and unstructured data through
|
| 10 |
+
> a singular SQL with exceptionally low latency in real time.
|
| 11 |
+
|
| 12 |
+
## Installation and Setup
|
| 13 |
+
|
| 14 |
+
Install the Python SDK
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
pip install dingodb
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
## VectorStore
|
| 21 |
+
|
| 22 |
+
There exists a wrapper around DingoDB indexes, allowing you to use it as a vectorstore,
|
| 23 |
+
whether for semantic search or example selection.
|
| 24 |
+
|
| 25 |
+
To import this vectorstore:
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from langchain_community.vectorstores import Dingo
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
For a more detailed walkthrough of the DingoDB wrapper, see [this notebook](/docs/integrations/vectorstores/dingo)
|
langchain_md_files/integrations/providers/discord.mdx
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Discord
|
| 2 |
+
|
| 3 |
+
>[Discord](https://discord.com/) is a VoIP and instant messaging social platform. Users have the ability to communicate
|
| 4 |
+
> with voice calls, video calls, text messaging, media and files in private chats or as part of communities called
|
| 5 |
+
> "servers". A server is a collection of persistent chat rooms and voice channels which can be accessed via invite links.
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install pandas
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
Follow these steps to download your `Discord` data:
|
| 14 |
+
|
| 15 |
+
1. Go to your **User Settings**
|
| 16 |
+
2. Then go to **Privacy and Safety**
|
| 17 |
+
3. Head over to the **Request all of my Data** and click on **Request Data** button
|
| 18 |
+
|
| 19 |
+
It might take 30 days for you to receive your data. You'll receive an email at the address which is registered
|
| 20 |
+
with Discord. That email will have a download button using which you would be able to download your personal Discord data.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Document Loader
|
| 24 |
+
|
| 25 |
+
See a [usage example](/docs/integrations/document_loaders/discord).
|
| 26 |
+
|
| 27 |
+
**NOTE:** The `DiscordChatLoader` is not the `ChatLoader` but a `DocumentLoader`.
|
| 28 |
+
It is used to load the data from the `Discord` data dump.
|
| 29 |
+
For the `ChatLoader` see Chat Loader section below.
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
from langchain_community.document_loaders import DiscordChatLoader
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
## Chat Loader
|
| 36 |
+
|
| 37 |
+
See a [usage example](/docs/integrations/chat_loaders/discord).
|
| 38 |
+
|
langchain_md_files/integrations/providers/docarray.mdx
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DocArray
|
| 2 |
+
|
| 3 |
+
> [DocArray](https://docarray.jina.ai/) is a library for nested, unstructured, multimodal data in transit,
|
| 4 |
+
> including text, image, audio, video, 3D mesh, etc. It allows deep-learning engineers to efficiently process,
|
| 5 |
+
> embed, search, recommend, store, and transfer multimodal data with a Pythonic API.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
|
| 10 |
+
We need to install `docarray` python package.
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
pip install docarray
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
## Vector Store
|
| 17 |
+
|
| 18 |
+
LangChain provides an access to the `In-memory` and `HNSW` vector stores from the `DocArray` library.
|
| 19 |
+
|
| 20 |
+
See a [usage example](/docs/integrations/vectorstores/docarray_hnsw).
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from langchain_community.vectorstores import DocArrayHnswSearch
|
| 24 |
+
```
|
| 25 |
+
See a [usage example](/docs/integrations/vectorstores/docarray_in_memory).
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from langchain_community.vectorstores DocArrayInMemorySearch
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Retriever
|
| 32 |
+
|
| 33 |
+
See a [usage example](/docs/integrations/retrievers/docarray_retriever).
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from langchain_community.retrievers import DocArrayRetriever
|
| 37 |
+
```
|
langchain_md_files/integrations/providers/doctran.mdx
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Doctran
|
| 2 |
+
|
| 3 |
+
>[Doctran](https://github.com/psychic-api/doctran) is a python package. It uses LLMs and open-source
|
| 4 |
+
> NLP libraries to transform raw text into clean, structured, information-dense documents
|
| 5 |
+
> that are optimized for vector space retrieval. You can think of `Doctran` as a black box where
|
| 6 |
+
> messy strings go in and nice, clean, labelled strings come out.
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
pip install doctran
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
## Document Transformers
|
| 16 |
+
|
| 17 |
+
### Document Interrogator
|
| 18 |
+
|
| 19 |
+
See a [usage example for DoctranQATransformer](/docs/integrations/document_transformers/doctran_interrogate_document).
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from langchain_community.document_loaders import DoctranQATransformer
|
| 23 |
+
```
|
| 24 |
+
### Property Extractor
|
| 25 |
+
|
| 26 |
+
See a [usage example for DoctranPropertyExtractor](/docs/integrations/document_transformers/doctran_extract_properties).
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
from langchain_community.document_loaders import DoctranPropertyExtractor
|
| 30 |
+
```
|
| 31 |
+
### Document Translator
|
| 32 |
+
|
| 33 |
+
See a [usage example for DoctranTextTranslator](/docs/integrations/document_transformers/doctran_translate_document).
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from langchain_community.document_loaders import DoctranTextTranslator
|
| 37 |
+
```
|
langchain_md_files/integrations/providers/docugami.mdx
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Docugami
|
| 2 |
+
|
| 3 |
+
>[Docugami](https://docugami.com) converts business documents into a Document XML Knowledge Graph, generating forests
|
| 4 |
+
> of XML semantic trees representing entire documents. This is a rich representation that includes the semantic and
|
| 5 |
+
> structural characteristics of various chunks in the document as an XML tree.
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
```bash
|
| 11 |
+
pip install dgml-utils
|
| 12 |
+
pip install docugami-langchain
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
## Document Loader
|
| 16 |
+
|
| 17 |
+
See a [usage example](/docs/integrations/document_loaders/docugami).
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from docugami_langchain.document_loaders import DocugamiLoader
|
| 21 |
+
```
|
langchain_md_files/integrations/providers/docusaurus.mdx
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Docusaurus
|
| 2 |
+
|
| 3 |
+
>[Docusaurus](https://docusaurus.io/) is a static-site generator which provides
|
| 4 |
+
> out-of-the-box documentation features.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
```bash
|
| 11 |
+
pip install -U beautifulsoup4 lxml
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
## Document Loader
|
| 15 |
+
|
| 16 |
+
See a [usage example](/docs/integrations/document_loaders/docusaurus).
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
from langchain_community.document_loaders import DocusaurusLoader
|
| 20 |
+
```
|
langchain_md_files/integrations/providers/dria.mdx
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Dria
|
| 2 |
+
|
| 3 |
+
>[Dria](https://dria.co/) is a hub of public RAG models for developers to
|
| 4 |
+
> both contribute and utilize a shared embedding lake.
|
| 5 |
+
|
| 6 |
+
See more details about the LangChain integration with Dria
|
| 7 |
+
at [this page](https://dria.co/docs/integrations/langchain).
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
You have to install a python package:
|
| 12 |
+
|
| 13 |
+
```bash
|
| 14 |
+
pip install dria
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
You have to get an API key from Dria. You can get it by signing up at [Dria](https://dria.co/).
|
| 18 |
+
|
| 19 |
+
## Retrievers
|
| 20 |
+
|
| 21 |
+
See a [usage example](/docs/integrations/retrievers/dria_index).
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.retrievers import DriaRetriever
|
| 25 |
+
```
|
langchain_md_files/integrations/providers/dropbox.mdx
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Dropbox
|
| 2 |
+
|
| 3 |
+
>[Dropbox](https://en.wikipedia.org/wiki/Dropbox) is a file hosting service that brings everything-traditional
|
| 4 |
+
> files, cloud content, and web shortcuts together in one place.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
See the detailed [installation guide](/docs/integrations/document_loaders/dropbox#prerequisites).
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
pip install -U dropbox
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
## Document Loader
|
| 16 |
+
|
| 17 |
+
See a [usage example](/docs/integrations/document_loaders/dropbox).
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from langchain_community.document_loaders import DropboxLoader
|
| 21 |
+
```
|
langchain_md_files/integrations/providers/duckdb.mdx
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DuckDB
|
| 2 |
+
|
| 3 |
+
>[DuckDB](https://duckdb.org/) is an in-process SQL OLAP database management system.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
First, you need to install `duckdb` python package.
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install duckdb
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
## Document Loader
|
| 14 |
+
|
| 15 |
+
See a [usage example](/docs/integrations/document_loaders/duckdb).
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.document_loaders import DuckDBLoader
|
| 19 |
+
```
|
langchain_md_files/integrations/providers/duckduckgo_search.mdx
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DuckDuckGo Search
|
| 2 |
+
|
| 3 |
+
>[DuckDuckGo Search](https://github.com/deedy5/duckduckgo_search) is a package that
|
| 4 |
+
> searches for words, documents, images, videos, news, maps and text
|
| 5 |
+
> translation using the `DuckDuckGo.com` search engine. It is downloading files
|
| 6 |
+
> and images to a local hard drive.
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
|
| 10 |
+
You have to install a python package:
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
pip install duckduckgo-search
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
## Tools
|
| 17 |
+
|
| 18 |
+
See a [usage example](/docs/integrations/tools/ddg).
|
| 19 |
+
|
| 20 |
+
There are two tools available:
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from langchain_community.tools import DuckDuckGoSearchRun
|
| 24 |
+
from langchain_community.tools import DuckDuckGoSearchResults
|
| 25 |
+
```
|
langchain_md_files/integrations/providers/e2b.mdx
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# E2B
|
| 2 |
+
|
| 3 |
+
>[E2B](https://e2b.dev/) provides open-source secure sandboxes
|
| 4 |
+
> for AI-generated code execution. See more [here](https://github.com/e2b-dev).
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
You have to install a python package:
|
| 9 |
+
|
| 10 |
+
```bash
|
| 11 |
+
pip install e2b_code_interpreter
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
## Tool
|
| 15 |
+
|
| 16 |
+
See a [usage example](/docs/integrations/tools/e2b_data_analysis).
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
from langchain_community.tools import E2BDataAnalysisTool
|
| 20 |
+
```
|
langchain_md_files/integrations/providers/edenai.mdx
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Eden AI
|
| 2 |
+
|
| 3 |
+
>[Eden AI](https://docs.edenai.co/docs/getting-started-with-eden-ai) user interface (UI)
|
| 4 |
+
> is designed for handling the AI projects. With `Eden AI Portal`,
|
| 5 |
+
> you can perform no-code AI using the best engines for the market.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
|
| 10 |
+
Accessing the Eden AI API requires an API key, which you can get by
|
| 11 |
+
[creating an account](https://app.edenai.run/user/register) and
|
| 12 |
+
heading [here](https://app.edenai.run/admin/account/settings).
|
| 13 |
+
|
| 14 |
+
## LLMs
|
| 15 |
+
|
| 16 |
+
See a [usage example](/docs/integrations/llms/edenai).
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
from langchain_community.llms import EdenAI
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Chat models
|
| 24 |
+
|
| 25 |
+
See a [usage example](/docs/integrations/chat/edenai).
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from langchain_community.chat_models.edenai import ChatEdenAI
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Embedding models
|
| 32 |
+
|
| 33 |
+
See a [usage example](/docs/integrations/text_embedding/edenai).
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from langchain_community.embeddings.edenai import EdenAiEmbeddings
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Tools
|
| 40 |
+
|
| 41 |
+
Eden AI provides a list of tools that grants your Agent the ability to do multiple tasks, such as:
|
| 42 |
+
* speech to text
|
| 43 |
+
* text to speech
|
| 44 |
+
* text explicit content detection
|
| 45 |
+
* image explicit content detection
|
| 46 |
+
* object detection
|
| 47 |
+
* OCR invoice parsing
|
| 48 |
+
* OCR ID parsing
|
| 49 |
+
|
| 50 |
+
See a [usage example](/docs/integrations/tools/edenai_tools).
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
from langchain_community.tools.edenai import (
|
| 54 |
+
EdenAiExplicitImageTool,
|
| 55 |
+
EdenAiObjectDetectionTool,
|
| 56 |
+
EdenAiParsingIDTool,
|
| 57 |
+
EdenAiParsingInvoiceTool,
|
| 58 |
+
EdenAiSpeechToTextTool,
|
| 59 |
+
EdenAiTextModerationTool,
|
| 60 |
+
EdenAiTextToSpeechTool,
|
| 61 |
+
)
|
| 62 |
+
```
|
langchain_md_files/integrations/providers/elasticsearch.mdx
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Elasticsearch
|
| 2 |
+
|
| 3 |
+
> [Elasticsearch](https://www.elastic.co/elasticsearch/) is a distributed, RESTful search and analytics engine.
|
| 4 |
+
> It provides a distributed, multi-tenant-capable full-text search engine with an HTTP web interface and schema-free
|
| 5 |
+
> JSON documents.
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
### Setup Elasticsearch
|
| 10 |
+
|
| 11 |
+
There are two ways to get started with Elasticsearch:
|
| 12 |
+
|
| 13 |
+
#### Install Elasticsearch on your local machine via Docker
|
| 14 |
+
|
| 15 |
+
Example: Run a single-node Elasticsearch instance with security disabled.
|
| 16 |
+
This is not recommended for production use.
|
| 17 |
+
|
| 18 |
+
```bash
|
| 19 |
+
docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.9.0
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
#### Deploy Elasticsearch on Elastic Cloud
|
| 23 |
+
|
| 24 |
+
`Elastic Cloud` is a managed Elasticsearch service. Signup for a [free trial](https://cloud.elastic.co/registration?utm_source=langchain&utm_content=documentation).
|
| 25 |
+
|
| 26 |
+
### Install Client
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
pip install elasticsearch
|
| 30 |
+
pip install langchain-elasticsearch
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Embedding models
|
| 34 |
+
|
| 35 |
+
See a [usage example](/docs/integrations/text_embedding/elasticsearch).
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from langchain_elasticsearch import ElasticsearchEmbeddings
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## Vector store
|
| 42 |
+
|
| 43 |
+
See a [usage example](/docs/integrations/vectorstores/elasticsearch).
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
from langchain_elasticsearch import ElasticsearchStore
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
### Third-party integrations
|
| 50 |
+
|
| 51 |
+
#### EcloudESVectorStore
|
| 52 |
+
|
| 53 |
+
```python
|
| 54 |
+
from langchain_community.vectorstores.ecloud_vector_search import EcloudESVectorStore
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
## Retrievers
|
| 58 |
+
|
| 59 |
+
### ElasticsearchRetriever
|
| 60 |
+
|
| 61 |
+
The `ElasticsearchRetriever` enables flexible access to all Elasticsearch features
|
| 62 |
+
through the Query DSL.
|
| 63 |
+
|
| 64 |
+
See a [usage example](/docs/integrations/retrievers/elasticsearch_retriever).
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
from langchain_elasticsearch import ElasticsearchRetriever
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
### BM25
|
| 71 |
+
|
| 72 |
+
See a [usage example](/docs/integrations/retrievers/elastic_search_bm25).
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
from langchain_community.retrievers import ElasticSearchBM25Retriever
|
| 76 |
+
```
|
| 77 |
+
## Memory
|
| 78 |
+
|
| 79 |
+
See a [usage example](/docs/integrations/memory/elasticsearch_chat_message_history).
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
from langchain_elasticsearch import ElasticsearchChatMessageHistory
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## LLM cache
|
| 86 |
+
|
| 87 |
+
See a [usage example](/docs/integrations/llm_caching/#elasticsearch-cache).
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
from langchain_elasticsearch import ElasticsearchCache
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## Byte Store
|
| 94 |
+
|
| 95 |
+
See a [usage example](/docs/integrations/stores/elasticsearch).
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
from langchain_elasticsearch import ElasticsearchEmbeddingsCache
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
## Chain
|
| 102 |
+
|
| 103 |
+
It is a chain for interacting with Elasticsearch Database.
|
| 104 |
+
|
| 105 |
+
```python
|
| 106 |
+
from langchain.chains.elasticsearch_database import ElasticsearchDatabaseChain
|
| 107 |
+
```
|
| 108 |
+
|
langchain_md_files/integrations/providers/elevenlabs.mdx
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ElevenLabs
|
| 2 |
+
|
| 3 |
+
>[ElevenLabs](https://elevenlabs.io/about) is a voice AI research & deployment company
|
| 4 |
+
> with a mission to make content universally accessible in any language & voice.
|
| 5 |
+
>
|
| 6 |
+
>`ElevenLabs` creates the most realistic, versatile and contextually-aware
|
| 7 |
+
> AI audio, providing the ability to generate speech in hundreds of
|
| 8 |
+
> new and existing voices in 29 languages.
|
| 9 |
+
|
| 10 |
+
## Installation and Setup
|
| 11 |
+
|
| 12 |
+
First, you need to set up an ElevenLabs account. You can follow the
|
| 13 |
+
[instructions here](https://docs.elevenlabs.io/welcome/introduction).
|
| 14 |
+
|
| 15 |
+
Install the Python package:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
pip install elevenlabs
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
## Tools
|
| 22 |
+
|
| 23 |
+
See a [usage example](/docs/integrations/tools/eleven_labs_tts).
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
from langchain_community.tools import ElevenLabsText2SpeechTool
|
| 27 |
+
```
|
langchain_md_files/integrations/providers/epsilla.mdx
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Epsilla
|
| 2 |
+
|
| 3 |
+
This page covers how to use [Epsilla](https://github.com/epsilla-cloud/vectordb) within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Epsilla wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
- Install the Python SDK with `pip/pip3 install pyepsilla`
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### VectorStore
|
| 13 |
+
|
| 14 |
+
There exists a wrapper around Epsilla vector databases, allowing you to use it as a vectorstore,
|
| 15 |
+
whether for semantic search or example selection.
|
| 16 |
+
|
| 17 |
+
To import this vectorstore:
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from langchain_community.vectorstores import Epsilla
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
For a more detailed walkthrough of the Epsilla wrapper, see [this notebook](/docs/integrations/vectorstores/epsilla)
|
langchain_md_files/integrations/providers/etherscan.mdx
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Etherscan
|
| 2 |
+
|
| 3 |
+
>[Etherscan](https://docs.etherscan.io/) is the leading blockchain explorer,
|
| 4 |
+
> search, API and analytics platform for `Ethereum`, a decentralized smart contracts platform.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
See the detailed [installation guide](/docs/integrations/document_loaders/etherscan).
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Document Loader
|
| 13 |
+
|
| 14 |
+
See a [usage example](/docs/integrations/document_loaders/etherscan).
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
from langchain_community.document_loaders import EtherscanLoader
|
| 18 |
+
```
|
langchain_md_files/integrations/providers/evernote.mdx
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# EverNote
|
| 2 |
+
|
| 3 |
+
>[EverNote](https://evernote.com/) is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual "notebooks" and can be tagged, annotated, edited, searched, and exported.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
First, you need to install `lxml` and `html2text` python packages.
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install lxml
|
| 11 |
+
pip install html2text
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
## Document Loader
|
| 15 |
+
|
| 16 |
+
See a [usage example](/docs/integrations/document_loaders/evernote).
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
from langchain_community.document_loaders import EverNoteLoader
|
| 20 |
+
```
|
langchain_md_files/integrations/providers/facebook.mdx
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Facebook - Meta
|
| 2 |
+
|
| 3 |
+
>[Meta Platforms, Inc.](https://www.facebook.com/), doing business as `Meta`, formerly
|
| 4 |
+
> named `Facebook, Inc.`, and `TheFacebook, Inc.`, is an American multinational technology
|
| 5 |
+
> conglomerate. The company owns and operates `Facebook`, `Instagram`, `Threads`,
|
| 6 |
+
> and `WhatsApp`, among other products and services.
|
| 7 |
+
|
| 8 |
+
## Embedding models
|
| 9 |
+
|
| 10 |
+
### LASER
|
| 11 |
+
|
| 12 |
+
>[LASER](https://github.com/facebookresearch/LASER) is a Python library developed by
|
| 13 |
+
> the `Meta AI Research` team and used for
|
| 14 |
+
> creating multilingual sentence embeddings for
|
| 15 |
+
> [over 147 languages as of 2/25/2024](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
pip install laser_encoders
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
See a [usage example](/docs/integrations/text_embedding/laser).
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.embeddings.laser import LaserEmbeddings
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Document loaders
|
| 28 |
+
|
| 29 |
+
### Facebook Messenger
|
| 30 |
+
|
| 31 |
+
>[Messenger](https://en.wikipedia.org/wiki/Messenger_(software)) is an instant messaging app and
|
| 32 |
+
> platform developed by `Meta Platforms`. Originally developed as `Facebook Chat` in 2008, the company revamped its
|
| 33 |
+
> messaging service in 2010.
|
| 34 |
+
|
| 35 |
+
See a [usage example](/docs/integrations/document_loaders/facebook_chat).
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from langchain_community.document_loaders import FacebookChatLoader
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## Vector stores
|
| 42 |
+
|
| 43 |
+
### Facebook Faiss
|
| 44 |
+
|
| 45 |
+
>[Facebook AI Similarity Search (Faiss)](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/)
|
| 46 |
+
> is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that
|
| 47 |
+
> search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting
|
| 48 |
+
> code for evaluation and parameter tuning.
|
| 49 |
+
|
| 50 |
+
[Faiss documentation](https://faiss.ai/).
|
| 51 |
+
|
| 52 |
+
We need to install `faiss` python package.
|
| 53 |
+
|
| 54 |
+
```bash
|
| 55 |
+
pip install faiss-gpu # For CUDA 7.5+ supported GPU's.
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
OR
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
pip install faiss-cpu # For CPU Installation
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
See a [usage example](/docs/integrations/vectorstores/faiss).
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
from langchain_community.vectorstores import FAISS
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
## Chat loaders
|
| 71 |
+
|
| 72 |
+
### Facebook Messenger
|
| 73 |
+
|
| 74 |
+
>[Messenger](https://en.wikipedia.org/wiki/Messenger_(software)) is an instant messaging app and
|
| 75 |
+
> platform developed by `Meta Platforms`. Originally developed as `Facebook Chat` in 2008, the company revamped its
|
| 76 |
+
> messaging service in 2010.
|
| 77 |
+
|
| 78 |
+
See a [usage example](/docs/integrations/chat_loaders/facebook).
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
from langchain_community.chat_loaders.facebook_messenger import (
|
| 82 |
+
FolderFacebookMessengerChatLoader,
|
| 83 |
+
SingleFileFacebookMessengerChatLoader,
|
| 84 |
+
)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
### Facebook WhatsApp
|
| 88 |
+
|
| 89 |
+
See a [usage example](/docs/integrations/chat_loaders/whatsapp).
|
| 90 |
+
|
| 91 |
+
```python
|
| 92 |
+
from langchain_community.chat_loaders.whatsapp import WhatsAppChatLoader
|
| 93 |
+
```
|
langchain_md_files/integrations/providers/fauna.mdx
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fauna
|
| 2 |
+
|
| 3 |
+
>[Fauna](https://fauna.com/) is a distributed document-relational database
|
| 4 |
+
> that combines the flexibility of documents with the power of a relational,
|
| 5 |
+
> ACID compliant database that scales across regions, clouds or the globe.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
|
| 10 |
+
We have to get the secret key.
|
| 11 |
+
See the detailed [guide](https://docs.fauna.com/fauna/current/learn/security_model/).
|
| 12 |
+
|
| 13 |
+
We have to install the `fauna` package.
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
pip install -U fauna
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
## Document Loader
|
| 20 |
+
|
| 21 |
+
See a [usage example](/docs/integrations/document_loaders/fauna).
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.document_loaders.fauna import FaunaLoader
|
| 25 |
+
```
|
langchain_md_files/integrations/providers/figma.mdx
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Figma
|
| 2 |
+
|
| 3 |
+
>[Figma](https://www.figma.com/) is a collaborative web application for interface design.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
The Figma API requires an `access token`, `node_ids`, and a `file key`.
|
| 8 |
+
|
| 9 |
+
The `file key` can be pulled from the URL. https://www.figma.com/file/{filekey}/sampleFilename
|
| 10 |
+
|
| 11 |
+
`Node IDs` are also available in the URL. Click on anything and look for the '?node-id={node_id}' param.
|
| 12 |
+
|
| 13 |
+
`Access token` [instructions](https://help.figma.com/hc/en-us/articles/8085703771159-Manage-personal-access-tokens).
|
| 14 |
+
|
| 15 |
+
## Document Loader
|
| 16 |
+
|
| 17 |
+
See a [usage example](/docs/integrations/document_loaders/figma).
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from langchain_community.document_loaders import FigmaFileLoader
|
| 21 |
+
```
|
langchain_md_files/integrations/providers/flyte.mdx
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flyte
|
| 2 |
+
|
| 3 |
+
> [Flyte](https://github.com/flyteorg/flyte) is an open-source orchestrator that facilitates building production-grade data and ML pipelines.
|
| 4 |
+
> It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform.
|
| 5 |
+
|
| 6 |
+
The purpose of this notebook is to demonstrate the integration of a `FlyteCallback` into your Flyte task, enabling you to effectively monitor and track your LangChain experiments.
|
| 7 |
+
|
| 8 |
+
## Installation & Setup
|
| 9 |
+
|
| 10 |
+
- Install the Flytekit library by running the command `pip install flytekit`.
|
| 11 |
+
- Install the Flytekit-Envd plugin by running the command `pip install flytekitplugins-envd`.
|
| 12 |
+
- Install LangChain by running the command `pip install langchain`.
|
| 13 |
+
- Install [Docker](https://docs.docker.com/engine/install/) on your system.
|
| 14 |
+
|
| 15 |
+
## Flyte Tasks
|
| 16 |
+
|
| 17 |
+
A Flyte [task](https://docs.flyte.org/en/latest/user_guide/basics/tasks.html) serves as the foundational building block of Flyte.
|
| 18 |
+
To execute LangChain experiments, you need to write Flyte tasks that define the specific steps and operations involved.
|
| 19 |
+
|
| 20 |
+
NOTE: The [getting started guide](https://docs.flyte.org/projects/cookbook/en/latest/index.html) offers detailed, step-by-step instructions on installing Flyte locally and running your initial Flyte pipeline.
|
| 21 |
+
|
| 22 |
+
First, import the necessary dependencies to support your LangChain experiments.
|
| 23 |
+
|
| 24 |
+
```python
|
| 25 |
+
import os
|
| 26 |
+
|
| 27 |
+
from flytekit import ImageSpec, task
|
| 28 |
+
from langchain.agents import AgentType, initialize_agent, load_tools
|
| 29 |
+
from langchain.callbacks import FlyteCallbackHandler
|
| 30 |
+
from langchain.chains import LLMChain
|
| 31 |
+
from langchain_openai import ChatOpenAI
|
| 32 |
+
from langchain_core.prompts import PromptTemplate
|
| 33 |
+
from langchain_core.messages import HumanMessage
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Set up the necessary environment variables to utilize the OpenAI API and Serp API:
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
# Set OpenAI API key
|
| 40 |
+
os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"
|
| 41 |
+
|
| 42 |
+
# Set Serp API key
|
| 43 |
+
os.environ["SERPAPI_API_KEY"] = "<your_serp_api_key>"
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Replace `<your_openai_api_key>` and `<your_serp_api_key>` with your respective API keys obtained from OpenAI and Serp API.
|
| 47 |
+
|
| 48 |
+
To guarantee reproducibility of your pipelines, Flyte tasks are containerized.
|
| 49 |
+
Each Flyte task must be associated with an image, which can either be shared across the entire Flyte [workflow](https://docs.flyte.org/en/latest/user_guide/basics/workflows.html) or provided separately for each task.
|
| 50 |
+
|
| 51 |
+
To streamline the process of supplying the required dependencies for each Flyte task, you can initialize an [`ImageSpec`](https://docs.flyte.org/en/latest/user_guide/customizing_dependencies/imagespec.html) object.
|
| 52 |
+
This approach automatically triggers a Docker build, alleviating the need for users to manually create a Docker image.
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
custom_image = ImageSpec(
|
| 56 |
+
name="langchain-flyte",
|
| 57 |
+
packages=[
|
| 58 |
+
"langchain",
|
| 59 |
+
"openai",
|
| 60 |
+
"spacy",
|
| 61 |
+
"https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.5.0/en_core_web_sm-3.5.0.tar.gz",
|
| 62 |
+
"textstat",
|
| 63 |
+
"google-search-results",
|
| 64 |
+
],
|
| 65 |
+
registry="<your-registry>",
|
| 66 |
+
)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
You have the flexibility to push the Docker image to a registry of your preference.
|
| 70 |
+
[Docker Hub](https://hub.docker.com/) or [GitHub Container Registry (GHCR)](https://docs.github.com/en/packages/working-with-a-github-packages-registry/working-with-the-container-registry) is a convenient option to begin with.
|
| 71 |
+
|
| 72 |
+
Once you have selected a registry, you can proceed to create Flyte tasks that log the LangChain metrics to Flyte Deck.
|
| 73 |
+
|
| 74 |
+
The following examples demonstrate tasks related to OpenAI LLM, chains and agent with tools:
|
| 75 |
+
|
| 76 |
+
### LLM
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
@task(disable_deck=False, container_image=custom_image)
|
| 80 |
+
def langchain_llm() -> str:
|
| 81 |
+
llm = ChatOpenAI(
|
| 82 |
+
model_name="gpt-3.5-turbo",
|
| 83 |
+
temperature=0.2,
|
| 84 |
+
callbacks=[FlyteCallbackHandler()],
|
| 85 |
+
)
|
| 86 |
+
return llm.invoke([HumanMessage(content="Tell me a joke")]).content
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
### Chain
|
| 90 |
+
|
| 91 |
+
```python
|
| 92 |
+
@task(disable_deck=False, container_image=custom_image)
|
| 93 |
+
def langchain_chain() -> list[dict[str, str]]:
|
| 94 |
+
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
|
| 95 |
+
Title: {title}
|
| 96 |
+
Playwright: This is a synopsis for the above play:"""
|
| 97 |
+
llm = ChatOpenAI(
|
| 98 |
+
model_name="gpt-3.5-turbo",
|
| 99 |
+
temperature=0,
|
| 100 |
+
callbacks=[FlyteCallbackHandler()],
|
| 101 |
+
)
|
| 102 |
+
prompt_template = PromptTemplate(input_variables=["title"], template=template)
|
| 103 |
+
synopsis_chain = LLMChain(
|
| 104 |
+
llm=llm, prompt=prompt_template, callbacks=[FlyteCallbackHandler()]
|
| 105 |
+
)
|
| 106 |
+
test_prompts = [
|
| 107 |
+
{
|
| 108 |
+
"title": "documentary about good video games that push the boundary of game design"
|
| 109 |
+
},
|
| 110 |
+
]
|
| 111 |
+
return synopsis_chain.apply(test_prompts)
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
### Agent
|
| 115 |
+
|
| 116 |
+
```python
|
| 117 |
+
@task(disable_deck=False, container_image=custom_image)
|
| 118 |
+
def langchain_agent() -> str:
|
| 119 |
+
llm = OpenAI(
|
| 120 |
+
model_name="gpt-3.5-turbo",
|
| 121 |
+
temperature=0,
|
| 122 |
+
callbacks=[FlyteCallbackHandler()],
|
| 123 |
+
)
|
| 124 |
+
tools = load_tools(
|
| 125 |
+
["serpapi", "llm-math"], llm=llm, callbacks=[FlyteCallbackHandler()]
|
| 126 |
+
)
|
| 127 |
+
agent = initialize_agent(
|
| 128 |
+
tools,
|
| 129 |
+
llm,
|
| 130 |
+
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
|
| 131 |
+
callbacks=[FlyteCallbackHandler()],
|
| 132 |
+
verbose=True,
|
| 133 |
+
)
|
| 134 |
+
return agent.run(
|
| 135 |
+
"Who is Leonardo DiCaprio's girlfriend? Could you calculate her current age and raise it to the power of 0.43?"
|
| 136 |
+
)
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
These tasks serve as a starting point for running your LangChain experiments within Flyte.
|
| 140 |
+
|
| 141 |
+
## Execute the Flyte Tasks on Kubernetes
|
| 142 |
+
|
| 143 |
+
To execute the Flyte tasks on the configured Flyte backend, use the following command:
|
| 144 |
+
|
| 145 |
+
```bash
|
| 146 |
+
pyflyte run --image <your-image> langchain_flyte.py langchain_llm
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
This command will initiate the execution of the `langchain_llm` task on the Flyte backend. You can trigger the remaining two tasks in a similar manner.
|
| 150 |
+
|
| 151 |
+
The metrics will be displayed on the Flyte UI as follows:
|
| 152 |
+
|
| 153 |
+
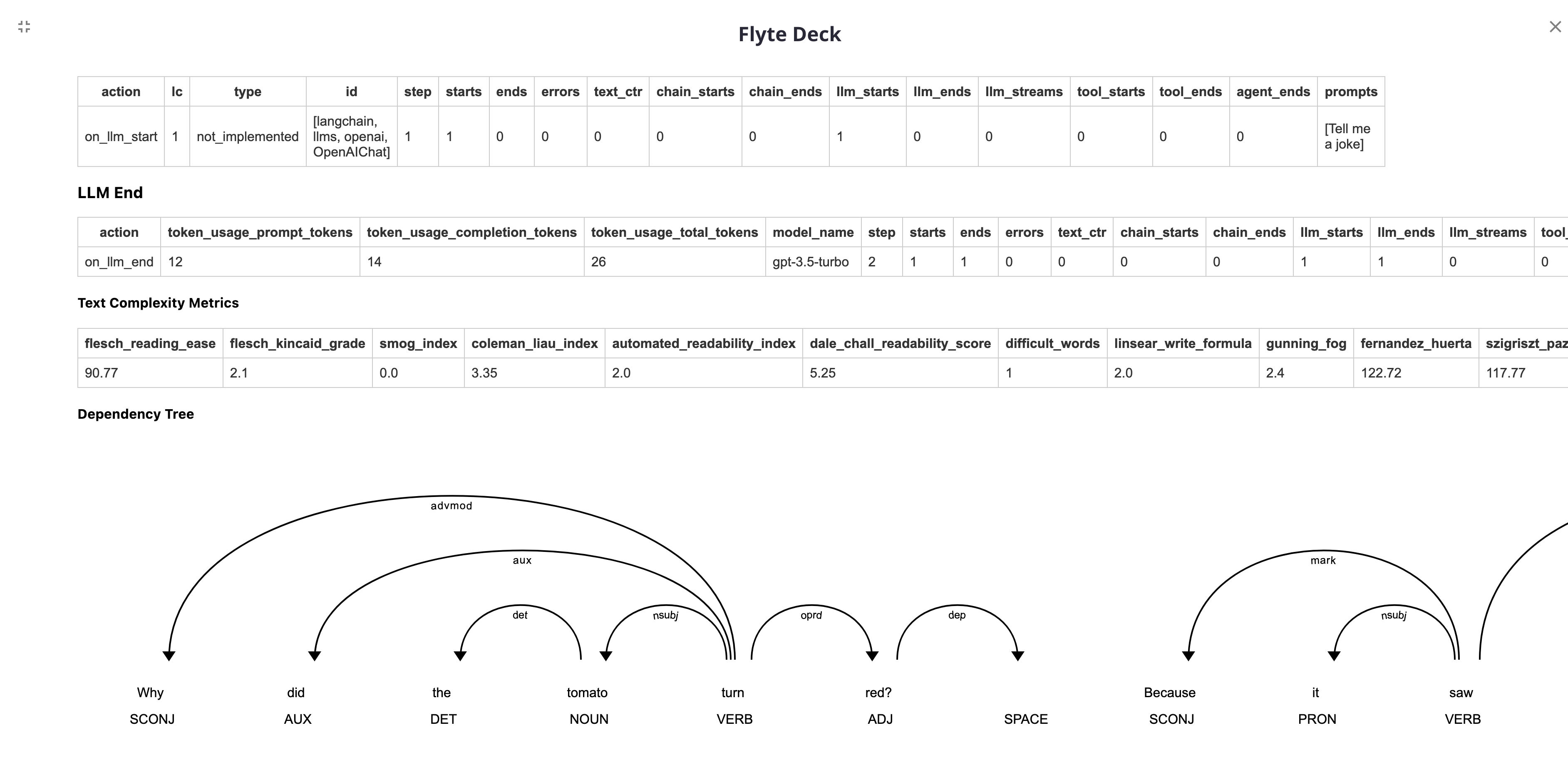
|
langchain_md_files/integrations/providers/forefrontai.mdx
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ForefrontAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the ForefrontAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific ForefrontAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Get an ForefrontAI api key and set it as an environment variable (`FOREFRONTAI_API_KEY`)
|
| 8 |
+
|
| 9 |
+
## Wrappers
|
| 10 |
+
|
| 11 |
+
### LLM
|
| 12 |
+
|
| 13 |
+
There exists an ForefrontAI LLM wrapper, which you can access with
|
| 14 |
+
```python
|
| 15 |
+
from langchain_community.llms import ForefrontAI
|
| 16 |
+
```
|
langchain_md_files/integrations/providers/geopandas.mdx
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Geopandas
|
| 2 |
+
|
| 3 |
+
>[GeoPandas](https://geopandas.org/) is an open source project to make working
|
| 4 |
+
> with geospatial data in python easier. `GeoPandas` extends the datatypes used by
|
| 5 |
+
> `pandas` to allow spatial operations on geometric types.
|
| 6 |
+
> Geometric operations are performed by `shapely`.
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
We have to install several python packages.
|
| 12 |
+
|
| 13 |
+
```bash
|
| 14 |
+
pip install -U sodapy pandas geopandas
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## Document Loader
|
| 18 |
+
|
| 19 |
+
See a [usage example](/docs/integrations/document_loaders/geopandas).
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from langchain_community.document_loaders import OpenCityDataLoader
|
| 23 |
+
```
|
langchain_md_files/integrations/providers/git.mdx
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Git
|
| 2 |
+
|
| 3 |
+
>[Git](https://en.wikipedia.org/wiki/Git) is a distributed version control system that tracks changes in any set of computer files, usually used for coordinating work among programmers collaboratively developing source code during software development.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
First, you need to install `GitPython` python package.
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install GitPython
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
## Document Loader
|
| 14 |
+
|
| 15 |
+
See a [usage example](/docs/integrations/document_loaders/git).
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.document_loaders import GitLoader
|
| 19 |
+
```
|
langchain_md_files/integrations/providers/gitbook.mdx
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GitBook
|
| 2 |
+
|
| 3 |
+
>[GitBook](https://docs.gitbook.com/) is a modern documentation platform where teams can document everything from products to internal knowledge bases and APIs.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
There isn't any special setup for it.
|
| 8 |
+
|
| 9 |
+
## Document Loader
|
| 10 |
+
|
| 11 |
+
See a [usage example](/docs/integrations/document_loaders/gitbook).
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
from langchain_community.document_loaders import GitbookLoader
|
| 15 |
+
```
|
langchain_md_files/integrations/providers/github.mdx
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GitHub
|
| 2 |
+
|
| 3 |
+
>[GitHub](https://github.com/) is a developer platform that allows developers to create,
|
| 4 |
+
> store, manage and share their code. It uses `Git` software, providing the
|
| 5 |
+
> distributed version control of Git plus access control, bug tracking,
|
| 6 |
+
> software feature requests, task management, continuous integration, and wikis for every project.
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
To access the GitHub API, you need a [personal access token](https://github.com/settings/tokens).
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Document Loader
|
| 15 |
+
|
| 16 |
+
There are two document loaders available for GitHub.
|
| 17 |
+
|
| 18 |
+
See a [usage example](/docs/integrations/document_loaders/github).
|
| 19 |
+
|
| 20 |
+
```python
|
| 21 |
+
from langchain_community.document_loaders import GitHubIssuesLoader, GithubFileLoader
|
| 22 |
+
```
|
langchain_md_files/integrations/providers/golden.mdx
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Golden
|
| 2 |
+
|
| 3 |
+
>[Golden](https://golden.com) provides a set of natural language APIs for querying and enrichment using the Golden Knowledge Graph e.g. queries such as: `Products from OpenAI`, `Generative ai companies with series a funding`, and `rappers who invest` can be used to retrieve structured data about relevant entities.
|
| 4 |
+
>
|
| 5 |
+
>The `golden-query` langchain tool is a wrapper on top of the [Golden Query API](https://docs.golden.com/reference/query-api) which enables programmatic access to these results.
|
| 6 |
+
>See the [Golden Query API docs](https://docs.golden.com/reference/query-api) for more information.
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
- Go to the [Golden API docs](https://docs.golden.com/) to get an overview about the Golden API.
|
| 10 |
+
- Get your API key from the [Golden API Settings](https://golden.com/settings/api) page.
|
| 11 |
+
- Save your API key into GOLDEN_API_KEY env variable
|
| 12 |
+
|
| 13 |
+
## Wrappers
|
| 14 |
+
|
| 15 |
+
### Utility
|
| 16 |
+
|
| 17 |
+
There exists a GoldenQueryAPIWrapper utility which wraps this API. To import this utility:
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from langchain_community.utilities.golden_query import GoldenQueryAPIWrapper
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
For a more detailed walkthrough of this wrapper, see [this notebook](/docs/integrations/tools/golden_query).
|
| 24 |
+
|
| 25 |
+
### Tool
|
| 26 |
+
|
| 27 |
+
You can also easily load this wrapper as a Tool (to use with an Agent).
|
| 28 |
+
You can do this with:
|
| 29 |
+
```python
|
| 30 |
+
from langchain.agents import load_tools
|
| 31 |
+
tools = load_tools(["golden-query"])
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
For more information on tools, see [this page](/docs/how_to/tools_builtin).
|
langchain_md_files/integrations/providers/google_serper.mdx
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Serper - Google Search API
|
| 2 |
+
|
| 3 |
+
This page covers how to use the [Serper](https://serper.dev) Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search.
|
| 4 |
+
It is broken into two parts: setup, and then references to the specific Google Serper wrapper.
|
| 5 |
+
|
| 6 |
+
## Setup
|
| 7 |
+
|
| 8 |
+
- Go to [serper.dev](https://serper.dev) to sign up for a free account
|
| 9 |
+
- Get the api key and set it as an environment variable (`SERPER_API_KEY`)
|
| 10 |
+
|
| 11 |
+
## Wrappers
|
| 12 |
+
|
| 13 |
+
### Utility
|
| 14 |
+
|
| 15 |
+
There exists a GoogleSerperAPIWrapper utility which wraps this API. To import this utility:
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.utilities import GoogleSerperAPIWrapper
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
You can use it as part of a Self Ask chain:
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.utilities import GoogleSerperAPIWrapper
|
| 25 |
+
from langchain_openai import OpenAI
|
| 26 |
+
from langchain.agents import initialize_agent, Tool
|
| 27 |
+
from langchain.agents import AgentType
|
| 28 |
+
|
| 29 |
+
import os
|
| 30 |
+
|
| 31 |
+
os.environ["SERPER_API_KEY"] = ""
|
| 32 |
+
os.environ['OPENAI_API_KEY'] = ""
|
| 33 |
+
|
| 34 |
+
llm = OpenAI(temperature=0)
|
| 35 |
+
search = GoogleSerperAPIWrapper()
|
| 36 |
+
tools = [
|
| 37 |
+
Tool(
|
| 38 |
+
name="Intermediate Answer",
|
| 39 |
+
func=search.run,
|
| 40 |
+
description="useful for when you need to ask with search"
|
| 41 |
+
)
|
| 42 |
+
]
|
| 43 |
+
|
| 44 |
+
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
|
| 45 |
+
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
#### Output
|
| 49 |
+
```
|
| 50 |
+
Entering new AgentExecutor chain...
|
| 51 |
+
Yes.
|
| 52 |
+
Follow up: Who is the reigning men's U.S. Open champion?
|
| 53 |
+
Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.
|
| 54 |
+
Follow up: Where is Carlos Alcaraz from?
|
| 55 |
+
Intermediate answer: El Palmar, Spain
|
| 56 |
+
So the final answer is: El Palmar, Spain
|
| 57 |
+
|
| 58 |
+
> Finished chain.
|
| 59 |
+
|
| 60 |
+
'El Palmar, Spain'
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
For a more detailed walkthrough of this wrapper, see [this notebook](/docs/integrations/tools/google_serper).
|
| 64 |
+
|
| 65 |
+
### Tool
|
| 66 |
+
|
| 67 |
+
You can also easily load this wrapper as a Tool (to use with an Agent).
|
| 68 |
+
You can do this with:
|
| 69 |
+
```python
|
| 70 |
+
from langchain.agents import load_tools
|
| 71 |
+
tools = load_tools(["google-serper"])
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
For more information on tools, see [this page](/docs/how_to/tools_builtin).
|
langchain_md_files/integrations/providers/gooseai.mdx
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GooseAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the GooseAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific GooseAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install openai`
|
| 8 |
+
- Get your GooseAI api key from this link [here](https://goose.ai/).
|
| 9 |
+
- Set the environment variable (`GOOSEAI_API_KEY`).
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
import os
|
| 13 |
+
os.environ["GOOSEAI_API_KEY"] = "YOUR_API_KEY"
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
## Wrappers
|
| 17 |
+
|
| 18 |
+
### LLM
|
| 19 |
+
|
| 20 |
+
There exists an GooseAI LLM wrapper, which you can access with:
|
| 21 |
+
```python
|
| 22 |
+
from langchain_community.llms import GooseAI
|
| 23 |
+
```
|
langchain_md_files/integrations/providers/gpt4all.mdx
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GPT4All
|
| 2 |
+
|
| 3 |
+
This page covers how to use the `GPT4All` wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
- Install the Python package with `pip install gpt4all`
|
| 8 |
+
- Download a [GPT4All model](https://gpt4all.io/index.html) and place it in your desired directory
|
| 9 |
+
|
| 10 |
+
In this example, we are using `mistral-7b-openorca.Q4_0.gguf`:
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
mkdir models
|
| 14 |
+
wget https://gpt4all.io/models/gguf/mistral-7b-openorca.Q4_0.gguf -O models/mistral-7b-openorca.Q4_0.gguf
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## Usage
|
| 18 |
+
|
| 19 |
+
### GPT4All
|
| 20 |
+
|
| 21 |
+
To use the GPT4All wrapper, you need to provide the path to the pre-trained model file and the model's configuration.
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.llms import GPT4All
|
| 25 |
+
|
| 26 |
+
# Instantiate the model. Callbacks support token-wise streaming
|
| 27 |
+
model = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)
|
| 28 |
+
|
| 29 |
+
# Generate text
|
| 30 |
+
response = model.invoke("Once upon a time, ")
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
You can also customize the generation parameters, such as `n_predict`, `temp`, `top_p`, `top_k`, and others.
|
| 34 |
+
|
| 35 |
+
To stream the model's predictions, add in a CallbackManager.
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from langchain_community.llms import GPT4All
|
| 39 |
+
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
|
| 40 |
+
|
| 41 |
+
# There are many CallbackHandlers supported, such as
|
| 42 |
+
# from langchain.callbacks.streamlit import StreamlitCallbackHandler
|
| 43 |
+
|
| 44 |
+
callbacks = [StreamingStdOutCallbackHandler()]
|
| 45 |
+
model = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)
|
| 46 |
+
|
| 47 |
+
# Generate text. Tokens are streamed through the callback manager.
|
| 48 |
+
model.invoke("Once upon a time, ", callbacks=callbacks)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Model File
|
| 52 |
+
|
| 53 |
+
You can download model files from the GPT4All client. You can download the client from the [GPT4All](https://gpt4all.io/index.html) website.
|
| 54 |
+
|
| 55 |
+
For a more detailed walkthrough of this, see [this notebook](/docs/integrations/llms/gpt4all)
|
langchain_md_files/integrations/providers/gradient.mdx
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Gradient
|
| 2 |
+
|
| 3 |
+
>[Gradient](https://gradient.ai/) allows to fine tune and get completions on LLMs with a simple web API.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
- Install the Python SDK :
|
| 7 |
+
```bash
|
| 8 |
+
pip install gradientai
|
| 9 |
+
```
|
| 10 |
+
Get a [Gradient access token and workspace](https://gradient.ai/) and set it as an environment variable (`Gradient_ACCESS_TOKEN`) and (`GRADIENT_WORKSPACE_ID`)
|
| 11 |
+
|
| 12 |
+
## LLM
|
| 13 |
+
|
| 14 |
+
There exists an Gradient LLM wrapper, which you can access with
|
| 15 |
+
See a [usage example](/docs/integrations/llms/gradient).
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.llms import GradientLLM
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
## Text Embedding Model
|
| 22 |
+
|
| 23 |
+
There exists an Gradient Embedding model, which you can access with
|
| 24 |
+
```python
|
| 25 |
+
from langchain_community.embeddings import GradientEmbeddings
|
| 26 |
+
```
|
| 27 |
+
For a more detailed walkthrough of this, see [this notebook](/docs/integrations/text_embedding/gradient)
|
langchain_md_files/integrations/providers/graphsignal.mdx
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Graphsignal
|
| 2 |
+
|
| 3 |
+
This page covers how to use [Graphsignal](https://app.graphsignal.com) to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
- Install the Python library with `pip install graphsignal`
|
| 8 |
+
- Create free Graphsignal account [here](https://graphsignal.com)
|
| 9 |
+
- Get an API key and set it as an environment variable (`GRAPHSIGNAL_API_KEY`)
|
| 10 |
+
|
| 11 |
+
## Tracing and Monitoring
|
| 12 |
+
|
| 13 |
+
Graphsignal automatically instruments and starts tracing and monitoring chains. Traces and metrics are then available in your [Graphsignal dashboards](https://app.graphsignal.com).
|
| 14 |
+
|
| 15 |
+
Initialize the tracer by providing a deployment name:
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
import graphsignal
|
| 19 |
+
|
| 20 |
+
graphsignal.configure(deployment='my-langchain-app-prod')
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
To additionally trace any function or code, you can use a decorator or a context manager:
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
@graphsignal.trace_function
|
| 27 |
+
def handle_request():
|
| 28 |
+
chain.run("some initial text")
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
with graphsignal.start_trace('my-chain'):
|
| 33 |
+
chain.run("some initial text")
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Optionally, enable profiling to record function-level statistics for each trace.
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
with graphsignal.start_trace(
|
| 40 |
+
'my-chain', options=graphsignal.TraceOptions(enable_profiling=True)):
|
| 41 |
+
chain.run("some initial text")
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
See the [Quick Start](https://graphsignal.com/docs/guides/quick-start/) guide for complete setup instructions.
|
langchain_md_files/integrations/providers/grobid.mdx
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Grobid
|
| 2 |
+
|
| 3 |
+
GROBID is a machine learning library for extracting, parsing, and re-structuring raw documents.
|
| 4 |
+
|
| 5 |
+
It is designed and expected to be used to parse academic papers, where it works particularly well.
|
| 6 |
+
|
| 7 |
+
*Note*: if the articles supplied to Grobid are large documents (e.g. dissertations) exceeding a certain number
|
| 8 |
+
of elements, they might not be processed.
|
| 9 |
+
|
| 10 |
+
This page covers how to use the Grobid to parse articles for LangChain.
|
| 11 |
+
|
| 12 |
+
## Installation
|
| 13 |
+
The grobid installation is described in details in https://grobid.readthedocs.io/en/latest/Install-Grobid/.
|
| 14 |
+
However, it is probably easier and less troublesome to run grobid through a docker container,
|
| 15 |
+
as documented [here](https://grobid.readthedocs.io/en/latest/Grobid-docker/).
|
| 16 |
+
|
| 17 |
+
## Use Grobid with LangChain
|
| 18 |
+
|
| 19 |
+
Once grobid is installed and up and running (you can check by accessing it http://localhost:8070),
|
| 20 |
+
you're ready to go.
|
| 21 |
+
|
| 22 |
+
You can now use the GrobidParser to produce documents
|
| 23 |
+
```python
|
| 24 |
+
from langchain_community.document_loaders.parsers import GrobidParser
|
| 25 |
+
from langchain_community.document_loaders.generic import GenericLoader
|
| 26 |
+
|
| 27 |
+
#Produce chunks from article paragraphs
|
| 28 |
+
loader = GenericLoader.from_filesystem(
|
| 29 |
+
"/Users/31treehaus/Desktop/Papers/",
|
| 30 |
+
glob="*",
|
| 31 |
+
suffixes=[".pdf"],
|
| 32 |
+
parser= GrobidParser(segment_sentences=False)
|
| 33 |
+
)
|
| 34 |
+
docs = loader.load()
|
| 35 |
+
|
| 36 |
+
#Produce chunks from article sentences
|
| 37 |
+
loader = GenericLoader.from_filesystem(
|
| 38 |
+
"/Users/31treehaus/Desktop/Papers/",
|
| 39 |
+
glob="*",
|
| 40 |
+
suffixes=[".pdf"],
|
| 41 |
+
parser= GrobidParser(segment_sentences=True)
|
| 42 |
+
)
|
| 43 |
+
docs = loader.load()
|
| 44 |
+
```
|
| 45 |
+
Chunk metadata will include Bounding Boxes. Although these are a bit funky to parse,
|
| 46 |
+
they are explained in https://grobid.readthedocs.io/en/latest/Coordinates-in-PDF/
|
langchain_md_files/integrations/providers/groq.mdx
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Groq
|
| 2 |
+
|
| 3 |
+
Welcome to Groq! 🚀 At Groq, we've developed the world's first Language Processing Unit™, or LPU. The Groq LPU has a deterministic, single core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.
|
| 4 |
+
|
| 5 |
+
Beyond the architecture, our software is designed to empower developers like you with the tools you need to create innovative, powerful AI applications. With Groq as your engine, you can:
|
| 6 |
+
|
| 7 |
+
* Achieve uncompromised low latency and performance for real-time AI and HPC inferences 🔥
|
| 8 |
+
* Know the exact performance and compute time for any given workload 🔮
|
| 9 |
+
* Take advantage of our cutting-edge technology to stay ahead of the competition 💪
|
| 10 |
+
|
| 11 |
+
Want more Groq? Check out our [website](https://groq.com) for more resources and join our [Discord community](https://discord.gg/JvNsBDKeCG) to connect with our developers!
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Installation and Setup
|
| 15 |
+
Install the integration package:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
pip install langchain-groq
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
Request an [API key](https://wow.groq.com) and set it as an environment variable:
|
| 22 |
+
|
| 23 |
+
```bash
|
| 24 |
+
export GROQ_API_KEY=gsk_...
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Chat Model
|
| 28 |
+
See a [usage example](/docs/integrations/chat/groq).
|
langchain_md_files/integrations/providers/gutenberg.mdx
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Gutenberg
|
| 2 |
+
|
| 3 |
+
>[Project Gutenberg](https://www.gutenberg.org/about/) is an online library of free eBooks.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
There isn't any special setup for it.
|
| 8 |
+
|
| 9 |
+
## Document Loader
|
| 10 |
+
|
| 11 |
+
See a [usage example](/docs/integrations/document_loaders/gutenberg).
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
from langchain_community.document_loaders import GutenbergLoader
|
| 15 |
+
```
|
langchain_md_files/integrations/providers/hacker_news.mdx
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hacker News
|
| 2 |
+
|
| 3 |
+
>[Hacker News](https://en.wikipedia.org/wiki/Hacker_News) (sometimes abbreviated as `HN`) is a social news
|
| 4 |
+
> website focusing on computer science and entrepreneurship. It is run by the investment fund and startup
|
| 5 |
+
> incubator `Y Combinator`. In general, content that can be submitted is defined as "anything that gratifies
|
| 6 |
+
> one's intellectual curiosity."
|
| 7 |
+
|
| 8 |
+
## Installation and Setup
|
| 9 |
+
|
| 10 |
+
There isn't any special setup for it.
|
| 11 |
+
|
| 12 |
+
## Document Loader
|
| 13 |
+
|
| 14 |
+
See a [usage example](/docs/integrations/document_loaders/hacker_news).
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
from langchain_community.document_loaders import HNLoader
|
| 18 |
+
```
|
langchain_md_files/integrations/providers/hazy_research.mdx
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hazy Research
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Hazy Research ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Hazy Research wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- To use the `manifest`, install it with `pip install manifest-ml`
|
| 8 |
+
|
| 9 |
+
## Wrappers
|
| 10 |
+
|
| 11 |
+
### LLM
|
| 12 |
+
|
| 13 |
+
There exists an LLM wrapper around Hazy Research's `manifest` library.
|
| 14 |
+
`manifest` is a python library which is itself a wrapper around many model providers, and adds in caching, history, and more.
|
| 15 |
+
|
| 16 |
+
To use this wrapper:
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.llms.manifest import ManifestWrapper
|
| 19 |
+
```
|
langchain_md_files/integrations/providers/helicone.mdx
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Helicone
|
| 2 |
+
|
| 3 |
+
This page covers how to use the [Helicone](https://helicone.ai) ecosystem within LangChain.
|
| 4 |
+
|
| 5 |
+
## What is Helicone?
|
| 6 |
+
|
| 7 |
+
Helicone is an [open-source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
## Quick start
|
| 12 |
+
|
| 13 |
+
With your LangChain environment you can just add the following parameter.
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
export OPENAI_API_BASE="https://oai.hconeai.com/v1"
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
Now head over to [helicone.ai](https://www.helicone.ai/signup) to create your account, and add your OpenAI API key within our dashboard to view your logs.
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## How to enable Helicone caching
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
from langchain_openai import OpenAI
|
| 27 |
+
import openai
|
| 28 |
+
openai.api_base = "https://oai.hconeai.com/v1"
|
| 29 |
+
|
| 30 |
+
llm = OpenAI(temperature=0.9, headers={"Helicone-Cache-Enabled": "true"})
|
| 31 |
+
text = "What is a helicone?"
|
| 32 |
+
print(llm.invoke(text))
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
[Helicone caching docs](https://docs.helicone.ai/advanced-usage/caching)
|
| 36 |
+
|
| 37 |
+
## How to use Helicone custom properties
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from langchain_openai import OpenAI
|
| 41 |
+
import openai
|
| 42 |
+
openai.api_base = "https://oai.hconeai.com/v1"
|
| 43 |
+
|
| 44 |
+
llm = OpenAI(temperature=0.9, headers={
|
| 45 |
+
"Helicone-Property-Session": "24",
|
| 46 |
+
"Helicone-Property-Conversation": "support_issue_2",
|
| 47 |
+
"Helicone-Property-App": "mobile",
|
| 48 |
+
})
|
| 49 |
+
text = "What is a helicone?"
|
| 50 |
+
print(llm.invoke(text))
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
[Helicone property docs](https://docs.helicone.ai/advanced-usage/custom-properties)
|
langchain_md_files/integrations/providers/hologres.mdx
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hologres
|
| 2 |
+
|
| 3 |
+
>[Hologres](https://www.alibabacloud.com/help/en/hologres/latest/introduction) is a unified real-time data warehousing service developed by Alibaba Cloud. You can use Hologres to write, update, process, and analyze large amounts of data in real time.
|
| 4 |
+
>`Hologres` supports standard `SQL` syntax, is compatible with `PostgreSQL`, and supports most PostgreSQL functions. Hologres supports online analytical processing (OLAP) and ad hoc analysis for up to petabytes of data, and provides high-concurrency and low-latency online data services.
|
| 5 |
+
|
| 6 |
+
>`Hologres` provides **vector database** functionality by adopting [Proxima](https://www.alibabacloud.com/help/en/hologres/latest/vector-processing).
|
| 7 |
+
>`Proxima` is a high-performance software library developed by `Alibaba DAMO Academy`. It allows you to search for the nearest neighbors of vectors. Proxima provides higher stability and performance than similar open-source software such as Faiss. Proxima allows you to search for similar text or image embeddings with high throughput and low latency. Hologres is deeply integrated with Proxima to provide a high-performance vector search service.
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
Click [here](https://www.alibabacloud.com/zh/product/hologres) to fast deploy a Hologres cloud instance.
|
| 12 |
+
|
| 13 |
+
```bash
|
| 14 |
+
pip install hologres-vector
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## Vector Store
|
| 18 |
+
|
| 19 |
+
See a [usage example](/docs/integrations/vectorstores/hologres).
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from langchain_community.vectorstores import Hologres
|
| 23 |
+
```
|
langchain_md_files/integrations/providers/html2text.mdx
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# HTML to text
|
| 2 |
+
|
| 3 |
+
>[html2text](https://github.com/Alir3z4/html2text/) is a Python package that converts a page of `HTML` into clean, easy-to-read plain `ASCII text`.
|
| 4 |
+
|
| 5 |
+
The ASCII also happens to be a valid `Markdown` (a text-to-HTML format).
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install html2text
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
## Document Transformer
|
| 14 |
+
|
| 15 |
+
See a [usage example](/docs/integrations/document_transformers/html2text).
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain_community.document_loaders import Html2TextTransformer
|
| 19 |
+
```
|
langchain_md_files/integrations/providers/huawei.mdx
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Huawei
|
| 2 |
+
|
| 3 |
+
>[Huawei Technologies Co., Ltd.](https://www.huawei.com/) is a Chinese multinational
|
| 4 |
+
> digital communications technology corporation.
|
| 5 |
+
>
|
| 6 |
+
>[Huawei Cloud](https://www.huaweicloud.com/intl/en-us/product/) provides a comprehensive suite of
|
| 7 |
+
> global cloud computing services.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Installation and Setup
|
| 11 |
+
|
| 12 |
+
To access the `Huawei Cloud`, you need an access token.
|
| 13 |
+
|
| 14 |
+
You also have to install a python library:
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
pip install -U esdk-obs-python
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Document Loader
|
| 22 |
+
|
| 23 |
+
### Huawei OBS Directory
|
| 24 |
+
|
| 25 |
+
See a [usage example](/docs/integrations/document_loaders/huawei_obs_directory).
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from langchain_community.document_loaders import OBSDirectoryLoader
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
### Huawei OBS File
|
| 32 |
+
|
| 33 |
+
See a [usage example](/docs/integrations/document_loaders/huawei_obs_file).
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from langchain_community.document_loaders.obs_file import OBSFileLoader
|
| 37 |
+
```
|
langchain_md_files/integrations/providers/ibm.mdx
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# IBM
|
| 2 |
+
|
| 3 |
+
The `LangChain` integrations related to [IBM watsonx.ai](https://www.ibm.com/products/watsonx-ai) platform.
|
| 4 |
+
|
| 5 |
+
IBM® watsonx.ai™ AI studio is part of the IBM [watsonx](https://www.ibm.com/watsonx)™ AI and data platform, bringing together new generative
|
| 6 |
+
AI capabilities powered by [foundation models](https://www.ibm.com/products/watsonx-ai/foundation-models) and traditional machine learning (ML)
|
| 7 |
+
into a powerful studio spanning the AI lifecycle. Tune and guide models with your enterprise data to meet your needs with easy-to-use tools for
|
| 8 |
+
building and refining performant prompts. With watsonx.ai, you can build AI applications in a fraction of the time and with a fraction of the data.
|
| 9 |
+
Watsonx.ai offers:
|
| 10 |
+
|
| 11 |
+
- **Multi-model variety and flexibility:** Choose from IBM-developed, open-source and third-party models, or build your own model.
|
| 12 |
+
- **Differentiated client protection:** IBM stands behind IBM-developed models and indemnifies the client against third-party IP claims.
|
| 13 |
+
- **End-to-end AI governance:** Enterprises can scale and accelerate the impact of AI with trusted data across the business, using data wherever it resides.
|
| 14 |
+
- **Hybrid, multi-cloud deployments:** IBM provides the flexibility to integrate and deploy your AI workloads into your hybrid-cloud stack of choice.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## Installation and Setup
|
| 18 |
+
|
| 19 |
+
Install the integration package with
|
| 20 |
+
```bash
|
| 21 |
+
pip install -qU langchain-ibm
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
Get an IBM watsonx.ai api key and set it as an environment variable (`WATSONX_APIKEY`)
|
| 25 |
+
```python
|
| 26 |
+
import os
|
| 27 |
+
|
| 28 |
+
os.environ["WATSONX_APIKEY"] = "your IBM watsonx.ai api key"
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Chat Model
|
| 32 |
+
|
| 33 |
+
### ChatWatsonx
|
| 34 |
+
|
| 35 |
+
See a [usage example](/docs/integrations/chat/ibm_watsonx).
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from langchain_ibm import ChatWatsonx
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## LLMs
|
| 42 |
+
|
| 43 |
+
### WatsonxLLM
|
| 44 |
+
|
| 45 |
+
See a [usage example](/docs/integrations/llms/ibm_watsonx).
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from langchain_ibm import WatsonxLLM
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Embedding Models
|
| 52 |
+
|
| 53 |
+
### WatsonxEmbeddings
|
| 54 |
+
|
| 55 |
+
See a [usage example](/docs/integrations/text_embedding/ibm_watsonx).
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
from langchain_ibm import WatsonxEmbeddings
|
| 59 |
+
```
|
langchain_md_files/integrations/providers/ieit_systems.mdx
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# IEIT Systems
|
| 2 |
+
|
| 3 |
+
>[IEIT Systems](https://en.ieisystem.com/) is a Chinese information technology company
|
| 4 |
+
> established in 1999. It provides the IT infrastructure products, solutions,
|
| 5 |
+
> and services, innovative IT products and solutions across cloud computing,
|
| 6 |
+
> big data, and artificial intelligence.
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## LLMs
|
| 10 |
+
|
| 11 |
+
See a [usage example](/docs/integrations/llms/yuan2).
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
from langchain_community.llms.yuan2 import Yuan2
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## Chat models
|
| 18 |
+
|
| 19 |
+
See the [installation instructions](/docs/integrations/chat/yuan2/#setting-up-your-api-server).
|
| 20 |
+
|
| 21 |
+
Yuan2.0 provided an OpenAI compatible API, and ChatYuan2 is integrated into langchain by using `OpenAI client`.
|
| 22 |
+
Therefore, ensure the `openai` package is installed.
|
| 23 |
+
|
| 24 |
+
```bash
|
| 25 |
+
pip install openai
|
| 26 |
+
```
|
| 27 |
+
See a [usage example](/docs/integrations/chat/yuan2).
|
| 28 |
+
|
| 29 |
+
```python
|
| 30 |
+
from langchain_community.chat_models import ChatYuan2
|
| 31 |
+
```
|
langchain_md_files/integrations/providers/ifixit.mdx
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# iFixit
|
| 2 |
+
|
| 3 |
+
>[iFixit](https://www.ifixit.com) is the largest, open repair community on the web. The site contains nearly 100k
|
| 4 |
+
> repair manuals, 200k Questions & Answers on 42k devices, and all the data is licensed under `CC-BY-NC-SA 3.0`.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
There isn't any special setup for it.
|
| 9 |
+
|
| 10 |
+
## Document Loader
|
| 11 |
+
|
| 12 |
+
See a [usage example](/docs/integrations/document_loaders/ifixit).
|
| 13 |
+
|
| 14 |
+
```python
|
| 15 |
+
from langchain_community.document_loaders import IFixitLoader
|
| 16 |
+
```
|
langchain_md_files/integrations/providers/iflytek.mdx
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# iFlytek
|
| 2 |
+
|
| 3 |
+
>[iFlytek](https://www.iflytek.com) is a Chinese information technology company
|
| 4 |
+
> established in 1999. It creates voice recognition software and
|
| 5 |
+
> voice-based internet/mobile products covering education, communication,
|
| 6 |
+
> music, intelligent toys industries.
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Installation and Setup
|
| 10 |
+
|
| 11 |
+
- Get `SparkLLM` app_id, api_key and api_secret from [iFlyTek SparkLLM API Console](https://console.xfyun.cn/services/bm3) (for more info, see [iFlyTek SparkLLM Intro](https://xinghuo.xfyun.cn/sparkapi)).
|
| 12 |
+
- Install the Python package (not for the embedding models):
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
pip install websocket-client
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
## LLMs
|
| 19 |
+
|
| 20 |
+
See a [usage example](/docs/integrations/llms/sparkllm).
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from langchain_community.llms import SparkLLM
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
## Chat models
|
| 27 |
+
|
| 28 |
+
See a [usage example](/docs/integrations/chat/sparkllm).
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
from langchain_community.chat_models import ChatSparkLLM
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## Embedding models
|
| 35 |
+
|
| 36 |
+
```python
|
| 37 |
+
from langchain_community.embeddings import SparkLLMTextEmbeddings
|
| 38 |
+
```
|
langchain_md_files/integrations/providers/imsdb.mdx
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# IMSDb
|
| 2 |
+
|
| 3 |
+
>[IMSDb](https://imsdb.com/) is the `Internet Movie Script Database`.
|
| 4 |
+
>
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
There isn't any special setup for it.
|
| 8 |
+
|
| 9 |
+
## Document Loader
|
| 10 |
+
|
| 11 |
+
See a [usage example](/docs/integrations/document_loaders/imsdb).
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
```python
|
| 15 |
+
from langchain_community.document_loaders import IMSDbLoader
|
| 16 |
+
```
|
langchain_md_files/integrations/providers/infinispanvs.mdx
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Infinispan VS
|
| 2 |
+
|
| 3 |
+
> [Infinispan](https://infinispan.org) Infinispan is an open-source in-memory data grid that provides
|
| 4 |
+
> a key/value data store able to hold all types of data, from Java objects to plain text.
|
| 5 |
+
> Since version 15 Infinispan supports vector search over caches.
|
| 6 |
+
|
| 7 |
+
## Installation and Setup
|
| 8 |
+
See [Get Started](https://infinispan.org/get-started/) to run an Infinispan server, you may want to disable authentication
|
| 9 |
+
(not supported atm)
|
| 10 |
+
|
| 11 |
+
## Vector Store
|
| 12 |
+
|
| 13 |
+
See a [usage example](/docs/integrations/vectorstores/infinispanvs).
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from langchain_community.vectorstores import InfinispanVS
|
| 17 |
+
```
|
langchain_md_files/integrations/providers/infinity.mdx
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Infinity
|
| 2 |
+
|
| 3 |
+
>[Infinity](https://github.com/michaelfeil/infinity) allows the creation of text embeddings.
|
| 4 |
+
|
| 5 |
+
## Text Embedding Model
|
| 6 |
+
|
| 7 |
+
There exists an infinity Embedding model, which you can access with
|
| 8 |
+
```python
|
| 9 |
+
from langchain_community.embeddings import InfinityEmbeddings
|
| 10 |
+
```
|
| 11 |
+
For a more detailed walkthrough of this, see [this notebook](/docs/integrations/text_embedding/infinity)
|
langchain_md_files/integrations/providers/infino.mdx
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Infino
|
| 2 |
+
|
| 3 |
+
>[Infino](https://github.com/infinohq/infino) is an open-source observability platform that stores both metrics and application logs together.
|
| 4 |
+
|
| 5 |
+
Key features of `Infino` include:
|
| 6 |
+
- **Metrics Tracking**: Capture time taken by LLM model to handle request, errors, number of tokens, and costing indication for the particular LLM.
|
| 7 |
+
- **Data Tracking**: Log and store prompt, request, and response data for each LangChain interaction.
|
| 8 |
+
- **Graph Visualization**: Generate basic graphs over time, depicting metrics such as request duration, error occurrences, token count, and cost.
|
| 9 |
+
|
| 10 |
+
## Installation and Setup
|
| 11 |
+
|
| 12 |
+
First, you'll need to install the `infinopy` Python package as follows:
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
pip install infinopy
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
If you already have an `Infino Server` running, then you're good to go; but if
|
| 19 |
+
you don't, follow the next steps to start it:
|
| 20 |
+
|
| 21 |
+
- Make sure you have Docker installed
|
| 22 |
+
- Run the following in your terminal:
|
| 23 |
+
```
|
| 24 |
+
docker run --rm --detach --name infino-example -p 3000:3000 infinohq/infino:latest
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Using Infino
|
| 30 |
+
|
| 31 |
+
See a [usage example of `InfinoCallbackHandler`](/docs/integrations/callbacks/infino).
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
from langchain.callbacks import InfinoCallbackHandler
|
| 35 |
+
```
|
langchain_md_files/integrations/providers/intel.mdx
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Intel
|
| 2 |
+
|
| 3 |
+
>[Optimum Intel](https://github.com/huggingface/optimum-intel?tab=readme-ov-file#optimum-intel) is the interface between the 🤗 Transformers and Diffusers libraries and the different tools and libraries provided by Intel to accelerate end-to-end pipelines on Intel architectures.
|
| 4 |
+
|
| 5 |
+
>[Intel® Extension for Transformers](https://github.com/intel/intel-extension-for-transformers?tab=readme-ov-file#intel-extension-for-transformers) (ITREX) is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU.
|
| 6 |
+
|
| 7 |
+
This page covers how to use optimum-intel and ITREX with LangChain.
|
| 8 |
+
|
| 9 |
+
## Optimum-intel
|
| 10 |
+
|
| 11 |
+
All functionality related to the [optimum-intel](https://github.com/huggingface/optimum-intel.git) and [IPEX](https://github.com/intel/intel-extension-for-pytorch).
|
| 12 |
+
|
| 13 |
+
### Installation
|
| 14 |
+
|
| 15 |
+
Install using optimum-intel and ipex using:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
pip install optimum[neural-compressor]
|
| 19 |
+
pip install intel_extension_for_pytorch
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
Please follow the installation instructions as specified below:
|
| 23 |
+
|
| 24 |
+
* Install optimum-intel as shown [here](https://github.com/huggingface/optimum-intel).
|
| 25 |
+
* Install IPEX as shown [here](https://intel.github.io/intel-extension-for-pytorch/index.html#installation?platform=cpu&version=v2.2.0%2Bcpu).
|
| 26 |
+
|
| 27 |
+
### Embedding Models
|
| 28 |
+
|
| 29 |
+
See a [usage example](/docs/integrations/text_embedding/optimum_intel).
|
| 30 |
+
We also offer a full tutorial notebook "rag_with_quantized_embeddings.ipynb" for using the embedder in a RAG pipeline in the cookbook dir.
|
| 31 |
+
|
| 32 |
+
```python
|
| 33 |
+
from langchain_community.embeddings import QuantizedBiEncoderEmbeddings
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
## Intel® Extension for Transformers (ITREX)
|
| 37 |
+
(ITREX) is an innovative toolkit to accelerate Transformer-based models on Intel platforms, in particular, effective on 4th Intel Xeon Scalable processor Sapphire Rapids (codenamed Sapphire Rapids).
|
| 38 |
+
|
| 39 |
+
Quantization is a process that involves reducing the precision of these weights by representing them using a smaller number of bits. Weight-only quantization specifically focuses on quantizing the weights of the neural network while keeping other components, such as activations, in their original precision.
|
| 40 |
+
|
| 41 |
+
As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computational demands of these modern architectures while maintaining the accuracy. Compared to [normal quantization](https://github.com/intel/intel-extension-for-transformers/blob/main/docs/quantization.md) like W8A8, weight only quantization is probably a better trade-off to balance the performance and the accuracy, since we will see below that the bottleneck of deploying LLMs is the memory bandwidth and normally weight only quantization could lead to better accuracy.
|
| 42 |
+
|
| 43 |
+
Here, we will introduce Embedding Models and Weight-only quantization for Transformers large language models with ITREX. Weight-only quantization is a technique used in deep learning to reduce the memory and computational requirements of neural networks. In the context of deep neural networks, the model parameters, also known as weights, are typically represented using floating-point numbers, which can consume a significant amount of memory and require intensive computational resources.
|
| 44 |
+
|
| 45 |
+
All functionality related to the [intel-extension-for-transformers](https://github.com/intel/intel-extension-for-transformers).
|
| 46 |
+
|
| 47 |
+
### Installation
|
| 48 |
+
|
| 49 |
+
Install intel-extension-for-transformers. For system requirements and other installation tips, please refer to [Installation Guide](https://github.com/intel/intel-extension-for-transformers/blob/main/docs/installation.md)
|
| 50 |
+
|
| 51 |
+
```bash
|
| 52 |
+
pip install intel-extension-for-transformers
|
| 53 |
+
```
|
| 54 |
+
Install other required packages.
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
pip install -U torch onnx accelerate datasets
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
### Embedding Models
|
| 61 |
+
|
| 62 |
+
See a [usage example](/docs/integrations/text_embedding/itrex).
|
| 63 |
+
|
| 64 |
+
```python
|
| 65 |
+
from langchain_community.embeddings import QuantizedBgeEmbeddings
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
### Weight-Only Quantization with ITREX
|
| 69 |
+
|
| 70 |
+
See a [usage example](/docs/integrations/llms/weight_only_quantization).
|
| 71 |
+
|
| 72 |
+
## Detail of Configuration Parameters
|
| 73 |
+
|
| 74 |
+
Here is the detail of the `WeightOnlyQuantConfig` class.
|
| 75 |
+
|
| 76 |
+
#### weight_dtype (string): Weight Data Type, default is "nf4".
|
| 77 |
+
We support quantize the weights to following data types for storing(weight_dtype in WeightOnlyQuantConfig):
|
| 78 |
+
* **int8**: Uses 8-bit data type.
|
| 79 |
+
* **int4_fullrange**: Uses the -8 value of int4 range compared with the normal int4 range [-7,7].
|
| 80 |
+
* **int4_clip**: Clips and retains the values within the int4 range, setting others to zero.
|
| 81 |
+
* **nf4**: Uses the normalized float 4-bit data type.
|
| 82 |
+
* **fp4_e2m1**: Uses regular float 4-bit data type. "e2" means that 2 bits are used for the exponent, and "m1" means that 1 bits are used for the mantissa.
|
| 83 |
+
|
| 84 |
+
#### compute_dtype (string): Computing Data Type, Default is "fp32".
|
| 85 |
+
While these techniques store weights in 4 or 8 bit, the computation still happens in float32, bfloat16 or int8(compute_dtype in WeightOnlyQuantConfig):
|
| 86 |
+
* **fp32**: Uses the float32 data type to compute.
|
| 87 |
+
* **bf16**: Uses the bfloat16 data type to compute.
|
| 88 |
+
* **int8**: Uses 8-bit data type to compute.
|
| 89 |
+
|
| 90 |
+
#### llm_int8_skip_modules (list of module's name): Modules to Skip Quantization, Default is None.
|
| 91 |
+
It is a list of modules to be skipped quantization.
|
| 92 |
+
|
| 93 |
+
#### scale_dtype (string): The Scale Data Type, Default is "fp32".
|
| 94 |
+
Now only support "fp32"(float32).
|
| 95 |
+
|
| 96 |
+
#### mse_range (boolean): Whether to Search for The Best Clip Range from Range [0.805, 1.0, 0.005], default is False.
|
| 97 |
+
#### use_double_quant (boolean): Whether to Quantize Scale, Default is False.
|
| 98 |
+
Not support yet.
|
| 99 |
+
#### double_quant_dtype (string): Reserve for Double Quantization.
|
| 100 |
+
#### double_quant_scale_dtype (string): Reserve for Double Quantization.
|
| 101 |
+
#### group_size (int): Group Size When Auantization.
|
| 102 |
+
#### scheme (string): Which Format Weight Be Quantize to. Default is "sym".
|
| 103 |
+
* **sym**: Symmetric.
|
| 104 |
+
* **asym**: Asymmetric.
|
| 105 |
+
#### algorithm (string): Which Algorithm to Improve the Accuracy . Default is "RTN"
|
| 106 |
+
* **RTN**: Round-to-nearest (RTN) is a quantification method that we can think of very intuitively.
|
| 107 |
+
* **AWQ**: Protecting only 1% of salient weights can greatly reduce quantization error. the salient weight channels are selected by observing the distribution of activation and weight per channel. The salient weights are also quantized after multiplying a big scale factor before quantization for preserving. .
|
| 108 |
+
* **TEQ**: A trainable equivalent transformation that preserves the FP32 precision in weight-only quantization.
|