
Generation procedure
The dataset was constructed using documents from the Pile scored using using Perspective API toxicity scores.
The procedure was the following:
- A chunk of the Pile (3%, 7m documents) was scored using the Perspective API.
- The first half of this dataset is tomekkorbak/pile-toxic-chunk-0, 100k most toxic documents of the scored chunk
- The first half of this dataset is tomekkorbak/pile-nontoxic-chunk-0, 100k least toxic documents of the scored chunk
- Then, the dataset was shuffled and a 9:1 train-test split was done
Basic stats
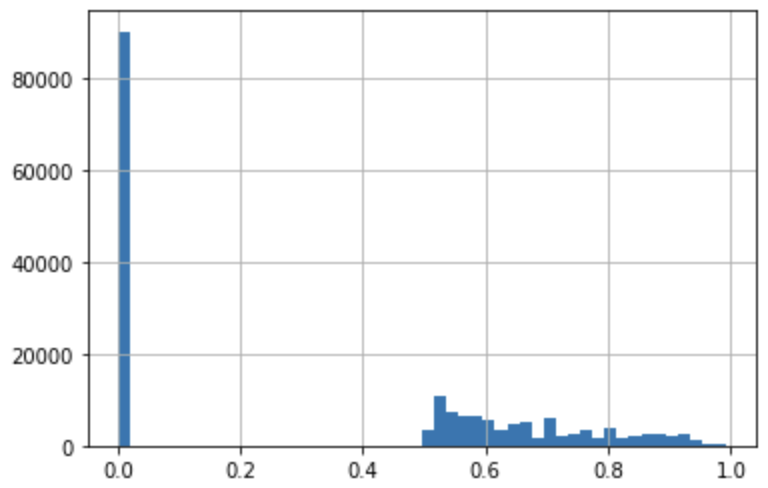
The average scores of the good and bad half are 0.0014 and 0.67, respectively. The average score of the whole dataset is 0.33; the median is 0.51.
However, the weighted average score (weighted by document length) is 0.45. Correlation between score and document length is 0.2.
Score histogram:
Mean score per Pile subset
| pile_set_name | score | length |
|---|---|---|
| ArXiv | 0.141808 | 9963.82 |
| Books3 | 0.405541 | 8911.67 |
| DM Mathematics | 0.535474 | 8194 |
| Enron Emails | 0.541136 | 1406.76 |
| EuroParl | 0.373395 | 4984.36 |
| FreeLaw | 0.279582 | 8986.73 |
| Github | 0.495742 | 2184.86 |
| Gutenberg (PG-19) | 0.583263 | 4034 |
| HackerNews | 0.617917 | 3714.83 |
| NIH ExPorter | 0.0376628 | 1278.83 |
| OpenSubtitles | 0.674261 | 14881.1 |
| OpenWebText2 | 0.613273 | 2634.41 |
| PhilPapers | 0.549582 | 9693 |
| Pile-CC | 0.525136 | 2925.7 |
| PubMed Abstracts | 0.0388705 | 1282.29 |
| PubMed Central | 0.235012 | 7418.34 |
| StackExchange | 0.590904 | 2210.16 |
| USPTO Backgrounds | 0.0100077 | 2086.39 |
| Ubuntu IRC | 0.598423 | 4396.67 |
| Wikipedia (en) | 0.0136901 | 1515.89 |
| YoutubeSubtitles | 0.65201 | 4729.52 |