

non-commercial licence: CC BY-NC-ND 4.0
license: cc-by-nc-nd-4.0
MAP-CC
🌐 Homepage | 🤗 MAP-CC | 🤗 CHC-Bench | 🤗 CT-LLM | 📖 arXiv | GitHub
An open-source Chinese pretraining dataset with a scale of 800 billion tokens, offering the NLP community high-quality Chinese pretraining data.
Disclaimer
This model, developed for academic purposes, employs rigorously compliance-checked training data to uphold the highest standards of integrity and compliance. Despite our efforts, the inherent complexities of data and the broad spectrum of model applications prevent us from ensuring absolute accuracy or appropriateness of the model outputs in every scenario.
It is essential to highlight that our model and its associated training data are intended solely for scholarly research. We explicitly disclaim any liability for problems that may arise from improper use, interpretation errors, unlawful activities, the dissemination of false information, or any data security issues related to the utilization of our model or its training data.
We strongly encourage users to report any concerns related to data misuse, security breaches, or potential infringement issues directly to us for immediate investigation and resolution.
Contact: {ge.zhang@uwaterloo.ca; duxinrun2000@gmail.com}
Our commitment to responsible data sharing and the security of our academic tools is paramount. We thank you for your cooperation in maintaining the ethical use of this technology.
License
The MAP-CC Dataset is made available under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (CC BY-NC-ND 4.0).
By using the MAP-CC Dataset, you accept and agree to be bound by the terms and conditions of the CC BY-NC-ND 4.0 License. This license allows users to share (copy and redistribute the material in any medium or format) the MAP-CC Dataset for non-commercial purposes only, and with no modifications or derivatives, as long as proper attribution is given to the creators. For further details, please refer to the LICENSE file.
We chose the CC BY-NC-ND 4.0 License for the MAP-CC Dataset to facilitate academic and educational use, promoting the spread of knowledge while protecting the work of the creators from unauthorized commercial use or modification.
Usage Instructions
After downloading the parts of the dataset, you can concatenate them into a single file for each split of the dataset using the following command in a UNIX-like terminal:
cat [split].gz.part* > [split].gz
Replace [split] with the name of the dataset component you wish to merge (zh-cc, zh-baike, zh-papers, zh-books, or zh-others). After merging, decompress the .gz file to access the dataset's content.
Dataset Composition
The dataset consists of several components, each originating from different sources and serving various purposes in language modeling and processing. Below is a brief overview of each component:
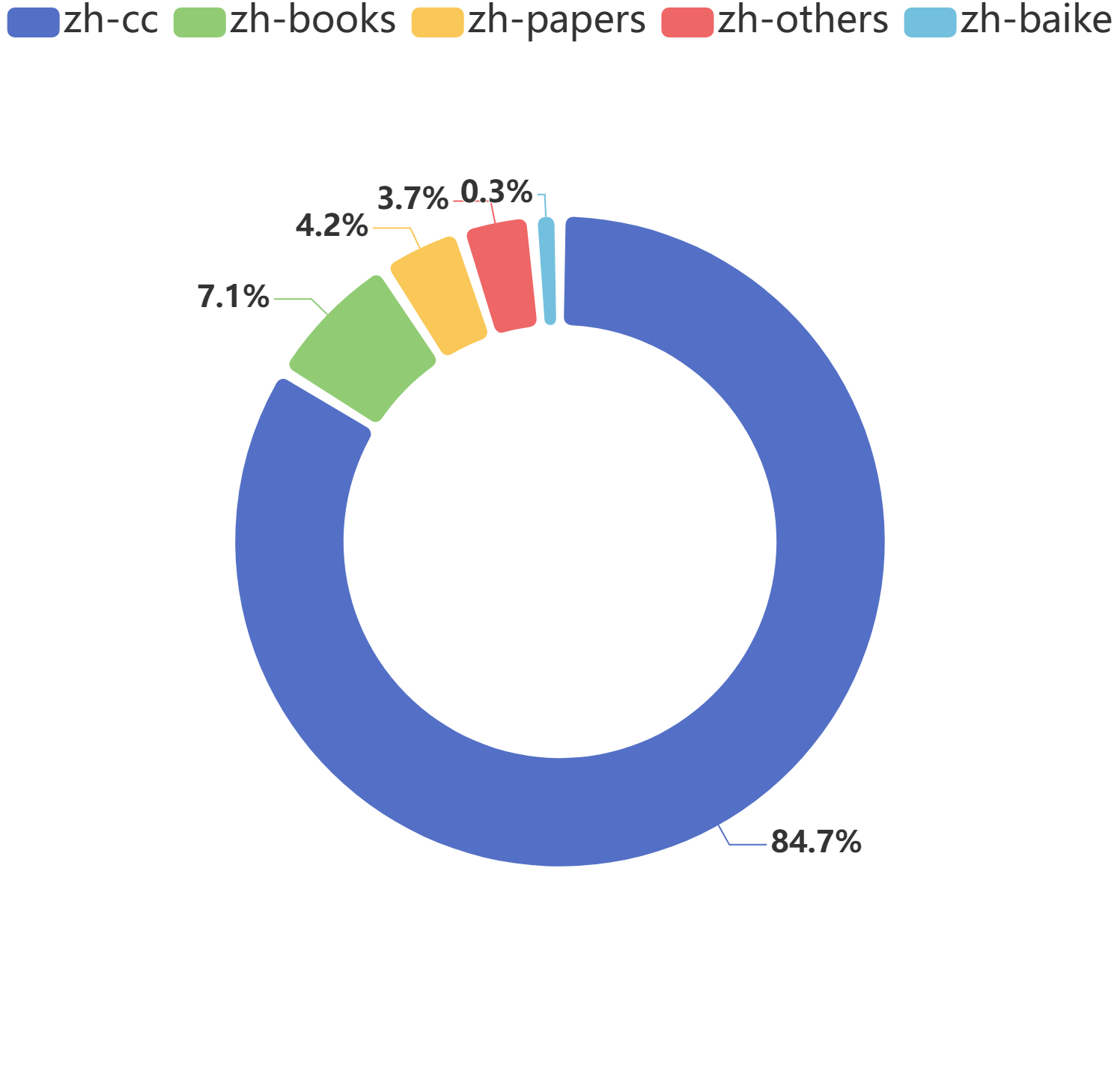 zh-cc (Chinese Common Crawl)
zh-cc (Chinese Common Crawl)
Extracts from the Common Crawl project specifically filtered for Chinese content. This component is rich in diverse internet text, ranging from websites, blogs, news articles, and more.
zh-baike (Chinese Encyclopedias)
A collection of articles from various Chinese encyclopedias, similar to Wikipedia but including other encyclopedic sources as well.
zh-papers (Chinese Academic Papers)
This component consists of academic and research papers published in Chinese. It covers a wide range of disciplines and offers technical, domain-specific language.
zh-books (Chinese Books)
Comprises texts extracted from books published in Chinese. This includes literature, non-fiction, textbooks, and more.
zh-others
This category is a collection of miscellaneous texts, notably including a substantial amount of QA (Question and Answer) data, alongside a variety of other texts.
Citation
@misc{du2024chinesetinyllmpretraining,
title={Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model},
author={Xinrun Du and Zhouliang Yu and Songyang Gao and Ding Pan and Yuyang Cheng and Ziyang Ma and Ruibin Yuan and Xingwei Qu and Jiaheng Liu and Tianyu Zheng and Xinchen Luo and Guorui Zhou and Wenhu Chen and Ge Zhang},
year={2024},
eprint={2404.04167},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.04167},
}