Datasets:

license: cc-by-4.0
OLID-BR
Offensive Language Identification Dataset for Brazilian Portuguese (OLID-BR) is a dataset with multi-task annotations for the detection of offensive language.
The current version (v1.0) contains 7,943 (extendable to 13,538) comments from different sources, including social media (YouTube and Twitter) and related datasets.
OLID-BR contains a collection of annotated sentences in Brazilian Portuguese using an annotation model that encompasses the following levels:
- Offensive content detection: Detect offensive content in sentences and categorize it.
- Offense target identification: Detect if an offensive sentence is targeted to a person or group of people.
- Offensive spans identification: Detect curse words in sentences.
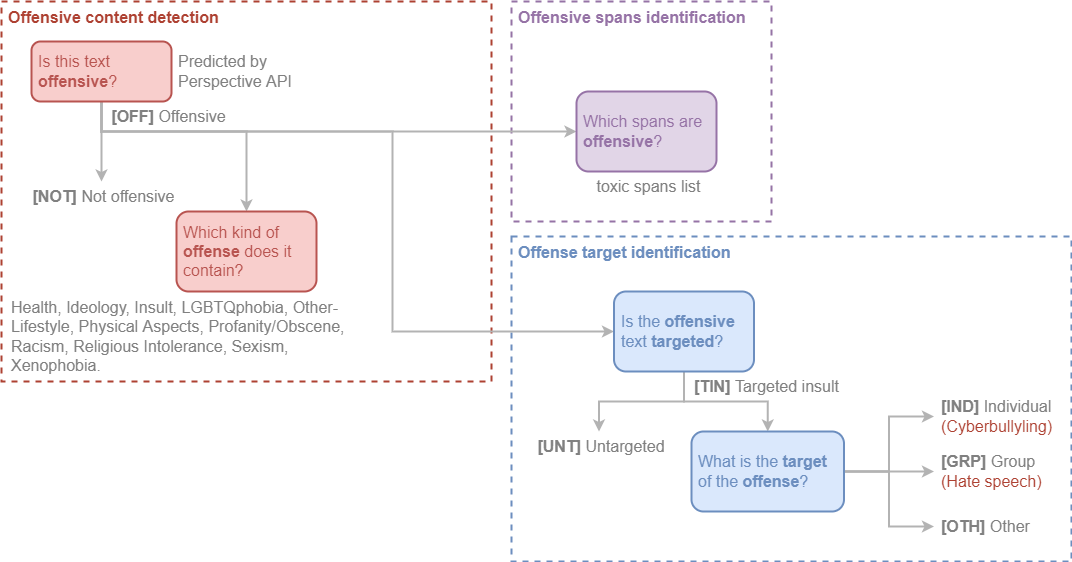
Categorization
Offensive Content Detection
This level is used to detect offensive content in the sentence.
Is this text offensive?
We use the Perspective API to detect if the sentence contains offensive content with double-checking by our qualified annotators.
OFFOffensive: Inappropriate language, insults, or threats.NOTNot offensive: No offense or profanity.
Which kind of offense does it contain?
The following labels were tagged by our annotators:
Health, Ideology, Insult, LGBTQphobia, Other-Lifestyle, Physical Aspects, Profanity/Obscene, Racism, Religious Intolerance, Sexism, and Xenophobia.
See the Glossary for further information.
Offense Target Identification
This level is used to detect if an offensive sentence is targeted to a person or group of people.
Is the offensive text targeted?
TINTargeted Insult: Targeted insult or threat towards an individual, a group or other.UNTUntargeted: Non-targeted profanity and swearing.
What is the target of the offense?
INDThe offense targets an individual, often defined as “cyberbullying”.GRPThe offense targets a group of people based on ethnicity, gender, sexualOTHThe target can belong to other categories, such as an organization, an event, an issue, etc.
Offensive Spans Identification
As toxic spans, we define a sequence of words that attribute to the text's toxicity.
For example, let's consider the following text:
"USER
CanalhaURL"
The toxic spans are:
[5, 6, 7, 8, 9, 10, 11, 12, 13]
Dataset Structure
Data Instances
Each instance is a social media comment with a corresponding ID and annotations for all the tasks described below.
Data Fields
The simplified configuration includes:
id(string): Unique identifier of the instance.text(string): The text of the instance.is_offensive(string): Whether the text is offensive (OFF) or not (NOT).is_targeted(string): Whether the text is targeted (TIN) or untargeted (UNT).targeted_type(string): Type of the target (individualIND, groupGRP, or otherOTH). Only available ifis_targetedisTrue.toxic_spans(string): List of toxic spans.health(boolean): Whether the text contains hate speech based on health conditions such as disability, disease, etc.ideology(boolean): Indicates if the text contains hate speech based on a person's ideas or beliefs.insult(boolean): Whether the text contains insult, inflammatory, or provocative content.lgbtqphobia(boolean): Whether the text contains harmful content related to gender identity or sexual orientation.other_lifestyle(boolean): Whether the text contains hate speech related to life habits (e.g. veganism, vegetarianism, etc.).physical_aspects(boolean): Whether the text contains hate speech related to physical appearance.profanity_obscene(boolean): Whether the text contains profanity or obscene content.racism(boolean): Whether the text contains prejudiced thoughts or discriminatory actions based on differences in race/ethnicity.religious_intolerance(boolean): Whether the text contains religious intolerance.sexism(boolean): Whether the text contains discriminatory content based on differences in sex/gender (e.g. sexism, misogyny, etc.).xenophobia(boolean): Whether the text contains hate speech against foreigners.
See the Get Started page for more information.
Considerations for Using the Data
Social Impact of Dataset
Toxicity detection is a worthwhile problem that can ensure a safer online environment for everyone.
However, toxicity detection algorithms have focused on English and do not consider the specificities of other languages.
This is a problem because the toxicity of a comment can be different in different languages.
Additionally, the toxicity detection algorithms focus on the binary classification of a comment as toxic or not toxic.
Therefore, we believe that the OLID-BR dataset can help to improve the performance of toxicity detection algorithms in Brazilian Portuguese.
Discussion of Biases
We are aware that the dataset contains biases and is not representative of global diversity.
We are aware that the language used in the dataset could not represent the language used in different contexts.
Potential biases in the data include: Inherent biases in the social media and user base biases, the offensive/vulgar word lists used for data filtering, and inherent or unconscious bias in the assessment of offensive identity labels.
All these likely affect labeling, precision, and recall for a trained model.
Citation
Pending