
license: cc-by-4.0
language:
- en
tags:
- medical
- MRI
- spine
- image segmentation
- computer vision
size_categories:
- n<1K
pretty_name: 'SPIDER: Spine MRI Segmentation'
Spine Segmentation: Discs, Vertebrae and Spinal Canal (SPIDER)
The SPIDER dataset contains (human) lumbar spine magnetic resonance images (MRI) and segmentation masks described in the following paper:
- van der Graaf, J.W., van Hooff, M.L., Buckens, C.F.M. et al. Lumbar spine segmentation in MR images: a dataset and a public benchmark. Sci Data 11, 264 (2024). https://doi.org/10.1038/s41597-024-03090-w
Original data are available on Zenodo. More information can be found at SPIDER Grand Challenge.
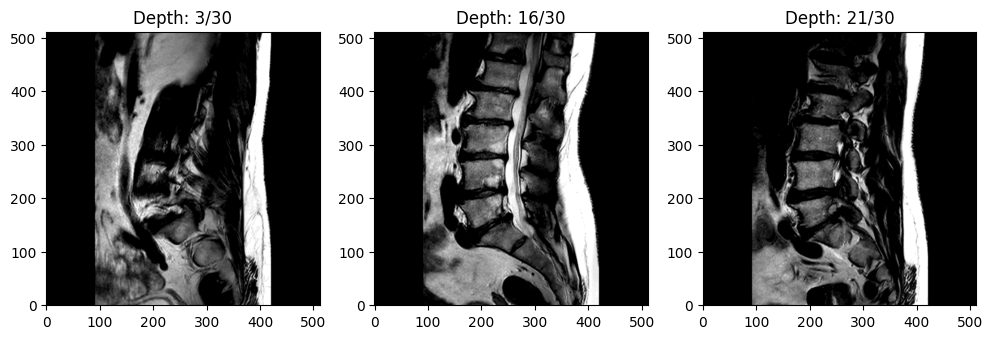
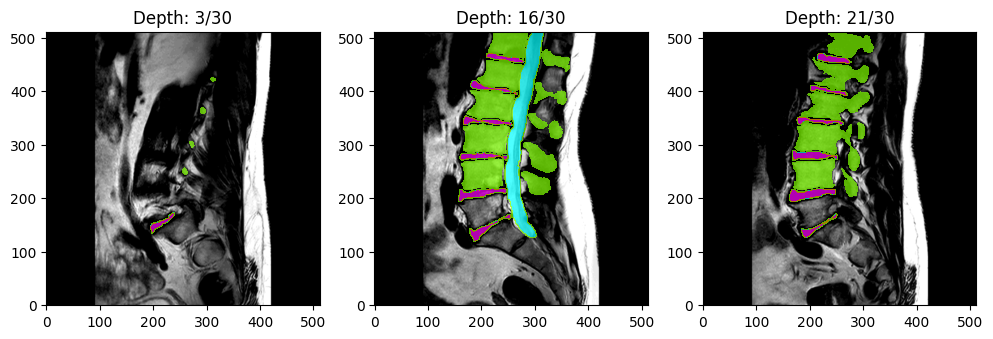
Dataset Description
- Published Paper: Lumbar spine segmentation in MR images: a dataset and a public benchmark
- ArXiv Link: https://arxiv.org/abs/2306.12217
- Repository: Zenodo
- Grand Challenge: SPIDER Grand Challenge
Tutorials
In addition to the information in this README, several detailed tutorials are provided in the tutorials folder:
Table of Contents (TOC)
Getting Started
First, you will need to install the following dependencies:
datasets >= 2.18.0scikit-image >= 0.19.3SimpleITK >= 2.3.1
Then you can load the SPIDER dataset as follows:
from datasets import load_dataset
dataset = load_dataset("cdoswald/SPIDER, name="default", trust_remote_code=True)
See the Loading the Dataset tutorial for more information.
Dataset Summary
The dataset includes 447 sagittal T1 and T2 MRI series collected from 218 patients across four hospitals. Segmentation masks indicating the vertebrae, intervertebral discs (IVDs), and spinal canal are also included. Segmentation masks were created manually by a medical trainee under the supervision of a medical imaging expert and an experienced musculoskeletal radiologist.
In addition to MR images and segmentation masks, additional metadata (e.g., scanner manufacturer, pixel bandwidth, etc.), limited patient characteristics (biological sex and age, when available), and radiological gradings indicating specific degenerative changes can be loaded with the corresponding image data.
Data Modifications
This version of the SPIDER dataset (i.e., available through the HuggingFace datasets library) differs from the original
data available on Zenodo in two key ways:
Image Rescaling/Resizing: The original 3D volumetric MRI data (images and masks) are stored as .mha files and do not have a standardized height, width, depth, and image resolution. To enable the data to be loaded through the HuggingFace
datasetslibrary, all 447 MRI series and masks are standardized to have size(512, 512, 30)and resolution[0, 255](unisgned 8-bit integers); therefore, n-dimensional interpolation is used to resize and/or rescale the images (via theskimage.transform.resizeandskimage.img_as_ubytefunctions). If you need a different standardization, you have two options:i. Pass your preferred standardization size as a
Tuple[int, int, int]to theresize_shapeargument inload_dataset(see the LoadData Tutorial); ORii. After loading the dataset from HuggingFace, use the
SimpleITKlibrary to import each image using the file path of the locally cached .mha file. The local cache file path is provided for each example when iterating over the dataset (again, see the LoadData Tutorial).Train, Validation, and Test Set: The original dataset contained 257 unique studies (i.e., patients) that were partitioned into 218 (85%) studies for the public training/validation set and 39 (15%) studies for the SPIDER Grand Challenge hidden test set. To enable users to train, validate, and test their models prior to submitting their models to the SPIDER Grand Challenge, the original 218 studies that comprised the public training/validation set were further partitioned using a 60%/20%/20% split. The original split for each study (i.e., training or validation set) is recorded in the
OrigSubsetvariable in the study's linked metadata.
Dataset Structure
Data Instances
There are 447 images and corresponding segmentation masks for 218 unique patients.
Data Schema
The format for each generated data instance is as follows:
patient_id: a unique ID number indicating the specific patient (note that many patients have more than one scan in the data)
scan_type: an indicator for whether the image is a T1-weighted, T2-weighted, or T2-SPACE MRI
image: a 3-dimensional volumetric array (height, width, depth) of values indicating pixel intensities of MRI scan
mask: a 3-dimensional volumetric array (height, width, depth) of values indicating the following segmented anatomical feature(s):
- 0 = background
- 1-25 = vertebrae (numbered from the bottom, i.e., L5 = 1)
- 100 = spinal canal
- 101-125 = partially visible vertebrae
- 201-225 = intervertebral discs (numbered from the bottom, i.e., L5/S1 = 201)
See the SPIDER Grand Challenge documentation for more details.
image_path: path to the local cache containing the original (non-rescaled and non-resized) MRI image
mask_path: path to the local cache containing the original (non-rescaled and non-resized) segementation mask
metadata: a dictionary of metadata of image, patient, and scanner characteristics:
- number of vertebrae
- number of discs
- biological sex
- age
- manufacturer
- manufacturer model name
- serial number
- software version
- echo numbers
- echo time
- echo train length
- flip angle
- imaged nucleus
- imaging frequency
- inplane phase encoding direction
- MR acquisition type
- magnetic field strength
- number of phase encoding steps
- percent phase field of view
- percent sampling
- photometric interpretation
- pixel bandwidth
- pixel spacing
- repetition time
- specific absorption rate (SAR)
- samples per pixel
- scanning sequence
- sequence name
- series description
- slice thickness
- spacing between slices
- specific character set
- transmit coil name
- window center
- window width
rad_gradings: radiological gradings by an expert musculoskeletal radiologist indicating specific degenerative changes at all intervertebral disc (IVD) levels (see page 3 of the original paper for more details). The data are provided as a dictionary of lists; an element's position in the list indicates the IVD level. Some elements are ratings while others are binary indicators. For consistency, each list will have 10 elements, but some IVD levels may not be applicable to every image (which will be indicated with an empty string).
Data Splits
The dataset is split as follows:
- Training set:
- 149 unique patients
- 304 total images
- Sagittal T1: 133 images
- Sagittal T2: 145 images
- Sagittal T2-SPACE: 26 images
- Validation set:
- 37 unique patients
- 75 total images
- Sagittal T1: 34 images
- Sagittal T2: 34 images
- Sagittal T2-SPACE: 7 images
- Test set:
- 32 unique patients
- 68 total images
- Sagittal T1: 29 images
- Sagittal T2: 31 images
- Sagittal T2-SPACE: 8 images
An additional hidden test set provided by the paper authors (i.e., not available via HuggingFace) is available on the SPIDER Grand Challenge.
Image Resolution
Standard sagittal T1 and T2 image resolution ranges from 3.3 x 0.33 x 0.33 mm to 4.8 x 0.90 x 0.90 mm. Sagittal T2 SPACE sequence images had a near isotropic spatial resolution with a voxel size of 0.90 x 0.47 x 0.47 mm. (https://spider.grand-challenge.org/data/)
Note that all images are rescaled to have pixel intensities in the range [0, 255] (i.e., unsigned 8-bit integers)
for compatibility with the HuggingFace datasets library. If you want to use the original resolution, you can
load the original images from the local cache indicated in each example's image_path and mask_path features.
See the tutorial for more information.
Additional Information
License
The dataset is published under a CC-BY 4.0 license: https://creativecommons.org/licenses/by/4.0/legalcode.
Citation
- van der Graaf, J.W., van Hooff, M.L., Buckens, C.F.M. et al. Lumbar spine segmentation in MR images: a dataset and a public benchmark. Sci Data 11, 264 (2024). https://doi.org/10.1038/s41597-024-03090-w.
Disclaimer
I am not affiliated in any way with the aforementioned paper, researchers, or organizations. Please validate any findings using this curated dataset against the original data provided by the researchers on Zenodo.)
Known Issues/Bugs
- Serializing data into Apache Arrow format is required to make the dataset available via HuggingFace's
datasetslibrary. However, it introduces some segmentation mask integer values that do not map exactly to a defined anatomical feature category. See the data loading tutorial for more information and temporary work-arounds.