
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/TensorRT
| 1,351
|
❓ [Question] Not enough inputs provided (runtime.RunCudaEngine)
|
## ❓ Question
<!-- Your question -->
i make a pressure test on my model compiled by torch-tensorrt, it will report errors after 5 minutes, the traceback as blow:
```shell
2022-09-09T09:16:01.618971735Z File "/component/text_detector.py", line 135, in __call__
2022-09-09T09:16:01.618975181Z outputs = self.net(inp)
2022-09-09T09:16:01.618978313Z File "/miniconda/envs/python36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
2022-09-09T09:16:01.618981965Z return forward_call(*input, **kwargs)
2022-09-09T09:16:01.618985142Z RuntimeError: The following operation failed in the TorchScript interpreter.
2022-09-09T09:16:01.618988457Z Traceback of TorchScript, serialized code (most recent call last):
2022-09-09T09:16:01.618991980Z File "code/__torch__.py", line 8, in forward
2022-09-09T09:16:01.618995305Z input_0: Tensor) -> Tensor:
2022-09-09T09:16:01.618998495Z __torch___ModelWrapper_trt_engine_ = self_1.__torch___ModelWrapper_trt_engine_
2022-09-09T09:16:01.619001820Z _0 = ops.tensorrt.execute_engine([input_0], __torch___ModelWrapper_trt_engine_)
2022-09-09T09:16:01.619005168Z ~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
2022-09-09T09:16:01.619008442Z _1, = _0
2022-09-09T09:16:01.619011485Z return _1
2022-09-09T09:16:01.619014563Z
2022-09-09T09:16:01.619017565Z Traceback of TorchScript, original code (most recent call last):
2022-09-09T09:16:01.619020865Z RuntimeError: [Error thrown at core/runtime/register_trt_op.cpp:101] Expected compiled_engine->exec_ctx->allInputDimensionsSpecified() to be true but got false
2022-09-09T09:16:01.619024625Z Not enough inputs provided (runtime.RunCudaEngine)
```
then i get an error about cuda memory illegal access:
```shell
2022-09-13T02:32:46.621963863Z File "/component/text_detector.py", line 136, in __call__
2022-09-13T02:32:46.621966267Z inp = inp.cuda()
2022-09-13T02:32:46.621968419Z RuntimeError: CUDA error: an illegal memory access was encountered
```
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
I have tried upgrade the pytorch version from 1.10.0 to 1.10.2, also tried upgrade torch to 1.11.0 python 3.7, but it didn't works.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10.2
- CPU Architecture: x86
- OS (e.g., Linux): centos 7
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source): /
- Are you using local sources or building from archives: no
- Python version: 3.6
- CUDA version: 11.3
- GPU models and configuration: gpu is nvidia-T4 with 16G memory
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1351
|
closed
|
[
"question",
"No Activity",
"component: runtime"
] | 2022-09-13T02:39:11Z
| 2023-03-26T00:02:17Z
| null |
Pekary
|
pytorch/TensorRT
| 1,340
|
❓ [Question] No improvement when I use sparse-weights?
|
## ❓ Question
<!-- Your question -->
**No speed improvement when I use sparse-weights.**
I just modified this notebook https://github.com/pytorch/TensorRT/blob/master/notebooks/Hugging-Face-BERT.ipynb
And add the sparse_weights=True in the compile part. I also changed the regional bert-base model when I apply 2:4 sparse on most parts of the FC layers.

But whether I set the "sparse_weights=True", the results look like no changes.
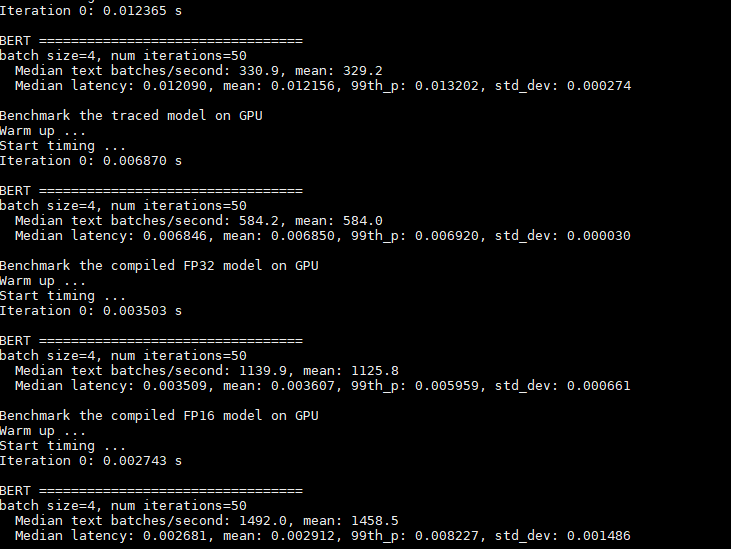
Here are some results.
set sparse_weights=False
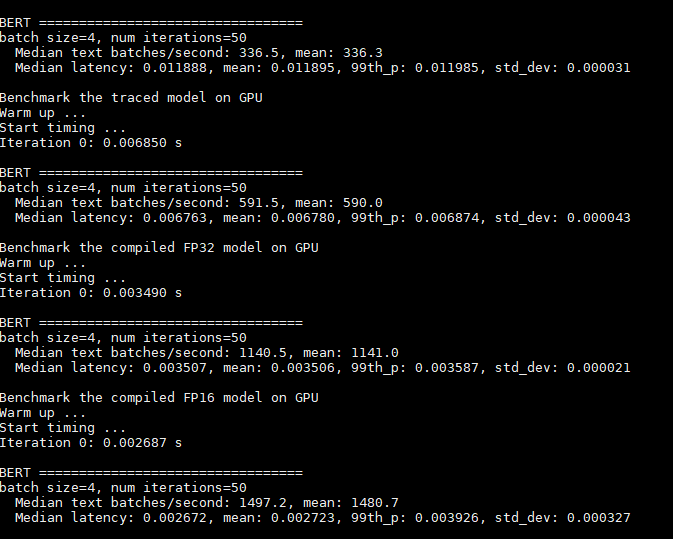
set sparse_weights=True
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.13
- CPU Architecture:x86-64
- OS (e.g., Linux):Ubuntu 18.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.8
- CUDA version: 11.7.1
- GPU models and configuration: Nvidia A100 GPU & CUDA Driver Version 515.65.01
- Any other relevant information:
## Additional context

<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1340
|
closed
|
[
"question",
"No Activity",
"performance"
] | 2022-09-09T02:26:48Z
| 2023-03-26T00:02:17Z
| null |
wzywzywzy
|
pytorch/vision
| 6,545
|
add quantized vision transformer model
|
### 🚀 The feature
hi, thanks for your great work. I hope to be able to add quantized vit model (for ptq or qat).
### Motivation, pitch
In 'torchvision/models/quantization', there are several quantized model (Eager Mode Quantization) that is very useful for me to learn quantization. In recent years, Transformer model is very popular. I want to learn how to quantized Transformer model, e.g Vision Transformer, Swin Transformer etc, using pytorch official tools like Eager Mode Quantization. I also tried to modify it myself, but failed. I don't know how to quantify 'pos_embedding' (nn.Parameter) and nn.MultiheadAttention module. look forward to your reply.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/vision/issues/6545
|
open
|
[
"question",
"module: models.quantization"
] | 2022-09-08T09:34:33Z
| 2022-09-09T11:17:45Z
| null |
WZMIAOMIAO
|
huggingface/datasets
| 4,944
|
larger dataset, larger GPU memory in the training phase? Is that correct?
|
from datasets import set_caching_enabled
set_caching_enabled(False)
for ds_name in ["squad","newsqa","nqopen","narrativeqa"]:
train_ds = load_from_disk("../../../dall/downstream/processedproqa/{}-train.hf".format(ds_name))
break
train_ds = concatenate_datasets([train_ds,train_ds,train_ds,train_ds]) #operation 1
trainer = QuestionAnsweringTrainer( #huggingface trainer
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset= None,
eval_examples=None,
answer_column_name=answer_column,
dataset_name="squad",
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
with operation 1, the GPU memory increases from 16G to 23G
|
https://github.com/huggingface/datasets/issues/4944
|
closed
|
[
"bug"
] | 2022-09-07T08:46:30Z
| 2022-09-07T12:34:58Z
| 2
|
debby1103
|
pytorch/vision
| 6,543
|
Inconsistent use of FrozenBatchNorm in Faster-RCNN?
|
Hi,
while customizing and training a Faster-RCNN object detection model based on `torchvision.models.detection.faster_rcnn`, I've noticed that the pre-trained model of type `fasterrcnn_resnet50_fpn_v2` always use `nn.BatchNorm2d` normalization layers, while `fasterrcnn_resnet50_fpn` uses `torchvision.models.ops.misc.FrozenBatchNorm2d` when pretrained weights are loaded. I've noticed deteriorating performance of the V2 model when training a COCO pretrained model with low batch size. I am suspecting that this is related to the un-frozen `nn.BatchNorm2d` layers, and indeed, replacing `nn.BatchNorm2d` with `torchvision.models.ops.misc.FrozenBatchNorm2d` improves the performance for my task.
Thus, my question is: Is this discrepancy in normalization layers intentional, and if yes what could be other reasons for V2 model underperforming compared to the V1 model?
I'm using pytorch 1.12, torchvision 0.13.
Thanks!
cc @datumbox
|
https://github.com/pytorch/vision/issues/6543
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2022-09-07T08:16:00Z
| 2024-06-23T16:24:37Z
| null |
MoPl90
|
huggingface/datasets
| 4,942
|
Trec Dataset has incorrect labels
|
## Describe the bug
Both coarse and fine labels seem to be out of line.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = "trec"
raw_datasets = load_dataset(dataset)
df = pd.DataFrame(raw_datasets["test"])
df.head()
```
## Expected results
text (string) | coarse_label (class label) | fine_label (class label)
-- | -- | --
How far is it from Denver to Aspen ? | 5 (NUM) | 40 (NUM:dist)
What county is Modesto , California in ? | 4 (LOC) | 32 (LOC:city)
Who was Galileo ? | 3 (HUM) | 31 (HUM:desc)
What is an atom ? | 2 (DESC) | 24 (DESC:def)
When did Hawaii become a state ? | 5 (NUM) | 39 (NUM:date)
## Actual results
index | label-coarse |label-fine | text
-- |-- | -- | --
0 | 4 | 40 | How far is it from Denver to Aspen ?
1 | 5 | 21 | What county is Modesto , California in ?
2 | 3 | 12 | Who was Galileo ?
3 | 0 | 7 | What is an atom ?
4 | 4 | 8 | When did Hawaii become a state ?
## Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-1086-azure-x86_64-with-glibc2.27
- Python version: 3.9.13
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4942
|
closed
|
[
"bug"
] | 2022-09-06T22:13:40Z
| 2022-09-08T11:12:03Z
| 1
|
wmpauli
|
pytorch/data
| 763
|
Online doc for DataLoader2/ReadingService and etc.
|
### 📚 The doc issue
As we are preparing the next release with `DataLoader2`, we might need to add a few pages for `DL2`, `ReadingService` and all other related functionalities in https://pytorch.org/data/main/
- [x] DataLoader2
- [x] ReadingService
- [x] Adapter
- [ ] Linter
- [x] Graph function
- [ ]
### Suggest a potential alternative/fix
_No response_
|
https://github.com/meta-pytorch/data/issues/763
|
open
|
[
"documentation"
] | 2022-09-06T15:37:49Z
| 2022-11-15T15:13:49Z
| 4
|
ejguan
|
pytorch/TensorRT
| 1,335
|
[Question? Bug?] Tried to allocate 166.38 GiB, seems weird
|
## ❓ Question
<!-- Your question -->
I got errors
```
model_new_trt = trt.compile(
File "/opt/conda/lib/python3.8/site-packages/torch_tensorrt/_compile.py", line 109, in compile
return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch_tensorrt/ts/_compiler.py", line 113, in compile
compiled_cpp_mod = _C.compile_graph(module._c, _parse_compile_spec(spec))
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
%1 : bool = prim::Constant[value=0]()
%2 : int[] = prim::Constant[value=[0, 0, 0]]()
%4 : Tensor = aten::_convolution(%x, %w, %b, %s, %p, %d, %1, %2, %g, %1, %1, %1, %1)
~~~~ <--- HERE
return (%4)
RuntimeError: CUDA out of memory. Tried to allocate 166.38 GiB (GPU 0; 31.75 GiB total capacity; 1.31 GiB already allocated; 29.14 GiB free; 1.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
Converting Script
```
model_new_trt = trt.compile(
model_new,
inputs=[trt.Input(
min_shape=[1, 1, 210, 748, 748],
opt_shape=[1, 1, 210, 748, 748],
max_shape=[1, 1, 210, 748, 748],
dtype=torch.float32
)],
)
```
My model takes 28GB on inference forward.
But the 166GB so huge, is this correct memory usage?
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- Docker : nvcr.io/nvidia/pytorch:22.07-py3
- TRT : 1.2.0a0
- GPU models and configuration: V100 32GB
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1335
|
closed
|
[
"question",
"No Activity",
"component: partitioning"
] | 2022-09-06T15:16:41Z
| 2022-12-26T00:02:39Z
| null |
zsef123
|
huggingface/datasets
| 4,936
|
vivos (Vietnamese speech corpus) dataset not accessible
|
## Describe the bug
VIVOS data is not accessible anymore, neither of these links work (at least from France):
* https://ailab.hcmus.edu.vn/assets/vivos.tar.gz (data)
* https://ailab.hcmus.edu.vn/vivos (dataset page)
Therefore `load_dataset` doesn't work.
## Steps to reproduce the bug
```python
ds = load_dataset("vivos")
```
## Expected results
dataset loaded
## Actual results
```
ConnectionError: Couldn't reach https://ailab.hcmus.edu.vn/assets/vivos.tar.gz (ConnectionError(MaxRetryError("HTTPSConnectionPool(host='ailab.hcmus.edu.vn', port=443): Max retries exceeded with url: /assets/vivos.tar.gz (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f9d8a27d190>: Failed to establish a new connection: [Errno -5] No address associated with hostname'))")))
```
Will try to contact the authors, as we wanted to use Vivos as an example in documentation on how to create scripts for audio datasets (https://github.com/huggingface/datasets/pull/4872), because it's small and straightforward and uses tar archives.
|
https://github.com/huggingface/datasets/issues/4936
|
closed
|
[
"dataset bug"
] | 2022-09-06T13:17:55Z
| 2022-09-21T06:06:02Z
| 3
|
polinaeterna
|
pytorch/data
| 762
|
Allow Header(limit=None) ?
|
Not urgent at all, just a minor suggestion:
In the benchmark scripts I'm currently running I want to limit the number of samples in a data-pipe according to an `args.limit` CLI parameter. I'd be nice to be able to just write:
```py
dp = Header(dp, limit=args.limit)
```
and let `Header` be a no-op when `limit=None`. This might be a bit niche, and the alternative is to just protect the call in a `if` block, so I would totally understand if this isn't in scope (and it's really not urgent in any case)
|
https://github.com/meta-pytorch/data/issues/762
|
closed
|
[
"good first issue"
] | 2022-09-06T11:04:57Z
| 2022-12-06T20:20:58Z
| 4
|
NicolasHug
|
huggingface/datasets
| 4,932
|
Dataset Viewer issue for bigscience-biomedical/biosses
|
### Link
https://huggingface.co/datasets/bigscience-biomedical/biosses
### Description
I've just been working on adding the dataset loader script to this dataset and working with the relative imports. I'm not sure how to interpret the error below (show where the dataset preview used to be) .
```
Status code: 400
Exception: ModuleNotFoundError
Message: No module named 'datasets_modules.datasets.bigscience-biomedical--biosses.ddbd5893bf6c2f4db06f407665eaeac619520ba41f69d94ead28f7cc5b674056.bigbiohub'
```
### Owner
Yes
|
https://github.com/huggingface/datasets/issues/4932
|
closed
|
[] | 2022-09-05T22:40:32Z
| 2022-09-06T14:24:56Z
| 4
|
galtay
|
pytorch/pytorch
| 84,553
|
[ONNX] Change how context is given to symbolic functions
|
Current symbolic functions can take a context as an input, pushing graphs to the second argument. To support these functions, we need to annotate the first argument as symbolic context and tell them part in call time by examining the annotations.
Checking annotations is slow and this process complicates the logic in the caller.
Instead we can wrap the graph object in a GraphContext, exposing all methods used from the graph and include the context in the GraphContext. This way all the old symbolic functions continue to work and we do not need to do the annotation checking if we know the symbolic function is a "new function".
We can edit a private field in the functions at registration time to tag them as "new style" symbolic functions that always takes a wrapped Graph with context object as input.
This also has the added benefit where we no longer need to monkey patch the Graph object to expose the g.op method. Instead the method can be defined in the graph context object.
|
https://github.com/pytorch/pytorch/issues/84553
|
closed
|
[
"module: onnx",
"triaged",
"topic: improvements"
] | 2022-09-05T22:04:52Z
| 2022-09-28T22:56:39Z
| null |
justinchuby
|
pytorch/TensorRT
| 1,332
|
❓ [Question] Using torch-trt to test bert's qat quantitative model
|
## ❓ Question
When using torch-trt to test Bert's qat quantization ( https://zenodo.org/record/4792496#.YxGrdRNBy3J ) model, I encountered many FakeTensorQuantFunction nodes in the pass, and at the same time triggered many nodes that could not convert TRT, and split the graph into many subgraphs


question:
1. Can you tell me how to explain the nodes that appear in the pass, and how to explain the symbols (^) in front of these nodes?
2. How can these quantization nodes be converted into qat nodes corresponding to torch-trt( https://github.com/pytorch/TensorRT/blob/master/core/conversion/converters/impl/quantization.cpp )?
|
https://github.com/pytorch/TensorRT/issues/1332
|
closed
|
[
"question",
"No Activity",
"component: quantization"
] | 2022-09-05T12:35:41Z
| 2023-03-25T00:02:27Z
| null |
lixiaolx
|
pytorch/serve
| 1,851
|
High utilization of hardware
|
HI, I'm trying to use torchserve as a backend with a custom hardware setup. How do you suggest to run such that the hardware is maximally utilized? For example I tried using the benchmarks-ab.py script to test the server for throughput on resnet18 but only achieved ~200 requests per second (tried different batch sizes) while the hardware is capable of crunching at least 10,000 images per second.
Thanks for any help.
|
https://github.com/pytorch/serve/issues/1851
|
closed
|
[
"question",
"triaged"
] | 2022-09-05T05:15:29Z
| 2022-09-08T09:13:40Z
| null |
Vert53
|
pytorch/data
| 761
|
Would TorchData provide GPU support for loading and preprocessing images?
|
### 🚀 The feature
Would TorchData provide GPU support for loading and preprocessing images?
### Motivation, pitch
When I am learning PyTorch, I find, currently, it do not support using GPU to load images or any other transforms of preprocessing and encoding data.
I want to know whether this would be taken into consideration into the design of TorchData.
### Alternatives
Currently, NVIDIA-DALI is an impressive alternative for loading and preprocessing images with GPU.
### Additional context
_No response_
|
https://github.com/meta-pytorch/data/issues/761
|
open
|
[
"topic: new feature",
"triaged"
] | 2022-09-03T09:16:30Z
| 2022-11-21T20:06:25Z
| 5
|
songyuc
|
pytorch/serve
| 1,842
|
initial parameters transmit
|
### 🚀 The feature
how transmit the initial parameters from the first model to laters in workflow.
### Motivation, pitch
how transmit the initial parameters from the first model to laters in workflow.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/serve/issues/1842
|
open
|
[
"question",
"triaged_wait",
"workflowx"
] | 2022-09-02T14:51:38Z
| 2022-09-06T10:42:39Z
| null |
jack-gits
|
pytorch/serve
| 1,841
|
how to register a workflow directly when docker is started.
|
### 🚀 The feature
how to register a workflow directly when docker is started.
### Motivation, pitch
how to register a workflow directly when docker is started.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/serve/issues/1841
|
open
|
[
"help wanted",
"triaged",
"workflowx"
] | 2022-09-02T14:21:34Z
| 2023-11-15T06:49:21Z
| null |
jack-gits
|
huggingface/datasets
| 4,924
|
Concatenate_datasets loads everything into RAM
|
## Describe the bug
When loading the datasets seperately and saving them on disk, I want to concatenate them. But `concatenate_datasets` is filling up my RAM and the process gets killed. Is there a way to prevent this from happening or is this intended behaviour? Thanks in advance
## Steps to reproduce the bug
```python
gcs = gcsfs.GCSFileSystem(project='project')
datasets = [load_from_disk(f'path/to/slice/of/data/{i}', fs=gcs, keep_in_memory=False) for i in range(10)]
dataset = concatenate_datasets(datasets)
```
## Expected results
A concatenated dataset which is stored on my disk.
## Actual results
Concatenated dataset gets loaded into RAM and overflows it which gets the process killed.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-4.19.0-21-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.13
- PyArrow version: 8.0.1
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4924
|
closed
|
[
"bug"
] | 2022-09-01T10:25:17Z
| 2022-09-01T11:50:54Z
| 0
|
louisdeneve
|
pytorch/TensorRT
| 1,328
|
❓ [Question] How do you ....?
|
## ❓ Question
Hi,
I am trying to use torch-tensorrt to optimize my model for inference. I first compile the model with torch.jit.script and then covnert it to tesnsorrt.
```shell
model = MoViNet(movinet_c.MODEL.MoViNetA0)
model.eval().cuda()
scripted_model = torch.jit.script(model)
trt_model = torch_tensorrt.compile(model,
inputs = [torch_tensorrt.Input((8, 3, 16, 344, 344))],
enabled_precisions= {torch.half}, # Run with FP16
workspace_size= 1 << 20,
truncate_long_and_double=True,
require_full_compilation=True, #True
)
```
However, the tensorrt model has almost the same speed as the regular PyTorch model. And the torchscript model is about 2 times slower:
```shell
cur_time = time.time()
with torch.inference_mode():
for _ in range(100):
x = torch.rand(4, 3, 16, 344, 344).cuda()
detections_batch = model(x)
print(time.time() - cur_time) #11.20 seconds
cur_time = time.time()
with torch.inference_mode():
scripted_model(x)
for _ in range(100):
x = torch.rand(4, 3, 16, 344, 344).cuda()
detections_batch = scripted_model(x)
print(time.time() - cur_time) #23.76 seconds
cur_time = time.time()
with torch.inference_mode():
trt_model(x)
for _ in range(100):
x = torch.rand(4, 3, 16, 344, 344).cuda()
detections_batch = trt_model(x)
print(time.time() - cur_time) #11.01 seconds
```
I'd really appreciate it if someone can help me understand what could be causing this issue.
## What you have already tried
I tried compiling and converting the model layer by layer and it doesn't seem like there is a specific operation or layer that takes too much time, however, each layer adds a little bit (0.5 seconds) to the runtime of the scripted model while it only adds about 0.01 to the runtime of the regular PyTorch model.
## Environment
Torch-TensorRT Version: 1.1.0
PyTorch Version: 1.11.0+cu113
CPU Architecture: x86_64
OS: Ubuntu 20.04
How you installed PyTorch: pip
Python version: 3.8
CUDA version: 11.3
GPU models and configuration: NVIDIA GeForce RTX 3070
## Additional context
This is the model. It's taken from here: [MoViNet-pytorch/models.py at main · Atze00/MoViNet-pytorch · GitHub](https://github.com/Atze00/MoViNet-pytorch/blob/main/movinets/models.py)
I made some changes to resolve the errors I was getting from torch.jit.script and torch-tensorrt.
```shell
class Swish(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x: Tensor) -> Tensor:
return x * torch.sigmoid(x)
class Conv3DBNActivation(nn.Sequential):
def __init__(
self,
in_planes: int,
out_planes: int,
*,
kernel_size: Union[int, Tuple[int, int, int]],
padding: Union[int, Tuple[int, int, int]],
stride: Union[int, Tuple[int, int, int]] = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None,
**kwargs: Any,
) -> None:
super().__init__()
kernel_size = _triple(kernel_size)
stride = _triple(stride)
padding = _triple(padding)
if norm_layer is None:
norm_layer = nn.Identity
if activation_layer is None:
activation_layer = nn.Identity
self.kernel_size = kernel_size
self.stride = stride
dict_layers = OrderedDict({
"conv3d": nn.Conv3d(in_planes, out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
**kwargs),
"norm": norm_layer(out_planes, eps=0.001),
"act": activation_layer()
})
self.out_channels = out_planes
self.seq_layer = nn.Sequential(dict_layers)
# super(Conv3DBNActivation, self).__init__(dict_layers)
def forward(self, input):
return self.seq_layer(input)
class ConvBlock3D(nn.Module):
def __init__(
self,
in_planes: int,
out_planes: int,
*,
kernel_size: Union[int, Tuple[int, int, int]],
conv_type: str,
padding: Union[int, Tuple[int, int, int]] = 0,
stride: Union[int, Tuple[int, int, int]] = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optio
|
https://github.com/pytorch/TensorRT/issues/1328
|
closed
|
[
"question",
"No Activity",
"performance"
] | 2022-08-31T15:06:50Z
| 2022-12-12T00:03:55Z
| null |
ghazalehtrb
|
pytorch/data
| 756
|
[RFC] More support for functionalities from `itertools`
|
### 🚀 The feature
Over time, we have received more and more request for additional `IterDataPipe` (e.g. #648, #754, plus many more). Sometimes, these functionalities are very similar to what is already implemented in [`itertools`](https://docs.python.org/3/library/itertools.html) and [`more-itertools`](https://github.com/more-itertools/more-itertools).
Keep adding more `IterDataPipe` one at a time seems unsustainable(?). Perhaps, we should draw a line somewhere or provide better interface for users to directly use functions from `itertools`. At the same time, providing APIs with names that are already familiar to Python users can improve the user experience. As @msaroufim mentioned, the Core library does aim to match operators with what is available in `numpy`.
We will need to decide on:
1. Coverage - which set of functionalities should we officially in `torchdata`?
2. Implementation - how will users be able to invoke those functions?
### Coverage
0. Arbitrary based on estimated user requests/contributions
1. `itertools` ~20 functions (some of which already exist in `torchdata`)
- **This seems common enough and reasonable?**
2. `more-itertools` ~100 functions?
- This is probably too much.
If we provide a good wrapper, we might not need to worry about the actual coverage too much?
### Implementation
0. Keep adding each function as a new `IterDataPipe`
- This is what we have been doing. We can keep doing that but the cost of maintenance will increase over time.
Currently, you can use `IterableWrapper`, but it doesn't always work well since it accepts an iterable, and an iterable doesn't guarantee to restart if you call `iter()` on it again.
```python
from torchdata.datapipes.iter import IterableWrapper
from itertools import accumulate
source_dp = IterableWrapper(range(10))
dp3 = IterableWrapper(accumulate(source_dp), deepcopy=False)
list(dp3) # [0, 1, 3, 6, 10, 15, 21, 28, 36, 45]
list(dp3) # []
```
One idea to work around that is to:
1. Provide a different wrapper that accepts a `Callable` that returns an `Iterable`, which will be iterated over
- Users can use `functool.partial` to pass in arguments (including `DataPipes` if desired)
- **I personally think we should do this since the cost of doing so is low and unlocks other possibilities.**
2. Create an `Itertools` DataPipe that delegates other DataPipes, it might look some like this:
```python
class ItertoolsIterDataPipe(IterDataPipe):
supported_operations: Dict[str, Callable] = {
"repeat": Repeater,
"chain": Concater,
"filterfalse": filter_false_constructor,
# most/all 20 `itertools` functions here?
}
def __new__(cls, name, *args, **kwargs):
if name not in cls.supported_operations:
raise RuntimeError("Operator is not supported")
constructor = cls.supported_operations[name]
return constructor(*args, **kwargs)
source_dp = IterableWrapper(range(10))
dp1 = source_dp.filter(lambda x: x >= 5)
dp2 = ItertoolsIterDataPipe("filterfalse", source_dp, lambda x: x >= 5)
list(dp1) # [5, 6, 7, 8, 9]
list(dp2) # [0, 1, 2, 3, 4]
```
These options are incomplete. If you have more ideas, please comment below.
### Motivation, pitch
These functionalities are commonly used and can be valuable for users.
### Additional context
Credit to @NicolasHug @msaroufim @pmeier and many others for past feedback and discussion related to this topic.
cc: @VitalyFedyunin @ejguan
|
https://github.com/meta-pytorch/data/issues/756
|
open
|
[] | 2022-08-30T21:30:19Z
| 2022-09-08T06:54:28Z
| 5
|
NivekT
|
pytorch/TensorRT
| 1,322
|
Error when I'm trying to use torch-tensorrt
|
## ❓ Question
Hi
I'm trying to use torch-tensorrt with the pre built ngc container
I built it with 22.04 branch and with 22.04 version of ngc
My versions are:
cuda 10.2
torchvision 0.13.1
torch 1.12.1
But I get that error:
Traceback (most recent call last):
File "main.py", line 31, in <module>
import torch_tensorrt
File "/usr/local/lib/python3.8/dist-packages/torch_tensorrt/__init__.py", line 11, in <module>
from torch_tensorrt._compile import *
File "/usr/local/lib/python3.8/dist-packages/torch_tensorrt/_compile.py", line 2, in <module>
from torch_tensorrt import _enums
File "/usr/local/lib/python3.8/dist-packages/torch_tensorrt/_enums.py", line 1, in <module>
from torch_tensorrt._C import dtype, DeviceType, EngineCapability, TensorFormat
ImportError: /usr/local/lib/python3.8/dist-packages/torch_tensorrt/lib/libtorchtrt.so: undefined symbol: _ZNK3c1010TensorImpl36is_contiguous_nondefault_policy_implENS_12MemoryFormatE
Thank's!!
|
https://github.com/pytorch/TensorRT/issues/1322
|
closed
|
[
"question",
"channel: NGC"
] | 2022-08-30T13:09:18Z
| 2022-12-15T17:43:52Z
| null |
EstherMalam
|
huggingface/diffusers
| 267
|
Non-squared Image shape
|
Is it possible to use diffusers on non-squared images?
That would be a very interesting feature!
|
https://github.com/huggingface/diffusers/issues/267
|
closed
|
[
"question"
] | 2022-08-29T01:29:33Z
| 2022-09-13T15:57:36Z
| null |
LucasSilvaFerreira
|
pytorch/functorch
| 1,011
|
memory_efficient_fusion leads to RuntimeError for higher-order gradients calculation. RuntimeError: You are attempting to call Tensor.requires_grad_()
|
Hi All,
I've tried improving the speed of my code via using `memory_efficient_fusion`, however, it leads to `Tensor.requires_grad_()` error and I have no idea why. The error is as follows,
```
RuntimeError: You are attempting to call Tensor.requires_grad_() (or perhaps using torch.autograd.functional.* APIs) inside of a function being transformed by a functorch transform. This is unsupported, please attempt to use the functorch transforms (e.g. grad, vjp, jacrev, jacfwd, hessian) or call requires_grad_() outside of a function being transformed instead.
```
I've attached a 'minimal' reproducible example of this behaviour below. I've tried a few different things but nothing's seems to have worked. I did see in #840 `memory_efficient_fusion` is done within a context manager, however, when using that I get the same error.
Thanks in advance!
EDIT: When I tried running it, it tried to use the `networkx` package but that wasn't installed by default. So, I had to manually install that (which wasn't a problem), just not sure if installing from source should also include install those packages as well!
```
import torch
from torch import nn
import functorch
from functorch import make_functional, vmap, jacrev, grad
from functorch.compile import memory_efficient_fusion
import time
_ = torch.manual_seed(1234)
#version info
print("PyTorch version: ", torch.__version__)
print("CUDA version: ", torch.version.cuda)
print("FuncTorch version: ", functorch.__version__)
#=============================================#
#time with torch synchronization
def sync_time() -> float:
torch.cuda.synchronize()
return time.perf_counter()
class model(nn.Module):
def __init__(self, num_inputs, num_hidden):
super(model, self).__init__()
self.num_inputs=num_inputs
self.func = nn.Tanh()
self.fc1 = nn.Linear(2, num_hidden)
self.fc2 = nn.Linear(num_hidden, num_inputs)
def forward(self, x):
"""
Takes x in [B,A,1] and maps it to sign/logabsdet value in Tuple([B,], [B,])
"""
idx=len(x.shape) #creates args for repeat if vmap is used or not
rep=[1 for _ in range(idx)]
rep[-2] = self.num_inputs
g = x.mean(dim=(idx-2), keepdim=True).repeat(*rep)
f = torch.cat((x,g), dim=-1)
h = self.func(self.fc1(f))
mat = self.fc2(h)
sgn, logabs = torch.linalg.slogdet(mat)
return sgn, logabs
#=============================================#
B=4096 #batch
N=2 #input nodes
H=64 #number of hidden nodes
device = torch.device('cuda')
x = torch.randn(B, N, 1, device=device) #input data
net = model(N, H) #our model
net=net.to(device)
fnet, params = make_functional(net)
def calc_logabs(params, x):
_, logabs = fnet(params, x)
return logabs
def calc_dlogabs_dx(params, x):
dlogabs_dx = jacrev(func=calc_logabs, argnums=1)(params, x)
return dlogabs_dx, dlogabs_dx #return aux
def local_kinetic_from_log_vmap(params, x):
d2logabs_dx2, dlogabs_dx = jacrev(func=calc_dlogabs_dx, argnums=1, has_aux=True)(params, x)
_local_kinetic = -0.5*(d2logabs_dx2.diagonal(0,-4,-2).sum() + dlogabs_dx.pow(2).sum())
return _local_kinetic
#memory efficient fusion here
#with torch.jit.fuser("fuser2"): is this needed (from functorch/issues/840)
ps_elocal = grad(local_kinetic_from_log_vmap, argnums=0)
ps_elocal_fusion = memory_efficient_fusion(grad(local_kinetic_from_log_vmap, argnums=0))
#ps_elocal_fusion(params, x) #no vmap attempt (throws size mis-match error)
t1=sync_time()
vmap(ps_elocal, in_dims=(None, 0))(params, x) #works fine
t2=sync_time()
vmap(ps_elocal_fusion, in_dims=(None, 0))(params, x) #error (crashes on this line)
t3=sync_time()
print("Laplacian (standard): %4.2e (s)",t2-t1)
print("Laplacian (fusion): %4.2e (s)",t3-t2)
```
|
https://github.com/pytorch/functorch/issues/1011
|
open
|
[] | 2022-08-28T16:56:02Z
| 2022-12-22T19:59:22Z
| 3
|
AlphaBetaGamma96
|
pytorch/functorch
| 1,010
|
Multiple gradient calculation for single sample
|
[According to the README](https://github.com/pytorch/functorch#working-with-nn-modules-make_functional-and-friends), we are able to calculate **per-sample-gradients** with functorch.
But what if we want to get multiple gradients for a **single sample**? For example, imagine that we are calculating multiple losses.
We can split each loss calculation as a different sample, but that implementation is inefficient, especially when the forward pass is expensive. Can we at least re-use forward computations?
|
https://github.com/pytorch/functorch/issues/1010
|
closed
|
[] | 2022-08-28T14:31:11Z
| 2023-01-08T10:23:04Z
| 23
|
JoaoLages
|
pytorch/TensorRT
| 1,317
|
caffe2
|
Why don't you install caffe2 with pytorch in NGC container 22.08?
|
https://github.com/pytorch/TensorRT/issues/1317
|
closed
|
[
"question",
"channel: NGC"
] | 2022-08-27T15:45:17Z
| 2023-01-03T18:30:26Z
| null |
s-mohaghegh97
|
pytorch/serve
| 1,819
|
How to transfer files to a custom handler with curl command
|
I have created a custom handler that inputs and outputs wav files.
The code is as follows
```Python
# custom handler file
# model_handler.py
"""
ModelHandler defines a custom model handler.
"""
import os
import soundfile
from espnet2.bin.enh_inference import *
from ts.torch_handler.base_handler import BaseHandler
class ModelHandler(BaseHandler):
"""
A custom model handler implementation.
"""
def __init__(self):
self._context = None
self.initialized = False
self.model = None
self.device = None
def initialize(self, context):
"""
Invoke by torchserve for loading a model
:param context: context contains model server system properties
:return:
"""
# load the model
self.manifest = context.manifest
properties = context.system_properties
model_dir = properties.get("model_dir")
self.device = torch.device("cuda:" + str(properties.get("gpu_id")) if torch.cuda.is_available() else "cpu")
# Read model serialize/pt file
serialized_file = self.manifest['model']['serializedFile']
model_pt_path = os.path.join(model_dir, serialized_file)
if not os.path.isfile(model_pt_path):
raise RuntimeError("Missing the model.pt file")
self.model = SeparateSpeech("./train_enh_transformer_tf.yaml", "./valid.loss.best.pth", normalize_output_wav=True)
self.initialized = True
def preprocess(self,data):
audio_data, rate = soundfile.read(data)
preprocessed_data = audio_data[np.newaxis, :]
return preprocessed_data
def inference(self, model_input):
model_output = self.model(model_input)
return model_output
def postprocess(self, inference_output):
"""
Return inference result.
:param inference_output: list of inference output
:return: list of predict results
"""
# Take output from network and post-process to desired format
postprocess_output = inference_output
#wav ni suru
return postprocess_output
def handle(self, data, context):
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)
```
I transferred the wav file to torhserve with the following command
> curl --data-binary @Mix.wav --noproxy '*' http://127.0.0.1:8080/predictions/denoise_transformer -v
However, I got the following response
```
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 8080 (#0)
> POST /predictions/denoise_transformer HTTP/1.1
> Host: 127.0.0.1:8080
> User-Agent: curl/7.58.0
> Accept: */*
> Content-Length: 128046
> Content-Type: application/x-www-form-urlencoded
> Expect: 100-continue
>
< HTTP/1.1 100 Continue
* We are completely uploaded and fine
< HTTP/1.1 500 Internal Server Error
< content-type: application/json
< x-request-id: 445155a4-5971-490a-ba7c-206f8eda5ea0
< Pragma: no-cache
< Cache-Control: no-cache; no-store, must-revalidate, private
< Expires: Thu, 01 Jan 1970 00:00:00 UTC
< content-length: 89
< connection: close
<
{
"code": 500,
"type": "ErrorDataDecoderException",
"message": "Bad end of line"
}
* Closing connection 0
```
What is wrong?
I have confirmed that the following command returns the response.
> curl --noproxy '*' http://127.0.0.1:8081/models
```
{
"models": [
{
"modelName": "denoise_transformer",
"modelUrl": "denoise_transformer.mar"
}
]
}
```
|
https://github.com/pytorch/serve/issues/1819
|
closed
|
[
"triaged_wait",
"support"
] | 2022-08-27T10:30:27Z
| 2022-08-30T23:40:53Z
| null |
Shin-ichi-Takayama
|
pytorch/data
| 754
|
A more powerful Mapper than can restrict function application to only part of the datapipe items?
|
We often have datapipes that return tuples `(img, target)` where we just want to call transformations on the img, but not the target. Sometimes it's the opposite: I want to apply a function to the target, and not to the img.
This usually forces us to write wrappers that "passthrough" either the img or the target. For example:
```py
def decode_img_only(data): # boilerplate wrapper
img, target = data
img = decode(img)
return img, data
def resize_img_only(data): # boilerplate wrapper
img, target = data
img = resize(img)
return img, data
def add_label_noise(data): # boilerplate wrapper
img, target = data
target = make_noisy_label(target)
return img, data
dp = ...
dp = dp.map(decode_img_only).map(resize_img_only).map(add_label_noise)
```
Perhaps a more convenient way of doing this would be to implement something similar to WebDataset's `map_dict` and `map_tuple`? This would avoid all the boilerplate wrappers. For example we could imagine the code above to simply be:
```py
dp = ...
dp = dp.map_tuple(decode, None).map(resize, None).map(None, make_noisy_label)
# or even
dp = dp.map_tuple(decode, None).map(resize, make_noisy_label)
# if the datapipes was returning a dict with "img" and "target" keys this could also be
dp = dp.map_dict("img"=decode).map_dict("img"=decode, "target"=make_noisy_label)
```
I even think it might be possible to implement all of `map_dict()` and `map_tuple()` functionalities withing the `.map()` function:
- 1 arg == current `map()`
- 1+ arg == `map_tuple()`
- keyword arg == `map_dict()`
CC @pmeier and @msaroufim to whom this might be of interest
|
https://github.com/meta-pytorch/data/issues/754
|
open
|
[] | 2022-08-26T21:16:32Z
| 2022-08-30T21:48:10Z
| 5
|
NicolasHug
|
huggingface/dataset-viewer
| 534
|
Store the cached responses on the Hub instead of mongodb?
|
The config and split info will be stored in the YAML of the dataset card (see https://github.com/huggingface/datasets/issues/4876), and the idea is to compute them and update the dataset card automatically. This means that storing the responses for `/splits` in the MongoDB is duplication.
If we store the responses for `/first-rows` in the Hub too (maybe in a special git ref), we might get rid of the MongoDB storage, or use another simpler cache mechanism if response time is an issue.
WDYT @huggingface/datasets-server @julien-c ?
|
https://github.com/huggingface/dataset-viewer/issues/534
|
closed
|
[
"question"
] | 2022-08-26T16:24:39Z
| 2022-09-19T09:09:29Z
| null |
severo
|
huggingface/datasets
| 4,902
|
Name the default config `default`
|
Currently, if a dataset has no configuration, a default configuration is created from the dataset name.
For example, for a dataset loaded from the hub repository, such as https://huggingface.co/datasets/user/dataset (repo id is `user/dataset`), the default configuration will be `user--dataset`.
It might be easier to handle to set it to `default`, or another reserved word.
|
https://github.com/huggingface/datasets/issues/4902
|
closed
|
[
"enhancement",
"question"
] | 2022-08-26T16:16:22Z
| 2023-07-24T21:15:31Z
| null |
severo
|
huggingface/optimum
| 362
|
unexpect behavior GPU runtime with ORTModelForSeq2SeqLM
|
### System Info
```shell
OS: Ubuntu 20.04.4 LTS
CARD: RTX 3080
Libs:
python 3.10.4
onnx==1.12.0
onnxruntime-gpu==1.12.1
torch==1.12.1
transformers==4.21.2
```
### Who can help?
@lewtun @michaelbenayoun @JingyaHuang @echarlaix
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Steps to reproceduce the behavior:
1. Convert a public translation from here: [vinai-translate-en2vi](https://huggingface.co/vinai/vinai-translate-en2vi)
```
from optimum.onnxruntime import ORTModelForSeq2SeqLM
save_directory = "models/en2vi_onnx"
# Load a model from transformers and export it through the ONNX format
model = ORTModelForSeq2SeqLM.from_pretrained('vinai/vinai-translate-en2vi', from_transformers=True)
# Save the onnx model and tokenizer
model.save_pretrained(save_directory)
```
2. Load model with modified from [example of origin creater model](https://github.com/VinAIResearch/VinAI_Translate#english-to-vietnamese-translation)
```
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForSeq2SeqLM
import torch
import time
device = "cuda:0" if torch.cuda.is_available() else "cpu"
tokenizer_en2vi = AutoTokenizer.from_pretrained("vinai/vinai-translate-en2vi", src_lang="en_XX")
model_en2vi = ORTModelForSeq2SeqLM.from_pretrained("models/en2vi_onnx")
model_en2vi.to(device)
# onnx_en2vi = pipeline("translation_en_to_vi", model=model_en2vi, tokenizer=tokenizer_en2vi, device=0)
# en_text = '''It's very cold to go out.'''
# start = time.time()
# outpt = onnx_en2vi(en_text)
# end = time.time()
# print(outpt)
# print("time: ", end - start)
def translate_en2vi(en_text: str) -> str:
start = time.time()
input_ids = tokenizer_en2vi(en_text, return_tensors="pt").input_ids.to(device)
end = time.time()
print("Tokenize time: {:.2f}s".format(end - start))
# print(input_ids.shape)
# print(input_ids)
start = time.time()
output_ids = model_en2vi.generate(
input_ids,
do_sample=True,
top_k=100,
top_p=0.8,
decoder_start_token_id=tokenizer_en2vi.lang_code_to_id["vi_VN"],
num_return_sequences=1,
)
end = time.time()
print("Generate time: {:.2f}s".format(end - start))
vi_text = tokenizer_en2vi.batch_decode(output_ids, skip_special_tokens=True)
vi_text = " ".join(vi_text)
return vi_text
en_text = '''It's very cold to go out.''' # long paragraph
start = time.time()
result = translate_en2vi(en_text)
print(result)
end = time.time()
print('{:.2f} seconds'.format((end - start)))
```
I change [line 167](https://github.com/huggingface/optimum/blob/661f4423097f580a06759ced557ecd638ab6b13a/optimum/onnxruntime/utils.py#L167) in optimum/onnxruntime/utils.py to _**return "CUDAExecutionProvider"**_ to run with GPU instead of an error.
3. run [example of origin creater model](https://github.com/VinAIResearch/VinAI_Translate#english-to-vietnamese-translation) with gpu and compare runtimes
### Expected behavior
The onnx model was expected run faster the result is unexpected:
- Runtime origin model with gpu is 3-5s while take about 3.5GB GPU

- Runtime onnx converted model with gpu is 70-80s while take about 7.7GB GPU

|
https://github.com/huggingface/optimum/issues/362
|
closed
|
[
"bug",
"inference",
"onnxruntime"
] | 2022-08-26T02:11:26Z
| 2022-12-09T09:13:22Z
| 3
|
tranmanhdat
|
huggingface/dataset-viewer
| 528
|
metrics: how to manage variability between the admin pods?
|
The metrics include one entry per uvicorn worker of the `admin` service, but they give different values.
<details>
<summary>Example of a response to https://datasets-server.huggingface.co/admin/metrics</summary>
<pre>
# HELP starlette_requests_in_progress Multiprocess metric
# TYPE starlette_requests_in_progress gauge
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="16"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="16"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="12"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="12"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="15"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="15"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="13"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="13"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="11"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="11"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="18"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="18"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="14"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="14"} 1.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="10"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="10"} 0.0
starlette_requests_in_progress{method="GET",path_template="/healthcheck",pid="17"} 0.0
starlette_requests_in_progress{method="GET",path_template="/metrics",pid="17"} 0.0
# HELP queue_jobs_total Multiprocess metric
# TYPE queue_jobs_total gauge
queue_jobs_total{pid="16",queue="/splits",status="waiting"} 0.0
queue_jobs_total{pid="16",queue="/splits",status="started"} 5.0
queue_jobs_total{pid="16",queue="/splits",status="success"} 71154.0
queue_jobs_total{pid="16",queue="/splits",status="error"} 41640.0
queue_jobs_total{pid="16",queue="/splits",status="cancelled"} 133.0
queue_jobs_total{pid="16",queue="/rows",status="waiting"} 372.0
queue_jobs_total{pid="16",queue="/rows",status="started"} 21.0
queue_jobs_total{pid="16",queue="/rows",status="success"} 300541.0
queue_jobs_total{pid="16",queue="/rows",status="error"} 121306.0
queue_jobs_total{pid="16",queue="/rows",status="cancelled"} 1500.0
queue_jobs_total{pid="16",queue="/splits-next",status="waiting"} 0.0
queue_jobs_total{pid="16",queue="/splits-next",status="started"} 4.0
queue_jobs_total{pid="16",queue="/splits-next",status="success"} 30896.0
queue_jobs_total{pid="16",queue="/splits-next",status="error"} 25611.0
queue_jobs_total{pid="16",queue="/splits-next",status="cancelled"} 92.0
queue_jobs_total{pid="16",queue="/first-rows",status="waiting"} 11406.0
queue_jobs_total{pid="16",queue="/first-rows",status="started"} 52.0
queue_jobs_total{pid="16",queue="/first-rows",status="success"} 142201.0
queue_jobs_total{pid="16",queue="/first-rows",status="error"} 30097.0
queue_jobs_total{pid="16",queue="/first-rows",status="cancelled"} 573.0
queue_jobs_total{pid="12",queue="/splits",status="waiting"} 0.0
queue_jobs_total{pid="12",queue="/splits",status="started"} 5.0
queue_jobs_total{pid="12",queue="/splits",status="success"} 71154.0
queue_jobs_total{pid="12",queue="/splits",status="error"} 41638.0
queue_jobs_total{pid="12",queue="/splits",status="cancelled"} 133.0
queue_jobs_total{pid="12",queue="/rows",status="waiting"} 424.0
queue_jobs_total{pid="12",queue="/rows",status="started"} 21.0
queue_jobs_total{pid="12",queue="/rows",status="success"} 300489.0
queue_jobs_total{pid="12",queue="/rows",status="error"} 121306.0
queue_jobs_total{pid="12",queue="/rows",status="cancelled"} 1500.0
queue_jobs_total{pid="12",queue="/splits-next",status="waiting"} 0.0
queue_jobs_total{pid="12",queue="/splits-next",status="started"} 4.0
queue_jobs_total{pid="12",queue="/splits-next",status="success"} 30896.0
queue_jobs_total{pid="12",queue="/splits-next",status="error"} 25610.0
queue_jobs_total{pid="12",queue="/splits-next",status="cancelled"} 92.0
queue_jobs_total{pid="12",queue="/first-rows",status="waiting"} 11470.0
queue_jobs_total{pid="12",queue="/first-rows",status="started"} 52.0
queue_jobs_total{pid="12",queue="/first-rows",status="success"} 142144.0
queue_jobs_total{pid="12",queue="/first-rows",status="error"} 30090.0
queue_jobs_total{pid="12",queue="/first-rows",status="cancelled"} 573.0
queue_jobs_total{pid="15",queue="/splits",status="waiting"} 0.0
queue_jobs_total{pid="15",queue="/splits",status="started"} 5.0
queue_jobs_total{pid="15",queue="/splits",status="success"} 71154.0
queue_jobs_total{pid="15",queue="/splits",status="error"} 41640.0
queue_jobs
|
https://github.com/huggingface/dataset-viewer/issues/528
|
closed
|
[
"bug",
"question"
] | 2022-08-25T19:48:44Z
| 2022-09-19T09:10:11Z
| null |
severo
|
pytorch/torchx
| 589
|
Add per workspace runopts/config
|
## Description
<!-- concise description of the feature/enhancement -->
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
Currently Workspaces piggyback on the config options for the scheduler. This means that every scheduler is deeply tied to the workspace and we have to copy the options to every runner.
https://github.com/pytorch/torchx/blob/main/torchx/schedulers/kubernetes_scheduler.py#L654-L658
## Detailed Proposal
<!-- provide a detailed proposal -->
1. Add a new method to the Workspace base class that allows specifying runopts from them
```python
@abstractmethod
def workspace_run_opts(self) -> runopts:
...
```
2. Update runner to call the workspace runopts method
3. Migrate all `image_repo` DockerWorkspace runopts to the class.
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
https://github.com/pytorch/torchx/blob/main/torchx/schedulers/api.py#L187
https://github.com/pytorch/torchx/blob/main/torchx/schedulers/docker_scheduler.py
https://github.com/pytorch/torchx/blob/main/torchx/workspace/docker_workspace.py
|
https://github.com/meta-pytorch/torchx/issues/589
|
open
|
[
"enhancement",
"module: runner",
"docker"
] | 2022-08-25T18:18:35Z
| 2022-08-25T18:18:35Z
| 0
|
d4l3k
|
pytorch/pytorch
| 84,014
|
fill_ OpInfo code not used, also, doesn't test the case where the second argument is a Tensor
|
Two observations:
1. `sample_inputs_fill_` is no longer used. Can be deleted (https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_methods_invocations.py#L1798-L1807)
2. The new OpInfo for fill doesn't actually test the `tensor.fill_(other_tensor)` case. Previously we did test this, as shown by `sample_inputs_fill_`
cc @mruberry
|
https://github.com/pytorch/pytorch/issues/84014
|
open
|
[
"module: tests",
"triaged"
] | 2022-08-24T20:39:11Z
| 2022-08-24T20:40:39Z
| null |
zou3519
|
huggingface/datasets
| 4,881
|
Language names and language codes: connecting to a big database (rather than slow enrichment of custom list)
|
**The problem:**
Language diversity is an important dimension of the diversity of datasets. To find one's way around datasets, being able to search by language name and by standardized codes appears crucial.
Currently the list of language codes is [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/languages.json), right? At about 1,500 entries, it is roughly at 1/4th of the world's diversity of extant languages. (Probably less, as the list of 1,418 contains variants that are linguistically very close: 108 varieties of English, for instance.)
Looking forward to ever increasing coverage, how will the list of language names and language codes improve over time?
Enrichment of the custom list by HFT contributors (like [here](https://github.com/huggingface/datasets/pull/4880)) has several issues:
* progress is likely to be slow:

(input required from reviewers, etc.)
* the more contributors, the less consistency can be expected among contributions. No need to elaborate on how much confusion is likely to ensue as datasets accumulate.
* there is no information on which language relates with which: no encoding of the special closeness between the languages of the Northwestern Germanic branch (English+Dutch+German etc.), for instance. Information on phylogenetic closeness can be relevant to run experiments on transfer of technology from one language to its close relatives.
**A solution that seems desirable:**
Connecting to an established database that (i) aims at full coverage of the world's languages and (ii) has information on higher-level groupings, alternative names, etc.
It takes a lot of hard work to do such databases. Two important initiatives are [Ethnologue](https://www.ethnologue.com/) (ISO standard) and [Glottolog](https://glottolog.org/). Both have pros and cons. Glottolog contains references to Ethnologue identifiers, so adopting Glottolog entails getting the advantages of both sets of language codes.
Both seem technically accessible & 'developer-friendly'. Glottolog has a [GitHub repo](https://github.com/glottolog/glottolog). For Ethnologue, harvesting tools have been devised (see [here](https://github.com/lyy1994/ethnologue); I did not try it out).
In case a conversation with linguists seemed in order here, I'd be happy to participate ('pro bono', of course), & to rustle up more colleagues as useful, to help this useful development happen.
With appreciation of HFT,
|
https://github.com/huggingface/datasets/issues/4881
|
open
|
[
"enhancement"
] | 2022-08-23T20:14:24Z
| 2024-04-22T15:57:28Z
| 49
|
alexis-michaud
|
pytorch/examples
| 1,040
|
In example DCGAN, curl timed out
|
Your issue may already be reported!
Please search on the [issue tracker](https://github.com/pytorch/serve/examples) before creating one.
## Context
<!--- How has this issue affected you? What are you trying to accomplish? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
* Pytorch version: 1.12.1
* Operating System and version: 20.04.4 LTS (Focal Fossa)
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Installed using source? [yes/no]: no
* Are you planning to deploy it using docker container? [yes/no]: yes
* Is it a CPU or GPU environment?: GPU
* Which example are you using: DCGAN
* Link to code or data to repro [if any]:
## Expected Behavior
<!--- If you're describing a bug, tell us what should happen -->
dcgan finishes without errors
## Current Behavior
<!--- If describing a bug, tell us what happens instead of the expected behavior -->
dcgan fails with exceptions
## Possible Solution
<!--- Not obligatory, but suggest a fix/reason for the bug -->
## Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug. Include code to reproduce, if relevant -->
1. cd examples
2. bash run_python_examples.sh "install_deps, dcgan"
## Failure Logs [if any]
<!--- Provide any relevant log snippets or files here. -->
```
Downloading classroom train set
--
181 | curl: /opt/conda/lib/libcurl.so.4: no version information available (required by curl)
182 | % Total % Received % Xferd Average Speed Time Time Time Current
183 | Dload Upload Total Spent Left Speed
...
curl: (18) transfer closed with 3277022655 bytes remaining to read
...
Some examples failed:
couldn't unzip classroom
```
I know this is a thrid-party repo issue, which I have already raised in [lsun repo](https://github.com/fyu/lsun/issues/46)
Is it possible that you could have a solution on your end? The request speed of the domain http://dl.yf.io is just slow in general.
Thank you!
|
https://github.com/pytorch/examples/issues/1040
|
open
|
[
"data"
] | 2022-08-23T18:34:09Z
| 2022-08-24T02:46:44Z
| 1
|
ShiboXing
|
huggingface/datasets
| 4,878
|
[not really a bug] `identical_ok` is deprecated in huggingface-hub's `upload_file`
|
In the huggingface-hub dependency, the `identical_ok` argument has no effect in `upload_file` (and it will be removed soon)
See
https://github.com/huggingface/huggingface_hub/blob/43499582b19df1ed081a5b2bd7a364e9cacdc91d/src/huggingface_hub/hf_api.py#L2164-L2169
It's used here:
https://github.com/huggingface/datasets/blob/fcfcc951a73efbc677f9def9a8707d0af93d5890/src/datasets/dataset_dict.py#L1373-L1381
https://github.com/huggingface/datasets/blob/fdcb8b144ce3ef241410281e125bd03e87b8caa1/src/datasets/arrow_dataset.py#L4354-L4362
https://github.com/huggingface/datasets/blob/fdcb8b144ce3ef241410281e125bd03e87b8caa1/src/datasets/arrow_dataset.py#L4197-L4213
We should remove it.
Maybe the third code sample has an unexpected behavior since it uses the non-default value `identical_ok = False`, but the argument is ignored.
|
https://github.com/huggingface/datasets/issues/4878
|
closed
|
[
"help wanted",
"question"
] | 2022-08-23T17:09:55Z
| 2022-09-13T14:00:06Z
| null |
severo
|
pytorch/TensorRT
| 1,303
|
How to correctly format input for Fp16 inference using torch-tensorrt C++
|
## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
Hi, I am using the following to export a torch scripted model to Fp16 tensorrt which will then be used in a C++ environment.
`network.load_state_dict(torch.load(path_weights, map_location="cuda:0"))
network.eval().cuda()
dummy_input = torch.rand(1, 6, 320, 224).cuda()
network_traced = torch.jit.trace(network, dummy_input) # converting to plain torchscript
# convert/ compile to trt
compile_settings = {
"inputs": [torchtrt.Input([1, 6, 320, 224])],
"enabled_precisions": {torch.half},
"workspace_size": 6 << 22
}
trt_ts_module = torchtrt.compile(network_traced, inputs=[torchtrt.Input((1, 6, 320, 224), dtype=torch.half)],
enabled_precisions={torch.half},
workspace_size=6<<22)
torch.jit.save(trt_ts_module, trt_ts_save_path)`
Is this correct?
If yes, then what is the correct way to cast the input tensor in C++?
Do I need to convert it to torck::kHalf explicitly? Or can the inputs stay as FP32
Please let me know.
Here is my code for loading the CNN for inference:
`try {
// Deserialize the ScriptModule from a file using torch::jit::load().
trt_ts_mod_cnn = torch::jit::load(trt_ts_module_path);
trt_ts_mod_cnn.to(torch::kCUDA);
cout << trt_ts_mod_cnn.type() << endl;
cout << trt_ts_mod_cnn.dump_to_str(true, true, false) << endl;
} catch (const c10::Error& e) {
std::cerr << "error loading the model from : " << trt_ts_module_path << std::endl;
// return -1;
}
auto inBEVInference = torch::rand({1, bevSettings.N_CHANNELS_BEV, bevSettings.N_ROWS_BEV, bevSettings.N_COLS_BEV},\
{at::kCUDA}).to(torch::kFloat32);
// auto inBEVInference = torch::rand({1, bevSettings.N_CHANNELS_BEV, bevSettings.N_ROWS_BEV, bevSettings.N_COLS_BEV},\
// {at::kCUDA}).to(torch::kFloat16);
std::vector<torch::jit::IValue> trt_inputs_ivalues;
trt_inputs_ivalues.push_back(inBEVInference);
auto outputs = trt_ts_mod_cnn.forward(trt_inputs_ivalues).toTuple();
auto kp = outputs->elements()[0].toTensor();
auto hwl = outputs->elements()[1].toTensor();
auto rot = outputs->elements()[2].toTensor();
auto dxdy = outputs->elements()[3].toTensor();
cout << "Size KP out -> " << kp.sizes() << endl;
cout << "Size HWL out -> " << hwl.sizes() << endl;
cout << "Size ROT out -> " << rot.sizes() << endl;
cout << "Size DXDY out -> " << dxdy.sizes() << endl;`
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.11.0+cu113
- CPU Architecture: x86_64
- OS (e.g., Linux): Linux, Ubuntu 20.04, docker container
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives: local
- Python version: 3.8.10
- CUDA version: Cuda compilation tools, release 11.4, V11.4.152 (on the linux system)
- GPU models and configuration: RTX2080 MaxQ
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1303
|
closed
|
[
"question",
"No Activity"
] | 2022-08-23T14:05:05Z
| 2022-12-04T00:02:10Z
| null |
SM1991CODES
|
pytorch/examples
| 1,039
|
FileNotFoundError: Couldn't find any class folder in /content/train2014.
|
Your issue may already be reported!
Please search on the [issue tracker](https://github.com/pytorch/serve/examples) before creating one.
I wanna train new style model
run this cmd
!unzip train2014.zip -d /content
!python /content/examples/fast_neural_style/neural_style/neural_style.py train --dataset /content/train2014 --style-image /content/A.jpg --save-model-dir /content --epochs 2 --cuda 1
## Context
<!--- How has this issue affected you? What are you trying to accomplish? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
* Pytorch version:
* Operating System and version:
## Your Environment
Colab
https://colab.research.google.com/github/pytorch/xla/blob/master/contrib/colab/style_transfer_inference.ipynb#scrollTo=EozMXwIV9iOJ
got this error
Traceback (most recent call last):
File "/content/examples/fast_neural_style/neural_style/neural_style.py", line 249, in <module>
main()
File "/content/examples/fast_neural_style/neural_style/neural_style.py", line 243, in main
train(args)
File "/content/examples/fast_neural_style/neural_style/neural_style.py", line 43, in train
train_dataset = datasets.ImageFolder(args.dataset, transform)
File "/usr/local/lib/python3.7/dist-packages/torchvision/datasets/folder.py", line 316, in __init__
is_valid_file=is_valid_file,
File "/usr/local/lib/python3.7/dist-packages/torchvision/datasets/folder.py", line 145, in __init__
classes, class_to_idx = self.find_classes(self.root)
File "/usr/local/lib/python3.7/dist-packages/torchvision/datasets/folder.py", line 219, in find_classes
return find_classes(directory)
File "/usr/local/lib/python3.7/dist-packages/torchvision/datasets/folder.py", line 43, in find_classes
raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")
FileNotFoundError: Couldn't find any class folder in /content/train2014.
How can I fix it?
thx
|
https://github.com/pytorch/examples/issues/1039
|
open
|
[
"bug",
"data"
] | 2022-08-23T07:33:17Z
| 2023-06-08T03:09:42Z
| 2
|
sevaroy
|
huggingface/diffusers
| 228
|
stable-diffusion-v1-4 link in release v0.2.3 is broken
|
### Describe the bug
@anton-l the link (https://huggingface.co/CompVis/stable-diffusion-v1-4) in the [release v0.2.3](https://github.com/huggingface/diffusers/releases/tag/v0.2.3) returns a 404.
### Reproduction
_No response_
### Logs
_No response_
### System Info
```shell
N/A
```
|
https://github.com/huggingface/diffusers/issues/228
|
closed
|
[
"question"
] | 2022-08-22T09:07:27Z
| 2022-08-22T20:53:00Z
| null |
leszekhanusz
|
huggingface/pytorch-image-models
| 1,424
|
[FEATURE] What hyperparameters is used to get the results stated in the paper with the ViT-B pretrained miil weights on imagenet1k?
|
**Is your feature request related to a problem? Please describe.**
What hyperparameters are used to get the results stated in this paper (https://arxiv.org/pdf/2104.10972.pdf) on ImageNet1k with the ViT-B pretrained miil weights from vision_transformer.py in line 164-167? I tried the hyperparemeters as stated in the paper for TResNet but I'm getting below average results. I'm not sure what other hyperparameter details i'm missing. How is the classifier head initialized? Do they use sgd momentum or without momentum? Do they use Hflip or random erasing? I think the hyperparameters stated in the paper is only applicable for TResNet and the code in https://github.com/Alibaba-MIIL/ImageNet21K is missing a lot of details in finetuning stage.
|
https://github.com/huggingface/pytorch-image-models/issues/1424
|
closed
|
[
"enhancement"
] | 2022-08-21T22:26:48Z
| 2022-08-22T04:17:43Z
| null |
Phuoc-Hoan-Le
|
pytorch/functorch
| 1,006
|
RuntimeError: CUDA error: no kernel image is available for execution on the device
|
Hi, I have cuda 11.7 on my system and I am trying to install functorch, since the stable version of pytorch for cuda 11.7 is not available [here](https://pytorch.org/get-started/previous-versions/), I just run `pip install functorch` which also installs the compatible version of pytorch.
But when I run my code that uses the GPU, I get the following error :
`RuntimeError: CUDA error: no kernel image is available for execution on the device`
Is it possible to use functorch in my case?
|
https://github.com/pytorch/functorch/issues/1006
|
closed
|
[] | 2022-08-21T19:30:34Z
| 2022-08-24T13:58:45Z
| 8
|
ykemiche
|
pytorch/TensorRT
| 1,295
|
Jetpack 5.0.2
|
## ❓ Question
Is it known yet whether Torch TensorRT is compatible with NVIDIA Jetpack 5.0.2 on NVIDIA Jetson devices?
## What you have already tried
I am trying to install torch-tensorrt for Python on my Jetson Xavier NX with Jetpack 5.0.2. Followed the instructions for the Jetpack 5.0 install and have successfully run everything up until ```python3 setup.py install --use-cxx11-abi``` which ran all the way until it got to “Allowing ninja to set a default number of workers” which it hung on for quite some time until eventually erroring out with the output listed below. Any advice would be much appreciated.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.13.0a0+08820cb0.nv22.07
- CPU Architecture: aarch64
- OS (e.g., Linux): Jetson Linux (Ubuntu)
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives: Honestly don't know the difference
- Python version: 3.8.10
- CUDA version: 11.4
- GPU models and configuration: Jetson Xavier NX
- Any other relevant information:
## Additional context
```
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/4] c++ -MMD -MF /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_classes.o.d -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -g -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -UNDEBUG -I/home/nvidia/TensorRT/pytorch_tensorrt/csrc -I/home/nvidia/TensorRT/pytorch_tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-TRTorch/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-Torch-TensorRT/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-TensorRT/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-tensorrt/external/tensorrt/include -I/home/nvidia/TensorRT/py/../ -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/TH -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/THC -I/usr/local/cuda-11.4/include -I/usr/include/python3.8 -c -c /home/nvidia/TensorRT/py/torch_tensorrt/csrc/tensorrt_classes.cpp -o /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_classes.o -Wno-deprecated -Wno-deprecated-declarations -D_GLIBCXX_USE_CXX11_ABI=1 -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1013"' -DTORCH_EXTENSION_NAME=_C -D_GLIBCXX_USE_CXX11_ABI=1 -std=c++14
FAILED: /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_classes.o
c++ -MMD -MF /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_classes.o.d -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -g -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -UNDEBUG -I/home/nvidia/TensorRT/pytorch_tensorrt/csrc -I/home/nvidia/TensorRT/pytorch_tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-TRTorch/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-Torch-TensorRT/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-TensorRT/external/tensorrt/include -I/home/nvidia/TensorRT/py/../bazel-tensorrt/external/tensorrt/include -I/home/nvidia/TensorRT/py/../ -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/TH -I/home/nvidia/.local/lib/python3.8/site-packages/torch/include/THC -I/usr/local/cuda-11.4/include -I/usr/include/python3.8 -c -c /home/nvidia/TensorRT/py/torch_tensorrt/csrc/tensorrt_classes.cpp -o /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_classes.o -Wno-deprecated -Wno-deprecated-declarations -D_GLIBCXX_USE_CXX11_ABI=1 -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1013"' -DTORCH_EXTENSION_NAME=_C -D_GLIBCXX_USE_CXX11_ABI=1 -std=c++14
c++: fatal error: Killed signal terminated program cc1plus
compilation terminated.
[2/4] c++ -MMD -MF /home/nvidia/TensorRT/py/build/temp.linux-aarch64-3.8/torch_tensorrt/csrc/tensorrt_backend.o.d -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -g -fstack-protector-strong -Wformat -Werror=forma
|
https://github.com/pytorch/TensorRT/issues/1295
|
closed
|
[
"question"
] | 2022-08-21T03:33:07Z
| 2022-08-22T00:38:23Z
| null |
HugeBob
|
pytorch/pytorch
| 83,721
|
How to export a simple model using List.__contains__ to ONNX
|
### 🐛 Describe the bug
When using torch.jit.script, the message shows that \_\_contains__ method is not supported.
This is a reduced part of my model, the function should be tagged with torch.jit.script because there's a for loop using list.\_\_contains__
And I want to export it to an onnx file but failed with the following output.
### Code
````python
from typing import List, Dict
import torch
x = torch.tensor([[59, 26, 32, 31, 58, 37, 12, 8, 8, 32, 27, 27, 35, 9, 3, 44, 22, 36,
22, 61, 51, 35, 15, 13, 14, 32, 22, 21, 9]], dtype=torch.long)
nums = [3, 4, 5, 6, 7, 8, 9, 14, 15, 16, 17, 18, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 37, 38, 39, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57]
@torch.jit.script
def batch(x, l: List[int]):
for i in range(len(x)):
for j in range(len(x[i])):
if x[i, j] in l:
x[i, j] *= 2
return x
class Module1(torch.nn.Module):
def forward(self, x):
return batch(x, nums)
m1 = Module1()
print(m1(x))
torch.onnx.export(m1,
(x),
"2.onnx",
verbose=True,
input_names=["x"],
dynamic_axes={
"x": {
1: "frames",
},
},
opset_version=11,
)
````
### Output
````
Traceback (most recent call last):
File "E:\My Files\Projects\Python\test\test.py", line 28, in <module>
torch.onnx.export(m1,
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 350, in export
return utils.export(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 163, in export
_export(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1074, in _export
graph, params_dict, torch_out = _model_to_graph(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 731, in _model_to_graph
graph = _optimize_graph(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 308, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1401, in _run_symbolic_function
return symbolic_fn(ctx, g, *inputs, **attrs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\symbolic_opset9.py", line 5064, in Loop
torch._C._jit_pass_onnx_block(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1401, in _run_symbolic_function
return symbolic_fn(ctx, g, *inputs, **attrs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\symbolic_opset9.py", line 5064, in Loop
torch._C._jit_pass_onnx_block(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1421, in _run_symbolic_function
raise symbolic_registry.UnsupportedOperatorError(
torch.onnx.symbolic_registry.UnsupportedOperatorError: Exporting the operator ::__contains_ to ONNX opset version 11 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub.
````
### Versions
PyTorch version: 1.12.1+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 家庭中文版
GCC version: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0
Clang version: Could not collect
CMake version: version 3.23.2
Libc version: N/A
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:51:29) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19044-SP0
Is CUDA available: True
CUDA runtime version: 11.5.119
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 512.78
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==0.7.1
[pip3] torch==1.12.1+cu113
[pip3] torchaudio==0.12.1+cu113
[pip3] torchvision==0.13.1+cu113
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch-lightning 0.7.1 pypi_0 pypi
[conda] torch 1.12.1+cu113
|
https://github.com/pytorch/pytorch/issues/83721
|
closed
|
[
"module: onnx",
"triaged",
"onnx-needs-info"
] | 2022-08-19T03:05:43Z
| 2024-04-01T16:53:35Z
| null |
SineStriker
|
pytorch/pytorch
| 83,685
|
How to use accessors for fast elementwise write?
|
### 📚 The doc issue

As seen above from Libtorch documentation, accessors can be used for fast element wise read operations on Libtorch tensors.
However, is there a similar functionality for write operations as well?
The use case is when preparing a data frame, we could directly use a CPU tensor, write into it and then just copy it to CUDA.
Presently I make a normal array, copy array to CPU tensor using from_blob() and then transfer it to CUDA.
Best Regards
Sambit
### Suggest a potential alternative/fix
_No response_
|
https://github.com/pytorch/pytorch/issues/83685
|
closed
|
[] | 2022-08-18T16:50:28Z
| 2022-08-24T20:36:19Z
| null |
SM1991CODES
|
pytorch/TensorRT
| 1,282
|
❓ [Question] How do you solve the error: Expected Tensor but got Uninitialized?
|
## ❓ Question
Currently, I am compiling a custom segmentation model using torch_tensorrt.compile(), using a model script obtained from jit. The code to compile is as follows:
```
scripted_model = torch.jit.freeze(torch.jit.script(model))
inputs = [torch_tensorrt.Input(
min_shape=[2, 3, 600, 400],
opt_shape=[2, 3, 600, 400],
max_shape=[2, 3, 600, 400],
dtype=torch.float,
)]
enabled_precisions = {torch.float, torch.half}
with torch_tensorrt.logging.debug():
trt_ts_module = torch_tensorrt.compile(scripted_model, inputs=inputs, enabled_precisions=enabled_precisions)
```
The code fails to compile at the following step:
```
a = self.compression(torch.cat(x_list, 1))
b = self.shortcut(x)
c = a + b
return c
```
, throwing the following error:
```
Traceback (most recent call last):
File "test.py", line 118, in <module>
trt_ts_module = torch_tensorrt.compile(scripted_model, inputs=inputs, enabled_precisions=enabled_precisions)
File "/home/oem/.pyenv/versions/ddrnet/lib/python3.8/site-packages/torch_tensorrt/_compile.py", line 115, in compile
return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)
File "/home/oem/.pyenv/versions/ddrnet/lib/python3.8/site-packages/torch_tensorrt/ts/_compiler.py", line 113, in compile
compiled_cpp_mod = _C.compile_graph(module._c, _parse_compile_spec(spec))
RuntimeError: Expected Tensor but got Uninitialized
```
It seems that some variable is uninitialized. However, the strange thing is that replacing the previous code with the following code pieces both compile:
```
a = self.compression(torch.cat(x_list, 1))
return a
```
and
```
b = self.shortcut(x)
return b
```
So, somehow taking the sum of these two tensors results in a failure to compile. Do you have any suggestions I can try such that this step compiles as well?
## What you have already tried
Tried adding the following two parameters to the compilation step as well:
```
trt_ts_module = torch_tensorrt.compile(scripted_model, inputs=inputs, enabled_precisions=enabled_precisions, torch_executed_ops=["prim::ListConstruct"], min_block_size=1)
trt_ts_module = torch_tensorrt.compile(scripted_model, inputs=inputs, enabled_precisions=enabled_precisions, torch_executed_ops=["prim::ListConstruct"])
trt_ts_module = torch_tensorrt.compile(scripted_model, inputs=inputs, enabled_precisions=enabled_precisions, min_block_size=1)
```
, but these resulted in different errors, thus I decided not to use these parameters for now.
## Environment
- PyTorch Version (e.g., 1.0): 1.11.0+cu113
- Torch-TensorRT version: 1.1.0
- CPU Architecture: x86_64
- OS (e.g., Linux): Ubuntu 20.04 (kernel: 5.4.0-124-generic)
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip, from within a virtual environment (pyenv)
- Are you using local sources or building from archives: No
- Python version: 3.8.13
- CUDA version: 11.7 (Nvidia Driver: 515.65.01)
- GPU models and configuration: Nvidia RTX A2000
Looking forwards to your answer, thanks in advance.
|
https://github.com/pytorch/TensorRT/issues/1282
|
closed
|
[
"question"
] | 2022-08-18T13:04:23Z
| 2022-10-11T15:42:19Z
| null |
Mark-M2L
|
pytorch/data
| 742
|
[Discussion] Is the implementation of `cycler` efficient?
|
TL;DR: It seems in most cases users might be better off using `.flatmap(lambda x: [x for _ in n_repeat])` rather than `.cycle(n_repeat)`.
Here is the [implementation](https://github.com/pytorch/data/blob/main/torchdata/datapipes/iter/util/cycler.py), basically `Cycler` reads from the source DataPipe for `n` number of times.
Things to consider:
1. This means repeating certain operations (e.g. reading from disk, complicated transformation) for `n` number of times, unless you use `in_memory_cache`.
2. If `shuffle` is used afterwards, I believe `.flatmap(lambda x: [x for _ in n_repeat])` is strictly better than `.cycle(n_repeat)`.
3. For `input = [0, 1, 2]`, the major difference is that `.cycle` returns `[0, 1, 2, 0, 1, 2]` compared to `.flatmap(...)` returning `[0, 0, 1, 1, 2, 2]`.
Questions:
1. Should we change the implementation?
2. Should we add something like `.repeat()` which basically does `.flatmap(lambda x: [x for _ in n_repeat])`?
3. Should we advise users to use `.flatmap(...)` instead unless they specifically want the ordering of `[0, 1, 2, 0, 1, 2]`?
@VitalyFedyunin @ejguan Let me know what you think.
|
https://github.com/meta-pytorch/data/issues/742
|
closed
|
[] | 2022-08-17T22:55:30Z
| 2022-08-30T18:57:10Z
| 4
|
NivekT
|
pytorch/data
| 736
|
Fix & Implement xdoctest
|
### 📚 The doc issue
There is a PR https://github.com/pytorch/pytorch/pull/82797 landed into PyTorch core, which adds the functionality to validate if the example in comment is runnable.
However, in the example of PyTorch Core, we normally refer `torchdata` in all examples for the sake of unification of importing path rather than directly importing `DataPipes` from pytorch core. This would cause `xdoctest` always failing. TBH, I don't know how to solve this problem without changing it back to `import torch.data.utils....`.
But, for `torchdata` project, we can do the similar work as a BE project to enable all doc test over the examples to prevent any failing test in our documentation.
### Suggest a potential alternative/fix
_No response_
|
https://github.com/meta-pytorch/data/issues/736
|
open
|
[
"Better Engineering"
] | 2022-08-16T13:49:46Z
| 2022-08-16T19:04:24Z
| 0
|
ejguan
|
pytorch/TensorRT
| 1,272
|
❓ [Question] How can I debug the error: Unable to freeze tensor of type Int64/Float64 into constant layer, try to compile model with truncate_long_and_double enabled
|
## ❓ Question
Converting a model to Tensor Engine with the next code does not work
Input:
```
trt_model = ttrt.compile(traced_model, "default",
[ttrt.Input((1, 3, 224, 224), dtype=torch.float32)],
torch.float32, truncate_long_and_double=False)
```
Output:
`RuntimeError: [Error thrown at core/conversion/converters/converter_util.cpp:167] Unable to freeze tensor of type Int64/Float64 into constant layer, try to compile model with truncate_long_and_double enabled
`
Running with `truncate_long_and_double=True` works but I want to understand what is going on wrong. So I ran
```
ttrt.logging.set_reportable_log_level(ttrt.logging.Level.Debug)
trt_model = ttrt.compile(traced_model, "default",
[ttrt.Input((1, 3, 224, 224), dtype=torch.float32)],
torch.float32, truncate_long_and_double=False)
```
but the output is not as clear as I expected (Next comment). Can you explain me the possible things that could raise this type of error? Sorry for the long logs, I worked in a 'tiny' version of the model to try make them shorter before writing here >.<
## Environment
- PyTorch Version (e.g., 1.0): 1.11.0+cu113
- OS (e.g., Linux): 22.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Are you using local sources or building from archives:
- Python version: 3.10
- CUDA version: 11.3
- GPU models and configuration: RTX3090
|
https://github.com/pytorch/TensorRT/issues/1272
|
closed
|
[
"question"
] | 2022-08-16T13:40:02Z
| 2022-08-22T18:14:00Z
| null |
mjack3
|
huggingface/optimum
| 351
|
Add all available ONNX models to ORTConfigManager
|
This issue is linked to the [ONNXConfig for all](https://huggingface.co/OWG) working group created for implementing an ONNXConfig for all available models. Let's extend our work and try to add all models with a fully functional ONNXConfig implemented to ORTConfigManager.
Adding models to ORTConfigManager will allow 🤗 Optimum users to boost even more their model with ONNX optimization capacity!
Feel free to join us in this adventure! Join the org by clicking [here](https://huggingface.co/organizations/OWG/share/TskjfGaGjGnMXXssbPPXrQWEIbosGqZshZ)
Here is a non-exhaustive list of models that have one ONNXConfig and could be added to ORTConfigManager:
*This includes only models with ONNXConfig implemented, if your target model doesn't have an ONNXConfig, please open an issue/or implement it (even cooler) in the 🤗 Transformers repository. Check [this issue](https://github.com/huggingface/transformers/issues/16308) to know how to do*
* [x] Albert
* [x] BART
* [ ] BeiT
* [x] BERT
* [x] BigBird
* [ ] BigBirdPegasus
* [x] Blenderbot
* [ ] BlenderbotSmall
* [x] BLOOM
* [x] CamemBERT
* [ ] CLIP
* [x] CodeGen
* [ ] ConvNext
* [ ] ConvBert
* [ ] Data2VecText
* [ ] Data2VecVision
* [x] Deberta
* [x] Deberta-v2
* [ ] DeiT
* [ ] DETR
* [x] Distilbert
* [x] ELECTRA
* [ ] Flaubert
* [x] GptBigCode
* [x] GPT2
* [x] GPTJ
* [x] GPT-NEO
* [x] GPT-NEOX
* [ ] I-BERT
* [ ] LayoutLM
* [ ] LayoutLMv2
* [ ] LayoutLMv3
* [ ] LeViT
* [x] Llama
* [x] LongT5
* [x] M2M100
* [x] mBART
* [x] MT5
* [x] MarianMT
* [ ] MobileBert
* [ ] MobileViT
* [x] nystromformer
* [ ] OpenAIGPT-2
* [ ] PLBart
* [x] Pegasus
* [ ] Perceiver
* [ ] ResNet
* [ ] RoFormer
* [x] RoBERTa
* [ ] SqueezeBERT
* [x] T5
* [x] ViT
* [x] Whisper
* [ ] XLM
* [x] XLM-RoBERTa
* [ ] XLM-RoBERTa-XL
* [ ] YOLOS
If you want an example of implementation, I did one for `MT5` #341.
You need to check how the `attention_heads` number and `hidden_size` arguments are named in the original implementation of your target model in the 🤗 Transformers source code. And then add it to the `_conf` dictionary. Finally, add your implemented model to tests to make it fully functional.
|
https://github.com/huggingface/optimum/issues/351
|
open
|
[
"good first issue"
] | 2022-08-16T08:18:50Z
| 2025-11-19T13:24:40Z
| 3
|
chainyo
|
huggingface/optimum
| 350
|
Migrate metrics used in all examples from Datasets to Evaluate
|
### Feature request
Copied from https://github.com/huggingface/transformers/issues/18306
The metrics are slowly leaving [Datasets](https://github.com/huggingface/datasets) (they are being deprecated as we speak) to move to the [Evaluate](https://github.com/huggingface/evaluate) library. We are looking for contributors to help us with the move.
Normally, the migration should be as easy as replacing the import of `load_metric` from Datasets to the `load` function in Evaluate. See a use in this [Accelerate example](https://github.com/huggingface/accelerate/blob/1486fa35b19abc788ddb609401118a601e68ff5d/examples/nlp_example.py#L104). To fix all tests, a dependency to evaluate will need to be added in the [requirements file](https://github.com/huggingface/transformers/blob/main/examples/pytorch/_tests_requirements.txt) (this is the link for PyTorch, there is another one for the Flax examples).
If you're interested in contributing, please reply to this issue with the examples you plan to move.
### Motivation
/
### Your contribution
/
|
https://github.com/huggingface/optimum/issues/350
|
closed
|
[] | 2022-08-16T08:04:07Z
| 2022-10-27T10:07:58Z
| 0
|
fxmarty
|
pytorch/data
| 732
|
Recommended way to shuffle intra and inter archives?
|
Say I have a bunch of archives containing samples. In my case each archive is a pickle file containing a list of samples, but it could be a tar or something else.
I want to shuffle between archives (inter) and within archives (intra). My current way of doing it is below. Is there a more canonical solution?
```py
from torchdata.dataloader2 import DataLoader2, adapter
from torchdata.datapipes.iter import IterDataPipe, FileLister, IterableWrapper
from pathlib import Path
import pickle
# Create archives
root = Path("/tmp/dataset/")
with open(root / "1.pkl", "wb") as f:
pickle.dump(list(range(10)), f)
with open(root / "2.pkl", "wb") as f:
pickle.dump(list(range(10, 20)), f)
class PickleLoaderDataPipe(IterDataPipe):
def __init__(self, source_datapipe):
self.source_datapipe = source_datapipe
def __iter__(self):
for path in self.source_datapipe:
with open(path, "rb") as f:
yield pickle.load(f) # <- this is a list
class ConcaterIterable(IterDataPipe):
# Same as unbatch(), kinda
def __init__(self, source_datapipe):
self.source_datapipe = source_datapipe
def __iter__(self):
for iterable in self.source_datapipe:
yield from iterable
def intra_archive_shuffle(archive_content):
return IterableWrapper(archive_content).shuffle()
dp = FileLister(str(root), masks=["*.pkl"])
dp = dp.shuffle() # inter-archive shuffling
dp = PickleLoaderDataPipe(dp)
dp = dp.map(intra_archive_shuffle)
dp = ConcaterIterable(dp) # Note: unbatch doesn't work because it's a datapipe of datapipes
print(list(dp))
```
|
https://github.com/meta-pytorch/data/issues/732
|
open
|
[] | 2022-08-15T17:14:39Z
| 2022-08-16T13:02:46Z
| 8
|
NicolasHug
|
pytorch/pytorch
| 83,392
|
How to turn off determinism just for specific operations, e.g. upsampling through bilinear interpolation?
|
This is the error caused by upsampling through bilinear interpolation when trying to use deterministic algorithms:
`RuntimeError: upsample_bilinear2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True)'. You can turn off determinism just for this operation if that's acceptable for your application. You can also file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation.`
How to turn off determinism just for upsampling_bilinear2d (and any other operation)? Thanks!
cc @ngimel @mruberry @kurtamohler
|
https://github.com/pytorch/pytorch/issues/83392
|
open
|
[
"module: cuda",
"triaged",
"module: determinism"
] | 2022-08-14T12:15:32Z
| 2022-08-15T04:42:36Z
| null |
Jingling1
|
huggingface/datasets
| 4,839
|
ImageFolder dataset builder does not read the validation data set if it is named as "val"
|
**Is your feature request related to a problem? Please describe.**
Currently, the `'imagefolder'` data set builder in [`load_dataset()`](https://github.com/huggingface/datasets/blob/2.4.0/src/datasets/load.py#L1541] ) only [supports](https://github.com/huggingface/datasets/blob/6c609a322da994de149b2c938f19439bca99408e/src/datasets/data_files.py#L31) the following names as the validation data set directory name: `["validation", "valid", "dev"]`. When the validation directory is named as `'val'`, the Data set will not have a validation split. I expected this to be a trivial task but ended up spending a lot of time before knowing that only the above names are supported.
Here's a minimal example of `val` not being recognized:
```python
import os
import numpy as np
import cv2
from datasets import load_dataset
# creating a dummy data set with the following structure:
# ROOT
# | -- train
# | ---- class_1
# | ---- class_2
# | -- val
# | ---- class_1
# | ---- class_2
ROOT = "data"
for which in ["train", "val"]:
for class_name in ["class_1", "class_2"]:
dir_name = os.path.join(ROOT, which, class_name)
if not os.path.exists(dir_name):
os.makedirs(dir_name)
for i in range(10):
cv2.imwrite(
os.path.join(dir_name, f"{i}.png"),
np.random.random((224, 224))
)
# trying to create a data set
dataset = load_dataset(
"imagefolder",
data_dir=ROOT
)
>> dataset
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 20
})
})
# ^ note how the dataset only has a 'train' subset
```
**Describe the solution you'd like**
The suggestion is to include `"val"` to [that list ](https://github.com/huggingface/datasets/blob/6c609a322da994de149b2c938f19439bca99408e/src/datasets/data_files.py#L31) as that's a commonly used phrase to name the validation directory.
Also, In the documentation, explicitly mention that only such directory names are supported as train/val/test directories to avoid confusion.
**Describe alternatives you've considered**
In the documentation, explicitly mention that only such directory names are supported as train/val/test directories without adding `val` to the above list.
**Additional context**
A question asked in the forum: [
Loading an imagenet-style image dataset with train/val directories](https://discuss.huggingface.co/t/loading-an-imagenet-style-image-dataset-with-train-val-directories/21554)
|
https://github.com/huggingface/datasets/issues/4839
|
closed
|
[
"enhancement"
] | 2022-08-12T13:26:00Z
| 2022-08-30T10:14:55Z
| 1
|
akt42
|
huggingface/datasets
| 4,836
|
Is it possible to pass multiple links to a split in load script?
|
**Is your feature request related to a problem? Please describe.**
I wanted to use a python loading script in hugging face datasets that use different sources of text (it's somehow a compilation of multiple datasets + my own dataset) based on how `load_dataset` [works](https://huggingface.co/docs/datasets/loading) I assumed I could do something like bellow in my loading script:
```python
...
_URL = "MY_DATASET_URL/resolve/main/data/"
_URLS = {
"train": [
"FIRST_URL_TO.txt",
_URL + "train-00000-of-00001-676bfebbc8742592.parquet"
]
}
...
```
but when loading the dataset it raises the following error:
```python
File ~/.local/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
...
668 if isinstance(a, str):
669 # Force-cast str subclasses to str (issue #21127)
670 parts.append(str(a))
TypeError: expected str, bytes or os.PathLike object, not list
```
**Describe the solution you'd like**
I believe since it's possible for `load_dataset` to get list of URLs instead of just a URL for `train` split it can be possible here too.
**Describe alternatives you've considered**
An alternative solution would be to download all needed datasets locally and `push_to_hub` them all, but since the datasets I'm talking about are huge it's not among my options.
**Additional context**
I think loading `text` beside the `parquet` is completely a different issue but I believe I can figure it out by proposing a config for my dataset to load each entry of `_URLS['train']` separately either by `load_dataset("text", ...` or `load_dataset("parquet", ...`.
|
https://github.com/huggingface/datasets/issues/4836
|
open
|
[
"enhancement"
] | 2022-08-12T11:06:11Z
| 2022-08-12T11:06:11Z
| 0
|
sadrasabouri
|
pytorch/TensorRT
| 1,253
|
❓ [Question] How to load a TRT_Module in python environment on Windows which has been compiled on C++ Windows ?
|
## ❓ Question
I have compiled torch_trt module using libtorch on C++ windows platform. This module is working perfectly on C++ for inference, however I want to use it in Python program on windows platform. How to load this module on python?
When I tried to load it with torch.jit.load() or torch.jit.load() it is throwing following error:
`File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\serialization.py:711, in load(f, map_location, pickle_module, **pickle_load_args)
707 warnings.warn("'torch.load' received a zip file that looks like a TorchScript archive"
708 " dispatching to 'torch.jit.load' (call 'torch.jit.load' directly to"
709 " silence this warning)", UserWarning)
710 opened_file.seek(orig_position)
--> 711 return torch.jit.load(opened_file)
712 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
713 return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\jit\_serialization.py:164, in load(f, map_location, _extra_files)
162 cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
163 else:
--> 164 cpp_module = torch._C.import_ir_module_from_buffer(
165 cu, f.read(), map_location, _extra_files
166 )
168 # TODO: Pretty sure this approach loses ConstSequential status and such
169 return wrap_cpp_module(cpp_module)
RuntimeError:
Unknown type name '__torch__.torch.classes.tensorrt.Engine':
File "code/__torch__/movinets/models.py", line 4
__parameters__ = []
__buffers__ = []
__torch___movinets_models_MoViNet_trt_engine_ : __torch__.torch.classes.tensorrt.Engine
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward(self_1: __torch__.movinets.models.MoViNet_trt,
input_0: Tensor) -> Tensor:`
## What you have already tried
Since torch_trt is not supported for Python on windows I picked `libtorchtrt_runtime.so` from linux `python3.8/site-packages/torch_tensorrt/lib/libtorchtrt_runtime.so` path and loaded on python on windows through torch.ops.load_library(). However it throws another error
`File "\video_play.py", line 189, in get_torch_tensorrt_converted_model torch.ops.load_library("libtorchtrt_runtime.so") File "C:\Users\NomanAnjum\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\_ops.py", line 255, in load_library ctypes.CDLL(path) File "C:\Users\NomanAnjum\AppData\Local\Programs\Python\Python310\lib\ctypes\__init__.py", line 374, in __init__ self._handle = _dlopen(self._name, mode) OSError: [WinError 193] %1 is not a valid Win32 application`
## Environment
Windows 11
CPU : i9-11980HK x86-64
GPU : RTX 3080 Mobile
Cuda : 11.5.2
Cudnn : 8.3.1
Libtorch : 1.11
Tensor_RT : 8.4.1.5
Visual Studio 2019
Python 3.10,3.8
#### Is there a way to load it in python??
|
https://github.com/pytorch/TensorRT/issues/1253
|
closed
|
[
"question",
"No Activity",
"channel: windows"
] | 2022-08-11T06:26:05Z
| 2023-02-26T00:02:28Z
| null |
ghost
|
pytorch/pytorch
| 83,227
|
QAT the bias is the int32, how to set the int8?
|
### 🐛 Describe the bug
i try to do quantization, the weight is int8 ,but the bias is int32, i want to set the bias ---> int8, what i need to do ?
thanks
### Versions
help me, thanks
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo
|
https://github.com/pytorch/pytorch/issues/83227
|
closed
|
[
"oncall: quantization"
] | 2022-08-11T03:11:12Z
| 2022-08-11T23:10:24Z
| null |
aimen123
|
huggingface/datasets
| 4,820
|
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
|
Hi, when i try to run prepare_dataset function in [fine tuning ASR tutorial 4](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) , i got this error.
I got this error
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
There is no other logs available, so i have no clue what is the cause of it.
```
def prepare_dataset(batch):
audio = batch["path"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
data = data.map(prepare_dataset, remove_columns=data.column_names["train"],
num_proc=4)
```
Specify the actual results or traceback.
There is no traceback except
`Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4820
|
closed
|
[
"bug"
] | 2022-08-10T19:42:33Z
| 2022-08-10T19:53:10Z
| 1
|
talhaanwarch
|
pytorch/functorch
| 999
|
vmap and forward-mode AD fail sometimes on in-place views
|
## The Problem
```py
import torch
from functorch import jvp, vmap
from functools import partial
B = 2
def f(x, y):
x = x.clone()
view = x[0]
x.copy_(y)
return view, x
def push_jvp(x, y, yt):
return jvp(partial(f, x), (y,), (yt,))
x = torch.randn(2, B, 6)
y = torch.randn(2, 6, B)
yt = torch.randn(2, 6, B)
outs, tangents = vmap(push_jvp, in_dims=(1, 2, 2))(x, y, yt)
```
raises the following:
```
RuntimeError: vmap: Calling Tensor.as_strided is not supported unless the batch dims being vmapped over are at the front of
the tensor (in memory layout). When they are not at the front of the tensor this operation can be error prone so we actively
discourage it; please file us a bug report and/or try to express the as_strided operation in terms of PyTorch view operatio
ns
```
If I am understanding what is going on correctly, the root cause of the problem is that, ignoring vmap for a second, in `x.copy_(y)`, x is a regular Tensor and y is a dual tensor:
- the copy_ causes x.tangent to be a copy of y.tangent
- then, the tangent on the base (x) gets propagated to the views. This happens by calling .as_strided. `view.tangent` gets assigned `x.tangent.as_strided(something)`
Now, if `y.tangent` is a BatchedTensor, then calling `as_strided` on it may raise the above error message.
## Is this actually a problem?
Previously, our approach was to say that vmap x jvp composition only works when the user must only vmap over dimension 0. However, that's not quite correct -- if the user users non-contiguous tensors, then it'll run into this problem. Also, vmap x jvp can produce tensors where the batch dimension is not at 0, so the user has no control over this.
## Potential solutions
1. When a tangent gets propagated to views as a result of an in-place operation, instead of calling `as_strided`, we should call the original view operation. This means we should save the original view operation somewhere.
1. (From Jeffrey) An alternative to (1) is: instead of calling as_strided, figure out what the correct non-as_strided view operation(s) are by reading the sizes/sizes/storage_offset, and call that instead.
1. It is possible to write a batching rule for a "safe as_strided". An as_strided call is safe if it does not expose memory that was not previously exposed in the Tensor. We would (a) add a `safe_as_strided` operator, (b) save some metadata on if a view Tensor was created from a base through a chain of "safe" operations or not, and (c) dispatch to either `safe_as_strided` or `as_strided`
Thoughts? cc @soulitzer @albanD
|
https://github.com/pytorch/functorch/issues/999
|
open
|
[] | 2022-08-10T17:45:17Z
| 2022-08-16T20:46:48Z
| 9
|
zou3519
|
pytorch/pytorch
| 83,135
|
torch.nn.functional.avg_pool{1|2|3}d error message does not match what is described in the documentation
|
### 📚 The doc issue
Parameter 'kernel_size' and 'stride' of torch.nn.functional.avg_pool{1|2|3}d can be a single number or a tuple. However, I found that error message only mentioned tuple of ints which means parameter 'kernel_size' and 'stride' can be only int number or tuple of ints.
```
import torch
results={}
arg_1 = torch.rand([1, 1, 7], dtype=torch.float32)
arg_2 = 8.0
arg_3 = 2
arg_4 = 0
arg_5 = True
arg_6 = True
results['res'] = torch.nn.functional.avg_pool1d(arg_1,arg_2,arg_3,arg_4,arg_5,arg_6,)
#TypeError: avg_pool1d(): argument 'kernel_size' (position 2) must be tuple of ints, not float
```
```
import torch
results={}
arg_1 = torch.rand([16, 528, 16, 16], dtype=torch.float32)
arg_2 = 32.0
arg_3 = 13.0
arg_4 = 0
arg_5 = False
arg_6 = True
arg_7 = None
results['res'] = torch.nn.functional.avg_pool2d(arg_1,arg_2,arg_3,arg_4,arg_5,arg_6,arg_7,)
#TypeError: avg_pool2d(): argument 'stride' (position 3) must be tuple of ints, not float
```
```
import torch
results={}
arg_1 = torch.rand([20, 16, 50, 44, 31], dtype=torch.float32)
arg_2_0 = 3.0
arg_2_1 = 2
arg_2_2 = 2
arg_2 = [3.0,2,2]
arg_3_0 = 2
arg_3_1 = 1
arg_3_2 = 2
arg_3 = [2,1,2]
arg_4 = 0
arg_5 = False
arg_6 = True
arg_7 = None
results['res'] = torch.nn.functional.avg_pool3d(arg_1,arg_2,arg_3,arg_4,arg_5,arg_6,arg_7,)
#TypeError: avg_pool3d(): argument 'kernel_size' must be tuple of ints, but found element of type float at pos 1
```
### Suggest a potential alternative/fix
It would be great if the doc could be written as follows:
kernel_size – size of the pooling region. Can be a int number or a tuple (kT, kH, kW).
stride – stride of the pooling operation. Can be a int number or a tuple (sT, sH, sW).
Or modify the error message so that it matches the document description.
cc @svekars @holly1238 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
|
https://github.com/pytorch/pytorch/issues/83135
|
open
|
[
"module: docs",
"module: nn",
"triaged"
] | 2022-08-10T01:11:59Z
| 2022-08-10T12:57:45Z
| null |
cheyennee
|
pytorch/test-infra
| 516
|
[CI] Use job summaries to display how to replicate failures on specific configs
|
For configs such as slow, dynamo, and parallel-native, reproducing a CI error is more involved than just rerunning the command locally. We should use tools (like job summaries) to give people the context they'd need to repro a bug.
|
https://github.com/pytorch/test-infra/issues/516
|
open
|
[] | 2022-08-09T18:15:15Z
| 2022-11-15T19:51:40Z
| null |
janeyx99
|
pytorch/TensorRT
| 1,243
|
❓ [Question] How to correctly configure LD_LIBRARY_PATH
|
## ❓ Question
Hello, after installing torch_tensorrt on my jetson xavier using jetpack 4.6, I cannot import it. I am having a similar issue to other bugs that have been reported and answered. I am wondering though, how do you correctly add tensorrt to LD_LIBRARY_PATH? (Proposed solution from other bugs).
## What you have already tried
The tensorrt package is stored in /usr/lib/python3.6/dist-packages/tensorrt
I try adding this to LD_LIBRARY_PATH like so:
`export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/python3.6/dist-packages/tensorrt`
This addition hadn't changed the import error, unfortunately.
## Environment
> Jetpack 4.6
|
https://github.com/pytorch/TensorRT/issues/1243
|
closed
|
[
"question"
] | 2022-08-08T20:24:55Z
| 2022-08-08T20:35:00Z
| null |
kneatco
|
huggingface/dataset-viewer
| 502
|
Improve the docs: what is needed to make the dataset viewer work?
|
See https://discuss.huggingface.co/t/the-dataset-preview-has-been-disabled-on-this-dataset/21339
|
https://github.com/huggingface/dataset-viewer/issues/502
|
closed
|
[
"documentation"
] | 2022-08-08T13:27:21Z
| 2022-09-19T09:12:00Z
| null |
severo
|
pytorch/TensorRT
| 1,235
|
❓ [Question] How do you debug errors in the compilation step?
|
## ❓ Question
Hello all,
After training a model, I decided to use torch_tensorrt to test and hopefully increase inference speed. When compiling the custom model, I get the following error: `RuntimeError: Trying to create tensor with negative dimension -1: [-1, 3, 600, 400]`. This did not occur when doing inference in regular PyTorch. Further the following warning was issued (before receiving the error):
```WARNING: [Torch-TensorRT] - For input x.1, found user specified input dtype as Float16, however when inspecting the graph, the input type expected was inferred to be Float
The compiler is going to use the user setting Float16
This conflict may cause an error at runtime due to partial compilation being enabled and therefore
compatibility with PyTorch's data type convention is required.
If you do indeed see errors at runtime either:
- Remove the dtype spec for x.1
- Disable partial compilation by setting require_full_compilation to True```
The code to compile is as follows:
```inputs = [torch_tensorrt.Input(
min_shape=[2, 3, 600, 400],
opt_shape=[4, 3, 600, 400],
max_shape=[8, 3, 600, 400],
dtype=torch.half,
)]
enabled_precisions = {torch.float, torch.half}
trt_ts_module = torch_tensorrt.compile(model, inputs=inputs, enabled_precisions=enabled_precisions)
```
My question is: what can I do to properly debug this error?
## What you have already tried
- Use `mobilenet_v2`, as specified in the example https://pytorch.org/TensorRT/tutorials/use_from_pytorch.html#use-from-pytorch. This model compiles successfully.
- Change the input size (change the batch size, i.e. the first dimension, use shapes of >= 100). This gave the same error.
- Set `require_full_compilation` to True, which was not fruitful either.
## Environment
- PyTorch Version (e.g., 1.0): 1.11.0+cu113
- Torch-TensorRT version: 1.1.0
- CPU Architecture: x86_64
- OS (e.g., Linux): Ubuntu 20.04 (kernel: 5.4.0-122-generic)
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): `pip`, from within a virtual environment (`pyenv`)
- Are you using local sources or building from archives:
- Python version: 3.8.13
- CUDA version: 11.4.4 (Driver: 470.82.01)
- GPU models and configuration: Nvidia RTX A2000
- Any other relevant information: TensorRT has been installed via pip, to install torch_tensorrt (and getting it to import in Python), I followed the answer in the following issue: https://github.com/pytorch/TensorRT/issues/1026#issuecomment-1119561746
Looking forwards to your answer, thanks in advance.
|
https://github.com/pytorch/TensorRT/issues/1235
|
closed
|
[
"question"
] | 2022-08-05T15:23:53Z
| 2022-08-08T17:04:30Z
| null |
Mark-M2L
|
pytorch/TensorRT
| 1,233
|
❓ [Question] How to install "tensorrt" package?
|
## ❓ Question
I'm trying to install `torch-tensorrt` on a Jetson AGX Xavier. I first installed `pytorch` 1.12.0 and `torchvision` 0.13.0 following this [guide](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-11-now-available/72048). Then I installed `torch-tensorrt` following this [guide](https://pytorch.org/TensorRT/tutorials/installation.html#installation), and the compilation completed succesfully.
When I try to import `torch_tensorrt` it throws an error, saying it can't find a module named `tensorrt`. Where I can find this package?
## Environment
I'm using a Jetson AGX Xavier with Jetpack 5.0.1.
|
https://github.com/pytorch/TensorRT/issues/1233
|
closed
|
[
"question",
"component: dependencies",
"channel: linux-jetpack"
] | 2022-08-05T08:40:18Z
| 2022-12-15T17:36:36Z
| null |
domef
|
pytorch/data
| 718
|
Recommended practice to shuffle data with datapipes differently every epoch
|
### 📚 The doc issue
I was trying `torchdata` 0.4.0 and I found that shuffling with data pipes will always yield the same result across different epochs, unless I shuffle it again at the beginning of every epoch.
```python
# same_result.py
import torch
import torchdata.datapipes as dp
X = torch.randn(200, 5)
dpX = dp.map.SequenceWrapper(X)
dpXS = dpX.shuffle()
for _ in range(5):
for i in dpXS:
print(i) # always prints the same value
break
# different_result.py
import torch
import torchdata.datapipes as dp
X = torch.randn(200, 5)
dpX = dp.map.SequenceWrapper(X)
for _ in range(5):
dpXS = dpX.shuffle()
for i in dpXS:
print(i) # prints different values
break
```
I wonder what is the recommended practice to shuffle the data at the beginning of every epoch? Neither the documentation nor the examples seem to answer this question.
### Suggest a potential alternative/fix
_No response_
|
https://github.com/meta-pytorch/data/issues/718
|
closed
|
[] | 2022-08-05T02:12:25Z
| 2022-09-13T21:18:49Z
| 4
|
BarclayII
|
huggingface/dataset-viewer
| 498
|
Test cookie authentication
|
Testing token authentication is easy, see https://github.com/huggingface/datasets-server/issues/199#issuecomment-1205528302, but testing session cookie authentication might be a bit more complex since we need to log in to get the cookie. I prefer to get a dedicate issue for it.
|
https://github.com/huggingface/dataset-viewer/issues/498
|
closed
|
[
"question",
"tests"
] | 2022-08-04T17:06:31Z
| 2022-08-22T18:34:29Z
| null |
severo
|
huggingface/datasets
| 4,791
|
Dataset Viewer issue for Team-PIXEL/rendered-wikipedia-english
|
### Link
https://huggingface.co/datasets/Team-PIXEL/rendered-wikipedia-english/viewer/rendered-wikipedia-en/train
### Description
The dataset can be loaded fine but the viewer shows this error:
```
Server Error
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
```
I'm guessing this is because I recently renamed the dataset. Based on related issues (e.g. https://github.com/huggingface/datasets/issues/4759) , is there something server-side that needs to be refreshed?
### Owner
Yes
|
https://github.com/huggingface/datasets/issues/4791
|
closed
|
[
"dataset-viewer"
] | 2022-08-04T12:49:16Z
| 2022-08-04T13:43:16Z
| 1
|
xplip
|
pytorch/pytorch
| 82,751
|
Refactor how errors decide whether to append C++ stacktrace
|
### 🚀 The feature, motivation and pitch
Per @zdevito's comment in https://github.com/pytorch/pytorch/pull/82665/files#r936022305, we should refactor the way C++ stacktrace is appended to errors.
Currently, in https://github.com/pytorch/pytorch/blob/752579a3735ce711ccaddd8d9acff8bd6260efe0/torch/csrc/Exceptions.h, each error goes through a try/catch and the C++ stacktrace is conditioned on whether cpp stacktraces are enabled or not.
Instead, specific exceptions can have a flag that determines whether cpp stacktrace is added or not. Most errors would set this in their constructor based on the env variable, but for certain types of errors which always report cpp stacktrace, this can just be set to true and this field can be checked when reporting errors.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/pytorch/issues/82751
|
open
|
[
"triaged",
"better-engineering"
] | 2022-08-03T20:28:56Z
| 2022-08-03T20:28:56Z
| null |
rohan-varma
|
pytorch/data
| 712
|
Add Examples of Common Preprocessing Steps with IterDataPipe (such as splitting a data set into two)
|
### 📚 The doc issue
There are a few common steps that users often would like to do while preprocessing data, such as [splitting their data set](https://pytorch.org/docs/stable/data.html#torch.utils.data.random_split) into train and eval. There are documentation in PyTorch Core about how to do these things with `Dataset`. We should add the same to our documentation, specifically for `IterDataPipe`. Or create a link to PyTorch Core's documentation for reference when that is appropriate. This issue is driven by common questions we have received either in person or on the forum.
If we find that any functionality is missing for `IterDataPipe`, we should implement them.
|
https://github.com/meta-pytorch/data/issues/712
|
closed
|
[
"documentation"
] | 2022-08-02T23:58:09Z
| 2022-10-20T17:49:41Z
| 9
|
NivekT
|
pytorch/data
| 709
|
Update tutorial about shuffling before sharding
|
### 📚 The doc issue
The [tutorial](https://pytorch.org/data/beta/tutorial.html#working-with-dataloader) needs to update the actual reason about shuffling before sharding. It's not accurate.
Shuffling before sharding is required to achieve global shuffling rather than only shuffling inside each shard.
### Suggest a potential alternative/fix
_No response_
|
https://github.com/meta-pytorch/data/issues/709
|
closed
|
[
"documentation"
] | 2022-08-02T17:53:56Z
| 2022-08-04T22:06:36Z
| 2
|
ejguan
|
pytorch/data
| 707
|
Map-style DataPipe to read from s3
|
### 🚀 The feature
[Amazon S3 plugin for PyTorch ](https://aws.amazon.com/blogs/machine-learning/announcing-the-amazon-s3-plugin-for-pytorch/)proposes S3Dataset which is a Map-style PyTorch Dataset. I was looking for a similar feature in torchdata but only found [S3FileLoader](https://pytorch.org/data/main/generated/torchdata.datapipes.iter.S3FileLoader.html#torchdata.datapipes.iter.S3FileLoader) which doesn't meet my requirements.
Is there any implementation of a Map-style DataPipe I am missing? Or any method to do a similar thing with the existing tools?
The main requirement is that I need to read images from s3, apply a transformation, and keep them syncronized with a list of labels.
Thank you
### Motivation, pitch
Map-style DataPipe to read from s3 to complement the existing itetable style Datapipe to read from s3.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/meta-pytorch/data/issues/707
|
closed
|
[] | 2022-08-02T12:58:21Z
| 2022-08-04T13:31:32Z
| 10
|
gombru
|
pytorch/tutorials
| 1,993
|
Problem with the torchtext library text classification example
|
The first section of the [tutorial](https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html) suggests
`
import torch
from torchtext.datasets import AG_NEWS
train_iter = iter(AG_NEWS(split='train'))
`
which does not work yielding
`TypeError: _setup_datasets() got an unexpected keyword argument 'split'`
I might highlight as well that the string doc for AG_NEWS mentions
`train_dataset, test_dataset = torchtext.datasets.AG_NEWS(ngrams=3)`
cc @pytorch/team-text-core @Nayef211
|
https://github.com/pytorch/tutorials/issues/1993
|
closed
|
[
"question",
"module: torchtext",
"docathon-h1-2023",
"medium"
] | 2022-08-02T08:46:49Z
| 2023-06-12T19:42:05Z
| null |
EssamWisam
|
huggingface/datasets
| 4,776
|
RuntimeError when using torchaudio 0.12.0 to load MP3 audio file
|
Current version of `torchaudio` (0.12.0) raises a RuntimeError when trying to use `sox_io` backend but non-Python dependency `sox` is not installed:
https://github.com/pytorch/audio/blob/2e1388401c434011e9f044b40bc8374f2ddfc414/torchaudio/backend/sox_io_backend.py#L21-L29
```python
def _fail_load(
filepath: str,
frame_offset: int = 0,
num_frames: int = -1,
normalize: bool = True,
channels_first: bool = True,
format: Optional[str] = None,
) -> Tuple[torch.Tensor, int]:
raise RuntimeError("Failed to load audio from {}".format(filepath))
```
Maybe we should raise a more actionable error message so that the user knows how to fix it.
UPDATE:
- this is an incompatibility of latest torchaudio (0.12.0) and the sox backend
TODO:
- [x] as a temporary solution, we should recommend installing torchaudio<0.12.0
- #4777
- #4785
- [ ] however, a stable solution must be found for torchaudio>=0.12.0
Related to:
- https://github.com/huggingface/transformers/issues/18379
|
https://github.com/huggingface/datasets/issues/4776
|
closed
|
[] | 2022-08-01T14:11:23Z
| 2023-03-02T15:58:16Z
| 3
|
albertvillanova
|
pytorch/tutorials
| 1,991
|
Some typos in and a question from TorchScript tutorial
|
Hi, I first thank for this tutorial.
Here are some typos in the tutorial:
1.`be` in https://github.com/pytorch/tutorials/blob/7976ab181fd2a97b2775574eec284d1fc8abcfe0/beginner_source/Intro_to_TorchScript_tutorial.py#L42 should be `by`.
2.`succintly` in https://github.com/pytorch/tutorials/blob/7976ab181fd2a97b2775574eec284d1fc8abcfe0/beginner_source/Intro_to_TorchScript_tutorial.py#L114 should be `succinctly`.
3.In https://github.com/pytorch/tutorials/blob/7976ab181fd2a97b2775574eec284d1fc8abcfe0/beginner_source/Intro_to_TorchScript_tutorial.py#L206-L207 `TracedModule` is wrongly stated to be an instance of `ScriptModule`. I suggest that this line become:
```
# instance of ``torch.jit.TracedModule`` (which is a subclass of ``torch.jit.ScriptModule``)
```
4.Second part in https://github.com/pytorch/tutorials/blob/7976ab181fd2a97b2775574eec284d1fc8abcfe0/beginner_source/Intro_to_TorchScript_tutorial.py#L322-L323 seems somewhat ambiguous to me. What does it mean by the second `inline`?
cc @svekars
|
https://github.com/pytorch/tutorials/issues/1991
|
closed
|
[
"grammar"
] | 2022-08-01T13:21:26Z
| 2022-10-13T22:49:41Z
| 2
|
sadra-barikbin
|
huggingface/optimum
| 327
|
Any workable example of exporting and inferencing with GPU?
|
### System Info
```shell
Been tried many methods, but never successfully done it. Thanks.
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model.save_pretrained(save_directory, file_name=file_name)
tokenizer.save_pretrained(save_directory)
optimization_config = OptimizationConfig(optimization_level=99, optimize_for_gpu=True)
optimizer = ORTOptimizer.from_pretrained(
model_checkpoint,
feature="sequence-classification",
)
optimizer.export(
onnx_model_path=onnx_path,
onnx_optimized_model_output_path=os.path.join(save_directory, "model-optimized.onnx"),
optimization_config=optimization_config,
)```
### Expected behavior
NA
|
https://github.com/huggingface/optimum/issues/327
|
closed
|
[
"bug"
] | 2022-08-01T05:12:15Z
| 2022-08-01T06:19:26Z
| 1
|
lkluo
|
pytorch/data
| 705
|
Set better defaults for `MultiProcessingReadingService`
|
### 🚀 The feature
```python
class MultiProcessingReadingService(ReadingServiceInterface):
num_workers: int = get_number_of_cpu_cores()
pin_memory: bool = True
timeout: float
worker_init_fn: Optional[Callable[[int], None]] # Remove this?
prefetch_factor: int = profile_optimal_prefetch_factor(model : nn.Module)
persistent_workers: bool = True
```
I can add these, opening this issue to discuss whether it's a good idea to change defaults.
+: Users get better out of the box performance with `torchdata`
-: backward compatibility issues when moving from `dataloaderv1` to `dataloaderv2`
### Motivation, pitch
There are many issues on discuss, stack overflow, and blogs describing how people should configure data loaders for optimized performance. Since a lot of the tricks haven't changed like `pin_memory = true` or `num_workers = num_cpu_cores` or `persistent_workers=true` and since we're in the process of developing `dataloaderv2` now may be a good time to revisit these default values
* https://www.jpatrickpark.com/post/prefetcher/#:~:text=The%20prefetch_factor%20parameter%20only%20controls,samples%20prefetched%20across%20all%20workers.)
* https://stackoverflow.com/questions/53998282/how-does-the-number-of-workers-parameter-in-pytorch-dataloader-actually-work
* https://discuss.pytorch.org/t/when-to-set-pin-memory-to-true/19723
### Alternatives
1. Instead of setting reasonable defaults, we can instead extend the `linter.py` to suggest some of these tips if we notice some sources of slowdowns
2. Do nothing, suggest people read documentation when configuring performance
### Additional context
_No response_
|
https://github.com/meta-pytorch/data/issues/705
|
open
|
[
"enhancement"
] | 2022-07-31T22:46:33Z
| 2022-08-02T22:07:18Z
| 1
|
msaroufim
|
pytorch/pytorch
| 82,542
|
Is there Doc that explains how to call an extension op in another extension implementation?
|
### 📚 The doc issue
For example, there is an extension op which is installed from public repo via `pip install torch-scatter`, and in Python code, it's easy to use this extension:
```py
import torch
output = torch.ops.torch_scatter.scatter_max(x, index)
```
However, I'm writing an C++ extension and want to call this extension as well, but I cannot find any doc that guides how to do this, or I don't know whether Pytorch C++ extension can even support it or not. Briefly, this is something I'd like to do in extension function:
```cpp
torch::Tensor my_op(torch::Tensor x, torch::Tensor y, torch::Tensor z) {
auto temp = torch::ops::torch_scatter::scatter_max(z, y.view(-1)); // not working
..
return temp;
}
```
### Suggest a potential alternative/fix
_No response_
cc @svekars @holly1238 @jbschlosser
|
https://github.com/pytorch/pytorch/issues/82542
|
open
|
[
"module: docs",
"module: cpp",
"triaged"
] | 2022-07-31T06:20:02Z
| 2022-08-03T15:18:05Z
| null |
ghostplant
|
pytorch/pytorch
| 82,524
|
how to build libtorch from source?
|
### 🐛 Describe the bug
where is the source? I want to build libtorch-win-shared-with-deps-1.12.0%2Bcu116.zip
### Versions
as in the title
cc @malfet @seemethere @svekars @holly1238 @jbschlosser
|
https://github.com/pytorch/pytorch/issues/82524
|
closed
|
[
"module: build",
"module: docs",
"module: cpp",
"triaged"
] | 2022-07-30T08:01:18Z
| 2022-08-21T01:50:37Z
| null |
xoofee
|
pytorch/data
| 703
|
Read Parquet Files Directly from S3?
|
### 🚀 The feature
The `ParquetDataFrameLoader` allows us to read parquet files from the local file system, but I don't think it supports reading parquet files from (for example) an S3 bucket.
Make this possible.
### Motivation, pitch
I would like to train my models on parquet files stored in an S3 bucket.
### Alternatives
You could probably download the parquet file locally and then use the `ParquetDataFrameLoader`?
### Additional context
_No response_
|
https://github.com/meta-pytorch/data/issues/703
|
open
|
[
"enhancement",
"feature"
] | 2022-07-30T06:07:01Z
| 2022-08-03T19:09:09Z
| 2
|
vedantroy
|
pytorch/TensorRT
| 1,213
|
❓ [Question] Is it ok to build v1.1.0 with cuda10.2 not default cuda11.3?
|
## ❓ Question
<!-- Your question -->
Is it ok to build v1.1.0 with cuda10.2 not default cuda11.3?
It's hard to upgrade latest gpu driver for some machine which is shared by many people. So cuda10.2 is preferred.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version: 1.11.0
- CUDA version: 10.2
- TensorRT: 8.2.4.2
|
https://github.com/pytorch/TensorRT/issues/1213
|
closed
|
[
"question",
"component: dependencies"
] | 2022-07-28T12:05:22Z
| 2022-08-12T01:46:32Z
| null |
wikiwen
|
huggingface/datasets
| 4,757
|
Document better when relative paths are transformed to URLs
|
As discussed with @ydshieh, when passing a relative path as `data_dir` to `load_dataset` of a dataset hosted on the Hub, the relative path is transformed to the corresponding URL of the Hub dataset.
Currently, we mention this in our docs here: [Create a dataset loading script > Download data files and organize splits](https://huggingface.co/docs/datasets/v2.4.0/en/dataset_script#download-data-files-and-organize-splits)
> If the data files live in the same folder or repository of the dataset script, you can just pass the relative paths to the files instead of URLs.
Maybe we should document better how relative paths are handled, not only when creating a dataset loading script, but also when passing to `load_dataset`:
- `data_dir`
- `data_files`
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4757
|
closed
|
[
"documentation"
] | 2022-07-28T08:46:27Z
| 2022-08-25T18:34:24Z
| 0
|
albertvillanova
|
huggingface/diffusers
| 143
|
Running difussers with GPU
|
Running the example codes i see that the CPU and not the GPU is used, is there a way to use GPU instead
|
https://github.com/huggingface/diffusers/issues/143
|
closed
|
[
"question"
] | 2022-07-28T08:34:12Z
| 2022-08-15T17:27:31Z
| null |
jfdelgad
|
pytorch/TensorRT
| 1,212
|
🐛 [Bug] Encountered bug when using Torch-TensorRT
|
## ❓ Question
Hello There,
I've tried to run torch_TensorRT on ubuntu and windows as well. On windows I compiled it with [this](https://github.com/gcuendet/Torch-TensorRT/tree/add-cmake-support) pull request and it is working good on C++. The resulting trt_module on ubuntu is loading flawlessly on python and can be saved and loaded from disk for future use. This is not the case with Windows C++ module, the resulting trt_model on windows via C++ program is working perfectly with C++ but it is not getting loaded on python. My question is, python library is using C binaries to perform this task and resulting model is getting loaded on python, why it is not same in other case? Am I missing something?
## What I have tried
### Working
#### Compiling and Loading TRT Model On Python Ubuntu:
```
trt_model_fp32 = torch_tensorrt.compile(torch_script_module, truncate_long_and_double=True,
inputs=[torch_tensorrt.Input((1, 3, 8, 290, 290), dtype=torch.float32)],
enabled_precisions=torch.float16,
workspace_size=1 << 34,
require_full_compilation=True,
)
torch.jit.save(trt_model_fp32, "NewTRTModel.ts")
model = torch.jit.load("NewTRTModel.ts")
```
### Not Working
#### Compiling TRT Model On C++ Windows and then Loading on Python:
```
const torch::Device device = torch::Device(torch::kCUDA, 0);
torch::jit::script::Module model;
std::cout << "Trying to load the model" << std::endl;
try {
model = torch::jit::load(model_path, device);
model.to(device);
model.eval();
}
catch (const c10::Error& e) {
std::cerr << e.what() << std::endl;
}
auto inp = std::vector<int64_t>{ 1, 3, 8, 290, 290 };
auto input = torch_tensorrt::Input(inp);
auto compile_settings = torch_tensorrt::ts::CompileSpec({ input });
compile_settings.enabled_precisions = { torch::kFloat16 };
// Compile module
std::cout << "Compiling..." << std::endl;
auto trt_mod = torch_tensorrt::ts::compile(model, compile_settings);
// Save module for later
trt_mod.save("/NewTRTModel.ts");
#### Loading On Python:
model = torch.load("NewTRTModel.ts")
model = torch.jit.load("NewTRTModel.ts")
```
## Error
```
RuntimeError Traceback (most recent call last)
Input In [3], in <cell line: 1>()
----> 1 model = torch.load("NewTRTModel.ts")
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\serialization.py:711, in load(f, map_location, pickle_module, **pickle_load_args)
707 warnings.warn("'torch.load' received a zip file that looks like a TorchScript archive"
708 " dispatching to 'torch.jit.load' (call 'torch.jit.load' directly to"
709 " silence this warning)", UserWarning)
710 opened_file.seek(orig_position)
--> 711 return torch.jit.load(opened_file)
712 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
713 return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\jit\_serialization.py:164, in load(f, map_location, _extra_files)
162 cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
163 else:
--> 164 cpp_module = torch._C.import_ir_module_from_buffer(
165 cu, f.read(), map_location, _extra_files
166 )
168 # TODO: Pretty sure this approach loses ConstSequential status and such
169 return wrap_cpp_module(cpp_module)
RuntimeError:
Unknown type name '__torch__.torch.classes.tensorrt.Engine':
File "code/__torch__/movinets/models.py", line 4
__parameters__ = []
__buffers__ = []
__torch___movinets_models_MoViNet_trt_engine_ : __torch__.torch.classes.tensorrt.Engine
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward(self_1: __torch__.movinets.models.MoViNet_trt,
input_0: Tensor) -> Tensor:
```
## Environment
Windows 11
CPU : i9-11980HK x86-64
GPU : RTX 3080 Mobile
Cuda : 11.5.2
Cudnn : 8.3.1
Libtorch : 1.11
Tensor_RT : 8.4.1.5
Visual Studio 2019
|
https://github.com/pytorch/TensorRT/issues/1212
|
closed
|
[
"question",
"No Activity",
"channel: windows"
] | 2022-07-28T06:31:49Z
| 2022-11-02T18:44:43Z
| null |
ghost
|
huggingface/optimum
| 320
|
Feature request: allow user to provide tokenizer when loading transformer model
|
### Feature request
When I try to load a locally saved transformers model with `ORTModelForSequenceClassification.from_pretrained(<path>, from_transformers=True)` an error occurs ("unable to generate dummy inputs for model") unless I also save the tokenizer in the checkpoint. A reproducible example of this is below.
A way to pass a tokenizer object to `from_pretrained()` would be helpful to avoid this problem.
```python
orig_model="prajjwal1/bert-tiny"
saved_model_path='saved_model'
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Load a model from the hub and save it locally
model = AutoModelForSequenceClassification.from_pretrained(orig_model)
model.save_pretrained(saved_model_path)
tokenizer=AutoTokenizer.from_pretrained(orig_model)
# attempt to load the locally saved model and convert to Onnx
loaded_model=ORTModelForSequenceClassification.from_pretrained(
saved_model_path,
from_transformers=True
)
```
Produces error:
```sh
Traceback (most recent call last):
File "optimum_loading_reprex.py", line 21, in <module>
loaded_model=ORTModelForSequenceClassification.from_pretrained(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/optimum/modeling_base.py", line 201, in from_pretrained
return cls._from_transformers(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/optimum/onnxruntime/modeling_ort.py", line 275, in _from_transformers
export(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/convert.py", line 335, in export
return export_pytorch(preprocessor, model, config, opset, output, tokenizer=tokenizer, device=device)
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/convert.py", line 142, in export_pytorch
model_inputs = config.generate_dummy_inputs(preprocessor, framework=TensorType.PYTORCH)
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/config.py", line 334, in generate_dummy_inputs
raise ValueError(
ValueError: Unable to generate dummy inputs for the model. Please provide a tokenizer or a preprocessor.
```
Package versions
- transformers: 4.20.1
- optimum: 1.3.0
- onnxruntime: 1.11.1
- torch: 1.11.0
### Motivation
Saving the tokenizer to the model checkpoint is a step that could be eliminated if there were a way to provide a tokenizer to `ORTModelForSequenceClassification.from_pretrained()`
### Your contribution
I'm not currently sure where to start on implementing this feature, but would be happy to help with some guidance.
|
https://github.com/huggingface/optimum/issues/320
|
closed
|
[
"Stale"
] | 2022-07-27T20:01:32Z
| 2025-07-27T02:17:59Z
| 3
|
jessecambon
|
pytorch/TensorRT
| 1,209
|
❓ [Question] How do you install an older TensorRT package?
|
## ❓ Question
How do you install an older TensorRT package? I'm using Pytorch 1.8 and TensorRT version 0.3.0 matches that Pytorch version.
## What you have already tried
I tried:
```
pip3 install torch-tensorrt==v0.3.0 -f https://github.com/pytorch/TensorRT/releases
Looking in links: https://github.com/pytorch/TensorRT/releases
ERROR: Could not find a version that satisfies the requirement torch-tensorrt==v0.3.0 (from versions: 0.0.0, 0.0.0.post1, 1.0.0, 1.1.0)
ERROR: No matching distribution found for torch-tensorrt==v0.3.0
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1209
|
closed
|
[
"question"
] | 2022-07-27T16:40:14Z
| 2022-08-01T15:54:24Z
| null |
JinLi711
|
pytorch/pytorch
| 82,304
|
How to use SwiftShader to test vulkan mobile models ?
|
### 📚 The doc issue
In this tutorial [here](https://pytorch.org/tutorials/prototype/vulkan_workflow.html),
It's pointed out at the end that it will be possible to use SwiftShader to test pytorch_mobile models on Vulkan backend without needing to go to mobile.
How?
### Suggest a potential alternative/fix
_No response_
|
https://github.com/pytorch/pytorch/issues/82304
|
closed
|
[
"oncall: mobile"
] | 2022-07-27T10:18:59Z
| 2022-07-28T22:40:59Z
| null |
MohamedAliRashad
|
pytorch/TensorRT
| 1,207
|
❓ [Question] cmake do not find torchtrt?
|
## ❓ Question
Hi, im trying to compile from source and test with c++.
I built using locally installed cuda 10.2 , tensort 8.2 and libtorch cxx11 abi, compile using `bazel build //:libtorchtrt -c opt`
It looks like the installation was successful.
```
INFO: Analyzed target //:libtorchtrt (0 packages loaded, 0 targets configured).
INFO: Found 1 target...
Target //:libtorchtrt up-to-date:
bazel-bin/libtorchtrt.tar.gz
INFO: Elapsed time: 248.908s, Critical Path: 35.38s
INFO: 217 processes: 2 internal, 215 linux-sandbox.
INFO: Build completed successfully, 217 total actions
```
But when i test with c++, the cmake can not find torchtrt, seems like the installation was not correctly???
Is there anyone who can tell me what do i miss??? thank u.
this is my cmakelist file, it works without `find_package(torchtrt REQUIRED)`
```
project(example)
cmake_minimum_required(VERSION 3.0)
set(CMAKE_CXX_STANDARD 14)
set(Torch_DIR /home/xs/libtorch/share/cmake/Torch)
find_package(Torch REQUIRED)
find_package(torchtrt REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(example main.cpp)
target_link_libraries(example "${TORCH_LIBRARIES}")
```
Errors:
```
CMake Error at CMakeLists.txt:10 (find_package):
By not providing "Findtorchtrt.cmake" in CMAKE_MODULE_PATH this project has
asked CMake to find a package configuration file provided by "torchtrt",
but CMake did not find one.
Could not find a package configuration file provided by "torchtrt" with any
of the following names:
torchtrtConfig.cmake
torchtrt-config.cmake
Add the installation prefix of "torchtrt" to CMAKE_PREFIX_PATH or set
"torchtrt_DIR" to a directory containing one of the above files. If
"torchtrt" provides a separate development package or SDK, be sure it has
been installed.
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.11.0
- CPU Architecture: x86-64
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip whl file from PyTorch.org
- Build command you used (if compiling from source): compiling from source
- Are you using local sources or building from archives: local sources
- Python version: 3.7.0
- CUDA version: 10.2
- GPU models and configuration: gtx 1050ti
- Any other relevant information:
|
https://github.com/pytorch/TensorRT/issues/1207
|
closed
|
[
"question",
"component: build system"
] | 2022-07-27T09:14:51Z
| 2023-09-14T17:40:25Z
| null |
xsxsmm
|
pytorch/torchx
| 569
|
[Ray] Elastic Launch on Ray Cluster
|
## Description
<!-- concise description of the feature/enhancement -->
Support elastic training on Ray Cluster.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
Training can tolerate node failures.
The number of worker nodes can expand as the size of the cluster grows.
## Detailed Proposal
<!-- provide a detailed proposal -->
Based on current implementation, there will be two major steps for this feature:
- [ ] #559 Support expanding the placement groups for command actors on the fly
- [ ] Support fault tolerance which depends on the implementation of ray.
Ray Placement Group supports fault tolerance, and its logic is when a node dead, GCS will reschedule the placement groups on that node to other nodes. And it introduces a problem: how do we know when a node is dead and which placement groups are being created, since we must restart the command actor on those placement groups who have been rescheduled, the reason is that those placement groups will never be removed until the training ends, and it reserves resources cannot be used by others. Currently there are two possible ways to achieve this:
1. Disable the fault tolerance feature of Ray Placement Group, then we need find a way to monitor the living placement groups.
2. Let the Ray GCS notifies the main process when some placement groups are being rescheduled, and we will be able to restart the command actors on those placement groups once they have been rescheduled.
## Additional context/links
<!-- link to code, documentation, etc. -->
[Ray Placement Group](https://docs.ray.io/en/latest/ray-core/placement-group.html#fault-tolerance)
[Support expanding the placement groups for command actors on the fly](https://github.com/pytorch/torchx/pull/559)
[Enable Notification on Node failure](https://github.com/ray-project/ray/issues/27076)
|
https://github.com/meta-pytorch/torchx/issues/569
|
open
|
[
"enhancement",
"ray"
] | 2022-07-27T04:32:41Z
| 2022-11-05T18:22:51Z
| 0
|
ntlm1686
|
pytorch/data
| 693
|
Changing decoding method in StreamReader
|
### 🐛 Describe the bug
Hi,
When decoding from a file stream in `StreamReader`, torchdata automatically assumes the incoming bytes are UTF-8. However, in the case of alternate encoding's this will error (in my case `UnicodeDecodeError: 'utf-8' codec can't decode byte 0xec in position 3: invalid continuation byte`). How do we change the decoding method to fit the particular data stream?
### Versions
```
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.0
[pip3] pytorch-lightning==1.6.4
[pip3] torch==1.11.0
[pip3] torchdata==0.3.0
[pip3] torchmetrics==0.9.1
[pip3] torchvision==0.12.0
[conda] numpy 1.23.0 pypi_0 pypi
[conda] pytorch-lightning 1.6.4 pypi_0 pypi
[conda] torch 1.11.0 pypi_0 pypi
[conda] torchdata 0.3.0 pypi_0 pypi
[conda] torchmetrics 0.9.1 pypi_0 pypi
[conda] torchvision 0.12.0 pypi_0 pypi
```
|
https://github.com/meta-pytorch/data/issues/693
|
open
|
[] | 2022-07-27T00:33:29Z
| 2022-07-27T13:18:15Z
| 2
|
is-jlehrer
|
pytorch/data
| 690
|
Unable to vectorize datapipe operations
|
### 🐛 Describe the bug
Let `t` be an input dataset that associates strings (model input) to integers (model output):
```python
t = [("a", 567), ("b", 908), ("c", 887)]
```
I now wrap `t` in a `SequenceWrapper`, to use it as part of a DataPipe:
```python
import torchdata.datapipes as dp
pipeline = dp.map.SequenceWrapper(t, deepcopy=False)
```
Now, I have a datapipe giving me tuples:
```python
>>> pipeline[0]
('a', 567)
```
After that, I am willing to do some preprocessing. However, since I have a huge dataset I want to vectorize the following operations: for that, I use `.batch`:
```python
batched_pipeline = pipeline.batch(batch_size=2)
```
By vectorizing, I mean grouping the X values (the strings) and the Y values (integers) together so that I can apply a custom logic to the input and the output at the same time, and in batch.
However, the `.batch()` function returns the following:
```python
>>> batched_pipeline[0]
[('a', 567), ('b', 908)]
```
Which really makes no sense because why would I want the whole line batched? Just so that I can iterate over it right after?
In my opinion, `.batch()` only makes sense if the different **slices** (see TensorFlow's `Dataset.from_tensor_slices()` which does handle that) are batched separately.
So what do you think? Is there something I am missing?
Thanks in advance!
<details>
<summary>Versions</summary>
PyTorch version: 1.12.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux release 8.5 (Ootpa) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-3)
Clang version: 12.0.1 (Red Hat 12.0.1-2.module+el8.5.0+12651+6a7729ff)
CMake version: version 3.20.2
Libc version: glibc-2.28
Python version: 3.10.4 (main, Mar 31 2022, 08:41:55) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.18.0-348.el8.x86_64-x86_64-with-glibc2.28
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 515.48.07
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] light-the-torch==0.4.0
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.0
[pip3] torch==1.12.0+cu116
[pip3] torchaudio==0.12.0
[pip3] torchdata==0.4.0
[pip3] torchmetrics==0.9.2
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0
[conda] light-the-torch 0.4.0 pypi_0 pypi
[conda] numpy 1.23.0 pypi_0 pypi
[conda] torch 1.12.0+cu116 pypi_0 pypi
[conda] torchaudio 0.12.0 pypi_0 pypi
[conda] torchdata 0.4.0 pypi_0 pypi
[conda] torchmetrics 0.9.2 pypi_0 pypi
[conda] torchtext 0.13.0 pypi_0 pypi
[conda] torchvision 0.13.0 pypi_0 pypi
</details>
|
https://github.com/meta-pytorch/data/issues/690
|
open
|
[] | 2022-07-26T13:30:39Z
| 2022-07-26T15:50:26Z
| 2
|
BlueskyFR
|
huggingface/datasets
| 4,744
|
Remove instructions to generate dummy data from our docs
|
In our docs, we indicate to generate the dummy data: https://huggingface.co/docs/datasets/dataset_script#testing-data-and-checksum-metadata
However:
- dummy data makes sense only for datasets in our GitHub repo: so that we can test their loading with our CI
- for datasets on the Hub:
- they do not pass any CI test requiring dummy data
- there are no instructions on how they can test their dataset locally using the dummy data
- the generation of the dummy data assumes our GitHub directory structure:
- the dummy data will be generated under `./datasets/<dataset_name>/dummy` even if locally there is no `./datasets` directory (which is the usual case). See issue:
- #4742
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4744
|
closed
|
[
"documentation"
] | 2022-07-26T07:32:58Z
| 2022-08-02T23:50:30Z
| 2
|
albertvillanova
|
pytorch/xla
| 3,760
|
How to load a gpu trained model on TPU for evaluation
|
## ❓ Questions and Help
Hello,
I am loading a GPU trained model on map_location=cpu and then doing "model.to(device)" where device is xm.xla_device(n=device_num,devkind="TPU") but on testing the cpu processing time and the tpu processing time is the same. Please let me know what I can do about it.
Thank you
|
https://github.com/pytorch/xla/issues/3760
|
open
|
[] | 2022-07-26T01:25:45Z
| 2022-07-26T02:22:58Z
| null |
Preethse
|
pytorch/data
| 689
|
Distributed training tutorial with DataLoader2
|
### 📚 The doc issue
I am not sure how to implement distributed training.
### Suggest a potential alternative/fix
If there was a simple example that showed how to use DDP with the torchdata library it would be super helpful.
|
https://github.com/meta-pytorch/data/issues/689
|
closed
|
[
"documentation"
] | 2022-07-25T22:44:56Z
| 2023-02-01T17:59:08Z
| 9
|
MatthewCaseres
|
huggingface/datasets
| 4,742
|
Dummy data nowhere to be found
|
## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co/datasets/BramVanroy/hebban-reviews). And even though the scripts runs and shows a message at the end that it succeeded, I cannot find the dummy data anywhere. Where is it?
## Expected results
To see the dummy data in the datasets' folder or in the folder where I ran the command.
## Actual results
I see the following message but I cannot find the dummy data anywhere.
```
Dummy data generation done and dummy data test succeeded for config 'filtered''.
Automatic dummy data generation succeeded for all configs of '.\datasets\hebban-reviews\'
```
## Environment info
- `datasets` version: 2.4.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.8
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4742
|
closed
|
[
"bug"
] | 2022-07-25T19:18:42Z
| 2022-11-04T14:04:24Z
| 3
|
BramVanroy
|
huggingface/dataset-viewer
| 466
|
Take decisions before launching in public
|
## Version
Should we integrate a version in the path or domain, to help with future breaking changes?
Three options:
1. domain based: https://v1.datasets-server.huggingface.co
2. path based: https://datasets-server.huggingface.co/v1/
3. no version (current): https://datasets-server.huggingface.co
I think 3 is OK. Not having a version means we have to try to make everything backward-compatible, which is not a bad idea. If it's really needed, we can switch to 1 or 2 afterward. Also: having a version means that if we do breaking changes, we should maintain at least two versions in parallel...
## Envelop
A common pattern is to always return a JSON object with `data` or `error`. This way, we know that we can always consume the API with:
```js
const {data, error} = fetch(...)
```
and test for the existence of data, or error. Otherwise, every endpoint might have different behavior. Also: it's useful to have the envelop when looking at the response without knowing the HTTP status code (eg: in our cache)
Options:
1. no envelop (current): the client must rely on the HTTP status code to get the type of response (error or OK)
2. envelop: we need to migrate all the endpoints, to add an intermediate "data" or "error" field.
## HTTP status codes
We currently only use 200, 400, and 500 for simplicity. We might want to return alternative status codes such as 404 (not found), or 401/403 (when we will protect some endpoints).
Options:
1. only use 200, 400, 500 (current)
2. add more status codes, like 404, 401, 403
I think it's OK to stay with 300, 400, and 500, and let the client use the details of the response to figure out what failed.
## Error codes
Currently, the errors have a "message" field, and optionally three more fields: "cause_exception", "cause_message" and "cause_traceback". We could add a "code" field, such as "NOT_STREAMABLE", to make it more reliable for the client to implement logic based on the type of error (indeed: the message is a long string that might be updated later. A short code should be more reliable). Also: having an error code could counterbalance the lack of detailed HTTP status codes (see the previous point).
Internally, having codes could help indirect the messages to a dictionary, and it would help to catalog all the possible types of errors in the same place.
Options:
1. no "code" field (current)
2. add a "code" field, such as "NOT_STREAMABLE"
I'm in favor of adding such a short code.
## Case
The endpoints with several words are currently using "spinal-case", eg "/first-rows". An alternative is to use "snake_case", eg "/first_rows". Nothing important here.
Options:
1. "/spinal-case" (current)
2. "/snake_case"
I think it's not important, we can keep with spinal-case, and it's coherent with Hub API: https://huggingface.co/docs/hub/api
|
https://github.com/huggingface/dataset-viewer/issues/466
|
closed
|
[
"question"
] | 2022-07-25T18:04:59Z
| 2022-07-26T14:39:46Z
| null |
severo
|
pytorch/TensorRT
| 1,203
|
❓ [Question] How do you install torch-tensorrt (Import error. no libvinfer_plugin.so.8 file error)?
|
## ❓ Question
<!-- ImportError: libnvinfer_plugin.so.8: cannot open shared object file: No such file or directory -->
### ImportError: libnvinfer_plugin.so.8: cannot open shared object file: No such file or directory
cuda and cudnn is installed well.
I installed pytorch and nvidia-tensorrt well in conda environment
and then install torch-tensorrt via pip
```
pip3 install torch-tensorrt -f https://github.com/pytorch/TensorRT/releases
```
but when I import torch-tensorrt, it gives importError
ImportError: libnvinfer_plugin.so.8: cannot open shared object file: No such file or directory
```
>>> import torch_tensorrt
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/user_name/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch_tensorrt/__init__.py", line 11, in <module>
from torch_tensorrt._compile import *
File "/home/user_name/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch_tensorrt/_compile.py", line 2, in <module>
from torch_tensorrt import _enums
File "/home/user_name/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch_tensorrt/_enums.py", line 1, in <module>
from torch_tensorrt._C import dtype, DeviceType, EngineCapability, TensorFormat
ImportError: libnvinfer_plugin.so.8: cannot open shared object file: No such file or directory
```
## What you have already tried
```
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
8
>>> torch.cuda.current_device()
0
>>> torch.cuda.get_device_name(0)
'NVIDIA RTX A5000'
>>> torch.__version__
'1.12.0'
>>> import tensorrt
```
<!-- checked cuda, cudnn, pytorch versions are right. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.12
- CPU Architecture: x86_64
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): conda
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.9.7
- CUDA version: 11.4
- GPU models and configuration: NVIDIA RTX A5000
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1203
|
closed
|
[
"question"
] | 2022-07-25T03:03:35Z
| 2024-04-30T02:16:10Z
| null |
YOONAHLEE
|
pytorch/TensorRT
| 1,202
|
❓ [Question] interpolate isn't suported?
|
## ❓ Question
does anyone succeed compile [torch.nn.functional.interpolate](https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html) with torch_tensort>1.x.x?
in the release note, it is written that nearest and bilinear interpolation are supported
if you can compile it, please share with me the example code. thank you!
|
https://github.com/pytorch/TensorRT/issues/1202
|
closed
|
[
"question",
"component: converters"
] | 2022-07-24T21:35:34Z
| 2022-07-27T23:46:37Z
| null |
yokosyun
|
pytorch/functorch
| 982
|
GPU Memeory
|
```
func_model, params = make_functional(model)
for param in params:
param.requires_grad_(False)
def compute_loss(params, data, targets):
data = data.unsqueeze(dim=0)
preds = func_model(params, data)
loss = loss_fn(preds, targets)
return loss
per_sample_info = vmap(grad_and_value(compute_loss, has_aux=False), (None, 0, 0),randomness='different')(params, images, labels)
per_sample_grads = per_sample_info[0]
per_sample_losses = per_sample_info[1].detach_()
grads = torch.cat([g.detach().view(b,-1) for g in per_sample_grads], dim=1)
```
It seems that when I get grads, the usage of gpu memory nearly doubles which is not what I want. Looking forward to some advice.
|
https://github.com/pytorch/functorch/issues/982
|
closed
|
[] | 2022-07-24T04:45:50Z
| 2022-07-24T10:37:22Z
| 0
|
kwwcv
|
pytorch/pytorch
| 82,041
|
[Misleading] The doc started using Tensorflow terminology in the document to explain how to use the Pytorch code.
|
### 📚 The doc issue
the model must be executed in inference mode and operate on input tensors that do not collect gradient tape information (e.g., running with torch.no_grad).
### Suggest a potential alternative/fix
the model must be executed in inference mode and operate on input tensors that do not collect gradient tape information (e.g., running with torch.no_grad).
Change it to be:
the model must be executed in inference mode and operate on input tensors that does not accumulate gradient. (e.g, setting the model with torch.no_grad).
cc @svekars @holly1238
|
https://github.com/pytorch/pytorch/issues/82041
|
open
|
[
"module: docs",
"triaged"
] | 2022-07-23T01:43:39Z
| 2022-07-24T16:35:11Z
| null |
AliceSum
|
huggingface/dataset-viewer
| 458
|
Move /webhook to admin instead of api?
|
As we've done with the technical endpoints in https://github.com/huggingface/datasets-server/pull/457?
It might help to protect the endpoint (#95), even if it's not really dangerous to let people add jobs to refresh datasets IMHO for now.
|
https://github.com/huggingface/dataset-viewer/issues/458
|
closed
|
[
"question"
] | 2022-07-22T20:21:39Z
| 2022-09-16T17:24:05Z
| null |
severo
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.