
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/pytorch
| 93,516
|
[Question] How to debug "munmap_chunk(): invalid pointer" when compiling to triton?
|
I'm trying to use torchdynamo to compile a function to triton.
My logs indicate that the function optimizes without issue,
but when running the function on a given input, I just get "munmap_chunk(): invalid pointer" w/o a stack trace / any useful debugging information.
I'm wondering how to go about debugging such an error.
Are any developers familiar with what this indicates?
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
|
https://github.com/pytorch/pytorch/issues/93516
|
closed
|
[
"oncall: pt2"
] | 2023-01-22T03:36:25Z
| 2023-02-01T14:19:30Z
| null |
vedantroy
|
pytorch/TensorRT
| 1,600
|
❓ [Question] How do you compile for Jetson 5.0?
|
## ❓ Question
Hi, as there seems to be no prebuilt python binary, just wanted to know if there is any way to install this package on jetson 5.0?
## What you have already tried
I tried normal installation for jetson 4.6 which fails, I aslo tried this https://forums.developer.nvidia.com/t/installing-building-torch-tensorrt-for-jetpack-5-0-1-dp-l4t-ml-r34-1-1-py3/220565/6 which gives me this error:
```
user@ubuntu:/mnt/Data/home/ParentCode/TensorRT$ bazel build //:libtorchtrt --platforms //toolchains:jetpack_5.0
Starting local Bazel server and connecting to it...
INFO: Analyzed target //:libtorchtrt (71 packages loaded, 9773 targets configured).
INFO: Found 1 target...
ERROR: /mnt/Data/home/ParentCode/TensorRT/cpp/lib/BUILD:5:10: Linking cpp/lib/libtorchtrt_plugins.so failed: (Exit 1): gcc failed: error executing command /usr/bin/gcc @bazel-out/aarch64-fastbuild/bin/cpp/lib/libtorchtrt_plugins.so-2.params
Use --sandbox_debug to see verbose messages from the sandbox and retain the sandbox build root for debugging
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Ctorch___Ulib/libtorch.so while searching for torch
/usr/bin/ld.gold: error: cannot find -ltorch
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Ctorch___Ulib/libtorch_cuda.so while searching for torch_cuda
/usr/bin/ld.gold: error: cannot find -ltorch_cuda
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Ctorch___Ulib/libtorch_cpu.so while searching for torch_cpu
/usr/bin/ld.gold: error: cannot find -ltorch_cpu
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Ctorch___Ulib/libtorch_global_deps.so while searching for torch_global_deps
/usr/bin/ld.gold: error: cannot find -ltorch_global_deps
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Cc10_Ucuda___Ulib/libc10_cuda.so while searching for c10_cuda
/usr/bin/ld.gold: error: cannot find -lc10_cuda
/usr/bin/ld.gold: warning: skipping incompatible bazel-out/aarch64-fastbuild/bin/_solib_aarch64/_U@libtorch_S_S_Cc10___Ulib/libc10.so while searching for c10
/usr/bin/ld.gold: error: cannot find -lc10
collect2: error: ld returned 1 exit status
Target //:libtorchtrt failed to build
Use --verbose_failures to see the command lines of failed build steps.
INFO: Elapsed time: 19.738s, Critical Path: 6.94s
INFO: 12 processes: 10 internal, 2 linux-sandbox.
FAILED: Build did NOT complete successfully
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version: 1.13.0a0+d0d6b1f2.nv22.10
- CPU Architecture: aarch64
- OS (e.g., Linux): Linux, NVidia's version of ubuntu 20.04 for jetson
- Python version: Python 3.8.10
- CUDA version:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_May__4_00:02:26_PDT_2022
Cuda compilation tools, release 11.4, V11.4.239
Build cuda_11.4.r11.4/compiler.31294910_0
|
https://github.com/pytorch/TensorRT/issues/1600
|
closed
|
[
"question",
"No Activity",
"channel: linux-jetpack"
] | 2023-01-20T17:08:42Z
| 2023-09-15T11:33:27Z
| null |
arnaghizadeh
|
huggingface/setfit
| 282
|
Loading a trained SetFit model without setfit?
|
SetFit team, first off, thanks for the awesome library!
I'm running into trouble trying to load and run inference on a trained SetFit model without using `SetFitModel.from_pretrained()`. Instead, I'd like to load the model using torch, transformers, sentence_transformers, or some combination thereof. Is there a clear-cut example anywhere of how to do this?
Here's my current code, which does not return clean predictions. Thank you in advance for the help. For reference, this was trained as a multiclass classification model with 18 potential classes:
```from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
inputs = ['xxx', 'yyy', 'zzz']
encoded_inputs = tokenizer(inputs,
padding = True,
truncation = True,
return_tensors = 'pt')
model = AutoModel.from_pretrained('/path/to/trained/setfit/model/')
with torch.no_grad():
preds = model(**encoded_inputs)
preds```
|
https://github.com/huggingface/setfit/issues/282
|
closed
|
[
"question"
] | 2023-01-20T01:08:00Z
| 2024-05-21T08:11:08Z
| null |
ZQ-Dev8
|
huggingface/datasets
| 5,442
|
OneDrive Integrations with HF Datasets
|
### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive** account and I want to move between drive and Hugging face repo or vis versa
### Motivation
make the dataset section more flexible with other possible storage
like the integration between Google Collab and Google drive the storage
### Your contribution
Can be done using Hugging face CLI
|
https://github.com/huggingface/datasets/issues/5442
|
closed
|
[
"enhancement"
] | 2023-01-19T23:12:08Z
| 2023-02-24T16:17:51Z
| 2
|
Mohammed20201991
|
pytorch/xla
| 4,482
|
How to save checkpoints in XLA
|
Hello
I have training scripts running on CPUs and GPUs without error.
I am trying to make the scripts compatible with TPUs.
I was using the following lines to save checkpoints
```
torch.save(checkpoint, path_checkpoints_file )
```
and following lines to load checkpoints
```
checkpoint = torch.load(path_checkpoints_file, map_location=torch.device('cpu'))
lastEpoch = checkpoint['lastEpoch']
activeChunk = checkpoint['activeChunk']
chunk_count = checkpoint['chunk_count']
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler_state_dict'])
```
For TPUs I replaced the saving operation with
```
xm.save(checkpoint, path_checkpoints_file )
```
and the loading part with
```
checkpoint = xser.load( path_checkpoints_file )
lastEpoch = checkpoint['lastEpoch']
activeChunk = checkpoint['activeChunk']
chunk_count = checkpoint['chunk_count']
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler_state_dict'])
```
But during training, the loss remains almost constant.
Do we have a template to save and load checkpoints having models, optimizers and learning schedulers?
best regards
|
https://github.com/pytorch/xla/issues/4482
|
open
|
[] | 2023-01-19T21:50:05Z
| 2023-02-15T22:58:13Z
| null |
mfatih7
|
pytorch/functorch
| 1,106
|
Vmap and backward hook problem
|
I try to get the gradient of the intermedia layer of model, so I use the backwards hook with functroch.grad to get the gradient of each image. When I used for loop to iterate each image, I successfully obtained 5000 gradients (dataset size). However, when I use vmap to do the same thing, I only get 40 gradients (40 batches in 1 epoch). Is there any way to solve it, or I have to use for loop?
|
https://github.com/pytorch/functorch/issues/1106
|
open
|
[] | 2023-01-19T21:25:02Z
| 2023-01-23T05:08:49Z
| 1
|
pmzzs
|
pytorch/tutorials
| 2,175
|
OSError: Missing: valgrind, callgrind_control, callgrind_annotate
|
The error occurs on below step:
8. Collecting instruction counts with Callgrind:
Traceback (most recent call last):
File "benchmark.py", line 805, in <module>
stats_v0 = t0.collect_callgrind()
File "/usr/local/lib/python3.8/dist-packages/torch/utils/benchmark/utils/timer.py", line 486, in collect_callgrind
result = valgrind_timer_interface.wrapper_singleton().collect_callgrind(
File "/usr/local/lib/python3.8/dist-packages/torch/utils/benchmark/utils/valgrind_wrapper/timer_interface.py", line 526, in collect_callgrind
self._validate()
File "/usr/local/lib/python3.8/dist-packages/torch/utils/benchmark/utils/valgrind_wrapper/timer_interface.py", line 512, in _validate
raise OSError("Missing: " + ", ".join(missing_cmds))
OSError: Missing: valgrind, callgrind_control, callgrind_annotate
|
https://github.com/pytorch/tutorials/issues/2175
|
open
|
[
"question"
] | 2023-01-19T16:00:52Z
| 2023-01-24T10:47:08Z
| null |
ghost
|
pytorch/data
| 949
|
`torchdata` not available through `pytorch-nightly` conda channel
|
### 🐛 Describe the bug
The nightly version of torchdata does not seem available through the corresponding conda channel.
**Command:**
```
$ conda install torchdata -c pytorch-nightly --override-channels
```
**Result:**
```
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
PackagesNotFoundError: The following packages are not available from current channels:
- torchdata
Current channels:
- https://conda.anaconda.org/pytorch-nightly/osx-arm64
- https://conda.anaconda.org/pytorch-nightly/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
```
### Versions
```
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 13.1 (arm64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.22.4
Libc version: N/A
Python version: 3.10.8 | packaged by conda-forge | (main, Nov 22 2022, 08:25:29) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.1-arm64-arm-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.23.5
[conda] numpy 1.23.5 py310h5d7c261_0 conda-forge
```
|
https://github.com/meta-pytorch/data/issues/949
|
closed
|
[
"high priority"
] | 2023-01-18T15:49:29Z
| 2023-01-18T17:11:32Z
| 4
|
PierreGtch
|
pytorch/tutorials
| 2,173
|
Area calculation in TorchVision Object Detection Finetuning Tutorial
|
I see that at https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html,
` area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])` but shouldn't it be something like `area = ((boxes[:, 3] - boxes[:, 1]) + 1) * ((boxes[:, 2] - boxes[:, 0]) + 1) ` for calculating areas? If I am wrong, can someone explain me why is it so. Thanks in advance !
cc @datumbox @nairbv
|
https://github.com/pytorch/tutorials/issues/2173
|
closed
|
[
"module: vision"
] | 2023-01-18T08:55:55Z
| 2023-02-15T16:55:24Z
| 1
|
Himanshunitrr
|
pytorch/torchx
| 684
|
Docker workspace: How to specify "latest" (nightly) base image?
|
## ❓ Questions and Help
For my docker workspace (e.g. scheduler == "local_docker" or "aws_batch"), I'd like to use a base image that is published on a nightly cadence. So I have this `Dockerfile.torchx`
```
# Dockerfile.torchx
ARGS IMAGE
ARGS WORKSPACE
FROM $IMAGE
WORKDIR /workspace/mfive
COPY $WORKSPACE .
# installs my workspace (has setup.py)
RUN pip install -e .[dev]
```
In my `.torchxconfig` I've specified the latest default image as:
```
# .torchxconfig
[dist.ddp]
image = registry.gitlab.aws.dev/mfive/mfive-nightly:latest
```
The nightly build tags the nightly image as `latest` in addition to the `YYYY.MM.DD` (e.g. `mfive-nightly:2023.01.15`) but because the [`DockerWorkspace`'s build argument has `pull=False`](https://github.com/pytorch/torchx/blob/main/torchx/workspace/docker_workspace.py#L126) this won't work since `latest` will be cached.
Is there a better way for me to specify a "use-the-latest" base image from the repo policy when building a docker workspace?
cc) @d4l3k
|
https://github.com/meta-pytorch/torchx/issues/684
|
closed
|
[] | 2023-01-17T22:03:19Z
| 2023-03-17T22:06:25Z
| 3
|
kiukchung
|
pytorch/PiPPy
| 723
|
How to reduce memory costs when running on CPU
|
I running HF_inference.py on my CPU and it works well! It can successfully applying pipeline parallelism on CPU. However, when I applying pipeline parallelism, I found that each rank will load the whole model and it seems not necessary since each rank only performs a part of the model. There must be some ways can figure out this issue and I would love to solve this issue. It would be great if developers of TAU can give me some advice, we can discuss more about it if you have any idea. Thanks!
|
https://github.com/pytorch/PiPPy/issues/723
|
closed
|
[] | 2023-01-17T07:54:31Z
| 2025-06-10T02:40:11Z
| null |
jiqing-feng
|
huggingface/diffusers
| 2,012
|
Reduce Imagic Pipeline Memory Consumption
|
I'm running the [Imagic Stable Diffusion community pipeline](https://github.com/huggingface/diffusers/blob/main/examples/community/imagic_stable_diffusion.py) and it's routinely allocating 25-38 GiB GPU vRAM which seems excessively high.
@MarkRich any ideas on how to reduce memory usage? Xformers and attention slicing brings it down to 20-25 GiB but fp16 doesn't work and memory consumption in general seems excessively high (trying to deploy on serverless GPUs)
|
https://github.com/huggingface/diffusers/issues/2012
|
closed
|
[
"question",
"stale"
] | 2023-01-16T23:43:03Z
| 2023-02-24T15:03:35Z
| null |
andreemic
|
huggingface/optimum
| 697
|
Custom model output
|
### System Info
```shell
Copy-and-paste the text below in your GitHub issue:
- `optimum` version: 1.6.1
- `transformers` version: 4.25.1
- Platform: Linux-5.19.0-29-generic-x86_64-with-glibc2.36
- Python version: 3.10.8
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.1 (cuda availabe: True)
```
### Who can help?
@michaelbenayoun @lewtun @fxm
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
no code
### Expected behavior
Sorry in advance if it does exists already, but I didn't find any doc on this.
In transformers it is possible to custom the output of a model by adding some boolean input arguments such as `output_attentions` and `output_hiddens`. How to make them available in my exported ONNX model?
If it is not possible yet, I will update this thread into a feature request :)
Thanks in advance.
|
https://github.com/huggingface/optimum/issues/697
|
open
|
[
"bug"
] | 2023-01-16T14:08:12Z
| 2023-04-11T12:30:04Z
| 3
|
jplu
|
huggingface/datasets
| 5,424
|
When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset?
|
### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduce the behaviour:
1. Import
`from datasets import load_dataset, ReadInstruction`
2. Instruction to load the dataset
```
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="test", from_=0, to=5, unit='%', rounding='closest')
]
```
3. Load
`dataset = load_dataset('csv', data_dir="data/", data_files={"train":"train.tsv", "dev":"dev.tsv", "test":"test.tsv"}, delimiter="\t", split=instructions)`
### Expected behavior
**Current behaviour**
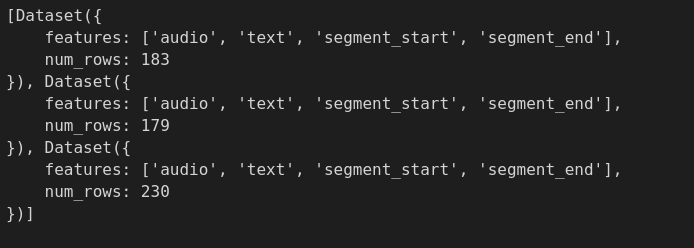
:
**Expected behaviour**
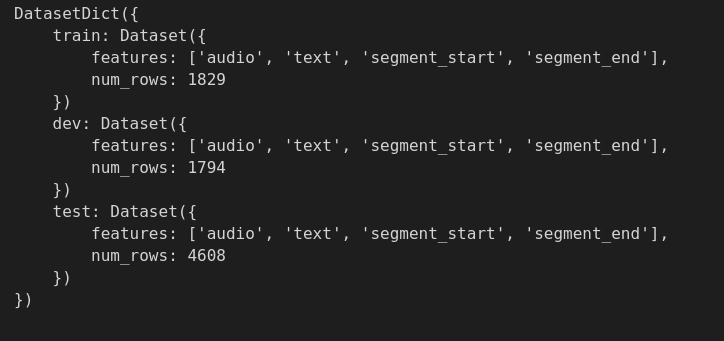
### Environment info
``datasets==2.8.0
``
`Python==3.8.5
`
`Platform - Ubuntu 20.04.4 LTS`
|
https://github.com/huggingface/datasets/issues/5424
|
closed
|
[] | 2023-01-16T06:54:28Z
| 2023-02-24T16:19:00Z
| 1
|
macabdul9
|
pytorch/pytorch
| 92,202
|
Generator: when I want to use a new backend, how to create a Generator with the new backend?
|
### 🐛 Describe the bug
I want to add a new backend, so I add my backend by referring to this tutorial. https://github.com/bdhirsh/pytorch_open_registration_example
But how to create a Generator with my new backend ?
I see the code related to 'Generator' is in the file, https://github.com/pytorch/pytorch/blob/master/torch/csrc/Generator.cpp
static PyObject* THPGenerator_pynew(
PyTypeObject* type,
PyObject* args,
PyObject* kwargs) {
HANDLE_TH_ERRORS
static torch::PythonArgParser parser({"Generator(Device device=None)"});
torch::ParsedArgs<1> parsed_args;
auto r = parser.parse(args, kwargs, parsed_args);
auto device = r.deviceWithDefault(0, at::Device(at::kCPU));
THPGeneratorPtr self((THPGenerator*)type->tp_alloc(type, 0));
if (device.type() == at::kCPU) {
self->cdata = make_generator<CPUGeneratorImpl>();
}
#ifdef USE_CUDA
else if (device.type() == at::kCUDA) {
self->cdata = make_generator<CUDAGeneratorImpl>(device.index());
}
#elif USE_MPS
else if (device.type() == at::kMPS) {
self->cdata = make_generator<MPSGeneratorImpl>();
}
#endif
else {
AT_ERROR(
"Device type ",
c10::DeviceTypeName(device.type()),
" is not supported for torch.Generator() api.");
}
return (PyObject*)self.release();
END_HANDLE_TH_ERRORS
}
So how to create a Generator with my new backend named "privateuseone" ?
### Versions
new backend
python:3.7.5
pytorch: 2.0.0
CUDA: None
|
https://github.com/pytorch/pytorch/issues/92202
|
closed
|
[
"triaged",
"module: backend"
] | 2023-01-14T08:11:04Z
| 2023-10-28T15:02:10Z
| null |
heidongxianhua
|
pytorch/TensorRT
| 1,592
|
❓ [Question] How should recompilation in Torch Dynamo + `fx2trt` be handled?
|
## ❓ Question
Given that Torch Dynamo compiles models lazily, how should benchmarking/usage of Torch Dynamo models, especially in cases where the inputs have a dynamic batch dimension, be handled?
## What you have already tried
Based on compiling and running inference using `fx2trt` with Torch Dynamo on the [BERT base-uncased model](https://huggingface.co/bert-base-uncased), and other similar networks, it seems that Torch Dynamo recompiles the model for each different batch-size input provided. Additionally, once the object has encountered a particular batch size, it does not recompile the model from scratch upon seeing another input of the same shape. It seems that Dynamo may be caching statically-shaped model compilations and dynamically selecting among these at inference time. The code used to generate the dynamo model and outputs is:
```python
dynamo_model = torchdynamo.optimize("fx2trt")(model)
output = dynamo_model(input)
```
While Dynamo does have a flag which allows users to specify dynamic shape prior to compilation (`torchdynamo.config.dynamic_shapes=True`), for BERT this seems to break compilation with `fx2trt`.
Recompilation of the model for each new batch size makes inference challenging for benchmarking and general usage tasks, as each time the model encounters an input of new shape, it would take much longer to complete the inference task than otherwise.
## Environment
- PyTorch Version (e.g., 1.0): 1.14.0.dev20221114+cu116
- Torch-TRT Version: dc570e47
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Python version: 3.8
- CUDA version: 11.6
## Additional context
Dynamo provides many benefits when used in conjunction with fx2trt, as it enables accelerated inference even when the graph might not normally be traceable due to control flow constraints. It would be beneficial to understand the dynamic batch/recompilation issue so Dynamo can be more effectively integrated into benchmarking for Torch-TRT.
Question #1569 could be relevant to this issue as it also relates to Dynamic Batch + FX.
|
https://github.com/pytorch/TensorRT/issues/1592
|
closed
|
[
"question",
"No Activity",
"component: fx"
] | 2023-01-14T02:18:53Z
| 2023-05-09T00:02:14Z
| null |
gs-olive
|
pytorch/functorch
| 1,101
|
How to get only the last few layers' gradident?
|
```
from functorch import make_functional_with_buffers, vmap, grad
fmodel, params, buffers = make_functional_with_buffers(net,disable_autograd_tracking=True)
def compute_loss_stateless_model (params, buffers, sample, target):
batch = sample.unsqueeze(0)
targets = target.unsqueeze(0)
predictions = fmodel(params, buffers, batch)
loss = criterion(predictions, targets)
return loss
ft_compute_grad = grad(compute_loss_stateless_model)
gradinet = ft_compute_grad(params, buffers, train_poi_set[0][0].cuda(), torch.tensor(train_poi_set[0][1]).cuda())
```
This will return the gradient of the whole model. However, I only want the second last layers' gradient, like:
```
gradinet = ft_compute_grad(params, buffers, train_poi_set[0][0].cuda(), torch.tensor(train_poi_set[0][1]).cuda())[-2]
```
Although this method can also obtain the required gradient, it will cause a lot of unnecessary overhead. Is there any way to close the 'require_grad' of all previous layers? Thanks for your answer!
|
https://github.com/pytorch/functorch/issues/1101
|
open
|
[] | 2023-01-13T21:48:42Z
| 2024-04-05T03:02:41Z
| null |
pmzzs
|
pytorch/functorch
| 1,099
|
Will pmap be supported in functorh?
|
Greetings, I am very grateful that vmap is supported in functorch. Is there any plan to include support for pmap in the future? Thank you. Additionally, what are the ways that I can contribute to the development of this project?
|
https://github.com/pytorch/functorch/issues/1099
|
open
|
[] | 2023-01-11T17:32:48Z
| 2024-06-05T16:32:36Z
| 2
|
shixun404
|
pytorch/TensorRT
| 1,585
|
❓ [Question] How can I make deserialized targets compatible with Torch-TensorRT ABI?
|
## ❓ Question
When I load my compiled model:
`model = torch.jit.load('model.ts')
`
**I keep getting the error:**
`RuntimeError: [Error thrown at core/runtime/TRTEngine.cpp:250] Expected serialized_info.size() == SERIALIZATION_LEN to be true but got false
Program to be deserialized targets an incompatible Torch-TensorRT ABI`
## What you have already tried
It works when I run the model inside the official [Nvidia PyTorch Release 22.12](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12) docker image:
```
model = torch.jit.load('model.ts')
model.eval()
```
However, I want to run the model in my normal environment for debugging purposes.
I've installed torch-tensorrt with: pip install torch-tensorrt==1.3.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.3.0
And I've compiled my model using docker: nvcr.io/nvidia/pytorch:22.12-py3
The [1.3.0 Release](https://github.com/pytorch/TensorRT/releases/tag/v1.3.0) says that it's based on TensorRT 8.5, and the docker image: [TensorRT™ 8.5.1](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12). I've also tried the 22.09 image that specifies NVIDIA TensorRT™ [8.5.0.12](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-09.html#rel-22-09), but I'm still getting the same error.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version: 1.13.0
- CPU Architecture: AMD Rome
- OS: Ubuntu 22.04 LTS
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 https://download.pytorch.org/whl/cu113
pip install nvidia-pyindex
pip install nvidia-tensorrt
pip install torch-tensorrt==1.3.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.3.0
import torch_tensorrt
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.9
- CUDA version: cu117
- GPU models and configuration: Nvidia A6000 (Ampere)
- Any other relevant information:
|
https://github.com/pytorch/TensorRT/issues/1585
|
closed
|
[
"question",
"No Activity",
"component: runtime"
] | 2023-01-11T12:44:58Z
| 2023-05-04T00:02:16Z
| null |
emilwallner
|
pytorch/kineto
| 713
|
How to get the CPU utilization by Pytorch Profiler?
|
According to the code of gpu_metrics_parser.py of torch-tb-profiler, I understand that the gpu utilization is actually the sum of event times of type EventTypes.KERNEL over a period of time / total time. So, is CPU utilization the sum of event times of type EventTypes.OPERATOR over a period of time / total time?
It seems that the result of this calculation is not normal.
|
https://github.com/pytorch/kineto/issues/713
|
closed
|
[] | 2023-01-11T09:46:20Z
| 2023-02-15T03:53:40Z
| null |
young-chao
|
pytorch/TensorRT
| 1,580
|
I am deleting some layers of Resneet152 for example del resnet152.fc and del resnet152.layer4 and save it locally in order to get the dimension of 1024. Later when I import this saved model it complains about the missing layer4. What might be the the reason? Does still try tp access the original model. How can get 1024 feature vectors for a given image using Resnet1024.
|
## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1580
|
closed
|
[
"question",
"No Activity"
] | 2023-01-09T15:22:23Z
| 2023-04-22T00:02:19Z
| null |
pradeep10kumar
|
pytorch/TensorRT
| 1,579
|
When I delete some layers from Resnet152 for example
|
## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1579
|
closed
|
[
"question"
] | 2023-01-09T15:17:50Z
| 2023-01-09T15:18:31Z
| null |
pradeep10kumar
|
pytorch/TensorRT
| 1,578
|
❓ [Question] Failed to compile EfficientNet: Error: Segmentation fault (core dumped)
|
I followed the step in the demo notebook `[EfficientNet-example.ipynb](https://github.com/pytorch/TensorRT/blob/main/notebooks/EfficientNet-example.ipynb)`
When I try to compile EfficientNet, an error occurred: `Segmentation fault (core dumped)`
I have located the error is caused by
`
trt_model_fp32 = torch_tensorrt.compile(model, inputs = [torch_tensorrt.Input((1, 3, 512, 512), dtype=torch.float32)],
enabled_precisions = torch.float32, # Run with FP32
workspace_size = 1 << 22
)
`
Full code
```
import os
import numpy as np
from PIL import Image
from torchvision import transforms
import sys
import timm
import torch.nn as nn
import torch
import io
import torch.backends.cudnn as cudnn
import torch_tensorrt
SIZE = 512
cudnn.benchmark = True
preprocess_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((SIZE, SIZE)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)])
def preprocess(byteImage):
image = Image.open(io.BytesIO(byteImage))
image = Image.fromarray(np.array(image)[:,:,:3])
return preprocess_transform(image).unsqueeze(0)
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.model = timm.create_model('tf_efficientnet_b0_ns', pretrained=False)
self.n_features = self.model.classifier.in_features
self.model.classifier = nn.Identity()
self.fc = nn.Linear(self.n_features, 1)
def feature(self, image):
feature = self.model(image)
return feature
def forward(self, image):
feature = self.feature(image)
output = self.fc(feature)
return output
def predict(tensorImage):
tensorImage = tensorImage.to('cuda')
with torch.no_grad:
pred = trt_model_fp32(tensorImage)
torch.cuda.synchronize()
return pred.cpu().detach().numpy()
model = CustomModel().to('cuda')
state_dict = torch.load(my_weight_path, map_location='cuda')
model.load_state_dict(state_dict['model'])
model.eval()
trt_model_fp32 = torch_tensorrt.compile(model, inputs = [torch_tensorrt.Input((1, 3, 512, 512), dtype=torch.float32)],
enabled_precisions = torch.float32, # Run with FP32
workspace_size = 1 << 22
)
input_data = torch.randn(1,3,512,512).to('cuda')
pred = predict(input_data)
print(pred.shape)
print(pred)
```
Please help❗
|
https://github.com/pytorch/TensorRT/issues/1578
|
closed
|
[
"question"
] | 2023-01-09T14:44:25Z
| 2023-02-28T23:40:20Z
| null |
Tonyboy999
|
huggingface/setfit
| 260
|
How to use .predict() function
|
Hi,
I am new at using the setfit. I will be running many tunings for models and currently achieved getting evaluation metrics using ("trainer.evaluate())
However, is there any way to do something like the following to save the trained model's predictions?
trainer = SetFitTrainer(......)
trainer.train()
**predictions=trainer.predict(testX)**
SetFitTrainer has no predict function
I can achieve that with trainer.push_to_hub() and downloading back with SetFitModel.from_pretrained() but there is probably a better way without publishing on the hub?
|
https://github.com/huggingface/setfit/issues/260
|
closed
|
[
"question"
] | 2023-01-08T23:18:56Z
| 2023-01-09T10:00:38Z
| null |
yafsin
|
huggingface/setfit
| 256
|
Contrastive training number of epochs
|
The `SentenceTransformer` number of epochs is the same as the number of epochs for the classification head.
Even when `SetFitTrainer` is initialized with `num_epochs=1` and then `trainer.train(num_epochs=10)`, the sentence transformer runs with 10 epochs. Ideally, senatence transformer should run 1 epoch and the classifier should run for 10.
The reason for this is that in `trainer.py`, the `model_body.fit()` is called with `num_epochs` rather than `self.num_epochs`. Is this intended??
I can write a PR to fix this if needed.
|
https://github.com/huggingface/setfit/issues/256
|
closed
|
[
"question"
] | 2023-01-06T02:26:30Z
| 2023-01-09T10:54:45Z
| null |
abhinav-kashyap-asus
|
pytorch/serve
| 2,057
|
what is my_tc ?
|
### 🐛 Describe the bug
torchserve --start --model-store model_store --models my_tc=BERTTokenClassification.mar --ncs
curl -X POST http://127.0.0.1:8080/predictions/my_tc -T Token_classification_artifacts/sample_text_captum_input.txt
### Error logs
2023-01-05T15:51:41,260 [INFO ] W-9001-my_tc_1.0-stdout MODEL_LOG - model_name: my_tc, batchSize: 1
2023-01-05T15:51:41,628 [INFO ] W-9003-my_tc_1.0-stdout MODEL_LOG - Listening on port: /tmp/.ts.sock.9003
2023-01-05T15:51:41,633 [INFO ] W-9003-my_tc_1.0-stdout MODEL_LOG - Successfully loaded /data//python3.9/site-packages/ts/configs/metrics.yaml.
So **model_name** is my_tc ? not BERTTokenClassification
### Installation instructions
conda install -c pytorch torchserve torch-model-archiver torch-workflow-archiver
### Model Packaing
torch-model-archiver --model-name BERTTokenClassification --version 1.0 --serialized-file Transformer_model/pytorch_model.bin --handler ./Transformer_handler_generalized.py --extra-files "Transformer_model/config.json,./setup_config.json,./Token_classification_artifacts/index_to_name.json"
model_name is what ?
### config.properties
_No response_
### Versions
------------------------------------------------------------------------------------------
Environment headers
------------------------------------------------------------------------------------------
Torchserve branch:
torchserve==0.7.0b20221212
torch-model-archiver==0.7.0b20221212
Python version: 3.9 (64-bit runtime)
Python executable: /data/python
Versions of relevant python libraries:
captum==0.6.0
future==0.18.2
numpy==1.24.1
nvgpu==0.9.0
psutil==5.9.4
requests==2.28.1
sentence-transformers==2.2.2
sentencepiece==0.1.97
torch==1.13.1+cu116
torch-model-archiver==0.7.0b20221212
torch-workflow-archiver==0.2.6b20221212
torchaudio==0.13.1+cu116
torchserve==0.7.0b20221212
torchvision==0.14.1+cu116
transformers==4.26.0.dev0
wheel==0.37.1
torch==1.13.1+cu116
**Warning: torchtext not present ..
torchvision==0.14.1+cu116
torchaudio==0.13.1+cu116
Java Version:
OS: CentOS Linux release 7.9.2009 (Core)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: N/A
CMake version: version 2.8.12.2
Is CUDA available: Yes
CUDA runtime version: 11.6.124
GPU models and configuration:
GPU 0: Tesla T4
GPU 1: Tesla T4
GPU 2: Tesla T4
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
### Repro instructions
just want to know what is my_tc
### Possible Solution
_No response_
|
https://github.com/pytorch/serve/issues/2057
|
open
|
[
"triaged"
] | 2023-01-05T07:57:46Z
| 2023-01-05T15:00:14Z
| null |
ucas010
|
huggingface/diffusers
| 1,921
|
How to finetune inpainting model for object removal? What is the input prompt for object removal for both training and inference?
|
Hi team,
Thanks for your great work!
I am trying to get object removal functionality from inpainting of SD.
How to finetune inpainting model for object removal?
What is the input prompt for object removal for both training and inference?
Thanks
|
https://github.com/huggingface/diffusers/issues/1921
|
closed
|
[
"stale"
] | 2023-01-05T01:23:20Z
| 2023-04-03T14:50:38Z
| null |
hdjsjyl
|
pytorch/functorch
| 1,094
|
batching over model parameters
|
I have a use-case for `functorch`. I would like to check possible iterations of model parameters in a very efficient way (I want to eliminate the loop). Here's an example code for a simplified case I got it working:
```python
linear = torch.nn.Linear(10,2)
default_weight = linear.weight.data
sample_input = torch.rand(3,10)
sample_add = torch.rand_like(default_weight)
def interpolate_weights(alpha):
with torch.no_grad():
res_weight = torch.nn.Parameter(default_weight + alpha*sample_add)
linear.weight = res_weight
return linear(sample_input)
```
now I could do `for alpha in np.np.linspace(0.0, 1.0, 100)` but I want to vectorise this loop since my code is prohibitively slow. Is functorch here applicable? Executing:
```python
alphas = torch.linspace(0.0, 1.0, 100)
vmap(interpolate_weights)(alphas)
```
works, but how to do something similar for a simple resnet does not work. I've tried using `load_state_dict` but that's not working:
```python
from torchvision import models
model_resnet = models.resnet18(pretrained=True)
named_params = list(model_resnet.named_parameters())
named_params_data = [(n,p.data.clone()) for (n,p) in named_params]
sample_data = torch.rand(10,3,224,244)
def test_resnet(new_params):
def interpolate(alpha):
with torch.no_grad():
p_dict = {name:(old + alpha*new_params[i]) for i,(name, old) in enumerate(named_params_data)}
model_resnet.load_state_dict(p_dict, strict=False)
out = model_resnet(sample_data)
return out
return interpolate
rand_tensor = [torch.rand_like(p) for n,p in named_params_data]
to_vamp_resnet = test_thing(rand_tensor)
vmap(to_vamp_resnet)(alphas)
```
results in:
`
While copying the parameter named "fc.bias", whose dimensions in the model are torch.Size([1000]) and whose dimensions in the checkpoint are torch.Size([1000]), an exception occurred : ('vmap: inplace arithmetic(self, *extra_args) is not possible because there exists a Tensor `other` in extra_args that has more elements than `self`. This happened due to `other` being vmapped over but `self` not being vmapped over in a vmap. Please try to use out-of-place operators instead of inplace arithmetic. If said operator is being called inside the PyTorch framework, please file a bug report instead.',).
`
|
https://github.com/pytorch/functorch/issues/1094
|
open
|
[] | 2023-01-04T17:59:59Z
| 2023-01-04T21:42:36Z
| 2
|
LeanderK
|
huggingface/setfit
| 254
|
Why are the models fine-tuned with CosineSimilarity between 0 and 1?
|
Hi everyone,
This is a small question related to how models are fine-tuned during the first step of training. I see that the default loss function is `losses.CosineSimilarityLoss`. But when generating sentence pairs [here](https://github.com/huggingface/setfit/blob/35c0511fa9917e653df50cb95a22105b397e14c0/src/setfit/modeling.py#L546), negative ones are assigned a 0 label.
I understand that having scores between 0 and 1 is ideal, because they can be interpreted as probabilities. But cosine similarity ranges from -1 to 1, so shouldn't we expect the full range to be used? The model head can then make predictions on a more isotropic embedding space.
Is this related to how Sentence Transformers are pre-trained?
Thanks for your clarifications!
|
https://github.com/huggingface/setfit/issues/254
|
open
|
[
"question"
] | 2023-01-03T09:47:11Z
| 2023-03-14T10:24:17Z
| null |
EdouardVilain-Git
|
pytorch/TensorRT
| 1,570
|
❓ [Question] When I use fx2trt, can an unsupported op fallback to pytorch like the TorchScript compiler?
|
## ❓ Question
<!-- Your question -->
When I use fx2trt, can an unsupported op fallback to pytorch like the TorchScript compiler?
|
https://github.com/pytorch/TensorRT/issues/1570
|
closed
|
[
"question"
] | 2023-01-03T05:26:00Z
| 2023-01-06T22:22:12Z
| null |
chenzhengda
|
pytorch/TensorRT
| 1,569
|
❓ [Question] How do you use dynamic shape when using fx as ir and the model is not fully lowerable
|
## ❓ Question
I have a pytorch model that contains a Pixel Shuffle operation (which is not fully supported) and I would like to convert it to TensorRT, while being able to specify a dynamic shape as input. The "ts" path does not work as there is an issue, the "fx" path has problems too and I am not able to use a splitted model with dynamic shapes.
## What you have already tried
* The conversion using TorchScript as "ir" is not working (see Issue #1568)
* The conversion using `torch_tensorrt.fx.compile` succeeds when I use a static shape, however there is no way of specifying a dynamic shape
* Using a manual approach (that is by manually tracing with `acc_tracer`, then constructing the `TRTInterpreter` and finally the `TRTModule`) fails as there is a non supported operation (a pixel shuffle layer) (Maybe I should open an Issue for this too?)
* Using the manual approach with a `TRTSplitter` is maybe the way to go but I don't know how to specify the dynamic shape constraints in this situation.
The "manual" approach that I mentioned is the one specified in [examples/fx/fx2trt_example.py](https://github.com/pytorch/TensorRT/blob/master/examples/fx/fx2trt_example.py) and in the docs.
Here is the code as I have it now. Please note that the branch with the splitter is executed and the result is errors when I execute the trt model with different shapes. If `do_split` is set to `False` the conversion fails as `nn.PixelShuffle` is not supported.
```python
import tensorrt as trt
import torch.fx
import torch.nn as nn
import torch_tensorrt.fx.tracer.acc_tracer.acc_tracer as acc_tracer
import torchvision.models as models
from torch_tensorrt.fx import InputTensorSpec, TRTInterpreter, TRTModule
from torch_tensorrt.fx.utils import LowerPrecision
from torch_tensorrt.fx.tools.trt_splitter import TRTSplitter
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.shuffle = nn.PixelShuffle(2)
def forward(self, x):
return self.shuffle(self.conv(x))
torch.set_grad_enabled(False)
# inputs
inputs = [torch.rand(1, 3, 224, 224).cuda()]
factory_kwargs = {"dtype": torch.float32, "device": torch.device("cuda:0")}
model = MyModel().to(**factory_kwargs)
model = model.eval()
out = model(inputs[0])
# sybolic trace
acc_model = acc_tracer.trace(model, inputs)
do_split = True
if do_split:
# split
splitter = TRTSplitter(acc_model, inputs)
splitter.node_support_preview(dump_graph=False)
split_mod = splitter()
print(split_mod.graph)
def get_submod_inputs(mod, submod, inputs):
acc_inputs = None
def get_input(self, inputs):
nonlocal acc_inputs
acc_inputs = inputs
handle = submod.register_forward_pre_hook(get_input)
mod(*inputs)
handle.remove()
return acc_inputs
for name, _ in split_mod.named_children():
if "_run_on_acc" in name:
submod = getattr(split_mod, name)
# Get submodule inputs for fx2trt
acc_inputs = get_submod_inputs(split_mod, submod, inputs)
# fx2trt replacement
interp = TRTInterpreter(
submod,
InputTensorSpec.from_tensors(acc_inputs),
explicit_batch_dimension=True,
)
r = interp.run(lower_precision=LowerPrecision.FP32)
trt_mod = TRTModule(*r)
setattr(split_mod, name, trt_mod)
trt_model = split_mod
else:
# input specs
input_specs = [
InputTensorSpec(
shape=(1, 3, -1, -1),
dtype=torch.float32,
device="cuda:0",
shape_ranges=[((1, 3, 112, 112), (1, 3, 224, 224), (1, 3, 512, 512))],
),
]
# input_specs = [
# InputTensorSpec(
# shape=(1, 3, 224, 224),
# dtype=torch.float32,
# device="cuda:0",
# ),
# ]
# TRT interpreter
interp = TRTInterpreter(
acc_model,
input_specs,
explicit_batch_dimension=True,
explicit_precision=True,
logger_level=trt.Logger.INFO,
)
interpreter_result = interp.run(
max_batch_size=4, lower_precision=LowerPrecision.FP32
)
# TRT module
trt_model = TRTModule(
interpreter_result.engine,
interpreter_result.input_names,
interpreter_result.output_names,
)
trt_out = trt_model(inputs[0])
trt_model(torch.rand(1,3, 112, 112).cuda())
trt_model(torch.rand(1,3, 150, 150).cuda())
trt_model(torch.rand(1,3, 400, 400).cuda())
trt_model(torch.rand(1,3, 512, 512).cuda())
print((trt_out - out).max())
```
## Environment
The official NVIDIA Pytorch Docker image version 22.12 is used.
> Build information about Torch-TensorRT can be found by turning on debug
|
https://github.com/pytorch/TensorRT/issues/1569
|
closed
|
[
"question",
"No Activity",
"component: fx"
] | 2023-01-02T14:44:52Z
| 2023-04-15T00:02:10Z
| null |
ivan94fi
|
pytorch/pytorch
| 91,537
|
Unclear how to change compiler used by `torch.compile`
|
### 📚 The doc issue
It is not clear from https://pytorch.org/tutorials//intermediate/torch_compile_tutorial.html, nor from the docs in `torch.compile`, nor even from looking through `_dynamo/config.py`, how one can change the compiler used by PyTorch.
Right now I am seeing the following issue. My code:
```python
import torch
@torch.compile
def f(x):
return 0.5 * x
f(torch.tensor(1.0))
```
<details><summary>This produces the following error message (click to toggle):</summary>
```
---------------------------------------------------------------------------
CalledProcessError Traceback (most recent call last)
File ~/venvs/main/lib/python3.10/site-packages/torch/_inductor/codecache.py:445, in CppCodeCache.load(cls, source_code)
444 try:
--> 445 subprocess.check_output(cmd, stderr=subprocess.STDOUT)
446 except subprocess.CalledProcessError as e:
File /opt/homebrew/Cellar/python@3.10/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/subprocess.py:421, in check_output(timeout, *popenargs, **kwargs)
419 kwargs['input'] = empty
--> 421 return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
422 **kwargs).stdout
File /opt/homebrew/Cellar/python@3.10/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/subprocess.py:526, in run(input, capture_output, timeout, check, *popenargs, **kwargs)
525 if check and retcode:
--> 526 raise CalledProcessError(retcode, process.args,
527 output=stdout, stderr=stderr)
528 return CompletedProcess(process.args, retcode, stdout, stderr)
CalledProcessError: Command '['g++', '/tmp/torchinductor_mcranmer/p4/cp42uf272g2qggmogzazkui7he4vnm4ftyfi2ghvyudtmaxxi25x.cpp', '-shared', '-fPIC', '-Wall', '-std=c++17', '-Wno-unused-variable', '-I/Users/mcranmer/venvs/main/lib/python3.10/site-packages/torch/include', '-I/Users/mcranmer/venvs/main/lib/python3.10/site-packages/torch/include/torch/csrc/api/include', '-I/Users/mcranmer/venvs/main/lib/python3.10/site-packages/torch/include/TH', '-I/Users/mcranmer/venvs/main/lib/python3.10/site-packages/torch/include/THC', '-I/opt/homebrew/opt/python@3.10/Frameworks/Python.framework/Versions/3.10/include/python3.10', '-lgomp', '-march=native', '-O3', '-ffast-math', '-fno-finite-math-only', '-fopenmp', '-D', 'C10_USING_CUSTOM_GENERATED_MACROS', '-o/tmp/torchinductor_mcranmer/p4/cp42uf272g2qggmogzazkui7he4vnm4ftyfi2ghvyudtmaxxi25x.so']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
CppCompileError Traceback (most recent call last)
File ~/venvs/main/lib/python3.10/site-packages/torch/_dynamo/output_graph.py:676, in OutputGraph.call_user_compiler(self, gm)
675 else:
--> 676 compiled_fn = compiler_fn(gm, self.fake_example_inputs())
677 _step_logger()(logging.INFO, f"done compiler function {name}")
File ~/venvs/main/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py:1032, in wrap_backend_debug.<locals>.debug_wrapper(gm, example_inputs, **kwargs)
1031 else:
-> 1032 compiled_gm = compiler_fn(gm, example_inputs, **kwargs)
1034 return compiled_gm
File ~/venvs/main/lib/python3.10/site-packages/torch/__init__.py:1190, in _TorchCompileInductorWrapper.__call__(self, model_, inputs_)
1189 with self.cm:
-> 1190 return self.compile_fn(model_, inputs_)
File ~/venvs/main/lib/python3.10/site-packages/torch/_inductor/compile_fx.py:398, in compile_fx(model_, example_inputs_, inner_compile)
393 with overrides.patch_functions():
394
395 # TODO: can add logging before/after the call to create_aot_dispatcher_function
396 # in torch._functorch/aot_autograd.py::aot_module_simplified::aot_function_simplified::new_func
397 # once torchdynamo is merged into pytorch
--> 398 return aot_autograd(
399 fw_compiler=fw_compiler,
400 bw_compiler=bw_compiler,
401 decompositions=select_decomp_table(),
402 partition_fn=functools.partial(
403 min_cut_rematerialization_partition, compiler="inductor"
404 ),
405 )(model_, example_inputs_)
File ~/venvs/main/lib/python3.10/site-packages/torch/_dynamo/optimizations/training.py:78, in aot_autograd.<locals>.compiler_fn(gm, example_inputs)
77 with enable_aot_logging():
---> 78 cg = aot_module_simplified(gm, example_inputs, **kwargs)
79 counters["aot_autograd"]["ok"] += 1
File ~/venvs/main/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py:2355, in aot_module_simplified(mod, args, fw_compiler, bw_compiler, partition_fn, decompositions, hasher_type, static_argnums)
2353 full_args.extend(args)
-> 2355 compiled_fn = create_aot_dispatcher_function(
2356 functional_call,
2357 full_args,
2358 aot_config,
2359 )
2361 # TODO: Th
|
https://github.com/pytorch/pytorch/issues/91537
|
closed
|
[
"module: docs",
"triaged",
"oncall: pt2",
"module: dynamo"
] | 2022-12-30T15:40:11Z
| 2023-12-01T19:00:48Z
| null |
MilesCranmer
|
pytorch/pytorch
| 91,498
|
how to Wrap normalization layers like LayerNorm in FP32 when use FSDP
|
in the blog https://pytorch.org/blog/scaling-vision-model-training-platforms-with-pytorch/
<img width="904" alt="image" src="https://user-images.githubusercontent.com/16861194/209910992-619704cd-0ef4-42ec-9d5c-ec7b42005b8b.png">
how to Wrap normalization layers like LayerNorm in FP32 when use FSDP, do we have a example code?
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
|
https://github.com/pytorch/pytorch/issues/91498
|
closed
|
[
"oncall: distributed",
"triaged",
"module: fsdp"
] | 2022-12-29T06:13:34Z
| 2023-08-04T17:17:32Z
| null |
xiaohu2015
|
huggingface/setfit
| 251
|
Using setfit with the Hugging Face API
|
Hi, thank you so much for this amazing library!
I have trained my model and pushed it to the Hugging Face hub.
Since the output is a text-classification task, and the model card uploaded is for the sentence transformers, how should I use the model to run the classification model through the Hugging Face API?
Thank you!
|
https://github.com/huggingface/setfit/issues/251
|
open
|
[
"question"
] | 2022-12-29T01:46:37Z
| 2023-01-01T07:53:43Z
| null |
kwen1510
|
huggingface/setfit
| 249
|
Sentence Pairs generation: is possible to parallelize it?
|
My dataset has 20k samples, 200 labels, and 32 iterations, so that means around 128 million samples, right?
there's some way to parallelize the pairs sentences creation?
or at least to save these pairs to create one time and reuse multiple times (i.e. to train with different epochs)
Thanks
|
https://github.com/huggingface/setfit/issues/249
|
open
|
[
"question"
] | 2022-12-28T17:50:02Z
| 2023-02-14T20:04:29Z
| null |
info2000
|
huggingface/setfit
| 245
|
extracting embeddings from a trained SetFit model.
|
Hey First of All, Thank You For This Great Package!
IMy task relates to semantic similarity, in which I find 'closeness' of a query sentence to a list of candidate sentences. Something like [shown here](https://www.sbert.net/docs/usage/semantic_textual_similarity.html)
I wanted to know if there was a way to extract embeddings from a 'trained SetFit' model and then instead of utilizing the classification head just compute similarity of a given query sentences to the embeddings in SetFit.
Awaiting your answer,
Thanks again
|
https://github.com/huggingface/setfit/issues/245
|
closed
|
[
"question"
] | 2022-12-26T12:27:50Z
| 2023-12-06T13:21:04Z
| null |
moonisali
|
huggingface/optimum
| 640
|
Improve documentations around ONNX export
|
### Feature request
* Document `-with-past`, `--for-ort`, why use it
* Add more details in `optimum-cli export onnx --help` directly
### Motivation
/
### Your contribution
/
|
https://github.com/huggingface/optimum/issues/640
|
closed
|
[
"documentation",
"onnx",
"exporters"
] | 2022-12-23T15:54:32Z
| 2023-01-03T16:34:56Z
| 0
|
fxmarty
|
huggingface/datasets
| 5,385
|
Is `fs=` deprecated in `load_from_disk()` as well?
|
### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the same thing shouldn't also apply to `datasets.load.load_from_disk()` as well ?
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/load.py#L1779
### Steps to reproduce the bug
n/a
### Expected behavior
n/a
### Environment info
n/a
|
https://github.com/huggingface/datasets/issues/5385
|
closed
|
[] | 2022-12-22T21:00:45Z
| 2023-01-23T10:50:05Z
| 3
|
dconathan
|
pytorch/examples
| 1,105
|
MNIST Hogwild on Apple Silicon
|
Any help would be appreciated! Unable to run multiprocessing with mps device
## Context
<!--- How has this issue affected you? What are you trying to accomplish? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
* Pytorch version: 2.0.0.dev20221220
* Operating System and version: macOS 13.1
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Installed using source? [yes/no]: no
* Are you planning to deploy it using docker container? [yes/no]: no
* Is it a CPU or GPU environment?: Trying to use GPU
* Which example are you using: MNIST Hogwild
* Link to code or data to repro [if any]: https://github.com/pytorch/examples/tree/main/mnist_hogwild
## Expected Behavior
<!--- If you're describing a bug, tell us what should happen -->
Adding argument --mps should result in training with GPU
## Current Behavior
<!--- If describing a bug, tell us what happens instead of the expected behavior -->
Runtimeerror: _share_filename_: only available on CPU
```
Traceback (most recent call last):
File "/Volumes/Main/pytorch/main.py", line 87, in <module>
model.share_memory() # gradients are allocated lazily, so they are not shared here
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/nn/modules/module.py", line 2340, in share_memory
return self._apply(lambda t: t.share_memory_())
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/nn/modules/module.py", line 784, in _apply
module._apply(fn)
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/nn/modules/module.py", line 807, in _apply
param_applied = fn(param)
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/nn/modules/module.py", line 2340, in <lambda>
return self._apply(lambda t: t.share_memory_())
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/_tensor.py", line 616, in share_memory_
self._typed_storage()._share_memory_()
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/storage.py", line 701, in _share_memory_
self._untyped_storage.share_memory_()
File "/Users/jeffreythomas/opt/anaconda3/envs/pytorch/lib/python3.9/site-packages/torch/storage.py", line 209, in share_memory_
self._share_filename_cpu_()
RuntimeError: _share_filename_: only available on CPU
```
## Possible Solution
<!--- Not obligatory, but suggest a fix/reason for the bug -->
## Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug. Include code to reproduce, if relevant -->
1. Clone repo
2. Run with --mps on Apple M1 Ultra
...
|
https://github.com/pytorch/examples/issues/1105
|
open
|
[
"help wanted"
] | 2022-12-22T06:25:48Z
| 2023-12-09T09:43:08Z
| 4
|
jeffreykthomas
|
pytorch/functorch
| 1,088
|
Add vmap support for PyTorch operators
|
We're looking for more motivated open-source developers to help build out functorch (and PyTorch, since functorch is now just a part of PyTorch). Below is a selection of good first issues.
- [x] https://github.com/pytorch/pytorch/issues/91174
- [x] https://github.com/pytorch/pytorch/issues/91175
- [x] https://github.com/pytorch/pytorch/issues/91176
- [x] https://github.com/pytorch/pytorch/issues/91177
- [x] https://github.com/pytorch/pytorch/issues/91402
- [x] https://github.com/pytorch/pytorch/issues/91403
- [x] https://github.com/pytorch/pytorch/issues/91404
- [x] https://github.com/pytorch/pytorch/issues/91415
- [ ] https://github.com/pytorch/pytorch/issues/91700
In general there's a high barrier to developing PyTorch and/or functorch. We've collected topics and information over at the [PyTorch Developer Wiki](https://github.com/pytorch/pytorch/wiki/Core-Frontend-Onboarding)
|
https://github.com/pytorch/functorch/issues/1088
|
open
|
[
"good first issue"
] | 2022-12-20T18:51:16Z
| 2023-04-19T23:40:06Z
| 2
|
zou3519
|
huggingface/optimum
| 625
|
Add support for Speech Encoder Decoder models in `optimum.exporters.onnx`
|
### Feature request
Add support for [Speech Encoder Decoder Models](https://huggingface.co/docs/transformers/v4.25.1/en/model_doc/speech-encoder-decoder#speech-encoder-decoder-models)
### Your contribution
Me or other members can implement it (cc @mht-sharma @fxmarty )
|
https://github.com/huggingface/optimum/issues/625
|
open
|
[
"feature-request",
"onnx"
] | 2022-12-20T16:48:49Z
| 2023-11-15T10:02:54Z
| 4
|
michaelbenayoun
|
huggingface/optimum
| 615
|
Shall we set diffusers as soft dependency for onnxruntime module?
|
It seems a little bit strange for me that we need to have diffusers for doing sequence classification.
### System Info
```shell
Dev branch of Optimum
```
### Who can help?
@echarlaix @JingyaHuang
### Reproduction
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
```
### Error message
```
RuntimeError: Failed to import optimum.onnxruntime.modeling_ort because of the following error (look up to see its traceback):
No module named 'diffusers'
```
### Expected behavior
Be able to do sequence classification without diffusers.
### Contribution
I can open a PR to make diffusers a soft dependency
|
https://github.com/huggingface/optimum/issues/615
|
closed
|
[
"bug"
] | 2022-12-19T11:23:34Z
| 2022-12-21T14:02:45Z
| 1
|
JingyaHuang
|
pytorch/android-demo-app
| 287
|
How to convert live camera to landscape object detection with correct camera aspect ratio?
|
https://github.com/pytorch/android-demo-app/issues/287
|
open
|
[] | 2022-12-19T10:01:47Z
| 2022-12-19T10:05:06Z
| null |
pratheeshsuvarna
|
|
pytorch/vision
| 7,043
|
How to generate the score for a determined region of an image using Mask R-CNN
|
### 🐛 Describe the bug
I want to change the RegionProposalNetwork of Mask R-CNN to generate the score for a determined region of an image using Mask R-CNN.
```
import torch
from torch import nn
import torchvision.models as models
import torchvision
from torchvision.models.detection import MaskRCNN
from torchvision.models.detection.anchor_utils import AnchorGenerator
model = models.detection.maskrcnn_resnet50_fpn(pretrained=True)
class rpn_help(nn.Module):
def __init__(self,) -> None:
super().__init__()
def forward(self,) :
proposals=torch.tensor([ 78.0753, 12.7310, 165.6465, 153.7253])
proposal_losses=0
return proposals, proposal_losses
model.rpn= rpn_help
model.eval()
model(input_tensor) # input_tensor is an image
```
It takes error like this
<img width="786" alt="WeChatbb686829d6c0f06106e53c1e3feecb55" src="https://user-images.githubusercontent.com/98499594/208374946-137eb9b2-6a64-4a06-8d4e-57caf1bb72b3.png">
Does anyone know how to generate the score for a determined region of an image using Mask R-CNN
?
### Versions
python 3.8
|
https://github.com/pytorch/vision/issues/7043
|
open
|
[] | 2022-12-19T08:04:50Z
| 2022-12-19T08:04:50Z
| null |
mingqiJ
|
pytorch/serve
| 2,039
|
how to load models at startup for docker
|
First, I created docker container by followed https://github.com/pytorch/serve/tree/master/docker#create-torchserve-docker-image, I leaves all configs default except remove `--rm` in `docker run ...` and make docker container start automatically by
```docker update --restart unless-stopped mytorchserve```
Then, I registered some model via Management API.
Now, how to make models automated registed when my PC reboot?
|
https://github.com/pytorch/serve/issues/2039
|
closed
|
[] | 2022-12-17T02:55:23Z
| 2022-12-18T01:00:29Z
| null |
hungtooc
|
huggingface/transformers
| 20,794
|
When I use the following code on tpuvm and use model.generate() to infer, the speed is very slow. It seems that the tpu is not used. What is the problem?
|
### System Info
When I use the following code on tpuvm and use model.generate() to infer, the speed is very slow. It seems that the tpu is not used. What is the problem?
jax device is exist
```python
import jax
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
assert "TPU" in device_type
from transformers import AutoTokenizer, FlaxAutoModelForCausalLM
model = FlaxMT5ForConditionalGeneration.from_pretrained("google/mt5-small")
tokenizer = T5Tokenizer.from_pretrained("google/mt5-small")
input_context = "The dog"
# encode input context
input_ids = tokenizer(input_context, return_tensors="np").input_ids
# generate candidates using sampling
outputs = model.generate(input_ids=input_ids, max_length=20, top_k=30, do_sample=True)
print(outputs)
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import jax
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
assert "TPU" in device_type
from transformers import AutoTokenizer, FlaxAutoModelForCausalLM
model = FlaxMT5ForConditionalGeneration.from_pretrained("google/mt5-small")
tokenizer = T5Tokenizer.from_pretrained("google/mt5-small")
input_context = "The dog"
# encode input context
input_ids = tokenizer(input_context, return_tensors="np").input_ids
# generate candidates using sampling
outputs = model.generate(input_ids=input_ids, max_length=20, top_k=30, do_sample=True)
print(outputs)
```
### Expected behavior
Expect it to be fast
|
https://github.com/huggingface/transformers/issues/20794
|
closed
|
[] | 2022-12-16T09:15:32Z
| 2023-05-21T15:03:06Z
| null |
joytianya
|
huggingface/optimum
| 595
|
Document and (possibly) improve the `use_past`, `use_past_in_inputs`, `use_present_in_outputs` API
|
### Feature request
As the title says.
Basically, for `OnnxConfigWithPast` there are three attributes:
- `use_past_in_inputs`: to specify that the exported model should have `past_key_values` as inputs
- `use_present_in_outputs`: to specify that the exported model should have `past_key_values` as outputs
- `use_past`, which is basically used for either of the previous attributes when those are left unspecified
It is not currently documented, and their current meaning might be unclear to the user.
Also, maybe it is possible to find a better way of handling those.
cc @mht-sharma @fxmarty
### Motivation
The current way is working, but might not be the best way of solving the problem, and might cause some misunderstanding for potential contributors.
### Your contribution
I can work on this.
|
https://github.com/huggingface/optimum/issues/595
|
closed
|
[
"documentation",
"Stale"
] | 2022-12-15T13:57:43Z
| 2025-07-03T02:16:51Z
| 2
|
michaelbenayoun
|
huggingface/datasets
| 5,362
|
Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' )
|
### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
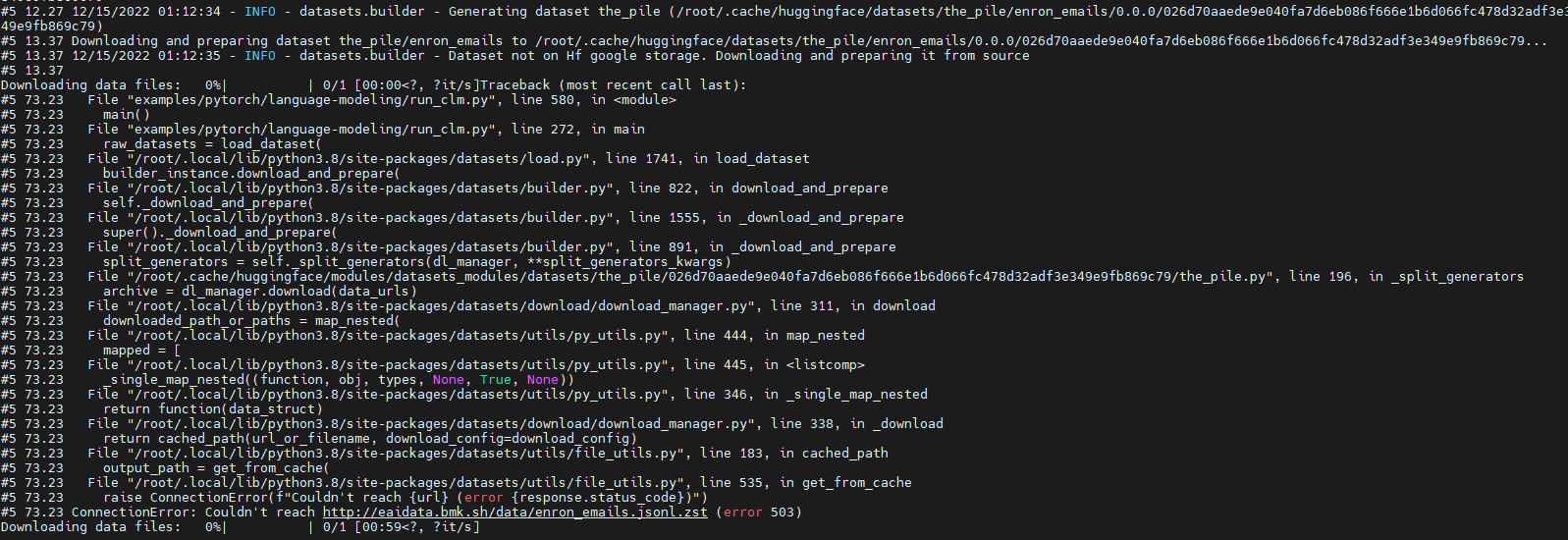
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to reproduce the bug
Steps to reproduce this issue:
git clone https://github.com/huggingface/transformers
cd transformers
python examples/pytorch/language-modeling/run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --dataset_name the_pile --dataset_config_name enron_emails --do_eval --output_dir /tmp/output --overwrite_output_dir
### Expected behavior
This issue looks like due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst " couldn't be reached.
Is there another way to download the dataset "the_pile" ?
Is there another way to cache the dataset "the_pile" but not let the hg to download it when runtime ?
### Environment info
huggingface_hub version: 0.11.1
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Python version: 3.9.12
Running in iPython ?: No
Running in notebook ?: No
Running in Google Colab ?: No
Token path ?: /home/taosy/.huggingface/token
Has saved token ?: False
Configured git credential helpers:
FastAI: N/A
Tensorflow: N/A
Torch: N/A
Jinja2: N/A
Graphviz: N/A
Pydot: N/A
|
https://github.com/huggingface/datasets/issues/5362
|
closed
|
[] | 2022-12-15T01:23:03Z
| 2022-12-15T07:45:54Z
| 2
|
shaoyuta
|
pytorch/TensorRT
| 1,547
|
❓ [Question] How can I load a TensorRT model generated with `trtexec`?
|
## ❓ Question
How can I load into Pytorch a TensorRT model engine (.trt or .plan) generated with `trtexec` ?
I have the following TensorRT model engine (generated from a ONNX file) using the `trtexec` tool provided by Nvidia
```
trtexec --onnx=../2.\ ONNX/CLIP-B32-image.onnx \
--saveEngine=../4.\ TensorRT/CLIP-B32-image.trt \
--minShapes=input:1x3x224x224 \
--optShapes=input:1x3x224x224 \
--maxShapes=input:32x3x224x224 \
--fp16
```
I want to load it into Pytorch for using the Pytorch's dataloader for fast batch ineference.
|
https://github.com/pytorch/TensorRT/issues/1547
|
closed
|
[
"question"
] | 2022-12-13T11:47:49Z
| 2022-12-13T17:49:06Z
| null |
javiabellan
|
huggingface/datasets
| 5,354
|
Consider using "Sequence" instead of "List"
|
### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
list_of_filenames = ["foo.parquet", "bar.parquet"]
ds = Dataset.from_parquet(list_of_filenames)
```
**Expected mypy output:**
```
Success: no issues found
```
**Actual mypy output:**
```py
test.py:19: error: Argument 1 to "from_parquet" of "Dataset" has incompatible type "List[str]"; expected "Union[Union[str, bytes, PathLike[Any]], List[Union[str, bytes, PathLike[Any]]]]" [arg-type]
test.py:19: note: "List" is invariant -- see https://mypy.readthedocs.io/en/stable/common_issues.html#variance
test.py:19: note: Consider using "Sequence" instead, which is covariant
```
**Env:** mypy 0.991, Python 3.10.0, datasets 2.7.1
|
https://github.com/huggingface/datasets/issues/5354
|
open
|
[
"enhancement",
"good first issue"
] | 2022-12-12T15:39:45Z
| 2025-11-21T22:35:10Z
| 13
|
tranhd95
|
huggingface/transformers
| 20,733
|
Verify that a test in `LayoutLMv3` 's tokenizer is checking what we want
|
I'm taking the liberty of opening an issue to share a question I've been keeping in the corner of my head, but now that I'll have less time to devote to `transformers` I prefer to share it before it's forgotten.
In the PR where the `LayoutLMv3` model was added, I was not very sure about the target value used for one of the tests that had to be overridden (the value was 1 in one of the previous commits and then changed to 0). The comment I am referring to is this one: https://github.com/huggingface/transformers/pull/17060#discussion_r872265358 .
Might be of interest to @ArthurZucker
|
https://github.com/huggingface/transformers/issues/20733
|
closed
|
[] | 2022-12-12T15:17:36Z
| 2023-05-26T10:14:14Z
| null |
SaulLu
|
huggingface/setfit
| 227
|
Compare with other approaches
|
Dumb question:
How does setfit compare with other approaches for sentence classification in low data settings? Two that may be worth comparing to:
- Various techniques for [augmented SBERT](https://www.sbert.net/examples/training/data_augmentation/README.html)
- Simple Contrastive Learning [SimCSE](https://github.com/princeton-nlp/SimCSE)
Pros and cons of these approaches? Thoughts?
|
https://github.com/huggingface/setfit/issues/227
|
open
|
[
"question"
] | 2022-12-12T14:32:51Z
| 2022-12-20T08:49:52Z
| null |
creatorrr
|
huggingface/datasets
| 5,351
|
Do we need to implement `_prepare_split`?
|
### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to implement, hence the genesis of my question):
```
Traceback (most recent call last):
File "/home/jason/source/python/prism_machine_learning/examples/create_hf_datasets.py", line 28, in <module>
dataset_builder.download_and_prepare()
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 1124, in _prepare_split
raise NotImplementedError()
NotImplementedError
```
### Steps to reproduce the bug
I will share implementation if it turns out that everything should be working (i.e. we only need to implement those 3 methods the docs mention), but I don't want to distract from the original question.
### Expected behavior
I just need to know if there are additional methods we need to implement when subclassing `DatasetBuilder` besides what the documentation specifies -> `_info`, `_split_generators` and `_generate_examples`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.2.5
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
|
https://github.com/huggingface/datasets/issues/5351
|
closed
|
[] | 2022-12-12T01:38:54Z
| 2022-12-20T18:20:57Z
| 11
|
jmwoloso
|
pytorch/tutorials
| 2,151
|
Quantize weights to unisgned 8 bit
|
I am trying to quantize the weights of the BERT model to unsigned 8 bits. Am using the 'dynamic_quantize' function for the same.
`quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.quint8
)`
But it throws the error 'AssertionError: The only supported dtypes for dynamic quantized linear are qint8 and float16 got: torch.quint8'.
Is there any specific reason for this not to be supported? Could I use any other method to quantize the weights to unsigned int8 bits?
Here is a link to the colab sheet:
https://colab.research.google.com/drive/14G_jdLuZD5846jUDZUdGNf1x0DMz8GKK?usp=sharing
Thanks!
cc @jerryzh168 @z-a-f @vkuzo
|
https://github.com/pytorch/tutorials/issues/2151
|
closed
|
[
"question",
"arch-optimization"
] | 2022-12-10T08:59:07Z
| 2023-02-23T19:53:08Z
| null |
rohanjuneja
|
huggingface/datasets
| 5,343
|
T5 for Q&A produces truncated sentence
|
Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to train the T5-large model. I have two questions.
For example, I set both the max_length, max_input_length, max_output_length to 128.
How to deal with those long answers? I just left them as is and the T5Tokenizer can automatically handle. I would assume the tokenizer just truncates an answer at the position of 128th word (or 127th). Is it possible that I manually split an answer into different parts, each part has 128 words; and then all these sub-answers serve as a separate answer to the same question?
Another question is that I get incomplete (truncated) answers when using the fine-tuned model in inference, even though the predicted answer is shorter than 128 words. I found a message posted 2 years ago saying that one should add at the end of texts when fine-tuning T5. I followed that but then got a warning message that duplicated were found. I am assuming that this is because the tokenizer truncates an answer text, thus is missing in the truncated answer, such that the end token is not produced in predicted answer. However, I am not sure. Can anybody point out how to address this issue?
Any suggestions are highly appreciated.
Below is some code snippet.
`
import pytorch_lightning as pl
from torch.utils.data import DataLoader
import torch
import numpy as np
import time
from pathlib import Path
from transformers import (
Adafactor,
T5ForConditionalGeneration,
T5Tokenizer,
get_linear_schedule_with_warmup
)
from torch.utils.data import RandomSampler
from question_answering.utils import *
class T5FineTuner(pl.LightningModule):
def __init__(self, hyparams):
super(T5FineTuner, self).__init__()
self.hyparams = hyparams
self.model = T5ForConditionalGeneration.from_pretrained(hyparams.model_name_or_path)
self.tokenizer = T5Tokenizer.from_pretrained(hyparams.tokenizer_name_or_path)
if self.hyparams.freeze_embeds:
self.freeze_embeds()
if self.hyparams.freeze_encoder:
self.freeze_params(self.model.get_encoder())
# assert_all_frozen()
self.step_count = 0
self.output_dir = Path(self.hyparams.output_dir)
n_observations_per_split = {
'train': self.hyparams.n_train,
'validation': self.hyparams.n_val,
'test': self.hyparams.n_test
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.em_score_list = []
self.subset_score_list = []
data_folder = r'C:\Datasets\MedQuAD-master'
self.train_data, self.val_data, self.test_data = load_medqa_data(data_folder)
def freeze_params(self, model):
for param in model.parameters():
param.requires_grad = False
def freeze_embeds(self):
try:
self.freeze_params(self.model.model.shared)
for d in [self.model.model.encoder, self.model.model.decoder]:
self.freeze_params(d.embed_positions)
self.freeze_params(d.embed_tokens)
except AttributeError:
self.freeze_params(self.model.shared)
for d in [self.model.encoder, self.model.decoder]:
self.freeze_params(d.embed_tokens)
def lmap(self, f, x):
return list(map(f, x))
def is_logger(self):
return self.trainer.proc_rank <= 0
def forward(self, input_ids, attention_mask=None, decoder_input_ids=None, decoder_attention_mask=None, labels=None):
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=labels
)
def _step(self, batch):
labels = batch['target_ids']
labels[labels[:, :] == self.tokenizer.pad_token_id] = -100
outputs = self(
input_ids = batch['source_ids'],
attention_mask=batch['source_mask'],
labels=labels,
decoder_attention_mask=batch['target_mask']
)
loss = outputs[0]
return loss
def ids_to_clean_text(self, generated_ids):
gen_text = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return self.lmap(str.strip, gen_text)
def _generative_step(self, batch):
t0 = time.time()
generated_ids = self.model.generate(
batch["source_ids"],
attention_mask=batch["source_mask"],
use_cache=True,
decode
|
https://github.com/huggingface/datasets/issues/5343
|
closed
|
[] | 2022-12-08T19:48:46Z
| 2022-12-08T19:57:17Z
| 0
|
junyongyou
|
huggingface/optimum
| 566
|
Add optimization and quantization options to `optimum.exporters.onnx`
|
### Feature request
Would be nice to have two more arguments in `optimum.exporters.onnx` in order to have the optimized and quantized version of the exported models along side with the "normal" ones. I can imagine something like:
```
python -m optimum.exporters.onnx --model <model-name> -OX -quantized-arch <arch> output
```
Where:
* `-OX` corresponds to the already available `O1`, `O2`, `O3` and `O4` optimization possibilities.
* `-quantized-arch` can take values such as `arm64`, `avx2`, `avx512`, `avx512_vnni` and `tensorrt`
### Motivation
This will allow to very easily create optimized/quantized version of the models we need.
### Your contribution
I might help on submiting a PR for it, but I'm not able to give a "when" for now.
|
https://github.com/huggingface/optimum/issues/566
|
closed
|
[] | 2022-12-08T18:49:04Z
| 2023-04-11T12:26:54Z
| 17
|
jplu
|
pytorch/pytorch
| 93,472
|
torch.compile does not bring better performance and even lower than no compile, what is the possible reason?
|
### 🐛 Describe the bug
_No response_
### Error logs
_No response_
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
|
https://github.com/pytorch/pytorch/issues/93472
|
closed
|
[
"oncall: pt2"
] | 2022-12-07T17:00:43Z
| 2023-02-01T17:47:28Z
| null |
chexiangying
|
pytorch/TensorRT
| 1,535
|
[Bug] Invoke error while implementing TensorRT on pytorch
|
## ❓ Question
Got the error while using tensorrt on pytorch pretrained resnet model. what is this error and how to solve it.
## Error
Traceback (most recent call last):
File "pretrained_resnet.py", line 116, in <module>
trt_model_32 = torch_tensorrt.compile(traced, inputs=[torch_tensorrt.Input(
File "/home/am/anaconda3/envs/amrith/lib/python3.8/site-packages/torch_tensorrt/_compile.py", line 125, in compile
return torch_tensorrt.ts.compile(
File "/home/am/anaconda3/envs/amrith/lib/python3.8/site-packages/torch_tensorrt/ts/_compiler.py", line 136, in compile
compiled_cpp_mod = _C.compile_graph(module._c, _parse_compile_spec(spec))
TypeError: compile_graph(): incompatible function arguments. The following argument types are supported:
1. (arg0: torch::jit::Module, arg1: torch_tensorrt._C.ts.CompileSpec) -> torch::jit::Module
Invoked with: <torch.ScriptModule object at 0x7fb5cc5c78f0>, <torch_tensorrt._C.ts.CompileSpec object at 0x7fb5cc47d8b0>
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1535
|
closed
|
[
"question",
"No Activity"
] | 2022-12-07T07:46:02Z
| 2023-04-01T00:02:09Z
| null |
amrithpartha
|
huggingface/transformers
| 20,638
|
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`labels` in this case) have excessive nesting (inputs type `list` where type `int` is expected).
|
### System Info
- `transformers` version: 4.25.1
- Platform: Linux-5.10.133+-x86_64-with-glibc2.27
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (True)
- Tensorflow version (GPU?): 2.9.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes (Tesla T4)
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger maybe you could help?
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
# Information
I am using the implementation of text classification given in official [documentation ](https://huggingface.co/docs/transformers/tasks/sequence_classification)from huggingface and one given by @lewtun in his book.
I retrained an instance of sentence-transformers using contrastive loss on an unsupervised data dump and now want to finetune the above model on a labeled, binary dataset.
[This ](https://github.com/huggingface/transformers/issues/15505)issue is similar, and I followed the fix but to no help.
# To reproduce
1. Run [this notebook](https://colab.research.google.com/drive/1VMl5l1O4lrgSMiGTh4yKIWEY2XGUgSIm?usp=sharing)
2. Trainer.train() should produce the following error:
```
ValueError Traceback (most recent call last)
[/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in convert_to_tensors(self, tensor_type, prepend_batch_axis)
716 if not is_tensor(value):
--> 717 tensor = as_tensor(value)
718
ValueError: too many dimensions 'str'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
9 frames
[<ipython-input-75-ce45916ac715>](https://localhost:8080/#) in <module>
7 )
8
----> 9 trainer.train()
[/usr/local/lib/python3.8/dist-packages/transformers/trainer.py](https://localhost:8080/#) in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1525 self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size
1526 )
-> 1527 return inner_training_loop(
1528 args=args,
1529 resume_from_checkpoint=resume_from_checkpoint,
[/usr/local/lib/python3.8/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1747
1748 step = -1
-> 1749 for step, inputs in enumerate(epoch_iterator):
1750
1751 # Skip past any already trained steps if resuming training
[/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in __next__(self)
679 # TODO(https://github.com/pytorch/pytorch/issues/76750)
680 self._reset() # type: ignore[call-arg]
--> 681 data = self._next_data()
682 self._num_yielded += 1
683 if self._dataset_kind == _DatasetKind.Iterable and \
[/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in _next_data(self)
719 def _next_data(self):
720 index = self._next_index() # may raise StopIteration
--> 721 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
722 if self._pin_memory:
723 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
[/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/fetch.py](https://localhost:8080/#) in fetch(self, possibly_batched_index)
50 else:
51 data = self.dataset[possibly_batched_index]
---> 52 return self.collate_fn(data)
[/usr/local/lib/python3.8/dist-packages/transformers/data/data_collator.py](https://localhost:8080/#) in __call__(self, features)
247
248 def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
--> 249 batch = self.tokenizer.pad(
250 features,
251 padding=self.padding,
[/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)
3015 batch_outputs[key].append(value)
3016
-> 3017 return BatchEncoding(batch_outputs, tensor_type=return_tensors)
3018
3019 def create_token_type_ids_from_sequences(
[/usr/local/lib/python3.8/dist-packages/transf
|
https://github.com/huggingface/transformers/issues/20638
|
closed
|
[] | 2022-12-07T02:10:35Z
| 2023-01-31T21:23:46Z
| null |
vitthal-bhandari
|
huggingface/setfit
| 222
|
Pre-training a generic SentenceTransformer for domain adaptation
|
When using `SetFit` for classification in a more technical domain, I could imagine the generically-trained `SBERT` models may produce poor sentence embeddings if the domain is not represented well enough in the diverse training corpus. In this case, would it be advantageous to first apply domain adaptation techniques (as discussed [here](https://sbert.net/examples/domain_adaptation/README.html)) to an `SBERT` model before using the model as a base in `SetFit`? Have you considered and/or tested such an approach?
Thanks for the help!
|
https://github.com/huggingface/setfit/issues/222
|
open
|
[
"question"
] | 2022-12-05T15:22:57Z
| 2023-04-30T06:45:47Z
| null |
zachschillaci27
|
huggingface/setfit
| 219
|
efficient way of saving finetuned zero-shot models?
|
Hi guys, pretty interesting project.
I was wondering if there is any way to save models after a zero-shot model is finetuned for few-shot model.
So for example, if I finetuned a couple of say, `sentence-transformers/paraphrase-mpnet-base-v2` models, the major difference between them is just the weights of final few layers, weights for the rest of the model mostly remains the same, so is there a way to efficiently save the necessary final few layers thus reducing the size of models, repetedly being saved.
This way one could save, the disk space by a lot.
And apart form that, while inferencing, I don't have to load multiple huge models and instead I could have just one model containg the common freezed layers that give me some common features and just has to host the final few layers with custom classes that intakes those common features.
|
https://github.com/huggingface/setfit/issues/219
|
open
|
[
"question"
] | 2022-12-05T07:36:40Z
| 2022-12-20T08:49:32Z
| null |
RaiAmanRai
|
pytorch/TensorRT
| 1,521
|
❓ [Question] How does INT8 inference really work at runtime?
|
## ❓ Question
Hi everyone,
I can’t really find an example of how int8 inference works at runtime. What I know is that, given that we are performing uniform symmetric quantisation, we calibrate the model, i.e. we find the best scale parameters for each weight tensor (channel-wise) and *activations* (that correspondto the outputs of the activation functions, if I understood correctly). After the calibration process we can quantize the model by applying these scale parameters and clipping che values that end up outside the dynamic range of the given layer. So at this point we have a new Neural Net where all the weights are int8 in the range [-127,127] and, additionally, we have some scale parameters for the *activations*.
What I don’t understand is how we perform inference on this new neural network, do we feed the input as float32 or directly as int8? All the computations are always in int8 or sometimes we cast from int8 to float32 and viceversa?
It would be nice to find a real example of e.g. a CONV2D+BIAS+ReLU layer.
|
https://github.com/pytorch/TensorRT/issues/1521
|
closed
|
[
"question",
"component: quantization"
] | 2022-12-04T16:32:57Z
| 2023-02-02T23:54:00Z
| null |
andreabonvini
|
pytorch/data
| 911
|
`DistributedReadingService` supports multi-processing reading
|
### 🚀 The feature
`TorchData` is a great work for better data loading! I have tried it and it gives me a nice workflow with tidy code-style.❤️
When using DDP, I work with the `DataLoader2` where `reading_service=DistributedReadingService()`. I find this service runs one worker for outputting datas per node. This means it has lower reading throughput than the legacy `DataLoader`, which utilizes multiple workers with the total worker number = `num_workers * world_size`.
Therefore, is it possible to combine `DistributedReadingService` with multi-processing reading? This could be possibly done by introducing `PrototypeMultiProcessingReadingService` into `DistributedReadingService` (Just guessing. I'm not a pro for handling this.).
### Motivation, pitch
I think this feature could be a part of #427 . The detailed motivation is declared above.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/meta-pytorch/data/issues/911
|
closed
|
[] | 2022-12-04T03:49:49Z
| 2023-02-07T06:25:35Z
| 9
|
xiaosu-zhu
|
pytorch/functorch
| 1,074
|
vmap equivalent for tensor[indices]
|
Hi,
Is there a way of vmapping over the selection of passing indices within a Tensor? Minimal reproducible example below,
```
import torch
from functorch import vmap
def select(x, index):
print(x.shape, index.shape)
return x[index]
x = torch.randn(64, 1000) #64 vectors of length 1000
index=torch.arange(64) #index for each vector
out = vmap(select, in_dims=(0, 0))(x, index) #vmap over the process
print(out) #should output vector of 64
```
This should take in a batches of vectors and select the corresponding index from `index` vector (which can be viewed as a batch of scalars, and is hence represented as a vector).
The error is as follows,
```
RuntimeError: vmap: It looks like you're calling .item() on a Tensor. We don't support vmap over calling .item() on a Tensor, please try to rewrite what you're doing with other operations. If error is occurring somewhere inside PyTorch internals, please file a bug report.
```
I tried using `torch.select` but that requires passing the index as an `int` rather than `Tensor` so it must call `.item()` interally. Is there a workaround that already exists for this?
|
https://github.com/pytorch/functorch/issues/1074
|
closed
|
[] | 2022-12-03T19:20:18Z
| 2022-12-03T19:31:37Z
| 1
|
AlphaBetaGamma96
|
pytorch/examples
| 1,101
|
Inconsistency b/w tutorial and the code
|
## 📚 Documentation
In the [DDP Tutorial](https://pytorch.org/tutorials/beginner/ddp_series_multigpu.html), there is inconsistency between the code in the tutorial and [original code](https://github.com/pytorch/examples/blob/main/distributed/ddp-tutorial-series/multigpu.py).
For example, under Running the distributed training job section,
the Trainer object should take train_data as an argument not dataset (in the original code, it is right).
The ideal PR to fix this issue is to make the tutorial consistent with the original code.
|
https://github.com/pytorch/examples/issues/1101
|
closed
|
[
"help wanted",
"distributed"
] | 2022-12-03T17:15:42Z
| 2023-02-17T18:47:56Z
| 4
|
BalajiAI
|
pytorch/android-demo-app
| 280
|
StreamingASR. How to use custom RNNT model?
|
Hey guys
I have a my self trained RNNT model with another smp_bpe model.
How I can convert my smp_bpe.model to smp_bpe.dict for fairseq.data.Dictionary.load method?
|
https://github.com/pytorch/android-demo-app/issues/280
|
closed
|
[] | 2022-12-02T12:18:50Z
| 2022-12-02T14:44:48Z
| null |
make1986
|
pytorch/serve
| 2,019
|
Diagnosing very slow performance
|
### 🐛 Describe the bug
I'm trying to work out why my endpoint throughput is very slow. I wasn't sure if this is the best forum but there doesn't appear to be a specific torchserve forum on https://discuss.pytorch.org/
I have simple text classifier, I've created a custom handler as the default wasn't suitable. I tested the handler by creating a harness based on https://github.com/frank-dong-ms/torchserve-performance/blob/main/test_models_windows.py - I also added custom timer metrics into my `preprocess`/`inference`/`postprocess`
The result is that most of the `handle` time is spent in `inference`, and my model performs as expected. It processes a batch of 1 text in about 40ms and a batch of 128 in 80ms - so clearly, to get good throughput, I need larger batches.
The throughput of a basic script, passing batches of 128 to the model is about 2000 examples per second. But `torchserve` only achieves 30-60 examples per second.
I'm fairly sure the bottleneck is not in the handler, the model log seems to imply it's not receiving the request quick enough. I would hope that it could generate a batch of 128 in for maxBatchDelay=50 whilst the model is processing the previous batch, but in fact it only manages a handful. I've attached my model log below
My first question is what does the message `Backend received inference at: 1669930796` means - specifically is the number a timestamp and if so why is the same value repeated many times given that the size of the batches being passed to the handler is well below the batch size of 128 set in the model config
Second how do I stream data faster to the endpoint? Our use case is to make many requests in succession. I've tried client batching, and that does increase throughput slightly but it's still extremely slow.
My test code is based on an [example](https://github.com/pytorch/serve/blob/master/examples/image_classifier/near_real_time_video/request.py), and I've also tried curl with the -P option and the time command. Throughput is orders of magnitude slower than a simple script running inference in a loop.
```
import requests
from requests_futures.sessions import FuturesSession
from concurrent.futures import as_completed
import json
import time
api = "http://localhost:8080/predictions/text_classifier"
headers = {"Content-type": "application/json", "Accept": "text/plain"}
session = FuturesSession()
start_time = time.time()
futures = []
for text in texts:
response = session.post(api, data=text)
futures.append(response)
for response in as_completed(futures):
response = response.result().content.decode("utf-8")
total_time = int((time.time() - start_time)*1e3)
print("total time in ms:", total_time)
throughput = len(texts) / total_time *1e3
print("throughput:", throughput)
```
I'm going to look at gRPC as that is probably a better match for our use case (I think), but I feel I'm doing something wrong, or there's an issue somewhere. In particular, the number of requests per second that the front end is receiving/handling appears to be way lower than I expected - the payload per request is a string of < 128 characters.
### Error logs
model_log.log looks like
```
2022-12-02T08:39:55,921 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930795
2022-12-02T08:39:55,925 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 8 text
2022-12-02T08:39:56,015 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,016 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 4 text
2022-12-02T08:39:56,079 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,084 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 5 text
2022-12-02T08:39:56,147 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,149 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 7 text
2022-12-02T08:39:56,214 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,215 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 3 text
2022-12-02T08:39:56,279 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,281 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 6 text
2022-12-02T08:39:56,345 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received inference at: 1669930796
2022-12-02T08:39:56,346 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Received batch of 5 text
2022-12-02T08:39:56,407 [INFO ] W-9000-text_classifier_1.0.0-stdout MODEL_LOG - Backend received infe
|
https://github.com/pytorch/serve/issues/2019
|
closed
|
[
"question"
] | 2022-12-01T21:59:57Z
| 2022-12-02T22:15:06Z
| null |
david-waterworth
|
huggingface/datasets
| 5,326
|
No documentation for main branch is built
|
Since:
- #5250
- Commit: 703b84311f4ead83c7f79639f2dfa739295f0be6
the docs for main branch are no longer built.
The change introduced only triggers the docs building for releases.
|
https://github.com/huggingface/datasets/issues/5326
|
closed
|
[
"bug"
] | 2022-12-01T16:50:58Z
| 2022-12-02T16:26:01Z
| 0
|
albertvillanova
|
huggingface/datasets
| 5,325
|
map(...batch_size=None) for IterableDataset
|
### Feature request
Dataset.map(...) allows batch_size to be None. It would be nice if IterableDataset did too.
### Motivation
Although it may seem a bit of a spurious request given that `IterableDataset` is meant for larger than memory datasets, but there are a couple of reasons why this might be nice.
One is that load_dataset(...) can return either IterableDataset or Dataset. mypy will then complain if batch_size=None even if we know it is Dataset. Of course we can do:
assert isinstance(d, datasets.DatasetDict)
But it is a mild inconvenience. What's more annoying is that whenever we use something like e.g. `combine_datasets(...)`, we end up with the union again, and so have to do the assert again.
Another is that we could actually end up with an IterableDataset small enough for memory in normal/correct usage, e.g. by filtering a massive IterableDataset.
For practical usages, an alternative to this would be to convert from an iterable dataset to a map-style dataset, but it is not obvious how to do this.
### Your contribution
Not this time.
|
https://github.com/huggingface/datasets/issues/5325
|
closed
|
[
"enhancement",
"good first issue"
] | 2022-12-01T15:43:42Z
| 2022-12-07T15:54:43Z
| 5
|
frankier
|
huggingface/datasets
| 5,324
|
Fix docstrings and types in documentation that appears on the website
|
While I was working on https://github.com/huggingface/datasets/pull/5313 I've noticed that we have a mess in how we annotate types and format args and return values in the code. And some of it is displayed in the [Reference section](https://huggingface.co/docs/datasets/package_reference/builder_classes) of the documentation on the website.
Would be nice someday, maybe before releasing datasets 3.0.0, to unify it......
|
https://github.com/huggingface/datasets/issues/5324
|
open
|
[
"documentation"
] | 2022-12-01T15:34:53Z
| 2024-01-23T16:21:54Z
| 5
|
polinaeterna
|
pytorch/TensorRT
| 1,509
|
❓ [Question] What does `is_aten` argument do in torch_tensorrt.fx.compile() ?
|
## ❓ Question
The docstring for `is_aten` argument in torch_tensorrt.fx.compile() is missing and hence the users don't know what it does.
|
https://github.com/pytorch/TensorRT/issues/1509
|
closed
|
[
"question"
] | 2022-12-01T14:38:12Z
| 2022-12-02T12:50:56Z
| null |
1559588143
|
pytorch/TensorRT
| 1,508
|
❓ [Question] How to save and load compiled model from torch-tensorrt
|
I am working on a Jetson Xavier NX16 and using torch-tensorrt.compile(model, "default", input, enable_optimization) every time I restart my program seems like it is just doing the same tedious task over and over.
Is there not a way for torch-tensorrt to load the serialized engine created by torch_tensorrt.convert_method_to_trt_engine or is it only on the CXX backend API?
How would I go about saving and loading a compiled model?
Okay, so I used print(dir(comp_model)) and saw that the model had a save function. I tried using it and figured out after a friendly pop up, that I should load it with torch.jit.load and it works.
Is this an okay solution or are there some kind of insecurities with it?
|
https://github.com/pytorch/TensorRT/issues/1508
|
closed
|
[
"question"
] | 2022-12-01T11:20:08Z
| 2022-12-16T07:46:59Z
| null |
MartinPedersenpp
|
pytorch/serve
| 2,016
|
Missing mandatory parameter --model-store
|
### 📚 The doc issue
I created a config.properties file
```
model_store="model_store"
load_models=all
models = {\
"tc": {\
"1.0.0": {\
"defaultVersion": true,\
"marName": "text_classifier.mar",\
"minWorkers": 1,\
"maxWorkers": 4,\
"batchSize": 1,\
"maxBatchDelay": 100,\
"responseTimeout": 120\
}\
}\
}
```
The [documentation](https://github.com/pytorch/serve/blob/master/docs/configuration.md#command-line-parameters) for `torchserve` states:
```
Customize TorchServe behaviour by using the following command line arguments when you call torchserve:
--model-store Overrides the model_store property in config.properties file
--models Overrides the load_models property in config.properties
```
This wording implies to me that --model-store is optional, but running `torchserve --start` (from a folder containing config.properties) results in the error `Missing mandatory parameter --model-store`
It seems to me there should only be an error if the model-store location cannot be inferred at all, i.e. it's not passed via `--model-store` or defined in config.properties (it's not clear how `--model-store` can 'override' the value in config.properties if it's mandatory)
### Suggest a potential alternative/fix
_No response_
|
https://github.com/pytorch/serve/issues/2016
|
open
|
[
"documentation",
"question"
] | 2022-12-01T01:09:00Z
| 2022-12-02T01:42:05Z
| null |
david-waterworth
|
huggingface/datasets
| 5,317
|
`ImageFolder` performs poorly with large datasets
|
### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point 1
Degradation occurs because [`get_data_files_patterns`](https://github.com/huggingface/datasets/blob/main/src/datasets/data_files.py#L231-L243) runs the exact same scan for many different types of patterns, and there doesn't seem to be a way to easily limit this. It's controlled by the definition of [`ALL_DEFAULT_PATTERNS`](https://github.com/huggingface/datasets/blob/main/src/datasets/data_files.py#L82-L85).
One scan with 3M+ files takes about 10-15 minutes to complete on my setup, so having those extra scans really slows things down – from 10 minutes to 60+. Most of the scans return no matches, but they still take a significant amount of time to complete – hence the poor performance.
As a side effect, when this scan is run on 3M+ image files, Python also consumes up to 12 GB of RAM, which is not ideal.
## Performance Degradation Point 2
The second performance bottleneck is in [`PackagedDatasetModuleFactory.get_module`](https://github.com/huggingface/datasets/blob/d7dfbc83d68e87ba002c5eb2555f7a932e59038a/src/datasets/load.py#L707-L711), which calls `DataFilesDict.from_local_or_remote`.
It runs for a long time (60min+), consuming significant amounts of RAM – even more than the point 1 above. Based on `iostat -d 2`, it performs **zero** disk operations, which to me suggests that there is a code based bottleneck there that could be sorted out.
### Steps to reproduce the bug
```python
from datasets import load_dataset
import os
import huggingface_hub
dataset = load_dataset(
'imagefolder',
data_dir='/some/path',
# just to spell it out:
split=None,
drop_labels=True,
keep_in_memory=False
)
dataset.push_to_hub('account/dataset', private=True)
```
### Expected behavior
While it's certainly possible to write a custom loader to replace `ImageFolder` with, it'd be great if the off-the-shelf `ImageFolder` would by default have a setup that can scale to large datasets.
Or perhaps there could be a dedicated loader just for large datasets that trades off flexibility for performance? As in, maybe you have to define explicitly how you want it to work rather than it trying to guess your data structure like `_get_data_files_patterns()` does?
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-4.14.296-222.539.amzn2.x86_64-x86_64-with-glibc2.2.5
- Python version: 3.7.10
- PyArrow version: 10.0.1
- Pandas version: 1.3.5
|
https://github.com/huggingface/datasets/issues/5317
|
open
|
[] | 2022-12-01T00:04:21Z
| 2022-12-01T21:49:26Z
| 3
|
salieri
|
pytorch/functorch
| 1,071
|
Different gradients for HyperNet training
|
TLDR: Is there a way to optimize model created by combine_state_for_ensemble using torch.backward()?
Hi, I am using combine_state_for_ensemble for HyperNet training.
```
fmodel, fparams, fbuffers = combine_state_for_ensemble([HyperMLP() for i in range(K)])
[p.requires_grad_() for p in fparams];
weights_and_biases = vmap(fmodel)(fparams, fbuffers, z.expand(self.K,-1,-1)) #in which it parallizes over K
```
After I create the `weights_and_biases`, I put them into right shapes `ws_and_bs` and use as parameters of another ensemble.
```
fmodel, fparams, fbuffers = combine_state_for_ensemble([SimpleMLP() for i in range(K)])
outputs = vmap(fmodel)(ws_and_bs, fbuffers, inputs)
```
This approach generates exactly the same outputs if I use loops instead of vmap. However, (somehow) their gradients are different.
```
loss = compute_loss(outputs)
loss.backward()
```
Do you have any idea why?
Update: It seems like ws_and_bs does not holding any gradient even though it is requires_grad.
**Update2: It seems like I can forward by using stateless model with my generated weights but I cannot backprop from them using loss.backward(). Is there any trick that I can use?**
|
https://github.com/pytorch/functorch/issues/1071
|
open
|
[] | 2022-11-30T21:37:05Z
| 2022-12-03T13:03:44Z
| 2
|
bkoyuncu
|
pytorch/functorch
| 1,070
|
Applying grad elementwise to tensors of arbitrary shape
|
What is the easiest way to apply the grad of a function elementwise to a tensor of arbitrary shape? For example
```python
import torch
from functorch import grad, vmap
# These functions can be called with tensor of any shape and will be applied elementwise
sin = torch.sin
cos = torch.cos
# Create cos function by using grad
cos_from_grad = grad(sin)
x = torch.rand([4, 2])
# This is fine
out = sin(x)
out = cos(x)
# This throws error
# Expected f(*args) to return a scalar Tensor, got tensor with 2 dims
out = cos_from_grad(x)
```
Now in this specific case, where we have a tensor of shape `(4, 2)`, we can use `vmap` twice
```python
cos_from_grad = vmap(vmap(grad(sin)))
# This now works
out = cos_from_grad(x)
```
However, if I later need to call `cos_from_grad` on a tensor of shape `(4, 2, 3)` for example, then the above code will no longer work as I would need to add an extra `vmap`. Is there a way to use `grad` to create a `cos` function that is equivalent to `torch.cos` in the sense that it can be applied elementwise to tensors of arbitrary shape?
Thank you!
|
https://github.com/pytorch/functorch/issues/1070
|
closed
|
[] | 2022-11-29T14:45:57Z
| 2022-11-29T16:59:34Z
| 4
|
EmilienDupont
|
pytorch/serve
| 2,010
|
How to assign one or more specific gpus to each model when deploying multiple models at once.
|
How to assign one or more specific gpus to each model when deploying multiple models at once. If I have two models and three gpus, the workers of the first model I only want to deploy on gpus 0 and 1, and the workers of the second model I only want to deploy on gpus 3. Instead of assigning gpus to each model sequentially.
|
https://github.com/pytorch/serve/issues/2010
|
closed
|
[
"question",
"gpu"
] | 2022-11-29T11:26:10Z
| 2023-12-17T22:56:55Z
| null |
Git-TengSun
|
huggingface/setfit
| 209
|
Limitations of Setfit Model
|
Hi, was wondering your thoughts on some of the limitations of the Setfit model. Can it support any sort of few shot text classification, or what are some areas where this model falls short? Are there any research papers / ideas to address some of these limitations.
Also, is the model available to call via Hugging Face's inference API for enterprise. We saw the Ag-News endpoint, but are there any other endpoints that are more generalizable, or how would you recommend distilling a derivative of this model into production?
|
https://github.com/huggingface/setfit/issues/209
|
open
|
[
"question"
] | 2022-11-28T22:58:35Z
| 2023-02-24T20:11:00Z
| null |
nv78
|
pytorch/vision
| 6,985
|
Range compatibility for pytorch dependency
|
### 🚀 The feature
Currently `torchvision` only ever supports a hard-pinned version of `torch`. f.e. `torchvision==0.13.0` requires`torch==1.12.0` and `torchvision==0.13.1` requires `torch==1.12.1`. It would be easier for users if torchvision wouldn't put exact restrictions on the `torch` version.
### Motivation, pitch
Hello 👋 Thank you for your continued support of `torchvison` we use it frequently and it works great!
In the project I maintain we manage our `torch` version regularly and therefore usually upgrade quickly to a new version when it comes out. However, due to the hard-pinning of `torchvision` we are often waiting for `torchvision` to release a new version before we can use bugfixes in `torch` (or exciting new features).
This raises a few questions:
* Is it important for `torchvision` to always hard-pin a version?
* Are the upgrades of `torch` version in `torchvision` truly backwards incompatible?
* Could `torchvision` support a range of `torch` versions? (like `torchmetrics` does)
Adding a max range for the `torch` requirement would allow users to upgrade to a new version of torch automatically when it comes out.
**Examples**
`torchvision==0.13.0` could have depended on `torch<1.13` to include all bugfix releases of `torch==0.13.*`.
`torchvision==0.13.1` could have depended on `torch<1.13` to include all bugfix releases of `torch==0.13.*`.
A minimum version may also be appropriate when `torch` adds new APIs that `torchvision` wants to consume.
Your thoughts there would be greatly appreciated! Thank you for your work 🙇♂️
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/vision/issues/6985
|
closed
|
[
"question",
"topic: binaries"
] | 2022-11-28T15:01:17Z
| 2022-12-08T15:00:36Z
| null |
alexandervaneck
|
pytorch/TensorRT
| 1,484
|
Building on Jetson Xavier NX16GB with Jetpack4.6 (TensorRT8.0.1) python3.9, pytorch1.13
|
I am trying to build the torch_tensorrt wheel on my Jetson Xavier NX16GB running Jetpack4.6 which means I run TensorRT8-0-1 with python3.9.15 and a on device compiled pytorch/torchlib 1.13.0.
I just can't seem to get it to compile succesfully.
I have tried both v1.1.0 until I realized that it was not really backwards compatible with TensorRT 8.0.1, I then downgraded to v1.1.0 and tried using the workspace file from the toolchains/jp_workspaces:
```
workspace(name = "Torch-TensorRT")
load("@bazel_tools//tools/build_defs/repo:git.bzl", "git_repository")
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
http_archive(
name = "rules_python",
sha256 = "778197e26c5fbeb07ac2a2c5ae405b30f6cb7ad1f5510ea6fdac03bded96cc6f",
url = "https://github.com/bazelbuild/rules_python/releases/download/0.2.0/rules_python-0.2.0.tar.gz",
)
load("@rules_python//python:pip.bzl", "pip_install")
http_archive(
name = "rules_pkg",
sha256 = "038f1caa773a7e35b3663865ffb003169c6a71dc995e39bf4815792f385d837d",
urls = [
"https://mirror.bazel.build/github.com/bazelbuild/rules_pkg/releases/download/0.4.0/rules_pkg-0.4.0.tar.gz",
"https://github.com/bazelbuild/rules_pkg/releases/download/0.4.0/rules_pkg-0.4.0.tar.gz",
],
)
load("@rules_pkg//:deps.bzl", "rules_pkg_dependencies")
rules_pkg_dependencies()
git_repository(
name = "googletest",
commit = "703bd9caab50b139428cea1aaff9974ebee5742e",
remote = "https://github.com/google/googletest",
shallow_since = "1570114335 -0400",
)
# External dependency for torch_tensorrt if you already have precompiled binaries.
local_repository(
name = "torch_tensorrt",
path = "/opt/conda/lib/python3.8/site-packages/torch_tensorrt",
)
# CUDA should be installed on the system locally
new_local_repository(
name = "cuda",
build_file = "@//third_party/cuda:BUILD",
path = "/usr/local/cuda-10.2/",
)
new_local_repository(
name = "cublas",
build_file = "@//third_party/cublas:BUILD",
path = "/usr",
)
####################################################################################
# Locally installed dependencies (use in cases of custom dependencies or aarch64)
####################################################################################
# NOTE: In the case you are using just the pre-cxx11-abi path or just the cxx11 abi path
# with your local libtorch, just point deps at the same path to satisfy bazel.
# NOTE: NVIDIA's aarch64 PyTorch (python) wheel file uses the CXX11 ABI unlike PyTorch's standard
# x86_64 python distribution. If using NVIDIA's version just point to the root of the package
# for both versions here and do not use --config=pre-cxx11-abi
new_local_repository(
name = "libtorch",
path = "/home/user/pytorch/torch",
build_file = "third_party/libtorch/BUILD"
)
# NOTE: Unused on aarch64-jetson with NVIDIA provided PyTorch distribu†ion
new_local_repository(
name = "libtorch_pre_cxx11_abi",
path = "/home/user/pytorch/torch",
build_file = "third_party/libtorch/BUILD"
)
new_local_repository(
name = "cudnn",
path = "/usr/",
build_file = "@//third_party/cudnn/local:BUILD"
)
new_local_repository(
name = "tensorrt",
path = "/usr/",
build_file = "@//third_party/tensorrt/local:BUILD"
)
#########################################################################
# Development Dependencies (optional - comment out on aarch64)
#########################################################################
pip_install(
name = "devtools_deps",
requirements = "//:requirements-dev.txt",
)
```
With the setup.py from v1.0.0
```
import os
import sys
import glob
import setuptools
from setuptools import setup, Extension, find_packages
from setuptools.command.build_ext import build_ext
from setuptools.command.develop import develop
from setuptools.command.install import install
from distutils.cmd import Command
from wheel.bdist_wheel import bdist_wheel
from torch.utils import cpp_extension
from shutil import copyfile, rmtree
import subprocess
import platform
import warnings
dir_path = os.path.dirname(os.path.realpath(__file__))
CXX11_ABI = False
JETPACK_VERSION = None
__version__ = '1.0.0'
def get_git_revision_short_hash() -> str:
return subprocess.check_output(['git', 'rev-parse', '--short', 'HEAD']).decode('ascii').strip()
if "--release" not in sys.argv:
__version__ = __version__ + "+" + get_git_revision_short_hash()
else:
sys.argv.remove("--release")
if "--use-cxx11-abi" in sys.argv:
sys.argv.remove("--use-cxx11-abi")
CXX11_ABI = True
if platform.uname().processor == "aarch64":
if "--jetpack-version" in sys.argv:
version_idx = sys.argv.index("--jetpack-version") + 1
version = sys.argv[version_idx]
sys.argv.remove(version)
sys.argv.remove("--j
|
https://github.com/pytorch/TensorRT/issues/1484
|
closed
|
[
"question",
"channel: linux-jetpack"
] | 2022-11-28T13:08:28Z
| 2022-12-01T11:05:36Z
| null |
MartinPedersenpp
|
pytorch/examples
| 1,097
|
argument -a/--arch: invalid choice: 'efficientnet_b0'
|
Error reported:
main.py: error: argument -a/--arch: invalid choice: 'efficientnet_b0' (choose from 'alexnet', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'googlenet', 'inception_v3', 'mnasnet0_5', 'mnasnet0_75', 'mnasnet1_0', 'mnasnet1_3', 'mobilenet_v2', 'resnet101', 'resnet152', 'resnet18', 'resnet34', 'resnet50', 'resnext101_32x8d', 'resnext50_32x4d', 'shufflenet_v2_x0_5', 'shufflenet_v2_x1_0', 'shufflenet_v2_x1_5', 'shufflenet_v2_x2_0', 'squeezenet1_0', 'squeezenet1_1', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'wide_resnet101_2', 'wide_resnet50_2')
However, the model `efficientnet_bx` is listed in **README** files, is there any changes in recent commits?
|
https://github.com/pytorch/examples/issues/1097
|
closed
|
[] | 2022-11-28T10:36:54Z
| 2022-11-28T10:45:53Z
| 1
|
Deeeerek
|
pytorch/functorch
| 1,066
|
Unable to compute derivatives due to calling .item()
|
Hello, i am getting the error below whenever i try to compute the jacobian of my network.
RuntimeError: vmap: It looks like you're either (1) calling .item() on a Tensor or (2) attempting to use a Tensor in some data-dependent control flow or (3) encountering this error in PyTorch internals. For (1): we don't support vmap over calling .item() on a Tensor, please try to rewrite what you're doing with other operations. For (2): If you're doing some control flow instead, we don't support that yet, please shout over at https://github.com/pytorch/functorch/issues/257 . For (3): please file an issue.
the error can be traced back to the line below.
`weights = interpolation_weights.prod(-1)`
Is there a way around this ?
Thank you .
|
https://github.com/pytorch/functorch/issues/1066
|
closed
|
[] | 2022-11-27T05:16:57Z
| 2022-11-29T10:53:43Z
| 3
|
elientumba2019
|
pytorch/examples
| 1,096
|
DDP training question
|
Hi, I'm using the tutorial [https://github.com/pytorch/tutorials/blob/master/intermediate_source/ddp_tutorial.rst](url) for DDP train,using 4 gpus in myself code, reference Basic Use Case. But when I finished the modification, it was stuck during run the demo,meanwhile,video memory has been occupied.Could you help me?
|
https://github.com/pytorch/examples/issues/1096
|
open
|
[
"help wanted",
"distributed"
] | 2022-11-25T06:58:55Z
| 2023-08-24T06:32:13Z
| 2
|
Henryplay
|
pytorch/android-demo-app
| 278
|
How to change portrait to landscape on camera view in Object Detection App ?
|
https://github.com/pytorch/android-demo-app/issues/278
|
open
|
[] | 2022-11-24T05:00:25Z
| 2022-12-15T09:07:27Z
| null |
aravinthk00
|
|
huggingface/Mongoku
| 92
|
Switch to Svelte(Kit?)
|
https://github.com/huggingface/Mongoku/issues/92
|
closed
|
[
"enhancement",
"help wanted",
"question"
] | 2022-11-23T21:28:39Z
| 2025-10-25T16:03:14Z
| null |
julien-c
|
|
huggingface/datasets
| 5,286
|
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/enwiki/20220301/dumpstatus.json
|
### Describe the bug
I follow the steps provided on the website [https://huggingface.co/datasets/wikipedia](https://huggingface.co/datasets/wikipedia)
$ pip install apache_beam mwparserfromhell
>>> from datasets import load_dataset
>>> load_dataset("wikipedia", "20220301.en")
however this results in the following error:
raise MissingBeamOptions(
datasets.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')`
If I then prompt the system with:
>>> load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')
the following error occurs:
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/enwiki/20220301/dumpstatus.json
Here is the exact code:
Python 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from datasets import load_dataset
>>> load_dataset('wikipedia', '20220301.en')
Downloading and preparing dataset wikipedia/20220301.en to /home/[EDITED]/.cache/huggingface/datasets/wikipedia/20220301.en/2.0.0/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...
Downloading: 100%|████████████████████████████████████████████████████████████████████████████| 15.3k/15.3k [00:00<00:00, 22.2MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/datasets/load.py", line 1741, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 822, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1879, in _download_and_prepare
raise MissingBeamOptions(
datasets.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')`
>>> load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')
Downloading and preparing dataset wikipedia/20220301.en to /home/[EDITED]/.cache/huggingface/datasets/wikipedia/20220301.en/2.0.0/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...
Downloading: 100%|████████████████████████████████████████████████████████████████████████████| 15.3k/15.3k [00:00<00:00, 18.8MB/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/datasets/load.py", line 1741, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 822, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 1909, in _download_and_prepare
super()._download_and_prepare(
File "/usr/local/lib/python3.10/dist-packages/datasets/builder.py", line 891, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/rorytol/.cache/huggingface/modules/datasets_modules/datasets/wikipedia/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559/wikipedia.py", line 945, in _split_generators
downloaded_files = dl_manager.download_and_extract({"info": info_url})
File "/usr/local/lib/python3.10/dist-packages/datasets/download/download_manager.py", line 447, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/usr/local/lib/python3.10/dist-packages/datasets/download/download_manager.py", line 311, in download
downloaded_path_or_paths = map_nested(
File "/usr/local/lib/python3.10/dist-packages/datasets/utils/py_utils.py", line
|
https://github.com/huggingface/datasets/issues/5286
|
closed
|
[] | 2022-11-23T14:54:15Z
| 2024-11-23T01:16:41Z
| 3
|
roritol
|
pytorch/tutorials
| 2,126
|
Incorrect use of "epoch" in the Optimizing Model Parameters tutorial
|
From the first paragraph of the [Optimizing Model Parameters](https://github.com/pytorch/tutorials/blob/master/beginner_source/basics/optimization_tutorial.py) tutorial:
> in each iteration (called an epoch) the model makes a guess about the output, calculates the error in its guess (loss), collects the derivatives of the error with respect to its parameters (as we saw in the [previous section](https://pytorch.org/tutorials/beginner/basics/autograd_tutorial.html)), and optimizes these parameters using gradient descent.
What is described in this paragraph is a single optimization step. An epoch is a full pass over the dataset (see e.g. https://deepai.org/machine-learning-glossary-and-terms/epoch).
I propose to simply remove the "(called an epoch)" here, as the term is correctly used and explained later in the "Hyperparameters" section:
> Number of Epochs - the number times to iterate over the dataset
cc @suraj813
|
https://github.com/pytorch/tutorials/issues/2126
|
closed
|
[
"intro"
] | 2022-11-22T10:23:34Z
| 2022-11-28T21:42:30Z
| 1
|
chrsigg
|
huggingface/setfit
| 198
|
text similarity
|
Hi can I use this system to obtain the similaarity scores of my data set to a given prompts.
If not what best solution could help this problem?
thank you
|
https://github.com/huggingface/setfit/issues/198
|
open
|
[
"question"
] | 2022-11-22T06:59:21Z
| 2022-12-20T09:04:53Z
| null |
aivyon
|
huggingface/datasets
| 5,274
|
load_dataset possibly broken for gated datasets?
|
### Describe the bug
When trying to download the [winoground dataset](https://huggingface.co/datasets/facebook/winoground), I get this error unless I roll back the version of huggingface-hub:
```
[/usr/local/lib/python3.7/dist-packages/huggingface_hub/utils/_validators.py](https://localhost:8080/#) in validate_repo_id(repo_id)
165 if repo_id.count("/") > 1:
166 raise HFValidationError(
--> 167 "Repo id must be in the form 'repo_name' or 'namespace/repo_name':"
168 f" '{repo_id}'. Use `repo_type` argument if needed."
169 )
HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': 'datasets/facebook/winoground'. Use `repo_type` argument if needed
```
### Steps to reproduce the bug
Install requirements:
```
pip install transformers
pip install datasets
# It works if you uncomment the following line, rolling back huggingface hub:
# pip install huggingface-hub==0.10.1
```
Then:
```
from datasets import load_dataset
auth_token = "" # Replace with an auth token, which you can get from your huggingface account: Profile -> Settings -> Access Tokens -> New Token
winoground = load_dataset("facebook/winoground", use_auth_token=auth_token)["test"]
```
### Expected behavior
Downloading of the datset
### Environment info
Just a google colab; see here: https://colab.research.google.com/drive/15wwOSte2CjTazdnCWYUm2VPlFbk2NGc0?usp=sharing
|
https://github.com/huggingface/datasets/issues/5274
|
closed
|
[] | 2022-11-21T21:59:53Z
| 2023-05-27T00:06:14Z
| 9
|
TristanThrush
|
pytorch/TensorRT
| 1,467
|
❓ [Question] Profiling examples?
|
## ❓ Question
When I'm not using TensorRT, I run my model through an FX interpreter that times each call op (by inserting CUDA events before/after and measuring the elapsed time). I'd like to do something similar after converting/compiling the model to TensorRT, and I see there is some profiling built in with [tensorrt.Proflier](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Profiler.html) but its usage isn't clear to me.
Is there an example anywhere on how to time each layer or op with this profiler, or any other means of profiling the TensorRT engine/layers? I don't mind messing with the op converters to do so, but I don't want to have to wrap every op converter my model uses. More generally I think I could use the PyTorch profiler but it would be difficult to parse the output to get clear per-layer/per-op results.
|
https://github.com/pytorch/TensorRT/issues/1467
|
closed
|
[
"question",
"No Activity",
"component: runtime"
] | 2022-11-21T21:13:28Z
| 2023-05-04T00:02:17Z
| null |
collinmccarthy
|
huggingface/datasets
| 5,272
|
Use pyarrow Tensor dtype
|
### Feature request
I was going the discussion of converting tensors to lists.
Is there a way to leverage pyarrow's Tensors for nested arrays / embeddings?
For example:
```python
import pyarrow as pa
import numpy as np
x = np.array([[2, 2, 4], [4, 5, 100]], np.int32)
pa.Tensor.from_numpy(x, dim_names=["dim1","dim2"])
```
[Apache docs](https://arrow.apache.org/docs/python/generated/pyarrow.Tensor.html)
Maybe this belongs into the pyarrow features / repo.
### Motivation
Working with big data, we need to make sure to use the best data structures and IO out there
### Your contribution
Can try to a PR if code changes necessary
|
https://github.com/huggingface/datasets/issues/5272
|
open
|
[
"enhancement"
] | 2022-11-20T15:18:41Z
| 2024-11-11T03:03:17Z
| 17
|
franz101
|
pytorch/tutorials
| 2,122
|
using nn.Module(X).argmax(1) - get IndexError
|
Hello there, I'm student of NN course, I'm try to implement FFNN (or TDNN) to work on prediction of AR(2)-model, im using PyTorch example, and on my data and NN architecture i got pred.argmax(1) - error:
```
Traceback (most recent call last):
File "/home/b0r1ngx/PycharmProjects/ArtificialNeuroNets/group_00201/lab01/lab01_pytorch.py", line 116, in <module>
first_method()
File "/home/b0r1ngx/PycharmProjects/ArtificialNeuroNets/group_00201/lab01/lab01_pytorch.py", line 87, in first_method
test(test_data, time_delay_nn, loss_function)
File "/home/b0r1ngx/PycharmProjects/ArtificialNeuroNets/group_00201/lab01/lab01_pytorch.py", line 70, in test
c1 = pred.argmax(1) == y_pred
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
```
where it's used in you're examples:
here in test_loop function - https://github.com/pytorch/tutorials/blob/master/beginner_source/basics/optimization_tutorial.py
I'm also doesn't think that i get best `Hyperparameter`s / loss_function / optimizer - cos i get bad Accuracy / Avg loss in my case,
please help me with that:
U can check my code here:
(now im using how its recommended -1 or 0, but there is always 0)
https://github.com/b0r1ngx/ArtificialNeuroNets/blob/master/group_00201/lab01/lab01_pytorch.py
Thanks!
cc @jerryzh168 @z-a-f @vkuzo
|
https://github.com/pytorch/tutorials/issues/2122
|
open
|
[
"question",
"arch-optimization"
] | 2022-11-19T16:05:26Z
| 2023-03-01T16:22:33Z
| null |
b0r1ngx
|
huggingface/optimum
| 488
|
Community contribution - `BetterTransformer` integration for more models!
|
## `BetterTransformer` integration for more models!
`BetterTransformer` API provides faster inference on CPU & GPU through a simple interface!
Models can benefit from very interesting speedups using a one liner and by making sure to install the latest version of PyTorch. A complete guideline on how to convert a new model has been created on the [BetterTransformer documentation](https://huggingface.co/docs/optimum/bettertransformer/tutorials/contribute)!
Here is a list of models that could be potentially supported, pick one of the architecture below and let's discuss about the conversion!
Text models 🖊️ :
- [x] FSMT - [FSMTEncoderLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/fsmt/modeling_fsmt.py#L397) / @Sumanth077 https://github.com/huggingface/optimum/pull/494
- [ ] MobileBERT - [MobileBertLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/mobilebert/modeling_mobilebert.py#L498) / @raghavanone https://github.com/huggingface/optimum/pull/506
- [x] MBart - [MBartEncoderLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/mbart/modeling_mbart.py#L296) + [M2M100EncoderLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/m2m_100/modeling_m2m_100.py#L345) / https://github.com/huggingface/optimum/pull/516 @ravenouse
- [x] ProphetNet - [ProphetNetEncoderLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/prophetnet/modeling_prophetnet.py#L1130)
- [x] RemBert - [RemBertLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/rembert/modeling_rembert.py#L415)
- [x] RocBert - [RocBertLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/roc_bert/modeling_roc_bert.py#LL519C7-L519C19)
- [x] RoFormer - [RoFormerLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/roformer/modeling_roformer.py#L448)
- [x] Tapas - [TapasLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/tapas/modeling_tapas.py#L524) / https://github.com/huggingface/optimum/pull/520
Vision models 📷 :
- [x] Blip - [BlipLayer](https://github.com/huggingface/transformers/blob/fcf813417aa34f3a0ea7d283f7d4f6b0834cf098/src/transformers/models/blip/modeling_blip.py#L372)
- [ ] Detr - [DetrLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/detr/modeling_detr.py#L610)
- [ ] Flava - [FlavaLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/flava/modeling_flava.py#L597)
- [ ] GLPN - [GLPNLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/glpn/modeling_glpn.py#L292) | Cannot be supported
- [x] ViLT - [ViLTLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/vilt/modeling_vilt.py#L472) / https://github.com/huggingface/optimum/pull/508
Audio models 🔉 :
- [ ] Speech2Text - [Speech2TextLayer](https://github.com/huggingface/transformers/blob/95754b47a6d4fbdad3440a45762531e8c471c528/src/transformers/models/speech_to_text/modeling_speech_to_text.py#L350)
- [ ] NEW: Audio Speech Transformer - [ASTLayer](https://github.com/huggingface/transformers/blob/f2e7d270ec795be09e6187dd2459edb43bd861c1/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py#L274)
Let us also know if you think that some architectures can be supported that we missed. Note that for encoder-decoder based models below, we expect to convert the encoder only.
**Support for decoder-based models coming soon!**
cc @michaelbenayoun @fxmarty
https://github.com/huggingface/transformers/issues/20372
|
https://github.com/huggingface/optimum/issues/488
|
open
|
[
"good first issue"
] | 2022-11-18T10:45:39Z
| 2025-05-20T20:35:02Z
| 26
|
younesbelkada
|
huggingface/setfit
| 192
|
How to use a custom Sentence Transformer pretrained model
|
Hello team,
Presently we are using models which are present in hugging face . I have a custom trained Sentence transformer.
How I can use a custom trained Hugging face model in the present pipeline.
|
https://github.com/huggingface/setfit/issues/192
|
open
|
[
"question"
] | 2022-11-17T09:13:59Z
| 2022-12-20T09:05:06Z
| null |
theainerd
|
huggingface/setfit
| 191
|
How to build multilabel text classfication dataset
|
From the sample below, param **column_mapping** is used to set up the dataset. What is the format of label column in multilabel?Is it the one-hot label?
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for constrastive learning
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
|
https://github.com/huggingface/setfit/issues/191
|
closed
|
[
"question"
] | 2022-11-17T05:50:56Z
| 2022-12-13T22:32:16Z
| null |
HenryYuen128
|
pytorch/pytorch
| 89,136
|
[FSDP] Adam Gives Different Results Where Only Difference Is Flattening
|
Consider the following unit test (that relies on some imports from `common_fsdp.py`):
```
def test(self):
local_model = TransformerWithSharedParams.init(
self.process_group,
FSDPInitMode.NO_FSDP,
CUDAInitMode.CUDA_BEFORE,
deterministic=True,
)
fsdp_model = FSDP(
copy.deepcopy(local_model),
sharding_strategy=ShardingStrategy.NO_SHARD,
)
ddp_model = DDP(local_model, device_ids=[self.rank])
ddp_optim = torch.optim.Adam(ddp_model.parameters(), lr=1e-2)
fsdp_optim = torch.optim.Adam(fsdp_model.parameters(), lr=1e-2)
max_norm = 1
norm_type = 1
device = torch.device("cuda")
for i in range(10):
ddp_optim.zero_grad(set_to_none=True)
fsdp_optim.zero_grad(set_to_none=True)
inp = ddp_model.module.get_input(device)
for model in (ddp_model, fsdp_model):
out = model(*inp)
loss = nn.functional.cross_entropy(
out.view(-1, out.size(-1)), inp[1].view(-1), reduction="sum"
)
loss.backward()
ddp_total_norm = torch.nn.utils.clip_grad_norm_(
ddp_model.parameters(),
max_norm=max_norm,
norm_type=norm_type,
)
fsdp_total_norm = torch.nn.utils.clip_grad_norm_(
fsdp_model.parameters(),
max_norm=max_norm,
norm_type=norm_type,
)
self.assertEqual(ddp_total_norm, fsdp_total_norm)
ddp_flat_grad = torch.cat(tuple(p.grad.flatten() for p in ddp_model.parameters()))
fsdp_flat_grad = torch.cat(tuple(p.grad.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_grad, fsdp_flat_grad)
ddp_flat_param = torch.cat(tuple(p.flatten() for p in ddp_model.parameters()))
fsdp_flat_param = torch.cat(tuple(p.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_param, fsdp_flat_param)
ddp_optim.step()
fsdp_optim.step()
ddp_flat_param = torch.cat(tuple(p.flatten() for p in ddp_model.parameters()))
fsdp_flat_param = torch.cat(tuple(p.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_param, fsdp_flat_param)
```
On the `i == 3` iteration, the assertion `self.assertEqual(ddp_flat_param, fsdp_flat_param)` *after* the optimizer steps fails.
```
Mismatched elements: 2 / 8427 (0.0%)
Greatest absolute difference: 1.0077477327286033e-05 at index (6610,) (up to 1e-05 allowed)
Greatest relative difference: 8.842818419533154 at index (6610,) (up to 1.3e-06 allowed)
```
The unit test initializes a model (`TransformerWithSharedParams`) and constructs `DDP` and `FSDP` (`NO_SHARD`) instances, which should be semantically equivalent. The _only_ relevant difference should be that FSDP has flattened all parameters into one `FlatParameter`.
We run a training loop that includes `torch.nn.utils.clip_grad_norm_(max_norm=1, norm_type=1)` and uses Adam optimizer. We have 3 checks: (1) gradient elements match after backward and clipping, (2) parameter elements match immediately before optimizer step, and (3) parameter elements match immediately after optimizer step.
Since (1) and (2) pass but (3) does not (on the `i == 3` iteration), this suggests that the optimizer step is not producing the same results. As discussed above, the only difference is that the `fsdp_model` parameters are "bucketed" into a `FlatParameter` (1D containing all the same elements), while the `ddp_model` parameters preserve the original shapes.
A couple of notes:
- [!!] The mismatch does not happen if we pass `use_orig_params=True` to the FSDP constructor. This is a key observation. For `use_orig_params=True`, the optimizer operates on the parameters with their original shapes, just like DDP. This suggests that operating on the flattened parameter is indeed the cause for the difference.
- The mismatch does not happen when using `SGD` instead of `Adam`.
- The mismatch does not happen if we remove the `torch.nn.utils.clip_grad_norm_()`. However, since we have check (1), this should rule out that `clip_grad_norm_()` is producing mismatching results. Rather, we may be relying on `clip_grad_norm_()` to have the gradients be at a sufficiently small magnitude.
- The mismatch also does happen when using `loss = out.sum()` instead of the `cross_entropy` computation.
It requires some nontrivial effort to simplify this repro to be equivalent but not rely on DDP, FSDP, or the FSDP utils from `common_fsdp.py`. I will hold off on that for now.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
|
https://github.com/pytorch/pytorch/issues/89136
|
closed
|
[
"oncall: distributed",
"module: fsdp"
] | 2022-11-16T15:16:55Z
| 2024-06-11T20:01:26Z
| null |
awgu
|
huggingface/datasets
| 5,249
|
Protect the main branch from inadvertent direct pushes
|
We have decided to implement a protection mechanism in this repository, so that nobody (not even administrators) can inadvertently push accidentally directly to the main branch.
See context here:
- d7c942228b8dcf4de64b00a3053dce59b335f618
To do:
- [x] Protect main branch
- Settings > Branches > Branch protection rules > main > Edit
- [x] Check: Do not allow bypassing the above settings
- The above settings will apply to administrators and custom roles with the "bypass branch protections" permission.
- [x] Additionally, uncheck: Require approvals [under "Require a pull request before merging", which was already checked]
- Before, we could exceptionally merge a non-approved PR, using Administrator bypass
- Now that Administrator bypass is no longer possible, we would always need an approval to be able to merge; and pull request authors cannot approve their own pull requests. This could be an inconvenient in some exceptional circumstances when an urgent fix is needed
- Nevertheless, although it is no longer enforced, it is strongly recommended to merge PRs only if they have at least one approval
- [x] #5250
- So that direct pushes to main branch are no longer necessary
|
https://github.com/huggingface/datasets/issues/5249
|
closed
|
[
"maintenance"
] | 2022-11-16T14:19:03Z
| 2023-12-21T10:28:27Z
| 1
|
albertvillanova
|
pytorch/TensorRT
| 1,452
|
🐛 [Bug] FX front-end layer norm, missing plugin
|
## Bug Description
I'm using a ConvNeXt model from the timm library which uses `torch.nn.functional.layer_norm`. I'm getting this warning during conversion:
```
Unable to find layer norm plugin, fall back to TensorRT implementation
```
which is triggered from [this line](https://github.com/pytorch/TensorRT/blob/e3b992941b3ae5f1863de271fc9032829834ec6a/py/torch_tensorrt/fx/converters/acc_ops_converters.py#L717) because it fails to find the `LayerNormDynamic` plugin.
Do I need to install TensorRT differently from what's described in the README to install this plugin? Or where should that be installed from?
I'm following the instructions for using the pre-compiled binaries (install commands shown below).
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.21.1
- CPU Architecture: x86_64
- OS (e.g., Linux): Ubuntu 20.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
```
conda install python=3.10
pip install nvidia-pyindex
pip install nvidia-tensorrt==8.4.3.1
pip install torch==1.12.1+cu116 --find-links https://download.pytorch.org/whl/torch/
pip install torch-tensorrt==1.2.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.2.0
```
- Are you using local sources or building from archives: Local CUDA and cuDNN
- Python version: 3.10
- CUDA version: 11.6
- GPU models and configuration: TitanV
|
https://github.com/pytorch/TensorRT/issues/1452
|
closed
|
[
"question",
"No Activity",
"component: plugins"
] | 2022-11-15T19:37:26Z
| 2023-06-10T00:02:28Z
| null |
collinmccarthy
|
huggingface/datasets
| 5,243
|
Download only split data
|
### Feature request
Is it possible to download only the data that I am requesting and not the entire dataset? I run out of disk spaceas it seems to download the entire dataset, instead of only the part needed.
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="test",
cache_dir="cache/path...",
use_auth_token=True,
download_config=DownloadConfig(delete_extracted='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')
)
### Motivation
efficiency improvement
### Your contribution
n/a
|
https://github.com/huggingface/datasets/issues/5243
|
open
|
[
"enhancement"
] | 2022-11-15T10:15:54Z
| 2025-02-25T14:47:03Z
| 7
|
capsabogdan
|
huggingface/diffusers
| 1,281
|
what is the meaning of parameter: "num_class_images"
|
What is the `num_class_images `parameter used for? I see that in some examples it is 50, sometimes it is 200. In the source code it is said that: "Minimal class images for prior preservation loss. If not have enough images, additional images will be sampled with class_prompt."
I still do not fully grasp it. For example if I have 20 images to train, what should I select this "`num_class_images`"?
|
https://github.com/huggingface/diffusers/issues/1281
|
closed
|
[] | 2022-11-14T18:32:22Z
| 2022-12-06T01:47:42Z
| null |
himmetozcan
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.