
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/datasets
| 5,665
|
Feature request: IterableDataset.push_to_hub
|
### Feature request
It'd be great to have a lazy push to hub, similar to the lazy loading we have with `IterableDataset`.
Suppose you'd like to filter [LAION](https://huggingface.co/datasets/laion/laion400m) based on certain conditions, but as LAION doesn't fit into your disk, you'd like to leverage streaming:
```
from datasets import load_dataset
dataset = load_dataset("laion/laion400m", streaming=True, split="train")
```
Then you could filter the dataset based on certain conditions:
```
filtered_dataset = dataset.filter(lambda example: example['HEIGHT'] > 400)
```
In order to persist this dataset and push it back to the hub, one currently needs to first load the entire filtered dataset on disk and then push:
```
from datasets import Dataset
Dataset.from_generator(filtered_dataset.__iter__).push_to_hub(...)
```
It would be great if we can instead lazy push to the data to the hub (basically stream the data to the hub), not being limited by our disk size:
```
filtered_dataset.push_to_hub("my-filtered-dataset")
```
### Motivation
This feature would be very useful for people that want to filter huge datasets without having to load the entire dataset or a filtered version thereof on their local disk.
### Your contribution
Happy to test out a PR :)
|
https://github.com/huggingface/datasets/issues/5665
|
closed
|
[
"enhancement"
] | 2023-03-23T09:53:04Z
| 2025-06-06T16:13:22Z
| 13
|
NielsRogge
|
pytorch/examples
| 1,128
|
Question about the difference between at::Tensor and torch::Tensor in PyTorch c++
|
I think the document of the PyTorch c++ library is not quite complete.
I noticed that there are some codes in the cppdoc use torch::Tensor, especially in the “Tensor Basics” and “Tensor Creation API”. I can’t find “torch::Tensor” in “Library API” but the “at::Tensor “.
I want to know is there any difference between them, and where can I find a more complete document about “PyTorch cpp”
|
https://github.com/pytorch/examples/issues/1128
|
closed
|
[] | 2023-03-23T06:59:46Z
| 2023-03-25T01:56:58Z
| 1
|
Ningreka
|
pytorch/pytorch
| 97,364
|
Confused as to where a script is.
|
According to pytorch/torch/_C/__init__.pyi.in there's supposed to be a torch/aten script but I can't find it, has this been phased out, because if it has is it in an older version of PyTorch? It's just without it, it completely stops one of the programs I downloaded from working, called Colossalai. It tries to call from aten.upsample_nearest2d_backward.vec and can't. According to ChatGPT the last version of PyTorch it saw, PyTorch 1.9.0 has aten in it, but both versions that you can download from the get started on the PyTorch website don't have it. Any recommendations would be great thanks.
|
https://github.com/pytorch/pytorch/issues/97364
|
closed
|
[] | 2023-03-22T18:04:44Z
| 2023-03-24T17:03:18Z
| null |
Shikamaru5
|
huggingface/datasets
| 5,660
|
integration with imbalanced-learn
|
### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I've looked online, asked gpt-4, but so far not making much progress.
### Your contribution
If I can get this working myself I can submit a PR with example code to go in the docs
|
https://github.com/huggingface/datasets/issues/5660
|
closed
|
[
"enhancement",
"wontfix"
] | 2023-03-22T11:05:17Z
| 2023-07-06T18:10:15Z
| 1
|
tansaku
|
pytorch/TensorRT
| 1,758
|
❓ [Question] The compilation process does not display errors, but the program does not continue...
|


With resnet it works fine, but with my model it compiles but doesn't output the result. I don't know if there is a problem with Input.
|
https://github.com/pytorch/TensorRT/issues/1758
|
closed
|
[
"question",
"No Activity"
] | 2023-03-22T02:30:28Z
| 2023-07-02T00:02:37Z
| null |
AllesOderNicht
|
huggingface/safetensors
| 202
|
`safetensor.torch.save_file()` throws `RuntimeError` - any recommended way to enforce?
|
was confronted with `RuntimeError: Some tensors share memory, this will lead to duplicate memory on disk and potential differences when loading them again`.
Can we explicitly disregard "**potential** differences"?
|
https://github.com/huggingface/safetensors/issues/202
|
closed
|
[] | 2023-03-21T21:24:38Z
| 2024-06-06T02:29:48Z
| 26
|
drahnreb
|
pytorch/text
| 2,125
|
How to install torchtext for cmake c++?
|
https://github.com/pytorch/text/issues/2125
|
open
|
[] | 2023-03-21T19:07:38Z
| 2023-06-06T22:01:16Z
| null |
Toocic
|
|
pytorch/data
| 1,104
|
Add documentation about custom Shuffle and Sharding DataPipe
|
### 📚 The doc issue
TorchData has a few special graph functions to handle Shuffle and Sharding DataPipe. But, we never document what is expected for those graph functions, which leads users to extend custom shuffle and sharding by diving into our code base.
We should add clear document about the expected methods attached to Shuffle or Sharding DataPipe.
This problem has been discussed in the #1081 as well, but I want to track documentation issue separately
### Suggest a potential alternative/fix
_No response_
|
https://github.com/meta-pytorch/data/issues/1104
|
open
|
[] | 2023-03-21T18:14:29Z
| 2023-03-21T21:47:32Z
| 0
|
ejguan
|
huggingface/optimum
| 906
|
Optimum export of whisper raises ValueError: There was an error while processing timestamps, we haven't found a timestamp as last token. Was WhisperTimeStampLogitsProcessor used?
|
### System Info
```shell
optimum: 1.7.1
Python: 3.8.3
transformers: 4.27.2
platform: Windows 10
```
### Who can help?
@philschmid @michaelbenayoun
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
1. Convert the model to ONNX:
```
python -m optimum.exporters.onnx --model openai/whisper-tiny.en whisper_onnx/
```
2. Due to [another bug in the pipeline function](https://github.com/huggingface/optimum/issues/905), you may need to comment out the lines in the generate function which raises an error for unused model kwargs:
https://github.com/huggingface/transformers/blob/48327c57182fdade7f7797d1eaad2d166de5c55b/src/transformers/generation/utils.py#L1104-L1108
3. Try to transcribe longer audio clip:
```python
import onnxruntime
from transformers import pipeline, AutoProcessor
from optimum.onnxruntime import ORTModelForSpeechSeq2Seq
whisper_model_name = './whisper_onnx/'
processor = AutoProcessor.from_pretrained(whisper_model_name)
session_options = onnxruntime.SessionOptions()
model_ort = ORTModelForSpeechSeq2Seq.from_pretrained(
whisper_model_name,
use_io_binding=True,
session_options=session_options
)
generator_ort = pipeline(
task="automatic-speech-recognition",
model=model_ort,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
)
out = generator_ort(
'https://xenova.github.io/transformers.js/assets/audio/ted_60.wav',
return_timestamps=True,
chunk_length_s=30,
stride_length_s=5
)
print(f'{out=}')
```
4. This raises the error:
```python
│ 878 │ │ if return_timestamps: │
│ 879 │ │ │ # Last token should always be timestamps, so there shouldn't be │
│ 880 │ │ │ # leftover │
│ ❱ 881 │ │ │ raise ValueError( │
│ 882 │ │ │ │ "There was an error while processing timestamps, we haven't found a time │
│ 883 │ │ │ │ " WhisperTimeStampLogitsProcessor used?" │
│ 884 │ │ │ ) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
ValueError: There was an error while processing timestamps, we haven't found a timestamp as last token. Was WhisperTimeStampLogitsProcessor used?
```
### Expected behavior
The program should act like the transformers version and not crash:
```python
from transformers import pipeline
transcriber = pipeline('automatic-speech-recognition', 'openai/whisper-tiny.en')
text = transcriber(
'https://xenova.github.io/transformers.js/assets/audio/ted_60.wav',
return_timestamps=True,
chunk_length_s=30,
stride_length_s=5
)
print(f'{text=}')
# outputs correctly
```
|
https://github.com/huggingface/optimum/issues/906
|
closed
|
[
"bug"
] | 2023-03-21T13:45:10Z
| 2023-03-24T18:26:17Z
| 3
|
xenova
|
pytorch/vision
| 7,438
|
Feedback on Video APIs
|
### Feedback request
With torchaudio's recent success in getting a clean FFMPEG build with a full support for FFMPEG 5 and 6 (something we can't replicate in torchvision easily yet), we are thinking of adopting their API and joining efforts to have a better support for video reading.
With that in mind, we were hoping to gather a some feedback from TV users who rely on video reader (or would like to use it but find it hard to do so):
1. What are your main pain points with our current API?
2. What do you wish was supported?
3. What are the most important features of a video IO for you?
We can't promise we'll support everything (of course), but we'd love to gather as much feedback as possible and get as much of it incorporated as possible.
|
https://github.com/pytorch/vision/issues/7438
|
open
|
[
"question",
"needs discussion",
"module: io",
"module: video"
] | 2023-03-21T13:20:36Z
| 2024-05-20T14:50:59Z
| null |
bjuncek
|
huggingface/datasets
| 5,653
|
Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented
|
### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_shards) explicitly says that it depends on `max_shard_size`, it should also mention `num_proc`.
### Environment info
datasets main document
|
https://github.com/huggingface/datasets/issues/5653
|
closed
|
[
"documentation",
"good first issue"
] | 2023-03-21T05:25:35Z
| 2023-03-24T16:36:23Z
| 1
|
RmZeta2718
|
pytorch/kineto
| 743
|
Questions about ROCm profiler
|
Hi @mwootton @aaronenyeshi ,
I found some interesting results for the models running on NVIDIA A100 and AMD MI210 GPUs. For example, I tested model resnext50_32x4d in [TorchBench](https://github.com/pytorch/benchmark). resnext50_32x4d obtains about 4.89X speedup on MI210. However, when I use PyTorch Profiler to profile models on MI210, the profile trace is strange. The total execution time of resnext50_32x4d is about 32ms on A100 and 7ms on MI210. But in the profile traces, the execution time is about 117ms on A100 and 106ms on MI210. I tested PyTorch 1.13.1 with CUDA 11.7 and ROCm 5.2. And the profile traces have been attached. Do you have any ideas?
Another question is that what do the GPU kernels do before the `Profiler Step` in ROCm profiling trace? These kernels take about 45s but no python calling context is shown in the trace view.
[resnext50.zip](https://github.com/pytorch/kineto/files/11021559/resnext50.zip)
|
https://github.com/pytorch/kineto/issues/743
|
closed
|
[
"question"
] | 2023-03-20T18:11:16Z
| 2023-10-24T17:39:57Z
| null |
FindHao
|
huggingface/dataset-viewer
| 965
|
Change the limit of started jobs? all kinds -> per kind
|
Currently, the `QUEUE_MAX_JOBS_PER_NAMESPACE` parameter limits the number of started jobs for the same namespace (user or organization). Maybe we should enforce this limit **per job kind** instead of **globally**.
|
https://github.com/huggingface/dataset-viewer/issues/965
|
closed
|
[
"question",
"improvement / optimization"
] | 2023-03-20T17:40:45Z
| 2023-04-29T15:03:57Z
| null |
severo
|
huggingface/dataset-viewer
| 964
|
Kill a job after a maximum duration?
|
The heartbeat already allows to detect if a job has crashed and to generate an error in that case. But some jobs can take forever, while not crashing. Should we set a maximum duration for the jobs, in order to save resources and free the queue? I imagine that we could automatically kill a job that takes more than 20 minutes to run, and insert an error in the cache.
|
https://github.com/huggingface/dataset-viewer/issues/964
|
closed
|
[
"question",
"improvement / optimization"
] | 2023-03-20T17:37:35Z
| 2023-03-23T13:16:33Z
| null |
severo
|
huggingface/optimum
| 903
|
Support transformers export to ggml format
|
### Feature request
ggml is gaining traction (e.g. llama.cpp has 10k stars), and it would be great to extend optimum.exporters and enable the community to export PyTorch/Tensorflow transformers weights to the format expected by ggml, having a more streamlined and single-entry export.
This could avoid duplicates as
https://github.com/ggerganov/llama.cpp/blob/master/convert-pth-to-ggml.py
https://github.com/ggerganov/whisper.cpp/blob/master/models/convert-pt-to-ggml.py
https://github.com/ggerganov/ggml/blob/master/examples/gpt-j/convert-h5-to-ggml.py
### Motivation
/
### Your contribution
I could have a look at it and submit a POC, cc @NouamaneTazi @ggerganov
Open to contribution as well, I don't expect it to be too much work
|
https://github.com/huggingface/optimum/issues/903
|
open
|
[
"feature-request",
"help wanted",
"exporters"
] | 2023-03-20T12:51:51Z
| 2023-07-03T04:51:18Z
| 2
|
fxmarty
|
pytorch/TensorRT
| 1,749
|
How to import after compilation
|

Show me that I don't have this package when I import torch_tensorrt
|
https://github.com/pytorch/TensorRT/issues/1749
|
closed
|
[
"question",
"No Activity"
] | 2023-03-20T10:35:37Z
| 2023-06-29T00:02:42Z
| null |
AllesOderNicht
|
pytorch/rl
| 977
|
[Feature Request] How to implement algorithms with multiple optimise phase like PPG?
|
## Motivation
I'm trying to implement [PPG](https://proceedings.mlr.press/v139/cobbe21a) and [DNA](https://arxiv.org/pdf/2206.10027.pdf) algorithms with torchrl, and both algorithms have more than one optimise phase in a single training loop. However, I suggest the [Trainer class](https://pytorch.org/rl/reference/trainers.html) doesn't support multiple loss modules or optimisers.
## Solution
I wish there will be an example code of how to implement the aforementioned algorithms, or alternatively, good guidance on how to customise the Trainer.
## Checklist
- [ x] I have checked that there is no similar issue in the repo
|
https://github.com/pytorch/rl/issues/977
|
closed
|
[
"enhancement"
] | 2023-03-20T04:57:59Z
| 2023-03-21T06:44:16Z
| null |
levilovearch
|
huggingface/datasets
| 5,650
|
load_dataset can't work correct with my image data
|
I have about 20000 images in my folder which divided into 4 folders with class names.
When i use load_dataset("my_folder_name", split="train") this function create dataset in which there are only 4 images, the remaining 19000 images were not added there. What is the problem and did not understand. Tried converting images and the like but absolutely nothing worked
|
https://github.com/huggingface/datasets/issues/5650
|
closed
|
[] | 2023-03-18T13:59:13Z
| 2023-07-24T14:13:02Z
| 21
|
WiNE-iNEFF
|
pytorch/pytorch
| 97,026
|
How to get list of all valid devices?
|
### 📚 The doc issue
`torch.testing.get_all_device_types()`
yields all valid devices on the current machine however unlike `torch._tensor_classes` , `torch.testing.get_all_dtypes()`, and `import typing; typing.get_args(torch.types.Device)`, there doesn't seem to be a comprehensive list of all valid device types, which gets listed when I force an error
```
torch.devcie('asdasjdfas')
RuntimeError: Expected one of cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, privateuseone device type at start of device string: asdasjdfas
```
### Suggest a potential alternative/fix
```
torch._device_names = cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, privateuseone
```
cc @svekars @carljparker
|
https://github.com/pytorch/pytorch/issues/97026
|
open
|
[
"module: docs",
"triaged"
] | 2023-03-17T15:37:00Z
| 2023-03-20T23:49:13Z
| null |
dsm-72
|
pytorch/kineto
| 742
|
How can I get detailed aten::op name like add.Tensor/abs.out?
|
I wonder if I could trace detailed op name like add.Tensor、add.Scalar、sin.out、abs.out
Currently the profiler only gives me add/sin/abs, etc.
Is there a method to acquire detailed dispatched op name?
|
https://github.com/pytorch/kineto/issues/742
|
closed
|
[
"question"
] | 2023-03-17T05:25:42Z
| 2024-04-23T15:31:20Z
| null |
Hurray0
|
pytorch/cppdocs
| 16
|
How to set up pytorch for c++ (with g++) via commandline not cmake
|
I have a Lapop with a nvidia graphicscard and I'm trying to use pytorch for cuda with g++. But i couldn't find any good information about dependecies e.g and my compiler always trohws errors, I'm currently using this command I found on the internet: "g++ -std=c++14 main.cpp -I ${TORCH_DIR}/include/torch/csrc/api/include/ -I ${TORCH_DIR}/include/ -L ${TORCH_DIR}/lib/ -L /usr/local/cuda/lib64 -L /usr/local/cuda/nvvm/lib64 -ltorch -lc10 -lc10_cuda -lnvrtc -lcudart_static -ldl -lrt -pthread -o out", but it just says: "torch/torch.h: file not found"
|
https://github.com/pytorch/cppdocs/issues/16
|
closed
|
[] | 2023-03-13T21:15:08Z
| 2023-03-18T22:36:04Z
| null |
usr577
|
huggingface/dataset-viewer
| 924
|
Support webhook version 3?
|
The Hub provides different formats for the webhooks. The current version, used in the public feature (https://huggingface.co/docs/hub/webhooks) is version 3. Maybe we should support version 3 soon.
|
https://github.com/huggingface/dataset-viewer/issues/924
|
closed
|
[
"question",
"refactoring / architecture"
] | 2023-03-13T13:39:59Z
| 2023-04-21T15:03:54Z
| null |
severo
|
huggingface/datasets
| 5,632
|
Dataset cannot convert too large dictionnary
|
### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of my dictionnary, and then I have the error "OverflowError: Python int too large to convert to C long".
Do you know how to solve this problem?
Unfortunately I cannot give a reproductible code because I cannot share a so large file, but you can find the code below (it's a test on only a part of the validation data ~10Go, but it's already the case).
Thank you!
### Steps to reproduce the bug
SAVE_DIR = './data/'
features = h5py.File(SAVE_DIR+'features.hdf5','r')
valid_data = features["validation"]["data/features"]
v_array_values = [np.float32(item[()]) for item in valid_data.values()]
for i in range(len(v_array_values)):
v_array_values[i] = v_array_values[i].round(decimals=5)
dict_valid = datasets.Dataset.from_dict({'input_values': v_array_values})
### Expected behavior
The code is expected to give me a Huggingface dataset.
### Environment info
python: 3.8.15
numpy: 1.22.3
datasets: 2.3.2
pyarrow: 8.0.0
|
https://github.com/huggingface/datasets/issues/5632
|
open
|
[] | 2023-03-13T10:14:40Z
| 2023-03-16T15:28:57Z
| 1
|
MaraLac
|
pytorch/pytorch
| 96,655
|
What is the state of support for AD of BatchNormalization and DropOut layers?
|
I have come to this issue from this post.
https://pytorch.org/functorch/stable/notebooks/per_sample_grads.html
## Background
What I am doing requires per-sample gradient (in fact, I migrated from TF, so I do not have much experience with pytorch, but I have a sufficient understanding of NN training).
When reading the post, I could not figure out whether functorch's `vmap` supports AD function of BN and DropOut layers.
In my understanding, these layers are relatively popular.
Because they are not pure functions (different behaviors in training and testing modes), and also not pure (e.g., BN layer accumulates the average across the different forward pass in training mode), which makes me wonder:
## My questions
1. Does functorch's `vmap` support AD function of BN and DropOut layers?
2. If yes, how does it do that?
I tried searching for issues with BatchNormalization or DropOut keywords, but the results were fragmented and I still do not know what is the current state now.
Opacus says that only `EmbeddingBag` is not supported (https://github.com/pytorch/opacus/blob/5aa378ea98df9caf8ca1987ee4d636219267d17e/opacus/grad_sample/functorch.py#L22).
Could anyone tell me the answer?
If possible, updating the docs to clarify the supports for these layers would be great.
Thank you very much.
cc @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
|
https://github.com/pytorch/pytorch/issues/96655
|
closed
|
[
"triaged",
"module: functorch"
] | 2023-03-10T01:47:20Z
| 2023-03-15T16:02:05Z
| null |
tranvansang
|
huggingface/ethics-education
| 1
|
What is AI Ethics?
|
With the amount of hype around things like ChatGPT, AI art, etc., there are a lot of misunderstandings being propagated through the media! Additionally, many people are not aware of the ethical impacts of AI, and they're even less aware about the work that folks in academia + industry are doing to ensure that AI systems are being developed and deployed in ways that are equitable, sustainable, etc.
This is a great opportunity for us to put together a simple explainer, with some very high-level information aimed at non-technical people, that runs through what AI Ethics is and why people should care. Format-wise, I'm aiming towards something like a light blog post.
More specifically, it would be really cool to have something that ties into the categories outlined on [hf.co/ethics](https://hf.co/ethics). A more detailed description is available here on [Google Docs](https://docs.google.com/document/d/19Ga4PX0xbRxMlAwoK-q7Xjuy9B9Z0jFvFuVYdhfcKiY/edit).
If you're interested in helping out with this, a great first step would be to collect some resources and start outlining a bullet-point draft on a Google Doc that I can share with you 😄
I've also got plans for the actual distribution of it (e.g. design-wise, distribution), which I'll follow up with soon.
|
https://github.com/huggingface/ethics-education/issues/1
|
open
|
[
"help wanted",
"explainer",
"audience: non-technical"
] | 2023-03-09T20:58:02Z
| 2023-03-17T14:50:39Z
| null |
NimaBoscarino
|
huggingface/diffusers
| 2,633
|
Asymmetric tiling
|
Hello. I'm trying to achieve tiling asymmetrically using Diffusers, in a similar fashion to the asymmetric tiling in Automatic1111's extension https://github.com/tjm35/asymmetric-tiling-sd-webui.
My understanding is that I must traverse all layers to alter the padding, in my case circular in X and constant in Y, but I would love to get advice on how to make a such change to the conv2d system in DIffusers.
Your advice is highly appreciated, as it may also help others down the road facing the same need.
|
https://github.com/huggingface/diffusers/issues/2633
|
closed
|
[
"good first issue",
"question"
] | 2023-03-09T19:09:34Z
| 2025-07-29T08:48:27Z
| null |
alejobrainz
|
huggingface/optimum
| 874
|
Assistance exporting git-large to ONNX
|
Hello! I am looking to export an image captioning Hugging Face model to ONNX (specifically I was playing with the [git-large](https://huggingface.co/microsoft/git-large) model but if anyone knows of one that might be easier to deal with in terms of exporting that is great too)
I'm trying to follow [these](https://huggingface.co/docs/transformers/serialization#exporting-a-model-for-an-unsupported-architecture) instructions for exporting an unsupported architecture, and I am a bit stuck on figuring out what base class to inherit from and how to define the custom ONNX Configuration since I'm not sure what examples to look at (the model card says this is a transformer decoder model, but it looks like i that it has both encoding and decoding so I am a bit confused)
I also found [this](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb) notebook but I am again not sure if it would work with this sort of model.
Any comments, advice, or suggestions would be so helpful -- I am feeling a bit stuck with how to proceed in deploying this model in the school capstone project I'm working on. In a worst-case scenario, can I use `from_pretrained` in my application?
|
https://github.com/huggingface/optimum/issues/874
|
closed
|
[
"Stale"
] | 2023-03-09T18:25:57Z
| 2025-06-22T02:17:24Z
| 3
|
gracemcgrath
|
huggingface/safetensors
| 190
|
Rust save ndarray using safetensors
|
I've been loving this library!
I have a question, how can I save an ndarray using safetensors?
https://docs.rs/ndarray/latest/ndarray/
For context: I am preprocessing data in rust and would like to then load it in python to do machine learning with pytorch.
|
https://github.com/huggingface/safetensors/issues/190
|
closed
|
[
"Stale"
] | 2023-03-08T22:29:11Z
| 2024-01-10T16:48:07Z
| 7
|
StrongChris
|
huggingface/optimum
| 867
|
Auto-detect framework for large models at ONNX export
|
### System Info
- `transformers` version: 4.26.1
- Platform: Linux-4.4.0-142-generic-x86_64-with-glibc2.23
- Python version: 3.9.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger @muellerzr
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import torch
import torch.nn as nn
from transformers import GPT2Config, GPT2Tokenizer, GPT2Model
num_attention_heads = 40
num_layers = 40
hidden_size = 5120
configuration = GPT2Config(
n_embd=hidden_size,
n_layer=num_layers,
n_head=num_attention_heads
)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2Model(configuration)
tokenizer.save_pretrained('gpt2_checkpoint')
model.save_pretrained('gpt2_checkpoint')
```
```shell
python -m transformers.onnx --model=gpt2_checkpoint onnx/
```
### Expected behavior
I created a GPT2 with a parameter volume of 13B. Just for testing, refer to https://huggingface.co/docs/transformers/serialization, I save it to gpt2_checkpoint. Then convert it to onnx using transformers.onnx. Due to the large amount of parameters, `save_pretrained` saves the model as *-0001.bin, *-0002.bin and so on. Later, when running ‘python -m transformers.onnx --model=gpt2_checkpoint onnx/’, an error `FileNotFoundError: Cannot determine framework from given checkpoint location. There should be a pytorch_model.bin for PyTorch or tf_model.h5 for TensorFlow.` So, I would like to ask how to convert a model with a large number of parameters into onnx for inference.
|
https://github.com/huggingface/optimum/issues/867
|
closed
|
[
"feature-request",
"onnx"
] | 2023-03-08T03:43:53Z
| 2023-03-16T15:52:39Z
| 3
|
WangYizhang01
|
pytorch/TensorRT
| 1,730
|
❓ [Question] Does torch-tensorrt support seq2seq models?
|
## ❓ Question
Does torch-tensorrt support seq2seq models? Are there any documentation/examples?
## What you have already tried
Previously, when I tried to use TensorRT, I need to convert the original torch seq2seq model to 2 onnx files, then convert them separately to TensorRT using trtexec. Not sure if this has changed with torch-tensorrt.
Thanks!
|
https://github.com/pytorch/TensorRT/issues/1730
|
closed
|
[
"question",
"No Activity"
] | 2023-03-08T00:51:31Z
| 2023-06-19T00:02:34Z
| null |
brevity2021
|
pytorch/TensorRT
| 1,727
|
complie model failed
|
## compile model failed with torchtrt-fp32 opt
#### ERROR INFO
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Tensor DataType is determined at build time for tensors not marked as input or output.
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 4: [graphShapeAnalyzer.cpp::analyzeShapes::1285] Error Code 4: Miscellaneous (IShuffleLayer (Unnamed Layer* 84) [Shuffle]: reshape changes volume. Reshaping [1,512,1,(+ (CEIL_DIV (+ (# 3 (SHAPE input_0)) -4) 4) 1)] to [1,512,0].)
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 2: [builder.cpp::buildSerializedNetwork::609] Error Code 2: Internal Error (Assertion enginePtr != nullptr failed. )
terminate called after throwing an instance of 'torch_tensorrt::Error'
what(): [Error thrown at core/conversion/conversionctx/ConversionCtx.cpp:147] Building serialized network failed in TensorRT
Aborted
code:
std::string min_input_shape = "1 3 32 32";
std::string opt_input_shape = "1 3 32 512";
std::string max_input_shape = "1 3 32 1024";
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.11.0):
- CPU Architecture: x86_64
- OS (Linux):
- How you installed PyTorch (`libtorch`):
- Python version:3.8
- CUDA version:11.3
|
https://github.com/pytorch/TensorRT/issues/1727
|
closed
|
[
"question",
"component: conversion",
"No Activity"
] | 2023-03-07T04:09:45Z
| 2023-06-18T00:02:24Z
| null |
f291400
|
pytorch/audio
| 3,153
|
Google colab notebook pointing to PyTorch 1.13.1
|
### 📚 The doc issue
When I open https://pytorch.org/audio/main/tutorials/audio_data_augmentation_tutorial.html in google colab and try running the notebook, I see that the PyTorch version is 1.13.1
### Suggest a potential alternative/fix
_No response_
|
https://github.com/pytorch/audio/issues/3153
|
closed
|
[
"question",
"triaged"
] | 2023-03-07T02:19:06Z
| 2023-03-07T15:41:03Z
| null |
agunapal
|
huggingface/datasets
| 5,615
|
IterableDataset.add_column is unable to accept another IterableDataset as a parameter.
|
### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
I wrote codes below to make it.
```py
def add_column(dataset: IterableDataset, name: str, add_dataset: IterableDataset, key: str) -> IterableDataset:
iter_add_dataset = iter(add_dataset)
def add_column_fn(example):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: next(iter_add_dataset)[key]}
return dataset.map(add_column_fn)
```
Is there other way to do it? Or is it intended?
### Steps to reproduce the bug
Thie codes below occurs `NotImplementedError`
```py
from datasets import IterableDataset
def gen(num):
yield {f"col{num}": 1}
yield {f"col{num}": 2}
yield {f"col{num}": 3}
ids1 = IterableDataset.from_generator(gen, gen_kwargs={"num": 1})
ids2 = IterableDataset.from_generator(gen, gen_kwargs={"num": 2})
new_ids = ids1.add_column("new_col", ids1)
for row in new_ids:
print(row)
```
### Expected behavior
`IterableDataset.add_column` is able to task `IterableDataset` and lazy evaluated values as a parameter since IterableDataset is lazy evalued.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-3.10.0-1160.36.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.7
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
https://github.com/huggingface/datasets/issues/5615
|
closed
|
[
"wontfix"
] | 2023-03-07T01:52:00Z
| 2023-03-09T15:24:05Z
| 1
|
zsaladin
|
huggingface/safetensors
| 188
|
How to extract weights from onnx to safetensors
|
How to extract weights from onnx to safetensors in rust?
|
https://github.com/huggingface/safetensors/issues/188
|
closed
|
[] | 2023-03-06T09:21:31Z
| 2023-03-07T14:23:16Z
| 2
|
oovm
|
huggingface/datasets
| 5,609
|
`load_from_disk` vs `load_dataset` performance.
|
### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_disk` and then use `load_from_disk` to load the filtered version.
The performance of these two approaches is wildly different:
* Using `load_dataset` takes about 20 seconds to load the dataset, and a few seconds to re-filter (thanks to the brilliant filter/map caching)
* Using `load_from_disk` takes 14 minutes! And the second time I tried, the session just crashed (on a machine with 32GB of RAM)
I don't know if you'd call this a bug, but it seems like there shouldn't need to be two methods to load from disk, or that they should not take such wildly different amounts of time, or that one should not crash. Or maybe that the docs could offer some guidance about when to pick which method and why two methods exist, or just how do most people do it?
Something I couldn't work out from reading the docs was this: can I modify a dataset from the hub, save it (locally) and use `load_dataset` to load it? This [post seemed to suggest that the answer is no](https://discuss.huggingface.co/t/save-and-load-datasets/9260).
### Steps to reproduce the bug
See above
### Expected behavior
Load times should be about the same.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
https://github.com/huggingface/datasets/issues/5609
|
open
|
[] | 2023-03-05T05:27:15Z
| 2023-07-13T18:48:05Z
| 4
|
davidgilbertson
|
huggingface/sentence-transformers
| 1,856
|
What it is the ideal sentence size to train with TSDAE?
|
I have an unlabeled data that contains 80k texts, with about 250 tokens on average(with bert-base-multilingual-uncased tokenizer). I want to pre-train the model on my dataset, but I'm not sure if the texts are too large. It's possible to break in small sentences, but I'm afraid that some sentences lose context.
What it is the ideal sentence size to train with TSDAE?
|
https://github.com/huggingface/sentence-transformers/issues/1856
|
open
|
[] | 2023-03-04T21:16:14Z
| 2023-03-04T21:16:14Z
| null |
Diegobm99
|
huggingface/transformers
| 21,950
|
auto_find_batch_size should say what batch size it is using
|
### Feature request
When using `auto_find_batch_size=True` in the trainer I believe it identifies the right batch size but then it doesn't log it to the console anywhere?
It would be good if it could log what batch size it is using?
### Motivation
I'd like to know what batch size it is using because then I will know roughly how big a batch can fit in memory - this info would be useful elsewhere.
### Your contribution
N/A
|
https://github.com/huggingface/transformers/issues/21950
|
closed
|
[] | 2023-03-04T08:53:25Z
| 2023-06-28T15:03:39Z
| null |
p-christ
|
huggingface/datasets
| 5,604
|
Problems with downloading The Pile
|
### Describe the bug
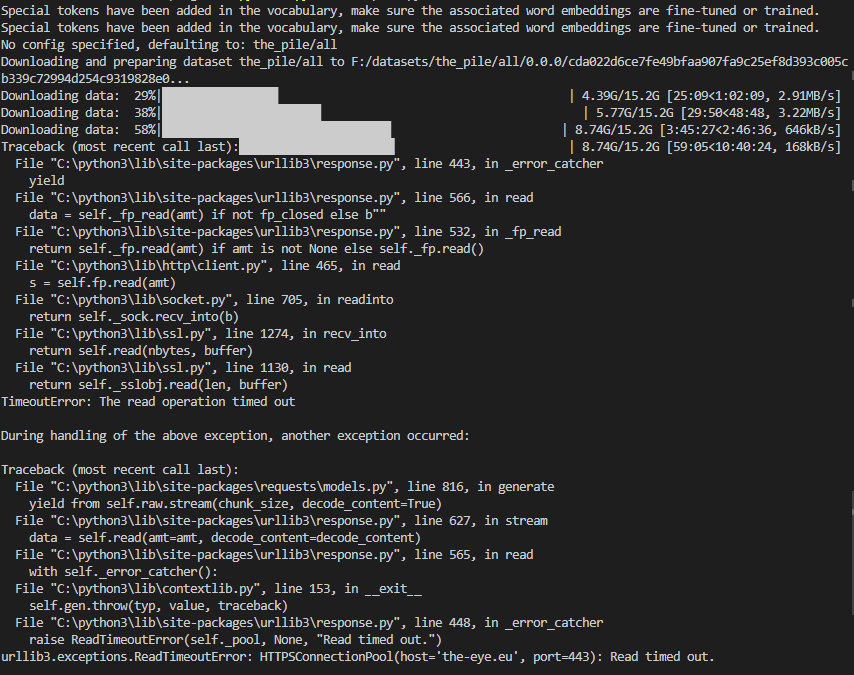
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
Here are the downloaded files:
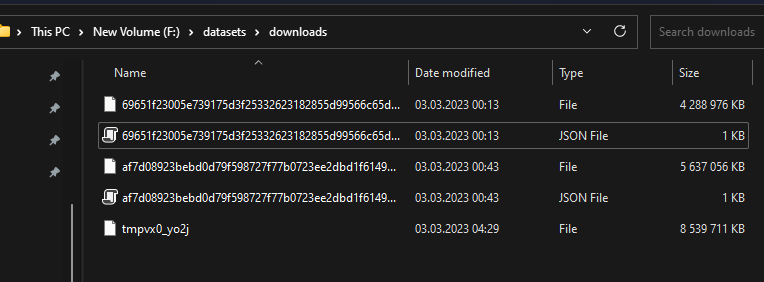
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/5604
|
closed
|
[] | 2023-03-03T09:52:08Z
| 2023-10-14T02:15:52Z
| 7
|
sentialx
|
huggingface/optimum
| 842
|
Auto-TensorRT engine compilation, or improved documentation for it
|
### Feature request
For decoder models with cache, it can be painful to manually compile the TensorRT engine as ONNX Runtime does not give options to specify shapes. The engine build could maybe be done automatically.
The current doc is only for `use_cache=False`, which is not very interesting. It could be improved to show how to pre-build the TRT with use_cache=True.
References:
https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/gpu#tensorrt-engine-build-and-warmup
https://github.com/microsoft/onnxruntime/issues/13559
### Motivation
TensorRT is fast
### Your contribution
will work on it sometime
|
https://github.com/huggingface/optimum/issues/842
|
open
|
[
"feature-request",
"onnxruntime"
] | 2023-03-02T13:50:17Z
| 2023-05-31T12:47:40Z
| 4
|
fxmarty
|
pytorch/tutorials
| 2,230
|
model.train(False) affects gradient tracking?
|
In this tutorial here it says in the comment that "# We don't need gradients on to do reporting". From what I understand the train flag only affects layers such as dropout and batch-normalization. Does it also affect gradient calculations, or is this comment wrong?
https://github.com/pytorch/tutorials/blob/6bd30cf214bf541a1c5d35cc45d10a381f57af1b/beginner_source/introyt/trainingyt.py#L293
cc @suraj813
|
https://github.com/pytorch/tutorials/issues/2230
|
closed
|
[
"question",
"intro",
"docathon-h1-2023",
"easy"
] | 2023-03-02T12:09:13Z
| 2023-06-01T01:19:02Z
| null |
MaverickMeerkat
|
huggingface/datasets
| 5,600
|
Dataloader getitem not working for DreamboothDatasets
|
### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset to load some images
2- error after loading when trying to visualise the images
### Expected behavior
I was expecting a numpy array of the image
### Environment info
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
|
https://github.com/huggingface/datasets/issues/5600
|
closed
|
[] | 2023-03-02T11:00:27Z
| 2023-03-13T17:59:35Z
| 1
|
salahiguiliz
|
huggingface/trl
| 180
|
what is AutoModelForCausalLMWithValueHead?
|
trl use `AutoModelForCausalLMWithValueHead`,which is base_model(eg: GPT2LMHeadModel) + fc layer,but I can't understand why need a fc head layer?
|
https://github.com/huggingface/trl/issues/180
|
closed
|
[] | 2023-02-28T07:46:49Z
| 2025-02-21T11:29:04Z
| null |
akk-123
|
pytorch/serve
| 2,162
|
How to run torchserver without log printing?
|
How to run torchserver without log printing?I didn't see the relevant command line. Could someone tell me, thank you!
|
https://github.com/pytorch/serve/issues/2162
|
closed
|
[
"triaged",
"support"
] | 2023-02-28T02:22:02Z
| 2023-03-09T20:06:37Z
| null |
mqy9787
|
huggingface/datasets
| 5,585
|
Cache is not transportable
|
### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I'm hoping that I can just copy/paste the cache files, but I notice that a lot of the file names start with the path name, e.g. `_home_davidg_.cache_huggingface_datasets_conll2003_default-451...98.lock` where `home/davidg` is where the cache is in WSL.
This seems to suggest that the cache is not portable/cannot be centralised or shared. Is this the case, or are the files that start with path names not integral to the caching mechanism? Because copying the cache files _seems_ to work, but I'm not filled with confidence that something isn't going to break.
A related issue, when trying to load a dataset that should come from cache (running in WSL, pointing to cache on the Windows host) it seemed to work fine, but it still uses a WSL directory for `.cache\huggingface\modules\datasets_modules`. I see nothing in the docs about this, or how to point it to a different place.
I have asked a related question on the forum: https://discuss.huggingface.co/t/is-datasets-cache-operating-system-agnostic/32656
### Steps to reproduce the bug
View the cache directory in WSL/Windows.
### Expected behavior
Cache can be shared between (virtual) machines and be transportable.
It would be nice to have a simple way to say "Dear Hugging Face packages, please put ALL your cache in `blah/de/blah`" and have all the Hugging Face packages respect that single location.
### Environment info
```
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
- ```
|
https://github.com/huggingface/datasets/issues/5585
|
closed
|
[] | 2023-02-28T00:53:06Z
| 2023-02-28T21:26:52Z
| 2
|
davidgilbertson
|
pytorch/examples
| 1,121
|
About fast_neural_style
|
How many rounds did you train in the fast neural style transfer experiment? I operate according to your steps, but the effect of the model I trained is not as good as the model you provided, and why is the model file I trained less than the file you provided by 3kb? I would like to know the reason and look forward to your reply!
|
https://github.com/pytorch/examples/issues/1121
|
closed
|
[
"help wanted"
] | 2023-02-27T15:53:38Z
| 2023-08-17T09:26:17Z
| 2
|
TOUBH
|
pytorch/functorch
| 1,113
|
How to get the jacobian matrix in GCNs?
|
Hi, I'm trying to use `jacrev` to get the jacobians in graph convolution networks, but it seems like I've called the function incorrectly.
```python
import torch.nn.functional as F
import functorch
import torch_geometric
from torch_geometric.data import Data
class GCN(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
torch.manual_seed(12345)
self.conv1 = torch_geometric.nn.GCNConv(input_dim, hidden_dim, aggr='add')
self.conv2 = torch_geometric.nn.GCNConv(hidden_dim, output_dim, aggr='add')
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
adj_matrix = torch.ones(3,3)
edge_index = adj_matrix .nonzero().t().contiguous()
gcn = GCN(input_dim=5, hidden_dim=64, output_dim=5)
N = (128,3, 5)
x =torch.randn(N, requires_grad=True) # batch_size:128, node_num:10 , node_feature: 5
graph = Data(x=x, edge_index=edge_index)
gcn_out = gcn(graph.x, graph.edge_index)
```
Then I try to compute the jacobians of the input data `x` based on the tutorial,
```python
jacobian = functorch.vmap(functorch.jacrev(gcn))(graph.x, graph.edge_index)
```
and get the following error message:
```python
ValueError: vmap: Expected all tensors to have the same size in the mapped dimension, got sizes [128, 2] for the mapped dimension
```
|
https://github.com/pytorch/functorch/issues/1113
|
open
|
[] | 2023-02-27T13:23:50Z
| 2023-02-27T13:24:15Z
| null |
pcheng2
|
huggingface/dataset-viewer
| 857
|
Contribute to https://github.com/huggingface/huggingface.js?
|
https://github.com/huggingface/huggingface.js is a JS client for the Hub and inference. We could propose to add a client for the datasets-server.
|
https://github.com/huggingface/dataset-viewer/issues/857
|
closed
|
[
"question"
] | 2023-02-27T12:27:43Z
| 2023-04-08T15:04:09Z
| null |
severo
|
huggingface/dataset-viewer
| 852
|
Store the parquet metadata in their own file?
|
See https://github.com/huggingface/datasets/issues/5380#issuecomment-1444281177
> From looking at Arrow's source, it seems Parquet stores metadata at the end, which means one needs to iterate over a Parquet file's data before accessing its metadata. We could mimic Dask to address this "limitation" and write metadata in a _metadata/_common_metadata file in to_parquet/push_to_hub, which we could then use to optimize reads (if present). Plus, it's handy that PyArrow can also parse these metadata files.
|
https://github.com/huggingface/dataset-viewer/issues/852
|
closed
|
[
"question"
] | 2023-02-27T08:29:12Z
| 2023-05-01T15:04:07Z
| null |
severo
|
pytorch/functorch
| 1,112
|
Error about using a grad transform with in-place operation is inconsistent with and without DDP
|
Hi,
I was using `torch.func` in pytorch 2.0 to compute the Hessian-vector product of a neural network.
I first used `torch.func.functional_call` to define a functional version of the neural network model, and then proceeded to use `torch.func.jvp` and `torch.func.grad` to compute the hvp.
The above works when I was using one gpu without parallel processing. However, when I wrapped the model with Distributed Data Parallel (DDP), it gave the following error:
`*** RuntimeError: During a grad (vjp, jvp, grad, etc) transform, the function provided attempted to call in-place operation (aten::copy_) that would mutate a captured Tensor. This is not supported; please rewrite the function being transformed to explicitly accept the mutated Tensor(s) as inputs.`
I am confused about this error, because if there were indeed such in-place operations (which I couldn't find in my model.forward() code), I'd expect this error to occur regardless of DDP. Given the inconsistent behaviour, can I still trust the hvp result when I wasn't using DDP?
My torch version: is `2.0.0.dev20230119+cu117`
|
https://github.com/pytorch/functorch/issues/1112
|
open
|
[] | 2023-02-24T23:09:30Z
| 2023-03-14T13:56:55Z
| 1
|
XuchanBao
|
huggingface/datasets
| 5,570
|
load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub
|
### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet = load_dataset("imagenet-1k", split="train", streaming=True)
FileNotFoundError: Couldn't find a dataset script at /content/imagenet-1k/imagenet-1k.py or any data file in the same directory. Couldn't find 'imagenet-1k' on the Hugging Face Hub either: FileNotFoundError: Dataset 'imagenet-1k' doesn't exist on the Hub
```
tested on a colab notebook.
### Expected behavior
I would expect a specific error indicating that I have to login then accept the dataset licence.
I find this bug very relevant as this code is on a guide on the [Huggingface documentation for Datasets](https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable)
### Environment info
google colab cpu-only instance
|
https://github.com/huggingface/datasets/issues/5570
|
closed
|
[] | 2023-02-23T16:44:32Z
| 2023-07-24T15:18:50Z
| 2
|
buoi
|
huggingface/optimum
| 810
|
ORTTrainer using DataParallel instead of DistributedDataParallel causes downstream errors
|
### System Info
```shell
optimum 1.6.4
python 3.8
```
### Who can help?
@JingyaHuang @echarlaix
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
FROM mcr.microsoft.com/azureml/aifx/stable-ubuntu2004-cu117-py38-torch1131:latest
RUN git clone https://github.com/huggingface/optimum.git && cd optimum && python setup.py install
RUN python examples/onnxruntime/training/summarization/run_summarization.py --model_name_or_path t5-small --do_train --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --predict_with_generate --fp16
### Expected behavior
This is expected to run t5-small with ONNXRuntime, however the model defaults to pytorch execution. I believe this is due to optimum's usage of torch.nn.DataParallel in trainer.py [here](https://github.com/huggingface/optimum/blob/dbb43fb622727f2206fa2a2b3b479f6efe82945b/optimum/onnxruntime/trainer.py#L1576) which is incompatible with ONNXRuntime.
PyTorch's [official documentation](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) recommends using DistributedDataParallel over DataParallel for multi-gpu training. Is there a reason why DataParallel is used here and, if not, can it be changed to use DistributedDataParallel?
|
https://github.com/huggingface/optimum/issues/810
|
closed
|
[
"bug"
] | 2023-02-22T22:15:41Z
| 2023-03-19T19:01:32Z
| 2
|
prathikr
|
huggingface/optimum
| 809
|
Better Transformer with QA pipeline returns padding issue
|
### System Info
```shell
Optimum version: 1.6.4
Platform: Linux
Python version: 3.10
Transformers version: 4.26.1
Accelerate version: 0.16.0
Torch version: 1.13.1+cu117
```
### Who can help?
@philschmid
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Notebook link to reproduce the same: https://colab.research.google.com/drive/1g-EzDtvEMIO1VjYBFJDlYWuKoBjaHxDd?usp=sharing
Code snippet:
```python
from optimum.pipelines import pipeline
qa_model = "bert-large-uncased-whole-word-masking-finetuned-squad"
reader = pipeline("question-answering", qa_model, accelerator="bettertransformer")
reader(question=["What is your name?", "What do you like to do in your free time?"] * 10, context=["My name is Bookworm and I like to read books."] * 20, batch_size=16)
```
Error persists on both cpu and cuda device. Works as expected if batches passed in require no padding.
Error received:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/question_answering.py", line 393, in __call__
return super().__call__(examples, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1065, in __call__
outputs = [output for output in final_iterator]
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1065, in <listcomp>
outputs = [output for output in final_iterator]
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 124, in __next__
item = next(self.iterator)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 266, in __next__
processed = self.infer(next(self.iterator), **self.params)
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 628, in __next__
data = self._next_data()
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 671, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
return self.collate_fn(data)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 169, in inner
padded[key] = _pad(items, key, _padding_value, padding_side)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 92, in _pad
tensor = torch.zeros((batch_size, max_length), dtype=dtype) + padding_value
TypeError: unsupported operand type(s) for +: 'Tensor' and 'NoneType'
```
The system versions mentioned above are from my server setup although it seems reproducible from the notebook with different torch/cuda installations!
### Expected behavior
Expected behavior is to produce correct results without error.
|
https://github.com/huggingface/optimum/issues/809
|
closed
|
[
"bug"
] | 2023-02-22T18:51:23Z
| 2023-02-27T11:29:09Z
| 2
|
vrdn-23
|
pytorch/text
| 2,072
|
how to build torchtext in cpp wiht cmake?
|
HI, guys, I want to use torchtext with liborch in cpp like cmake build torchvision in cpp, but I has try ,but meet some error in windows system,I don't know why some dependency subdirectory is empty, how to build it then include with cpp ?
thanks
````
-- Building for: Visual Studio 17 2022
-- Selecting Windows SDK version 10.0.20348.0 to target Windows 10.0.22621.
-- The C compiler identification is MSVC 19.34.31942.0
-- The CXX compiler identification is MSVC 19.34.31942.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: C:/Program Files/Microsoft Visual Studio/2022/Professional/VC/Tools/MSVC/14.34.31933/bin/Hostx64/x64/cl.exe - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: C:/Program Files/Microsoft Visual Studio/2022/Professional/VC/Tools/MSVC/14.34.31933/bin/Hostx64/x64/cl.exe - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
CMake Error at third_party/CMakeLists.txt:8 (add_subdirectory):
The source directory
C:/Apps/text-main/third_party/re2
does not contain a CMakeLists.txt file.
CMake Error at third_party/CMakeLists.txt:9 (add_subdirectory):
The source directory
C:/Apps/text-main/third_party/double-conversion
does not contain a CMakeLists.txt file.
CMake Error at third_party/CMakeLists.txt:10 (add_subdirectory):
The source directory
C:/Apps/text-main/third_party/sentencepiece
does not contain a CMakeLists.txt file.
CMake Error at third_party/CMakeLists.txt:11 (add_subdirectory):
The source directory
C:/Apps/text-main/third_party/utf8proc
does not contain a CMakeLists.txt file.
-- Configuring incomplete, errors occurred!
PS C:\Apps\text-main\build>
````
|
https://github.com/pytorch/text/issues/2072
|
closed
|
[] | 2023-02-22T15:33:37Z
| 2023-02-23T02:53:05Z
| null |
mullerhai
|
pytorch/xla
| 4,666
|
Got error when build xla from source
|
Hi! I am trying to build xla wheel by following the setup guide here: https://github.com/pytorch/xla/blob/master/CONTRIBUTING.md
I skipped building torch by `pip install torch==1.13.0` into virtualenv, and then run `env BUILD_CPP_TESTS=0 python setup.py bdist_wheel` under pytorch/xla. I got the following error:
```bash
ERROR: /home/ubuntu/pytorch/xla/third_party/tensorflow/tensorflow/compiler/xla/xla_client/BUILD:42:20: Linking tensorflow/compiler/xla/xla_client/libxla_computation_client.so failed: (Exit 1): gcc failed: error executing command /usr/bin/gcc @bazel-out/k8-opt/bin/tensorflow/compiler/xla/xla_client/libxla_computation_client.so-2.params
bazel-out/k8-opt/bin/tensorflow/core/profiler/convert/_objs/xplane_to_tools_data/xplane_to_tools_data.pic.o:xplane_to_tools_data.cc:function tensorflow::profiler::ConvertMultiXSpacesToToolData(tensorflow::profiler::SessionSnapshot const&, std::basic_string_view<char, std::char_traits<char> >, absl::lts_20220623::flat_hash_map<std::string, std::variant<int, std::string>, absl::lts_20220623::container_internal::StringHash, absl::lts_20220623::container_internal::StringEq, std::allocator<std::pair<std::string const, std::variant<int, std::string> > > > const&): error: undefined reference to 'tensorflow::profiler::ConvertHloProtoToToolData(tensorflow::profiler::SessionSnapshot const&, std::basic_string_view<char, std::char_traits<char> >, absl::lts_20220623::flat_hash_map<std::string, std::variant<int, std::string>, absl::lts_20220623::container_internal::StringHash, absl::lts_20220623::container_internal::StringEq, std::allocator<std::pair<std::string const, std::variant<int, std::string> > > > const&)'
collect2: error: ld returned 1 exit status
Target //tensorflow/compiler/xla/xla_client:libxla_computation_client.so failed to build
Use --verbose_failures to see the command lines of failed build steps.
INFO: Elapsed time: 1657.036s, Critical Path: 351.63s
INFO: 9274 processes: 746 internal, 8528 local.
FAILED: Build did NOT complete successfully
Failed to build external libraries: ['/home/ubuntu/pytorch/xla/build_torch_xla_libs.sh', '-O', '-D_GLIBCXX_USE_CXX11_ABI=0', 'bdist_wheel']
```
|
https://github.com/pytorch/xla/issues/4666
|
closed
|
[
"question",
"build"
] | 2023-02-21T19:56:52Z
| 2025-05-06T13:32:43Z
| null |
aws-bowencc
|
pytorch/xla
| 4,662
|
CUDA momery:how can i control xla reserved in total by PyTorch with GPU
|
## ❓ Questions and Help
I see xla will reserve almost all memory on GPU,but when i run code both with xla and cuda, it will be error of `torch.cuda.OutOfMemoryError`。
```python
File "/workspace/volume/hqp-nas/xla/mmdetection/mmdet/models/backbones/resnet.py", line 298, in forward
out = _inner_forward(x)
File "/workspace/volume/hqp-nas/xla/mmdetection/mmdet/models/backbones/resnet.py", line 275, in _inner_forward
out = self.conv2(out)
File "/root/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/root/anaconda3/envs/pytorch/lib/python3.8/site-packages/mmcv/ops/modulated_deform_conv.py", line 338, in forward
output = modulated_deform_conv2d(x, offset, mask, weight1, bias1,
File "/root/anaconda3/envs/pytorch/lib/python3.8/site-packages/mmcv/ops/modulated_deform_conv.py", line 142, in forward
ext_module.modulated_deform_conv_forward(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 52.00 MiB (GPU 0; 79.20 GiB total capacity; 752.52 MiB already allocated; 27.25 MiB free; 886.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
We can see there is 80GB in the single card of GPU-A100。but CUDA of Pytorch only 886.00 MiB reserved,and xla does reserve almost all memory on GPU。if i need cuda to exec operators that xla is not supported,it need more memory。
```markdown
Tue Feb 21 12:39:45 2023
+-----------------------------------------------------------+
| NVIDIA-SMI 520.61.05 Driver Version: 520.61.05 CUDA Version: 11.8 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... Off | 00000000:16:00.0 Off | 0 |
| N/A 33C P0 88W / 400W | 81073MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
```
If i can contorl the size of XLA reserved, it will be nice。any answer will be helpful。
|
https://github.com/pytorch/xla/issues/4662
|
closed
|
[
"question",
"xla:gpu"
] | 2023-02-21T12:43:09Z
| 2025-05-07T12:13:34Z
| null |
qipengh
|
pytorch/kineto
| 727
|
How to trace torch cuda time in C++ using kineto?
|
**The problem**
Hi, I am using the pytorch profile to trace the gpu performance of models, and it works well in python.
For example:
```
import torch
from torch.autograd.profiler import profile, record_function
with profile(record_shapes=True, use_cuda=True, use_kineto=True, with_stack=False) as prof:
with record_function("model_inference"):
a = torch.randn(128, 128, device=torch.device('cuda:0'))
b = torch.randn(128, 128, device=torch.device('cuda:0'))
c = a + b
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=50))
```
Now, I want to implement the above code in C++ and get each operator's cuda (kernel) time. But I found very few relevant examples. So I implemented a C++ program against the python interface.
```
#include <torch/csrc/autograd/profiler_kineto.h>
...
...
const std::set<torch::autograd::profiler::ActivityType> activities(
{torch::autograd::profiler::ActivityType::CPU, torch::autograd::profiler::ActivityType::CUDA});
torch::autograd::profiler::prepareProfiler(
torch::autograd::profiler::ProfilerConfig(
torch::autograd::profiler::ProfilerState::KINETO, false, false), activities);
torch::autograd::profiler::enableProfiler(
torch::autograd::profiler::ProfilerConfig(
torch::autograd::profiler::ProfilerState::KINETO, false, false), activities);
auto a = torch::rand({128, 128}, {at::kCUDA});
auto b = torch::rand({128, 128}, {at::kCUDA});
auto c = a + b;
auto profiler_results_ptr = torch::autograd::profiler::disableProfiler();
const auto& kineto_events = profiler_results_ptr->events();
for (const auto e : kineto_events) {
std::cout << e.name() << " " << e.cudaElapsedUs() << " " << e.durationUs()<<std::endl;
}
```
But the printed cuda time is all equal to -1 like:
```
aten::empty -1 847
aten::uniform_ -1 3005641
aten::rand -1 3006600
aten::empty -1 21
aten::uniform_ -1 53
aten::rand -1 82
aten::add -1 156
cudaStreamIsCapturing -1 8
_ZN2at6native90_GLOBAL__N__66_tmpxft_000055e0_00000000_13_DistributionUniform_compute_86_cpp1_ii_f2fea07d43distribution_elementwise_grid_stride_kernelIfLi4EZNS0_9templates4cuda21uniform_and_transformIffLm4EPNS_17CUDAGeneratorImplEZZZNS4_14uniform_kernelIS7_EEvRNS_18TensorIteratorBaseEddT_ENKUlvE_clEvENKUlvE2_clEvEUlfE_EEvSA_T2_T3_EUlP24curandStatePhilox4_32_10E0_ZNS1_27distribution_nullary_kernelIffLi4ES7_SJ_SE_EEvSA_SF_RKSG_T4_EUlifE_EEviNS_15PhiloxCudaStateET1_SF_ -1 2
cudaLaunchKernel -1 3005499
cudaStreamIsCapturing -1 4
_ZN2at6native90_GLOBAL__N__66_tmpxft_000055e0_00000000_13_DistributionUniform_compute_86_cpp1_ii_f2fea07d43distribution_elementwise_grid_stride_kernelIfLi4EZNS0_9templates4cuda21uniform_and_transformIffLm4EPNS_17CUDAGeneratorImplEZZZNS4_14uniform_kernelIS7_EEvRNS_18TensorIteratorBaseEddT_ENKUlvE_clEvENKUlvE2_clEvEUlfE_EEvSA_T2_T3_EUlP24curandStatePhilox4_32_10E0_ZNS1_27distribution_nullary_kernelIffLi4ES7_SJ_SE_EEvSA_SF_RKSG_T4_EUlifE_EEviNS_15PhiloxCudaStateET1_SF_ -1 1
cudaLaunchKernel -1 14
void at::native::vectorized_elementwise_kernel<4, at::native::AddFunctor<float>, at::detail::Array<char*, 3> >(int, at::native::AddFunctor<float>, at::detail::Array<char*, 3>) -1 1
cudaLaunchKernel -1 16
```
I carefully compared the differences between the above two programs (python and C++) but did not find the cause of the problem. I also tried other parameter combinations and couldn't get the real cuda time.
**Expected behavior**
It can output cuda time of each operator in C++ program like python.
**Environment version**
OS: CentOS release 7.5 (Final)
nvidia driver version: 460.32.03
CUDA version: 11.2
PyTorch version: 1.9.0+cu111
Python version: 3.6.5
GPU: A10
|
https://github.com/pytorch/kineto/issues/727
|
closed
|
[
"question"
] | 2023-02-21T11:37:24Z
| 2023-10-10T15:07:23Z
| null |
TianShaoqing
|
pytorch/kineto
| 726
|
How to remove log output similar to “ActivityProfilerController.cpp:294] Completed Stage: Warm Up”
|
## What I encounter
when I use torch.profie to profie a large model, I found my log file have many lines like:
```
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101899:101899 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101899:101899 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101899:101899 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101899:101899 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101899:101899 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:300] Completed Stage: Collection
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101898:101898 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
```
## What I expect
Is there any way to ignore or turn off the output of these useless logs? I tried to set the environment variable `KINETO_LOG_LEVEL` equal to 99, but it didn't work. thanks you all.
```python
import os
os.environ.update({'KINETO_LOG_LEVEL' : '99'})
```
## Version and platform
CentOS-7 Linux
torch 1.13.1+cu117 <pip>
torch-tb-profiler 0.4.1 <pip>
torchaudio 0.13.1+cu117 <pip>
torchvision 0.14.1+cu117 <pip>
|
https://github.com/pytorch/kineto/issues/726
|
closed
|
[
"enhancement"
] | 2023-02-21T07:46:59Z
| 2023-06-22T02:37:44Z
| null |
SolenoidWGT
|
pytorch/data
| 1,033
|
Accessing DataPipe state with MultiProcessingReadingService
|
Hi TorchData team,
I'm wondering how to access the state of the datapipe in the multi-processing context with DataLoader2 + MultiProcessingReadingService. When using no reading service, we can simply access the graph using `dataloader.datapipe`, then I can easily access the state of my datapipe using the code shown below.
However, in the multi processing case, the datapipe graph is replaced with QueueWrapper instances, and I cannot find any way to communicate with the workers to get access to the state of the data pipe (and I get the error that my StatefulIterator cannot be found on the datapipe). If I access `dl2._datapipe_before_reading_service_adapt` I do get the initial state only which makes sense since there is no state sync between the main and worker processes.
As far as I understand, this will also be a blocker for state capturing for proper DataLoader checkpointing when the MultiProcessingReadingService is being used.
Potentially, could we add a `getstate` communication primitive in `communication.messages` in order to capture the state (via getstate) of a datapipe in a worker process?
We're also open to using `sharding_round_robin_dispatch` in order to keep more information in the main process but I'm a bit confused on how to use it, if you have some sample code for me for the following case?
Running against today's master (commit a3b34a00e7d2b6694ea0d5e21fcc084080a3abae):
```python
import torchdata.datapipes as dp
from torch.utils.data.graph_settings import get_all_graph_pipes, traverse_dps
from torchdata.dataloader2 import DataLoader2, MultiProcessingReadingService
class StatefulIterator(dp.iter.IterDataPipe):
def __init__(self, datapipe):
self.datapipe = datapipe
self.custom_index = 0
def __iter__(self):
self.custom_index = 0
for item in self.datapipe:
self.custom_index += 1
yield item
self.custom_index = 0
def get_datapipe():
initial_data = dp.iter.IterableWrapper([1, 2, 3, 4])
stateful_data = StatefulIterator(initial_data)
sharded_data = stateful_data.sharding_filter()
return sharded_data
def get_datapipe_state(datapipe):
graph = traverse_dps(datapipe)
all_pipes = get_all_graph_pipes(graph)
for pipe in all_pipes:
if hasattr(pipe, "custom_index"):
return pipe.custom_index
raise ValueError("This datapipe does not contain a StatefulIterator.")
def main_no_multiprocessing():
dp = get_datapipe()
dl2 = DataLoader2(dp)
for item in dl2:
print("Custom index", get_datapipe_state(dl2.datapipe))
print("Item", item)
def main_multiprocessing():
dp = get_datapipe()
dl2 = DataLoader2(dp, reading_service=MultiProcessingReadingService(num_workers=4))
for item in dl2:
print("Custom index", get_datapipe_state(dl2.datapipe))
print("Item", item)
if __name__ == "__main__":
main_no_multiprocessing()
main_multiprocessing()
```
cc: @ejguan @VitalyFedyunin @NivekT
|
https://github.com/meta-pytorch/data/issues/1033
|
closed
|
[] | 2023-02-20T15:01:44Z
| 2025-08-25T06:43:11Z
| 9
|
jhoareau
|
pytorch/benchmark
| 1,420
|
How to enable jit with nvfuser testing
|
I want to benchmark models in torchbenchmark with jit and nvfuser. I want to also dump the graph fused.
I tried following command, but nothing is printed.
PYTORCH_JIT_LOG_LEVEL=">>graph_fuser" python3 ../../run.py resnet50 -d cuda -m jit -t train
|
https://github.com/pytorch/benchmark/issues/1420
|
closed
|
[] | 2023-02-20T14:26:50Z
| 2023-03-07T16:20:49Z
| null |
fxing-GitHub
|
pytorch/TensorRT
| 1,680
|
❓ [Question]just import acc_tracer speed up my code
|
## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
I use torch_tensortt compile a trt model,when I use the model to inference video ,I found when I add a line `import torch_tensorrt.fx.tracer.acc_tracer.acc_tracer as acc_tracer` , the code ran faster.
Time spent on the original code:

Time spent on the code with add `import torch_tensorrt.fx.tracer.acc_tracer.acc_tracer as acc_tracer`:

I don't know why this happened.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):1.13.0
- CPU Architecture:
- OS (e.g., Linux):Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:3.10
- CUDA version:11.7
- GPU models and configuration:A4000
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1680
|
closed
|
[
"question",
"No Activity",
"component: fx"
] | 2023-02-17T09:19:19Z
| 2023-05-29T00:02:22Z
| null |
T0L0ve
|
huggingface/setfit
| 315
|
Choosing the datapoints that need to be annotated?
|
Hello,
I have a large set of unlabelled data on which I need to do text classification. Since few-shot text classification uses only a handful of datapoints per class, is there a systematic way to choose which datapoints should be chosen for annotation?
Thank you!
|
https://github.com/huggingface/setfit/issues/315
|
open
|
[
"question"
] | 2023-02-16T05:25:03Z
| 2023-03-06T20:56:22Z
| null |
vahuja4
|
huggingface/setfit
| 314
|
Question: train and deploy via Sagemaker
|
Hi
I'm trying to setup training (and hyperparameter tuning) using Amazon SageMaker.
Because SetFit is not a standard model on HugginFace I'm guessing that the examples provided in the HuggingFace/SageMaker integration are not useable: [example](https://github.com/huggingface/notebooks/tree/ef21344eb20fe19f881c846d5e36c8e19d99647c/sagemaker/01_getting_started_pytorch).
What would the best way to tackle hyperparameter tuning (tuning body and head separately) on SageMaker and track the results?
|
https://github.com/huggingface/setfit/issues/314
|
open
|
[
"question"
] | 2023-02-15T12:23:33Z
| 2024-03-28T15:10:28Z
| null |
lbelpaire
|
pytorch/functorch
| 1,111
|
Use functional models inside usual nn.Module
|
Hi, Thanks for the adding functional features to Pytorch. I want to use a `nn.Module` converted into a functional form inside a usual stateful `nn.Module`. However, the code below does not correctly register the parameters for the functional module. Is there a way to do this currently?
```python
import torch
import optree
import torch.nn as nn
from functorch import make_functional
x = torch.randn(4, 10)
class TinyModel(torch.nn.Module):
def __init__(self):
super(TinyModel, self).__init__()
self.func_l,self.params_l=make_functional(nn.Linear(10,10))
for i,ele in enumerate(self.params_l):
self.register_parameter(str(i),ele)
def forward(self,inputs):
return self.func_l(self.params_l,inputs)
model = TinyModel()
func, params = make_functional(model)
```
This is useful for me as I want to use functional operations over an inner `nn.Module` (such as vmap, jvp, vip) inside the forward pass of an outer `nn.Module`. The idea is to be able to have a lifted version of vjp, jvp, etc, similar to Flax (https://flax.readthedocs.io/en/latest/api_reference/_autosummary/flax.linen.vjp.html).
|
https://github.com/pytorch/functorch/issues/1111
|
open
|
[] | 2023-02-15T08:14:22Z
| 2023-02-18T09:57:48Z
| 1
|
subho406
|
huggingface/setfit
| 313
|
Setfit no support evaluate each epoch or step and save model each epoch or step
|
Hi everyone, can u give me about evaluate each epoch and save checkpoint model ? thanks everyone
|
https://github.com/huggingface/setfit/issues/313
|
closed
|
[
"question"
] | 2023-02-15T04:14:24Z
| 2023-12-06T13:20:50Z
| null |
batman-do
|
pytorch/vision
| 7,250
|
Add more docs about how to build a wheel of vision with the all features of video
|
### 🚀 The feature
No docs to show how to build a wheel with the all features of video including the video_reader(gpu decoder).
### Motivation, pitch
I want to use GPU to accelerate the speed of video decoding.
And i find that you support the gpu video decoder.
There are some questions below:
1. from https://github.com/pytorch/vision#video-backend, I know that i need ffmpeg or pyav to enable the video feature. However, both of them do not support GPU originally. So what do i need if i want to use GPU video decoder.
2. No detail docs to show how to build a wheel of vision with GPU video decoder.
3. After gpu decoding,where is the tensor, system memory or gpu memory?
4. What's the data flow of your video processing and inference?
```
1. Decoding in the gpu memory
2. Downloading to the system memory.
3. Uploading to the gpu memory for inference.
4. Downloading to the system memory.
5. Uploading to gpu memory for encoding.(Maybe it does not exist)
```
or
```
1. Decoding in the gpu memory
2. Inference in the gpu memory directly.
3. Encoding in the gpu memory(Maybe it does not exist)
```
5.Is there any way for video to work with this pipeline——1.decoded by gpu and keep it in the gpu memory. 2.Inference with tensor in gpu memory directly without downloading to the system memory and uploading to gpu memory for inference again.
I think you should add these to docs.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/vision/issues/7250
|
open
|
[
"module: documentation",
"module: video"
] | 2023-02-15T01:53:44Z
| 2023-02-15T08:07:13Z
| null |
wqh17101
|
pytorch/tutorials
| 2,205
|
During downsampling, bicubic interpolation produces WORSE results than ffmpeg. How can I fix this issue?
|
I have used "`bicubic`" interpolation with `(antialias=True)`. I checked the output downsampled image and found that It crates some artifacts on the image. See the image **[here](https://drive.google.com/file/d/1x1knhzyGpyqfkEjqi8tCxD4Ka_lhpfE5/view?usp=sharing)**,
Here is my code for downsampling:
```
from torch.nn.functional import interpolate
img = Image.open("image_location")
#4x down-sampled
ds_img = interpolate(transforms.ToTensor()(img).unsqueeze(0),scale_factor=.25,mode = "bicubic", antialias=True)
down_img=transforms.ToPILImage()(ds_img.squeeze().cpu())
```
Thank you
|
https://github.com/pytorch/tutorials/issues/2205
|
closed
|
[
"question"
] | 2023-02-14T17:38:57Z
| 2023-02-16T14:01:04Z
| null |
tahsirmunna
|
huggingface/optimum
| 776
|
Loss of accuracy when Longformer for SequenceClassification model is exported to ONNX
|
### Edit: This is a crosspost to [pytorch #94810](https://github.com/pytorch/pytorch/issues/94810). I don't know, where the issue lies.
### System info
- `transformers` version: 4.26.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- PyTorch version (GPU?): 1.13.0 (False)
- onnx: 1.13.0
- onnxruntime: 1.13.1
### Who can help?
I think
@younesbelkada
would be a great help :)
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This model is trained on client data and I'm not allowed to share the data or the weights, which makes any reproduction of this issue much harder. Please let me know when you need more information.
Here is the code snippet for the onnx conversion:
I follow this [tutorial](https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html), but I also tried your [tutorial](https://huggingface.co/docs/transformers/serialization). The onnx conversion with optimum is not available for Longformer so far and I haven't figured out yet, how to add it.
conversion:
```python
import numpy as np
from onnxruntime import InferenceSession
from tqdm.auto import tqdm
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("deployment/best_model/")
model = AutoModelForSequenceClassification.from_pretrained("deployment/best_model/")
model.to("cpu")
model.eval()
example_input = tokenizer(
dataset["test"]["text"][0], max_length=512, truncation=True, return_tensors="pt"
)
_ = model(**example_input)
torch.onnx.export(
model,
tuple(example_input.values()),
f="model.onnx",
input_names=["input_ids", "attention_mask"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size", 1: "sequence"},
"attention_mask": {0: "batch_size", 1: "sequence"},
"logits": {0: "batch_size", 1: "sequence"},
},
do_constant_folding=True,
opset_version=16,
)
```
Calculating the accuracy:
```python
session = InferenceSession("deployment/model.onnx", providers=["CPUExecutionProvider"])
y_hat_torch = []
y_hat_onnx = []
for text in dataset["test"]["text"]:
tok_text = tokenizer(
text, padding="max_length", max_length=512, truncation=True, return_tensors="np"
)
pred = session.run(None, input_feed=dict(tok_text))
pred = np.argsort(pred[0][0])[::-1][0]
y_hat_onnx.append(int(pred))
tok_text = tokenizer(
text, padding="max_length", max_length=512, truncation=True, return_tensors="pt"
)
pred = model(**tok_text)
pred = torch.argsort(pred[0][0], descending=True)[0].numpy()
y_hat_torch.append(int(pred))
print(
f"Accuracy onnx:{sum([int(i)== int(j) for I, j in zip(y_hat_onnx, dataset['test']['label'])]) / len(y_hat_onnx):.2f}"
)
print(
f"Accuracy torch:{sum([int(i)== int(j) for I, j in zip(y_hat_torch, dataset['test']['label'])]) / len(y_hat_torch):.2f}"
)
```
I also looked into the models' weights and the weights for the attention layer differ between torch and onnx. Here is an example:
```python
import torch
import onnx
from onnx import numpy_helper
import numpy as np
from numpy.testing import assert_almost_equal
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("deployment/best_model/")
onnx_model = onnx.load("deployment/model.onnx")
graph = onnx_model.graph
initalizers = dict()
for init in graph.initializer:
initalizers[init.name] = numpy_helper.to_array(init).astype(np.float16)
model_init = dict()
for name, p in model.named_parameters():
model_init[name] = p.detach().numpy().astype(np.float16)
assert len(initalizers) == len(model_init.keys()) # 53 layers
assert_almost_equal(initalizers['longformer.embeddings.word_embeddings.weight'],
model_init['longformer.embeddings.word_embeddings.weight'], decimal=5)
assert_almost_equal(initalizers['classifier.dense.weight'],
model_init['classifier.dense.weight'], decimal=5)
```
For the layer longformer.encoder.layer.0.output.dense.weight, which aligns with onnx::MatMul_6692 in shape and position:
```
assert_almost_equal(initalizers['onnx::MatMul_6692'],
model_init['longformer.encoder.layer.0.output.dense.weight'], decimal=4)
```
I get
```python
AssertionError:
Arrays are not almost equal to 4 decimals
Mismatched elements: 2356293 / 2359296 (99.9%)
Max absolute difference: 1.776
Max relative difference: inf
x: array([[ 0.0106, 0.1076, 0.0801, ..., 0.0425, 0.1548, 0.0123],
[-0.0399, -0.1415, 0.0916, ..., 0.0181, -0.1277, -0.133
|
https://github.com/huggingface/optimum/issues/776
|
closed
|
[] | 2023-02-14T10:22:12Z
| 2023-02-17T13:55:17Z
| 8
|
SteffenHaeussler
|
pytorch/pytorch
| 94,704
|
`where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types
|
### 🐛 Describe the bug
`where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types
```py
import torch
a = torch.ones(3, 4)
b = torch.zeros(3, 4)
c = torch.where(a > 0, a, b, out=torch.zeros(3, 4, dtype=torch.long))
# RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERNAL ASSERT FAILED
# at "/opt/conda/conda-bld/pytorch_1672906354936/work/aten/src/ATen/native/cpu/Loops.h":308,
# please report a bug to PyTorch.
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @nairbv @mruberry
|
https://github.com/pytorch/pytorch/issues/94704
|
open
|
[
"module: error checking",
"triaged",
"module: type promotion"
] | 2023-02-12T16:32:30Z
| 2023-02-27T18:15:01Z
| null |
cafffeeee
|
pytorch/pytorch
| 94,699
|
How to correct TypeError: zip argument #1 must support iteration training in multiple GPU
|
### 🐛 Describe the bug
I am doing a creating custom pytorch layer and model training using `Trainer API` function on top of `Hugging face` model.
When I run on `single GPU`, it trains fine. But when I train it on `multiple GPU` it throws me error.
`TypeError: zip argument #1 must support iteration training in multiple GPU`
Data Creation Code:
```
train_ex ={'texts':[x[0] for x in train_set],'tag_names':[x[1] for x in train_set]}
train_data = tokenize_and_align_labels(train_ex,label2id)
_=train_data.pop('offset_mapping')
class MyDataset(torch.utils.data.Dataset):
def __init__(self, examples):
self.encodings = examples
self.labels = examples['labels']
def __getitem__(self, idx):
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items()}
item["labels"] = torch.tensor([self.labels[idx]])
return item def __len__(self):
return len(self.labels)
train_data=MyDataset(train_data)
```
**Training Code**
bert_model = BertForTokenClassification.from_pretrained( model_checkpoint,id2label=id2label,label2id=label2id)
bert_model.config.output_hidden_states=True
class BERT_CUSTOM(nn.Module):
def __init__(self, bert_model,id2label,num_labels):
super(BERT_CUSTOM, self).__init__()
self.bert = bert_model
self.config=self.bert.config
self.dropout = nn.Dropout(0.25)
self.classifier = nn.Linear(768, num_labels)
self.crf = CRF(num_labels, batch_first = True)
def forward(self, input_ids, attention_mask, labels=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
sequence_output = torch.stack((outputs[1][-1], outputs[1][-2], outputs[1][-3], outputs[1][-4])).mean(dim=0)
sequence_output = self.dropout(sequence_output)
emission = self.classifier(sequence_output) # [32,256,21] logits
if labels is not None:
labels=labels.reshape(attention_mask.size()[0],attention_mask.size()[1])
loss = -self.crf(log_soft(emission, 2), labels, mask=attention_mask.type(torch.uint8), reduction='mean')
prediction = self.crf.decode(emission, mask=attention_mask.type(torch.uint8))
return [loss, prediction]
else:
prediction = self.crf.decode(emission, mask=attention_mask.type(torch.uint8))
prediction=[id2label[k] for k in prediction]
return prediction
**Training API**
model = BERT_CUSTOM(bert_model, id2label,num_labels=len(label2id))
model.to(device)
args = TrainingArguments(
"model",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=2,
weight_decay=0.01,
per_device_train_batch_size=32,
fp16=True
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_data,
tokenizer=tokenizer)
trainer.train()
### Versions
'1.7.1+cu110'
**Error**
Here is the complete traceback:
```
Traceback (most recent call last):
File "spanbert_model_check.py", line 263, in <module>
trainer.train()
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1531, in train
ignore_keys_for_eval=ignore_keys_for_eval,
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1775, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 2523, in training_step
loss = self.compute_loss(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 2555, in compute_loss
outputs = model(**inputs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 162, in forward
return self.gather(outputs, self.output_device)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 174, in gather
return gather(outputs, output_device, dim=self.dim)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 68, in gather
res = gather_map(outputs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 63, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 63, in gather_map
return type(out)(map(gather_
|
https://github.com/pytorch/pytorch/issues/94699
|
closed
|
[] | 2023-02-12T13:37:47Z
| 2023-05-12T11:27:46Z
| null |
pratikchhapolika
|
pytorch/data
| 1,005
|
"torchdata=0.4.1=py38" and Conda runtime error "glibc 2.29" not found.
|
### 🐛 Describe the bug
I installed "torchdata=0.4.1=py38" in a Conda environment.
When I run the code, there is an error, "glibc 2.29" not found.
Our cluster run on Centos 8.5 and only has upto "glibc 2.28" .
Is "torchdata 0.4.1" compatible with "glibc 2.28"?
Is there a conda build that support gilbc 2.28?
Or, is there a workaround to make "torchdata 0.4.1" work with clusters having only "glibc 2.28" .
### Versions
torchdata=0.4.1
py38
glibc 2.28
conda 23.1.0
|
https://github.com/meta-pytorch/data/issues/1005
|
closed
|
[] | 2023-02-11T03:26:10Z
| 2023-02-13T14:29:56Z
| 1
|
mahm1846
|
huggingface/setfit
| 310
|
How does predict_proba work exactly ?
|
Hi everyone !
Thanks for this amazing package first ! it is more than useful for a project at my work currently ! and the 0.6.0 was much needed on my side !
BUT i'd like to have some clarifications on how the function predict_proba works because I have a hard understanding.
This table :
<html>
<body>
<!--StartFragment-->
score | predicted | pred_proba_0 | pred_proba_1
-- | -- | -- | --
1 | 1 | 0.866082 | 0.133918
1 | 1 | 0.762696 | 0.237304
1 | 1 | 0.730971 | 0.269029
1 | 1 | 0.871808 | 0.128192
1 | 1 | 0.671637 | 0.328363
1 | 1 | 0.780433 | 0.219567
1 | 1 | 0.652668 | 0.347332
1 | 0 | 0.767050 | 0.232950
<!--EndFragment-->
</body>
</html>
The score column is the true outcome, predicted is what the predict method gives me when I'm doing inference.
pred_proba_0 and pred_proba_1 are given from this code :
validate_dataset['pred_proba_0'] = trainer.model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)[:,0]
validate_dataset['pred_proba_1'] = trainer.model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)[:,1]
Also when I use this code :
model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)
I have this output :
array([[9.1999289e-07, 9.9999905e-01],
[7.2725675e-07, 9.9999928e-01],
[8.1967613e-07, 9.9999917e-01],
...,
[9.4037086e-06, 9.9999058e-01],
[9.1749916e-07, 9.9999905e-01],
[1.2628381e-06, 9.9999869e-01]], dtype=float32)
my question is , i'd like to know if the predict_proba output gives (probability to predict 0 , probability to predict 1) ?
It doesn't seem like it because of this line :
<html>
<body>
<!--StartFragment-->
229 | 0 | 1 | 0.694485 | 0.305515
-- | -- | -- | -- | --
<!--EndFragment-->
</body>
</html>
something is strange also train.model.predict_proba doesn't give the same result as model.predict_proba... can someone please explain to help me understand ?
Thank you very much !
|
https://github.com/huggingface/setfit/issues/310
|
open
|
[
"question",
"needs verification"
] | 2023-02-10T14:13:13Z
| 2023-11-15T08:24:38Z
| null |
doubianimehdi
|
pytorch/examples
| 1,112
|
word_language_model with torch.nn.modules.transformer
|
The `torch.nn.modules.transformer` documentation says the `word_language_model` example in this repo is an example of its use. But it seems to instead DIY a transformer and uses that instead. Is this intentional? I would offer my help to write it for `torch.nn.modules.transformer` but I'm here to learn how to use it.
|
https://github.com/pytorch/examples/issues/1112
|
open
|
[
"good first issue",
"nlp",
"docs"
] | 2023-02-09T19:31:43Z
| 2023-02-21T04:05:42Z
| 2
|
olafx
|
pytorch/examples
| 1,111
|
🚀 Feature request / I want to contribute an algorithm
|
<!--
Thank you for suggesting an idea to improve pytorch/examples
Please fill in as much of the template below as you're able.
-->
## Is your feature request related to a problem? Please describe.
<!-- Please describe the problem you are trying to solve. -->
Currently, PyTorch/examples does not have an implementation of the forward forward algorithm.[forward forward algorithm.](https://arxiv.org/abs/2212.13345) This algorithm is a new learning procedure for neural networks and has promising approach to training neural networks, it is also becoming popular, because it's written by father of deep learning aka Geoffrey Hinton, its inclusion in PyTorch/examples would make it more accessible to a wider community of researchers practitioners, and I would like to contribute in it❤️, I've Implemented This algorithm in my local notebook in pure pytorch❤️.I am new so please let me know How can I contribute this algorithm in this repo.
Thanks,
Vivek
## Describe the solution
The solution is to implement/add the forward forward algorithm in PyTorch/examples. This would include writing the code for the algorithm, as well as any docs or tutorial addition to the existing codebase.
## Describe alternatives solution
<!-- Please describe alternative solutions or features you have considered. -->
[https://keras.io/examples/vision/forwardforward/](https://keras.io/examples/vision/forwardforward/)
|
https://github.com/pytorch/examples/issues/1111
|
closed
|
[] | 2023-02-09T15:13:40Z
| 2023-02-26T23:47:19Z
| 3
|
viveks-codes
|
huggingface/setfit
| 308
|
[QUESTION] Using callbacks (early stopping, logging, etc)
|
Hi all, thanks for your work here!
**TLDR**: Is there a way to add callbacks for early stopping and logging (for example, with W&B?).
I am using setfit for a project, but I could not figure out a way to add early stopping. I am afraid that I am overfitting to the training set. I also cant really say that I am, because I am not sure how I can log the training metrics (train/eval performance across epochs).
I saw that the script [run_full.py](https://github.com/huggingface/setfit/blob/ebee18ceaecb4414482e0a6b92c97f3f99309d56/scripts/transformers/run_full.py#L104) has it, but I couldn't figure out how to do it with SetFit API.
thanks!
|
https://github.com/huggingface/setfit/issues/308
|
closed
|
[
"question"
] | 2023-02-08T19:39:20Z
| 2023-02-27T16:25:26Z
| null |
FMelloMascarenhas-Cohere
|
huggingface/optimum
| 763
|
Documented command "optimum-cli onnxruntime" doesn't exist?
|
### System Info
```shell
Python 3.9, Ubuntu 20.04, Miniconda. CUDA GPU available
Packages installed (the important stuff):
onnx==1.13.0
onnxruntime==1.13.1
optimum==1.6.3
tokenizers==0.13.2
torch==1.13.1
transformers==4.26.0
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
```
### Who can help?
@lewtun, @michaelbenayoun
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I have an existing ONNX model, which I am trying to optimize with different scenarios. When attempting to follow the documented instructions for optimizing an existing ONNX model, the command does not exist. I am using the instructions from this page: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization
NOTE: I am using zsh, which requires escaping brackets
```bash
pip install optimum
pip install optimum\[onnxruntime\]
pip install optimum\[exporters\]
```
Command execution:
```bash
optimum-cli onnxruntime optimize --onnx_model ../output/sentence-transformers/all-MiniLM-L6-v2/model.onnx -o output/sentence-transformers/all-MiniLM-L6-v2/model-optimized.onnx -04
```
Result:
```
usage: optimum-cli <command> [<args>]
Optimum CLI tool: error: invalid choice: 'onnxruntime' (choose from 'export', 'env')
```
### Expected behavior
I'd expect for the command to exist, or to understand which command to use for experimenting with different ONNX optimizations. I tried using the optimum-cli export onnx command, but that does not have options for optimization types.
I'd be happy to start from a torch model instead of using an existing ONNX model - but I'd also like to be able to specify different optimizations (-01 | -02 | -03 | -04)
Thanks!
|
https://github.com/huggingface/optimum/issues/763
|
closed
|
[
"bug"
] | 2023-02-08T18:19:52Z
| 2023-02-08T18:25:52Z
| 2
|
binarymax
|
huggingface/datasets
| 5,513
|
Some functions use a param named `type` shouldn't that be avoided since it's a Python reserved name?
|
Hi @mariosasko, @lhoestq, or whoever reads this! :)
After going through `ArrowDataset.set_format` I found out that the `type` param is actually named `type` which is a Python reserved name as you may already know, shouldn't that be renamed to `format_type` before the 3.0.0 is released?
Just wanted to get your input, and if applicable, tackle this issue myself! Thanks 🤗
|
https://github.com/huggingface/datasets/issues/5513
|
closed
|
[] | 2023-02-08T15:13:46Z
| 2023-07-24T16:02:18Z
| 4
|
alvarobartt
|
pytorch/TensorRT
| 1,653
|
❓ [Question] Partitioning for unsupported operations
|
## ❓ Question
As far as I understand Torch-TensorRT performs a partitioning step when unsupported operations are encountered. Then, graph uses generated TensorRT engine(s) for supported partition(s) and falls back to TorchScript JIT anywhere else. I can observe this behavior from generated graphs in general. However, I receive errors with specific blocks in which I couldn't understand why such blocks are problematic.
For instance, for the following (example) block:
```python
"""block(for+cond)"""
retval=[]
for slice in x: # x: torch.Tensor
if slice.sum() > 0: # any cond. dep. on tensor/slice
retval.append(slice + 100)
else:
retval.append(slice + 50)
"""block(for+cond)"""
```
I receive a `RuntimeError: [Error thrown at core/partitioning/shape_analysis.cpp:167] Expected ivalues_maps.count(input) to be true but got false` on `torch_tensorrt.compile(...)`:
```
Traceback (most recent call last):
File "/home/burak/test.py", line 36, in <module>
net_trt = torch_tensorrt.compile(net, **net_specs)
File "/home/burak/miniconda3/envs/convert/lib/python3.10/site-packages/torch_tensorrt/_compile.py", line 125, in compile
return torch_tensorrt.ts.compile(
File "/home/burak/miniconda3/envs/convert/lib/python3.10/site-packages/torch_tensorrt/ts/_compiler.py", line 136, in compile
compiled_cpp_mod = _C.compile_graph(module._c, _parse_compile_spec(spec))
RuntimeError: [Error thrown at core/partitioning/shape_analysis.cpp:167] Expected ivalues_maps.count(input) to be true but got false
Could not find torch::jit::Value* slice.1 produced from %slice.1 : Tensor = aten::select(%158, %6, %19) # /home/burak/test.py:20:8 in lowering graph for mini graph input.
```
## What you have already tried
I have tried this behavior with the following example script:
```python
import torch
import torch_tensorrt
torch_tensorrt.logging.set_reportable_log_level(torch_tensorrt.logging.Level.Info)
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv0 = torch.nn.Conv2d(3, 8, kernel_size=3)
self.relu = torch.nn.ReLU(inplace=True)
self.conv1 = torch.nn.Conv2d(8, 16, kernel_size=3)
def forward(self, x):
x = self.conv0(x)
x = self.relu(x)
x = self.conv1(x)
"""block(for+cond)"""
retval=[]
for slice in x:
if slice.sum() > 0: # any cond. dep. on tensor/slice
retval.append(slice + 100)
else:
retval.append(slice + 50)
"""block(for+cond)"""
return retval
net = Net().eval().cuda()
net_specs = {
'inputs': [torch_tensorrt.Input(shape=[1, 3, 224, 224], dtype=torch.float32)],
'enabled_precisions': {torch.float32, torch.half},
}
net_trt = torch_tensorrt.compile(net, **net_specs)
print(net_trt.graph)
```
I receive the following RuntimeError (full output, info log-level):
```
INFO: [Torch-TensorRT] - ir was set to default, using TorchScript as ir
INFO: [Torch-TensorRT] - Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript
INFO: [Torch-TensorRT] - Lowered Graph: graph(%x.1 : Tensor):
%self.conv0.weight.1 : Float(8, 3, 3, 3, strides=[27, 9, 3, 1], requires_grad=0, device=cuda:0) = prim::Constant[value=<Tensor>]()
%self.conv0.bias.1 : Float(8, strides=[1], requires_grad=0, device=cuda:0) = prim::Constant[value= 0.1437 0.0745 0.1127 0.1185 0.1406 0.1445 -0.0802 0.0562 [ CUDAFloatType{8} ]]()
%self.conv1.weight.1 : Float(16, 8, 3, 3, strides=[72, 9, 3, 1], requires_grad=0, device=cuda:0) = prim::Constant[value=<Tensor>]()
%self.conv1.bias.1 : Float(16, strides=[1], requires_grad=0, device=cuda:0) = prim::Constant[value=<Tensor>]()
%9 : int = prim::Constant[value=1]()
%8 : NoneType = prim::Constant()
%7 : bool = prim::Constant[value=1]() # /home/burak/test.py:20:8
%6 : int = prim::Constant[value=0]() # /home/burak/test.py:21:29
%5 : int = prim::Constant[value=100]() # /home/burak/test.py:22:38
%4 : int = prim::Constant[value=50]() # /home/burak/test.py:24:38
%3 : int[] = prim::Constant[value=[1, 1]]()
%2 : int[] = prim::Constant[value=[0, 0]]()
%153 : bool = prim::Constant[value=0]()
%154 : int[] = prim::Constant[value=[0, 0]]()
%155 : Tensor = aten::_convolution(%x.1, %self.conv0.weight.1, %self.conv0.bias.1, %3, %2, %3, %153, %154, %9, %153, %153, %153, %153)
%17 : Tensor[] = prim::ListConstruct()
%137 : Tensor = aten::relu(%155) # /home/burak/miniconda3/envs/convert/lib/python3.10/site-packages/torch/nn/functional.py:1455:17
%156 : bool = prim::Constant[value=0]()
%157 : int[] = prim::Constant[value=[0, 0]]()
%158 : Tensor = aten::_convolution(%137, %self.conv1.weight.1, %self.conv1.bias.1, %3, %2, %3, %156, %157, %9, %156, %156, %156, %156)
%144 : int = aten::len(%15
|
https://github.com/pytorch/TensorRT/issues/1653
|
closed
|
[
"question",
"No Activity",
"component: partitioning"
] | 2023-02-08T07:39:17Z
| 2023-06-10T00:02:25Z
| null |
kunkcu
|
pytorch/TensorRT
| 1,651
|
❓ [Question] Unknown type name '__torch__.torch.classes.tensorrt.Engine'
|
## ❓ Question
<!-- Your question -->
## What you have already tried
**My c++ code:**
torch::Device device(torch::kCUDA);
torch::jit::script::Module module = torch::jit::load("lenet_trt.ts");
module.to(device);
vector<jit::IValue> inputs;
inputs.emplace_back(torch::ones({1,1,32,32}).to(device));
at::Tensor output = module.forward(inputs).toTensor();
cout << output << endl;
**After running the code, the error occurs:**
terminate called after throwing an instance of 'torch::jit::ErrorReport'
what():
Unknown type name '__torch__.torch.classes.tensorrt.Engine':
File "code/__torch__/___torch_mangle_18.py", line 4
__parameters__ = []
__buffers__ = []
__torch______torch_mangle_18_LeNet_trt_engine_ : __torch__.torch.classes.tensorrt.Engine
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward(self_1: __torch__.___torch_mangle_18.LeNet_trt,
input_0: Tensor) -> Tensor:
Signal: SIGABRT (Aborted)
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- CPU Architecture: x86 x64
- OS: Ubuntu22.04
- CUDA version: 11.7
- libtorch Version 1.13.1:
- TensorRT: 8.5.3.1
- torch_tensorrt: 1.3.0
## Additional context
I compiled a pytorch model using the torchtrtc command. This model can be loaded successfully with python code, but fails with c++ code. Can someone help me solve this issue?
|
https://github.com/pytorch/TensorRT/issues/1651
|
closed
|
[
"question",
"component: api [C++]",
"component: runtime"
] | 2023-02-07T05:49:57Z
| 2023-02-08T02:08:12Z
| null |
chensuo2048
|
pytorch/rl
| 897
|
[Feature Request] Tutorial on how to build the simplest agent
|
## Motivation
Hey,
the [DDPG tutorial](https://pytorch.org/rl/tutorials/coding_ddpg.html) has me pooping my pants. I want to suggest an example of creating a simple DDPG or similar agent that just acts and observes and gets the job done for a researcher looking to implement and RL algorithm on their own environment that has nothing to do with the usual benchmarking environments., i.e. just applying RL to their specific field.
This [video](https://www.youtube.com/watch?v=cIKMhZoykEE) advertises being able to use components without having to use the rest of the library, and I want to believe it, but when I look at the [docs page](https://pytorch.org/rl/reference/index.html) I see a lot of components that I don't know how to use and when I look into the docs of the specific components I find that they take arguments that are an interface to something that I have no idea what it is and has an abstract name. Not to sound ignorant, but I feel like I have to know the entire framework just to use one part of it, which is againts the core idea, as I understand it.
## Solution
Like, I have my own environment that's completely numpy and doesn't have anything to do with Gym or anything else, and I wan't to have the following workflow:
```
class MyAgent:
def __init__(self, **kwargs):
# torchrl code goes here
# how to init networks
# how to init a replay buffer, a simple one
# init objectives like DDPGloss
def act(self, state):
# how to produce an action with the actor network or more likely actor module
# how to add noise
def observe(self, s, action, new_s, reward):
# how to put a transition into the replay buffer
# how to update the neural networks
# so how to sample from the RB, how to use the objectives, how to backpropagate, how to soft update
env = MyEnv() # isn't made with torchrl
agent = MyAgent() # class made with torchrl
s = env.reset() # init state
for t in range(T):
action = agent.act(s)
new_s, reward = env.step() # could be converted to output tensordicts
agent.observe(s, action, new_s, reward) # observe transition and update the model
```
Just the "RL for dummies" toy example. For those of us who don't need transforms and parallelization just yet; we can get into that once we've got the basics working. Like, I found the component's I need - [soft update](https://pytorch.org/rl/reference/generated/torchrl.objectives.SoftUpdate.html#torchrl.objectives.SoftUpdate), [ddpg loss](https://pytorch.org/rl/reference/generated/torchrl.objectives.DDPGLoss.html#torchrl.objectives.DDPGLoss)... I just don't know how to put them together without the monstrosity of the code that is [DDPG tutorial](https://pytorch.org/rl/tutorials/coding_ddpg.html).
## Alternatives
/
## Additional context
/
## Checklist
- [ x] I have checked that there is no similar issue in the repo (**required**)
I've found this [issue](https://github.com/pytorch/rl/issues/90) that hits the spot but I don't know if it amounted to anything, and my issue is leaning towards providing an example of this low level functionality.
This [issue](https://github.com/pytorch/rl/issues/861) is also pretty good but I'd aim for even simpler and especially for the environment to not need to be torchrl.
## Conclusion
Those were my two cents. I hope I've hit the target with them. If there's something like this already available and I just haven't found it yet, please do let me know.
|
https://github.com/pytorch/rl/issues/897
|
open
|
[
"enhancement"
] | 2023-02-06T22:42:47Z
| 2023-02-07T10:01:42Z
| null |
viktor-ktorvi
|
pytorch/tutorials
| 2,196
|
nestedtensor.py on Colab building from master
|
When running the [nested tensors tutorial](https://pytorch.org/tutorials/prototype/nestedtensor.html) on [google colab](https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/db9e0933e73063322e250e5d0cec413d/nestedtensor.ipynb) builds from master instead of main. The master branch version is non-functional, main branch version appears to work correctly:
- nested tensors created with `torch.nested_tensor` instead of `torch.nested.nested_tensor`
- the `mha_netsed` function handle batch size inference incorrectly.
|
https://github.com/pytorch/tutorials/issues/2196
|
open
|
[
"question",
"2.0"
] | 2023-02-06T22:13:41Z
| 2023-02-07T21:32:28Z
| null |
alex-rakowski
|
pytorch/data
| 986
|
Disable cron job running on forked repo
|
### 🐛 Describe the bug
My forked repo of torchdata have been running the cron job to validate nightly binaries.
See workflow https://github.com/ejguan/data/actions/runs/4097726223
@atalman Is this expected? Can we disable it by doing something like:
https://github.com/pytorch/data/blob/01fc76200354501b057bb439b43a1f05f609dd0a/.github/workflows/nightly_release.yml#L11
### Versions
main
|
https://github.com/meta-pytorch/data/issues/986
|
open
|
[
"Better Engineering"
] | 2023-02-06T16:29:00Z
| 2023-04-11T16:48:19Z
| 0
|
ejguan
|
pytorch/TensorRT
| 1,650
|
error when bazel compile torch_tensorrt on win10
|
## ❓ Question
when command " bazel build //:libtorchtrt --compilation_mode opt", the error comes
ERROR: C:/users/zhang/downloads/tensorrt-main/core/runtime/BUILD:13:11: Compiling core/runtime/TRTEngineProfiler.cpp failed: (Exit 2): cl.exe failed: error executing command (from target //core/runtime:runtime) D:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.28.29333\bin\HostX64\x64\cl.exe /nologo /DCOMPILER_MSVC /DNOMINMAX /D_WIN3 2_WINNT=0x0601 /D_CRT_SECURE_NO_DEPRECATE ... (remaining 48 arguments skipped)
## What you have already tried
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):1.13
- CPU Architecture: AMD5600x
- OS (e.g., Linux):win10
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:11.7
- GPU models and configuration:2060
- Any other relevant information: visual studio2019
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1650
|
closed
|
[
"question",
"No Activity",
"channel: windows"
] | 2023-02-06T07:38:28Z
| 2023-06-08T00:02:27Z
| null |
zhanghuqiang
|
huggingface/setfit
| 298
|
apply the optimized parameters
|
I did my hyperparameter search optimization on one computer and now I'm trying to apply the obtained parameters on another computer, so I could not use this code "trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
trainer.train()". I put the obtained parameters manually in my new trainer instead. But I have two sets of the parameters, and I'm not sure which set to use. For example, in the line above I have seed =9, but below seed = 8.
Here are the obtained parameters from the optimization:
Trial 14 finished with value: 0.8711734693877551 and parameters: {'learning_rate': 1.0472016582222107e-05, 'num_epochs': 1, 'batch_size': 4, 'num_iterations': 40, 'seed': 9, 'max_iter': 54, 'solver': 'lbfgs', 'model_id': 'sentence-transformers/all-mpnet-base-v2'}. Best is trial 14 with value: 0.8711734693877551.
Trial: {'learning_rate': 5.786637612112363e-05, 'num_epochs': 1, 'batch_size': 4, 'num_iterations': 20, 'seed': 8, 'max_iter': 52, 'solver': 'lbfgs', 'model_id': 'sentence-transformers/all-mpnet-base-v2'}
model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
***** Running training *****
Num examples = 73160
Num epochs = 1
Total optimization steps = 18290
Total train batch size = 4
Thank you so much!!
|
https://github.com/huggingface/setfit/issues/298
|
closed
|
[
"question"
] | 2023-02-03T18:31:59Z
| 2023-02-16T08:00:52Z
| null |
zoezhupingli
|
pytorch/text
| 2,047
|
Update `CONTRIBUTING.md` w/ instruction on how to install `torchdata` from source
|
See https://github.com/pytorch/text/issues/2045
|
https://github.com/pytorch/text/issues/2047
|
closed
|
[] | 2023-02-03T18:20:17Z
| 2023-02-06T00:37:39Z
| null |
joecummings
|
huggingface/setfit
| 297
|
Comparing setfit with a simpler approach
|
Hi,
I am trying to compare setfit with another approach. The other approach is like this:
1. Define a list of representative sentences per class, call it `rep_sent`
2. Compute sentence embeddings for `rep_sent` using `mpnet-base-v2`
3. Define a list of test sentences, call it 'test_sent'.
4. Compute sentence embeddings for 'test_sent'
5. Now, in order to assign a class to the sentences in `test_sent`, compute the cosine similarity with `rep_sent` and choose the class based on the highest cosine sim.
If we consider a particular test set sentence: "Remove maiden name from account", then the results from the two approaches are as follows:
setfit predicts this to be 'manage account transfer'
other approach predicts this to be 'edit account details'
Can someone please help me to understand how setfit's performance can be improved.
As far as setfit goes, it has been trained use 'rep_sent' as the training set. Here is how it looks like:
`text,label
I want to close my account,accountClose
Close my credit card,accountClose
Mortgage payoff,accountClose
Loan payoff,accountClose
Loan pay off,accountClose
pay off,accountClose
lease payoff,accountClose
lease pay off,accountClose
account close,accountClose
close card account,accountClose
I want to open an account,accountOpenGeneral
I want to get a card,accountOpenGeneral
I want a loan,accountOpenGeneral
Refinance my car,accountOpenGeneral
Buy a car,accountOpenGeneral
Open checking,accountOpenGeneral
Open savings,accountOpenGeneral
Lease a vehicle,accountOpenGeneral
Link external bank account,accountTransferManage
verify external account,accountTransferManage
Add external account,accountTransferManage
Edit external account,accountTransferManage
Remove external account,accountTransferManage
Mortgage payment,billPaySchedulePayment
Setup Loan payment,billPaySchedulePayment
Setup auto loan payment,billPaySchedulePayment
Schedule bill payment,billPaySchedulePayment
Setup bill payment,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Setup auto pay,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Modify account details,editAccountDetails
Modify name on my account,editAccountDetails
Change address in my account,editAccountDetails`
|
https://github.com/huggingface/setfit/issues/297
|
closed
|
[
"question"
] | 2023-02-03T10:11:44Z
| 2023-02-06T13:01:02Z
| null |
vahuja4
|
huggingface/setfit
| 295
|
Question: How the number of categories affect the training and accuracy?
|
I have found that increasing the number of categories reduce the accuracy results. Has anyone studied how the increased number of samples per category affect the results?
|
https://github.com/huggingface/setfit/issues/295
|
open
|
[
"question"
] | 2023-02-02T18:43:33Z
| 2023-07-26T19:30:21Z
| null |
rubensmau
|
pytorch/vision
| 7,168
|
Current way to use torchvision.prototype.transforms
|
### 📚 The doc issue
I tried to run the [end-to-end example in this recent blog post](https://pytorch.org/blog/extending-torchvisions-transforms-to-object-detection-segmentation-and-video-tasks/#an-end-to-end-example):
```python
import PIL
from torchvision import io, utils
from torchvision.prototype import features, transforms as T
from torchvision.prototype.transforms import functional as F
# Defining and wrapping input to appropriate Tensor Subclasses
path = "COCO_val2014_000000418825.jpg"
img = features.Image(io.read_image(path), color_space=features.ColorSpace.RGB)
# img = PIL.Image.open(path)
bboxes = features.BoundingBox(
[[2, 0, 206, 253], [396, 92, 479, 241], [328, 253, 417, 332],
[148, 68, 256, 182], [93, 158, 170, 260], [432, 0, 438, 26],
[422, 0, 480, 25], [419, 39, 424, 52], [448, 37, 456, 62],
[435, 43, 437, 50], [461, 36, 469, 63], [461, 75, 469, 94],
[469, 36, 480, 64], [440, 37, 446, 56], [398, 233, 480, 304],
[452, 39, 463, 63], [424, 38, 429, 50]],
format=features.BoundingBoxFormat.XYXY,
spatial_size=F.get_spatial_size(img),
)
labels = features.Label([59, 58, 50, 64, 76, 74, 74, 74, 74, 74, 74, 74, 74, 74, 50, 74, 74])
# Defining and applying Transforms V2
trans = T.Compose(
[
T.ColorJitter(contrast=0.5),
T.RandomRotation(30),
T.CenterCrop(480),
]
)
img, bboxes, labels = trans(img, bboxes, labels)
# Visualizing results
viz = utils.draw_bounding_boxes(F.to_image_tensor(img), boxes=bboxes)
F.to_pil_image(viz).show()
```
but found that `torchvision.prototype.features` is now gone. What's the current way to run this? I attempted to simply pass the images, bboxes and labels with the following types: `torchvision.prototype.datasets.utils._encoded.EncodedImage`, `torchvision.prototype.datapoints._bounding_box.BoundingBox`, `torchvision.prototype.datapoints._label.Label`. However this didn't seem to apply the transforms as everything remained the same shape.
**edit:** I've found that `features` seems to be renamed to `datapoints`. I tried applying this, but `EncodedImage` in a coco `sample['image']` seems to be 1D and `prototype.transforms` requires 2D images. What's the proper way to get this as 2D so I can apply transforms? Is there a decode method I'm missing?
### Suggest a potential alternative/fix
_No response_
cc @vfdev-5 @bjuncek @pmeier
|
https://github.com/pytorch/vision/issues/7168
|
closed
|
[
"question",
"module: transforms",
"prototype"
] | 2023-02-02T15:47:41Z
| 2023-02-02T21:11:35Z
| null |
austinmw
|
pytorch/TensorRT
| 1,645
|
❓ [Question] How to use Torch-TensorRT with multi-headed (multiple output) networks
|
## ❓ Question
I am having trouble using Torch-TensorRT with multi-headed networks. `torch_tensorrt.compile(...)` works fine and I can successfully use the resulting `ScriptModule` for execution. However, when I try to save and re-load the module I receive a RuntimeError on `torch.jit.load(...)`:
```
Traceback (most recent call last):
File "/home/burak/test.py", line 33, in <module>
net_trt = torch.jit.load('net_trt.ts')
File "/home/burak/miniconda3/envs/convert/lib/python3.9/site-packages/torch/jit/_serialization.py", line 162, in load
cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
RuntimeError: [Error thrown at core/runtime/TRTEngine.cpp:132] Expected (binding_name == engine_binded_name) to be true but got false
Could not find a TensorRT engine binding for output named output_0
```
## What you have already tried
I have tried this behavior with a very simple multi-headed network:
```python
import torch
import torch_tensorrt
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv0 = torch.nn.Conv2d(3, 8, kernel_size=3)
self.relu = torch.nn.ReLU(inplace=True)
self.conv1b1 = torch.nn.Conv2d(8, 16, kernel_size=3)
self.conv1b2 = torch.nn.Conv2d(8, 32, kernel_size=3)
def forward(self, x):
x = self.conv0(x)
x = self.relu(x)
output1 = self.conv1b1(x)
output2 = self.conv1b2(x)
return output1, output2
net = Net().eval().cuda()
```
Then, I have compiled this network for TensorRT as usual:
```python
net_specs = {
'inputs': [torch_tensorrt.Input(shape=[1, 3, 224, 224], dtype=torch.float32)],
'enabled_precisions': {torch.float32, torch.half},
}
net_trt = torch_tensorrt.compile(net, **net_specs)
```
No problem so far. `net_trt` works just fine. However, when I try to save and re-load it:
```python
torch.jit.save(net_trt, 'net_trt.ts')
net_trt = torch.jit.load('net_trt.ts')
```
I receive the following RuntimeError:
```
Traceback (most recent call last):
File "/home/burak/test.py", line 33, in <module>
net_trt = torch.jit.load('net_trt.ts')
File "/home/burak/miniconda3/envs/convert/lib/python3.9/site-packages/torch/jit/_serialization.py", line 162, in load
cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
RuntimeError: [Error thrown at core/runtime/TRTEngine.cpp:132] Expected (binding_name == engine_binded_name) to be true but got false
Could not find a TensorRT engine binding for output named output_0
```
I have only encountered this with multi-headed networks. Everything seems to work fine with other type of networks.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- Torch-TensorRT Version (e.g. 1.0.0): 1.3.0
- PyTorch Version (e.g., 1.0): 1.13.1
- CPU Architecture: x86_64
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.9.15
- CUDA version: 11.7
- GPU models and configuration: NVIDIA GeForce RTX 3070 (Laptop)
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/1645
|
closed
|
[
"question",
"bug: triaged [verified]"
] | 2023-02-02T13:05:35Z
| 2023-02-03T19:58:34Z
| null |
kunkcu
|
huggingface/dataset-viewer
| 762
|
Handle the case where the DatasetInfo is too big
|
In the /parquet-and-dataset-info processing step, if DatasetInfo is over 16MB, we will not be able to store it in MongoDB (https://pymongo.readthedocs.io/en/stable/api/pymongo/errors.html#pymongo.errors.DocumentTooLarge). We have to handle this case, and return a clear error to the user.
See https://huggingface.slack.com/archives/C04L6P8KNQ5/p1675332303097889 (internal). It's a similar issue to https://github.com/huggingface/datasets-server/issues/731 (should be raised for that dataset, btw)
|
https://github.com/huggingface/dataset-viewer/issues/762
|
closed
|
[
"bug"
] | 2023-02-02T10:25:19Z
| 2023-02-13T13:48:06Z
| null |
severo
|
huggingface/datasets
| 5,494
|
Update audio installation doc page
|
Our [installation documentation page](https://huggingface.co/docs/datasets/installation#audio) says that one can use Datasets for mp3 only with `torchaudio<0.12`. `torchaudio>0.12` is actually supported too but requires a specific version of ffmpeg which is not easily installed on all linux versions but there is a custom ubuntu repo for it, we have insctructions in the code: https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L327
So we should update the doc page. But first investigate [this issue](5488).
|
https://github.com/huggingface/datasets/issues/5494
|
closed
|
[
"documentation"
] | 2023-02-01T19:07:50Z
| 2023-03-02T16:08:17Z
| 4
|
polinaeterna
|
pytorch/pytorch
| 93,347
|
when I want to use a new backend, how to deal with the op with 'device' argument?
|
### 🐛 Describe the bug
Hi
I saw the generated code in python_torch_functionsEverything.cpp line 4763, there are so many tricks for the op with 'device' argument, such as init CUDA device, `torch::utils::maybe_initialize_cuda(options);`
```
static PyObject * THPVariable_arange(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"arange(Scalar end, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
"arange(Scalar start, Scalar end, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
"arange(Scalar start, Scalar end, Scalar step=1, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
}, /*traceable=*/true);
ParsedArgs<9> parsed_args;
auto _r = parser.parse(nullptr, args, kwargs, parsed_args);
if(_r.has_torch_function()) {
return handle_torch_function(_r, nullptr, args, kwargs, THPVariableFunctionsModule, "torch");
}
switch (_r.idx) {
case 0: {
if (_r.isNone(1)) {
// aten::arange(Scalar end, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=None) -> Tensor
const auto options = TensorOptions()
.dtype(_r.scalartypeOptional(2))
.device(_r.deviceWithDefault(4, torch::tensors::get_default_device()))
.layout(_r.layoutOptional(3))
.requires_grad(_r.toBool(6))
.pinned_memory(_r.toBool(5));
torch::utils::maybe_initialize_cuda(options);
```
when I want to use a new backend which also need to init like CUDA, so I want to add some code to make my backend running fine, It is that ok ?
thanks.
### Versions
new backend
python:3.7.5
pytorch: 2.0.0
CUDA: None
|
https://github.com/pytorch/pytorch/issues/93347
|
open
|
[
"triaged",
"module: backend"
] | 2023-01-31T09:34:00Z
| 2023-02-06T14:44:50Z
| null |
heidongxianhua
|
pytorch/TensorRT
| 1,638
|
Error when running Resnet50-CPP.ipynb, ./torchtrt_runtime_example: symbol lookup error: ./torchtrt_runtime_example: undefined symbol: _ZN2at4_ops11randint_low4callEllN3c108ArrayRefIlEENS2_8optionalINS2_10ScalarTypeEEENS5_INS2_6LayoutEEENS5_INS2_6DeviceEEENS5_IbEE
|
I was following this notebook on nvcr.io/nvidia/pytorch:22.12-py3, container make runs fine but this step fails. My host has nvidia-470, 11.4. I have tried multiple times but the same error.
|
https://github.com/pytorch/TensorRT/issues/1638
|
closed
|
[
"question",
"No Activity"
] | 2023-01-31T06:09:55Z
| 2023-05-13T00:02:12Z
| null |
akshayantony12
|
huggingface/diffusers
| 2,167
|
Im using jupyter notebook and every time it stacks ckpt file but I don't know where it is
|
every time I try using diffusers, it downloads all .bin files and ckpt files but it piles up somewhere in the server.
i thought it got piled up in anaconda3/env but it wasn't.
where would it downloads the files be? my server its full of memory:(
|
https://github.com/huggingface/diffusers/issues/2167
|
closed
|
[] | 2023-01-31T00:58:18Z
| 2023-02-02T02:51:10Z
| null |
jakeyahn
|
pytorch/TensorRT
| 1,631
|
Is NN inheritance possible?
|
So I have an application that I am enhancing; I really want to use the TensorRT backend as it's benchmarks are just brilliant; however, I cannot see a way one would go about using inheritance: eg ``class MyFancyEncoder(tensor_compiled_resnet_passing_torch.nn)``
Example here: https://pastebin.com/nTdTfFnZ
Versus here: https://pastebin.com/L0YyKg9H
|
https://github.com/pytorch/TensorRT/issues/1631
|
closed
|
[
"question"
] | 2023-01-30T23:43:51Z
| 2023-01-31T21:14:03Z
| null |
manbehindthemadness
|
huggingface/datasets
| 5,475
|
Dataset scan time is much slower than using native arrow
|
### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that explains this phenomenon?
### Steps to reproduce the bug
https://colab.research.google.com/drive/11EtHDaGAf1DKCpvYnAPJUW-LFfAcDzHY?usp=sharing
### Expected behavior
I expect scan times to be on par with using pyarrow directly.
### Environment info
standard colab environment
|
https://github.com/huggingface/datasets/issues/5475
|
closed
|
[] | 2023-01-27T01:32:25Z
| 2023-01-30T16:17:11Z
| 3
|
jonny-cyberhaven
|
pytorch/data
| 965
|
Correct way to shuffle, batch and shard WebDataset
|
### 📚 The doc issue
Hi, the [docs on the WebDataset decoder](https://pytorch.org/data/main/generated/torchdata.datapipes.iter.WebDataset.html) give the following example:
```python
>>> from torchdata.datapipes.iter import FileLister, FileOpener
>>>
>>> def decode(item):
>>> key, value = item
>>> if key.endswith(".txt"):
>>> return key, value.read().decode("utf-8")
>>> if key.endswith(".bin"):
>>> return key, value.read().decode("utf-8")
>>>
>>> datapipe1 = FileLister("test/_fakedata", "wds*.tar")
>>> datapipe2 = FileOpener(datapipe1, mode="b")
>>> dataset = datapipe2.load_from_tar().map(decode).webdataset()
>>> for obj in dataset:
>>> print(obj)
```
However this doesn't include demonstrating the proper location for shuffling, sharding and batching the dataset.
### Suggest a potential alternative/fix
Could you please let me know where to place `.shuffle`, `.batch` and `.sharding_filter` in this pipeline?
|
https://github.com/meta-pytorch/data/issues/965
|
closed
|
[
"documentation",
"good first issue"
] | 2023-01-25T16:25:40Z
| 2023-01-25T17:51:57Z
| 4
|
austinmw
|
huggingface/setfit
| 289
|
[question]: creating a custom dataset class like `sst` to fit into `setfit`, throws `Cannot index by location index with a non-integer key`
|
I'm trying to experiment with PyTorch some model; the dataset they were using for the experiment is [`sst`][1]
But I'm also learning PyTorch, so I thought it would be better to play with `Dataset` class and create my own dataset.
So this was my approach:
```
class CustomDataset(Dataset):
def __init__(self, dataframe):
self.dataframe = dataframe
self.column_names = ['text','label']
def __getitem__(self, index):
print('index: ',index)
row = self.dataframe.iloc[index].to_numpy()
features = row[1:]
label = row[0]
return features, label
def __len__(self):
return len(self.dataframe)
df = pd.DataFrame(np.array([
["hello", 0] ,
["sex", 1] ,
["beshi kore sex", 1],]),
columns=['text','label'])
dataset = CustomDataset(dataframe=df)
```
Instead of creating sub-categories like validation/test/train, I'm just trying to create one custom `Dataset` class at first.
And it keeps giving me **`Cannot index by location index with a non-integer key`** During conceptual development, I tried this: `df.iloc[0].to_numpy()`, and it works absolutely fine. But it's sending `index: text` for some reason. I even tried putting an 'id' column.
But I'm sure that there must be some other way to achieve this. **_How can I resolve this issue?_** As my code worked fine for sst, as this not working any longer. I'm pretty sure, this is not one to one mapping.
Complete code:
```
#!pip install sentence_transformers -q
#!pip install setfit -q
from sentence_transformers.losses import CosineSimilarityLoss
from torch.utils.data import Dataset
import pandas as pd
import numpy as np
from setfit import SetFitModel, SetFitTrainer, sample_dataset
class CustomDataset(Dataset):
def __init__(self, dataframe):
self.dataframe = dataframe
self.column_names = ['id','text','label']
def __getitem__(self, index):
print('index: ',index)
row = self.dataframe.iloc[index].to_numpy()
features = row[1:]
label = row[0]
return features, label
def __len__(self):
return len(self.dataframe)
df = pd.DataFrame(np.array([ [1,"hello", 0] ,
[2,"sex", 1] ,
[3,"beshi kore sex", 1],]),columns=['id','text','label'])
# df.head()
dataset = CustomDataset(dataframe=df)
# Load a dataset from the Hugging Face Hub
# dataset = load_dataset("sst2") # HERE, previously I was simply using sst/sst2
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = dataset
eval_dataset = dataset
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=1, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for contrastive learning
)
# Train and evaluate
trainer.train()
```
[1]: https://pytorch.org/text/_modules/torchtext/datasets/sst.html
|
https://github.com/huggingface/setfit/issues/289
|
closed
|
[
"question"
] | 2023-01-25T10:22:35Z
| 2023-01-27T15:53:44Z
| null |
maifeeulasad
|
huggingface/transformers
| 21,287
|
[docs] TrainingArguments default label_names is not what is described in the documentation
|
### System Info
- `transformers` version: 4.25.1
- Platform: macOS-12.6.1-arm64-arm-64bit
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger, @stevhliu and @MKhalusova
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Create a model with a `forward` that has more than one label. For example:
```
def forward(
self,
input_ids,
bbox,
attention_mask,
token_type_ids,
labels,
reference_labels
)
```
2. Create a trainer for your model with `trainer = Trainer(model, ...)`. Make sure to not set `label_names` and let it default.
3. Check `trainer.label_names` and see that it returns `["labels", "reference_labels"]`
### Expected behavior
[The documentation](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.label_names) states that:
> Will eventually default to ["labels"] except if the model used is one of the XxxForQuestionAnswering in which case it will default to ["start_positions", "end_positions"].
[This PR](https://github.com/huggingface/transformers/pull/16526) changed the behaviour that the documentation describes.
|
https://github.com/huggingface/transformers/issues/21287
|
closed
|
[] | 2023-01-24T18:24:47Z
| 2023-01-24T19:48:26Z
| null |
fredsensibill
|
pytorch/cpuinfo
| 131
|
How to cross-compile pytorch-cpuinfo?
|
Hi!
First a bit of context. I'm trying to build onnxruntime for raspberry pi using cross-compilation ([instructions here](https://onnxruntime.ai/docs/build/inferencing.html#cross-compiling-on-linux)). The onnxruntime package depends on pytorch-cpuinfo and fetches and builds it as part of the build process.
I'm using this command.
```shell
VERBOSE=1 ./build.sh --config Release --build_shared_lib --arm --update --build --path_to_protoc_exe /build/bin/protoc
```
This triggers the following error:
```shell
[...]
[ 66%] Building C object _deps/pytorch_cpuinfo-build/CMakeFiles/cpuinfo.dir/src/x86/init.c.o
cd /build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-build && /usr/bin/arm-linux-gnueabihf-gcc -DCPUINFO_LOG_LEVEL=2 -DEIGEN_MPL2_ONLY -DORT_ENABLE_STREAM -D_GNU_SOURCE=1 -I/build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/src -I/build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/include -I/build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/deps/clog/include -ffunction-sections -fdata-sections -Wno-error=attributes -O3 -DNDEBUG -fPIC -std=c99 -MD -MT _deps/pytorch_cpuinfo-build/CMakeFiles/cpuinfo.dir/src/x86/init.c.o -MF CMakeFiles/cpuinfo.dir/src/x86/init.c.o.d -o CMakeFiles/cpuinfo.dir/src/x86/init.c.o -c /build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/src/x86/init.c
In file included from /build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/src/x86/init.c:5:
/build/onnxruntime/build/Linux/Release/_deps/pytorch_cpuinfo-src/src/x86/cpuid.h:5:11: fatal error: cpuid.h: No such file or directory
5 | #include <cpuid.h>
| ^~~~~~~~~
compilation terminated.
gmake[2]: *** [_deps/pytorch_cpuinfo-build/CMakeFiles/cpuinfo.dir/build.make:118: _deps/pytorch_cpuinfo-build/CMakeFiles/cpuinfo.dir/src/x86/init.c.o] Error 1
gmake[2]: Leaving directory '/build/onnxruntime/build/Linux/Release'
gmake[1]: *** [CMakeFiles/Makefile2:5506: _deps/pytorch_cpuinfo-build/CMakeFiles/cpuinfo.dir/all] Error 2
gmake[1]: Leaving directory '/build/onnxruntime/build/Linux/Release'
[...]
```
My take on this is that pytorch-cpuinfo errorneously tries to compile for x86 (the host for the cross-compile).
Looking at the CMakeList.txt in this project, I think the culprit is that it always assumes that the host architecture is also the target architecture: https://github.com/pytorch/cpuinfo/blob/3dc310302210c1891ffcfb12ae67b11a3ad3a150/CMakeLists.txt#L59
Would love to hear if I'm doing something wrong. Or if I can submit a PR for this to allow to override the target architecture from the environment variables.
|
https://github.com/pytorch/cpuinfo/issues/131
|
closed
|
[] | 2023-01-24T09:25:31Z
| 2023-01-27T13:02:24Z
| null |
pietermarsman
|
pytorch/data
| 959
|
Tables in Documentation not rendering properly
|
### 📚 The doc issue
Compared to the last release, the tables in the documentation of the `main` branch is rendering differently. I do not recall any intentional changes to the format of our documentation or generation. We should have a look at this before the next release.
Before (0.5.1):
<img width="886" alt="Screenshot 2023-01-23 at 3 14 36 PM" src="https://user-images.githubusercontent.com/4935152/214140520-f2a78f1b-84c1-4b02-a1a9-d43c15019340.png">
Current (main):
<img width="947" alt="Screenshot 2023-01-23 at 3 14 45 PM" src="https://user-images.githubusercontent.com/4935152/214140549-8917d8fe-8483-4bb6-85d9-4cb0b9162cf7.png">
|
https://github.com/meta-pytorch/data/issues/959
|
closed
|
[
"documentation",
"good first issue"
] | 2023-01-23T20:14:52Z
| 2023-02-02T14:38:24Z
| 8
|
NivekT
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.