|
--- |
|
language: |
|
- id |
|
- su |
|
- ja |
|
- jv |
|
- min |
|
- br |
|
- ga |
|
- es |
|
- pt |
|
- 'no' |
|
- mn |
|
- ms |
|
- zh |
|
- ko |
|
- ta |
|
- ben |
|
- si |
|
- bg |
|
- ro |
|
- ru |
|
- am |
|
- orm |
|
- ar |
|
- ig |
|
- hi |
|
- mr |
|
size_categories: |
|
- 10K<n<100K |
|
task_categories: |
|
- question-answering |
|
pretty_name: cvqa |
|
dataset_info: |
|
features: |
|
- name: image |
|
dtype: image |
|
- name: ID |
|
dtype: string |
|
- name: Subset |
|
dtype: string |
|
- name: Question |
|
dtype: string |
|
- name: Translated Question |
|
dtype: string |
|
- name: Options |
|
sequence: string |
|
- name: Translated Options |
|
sequence: string |
|
- name: Label |
|
dtype: int64 |
|
- name: Category |
|
dtype: string |
|
- name: Image Type |
|
dtype: string |
|
- name: Image Source |
|
dtype: string |
|
- name: License |
|
dtype: string |
|
splits: |
|
- name: test |
|
num_bytes: 4778972036.042 |
|
num_examples: 10374 |
|
download_size: 4952302684 |
|
dataset_size: 4778972036.042 |
|
configs: |
|
- config_name: default |
|
data_files: |
|
- split: test |
|
path: data/test-* |
|
--- |
|
|
|
# About CVQA |
|
|
|
|
|
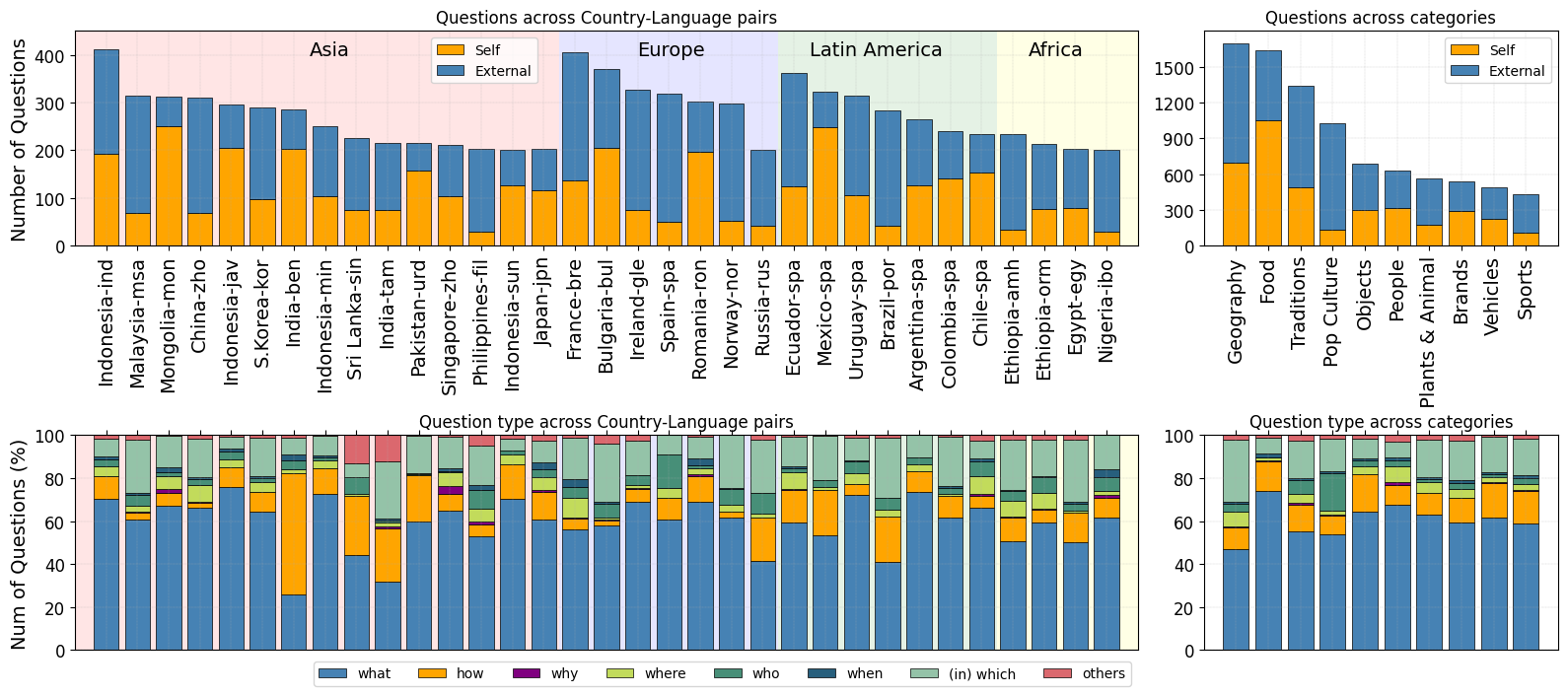
[CVQA](https://arxiv.org/pdf/2406.05967) is a culturally diverse multilingual VQA benchmark consisting of over 10,000 questions from 39 country-language pairs. The questions in CVQA are written in both the native languages and English, and are categorized into 10 diverse categories. |
|
|
|
This data is designed for use as a test set. Please [submit your submission here](https://eval.ai/web/challenges/challenge-page/2305/) to evaluate your model performance. CVQA is constructed through a collaborative effort led by a team of researchers from MBZUAI. [Read more about CVQA in this paper](https://arxiv.org/pdf/2406.05967). |
|
|
|
 |
|
|
|
# Dataset Structure |
|
|
|
## Data Instances |
|
|
|
An example of `test` looks as follows: |
|
``` |
|
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=2048x1536 at 0x7C3E0EBEEE00>, |
|
'ID': '5919991144272485961_0', |
|
'Subset': "('Japanese', 'Japan')", |
|
'Question': '写真に写っているキャラクターの名前は? ', |
|
'Translated Question': 'What is the name of the object in the picture? ', |
|
'Options': ['コスモ星丸', 'ミャクミャク', ' フリービー ', 'ハイバオ'], |
|
'Translated Options': ['Cosmo Hoshimaru','MYAKU-MYAKU','Freebie ','Haibao'], |
|
'Label': -1, |
|
'Category': 'Objects / materials / clothing', |
|
'Image Type': 'Self', |
|
'Image Source': 'Self-open', |
|
'License': 'CC BY-SA' |
|
} |
|
``` |
|
|
|
Data Fields |
|
|
|
The data fields are: |
|
- `image`: The image referenced by the question. |
|
- `ID`: A unique ID for the given sample. |
|
- `Subset`: A Language-Country pair |
|
- `Question`: The question elicited in the local language. |
|
- `Translated Question`: The question elicited in the English language. |
|
- `Options`: A list of possible answers to the question in the Local Language. |
|
- `Translated Options`: A list of possible answers to the question in the English Language. |
|
- `Label`: Will always be -1. Please refer to our leaderboard to get your performance. |
|
- `Category`: A specific category for the given sample. |
|
- `Image Type`: `Self` or `External`, meaning if the image is self-taken from the annotator or comes from the internet. |
|
- `Image Source`: If the image type is Self, this can be `Self-open` or `Self-research_only`, meaning that the image can be used for commercial purposes or only for research purposes. If the image type is External, this will be the link to the external source. |
|
- `License`: The corresponding license for the image. |
|
|
|
|
|
# Dataset Creation |
|
|
|
## Source Data |
|
|
|
The images in CVQA can either be based on existing external images or from the contributor's own images. You can see this information from the 'Image Type' and 'Image Source' columns. Images based on external sources will retain their original licensing, whereas images from contributors will be licensed based on each contributor's decision. |
|
|
|
All the questions are hand-crafted by annotators. |
|
|
|
## Data Annotation |
|
|
|
Data creation follows two general steps: question formulation and validation. |
|
During question formulation, annotators are asked to write a question, with one correct answer and three distractors. |
|
Questions must be culturally nuanced and relevant to the image. Annotators are asked to mask sensitive information and text that can easily give away the answers. |
|
During data validation, another annotator is asked to check and validate whether the images and questions adhere to the guidelines. |
|
|
|
You can learn more about our annotation protocol and guidelines in our paper. |
|
|
|
## Annotators |
|
|
|
Annotators needed to be fluent speakers of the language in question and be accustomed to the cultures of the locations for which they provided data. Our annotators are predominantly native speakers, with around 89% residing in the respective country for over 16 years. |
|
|
|
## Licensing Information |
|
|
|
Note that each question has its own license. All data here is free to use for research purposes, but not every entry is permissible for commercial use. |
|
|
|
--- |
