metadata
license: cc-by-nc-4.0
task_categories:
- text-to-video
language:
- en
size_categories:
- 1M<n<10M
tags:
- prompts
- text-to-video

Summary
This is the dataset proposed in our paper "VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models"
VidProM is the first dataset featuring 1.67 million unique text-to-video prompts and 6.69 million videos generated from 4 different state-of-the-art diffusion models. It inspires many exciting new research areas, such as Text-to-Video Prompt Engineering, Efficient Video Generation, Fake Video Detection, and Video Copy Detection for Diffusion Models.
Directory
*DATA_PATH
*original_files
*generate_1_ori.html
*generate_2_ori.html
...
*pika_videos
*pika_videos_1.tar
*pika_videos_2.tar
...
*vc2_videos
*vc2_videos_1.tar
*vc2_videos_2.tar
...
*t2vz_videos
*t2vz_videos_1.tar
*t2vz_videos_2.tar
...
*ms_videos
*ms_videos_1.tar
*ms_videos_2.tar
...
*VidProM_unique.csv
*VidProM_semantic_unique.csv
*VidProM_embed.hdf5
Download
Automatically
Install the datasets library first, by:
pip install datasets
Then it can be downloaded automatically with
import numpy as np
from datasets import load_dataset
dataset = load_dataset('WenhaoWang/VidProM')
Manual
You can download each file by wget, for instance:
wget https://huggingface.co/datasets/WenhaoWang/VidProM/resolve/main/VidProM_unique.csv
Explanation
Datapoint

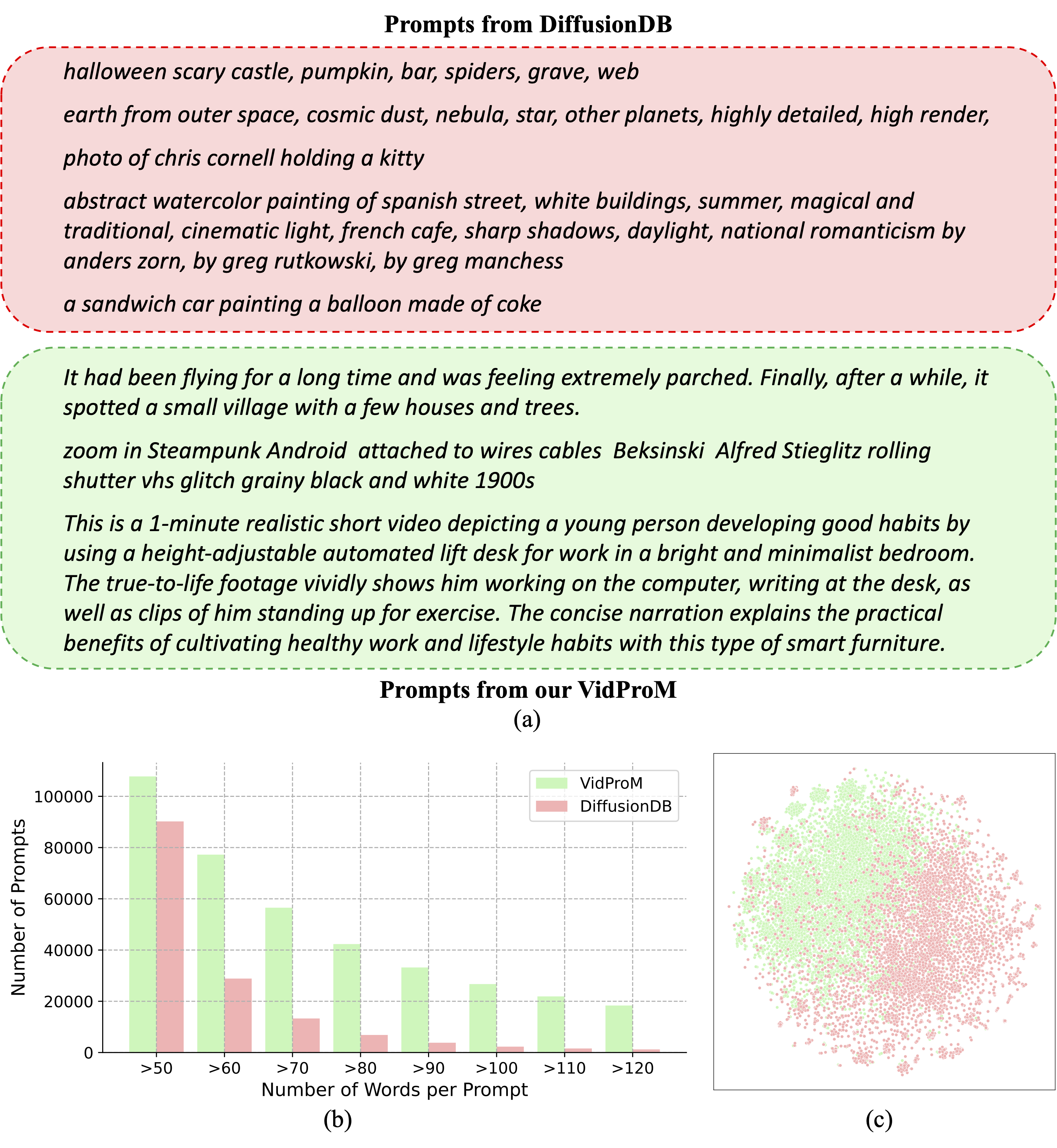
Comparison with DiffusionDB