|
--- |
|
dataset_info: |
|
features: |
|
- name: text_id |
|
dtype: string |
|
- name: page_url |
|
dtype: string |
|
- name: page_title |
|
dtype: string |
|
- name: section_title |
|
dtype: string |
|
- name: context_page_description |
|
dtype: string |
|
- name: context_section_description |
|
dtype: string |
|
- name: media |
|
sequence: string |
|
- name: hierachy |
|
sequence: string |
|
- name: category |
|
sequence: string |
|
- name: source_id |
|
dtype: string |
|
splits: |
|
- name: train |
|
num_bytes: 18109.758012141203 |
|
num_examples: 9 |
|
download_size: 61847 |
|
dataset_size: 18109.758012141203 |
|
--- |
|
|
|
We are now releasing the topics for model development for TREC-AToMiC. These topics are an addition on top of the validation set of AToMiC and aim to be closer to what you should expect for the task. The main difference is that they have a pooled set of annotations, leading to a richer annotation compared to the validation set. However, in order to achieve this richer annotation, there are way less queries (only 13) that have been selected to showcase different attributes of retrievers. |
|
|
|
We note that the topics do not represent exactly what will be the final task (we will aim for topics that are more important to wikipedia), but more in a way that they were: a) Easy to annotate and b) Could show some important factor, such as topics from the AToMiC training set, but that the linked image is very different from others that may be found in the original AToMiC corpus. The 13 topics are divided into 4 areas: |
|
|
|
### TV/Cinema |
|
|
|
We choose the five following topics: Goldfinger (Cast and Plot), Space Jam (Cast), Friends (Premise), How I met your Mother (Premise) |
|
|
|
Here we want to see if the model can find simple information (e.g. photos of cast members that we now have photos on wikimedia), but also look into something more complicated (plot points for GoldFinger). There's also the idea of checking if the retriever will look into the Section as it is the goal of AToMiC and not pages (thus Cast and Plot should have very different results for Goldfinger). |
|
|
|
### Soccer |
|
|
|
Three topics: Andrea Barzagli (Return to the national team: Euro 2012, 2013 Confederations Cup and 2014 World Cup), Manchester United (2013->Present and Ferguson years (1986–2013)). |
|
|
|
Again, we want to make sure that models are looking more at the section level (including years that things happened) than the passage level. All topics here were selected knowing that images for those topics exist in other languages |
|
|
|
### Transportation |
|
|
|
Again three topics: Emirates Airline (fleet), Flixbus (Europe) and List_of_Cadillac_vehicles |
|
|
|
We chose those topics because they are easy for MultiModal models (Salient Points on images/ Require OCR), but are not always easy for text-only models (e.g. Some flixbus images describe only the bus model, but not the fact that it belongs to Flixbus). |
|
|
|
### Geography/History |
|
|
|
Finally we also take two completely different topics: NIST () and Mutawakkilite_Kingdom_of_Yemen (introduction). The goal here was to pick something that not only was different from the ones before, but that also contain images that are not that present in traditional multimodal evaluation (e.g. Country maps, Schematics). |
|
|
|
## Baseline results |
|
|
|
In order to annotate the queries we ran 5 baselines (4 Multi-Modal and 1 textual only) and created 3 ensembles (all multi-modal, best multi-modal + text, all 5 baselines). Everything is ran in the TREC task scenario ("AToMiC large"). We took the top-10 of each of the 8 runs and annotated it, leading to 533 annotations (average of 41 unique results per query). We run several metrics and present the results below: |
|
|
|
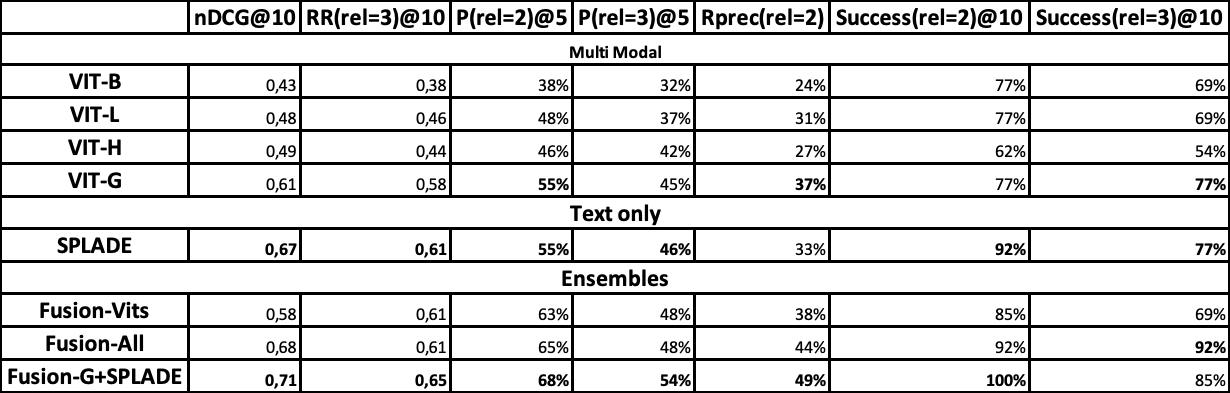 |
|
|
|
The first thing we notice is that the models are able to perform better than expected on this set of topics. Indeed, if we compare the RR@10 of ViT-G on the validation of AToMiC (0.074) with the one we obtained it is clear that the sparse annotations do not suffise for this task (we talk in more detail below looking at each topic individually). More-so, the gap between textual only models (such as SPLADE) and Multi-Modal is greatly reduced, especially on precision based metrics. Finally, we are able to see improvements using an ensemble of multi-modal and text-only models. |
|
|

