

Table of Contents
Dataset Description
- Repository: https://github.com/Orange-OpenSource/CoQAR/
- Paper: https://arxiv.org/abs/2207.03240
- Point of Contact: quentin.brabant@orange.com, gwenole.lecorve@orange.com, linamaria.rojasbarahona@orange.com
Dataset Summary
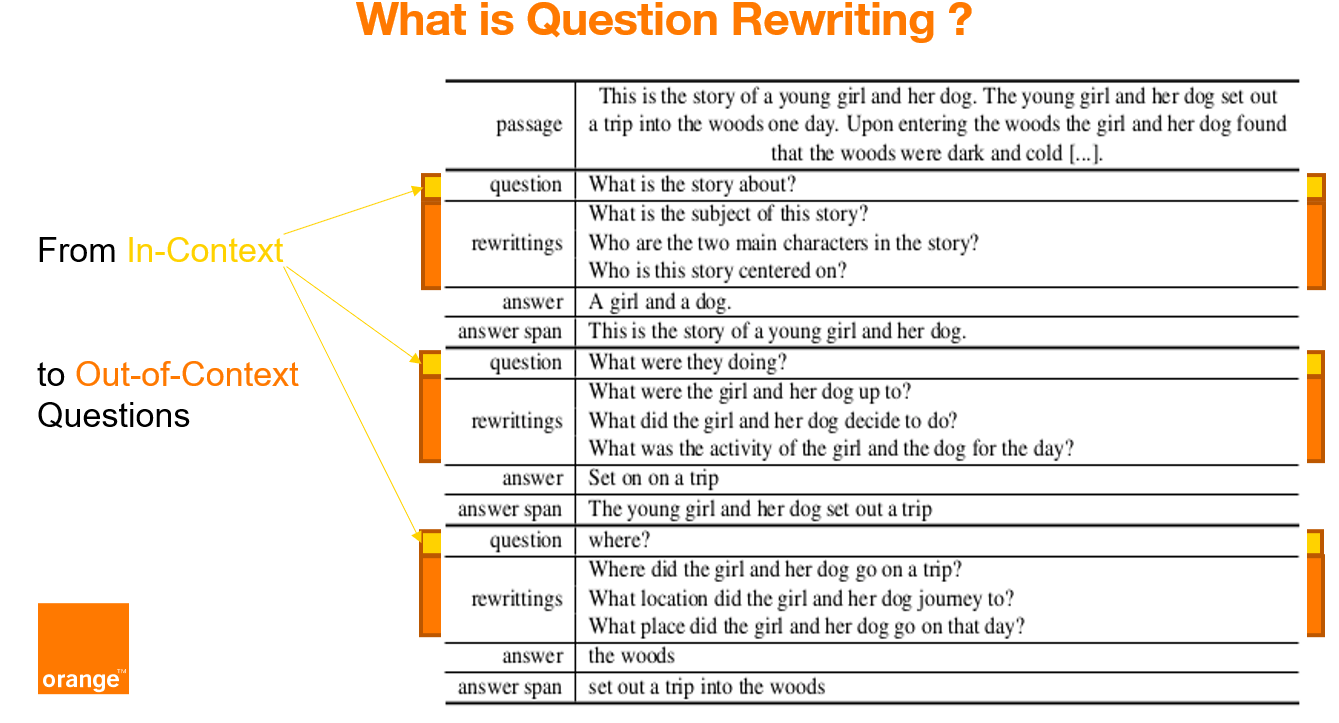
CoQAR is a corpus containing 4.5K conversations from the open-source dataset Conversational Question-Answering dataset CoQA, for a total of 53K follow-up question-answer pairs. In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
Languages
English.
Dataset Structure
The dataset is composed of several conversations. Each row correspond to one question of one conversation. The fields are the following:
- conversation_id
- turn_id: first question has turn id 0, second question has turn id 1, etc.
- original_question: string
- question_paraphrases : list of decontextualized rewrittings of the original question,
- answer: string, answer to the question,
- answer_span_start: start of the answer span (char number in the story),
- answer_span_end: end of the answer span (char number in the story),
- answer_span_text: string, excerpt of the story from answer_span_start to answer_span_end,
- conversation_history: list of strings corresponding to previous (original) questions and answers,
- file_name
- story: string providing context for the conversation, from which the answers can be deduced
- name
Additional Information
Licensing Information
The annotations are published under the licence CC-BY-SA 4.0. The original content of the dataset CoQA is under the distinct licences described below.
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
- Children's stories are collected from MCTest which comes with MSR-LA license.
- Middle/High school exam passages are collected from RACE which comes with its own license.
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015).
Citation Information
@inproceedings{brabant-etal-2022-coqar,
title = "{C}o{QAR}: Question Rewriting on {C}o{QA}",
author = "Brabant, Quentin and
Lecorv{\'e}, Gw{\'e}nol{\'e} and
Rojas Barahona, Lina M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.13",
pages = "119--126"
}