Datasets:

Tasks:
Fill-Mask
Sub-tasks:
masked-language-modeling
Languages:
English
Multilinguality:
monolingual
Size Categories:
100K<n<1M
Language Creators:
machine-generated
Annotations Creators:
no-annotation
License:

| annotations_creators: | |
| - no-annotation | |
| language: | |
| - en | |
| language_creators: | |
| - machine-generated | |
| license: | |
| - cc0-1.0 | |
| multilinguality: | |
| - monolingual | |
| pretty_name: Dataset Card for ERWT Hertiage Made Digital Newspapers training data | |
| size_categories: | |
| - 100K<n<1M | |
| source_datasets: [] | |
| tags: | |
| - library,lam,newspapers,1800-1900 | |
| task_categories: | |
| - fill-mask | |
| task_ids: | |
| - masked-language-modeling | |
| # Dataset Card for ERWT Hertiage Made Digital Newspapers training data | |
| ## Table of Contents | |
| - [Table of Contents](#table-of-contents) | |
| - [Dataset Description](#dataset-description) | |
| - [Dataset Summary](#dataset-summary) | |
| - [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards) | |
| - [Languages](#languages) | |
| - [Dataset Structure](#dataset-structure) | |
| - [Data Instances](#data-instances) | |
| - [Data Fields](#data-fields) | |
| - [Data Splits](#data-splits) | |
| - [Dataset Creation](#dataset-creation) | |
| - [Curation Rationale](#curation-rationale) | |
| - [Source Data](#source-data) | |
| - [Annotations](#annotations) | |
| - [Personal and Sensitive Information](#personal-and-sensitive-information) | |
| - [Considerations for Using the Data](#considerations-for-using-the-data) | |
| - [Social Impact of Dataset](#social-impact-of-dataset) | |
| - [Discussion of Biases](#discussion-of-biases) | |
| - [Other Known Limitations](#other-known-limitations) | |
| - [Additional Information](#additional-information) | |
| - [Dataset Curators](#dataset-curators) | |
| - [Licensing Information](#licensing-information) | |
| - [Citation Information](#citation-information) | |
| - [Contributions](#contributions) | |
| ## Dataset Description | |
| - **Homepage:** | |
| - **Repository:** | |
| - **Paper:** | |
| - **Leaderboard:** | |
| - **Point of Contact:** | |
| ### Dataset Summary | |
| This dataset contains text extracted at the page level from historic digitised newspapers from the [Heritage Made Digital](https://bl.iro.bl.uk/collections/9a6a4cdd-2bfe-47bb-8c14-c0a5d100501f?locale=en) newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870. | |
| The data was primarily created as a dataset for training 'time-aware' language models. | |
| The dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software. | |
| #### Breakdown of word counts over time | |
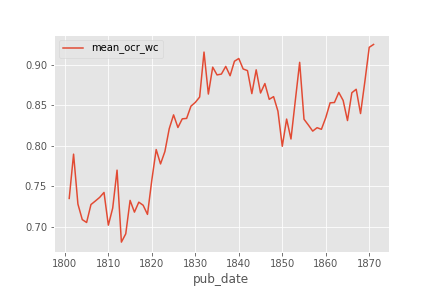
| Whilst the dataset covers a time period between 1800 and 1870, the number of words in the dataset is not distributed evenly across time in this dataset. The figures below give a sense of the breakdown over time in terms of the number of words which appear in the dataset. | |
| | year | total word_count | unique words | | |
| |-------:|-------------------:|---------------:| | |
| | 1800 | 282,554,255 | 15,506,515 | | |
| | 1810 | 328,817,174 | 18,295,974 | | |
| | 1820 | 328,817,174 | 18,295,974 | | |
| | 1830 | 194,958,624 | 10,816,938 | | |
| | 1840 | 305,545,086 | 17,018,560 | | |
| | 1850 | 376,194,785 | 20,942,876 | | |
| | 1860 | 305,545,086 | 17,018,560 | | |
| | 1870 | 51,241,037 | 2,284,803 | | |
|  | |
| ### Supported Tasks and Leaderboards | |
| [More Information Needed] | |
| ### Languages | |
| [More Information Needed] | |
| ## Dataset Structure | |
| ### Data Instances | |
| [More Information Needed] | |
| ### Data Fields | |
| [More Information Needed] | |
| ### Data Splits | |
| [More Information Needed] | |
| ## Dataset Creation | |
| ### Curation Rationale | |
| [More Information Needed] | |
| ### Source Data | |
| #### Initial Data Collection and Normalization | |
| [More Information Needed] | |
| #### Who are the source language producers? | |
| [More Information Needed] | |
| ### Annotations | |
| #### Annotation process | |
| [More Information Needed] | |
| #### Who are the annotators? | |
| [More Information Needed] | |
| ### Personal and Sensitive Information | |
| [More Information Needed] | |
| ## Considerations for Using the Data | |
| ### Social Impact of Dataset | |
| [More Information Needed] | |
| ### Discussion of Biases | |
|  | |
| [More Information Needed] | |
| ### Other Known Limitations | |
| [More Information Needed] | |
| ## Additional Information | |
| ### Dataset Curators | |
| [More Information Needed] | |
| ### Licensing Information | |
| [More Information Needed] | |
| ### Citation Information | |
| [More Information Needed] | |
| ### Contributions | |
| Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. | |