|
--- |
|
annotations_creators: |
|
- no-annotation |
|
language: |
|
- en |
|
language_creators: |
|
- machine-generated |
|
license: |
|
- cc0-1.0 |
|
multilinguality: |
|
- monolingual |
|
pretty_name: Dataset Card for ERWT Hertiage Made Digital Newspapers training data |
|
size_categories: |
|
- 100K<n<1M |
|
source_datasets: [] |
|
tags: |
|
- library,lam,newspapers,1800-1900 |
|
task_categories: |
|
- fill-mask |
|
task_ids: |
|
- masked-language-modeling |
|
--- |
|
|
|
# Dataset Card for ERWT Hertiage Made Digital Newspapers training data |
|
|
|
## Table of Contents |
|
- [Table of Contents](#table-of-contents) |
|
- [Dataset Description](#dataset-description) |
|
- [Dataset Summary](#dataset-summary) |
|
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards) |
|
- [Languages](#languages) |
|
- [Dataset Structure](#dataset-structure) |
|
- [Data Instances](#data-instances) |
|
- [Data Fields](#data-fields) |
|
- [Data Splits](#data-splits) |
|
- [Dataset Creation](#dataset-creation) |
|
- [Curation Rationale](#curation-rationale) |
|
- [Source Data](#source-data) |
|
- [Annotations](#annotations) |
|
- [Personal and Sensitive Information](#personal-and-sensitive-information) |
|
- [Considerations for Using the Data](#considerations-for-using-the-data) |
|
- [Social Impact of Dataset](#social-impact-of-dataset) |
|
- [Discussion of Biases](#discussion-of-biases) |
|
- [Other Known Limitations](#other-known-limitations) |
|
- [Additional Information](#additional-information) |
|
- [Dataset Curators](#dataset-curators) |
|
- [Licensing Information](#licensing-information) |
|
- [Citation Information](#citation-information) |
|
- [Contributions](#contributions) |
|
|
|
## Dataset Description |
|
|
|
- **Homepage:** |
|
- **Repository:** |
|
- **Paper:** |
|
- **Leaderboard:** |
|
- **Point of Contact:** |
|
|
|
### Dataset Summary |
|
|
|
|
|
#### Breakdown of word counts over time |
|
|
|
|
|
| year | total word_count | unique words | |
|
|-------:|-------------------:|---------------:| |
|
| 1810 | 328,817,174 | 18,295,974 | |
|
| 1830 | 194,958,624 | 10,816,938 | |
|
| 1870 | 51,241,037 | 2,284,803 | |
|
| 1860 | 305,545,086 | 17,018,560 | |
|
| 1850 | 376,194,785 | 20,942,876 | |
|
| 1800 | 282,554,255 | 15,506,515 | |
|
| 1820 | 328,817,174 | 18,295,974 | |
|
| 1840 | 305,545,086 | 17,018,560 | |
|
|
|
|
|
 |
|
|
|
|
|
|
|
[More Information Needed] |
|
|
|
### Supported Tasks and Leaderboards |
|
|
|
[More Information Needed] |
|
|
|
### Languages |
|
|
|
[More Information Needed] |
|
|
|
## Dataset Structure |
|
|
|
### Data Instances |
|
|
|
[More Information Needed] |
|
|
|
### Data Fields |
|
|
|
[More Information Needed] |
|
|
|
### Data Splits |
|
|
|
[More Information Needed] |
|
|
|
## Dataset Creation |
|
|
|
### Curation Rationale |
|
|
|
[More Information Needed] |
|
|
|
### Source Data |
|
|
|
#### Initial Data Collection and Normalization |
|
|
|
[More Information Needed] |
|
|
|
#### Who are the source language producers? |
|
|
|
[More Information Needed] |
|
|
|
### Annotations |
|
|
|
#### Annotation process |
|
|
|
[More Information Needed] |
|
|
|
#### Who are the annotators? |
|
|
|
[More Information Needed] |
|
|
|
### Personal and Sensitive Information |
|
|
|
[More Information Needed] |
|
|
|
## Considerations for Using the Data |
|
|
|
### Social Impact of Dataset |
|
|
|
[More Information Needed] |
|
|
|
### Discussion of Biases |
|
|
|
|
|
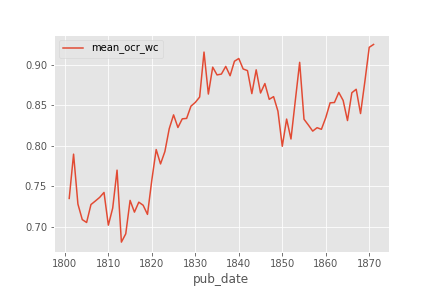 |
|
|
|
[More Information Needed] |
|
|
|
### Other Known Limitations |
|
|
|
[More Information Needed] |
|
|
|
## Additional Information |
|
|
|
### Dataset Curators |
|
|
|
[More Information Needed] |
|
|
|
### Licensing Information |
|
|
|
[More Information Needed] |
|
|
|
### Citation Information |
|
|
|
[More Information Needed] |
|
|
|
### Contributions |
|
|
|
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. |

