

Update README.md
Browse files
README.md
CHANGED
|
@@ -27,4 +27,6 @@ The model architecture is LLaMA-1.3B and we adopt the [OpenLLaMA](https://github
|
|
| 27 |
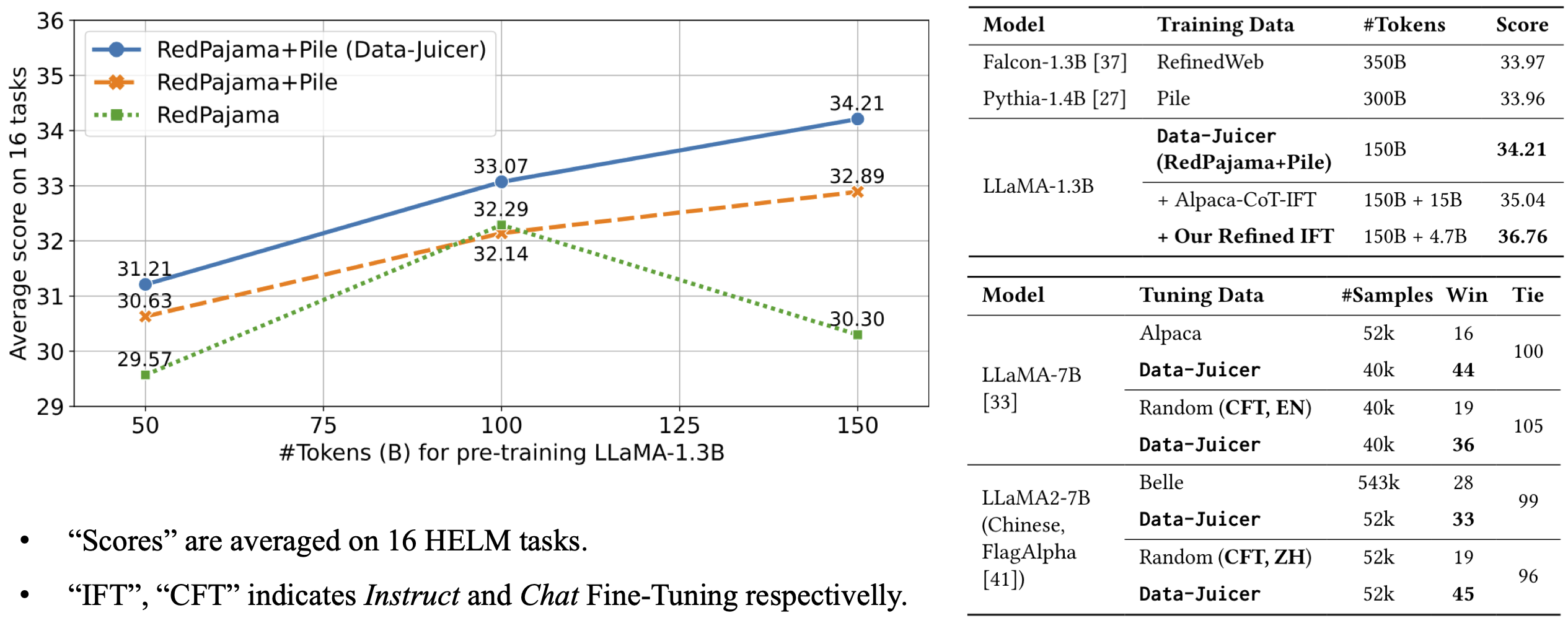
The model is pre-trained on 150B tokens of Data-Juicer's refined RedPajama and Pile.
|
| 28 |
It achieves an average score of 34.21 over 16 HELM tasks, beating Falcon-1.3B (trained on 350B tokens from RefinedWeb), Pythia-1.4B (trained on 300B tokens from original Pile) and Open-LLaMA-1.3B (trained on 150B tokens from original RedPajama and Pile).
|
| 29 |
|
| 30 |
-
For more details, please refer to our [paper](https://arxiv.org/abs/2309.02033).
|
|
|
|
|
|
|
|
|
| 27 |
The model is pre-trained on 150B tokens of Data-Juicer's refined RedPajama and Pile.
|
| 28 |
It achieves an average score of 34.21 over 16 HELM tasks, beating Falcon-1.3B (trained on 350B tokens from RefinedWeb), Pythia-1.4B (trained on 300B tokens from original Pile) and Open-LLaMA-1.3B (trained on 150B tokens from original RedPajama and Pile).
|
| 29 |
|
| 30 |
+
For more details, please refer to our [paper](https://arxiv.org/abs/2309.02033).
|
| 31 |
+
|
| 32 |
+
|