
codefuse-admin
commited on
Commit
·
f9e02c9
1
Parent(s):
aa0340b
init model
Browse files- CodeFuse-VLM-14B-performance.png +0 -0
- CodeFuse-VLM-arch.png +0 -0
- README.md +57 -3
- config.json +41 -0
- configuration_qwen.py +69 -0
- generation_config.json +11 -0
- modeling_qwen.py +1417 -0
- pytorch_model-00001-of-00003.bin +3 -0
- pytorch_model-00002-of-00003.bin +3 -0
- pytorch_model-00003-of-00003.bin +3 -0
- pytorch_model.bin.index.json +330 -0
- qwen.tiktoken +0 -0
- qwen_generation_utils.py +420 -0
- special_tokens_map.json +3 -0
- tokenization_qwen.py +590 -0
- tokenizer_config.json +11 -0
- training_args.bin +3 -0
CodeFuse-VLM-14B-performance.png
ADDED
|
CodeFuse-VLM-arch.png
ADDED

|
README.md
CHANGED
|
@@ -1,3 +1,57 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## CodeFuse-VLM
|
| 2 |
+
CodeFuse-VLM is a Multimodal LLM(MLLM) framework that provides users with multiple vision encoders, multimodal alignment adapters, and LLMs. Through CodeFuse-VLM framework, users are able to customize their own MLLM model to adapt their own tasks.
|
| 3 |
+
As more and more models are published on Huggingface community, there will be more open-source vision encoders and LLMs. Each of these models has their own specialties, e.g. Code-LLama is good at code-related tasks but has poor performance for Chinese tasks. Therefore, we built CodeFuse-VLM framework to support multiple vision encoders, multimodal alignment adapters, and LLMs to adapt different types of tasks.
|
| 4 |
+
<p align="center">
|
| 5 |
+
<img src="./CodeFuse-VLM-arch.png" width="50%" />
|
| 6 |
+
</p>
|
| 7 |
+
|
| 8 |
+
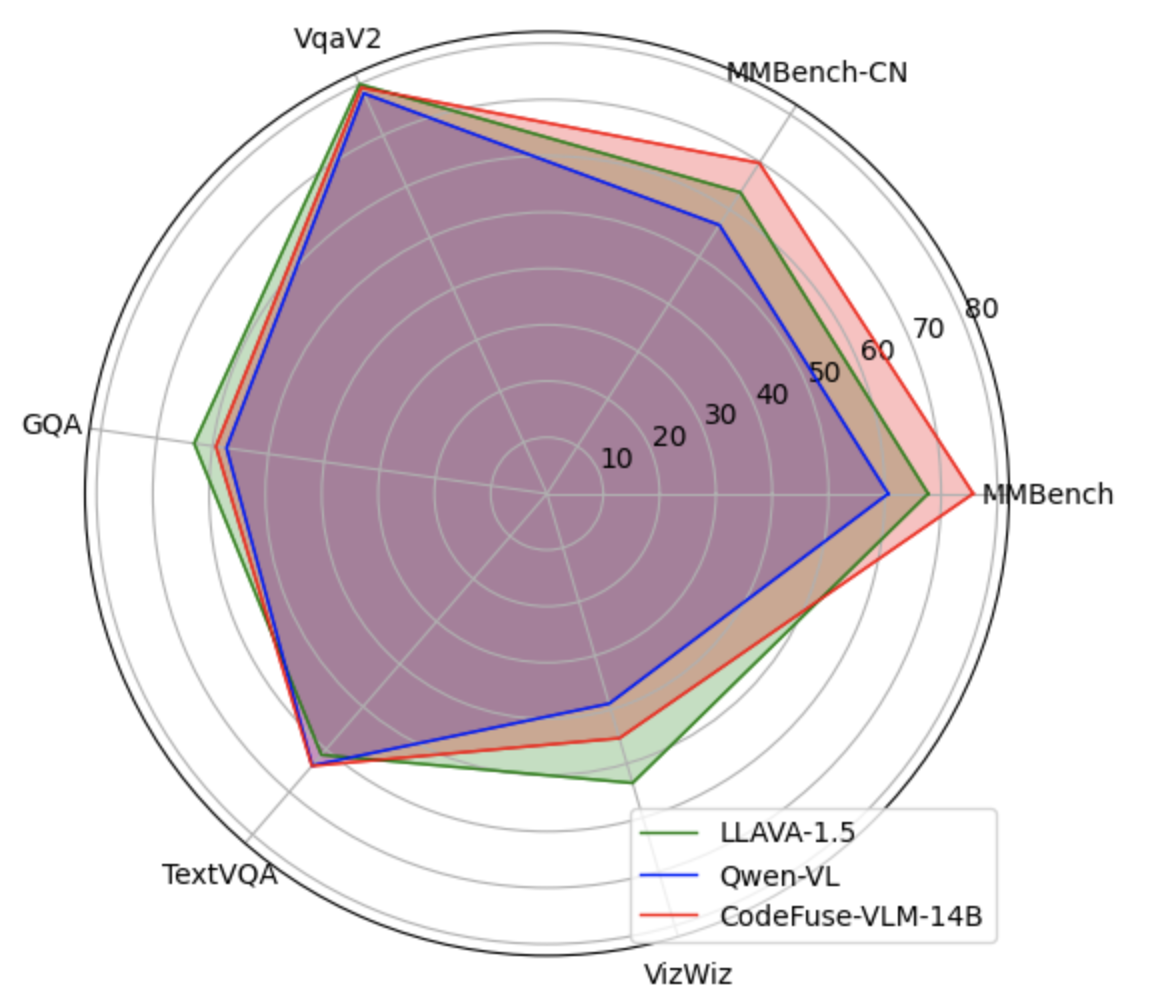
Under CodeFuse-VLM framework, we use cross attention multimodal adapter, Qwen-14B LLM, and Qwen-VL's vision encoder to train CodeFuse-VLM-14B model. On multiple benchmarks, our CodeFuse-VLM-14B shows superior performances over Qwen-VL and LLAVA-1.5.
|
| 9 |
+
|
| 10 |
+
<p align="center">
|
| 11 |
+
<img src="./CodeFuse-VLM-14B-performance.png" width="50%" />
|
| 12 |
+
</p>
|
| 13 |
+
|
| 14 |
+
Here is the table for different MLLM model's performance on benchmarks
|
| 15 |
+
Model | MMBench | MMBench-CN | VqaV2 | GQA | TextVQA | Vizwiz
|
| 16 |
+
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
|
| 17 |
+
LLAVA-1.5 | 67.7 | 63.6 | 80.0 | 63.3 | 61.3 | 53.6
|
| 18 |
+
Qwen-VL | 60.6 | 56.7 | 78.2 | 57.5 | 63.8 | 38.9
|
| 19 |
+
CodeFuse-VLM-14B | 75.7 | 69.8 | 79.3 | 59.4 | 63.9 | 45.3
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## Contents
|
| 23 |
+
- [Install](#Install)
|
| 24 |
+
- [Datasets](#Datasets)
|
| 25 |
+
- [Multimodal Alignment](#Multimodal-Alignment)
|
| 26 |
+
- [Visual Instruction Tuning](#Visual-Instruction-Tuning)
|
| 27 |
+
- [Evaluation](#Evaluation)
|
| 28 |
+
|
| 29 |
+
## Install
|
| 30 |
+
Please run sh init\_env.sh
|
| 31 |
+
|
| 32 |
+
## Datasets
|
| 33 |
+
Here's the table of datasets we used to train CodeFuse-VLM-14B:
|
| 34 |
+
|
| 35 |
+
Dataset | Task Type | Number of Samples
|
| 36 |
+
| ------------- | ------------- | ------------- |
|
| 37 |
+
synthdog-en | OCR | 800,000
|
| 38 |
+
synthdog-zh | OCR | 800,000
|
| 39 |
+
cc3m(downsampled)| Image Caption | 600,000
|
| 40 |
+
cc3m(downsampled)| Image Caption | 600,000
|
| 41 |
+
SBU | Image Caption | 850,000
|
| 42 |
+
Visual Genome VQA (Downsampled) | Visual Question Answer(VQA) | 500,000
|
| 43 |
+
Visual Genome Region descriptions (Downsampled) | Reference Grouding | 500,000
|
| 44 |
+
Visual Genome objects (Downsampled) | Grounded Caption | 500,000
|
| 45 |
+
OCR VQA (Downsampled) | OCR and VQA | 500,000
|
| 46 |
+
|
| 47 |
+
Please download these datasets on their own official websites.
|
| 48 |
+
|
| 49 |
+
## Multimodal Alignment
|
| 50 |
+
Please run sh scripts/pretrain.sh or sh scripts/pretrain\_multinode.sh
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Visual Instruction Tuning
|
| 54 |
+
Please run sh scripts/finetune.sh or sh scripts/finetune\_multinode.sh
|
| 55 |
+
|
| 56 |
+
## Evaluation
|
| 57 |
+
Please run python scrips in directory llava/eval/
|
config.json
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/mnt/user/laiyan/salesgpt/model/Qwen-14B-Chat-VL/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"QWenLMHeadModel"
|
| 5 |
+
],
|
| 6 |
+
"attn_dropout_prob": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_qwen.QWenConfig",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_qwen.QWenLMHeadModel"
|
| 10 |
+
},
|
| 11 |
+
"bf16": true,
|
| 12 |
+
"emb_dropout_prob": 0.0,
|
| 13 |
+
"fp16": false,
|
| 14 |
+
"fp32": false,
|
| 15 |
+
"hidden_size": 5120,
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 27392,
|
| 18 |
+
"kv_channels": 128,
|
| 19 |
+
"layer_norm_epsilon": 1e-06,
|
| 20 |
+
"max_position_embeddings": 8192,
|
| 21 |
+
"model_type": "qwen",
|
| 22 |
+
"no_bias": true,
|
| 23 |
+
"num_attention_heads": 40,
|
| 24 |
+
"num_hidden_layers": 40,
|
| 25 |
+
"onnx_safe": null,
|
| 26 |
+
"rotary_emb_base": 10000,
|
| 27 |
+
"rotary_pct": 1.0,
|
| 28 |
+
"scale_attn_weights": true,
|
| 29 |
+
"seq_length": 2048,
|
| 30 |
+
"tie_word_embeddings": false,
|
| 31 |
+
"tokenizer_class": "QWenTokenizer",
|
| 32 |
+
"torch_dtype": "float16",
|
| 33 |
+
"transformers_version": "4.32.0",
|
| 34 |
+
"use_cache": true,
|
| 35 |
+
"use_cache_kernel": false,
|
| 36 |
+
"use_cache_quantization": false,
|
| 37 |
+
"use_dynamic_ntk": true,
|
| 38 |
+
"use_flash_attn": true,
|
| 39 |
+
"use_logn_attn": true,
|
| 40 |
+
"vocab_size": 152064
|
| 41 |
+
}
|
configuration_qwen.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from transformers import PretrainedConfig
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class QWenConfig(PretrainedConfig):
|
| 10 |
+
model_type = "qwen"
|
| 11 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 12 |
+
|
| 13 |
+
def __init__(
|
| 14 |
+
self,
|
| 15 |
+
vocab_size=151936,
|
| 16 |
+
hidden_size=4096,
|
| 17 |
+
num_hidden_layers=32,
|
| 18 |
+
num_attention_heads=32,
|
| 19 |
+
emb_dropout_prob=0.0,
|
| 20 |
+
attn_dropout_prob=0.0,
|
| 21 |
+
layer_norm_epsilon=1e-6,
|
| 22 |
+
initializer_range=0.02,
|
| 23 |
+
max_position_embeddings=8192,
|
| 24 |
+
scale_attn_weights=True,
|
| 25 |
+
use_cache=True,
|
| 26 |
+
bf16=False,
|
| 27 |
+
fp16=False,
|
| 28 |
+
fp32=False,
|
| 29 |
+
kv_channels=128,
|
| 30 |
+
rotary_pct=1.0,
|
| 31 |
+
rotary_emb_base=10000,
|
| 32 |
+
use_dynamic_ntk=True,
|
| 33 |
+
use_logn_attn=True,
|
| 34 |
+
use_flash_attn="auto",
|
| 35 |
+
intermediate_size=22016,
|
| 36 |
+
no_bias=True,
|
| 37 |
+
tie_word_embeddings=False,
|
| 38 |
+
use_cache_quantization=False,
|
| 39 |
+
use_cache_kernel=False,
|
| 40 |
+
**kwargs,
|
| 41 |
+
):
|
| 42 |
+
self.vocab_size = vocab_size
|
| 43 |
+
self.hidden_size = hidden_size
|
| 44 |
+
self.intermediate_size = intermediate_size
|
| 45 |
+
self.num_hidden_layers = num_hidden_layers
|
| 46 |
+
self.num_attention_heads = num_attention_heads
|
| 47 |
+
self.emb_dropout_prob = emb_dropout_prob
|
| 48 |
+
self.attn_dropout_prob = attn_dropout_prob
|
| 49 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 50 |
+
self.initializer_range = initializer_range
|
| 51 |
+
self.scale_attn_weights = scale_attn_weights
|
| 52 |
+
self.use_cache = use_cache
|
| 53 |
+
self.max_position_embeddings = max_position_embeddings
|
| 54 |
+
self.bf16 = bf16
|
| 55 |
+
self.fp16 = fp16
|
| 56 |
+
self.fp32 = fp32
|
| 57 |
+
self.kv_channels = kv_channels
|
| 58 |
+
self.rotary_pct = rotary_pct
|
| 59 |
+
self.rotary_emb_base = rotary_emb_base
|
| 60 |
+
self.use_dynamic_ntk = use_dynamic_ntk
|
| 61 |
+
self.use_logn_attn = use_logn_attn
|
| 62 |
+
self.use_flash_attn = use_flash_attn
|
| 63 |
+
self.no_bias = no_bias
|
| 64 |
+
self.use_cache_quantization=use_cache_quantization
|
| 65 |
+
self.use_cache_kernel=use_cache_kernel
|
| 66 |
+
super().__init__(
|
| 67 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 68 |
+
**kwargs
|
| 69 |
+
)
|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_format": "chatml",
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": 151643,
|
| 5 |
+
"max_new_tokens": 512,
|
| 6 |
+
"max_window_size": 6144,
|
| 7 |
+
"pad_token_id": 151643,
|
| 8 |
+
"top_k": 0,
|
| 9 |
+
"top_p": 0.5,
|
| 10 |
+
"transformers_version": "4.32.0"
|
| 11 |
+
}
|
modeling_qwen.py
ADDED
|
@@ -0,0 +1,1417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import importlib
|
| 7 |
+
import math
|
| 8 |
+
from typing import TYPE_CHECKING, Optional, Tuple, Union, Callable, List, Any, Generator
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
import torch.utils.checkpoint
|
| 13 |
+
from torch.cuda.amp import autocast
|
| 14 |
+
|
| 15 |
+
from torch.nn import CrossEntropyLoss
|
| 16 |
+
from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList
|
| 17 |
+
from transformers.generation.logits_process import LogitsProcessorList
|
| 18 |
+
|
| 19 |
+
if TYPE_CHECKING:
|
| 20 |
+
from transformers.generation.streamers import BaseStreamer
|
| 21 |
+
from transformers.generation.utils import GenerateOutput
|
| 22 |
+
from transformers.modeling_outputs import (
|
| 23 |
+
BaseModelOutputWithPast,
|
| 24 |
+
CausalLMOutputWithPast,
|
| 25 |
+
)
|
| 26 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 27 |
+
from transformers.utils import logging
|
| 28 |
+
|
| 29 |
+
try:
|
| 30 |
+
from einops import rearrange
|
| 31 |
+
except ImportError:
|
| 32 |
+
rearrange = None
|
| 33 |
+
from torch import nn
|
| 34 |
+
|
| 35 |
+
try:
|
| 36 |
+
from kernels.cpp_kernels import cache_autogptq_cuda_256
|
| 37 |
+
except ImportError:
|
| 38 |
+
cache_autogptq_cuda_256 = None
|
| 39 |
+
|
| 40 |
+
SUPPORT_CUDA = torch.cuda.is_available()
|
| 41 |
+
SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported()
|
| 42 |
+
SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
|
| 43 |
+
|
| 44 |
+
from .configuration_qwen import QWenConfig
|
| 45 |
+
from .qwen_generation_utils import (
|
| 46 |
+
HistoryType,
|
| 47 |
+
make_context,
|
| 48 |
+
decode_tokens,
|
| 49 |
+
get_stop_words_ids,
|
| 50 |
+
StopWordsLogitsProcessor,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
logger = logging.get_logger(__name__)
|
| 55 |
+
|
| 56 |
+
_CHECKPOINT_FOR_DOC = "qwen"
|
| 57 |
+
_CONFIG_FOR_DOC = "QWenConfig"
|
| 58 |
+
|
| 59 |
+
QWen_PRETRAINED_MODEL_ARCHIVE_LIST = ["qwen-7b"]
|
| 60 |
+
|
| 61 |
+
_ERROR_BAD_CHAT_FORMAT = """\
|
| 62 |
+
We detect you are probably using the pretrained model (rather than chat model) for chatting, since the chat_format in generation_config is not "chatml".
|
| 63 |
+
If you are directly using the model downloaded from Huggingface, please make sure you are using our "Qwen/Qwen-7B-Chat" Huggingface model (rather than "Qwen/Qwen-7B") when you call model.chat().
|
| 64 |
+
我们检测到您可能在使用预训练模型(而非chat模型)进行多轮chat,因为您当前在generation_config指定的chat_format,并未设置为我们在对话中所支持的"chatml"格式。
|
| 65 |
+
如果您在直接使用我们从Huggingface提供的模型,请确保您在调用model.chat()时,使用的是"Qwen/Qwen-7B-Chat"模型(而非"Qwen/Qwen-7B"预训练模型)。
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
_SENTINEL = object()
|
| 69 |
+
_ERROR_STREAM_IN_CHAT = """\
|
| 70 |
+
Pass argument `stream` to model.chat() is buggy, deprecated, and marked for removal. Please use model.chat_stream(...) instead of model.chat(..., stream=True).
|
| 71 |
+
向model.chat()传入参数stream的用法可能存在Bug,该用法已被废弃,将在未来被移除。请使用model.chat_stream(...)代替model.chat(..., stream=True)。
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED = """\
|
| 75 |
+
We detect you have activated flash attention support, but running model computation on CPU. Please make sure that your input data has been placed on GPU. If you actually want to run CPU computation, please following the readme and set device_map="cpu" to disable flash attention when loading the model (calling AutoModelForCausalLM.from_pretrained).
|
| 76 |
+
检测到您的模型已激活了flash attention支持,但正在执行CPU运算任务。如使用flash attention,请您确认模型输入已经传到GPU上。如果您确认要执行CPU运算,请您在载入模型(调用AutoModelForCausalLM.from_pretrained)时,按照readme说法,指定device_map="cpu"以禁用flash attention。
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
apply_rotary_emb_func = None
|
| 80 |
+
rms_norm = None
|
| 81 |
+
flash_attn_unpadded_func = None
|
| 82 |
+
|
| 83 |
+
def _import_flash_attn():
|
| 84 |
+
global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_func
|
| 85 |
+
try:
|
| 86 |
+
from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_func
|
| 87 |
+
apply_rotary_emb_func = __apply_rotary_emb_func
|
| 88 |
+
except ImportError:
|
| 89 |
+
logger.warn(
|
| 90 |
+
"Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency "
|
| 91 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary"
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
try:
|
| 95 |
+
from flash_attn.ops.rms_norm import rms_norm as __rms_norm
|
| 96 |
+
rms_norm = __rms_norm
|
| 97 |
+
except ImportError:
|
| 98 |
+
logger.warn(
|
| 99 |
+
"Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency "
|
| 100 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm"
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
try:
|
| 104 |
+
import flash_attn
|
| 105 |
+
if not hasattr(flash_attn, '__version__'):
|
| 106 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 107 |
+
else:
|
| 108 |
+
if int(flash_attn.__version__.split(".")[0]) >= 2:
|
| 109 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_func
|
| 110 |
+
else:
|
| 111 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 112 |
+
flash_attn_unpadded_func = __flash_attn_unpadded_func
|
| 113 |
+
except ImportError:
|
| 114 |
+
logger.warn(
|
| 115 |
+
"Warning: import flash_attn fail, please install FlashAttention to get higher efficiency "
|
| 116 |
+
"https://github.com/Dao-AILab/flash-attention"
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
def quantize_cache_v(fdata, bits, qmax, qmin):
|
| 120 |
+
# b, s, head, h-dim->b, head, s, h-dim
|
| 121 |
+
qtype = torch.uint8
|
| 122 |
+
device = fdata.device
|
| 123 |
+
shape = fdata.shape
|
| 124 |
+
|
| 125 |
+
fdata_cal = torch.flatten(fdata, 2)
|
| 126 |
+
fmax = torch.amax(fdata_cal, dim=-1, keepdim=True)
|
| 127 |
+
fmin = torch.amin(fdata_cal, dim=-1, keepdim=True)
|
| 128 |
+
# Compute params
|
| 129 |
+
if qmax.device != fmax.device:
|
| 130 |
+
qmax = qmax.to(device)
|
| 131 |
+
qmin = qmin.to(device)
|
| 132 |
+
scale = (fmax - fmin) / (qmax - qmin)
|
| 133 |
+
zero = qmin - fmin / scale
|
| 134 |
+
scale = scale.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 135 |
+
zero = zero.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 136 |
+
# Quantize
|
| 137 |
+
res_data = fdata / scale + zero
|
| 138 |
+
qdata = torch.clamp(res_data, qmin, qmax).to(qtype)
|
| 139 |
+
return qdata.contiguous(), scale, zero
|
| 140 |
+
|
| 141 |
+
def dequantize_cache_torch(qdata, scale, zero):
|
| 142 |
+
data = scale * (qdata - zero)
|
| 143 |
+
return data
|
| 144 |
+
|
| 145 |
+
class FlashSelfAttention(torch.nn.Module):
|
| 146 |
+
def __init__(
|
| 147 |
+
self,
|
| 148 |
+
causal=False,
|
| 149 |
+
softmax_scale=None,
|
| 150 |
+
attention_dropout=0.0,
|
| 151 |
+
):
|
| 152 |
+
super().__init__()
|
| 153 |
+
assert flash_attn_unpadded_func is not None, (
|
| 154 |
+
"Please install FlashAttention first, " "e.g., with pip install flash-attn"
|
| 155 |
+
)
|
| 156 |
+
assert (
|
| 157 |
+
rearrange is not None
|
| 158 |
+
), "Please install einops first, e.g., with pip install einops"
|
| 159 |
+
self.causal = causal
|
| 160 |
+
self.softmax_scale = softmax_scale
|
| 161 |
+
self.dropout_p = attention_dropout
|
| 162 |
+
|
| 163 |
+
def unpad_input(self, hidden_states, attention_mask):
|
| 164 |
+
valid_mask = attention_mask.squeeze(1).squeeze(1).eq(0)
|
| 165 |
+
seqlens_in_batch = valid_mask.sum(dim=-1, dtype=torch.int32)
|
| 166 |
+
indices = torch.nonzero(valid_mask.flatten(), as_tuple=False).flatten()
|
| 167 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 168 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 169 |
+
hidden_states = hidden_states[indices]
|
| 170 |
+
return hidden_states, indices, cu_seqlens, max_seqlen_in_batch
|
| 171 |
+
|
| 172 |
+
def pad_input(self, hidden_states, indices, batch, seqlen):
|
| 173 |
+
output = torch.zeros(batch * seqlen, *hidden_states.shape[1:], device=hidden_states.device,
|
| 174 |
+
dtype=hidden_states.dtype)
|
| 175 |
+
output[indices] = hidden_states
|
| 176 |
+
return rearrange(output, '(b s) ... -> b s ...', b=batch)
|
| 177 |
+
|
| 178 |
+
def forward(self, q, k, v, attention_mask=None):
|
| 179 |
+
assert all((i.dtype in [torch.float16, torch.bfloat16] for i in (q, k, v)))
|
| 180 |
+
assert all((i.is_cuda for i in (q, k, v)))
|
| 181 |
+
batch_size, seqlen_q = q.shape[0], q.shape[1]
|
| 182 |
+
seqlen_k = k.shape[1]
|
| 183 |
+
|
| 184 |
+
q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]
|
| 185 |
+
cu_seqlens_q = torch.arange(
|
| 186 |
+
0,
|
| 187 |
+
(batch_size + 1) * seqlen_q,
|
| 188 |
+
step=seqlen_q,
|
| 189 |
+
dtype=torch.int32,
|
| 190 |
+
device=q.device,
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
if attention_mask is not None:
|
| 194 |
+
k, indices_k, cu_seqlens_k, seqlen_k = self.unpad_input(k, attention_mask)
|
| 195 |
+
v = v[indices_k]
|
| 196 |
+
if seqlen_q == seqlen_k:
|
| 197 |
+
q = q[indices_k]
|
| 198 |
+
cu_seqlens_q = cu_seqlens_k
|
| 199 |
+
else:
|
| 200 |
+
cu_seqlens_k = torch.arange(
|
| 201 |
+
0,
|
| 202 |
+
(batch_size + 1) * seqlen_k,
|
| 203 |
+
step=seqlen_k,
|
| 204 |
+
dtype=torch.int32,
|
| 205 |
+
device=q.device,
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
if self.training:
|
| 209 |
+
assert seqlen_k == seqlen_q
|
| 210 |
+
is_causal = self.causal
|
| 211 |
+
dropout_p = self.dropout_p
|
| 212 |
+
else:
|
| 213 |
+
is_causal = seqlen_q == seqlen_k
|
| 214 |
+
dropout_p = 0
|
| 215 |
+
|
| 216 |
+
output = flash_attn_unpadded_func(
|
| 217 |
+
q,
|
| 218 |
+
k,
|
| 219 |
+
v,
|
| 220 |
+
cu_seqlens_q,
|
| 221 |
+
cu_seqlens_k,
|
| 222 |
+
seqlen_q,
|
| 223 |
+
seqlen_k,
|
| 224 |
+
dropout_p,
|
| 225 |
+
softmax_scale=self.softmax_scale,
|
| 226 |
+
causal=is_causal,
|
| 227 |
+
)
|
| 228 |
+
if attention_mask is not None and seqlen_q == seqlen_k:
|
| 229 |
+
output = self.pad_input(output, indices_k, batch_size, seqlen_q)
|
| 230 |
+
else:
|
| 231 |
+
new_shape = (batch_size, output.shape[0] // batch_size) + output.shape[1:]
|
| 232 |
+
output = output.view(new_shape)
|
| 233 |
+
return output
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
class QWenAttention(nn.Module):
|
| 237 |
+
def __init__(self, config):
|
| 238 |
+
super().__init__()
|
| 239 |
+
|
| 240 |
+
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
|
| 241 |
+
self.seq_length = config.seq_length
|
| 242 |
+
|
| 243 |
+
self.hidden_size = config.hidden_size
|
| 244 |
+
self.split_size = config.hidden_size
|
| 245 |
+
self.num_heads = config.num_attention_heads
|
| 246 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 247 |
+
|
| 248 |
+
self.use_flash_attn = config.use_flash_attn
|
| 249 |
+
self.scale_attn_weights = True
|
| 250 |
+
|
| 251 |
+
self.projection_size = config.kv_channels * config.num_attention_heads
|
| 252 |
+
|
| 253 |
+
assert self.projection_size % config.num_attention_heads == 0
|
| 254 |
+
self.hidden_size_per_attention_head = (
|
| 255 |
+
self.projection_size // config.num_attention_heads
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
self.c_attn = nn.Linear(config.hidden_size, 3 * self.projection_size)
|
| 259 |
+
|
| 260 |
+
self.c_proj = nn.Linear(
|
| 261 |
+
config.hidden_size, self.projection_size, bias=not config.no_bias
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 265 |
+
if (
|
| 266 |
+
self.use_flash_attn
|
| 267 |
+
and flash_attn_unpadded_func is not None
|
| 268 |
+
and not self.is_fp32
|
| 269 |
+
):
|
| 270 |
+
self.core_attention_flash = FlashSelfAttention(
|
| 271 |
+
causal=True, attention_dropout=config.attn_dropout_prob
|
| 272 |
+
)
|
| 273 |
+
self.bf16 = config.bf16
|
| 274 |
+
|
| 275 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 276 |
+
self.use_logn_attn = config.use_logn_attn
|
| 277 |
+
|
| 278 |
+
logn_list = [
|
| 279 |
+
math.log(i, self.seq_length) if i > self.seq_length else 1
|
| 280 |
+
for i in range(1, 32768)
|
| 281 |
+
]
|
| 282 |
+
logn_tensor = torch.tensor(logn_list)[None, :, None, None]
|
| 283 |
+
self.register_buffer("logn_tensor", logn_tensor, persistent=False)
|
| 284 |
+
|
| 285 |
+
self.attn_dropout = nn.Dropout(config.attn_dropout_prob)
|
| 286 |
+
self.use_cache_quantization = config.use_cache_quantization if hasattr(config, 'use_cache_quantization') else False
|
| 287 |
+
self.use_cache_kernel = config.use_cache_kernel if hasattr(config,'use_cache_kernel') else False
|
| 288 |
+
cache_dtype = torch.float
|
| 289 |
+
if self.bf16:
|
| 290 |
+
cache_dtype=torch.bfloat16
|
| 291 |
+
elif config.fp16:
|
| 292 |
+
cache_dtype = torch.float16
|
| 293 |
+
self.cache_qmax = torch.tensor(torch.iinfo(torch.uint8).max, dtype=cache_dtype)
|
| 294 |
+
self.cache_qmin = torch.tensor(torch.iinfo(torch.uint8).min, dtype=cache_dtype)
|
| 295 |
+
|
| 296 |
+
def _attn(self, query, key, value, registered_causal_mask, attention_mask=None, head_mask=None):
|
| 297 |
+
device = query.device
|
| 298 |
+
if self.use_cache_quantization:
|
| 299 |
+
qk, qk_scale, qk_zero = key
|
| 300 |
+
if self.use_cache_kernel and cache_autogptq_cuda_256 is not None:
|
| 301 |
+
shape = query.shape[:-1] + (qk.shape[-2],)
|
| 302 |
+
attn_weights = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 303 |
+
cache_autogptq_cuda_256.vecquant8matmul_batched_faster_old(
|
| 304 |
+
query.contiguous() if query.dtype == torch.float16 else query.to(torch.float16).contiguous(),
|
| 305 |
+
qk.transpose(-1, -2).contiguous(),
|
| 306 |
+
attn_weights,
|
| 307 |
+
qk_scale.contiguous() if qk_scale.dtype == torch.float16 else qk_scale.to(torch.float16).contiguous(),
|
| 308 |
+
qk_zero.contiguous()if qk_zero.dtype == torch.float16 else qk_zero.to(torch.float16).contiguous())
|
| 309 |
+
# attn_weights = attn_weights.to(query.dtype).contiguous()
|
| 310 |
+
else:
|
| 311 |
+
key = dequantize_cache_torch(qk, qk_scale, qk_zero)
|
| 312 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 313 |
+
else:
|
| 314 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 315 |
+
|
| 316 |
+
if self.scale_attn_weights:
|
| 317 |
+
if self.use_cache_quantization:
|
| 318 |
+
size_temp = value[0].size(-1)
|
| 319 |
+
else:
|
| 320 |
+
size_temp = value.size(-1)
|
| 321 |
+
attn_weights = attn_weights / torch.full(
|
| 322 |
+
[],
|
| 323 |
+
size_temp ** 0.5,
|
| 324 |
+
dtype=attn_weights.dtype,
|
| 325 |
+
device=attn_weights.device,
|
| 326 |
+
)
|
| 327 |
+
if self.use_cache_quantization:
|
| 328 |
+
query_length, key_length = query.size(-2), key[0].size(-2)
|
| 329 |
+
else:
|
| 330 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 331 |
+
causal_mask = registered_causal_mask[
|
| 332 |
+
:, :, key_length - query_length : key_length, :key_length
|
| 333 |
+
]
|
| 334 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 335 |
+
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(
|
| 336 |
+
attn_weights.device
|
| 337 |
+
)
|
| 338 |
+
attn_weights = torch.where(
|
| 339 |
+
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
if attention_mask is not None:
|
| 343 |
+
attn_weights = attn_weights + attention_mask
|
| 344 |
+
|
| 345 |
+
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1)
|
| 346 |
+
|
| 347 |
+
attn_weights = attn_weights.type(query.dtype)
|
| 348 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 349 |
+
|
| 350 |
+
if head_mask is not None:
|
| 351 |
+
attn_weights = attn_weights * head_mask
|
| 352 |
+
|
| 353 |
+
if self.use_cache_quantization:
|
| 354 |
+
qv, qv_scale, qv_zero = value
|
| 355 |
+
if self.use_cache_kernel and cache_autogptq_cuda_256 is not None:
|
| 356 |
+
shape = attn_weights.shape[:-1] + (query.shape[-1],)
|
| 357 |
+
attn_output = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 358 |
+
cache_autogptq_cuda_256.vecquant8matmul_batched_column_compression_faster_old(
|
| 359 |
+
attn_weights.contiguous() if attn_weights.dtype == torch.float16 else attn_weights.to(torch.float16).contiguous(),
|
| 360 |
+
qv.contiguous(), # dtype: int32
|
| 361 |
+
attn_output,
|
| 362 |
+
qv_scale.contiguous() if qv_scale.dtype == torch.float16 else qv_scale.to(torch.float16).contiguous(),
|
| 363 |
+
qv_zero.contiguous() if qv_zero.dtype == torch.float16 else qv_zero.to(torch.float16).contiguous())
|
| 364 |
+
if attn_output.dtype != query.dtype:
|
| 365 |
+
attn_output = attn_output.to(query.dtype)
|
| 366 |
+
attn_weights = attn_weights.to(query.dtype)
|
| 367 |
+
else:
|
| 368 |
+
value = dequantize_cache_torch(qv, qv_scale, qv_zero)
|
| 369 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 370 |
+
else:
|
| 371 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 372 |
+
|
| 373 |
+
attn_output = attn_output.transpose(1, 2)
|
| 374 |
+
|
| 375 |
+
return attn_output, attn_weights
|
| 376 |
+
|
| 377 |
+
def _upcast_and_reordered_attn(
|
| 378 |
+
self, query, key, value, registered_causal_mask, attention_mask=None, head_mask=None
|
| 379 |
+
):
|
| 380 |
+
bsz, num_heads, q_seq_len, dk = query.size()
|
| 381 |
+
_, _, k_seq_len, _ = key.size()
|
| 382 |
+
|
| 383 |
+
attn_weights = torch.empty(
|
| 384 |
+
bsz * num_heads,
|
| 385 |
+
q_seq_len,
|
| 386 |
+
k_seq_len,
|
| 387 |
+
dtype=torch.float32,
|
| 388 |
+
device=query.device,
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
scale_factor = 1.0
|
| 392 |
+
if self.scale_attn_weights:
|
| 393 |
+
scale_factor /= float(value.size(-1)) ** 0.5
|
| 394 |
+
|
| 395 |
+
with autocast(enabled=False):
|
| 396 |
+
q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(
|
| 397 |
+
-1, dk, k_seq_len
|
| 398 |
+
)
|
| 399 |
+
attn_weights = torch.baddbmm(
|
| 400 |
+
attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor
|
| 401 |
+
)
|
| 402 |
+
attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)
|
| 403 |
+
|
| 404 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 405 |
+
causal_mask = registered_causal_mask[
|
| 406 |
+
:, :, key_length - query_length : key_length, :key_length
|
| 407 |
+
]
|
| 408 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 409 |
+
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(
|
| 410 |
+
attn_weights.device
|
| 411 |
+
)
|
| 412 |
+
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
|
| 413 |
+
|
| 414 |
+
if attention_mask is not None:
|
| 415 |
+
attn_weights = attn_weights + attention_mask
|
| 416 |
+
|
| 417 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 418 |
+
|
| 419 |
+
if attn_weights.dtype != torch.float32:
|
| 420 |
+
raise RuntimeError(
|
| 421 |
+
"Error with upcasting, attn_weights does not have dtype torch.float32"
|
| 422 |
+
)
|
| 423 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 424 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 425 |
+
|
| 426 |
+
if head_mask is not None:
|
| 427 |
+
attn_weights = attn_weights * head_mask
|
| 428 |
+
|
| 429 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 430 |
+
|
| 431 |
+
return attn_output, attn_weights
|
| 432 |
+
|
| 433 |
+
def _split_heads(self, tensor, num_heads, attn_head_size):
|
| 434 |
+
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
|
| 435 |
+
tensor = tensor.view(new_shape)
|
| 436 |
+
return tensor
|
| 437 |
+
|
| 438 |
+
def _merge_heads(self, tensor, num_heads, attn_head_size):
|
| 439 |
+
tensor = tensor.contiguous()
|
| 440 |
+
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
|
| 441 |
+
return tensor.view(new_shape)
|
| 442 |
+
|
| 443 |
+
def forward(
|
| 444 |
+
self,
|
| 445 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 446 |
+
rotary_pos_emb_list: Optional[List[torch.Tensor]] = None,
|
| 447 |
+
registered_causal_mask: Optional[torch.Tensor] = None,
|
| 448 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 449 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 450 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 451 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 452 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 453 |
+
output_attentions: Optional[bool] = False,
|
| 454 |
+
use_cache: Optional[bool] = False,
|
| 455 |
+
):
|
| 456 |
+
mixed_x_layer = self.c_attn(hidden_states)
|
| 457 |
+
|
| 458 |
+
query, key, value = mixed_x_layer.split(self.split_size, dim=2)
|
| 459 |
+
|
| 460 |
+
query = self._split_heads(query, self.num_heads, self.head_dim)
|
| 461 |
+
key = self._split_heads(key, self.num_heads, self.head_dim)
|
| 462 |
+
value = self._split_heads(value, self.num_heads, self.head_dim)
|
| 463 |
+
|
| 464 |
+
if rotary_pos_emb_list is not None:
|
| 465 |
+
cur_len = query.shape[1]
|
| 466 |
+
if len(rotary_pos_emb_list) == 1:
|
| 467 |
+
rotary_pos_emb = rotary_pos_emb_list[0]
|
| 468 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 469 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 470 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 471 |
+
# Slice the pos emb for current inference
|
| 472 |
+
query = apply_rotary_pos_emb(query, q_pos_emb)
|
| 473 |
+
key = apply_rotary_pos_emb(key, k_pos_emb)
|
| 474 |
+
else:
|
| 475 |
+
query_list = []
|
| 476 |
+
key_list = []
|
| 477 |
+
for i, rotary_pos_emb in enumerate(rotary_pos_emb_list):
|
| 478 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 479 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 480 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 481 |
+
# Slice the pos emb for current inference
|
| 482 |
+
query_list += [apply_rotary_pos_emb(query[i:i+1, :, :], q_pos_emb)]
|
| 483 |
+
key_list += [apply_rotary_pos_emb(key[i:i+1, :, :], k_pos_emb)]
|
| 484 |
+
query = torch.cat(query_list, dim=0)
|
| 485 |
+
key = torch.cat(key_list, dim=0)
|
| 486 |
+
|
| 487 |
+
if self.use_cache_quantization:
|
| 488 |
+
key = quantize_cache_v(key.permute(0, 2, 1, 3),
|
| 489 |
+
bits=8,
|
| 490 |
+
qmin=self.cache_qmin,
|
| 491 |
+
qmax=self.cache_qmax)
|
| 492 |
+
value = quantize_cache_v(value.permute(0, 2, 1, 3),
|
| 493 |
+
bits=8,
|
| 494 |
+
qmin=self.cache_qmin,
|
| 495 |
+
qmax=self.cache_qmax)
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
if layer_past is not None:
|
| 499 |
+
past_key, past_value = layer_past[0], layer_past[1]
|
| 500 |
+
if self.use_cache_quantization:
|
| 501 |
+
# use_cache_quantization:
|
| 502 |
+
# present=((q_key,key_scale,key_zero_point),
|
| 503 |
+
# (q_value,value_scale,value_zero_point))
|
| 504 |
+
key = (torch.cat((past_key[0], key[0]), dim=2),
|
| 505 |
+
torch.cat((past_key[1], key[1]), dim=2),
|
| 506 |
+
torch.cat((past_key[2], key[2]), dim=2))
|
| 507 |
+
value = (torch.cat((past_value[0], value[0]), dim=2),
|
| 508 |
+
torch.cat((past_value[1], value[1]), dim=2),
|
| 509 |
+
torch.cat((past_value[2], value[2]), dim=2))
|
| 510 |
+
else:
|
| 511 |
+
# not use_cache_quantization:
|
| 512 |
+
# present=(key,value)
|
| 513 |
+
key = torch.cat((past_key, key), dim=1)
|
| 514 |
+
value = torch.cat((past_value, value), dim=1)
|
| 515 |
+
|
| 516 |
+
if use_cache:
|
| 517 |
+
present = (key, value)
|
| 518 |
+
else:
|
| 519 |
+
present = None
|
| 520 |
+
|
| 521 |
+
if self.use_logn_attn and not self.training:
|
| 522 |
+
if self.use_cache_quantization:
|
| 523 |
+
seq_start = key[0].size(2) - query.size(1)
|
| 524 |
+
seq_end = key[0].size(2)
|
| 525 |
+
else:
|
| 526 |
+
seq_start = key.size(1) - query.size(1)
|
| 527 |
+
seq_end = key.size(1)
|
| 528 |
+
logn_tensor = self.logn_tensor[:, seq_start:seq_end, :, :]
|
| 529 |
+
query = query * logn_tensor.expand_as(query)
|
| 530 |
+
|
| 531 |
+
if (
|
| 532 |
+
self.use_flash_attn
|
| 533 |
+
and flash_attn_unpadded_func is not None
|
| 534 |
+
and not self.is_fp32
|
| 535 |
+
and query.is_cuda
|
| 536 |
+
):
|
| 537 |
+
q, k, v = query, key, value
|
| 538 |
+
context_layer = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
|
| 539 |
+
|
| 540 |
+
# b s h d -> b s (h d)
|
| 541 |
+
context_layer = context_layer.flatten(2,3).contiguous()
|
| 542 |
+
|
| 543 |
+
else:
|
| 544 |
+
query = query.permute(0, 2, 1, 3)
|
| 545 |
+
if not self.use_cache_quantization:
|
| 546 |
+
key = key.permute(0, 2, 1, 3)
|
| 547 |
+
value = value.permute(0, 2, 1, 3)
|
| 548 |
+
if (
|
| 549 |
+
registered_causal_mask is None
|
| 550 |
+
and self.use_flash_attn
|
| 551 |
+
and flash_attn_unpadded_func is not None
|
| 552 |
+
and not self.is_fp32
|
| 553 |
+
and not query.is_cuda
|
| 554 |
+
):
|
| 555 |
+
raise Exception(_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED)
|
| 556 |
+
attn_output, attn_weight = self._attn(
|
| 557 |
+
query, key, value, registered_causal_mask, attention_mask, head_mask
|
| 558 |
+
)
|
| 559 |
+
context_layer = self._merge_heads(
|
| 560 |
+
attn_output, self.num_heads, self.head_dim
|
| 561 |
+
)
|
| 562 |
+
|
| 563 |
+
attn_output = self.c_proj(context_layer)
|
| 564 |
+
|
| 565 |
+
outputs = (attn_output, present)
|
| 566 |
+
if output_attentions:
|
| 567 |
+
if (
|
| 568 |
+
self.use_flash_attn
|
| 569 |
+
and flash_attn_unpadded_func is not None
|
| 570 |
+
and not self.is_fp32
|
| 571 |
+
):
|
| 572 |
+
raise ValueError("Cannot output attentions while using flash-attn")
|
| 573 |
+
else:
|
| 574 |
+
outputs += (attn_weight,)
|
| 575 |
+
|
| 576 |
+
return outputs
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
class QWenMLP(nn.Module):
|
| 580 |
+
def __init__(self, config):
|
| 581 |
+
super().__init__()
|
| 582 |
+
self.w1 = nn.Linear(
|
| 583 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 584 |
+
)
|
| 585 |
+
self.w2 = nn.Linear(
|
| 586 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 587 |
+
)
|
| 588 |
+
ff_dim_in = config.intermediate_size // 2
|
| 589 |
+
self.c_proj = nn.Linear(ff_dim_in, config.hidden_size, bias=not config.no_bias)
|
| 590 |
+
|
| 591 |
+
def forward(self, hidden_states):
|
| 592 |
+
a1 = self.w1(hidden_states)
|
| 593 |
+
a2 = self.w2(hidden_states)
|
| 594 |
+
intermediate_parallel = a1 * F.silu(a2)
|
| 595 |
+
output = self.c_proj(intermediate_parallel)
|
| 596 |
+
return output
|
| 597 |
+
|
| 598 |
+
class QWenBlock(nn.Module):
|
| 599 |
+
def __init__(self, config):
|
| 600 |
+
super().__init__()
|
| 601 |
+
hidden_size = config.hidden_size
|
| 602 |
+
self.bf16 = config.bf16
|
| 603 |
+
|
| 604 |
+
self.ln_1 = RMSNorm(
|
| 605 |
+
hidden_size,
|
| 606 |
+
eps=config.layer_norm_epsilon,
|
| 607 |
+
)
|
| 608 |
+
self.attn = QWenAttention(config)
|
| 609 |
+
self.ln_2 = RMSNorm(
|
| 610 |
+
hidden_size,
|
| 611 |
+
eps=config.layer_norm_epsilon,
|
| 612 |
+
)
|
| 613 |
+
|
| 614 |
+
self.mlp = QWenMLP(config)
|
| 615 |
+
|
| 616 |
+
def forward(
|
| 617 |
+
self,
|
| 618 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 619 |
+
rotary_pos_emb_list: Optional[List[torch.Tensor]] = None,
|
| 620 |
+
registered_causal_mask: Optional[torch.Tensor] = None,
|
| 621 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 622 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 623 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 624 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 625 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 626 |
+
use_cache: Optional[bool] = False,
|
| 627 |
+
output_attentions: Optional[bool] = False,
|
| 628 |
+
):
|
| 629 |
+
layernorm_output = self.ln_1(hidden_states)
|
| 630 |
+
|
| 631 |
+
attn_outputs = self.attn(
|
| 632 |
+
layernorm_output,
|
| 633 |
+
rotary_pos_emb_list,
|
| 634 |
+
registered_causal_mask=registered_causal_mask,
|
| 635 |
+
layer_past=layer_past,
|
| 636 |
+
attention_mask=attention_mask,
|
| 637 |
+
head_mask=head_mask,
|
| 638 |
+
use_cache=use_cache,
|
| 639 |
+
output_attentions=output_attentions,
|
| 640 |
+
)
|
| 641 |
+
attn_output = attn_outputs[0]
|
| 642 |
+
|
| 643 |
+
outputs = attn_outputs[1:]
|
| 644 |
+
|
| 645 |
+
residual = hidden_states
|
| 646 |
+
layernorm_input = attn_output + residual
|
| 647 |
+
|
| 648 |
+
layernorm_output = self.ln_2(layernorm_input)
|
| 649 |
+
|
| 650 |
+
residual = layernorm_input
|
| 651 |
+
mlp_output = self.mlp(layernorm_output)
|
| 652 |
+
hidden_states = residual + mlp_output
|
| 653 |
+
|
| 654 |
+
if use_cache:
|
| 655 |
+
outputs = (hidden_states,) + outputs
|
| 656 |
+
else:
|
| 657 |
+
outputs = (hidden_states,) + outputs[1:]
|
| 658 |
+
|
| 659 |
+
return outputs
|
| 660 |
+
|
| 661 |
+
|
| 662 |
+
class QWenPreTrainedModel(PreTrainedModel):
|
| 663 |
+
config_class = QWenConfig
|
| 664 |
+
base_model_prefix = "transformer"
|
| 665 |
+
is_parallelizable = False
|
| 666 |
+
supports_gradient_checkpointing = True
|
| 667 |
+
_no_split_modules = ["QWenBlock"]
|
| 668 |
+
|
| 669 |
+
def __init__(self, *inputs, **kwargs):
|
| 670 |
+
super().__init__(*inputs, **kwargs)
|
| 671 |
+
|
| 672 |
+
def _init_weights(self, module):
|
| 673 |
+
"""Initialize the weights."""
|
| 674 |
+
if isinstance(module, nn.Linear):
|
| 675 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 676 |
+
if module.bias is not None:
|
| 677 |
+
module.bias.data.zero_()
|
| 678 |
+
elif isinstance(module, nn.Embedding):
|
| 679 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 680 |
+
if module.padding_idx is not None:
|
| 681 |
+
module.weight.data[module.padding_idx].zero_()
|
| 682 |
+
elif isinstance(module, RMSNorm):
|
| 683 |
+
module.weight.data.fill_(1.0)
|
| 684 |
+
|
| 685 |
+
for name, p in module.named_parameters():
|
| 686 |
+
if name == "c_proj.weight":
|
| 687 |
+
p.data.normal_(
|
| 688 |
+
mean=0.0,
|
| 689 |
+
std=(
|
| 690 |
+
self.config.initializer_range
|
| 691 |
+
/ math.sqrt(2 * self.config.num_hidden_layers)
|
| 692 |
+
),
|
| 693 |
+
)
|
| 694 |
+
|
| 695 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 696 |
+
if isinstance(module, QWenModel):
|
| 697 |
+
module.gradient_checkpointing = value
|
| 698 |
+
|
| 699 |
+
|
| 700 |
+
class QWenModel(QWenPreTrainedModel):
|
| 701 |
+
_keys_to_ignore_on_load_missing = ["attn.masked_bias"]
|
| 702 |
+
|
| 703 |
+
def __init__(self, config):
|
| 704 |
+
super().__init__(config)
|
| 705 |
+
self.vocab_size = config.vocab_size
|
| 706 |
+
self.num_hidden_layers = config.num_hidden_layers
|
| 707 |
+
self.embed_dim = config.hidden_size
|
| 708 |
+
self.use_cache_quantization = self.config.use_cache_quantization if hasattr(self.config, 'use_cache_quantization') else False
|
| 709 |
+
|
| 710 |
+
self.gradient_checkpointing = False
|
| 711 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 712 |
+
self.seq_length = config.seq_length
|
| 713 |
+
|
| 714 |
+
self.wte = nn.Embedding(self.vocab_size, self.embed_dim)
|
| 715 |
+
|
| 716 |
+
self.drop = nn.Dropout(config.emb_dropout_prob)
|
| 717 |
+
|
| 718 |
+
if config.rotary_pct == 1.0:
|
| 719 |
+
self.rotary_ndims = None
|
| 720 |
+
else:
|
| 721 |
+
assert config.rotary_pct < 1
|
| 722 |
+
self.rotary_ndims = int(
|
| 723 |
+
config.kv_channels * config.rotary_pct
|
| 724 |
+
)
|
| 725 |
+
dim = (
|
| 726 |
+
self.rotary_ndims
|
| 727 |
+
if self.rotary_ndims is not None
|
| 728 |
+
else config.kv_channels
|
| 729 |
+
)
|
| 730 |
+
self.rotary_emb = RotaryEmbedding(dim, base=config.rotary_emb_base)
|
| 731 |
+
|
| 732 |
+
self.use_flash_attn = config.use_flash_attn
|
| 733 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 734 |
+
if (
|
| 735 |
+
self.use_flash_attn
|
| 736 |
+
and flash_attn_unpadded_func is not None
|
| 737 |
+
and not self.is_fp32
|
| 738 |
+
):
|
| 739 |
+
self.registered_causal_mask = None
|
| 740 |
+
else:
|
| 741 |
+
max_positions = config.max_position_embeddings
|
| 742 |
+
self.register_buffer(
|
| 743 |
+
"registered_causal_mask",
|
| 744 |
+
torch.tril(
|
| 745 |
+
torch.ones((max_positions, max_positions), dtype=torch.bool)
|
| 746 |
+
).view(1, 1, max_positions, max_positions),
|
| 747 |
+
persistent=False,
|
| 748 |
+
)
|
| 749 |
+
|
| 750 |
+
self.h = nn.ModuleList(
|
| 751 |
+
[
|
| 752 |
+
QWenBlock(
|
| 753 |
+
config
|
| 754 |
+
)
|
| 755 |
+
for i in range(config.num_hidden_layers)
|
| 756 |
+
]
|
| 757 |
+
)
|
| 758 |
+
self.ln_f = RMSNorm(
|
| 759 |
+
self.embed_dim,
|
| 760 |
+
eps=config.layer_norm_epsilon,
|
| 761 |
+
)
|
| 762 |
+
|
| 763 |
+
self.post_init()
|
| 764 |
+
|
| 765 |
+
def get_input_embeddings(self):
|
| 766 |
+
return self.wte
|
| 767 |
+
|
| 768 |
+
def set_input_embeddings(self, new_embeddings):
|
| 769 |
+
self.wte = new_embeddings
|
| 770 |
+
|
| 771 |
+
def get_ntk_alpha(self, true_seq_len):
|
| 772 |
+
context_value = math.log(true_seq_len / self.seq_length, 2) + 1
|
| 773 |
+
ntk_alpha = 2 ** math.ceil(context_value) - 1
|
| 774 |
+
ntk_alpha = max(ntk_alpha, 1)
|
| 775 |
+
return ntk_alpha
|
| 776 |
+
|
| 777 |
+
def forward(
|
| 778 |
+
self,
|
| 779 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 780 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 781 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 782 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 783 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 784 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 785 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 786 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 787 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 788 |
+
use_cache: Optional[bool] = None,
|
| 789 |
+
output_attentions: Optional[bool] = None,
|
| 790 |
+
output_hidden_states: Optional[bool] = None,
|
| 791 |
+
return_dict: Optional[bool] = None,
|
| 792 |
+
):
|
| 793 |
+
output_attentions = (
|
| 794 |
+
output_attentions
|
| 795 |
+
if output_attentions is not None
|
| 796 |
+
else self.config.output_attentions
|
| 797 |
+
)
|
| 798 |
+
output_hidden_states = (
|
| 799 |
+
output_hidden_states
|
| 800 |
+
if output_hidden_states is not None
|
| 801 |
+
else self.config.output_hidden_states
|
| 802 |
+
)
|
| 803 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 804 |
+
return_dict = (
|
| 805 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 806 |
+
)
|
| 807 |
+
|
| 808 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 809 |
+
raise ValueError(
|
| 810 |
+
"You cannot specify both input_ids and inputs_embeds at the same time"
|
| 811 |
+
)
|
| 812 |
+
elif input_ids is not None:
|
| 813 |
+
input_shape = input_ids.size()
|
| 814 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 815 |
+
batch_size = input_ids.shape[0]
|
| 816 |
+
elif inputs_embeds is not None:
|
| 817 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 818 |
+
batch_size = inputs_embeds.shape[0]
|
| 819 |
+
else:
|
| 820 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 821 |
+
|
| 822 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 823 |
+
|
| 824 |
+
if token_type_ids is not None:
|
| 825 |
+
token_type_ids = token_type_ids.view(-1, input_shape[-1])
|
| 826 |
+
if position_ids is not None:
|
| 827 |
+
position_ids = position_ids.view(-1, input_shape[-1])
|
| 828 |
+
|
| 829 |
+
if past_key_values is None:
|
| 830 |
+
past_length = 0
|
| 831 |
+
past_key_values = tuple([None] * len(self.h))
|
| 832 |
+
else:
|
| 833 |
+
if self.use_cache_quantization:
|
| 834 |
+
past_length = past_key_values[0][0][0].size(2)
|
| 835 |
+
else:
|
| 836 |
+
past_length = past_key_values[0][0].size(-2)
|
| 837 |
+
if position_ids is None:
|
| 838 |
+
position_ids = torch.arange(
|
| 839 |
+
past_length,
|
| 840 |
+
input_shape[-1] + past_length,
|
| 841 |
+
dtype=torch.long,
|
| 842 |
+
device=device,
|
| 843 |
+
)
|
| 844 |
+
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
|
| 845 |
+
|
| 846 |
+
if attention_mask is not None:
|
| 847 |
+
if batch_size <= 0:
|
| 848 |
+
raise ValueError("batch_size has to be defined and > 0")
|
| 849 |
+
attention_mask = attention_mask.view(batch_size, -1)
|
| 850 |
+
attention_mask = attention_mask[:, None, None, :]
|
| 851 |
+
attention_mask = attention_mask.to(dtype=self.dtype)
|
| 852 |
+
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
|
| 853 |
+
|
| 854 |
+
encoder_attention_mask = None
|
| 855 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 856 |
+
|
| 857 |
+
if inputs_embeds is None:
|
| 858 |
+
inputs_embeds = self.wte(input_ids)
|
| 859 |
+
hidden_states = inputs_embeds
|
| 860 |
+
|
| 861 |
+
kv_seq_len = hidden_states.size()[1]
|
| 862 |
+
if past_key_values[0] is not None:
|
| 863 |
+
# past key values[0][0] shape: bs * seq_len * head_num * dim
|
| 864 |
+
if self.use_cache_quantization:
|
| 865 |
+
kv_seq_len += past_key_values[0][0][0].shape[2]
|
| 866 |
+
else:
|
| 867 |
+
kv_seq_len += past_key_values[0][0].shape[1]
|
| 868 |
+
|
| 869 |
+
if self.training or not self.use_dynamic_ntk:
|
| 870 |
+
ntk_alpha_list = [1.0]
|
| 871 |
+
elif kv_seq_len != hidden_states.size()[1]:
|
| 872 |
+
ntk_alpha_list = self.rotary_emb._ntk_alpha_cached_list
|
| 873 |
+
else:
|
| 874 |
+
ntk_alpha_list = []
|
| 875 |
+
if attention_mask is not None and kv_seq_len > self.seq_length:
|
| 876 |
+
true_seq_lens = attention_mask.squeeze(1).squeeze(1).eq(0).sum(dim=-1, dtype=torch.int32)
|
| 877 |
+
for i in range(hidden_states.size()[0]):
|
| 878 |
+
true_seq_len = true_seq_lens[i].item()
|
| 879 |
+
ntk_alpha = self.get_ntk_alpha(true_seq_len)
|
| 880 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 881 |
+
else:
|
| 882 |
+
ntk_alpha = self.get_ntk_alpha(kv_seq_len)
|
| 883 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 884 |
+
self.rotary_emb._ntk_alpha_cached_list = ntk_alpha_list
|
| 885 |
+
|
| 886 |
+
rotary_pos_emb_list = []
|
| 887 |
+
for ntk_alpha in ntk_alpha_list:
|
| 888 |
+
rotary_pos_emb = self.rotary_emb(kv_seq_len, ntk_alpha=ntk_alpha)
|
| 889 |
+
rotary_pos_emb_list.append(rotary_pos_emb)
|
| 890 |
+
|
| 891 |
+
hidden_states = self.drop(hidden_states)
|
| 892 |
+
output_shape = input_shape + (hidden_states.size(-1),)
|
| 893 |
+
|
| 894 |
+
if self.gradient_checkpointing and self.training:
|
| 895 |
+
if use_cache:
|
| 896 |
+
logger.warning_once(
|
| 897 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 898 |
+
)
|
| 899 |
+
use_cache = False
|
| 900 |
+
|
| 901 |
+
presents = () if use_cache else None
|
| 902 |
+
all_self_attentions = () if output_attentions else None
|
| 903 |
+
all_hidden_states = () if output_hidden_states else None
|
| 904 |
+
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
| 905 |
+
|
| 906 |
+
if output_hidden_states:
|
| 907 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 908 |
+
|
| 909 |
+
if self.gradient_checkpointing and self.training:
|
| 910 |
+
|
| 911 |
+
def create_custom_forward(module):
|
| 912 |
+
def custom_forward(*inputs):
|
| 913 |
+
# None for past_key_value
|
| 914 |
+
return module(*inputs, use_cache, output_attentions)
|
| 915 |
+
|
| 916 |
+
return custom_forward
|
| 917 |
+
|
| 918 |
+
outputs = torch.utils.checkpoint.checkpoint(
|
| 919 |
+
create_custom_forward(block),
|
| 920 |
+
hidden_states,
|
| 921 |
+
rotary_pos_emb_list,
|
| 922 |
+
self.registered_causal_mask,
|
| 923 |
+
None,
|
| 924 |
+
attention_mask,
|
| 925 |
+
head_mask[i],
|
| 926 |
+
encoder_hidden_states,
|
| 927 |
+
encoder_attention_mask,
|
| 928 |
+
)
|
| 929 |
+
else:
|
| 930 |
+
outputs = block(
|
| 931 |
+
hidden_states,
|
| 932 |
+
layer_past=layer_past,
|
| 933 |
+
rotary_pos_emb_list=rotary_pos_emb_list,
|
| 934 |
+
registered_causal_mask=self.registered_causal_mask,
|
| 935 |
+
attention_mask=attention_mask,
|
| 936 |
+
head_mask=head_mask[i],
|
| 937 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 938 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 939 |
+
use_cache=use_cache,
|
| 940 |
+
output_attentions=output_attentions,
|
| 941 |
+
)
|
| 942 |
+
|
| 943 |
+
hidden_states = outputs[0]
|
| 944 |
+
if use_cache is True:
|
| 945 |
+
presents = presents + (outputs[1],)
|
| 946 |
+
|
| 947 |
+
if output_attentions:
|
| 948 |
+
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
| 949 |
+
|
| 950 |
+
hidden_states = self.ln_f(hidden_states)
|
| 951 |
+
hidden_states = hidden_states.view(output_shape)
|
| 952 |
+
# Add last hidden state
|
| 953 |
+
if output_hidden_states:
|
| 954 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 955 |
+
|
| 956 |
+
if not return_dict:
|
| 957 |
+
return tuple(
|
| 958 |
+
v for v in [hidden_states, presents, all_hidden_states] if v is not None
|
| 959 |
+
)
|
| 960 |
+
|
| 961 |
+
return BaseModelOutputWithPast(
|
| 962 |
+
last_hidden_state=hidden_states,
|
| 963 |
+
past_key_values=presents,
|
| 964 |
+
hidden_states=all_hidden_states,
|
| 965 |
+
attentions=all_self_attentions,
|
| 966 |
+
)
|
| 967 |
+
|
| 968 |
+
|
| 969 |
+
class QWenLMHeadModel(QWenPreTrainedModel):
|
| 970 |
+
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.rotary_emb\.inv_freq"]
|
| 971 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.masked_bias"]
|
| 972 |
+
|
| 973 |
+
def __init__(self, config):
|
| 974 |
+
super().__init__(config)
|
| 975 |
+
assert (
|
| 976 |
+
config.bf16 + config.fp16 + config.fp32 <= 1
|
| 977 |
+
), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true"
|
| 978 |
+
logger.warn(
|
| 979 |
+
"Warning: please make sure that you are using the latest codes and checkpoints, "
|
| 980 |
+
"especially if you used Qwen-7B before 09.25.2023."
|
| 981 |
+
"请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。"
|
| 982 |
+
)
|
| 983 |
+
|
| 984 |
+
autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0
|
| 985 |
+
|
| 986 |
+
if autoset_precision:
|
| 987 |
+
if SUPPORT_BF16:
|
| 988 |
+
logger.warn(
|
| 989 |
+
"The model is automatically converting to bf16 for faster inference. "
|
| 990 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 991 |
+
)
|
| 992 |
+
config.bf16 = True
|
| 993 |
+
elif SUPPORT_FP16:
|
| 994 |
+
logger.warn(
|
| 995 |
+
"The model is automatically converting to fp16 for faster inference. "
|
| 996 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 997 |
+
)
|
| 998 |
+
config.fp16 = True
|
| 999 |
+
else:
|
| 1000 |
+
config.fp32 = True
|
| 1001 |
+
|
| 1002 |
+
if config.bf16 and SUPPORT_CUDA and not SUPPORT_BF16:
|
| 1003 |
+
logger.warn("Your device does NOT seem to support bf16, you can switch to fp16 or fp32 by by passing fp16/fp32=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1004 |
+
if config.fp16 and SUPPORT_CUDA and not SUPPORT_FP16:
|
| 1005 |
+
logger.warn("Your device does NOT support faster inference with fp16, please switch to fp32 which is likely to be faster")
|
| 1006 |
+
if config.fp32:
|
| 1007 |
+
if SUPPORT_BF16:
|
| 1008 |
+
logger.warn("Your device support faster inference by passing bf16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1009 |
+
elif SUPPORT_FP16:
|
| 1010 |
+
logger.warn("Your device support faster inference by passing fp16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1011 |
+
|
| 1012 |
+
if config.use_flash_attn == "auto":
|
| 1013 |
+
if config.bf16 or config.fp16:
|
| 1014 |
+
logger.warn("Try importing flash-attention for faster inference...")
|
| 1015 |
+
config.use_flash_attn = True
|
| 1016 |
+
else:
|
| 1017 |
+
config.use_flash_attn = False
|
| 1018 |
+
if config.use_flash_attn and config.fp32:
|
| 1019 |
+
logger.warn("Flash attention will be disabled because it does NOT support fp32.")
|
| 1020 |
+
|
| 1021 |
+
if config.use_flash_attn:
|
| 1022 |
+
_import_flash_attn()
|
| 1023 |
+
|
| 1024 |
+
|
| 1025 |
+
if hasattr(config, 'use_cache_quantization') and config.use_cache_quantization:
|
| 1026 |
+
config.use_flash_attn = False
|
| 1027 |
+
if hasattr(config, 'use_cache_kernel') and config.use_cache_kernel:
|
| 1028 |
+
try:
|
| 1029 |
+
from kernels.cpp_kernels import cache_autogptq_cuda_256
|
| 1030 |
+
except ImportError:
|
| 1031 |
+
cache_autogptq_cuda_256 = None
|
| 1032 |
+
|
| 1033 |
+
self.transformer = QWenModel(config)
|
| 1034 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1035 |
+
|
| 1036 |
+
if config.bf16:
|
| 1037 |
+
self.transformer.bfloat16()
|
| 1038 |
+
self.lm_head.bfloat16()
|
| 1039 |
+
if config.fp16:
|
| 1040 |
+
self.transformer.half()
|
| 1041 |
+
self.lm_head.half()
|
| 1042 |
+
self.post_init()
|
| 1043 |
+
|
| 1044 |
+
|
| 1045 |
+
def get_output_embeddings(self):
|
| 1046 |
+
return self.lm_head
|
| 1047 |
+
|
| 1048 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1049 |
+
self.lm_head = new_embeddings
|
| 1050 |
+
|
| 1051 |
+
def prepare_inputs_for_generation(
|
| 1052 |
+
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
| 1053 |
+
):
|
| 1054 |
+
token_type_ids = kwargs.get("token_type_ids", None)
|
| 1055 |
+
if past_key_values:
|
| 1056 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 1057 |
+
if token_type_ids is not None:
|
| 1058 |
+
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
|
| 1059 |
+
|
| 1060 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 1061 |
+
position_ids = kwargs.get("position_ids", None)
|
| 1062 |
+
|
| 1063 |
+
if attention_mask is not None and position_ids is None:
|
| 1064 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1065 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1066 |
+
if past_key_values:
|
| 1067 |
+
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 1068 |
+
else:
|
| 1069 |
+
position_ids = None
|
| 1070 |
+
|
| 1071 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1072 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1073 |
+
else:
|
| 1074 |
+
model_inputs = {"input_ids": input_ids}
|
| 1075 |
+
|
| 1076 |
+
model_inputs.update(
|
| 1077 |
+
{
|
| 1078 |
+
"past_key_values": past_key_values,
|
| 1079 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1080 |
+
"position_ids": position_ids,
|
| 1081 |
+
"attention_mask": attention_mask,
|
| 1082 |
+
"token_type_ids": token_type_ids,
|
| 1083 |
+
}
|
| 1084 |
+
)
|
| 1085 |
+
return model_inputs
|
| 1086 |
+
|
| 1087 |
+
def forward(
|
| 1088 |
+
self,
|
| 1089 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1090 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1091 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1092 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1093 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1094 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1095 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1096 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 1097 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1098 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1099 |
+
use_cache: Optional[bool] = None,
|
| 1100 |
+
output_attentions: Optional[bool] = None,
|
| 1101 |
+
output_hidden_states: Optional[bool] = None,
|
| 1102 |
+
return_dict: Optional[bool] = None,
|
| 1103 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1104 |
+
|
| 1105 |
+
return_dict = (
|
| 1106 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1107 |
+
)
|
| 1108 |
+
|
| 1109 |
+
transformer_outputs = self.transformer(
|
| 1110 |
+
input_ids,
|
| 1111 |
+
past_key_values=past_key_values,
|
| 1112 |
+
attention_mask=attention_mask,
|
| 1113 |
+
token_type_ids=token_type_ids,
|
| 1114 |
+
position_ids=position_ids,
|
| 1115 |
+
head_mask=head_mask,
|
| 1116 |
+
inputs_embeds=inputs_embeds,
|
| 1117 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1118 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1119 |
+
use_cache=use_cache,
|
| 1120 |
+
output_attentions=output_attentions,
|
| 1121 |
+
output_hidden_states=output_hidden_states,
|
| 1122 |
+
return_dict=return_dict,
|
| 1123 |
+
)
|
| 1124 |
+
hidden_states = transformer_outputs[0]
|
| 1125 |
+
|
| 1126 |
+
lm_logits = self.lm_head(hidden_states)
|
| 1127 |
+
|
| 1128 |
+
loss = None
|
| 1129 |
+
if labels is not None:
|
| 1130 |
+
labels = labels.to(lm_logits.device)
|
| 1131 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 1132 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1133 |
+
loss_fct = CrossEntropyLoss()
|
| 1134 |
+
loss = loss_fct(
|
| 1135 |
+
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
|
| 1136 |
+
)
|
| 1137 |
+
|
| 1138 |
+
if not return_dict:
|
| 1139 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 1140 |
+
return ((loss,) + output) if loss is not None else output
|
| 1141 |
+
|
| 1142 |
+
return CausalLMOutputWithPast(
|
| 1143 |
+
loss=loss,
|
| 1144 |
+
logits=lm_logits,
|
| 1145 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1146 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1147 |
+
attentions=transformer_outputs.attentions,
|
| 1148 |
+
)
|
| 1149 |
+
|
| 1150 |
+
@staticmethod
|
| 1151 |
+
def _reorder_cache(
|
| 1152 |
+
past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
|
| 1153 |
+
) -> Tuple[Tuple[torch.Tensor]]:
|
| 1154 |
+
|
| 1155 |
+
return tuple(
|
| 1156 |
+
tuple(
|
| 1157 |
+
past_state.index_select(0, beam_idx.to(past_state.device))
|
| 1158 |
+
for past_state in layer_past
|
| 1159 |
+
)
|
| 1160 |
+
for layer_past in past_key_values
|
| 1161 |
+
)
|
| 1162 |
+
|
| 1163 |
+
def chat(
|
| 1164 |
+
self,
|
| 1165 |
+
tokenizer: PreTrainedTokenizer,
|
| 1166 |
+
query: str,
|
| 1167 |
+
history: Optional[HistoryType],
|
| 1168 |
+
system: str = "You are a helpful assistant.",
|
| 1169 |
+
append_history: bool = True,
|
| 1170 |
+
stream: Optional[bool] = _SENTINEL,
|
| 1171 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1172 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1173 |
+
**kwargs,
|
| 1174 |
+
) -> Tuple[str, HistoryType]:
|
| 1175 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1176 |
+
|
| 1177 |
+
assert stream is _SENTINEL, _ERROR_STREAM_IN_CHAT
|
| 1178 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1179 |
+
if history is None:
|
| 1180 |
+
history = []
|
| 1181 |
+
if stop_words_ids is None:
|
| 1182 |
+
stop_words_ids = []
|
| 1183 |
+
|
| 1184 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1185 |
+
if max_window_size is None:
|
| 1186 |
+
max_window_size = generation_config.max_window_size
|
| 1187 |
+
raw_text, context_tokens = make_context(
|
| 1188 |
+
tokenizer,
|
| 1189 |
+
query,
|
| 1190 |
+
history=history,
|
| 1191 |
+
system=system,
|
| 1192 |
+
max_window_size=max_window_size,
|
| 1193 |
+
chat_format=generation_config.chat_format,
|
| 1194 |
+
)
|
| 1195 |
+
|
| 1196 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1197 |
+
generation_config.chat_format, tokenizer
|
| 1198 |
+
))
|
| 1199 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1200 |
+
outputs = self.generate(
|
| 1201 |
+
input_ids,
|
| 1202 |
+
stop_words_ids=stop_words_ids,
|
| 1203 |
+
return_dict_in_generate=False,
|
| 1204 |
+
generation_config=generation_config,
|
| 1205 |
+
**kwargs,
|
| 1206 |
+
)
|
| 1207 |
+
|
| 1208 |
+
response = decode_tokens(
|
| 1209 |
+
outputs[0],
|
| 1210 |
+
tokenizer,
|
| 1211 |
+
raw_text_len=len(raw_text),
|
| 1212 |
+
context_length=len(context_tokens),
|
| 1213 |
+
chat_format=generation_config.chat_format,
|
| 1214 |
+
verbose=False,
|
| 1215 |
+
errors='replace'
|
| 1216 |
+
)
|
| 1217 |
+
|
| 1218 |
+
if append_history:
|
| 1219 |
+
history.append((query, response))
|
| 1220 |
+
|
| 1221 |
+
return response, history
|
| 1222 |
+
|
| 1223 |
+
def chat_stream(
|
| 1224 |
+
self,
|
| 1225 |
+
tokenizer: PreTrainedTokenizer,
|
| 1226 |
+
query: str,
|
| 1227 |
+
history: Optional[HistoryType],
|
| 1228 |
+
system: str = "You are a helpful assistant.",
|
| 1229 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1230 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1231 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1232 |
+
**kwargs,
|
| 1233 |
+
) -> Generator[str, Any, None]:
|
| 1234 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1235 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1236 |
+
if history is None:
|
| 1237 |
+
history = []
|
| 1238 |
+
if stop_words_ids is None:
|
| 1239 |
+
stop_words_ids = []
|
| 1240 |
+
|
| 1241 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1242 |
+
if max_window_size is None:
|
| 1243 |
+
max_window_size = generation_config.max_window_size
|
| 1244 |
+
raw_text, context_tokens = make_context(
|
| 1245 |
+
tokenizer,
|
| 1246 |
+
query,
|
| 1247 |
+
history=history,
|
| 1248 |
+
system=system,
|
| 1249 |
+
max_window_size=max_window_size,
|
| 1250 |
+
chat_format=generation_config.chat_format,
|
| 1251 |
+
)
|
| 1252 |
+
|
| 1253 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1254 |
+
generation_config.chat_format, tokenizer
|
| 1255 |
+
))
|
| 1256 |
+
if stop_words_ids is not None:
|
| 1257 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1258 |
+
stop_words_ids=stop_words_ids,
|
| 1259 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1260 |
+
)
|
| 1261 |
+
if logits_processor is None:
|
| 1262 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1263 |
+
else:
|
| 1264 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1265 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1266 |
+
|
| 1267 |
+
from transformers_stream_generator.main import NewGenerationMixin, StreamGenerationConfig
|
| 1268 |
+
self.__class__.generate_stream = NewGenerationMixin.generate
|
| 1269 |
+
self.__class__.sample_stream = NewGenerationMixin.sample_stream
|
| 1270 |
+
stream_config = StreamGenerationConfig(**generation_config.to_dict(), do_stream=True)
|
| 1271 |
+
|
| 1272 |
+
def stream_generator():
|
| 1273 |
+
outputs = []
|
| 1274 |
+
for token in self.generate_stream(
|
| 1275 |
+
input_ids,
|
| 1276 |
+
return_dict_in_generate=False,
|
| 1277 |
+
generation_config=stream_config,
|
| 1278 |
+
logits_processor=logits_processor,
|
| 1279 |
+
seed=-1,
|
| 1280 |
+
**kwargs):
|
| 1281 |
+
outputs.append(token.item())
|
| 1282 |
+
yield tokenizer.decode(outputs, skip_special_tokens=True, errors='ignore')
|
| 1283 |
+
|
| 1284 |
+
return stream_generator()
|
| 1285 |
+
|
| 1286 |
+
def generate(
|
| 1287 |
+
self,
|
| 1288 |
+
inputs: Optional[torch.Tensor] = None,
|
| 1289 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1290 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1291 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
| 1292 |
+
prefix_allowed_tokens_fn: Optional[
|
| 1293 |
+
Callable[[int, torch.Tensor], List[int]]
|
| 1294 |
+
] = None,
|
| 1295 |
+
synced_gpus: Optional[bool] = None,
|
| 1296 |
+
assistant_model: Optional["PreTrainedModel"] = None,
|
| 1297 |
+
streamer: Optional["BaseStreamer"] = None,
|
| 1298 |
+
**kwargs,
|
| 1299 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 1300 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1301 |
+
|
| 1302 |
+
# Process stop_words_ids.
|
| 1303 |
+
stop_words_ids = kwargs.pop("stop_words_ids", None)
|
| 1304 |
+
if stop_words_ids is None and generation_config is not None:
|
| 1305 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1306 |
+
if stop_words_ids is None:
|
| 1307 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1308 |
+
|
| 1309 |
+
if stop_words_ids is not None:
|
| 1310 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1311 |
+
stop_words_ids=stop_words_ids,
|
| 1312 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1313 |
+
)
|
| 1314 |
+
if logits_processor is None:
|
| 1315 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1316 |
+
else:
|
| 1317 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1318 |
+
|
| 1319 |
+
return super().generate(
|
| 1320 |
+
inputs,
|
| 1321 |
+
generation_config=generation_config,
|
| 1322 |
+
logits_processor=logits_processor,
|
| 1323 |
+
stopping_criteria=stopping_criteria,
|
| 1324 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 1325 |
+
synced_gpus=synced_gpus,
|
| 1326 |
+
assistant_model=assistant_model,
|
| 1327 |
+
streamer=streamer,
|
| 1328 |
+
**kwargs,
|
| 1329 |
+
)
|
| 1330 |
+
|
| 1331 |
+
|
| 1332 |
+
class RotaryEmbedding(torch.nn.Module):
|
| 1333 |
+
def __init__(self, dim, base=10000):
|
| 1334 |
+
super().__init__()
|
| 1335 |
+
self.dim = dim
|
| 1336 |
+
self.base = base
|
| 1337 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 1338 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 1339 |
+
if importlib.util.find_spec("einops") is None:
|
| 1340 |
+
raise RuntimeError("einops is required for Rotary Embedding")
|
| 1341 |
+
|
| 1342 |
+
self._rotary_pos_emb_cache = None
|
| 1343 |
+
self._seq_len_cached = 0
|
| 1344 |
+
self._ntk_alpha_cached = 1.0
|
| 1345 |
+
self._ntk_alpha_cached_list = [1.0]
|
| 1346 |
+
|
| 1347 |
+
def update_rotary_pos_emb_cache(self, max_seq_len, offset=0, ntk_alpha=1.0):
|
| 1348 |
+
seqlen = max_seq_len + offset
|
| 1349 |
+
if seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:
|
| 1350 |
+
base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))
|
| 1351 |
+
self.inv_freq = 1.0 / (
|
| 1352 |
+
base
|
| 1353 |
+
** (
|
| 1354 |
+
torch.arange(0, self.dim, 2, device=self.inv_freq.device).float()
|
| 1355 |
+
/ self.dim
|
| 1356 |
+
)
|
| 1357 |
+
)
|
| 1358 |
+
self._seq_len_cached = max(2 * seqlen, 16)
|
| 1359 |
+
self._ntk_alpha_cached = ntk_alpha
|
| 1360 |
+
seq = torch.arange(self._seq_len_cached, device=self.inv_freq.device)
|
| 1361 |
+
freqs = torch.outer(seq.type_as(self.inv_freq), self.inv_freq)
|
| 1362 |
+
|
| 1363 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 1364 |
+
from einops import rearrange
|
| 1365 |
+
|
| 1366 |
+
emb = rearrange(emb, "n d -> 1 n 1 d")
|
| 1367 |
+
|
| 1368 |
+
cos, sin = emb.cos(), emb.sin()
|
| 1369 |
+
self._rotary_pos_emb_cache = [cos, sin]
|
| 1370 |
+
|
| 1371 |
+
def forward(self, max_seq_len, offset=0, ntk_alpha=1.0):
|
| 1372 |
+
self.update_rotary_pos_emb_cache(max_seq_len, offset, ntk_alpha)
|
| 1373 |
+
cos, sin = self._rotary_pos_emb_cache
|
| 1374 |
+
return [cos[:, offset : offset + max_seq_len], sin[:, offset : offset + max_seq_len]]
|
| 1375 |
+
|
| 1376 |
+
|
| 1377 |
+
def _rotate_half(x):
|
| 1378 |
+
from einops import rearrange
|
| 1379 |
+
|
| 1380 |
+
x = rearrange(x, "... (j d) -> ... j d", j=2)
|
| 1381 |
+
x1, x2 = x.unbind(dim=-2)
|
| 1382 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 1383 |
+
|
| 1384 |
+
|
| 1385 |
+
def apply_rotary_pos_emb(t, freqs):
|
| 1386 |
+
cos, sin = freqs
|
| 1387 |
+
if apply_rotary_emb_func is not None and t.is_cuda:
|
| 1388 |
+
t_ = t.float()
|
| 1389 |
+
cos = cos.squeeze(0).squeeze(1)[:, : cos.shape[-1] // 2]
|
| 1390 |
+
sin = sin.squeeze(0).squeeze(1)[:, : sin.shape[-1] // 2]
|
| 1391 |
+
output = apply_rotary_emb_func(t_, cos, sin).type_as(t)
|
| 1392 |
+
return output
|
| 1393 |
+
else:
|
| 1394 |
+
rot_dim = freqs[0].shape[-1]
|
| 1395 |
+
cos, sin = freqs
|
| 1396 |
+
t_, t_pass_ = t[..., :rot_dim], t[..., rot_dim:]
|
| 1397 |
+
t_ = t_.float()
|
| 1398 |
+
t_pass_ = t_pass_.float()
|
| 1399 |
+
t_ = (t_ * cos) + (_rotate_half(t_) * sin)
|
| 1400 |
+
return torch.cat((t_, t_pass_), dim=-1).type_as(t)
|
| 1401 |
+
|
| 1402 |
+
|
| 1403 |
+
class RMSNorm(torch.nn.Module):
|
| 1404 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 1405 |
+
super().__init__()
|
| 1406 |
+
self.eps = eps
|
| 1407 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 1408 |
+
|
| 1409 |
+
def _norm(self, x):
|
| 1410 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 1411 |
+
|
| 1412 |
+
def forward(self, x):
|
| 1413 |
+
if rms_norm is not None and x.is_cuda:
|
| 1414 |
+
return rms_norm(x, self.weight, self.eps)
|
| 1415 |
+
else:
|
| 1416 |
+
output = self._norm(x.float()).type_as(x)
|
| 1417 |
+
return output * self.weight
|
pytorch_model-00001-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3d754cfdf088b451d1dd857d2e59fd8f4fb88c6a7874ea745293e5b417ef2489
|
| 3 |
+
size 9963537981
|
pytorch_model-00002-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a98a484e0663d6dfe99ebdeb0720b28ed20b66ec897e5077123ce169af0585c1
|
| 3 |
+
size 9878407559
|
pytorch_model-00003-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:79bc6809ec8d0f4af76274a47873f983e5346d6ff04bb727368521cb19301912
|
| 3 |
+
size 8492748925
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 28334581760
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00003-of-00003.bin",
|
| 7 |
+
"transformer.h.0.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 8 |
+
"transformer.h.0.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 9 |
+
"transformer.h.0.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 10 |
+
"transformer.h.0.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 11 |
+
"transformer.h.0.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 12 |
+
"transformer.h.0.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 13 |
+
"transformer.h.0.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 14 |
+
"transformer.h.0.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 15 |
+
"transformer.h.1.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 16 |
+
"transformer.h.1.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 17 |
+
"transformer.h.1.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 18 |
+
"transformer.h.1.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 19 |
+
"transformer.h.1.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 20 |
+
"transformer.h.1.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 21 |
+
"transformer.h.1.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 22 |
+
"transformer.h.1.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 23 |
+
"transformer.h.10.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 24 |
+
"transformer.h.10.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 25 |
+
"transformer.h.10.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 26 |
+
"transformer.h.10.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 27 |
+
"transformer.h.10.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 28 |
+
"transformer.h.10.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 29 |
+
"transformer.h.10.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 30 |
+
"transformer.h.10.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 31 |
+
"transformer.h.11.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 32 |
+
"transformer.h.11.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 33 |
+
"transformer.h.11.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 34 |
+
"transformer.h.11.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 35 |
+
"transformer.h.11.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 36 |
+
"transformer.h.11.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 37 |
+
"transformer.h.11.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 38 |
+
"transformer.h.11.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 39 |
+
"transformer.h.12.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 40 |
+
"transformer.h.12.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 41 |
+
"transformer.h.12.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 42 |
+
"transformer.h.12.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 43 |
+
"transformer.h.12.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 44 |
+
"transformer.h.12.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 45 |
+
"transformer.h.12.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 46 |
+
"transformer.h.12.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 47 |
+
"transformer.h.13.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 48 |
+
"transformer.h.13.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 49 |
+
"transformer.h.13.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 50 |
+
"transformer.h.13.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 51 |
+
"transformer.h.13.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 52 |
+
"transformer.h.13.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 53 |
+
"transformer.h.13.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 54 |
+
"transformer.h.13.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 55 |
+
"transformer.h.14.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 56 |
+
"transformer.h.14.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 57 |
+
"transformer.h.14.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 58 |
+
"transformer.h.14.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 59 |
+
"transformer.h.14.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 60 |
+
"transformer.h.14.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 61 |
+
"transformer.h.14.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 62 |
+
"transformer.h.14.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 63 |
+
"transformer.h.15.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 64 |
+
"transformer.h.15.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 65 |
+
"transformer.h.15.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 66 |
+
"transformer.h.15.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 67 |
+
"transformer.h.15.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 68 |
+
"transformer.h.15.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 69 |
+
"transformer.h.15.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 70 |
+
"transformer.h.15.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 71 |
+
"transformer.h.16.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 72 |
+
"transformer.h.16.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 73 |
+
"transformer.h.16.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 74 |
+
"transformer.h.16.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 75 |
+
"transformer.h.16.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 76 |
+
"transformer.h.16.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 77 |
+
"transformer.h.16.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 78 |
+
"transformer.h.16.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 79 |
+
"transformer.h.17.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 80 |
+
"transformer.h.17.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 81 |
+
"transformer.h.17.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 82 |
+
"transformer.h.17.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 83 |
+
"transformer.h.17.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 84 |
+
"transformer.h.17.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 85 |
+
"transformer.h.17.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 86 |
+
"transformer.h.17.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 87 |
+
"transformer.h.18.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 88 |
+
"transformer.h.18.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 89 |
+
"transformer.h.18.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 90 |
+
"transformer.h.18.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 91 |
+
"transformer.h.18.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 92 |
+
"transformer.h.18.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 93 |
+
"transformer.h.18.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 94 |
+
"transformer.h.18.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 95 |
+
"transformer.h.19.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 96 |
+
"transformer.h.19.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 97 |
+
"transformer.h.19.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 98 |
+
"transformer.h.19.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 99 |
+
"transformer.h.19.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 100 |
+
"transformer.h.19.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 101 |
+
"transformer.h.19.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 102 |
+
"transformer.h.19.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 103 |
+
"transformer.h.2.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 104 |
+
"transformer.h.2.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 105 |
+
"transformer.h.2.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 106 |
+
"transformer.h.2.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 107 |
+
"transformer.h.2.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 108 |
+
"transformer.h.2.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 109 |
+
"transformer.h.2.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 110 |
+
"transformer.h.2.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 111 |
+
"transformer.h.20.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 112 |
+
"transformer.h.20.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 113 |
+
"transformer.h.20.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 114 |
+
"transformer.h.20.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 115 |
+
"transformer.h.20.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 116 |
+
"transformer.h.20.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 117 |
+
"transformer.h.20.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 118 |
+
"transformer.h.20.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 119 |
+
"transformer.h.21.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 120 |
+
"transformer.h.21.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 121 |
+
"transformer.h.21.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 122 |
+
"transformer.h.21.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 123 |
+
"transformer.h.21.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 124 |
+
"transformer.h.21.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 125 |
+
"transformer.h.21.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 126 |
+
"transformer.h.21.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 127 |
+
"transformer.h.22.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 128 |
+
"transformer.h.22.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 129 |
+
"transformer.h.22.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 130 |
+
"transformer.h.22.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 131 |
+
"transformer.h.22.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 132 |
+
"transformer.h.22.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 133 |
+
"transformer.h.22.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 134 |
+
"transformer.h.22.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 135 |
+
"transformer.h.23.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 136 |
+
"transformer.h.23.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 137 |
+
"transformer.h.23.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 138 |
+
"transformer.h.23.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 139 |
+
"transformer.h.23.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 140 |
+
"transformer.h.23.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 141 |
+
"transformer.h.23.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 142 |
+
"transformer.h.23.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 143 |
+
"transformer.h.24.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 144 |
+
"transformer.h.24.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 145 |
+
"transformer.h.24.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 146 |
+
"transformer.h.24.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 147 |
+
"transformer.h.24.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 148 |
+
"transformer.h.24.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 149 |
+
"transformer.h.24.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 150 |
+
"transformer.h.24.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 151 |
+
"transformer.h.25.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 152 |
+
"transformer.h.25.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 153 |
+
"transformer.h.25.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 154 |
+
"transformer.h.25.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 155 |
+
"transformer.h.25.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 156 |
+
"transformer.h.25.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 157 |
+
"transformer.h.25.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 158 |
+
"transformer.h.25.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 159 |
+
"transformer.h.26.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 160 |
+
"transformer.h.26.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 161 |
+
"transformer.h.26.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 162 |
+
"transformer.h.26.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 163 |
+
"transformer.h.26.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 164 |
+
"transformer.h.26.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 165 |
+
"transformer.h.26.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 166 |
+
"transformer.h.26.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 167 |
+
"transformer.h.27.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 168 |
+
"transformer.h.27.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 169 |
+
"transformer.h.27.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 170 |
+
"transformer.h.27.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 171 |
+
"transformer.h.27.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 172 |
+
"transformer.h.27.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 173 |
+
"transformer.h.27.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 174 |
+
"transformer.h.27.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 175 |
+
"transformer.h.28.attn.c_attn.bias": "pytorch_model-00002-of-00003.bin",
|
| 176 |
+
"transformer.h.28.attn.c_attn.weight": "pytorch_model-00002-of-00003.bin",
|
| 177 |
+
"transformer.h.28.attn.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 178 |
+
"transformer.h.28.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 179 |
+
"transformer.h.28.ln_2.weight": "pytorch_model-00002-of-00003.bin",
|
| 180 |
+
"transformer.h.28.mlp.c_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 181 |
+
"transformer.h.28.mlp.w1.weight": "pytorch_model-00002-of-00003.bin",
|
| 182 |
+
"transformer.h.28.mlp.w2.weight": "pytorch_model-00002-of-00003.bin",
|
| 183 |
+
"transformer.h.29.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 184 |
+
"transformer.h.29.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 185 |
+
"transformer.h.29.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 186 |
+
"transformer.h.29.ln_1.weight": "pytorch_model-00002-of-00003.bin",
|
| 187 |
+
"transformer.h.29.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 188 |
+
"transformer.h.29.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 189 |
+
"transformer.h.29.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 190 |
+
"transformer.h.29.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 191 |
+
"transformer.h.3.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 192 |
+
"transformer.h.3.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 193 |
+
"transformer.h.3.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 194 |
+
"transformer.h.3.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 195 |
+
"transformer.h.3.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 196 |
+
"transformer.h.3.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 197 |
+
"transformer.h.3.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 198 |
+
"transformer.h.3.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 199 |
+
"transformer.h.30.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 200 |
+
"transformer.h.30.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 201 |
+
"transformer.h.30.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 202 |
+
"transformer.h.30.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 203 |
+
"transformer.h.30.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 204 |
+
"transformer.h.30.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 205 |
+
"transformer.h.30.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 206 |
+
"transformer.h.30.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 207 |
+
"transformer.h.31.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 208 |
+
"transformer.h.31.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 209 |
+
"transformer.h.31.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 210 |
+
"transformer.h.31.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 211 |
+
"transformer.h.31.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 212 |
+
"transformer.h.31.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 213 |
+
"transformer.h.31.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 214 |
+
"transformer.h.31.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 215 |
+
"transformer.h.32.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 216 |
+
"transformer.h.32.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 217 |
+
"transformer.h.32.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 218 |
+
"transformer.h.32.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 219 |
+
"transformer.h.32.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 220 |
+
"transformer.h.32.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 221 |
+
"transformer.h.32.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 222 |
+
"transformer.h.32.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 223 |
+
"transformer.h.33.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 224 |
+
"transformer.h.33.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 225 |
+
"transformer.h.33.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 226 |
+
"transformer.h.33.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 227 |
+
"transformer.h.33.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 228 |
+
"transformer.h.33.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 229 |
+
"transformer.h.33.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 230 |
+
"transformer.h.33.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 231 |
+
"transformer.h.34.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 232 |
+
"transformer.h.34.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 233 |
+
"transformer.h.34.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 234 |
+
"transformer.h.34.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 235 |
+
"transformer.h.34.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 236 |
+
"transformer.h.34.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 237 |
+
"transformer.h.34.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 238 |
+
"transformer.h.34.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 239 |
+
"transformer.h.35.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 240 |
+
"transformer.h.35.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 241 |
+
"transformer.h.35.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 242 |
+
"transformer.h.35.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 243 |
+
"transformer.h.35.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 244 |
+
"transformer.h.35.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 245 |
+
"transformer.h.35.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 246 |
+
"transformer.h.35.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 247 |
+
"transformer.h.36.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 248 |
+
"transformer.h.36.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 249 |
+
"transformer.h.36.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 250 |
+
"transformer.h.36.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 251 |
+
"transformer.h.36.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 252 |
+
"transformer.h.36.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 253 |
+
"transformer.h.36.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 254 |
+
"transformer.h.36.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 255 |
+
"transformer.h.37.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 256 |
+
"transformer.h.37.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 257 |
+
"transformer.h.37.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 258 |
+
"transformer.h.37.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 259 |
+
"transformer.h.37.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 260 |
+
"transformer.h.37.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 261 |
+
"transformer.h.37.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 262 |
+
"transformer.h.37.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 263 |
+
"transformer.h.38.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 264 |
+
"transformer.h.38.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 265 |
+
"transformer.h.38.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 266 |
+
"transformer.h.38.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 267 |
+
"transformer.h.38.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 268 |
+
"transformer.h.38.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 269 |
+
"transformer.h.38.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 270 |
+
"transformer.h.38.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 271 |
+
"transformer.h.39.attn.c_attn.bias": "pytorch_model-00003-of-00003.bin",
|
| 272 |
+
"transformer.h.39.attn.c_attn.weight": "pytorch_model-00003-of-00003.bin",
|
| 273 |
+
"transformer.h.39.attn.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 274 |
+
"transformer.h.39.ln_1.weight": "pytorch_model-00003-of-00003.bin",
|
| 275 |
+
"transformer.h.39.ln_2.weight": "pytorch_model-00003-of-00003.bin",
|
| 276 |
+
"transformer.h.39.mlp.c_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 277 |
+
"transformer.h.39.mlp.w1.weight": "pytorch_model-00003-of-00003.bin",
|
| 278 |
+
"transformer.h.39.mlp.w2.weight": "pytorch_model-00003-of-00003.bin",
|
| 279 |
+
"transformer.h.4.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 280 |
+
"transformer.h.4.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 281 |
+
"transformer.h.4.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 282 |
+
"transformer.h.4.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 283 |
+
"transformer.h.4.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 284 |
+
"transformer.h.4.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 285 |
+
"transformer.h.4.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 286 |
+
"transformer.h.4.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 287 |
+
"transformer.h.5.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 288 |
+
"transformer.h.5.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 289 |
+
"transformer.h.5.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 290 |
+
"transformer.h.5.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 291 |
+
"transformer.h.5.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 292 |
+
"transformer.h.5.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 293 |
+
"transformer.h.5.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 294 |
+
"transformer.h.5.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 295 |
+
"transformer.h.6.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 296 |
+
"transformer.h.6.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 297 |
+
"transformer.h.6.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 298 |
+
"transformer.h.6.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 299 |
+
"transformer.h.6.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 300 |
+
"transformer.h.6.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 301 |
+
"transformer.h.6.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 302 |
+
"transformer.h.6.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 303 |
+
"transformer.h.7.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 304 |
+
"transformer.h.7.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 305 |
+
"transformer.h.7.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 306 |
+
"transformer.h.7.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 307 |
+
"transformer.h.7.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 308 |
+
"transformer.h.7.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 309 |
+
"transformer.h.7.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 310 |
+
"transformer.h.7.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 311 |
+
"transformer.h.8.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 312 |
+
"transformer.h.8.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 313 |
+
"transformer.h.8.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 314 |
+
"transformer.h.8.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 315 |
+
"transformer.h.8.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 316 |
+
"transformer.h.8.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 317 |
+
"transformer.h.8.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 318 |
+
"transformer.h.8.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 319 |
+
"transformer.h.9.attn.c_attn.bias": "pytorch_model-00001-of-00003.bin",
|
| 320 |
+
"transformer.h.9.attn.c_attn.weight": "pytorch_model-00001-of-00003.bin",
|
| 321 |
+
"transformer.h.9.attn.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 322 |
+
"transformer.h.9.ln_1.weight": "pytorch_model-00001-of-00003.bin",
|
| 323 |
+
"transformer.h.9.ln_2.weight": "pytorch_model-00001-of-00003.bin",
|
| 324 |
+
"transformer.h.9.mlp.c_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 325 |
+
"transformer.h.9.mlp.w1.weight": "pytorch_model-00001-of-00003.bin",
|
| 326 |
+
"transformer.h.9.mlp.w2.weight": "pytorch_model-00001-of-00003.bin",
|
| 327 |
+
"transformer.ln_f.weight": "pytorch_model-00003-of-00003.bin",
|
| 328 |
+
"transformer.wte.weight": "pytorch_model-00001-of-00003.bin"
|
| 329 |
+
}
|
| 330 |
+
}
|
qwen.tiktoken
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
qwen_generation_utils.py
ADDED
|
@@ -0,0 +1,420 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Generation support."""
|
| 7 |
+
|
| 8 |
+
from typing import Tuple, List, Union, Iterable
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from transformers import PreTrainedTokenizer
|
| 14 |
+
from transformers import logging
|
| 15 |
+
from transformers.generation import LogitsProcessor
|
| 16 |
+
|
| 17 |
+
logger = logging.get_logger(__name__)
|
| 18 |
+
|
| 19 |
+
# Types.
|
| 20 |
+
HistoryType = List[Tuple[str, str]]
|
| 21 |
+
TokensType = List[int]
|
| 22 |
+
BatchTokensType = List[List[int]]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def pad_batch(batch: BatchTokensType, pad_id: int, seq_length: int) -> BatchTokensType:
|
| 26 |
+
for tokens in batch:
|
| 27 |
+
context_length = len(tokens)
|
| 28 |
+
if context_length < seq_length:
|
| 29 |
+
tokens.extend([pad_id] * (seq_length - context_length))
|
| 30 |
+
return batch
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_ltor_masks_and_position_ids(
|
| 34 |
+
data,
|
| 35 |
+
eod_token,
|
| 36 |
+
reset_position_ids,
|
| 37 |
+
reset_attention_mask,
|
| 38 |
+
eod_mask_loss,
|
| 39 |
+
):
|
| 40 |
+
"""Build masks and position id for left to right model."""
|
| 41 |
+
|
| 42 |
+
# Extract batch size and sequence length.
|
| 43 |
+
micro_batch_size, seq_length = data.size()
|
| 44 |
+
|
| 45 |
+
# Attention mask (lower triangular).
|
| 46 |
+
if reset_attention_mask:
|
| 47 |
+
att_mask_batch = micro_batch_size
|
| 48 |
+
else:
|
| 49 |
+
att_mask_batch = 1
|
| 50 |
+
attention_mask = torch.tril(
|
| 51 |
+
torch.ones((att_mask_batch, seq_length, seq_length), device=data.device)
|
| 52 |
+
).view(att_mask_batch, 1, seq_length, seq_length)
|
| 53 |
+
|
| 54 |
+
# Loss mask.
|
| 55 |
+
loss_mask = torch.ones(data.size(), dtype=torch.float, device=data.device)
|
| 56 |
+
if eod_mask_loss:
|
| 57 |
+
loss_mask[data == eod_token] = 0.0
|
| 58 |
+
|
| 59 |
+
# Position ids.
|
| 60 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=data.device)
|
| 61 |
+
position_ids = position_ids.unsqueeze(0).expand_as(data)
|
| 62 |
+
# We need to clone as the ids will be modifed based on batch index.
|
| 63 |
+
if reset_position_ids:
|
| 64 |
+
position_ids = position_ids.clone()
|
| 65 |
+
|
| 66 |
+
if reset_position_ids or reset_attention_mask:
|
| 67 |
+
# Loop through the batches:
|
| 68 |
+
for b in range(micro_batch_size):
|
| 69 |
+
|
| 70 |
+
# Find indecies where EOD token is.
|
| 71 |
+
eod_index = position_ids[b, data[b] == eod_token]
|
| 72 |
+
# Detach indecies from positions if going to modify positions.
|
| 73 |
+
if reset_position_ids:
|
| 74 |
+
eod_index = eod_index.clone()
|
| 75 |
+
|
| 76 |
+
# Loop through EOD indecies:
|
| 77 |
+
prev_index = 0
|
| 78 |
+
for j in range(eod_index.size()[0]):
|
| 79 |
+
i = eod_index[j]
|
| 80 |
+
# Mask attention loss.
|
| 81 |
+
if reset_attention_mask:
|
| 82 |
+
attention_mask[b, 0, (i + 1) :, : (i + 1)] = 0
|
| 83 |
+
# Reset positions.
|
| 84 |
+
if reset_position_ids:
|
| 85 |
+
position_ids[b, (i + 1) :] -= i + 1 - prev_index
|
| 86 |
+
prev_index = i + 1
|
| 87 |
+
|
| 88 |
+
# Convert attention mask to binary:
|
| 89 |
+
attention_mask = attention_mask < 0.5
|
| 90 |
+
|
| 91 |
+
return attention_mask, loss_mask, position_ids
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def get_batch(context_tokens: torch.LongTensor, eod_id: int):
|
| 95 |
+
"""Generate batch from context tokens."""
|
| 96 |
+
# Move to GPU.
|
| 97 |
+
tokens = context_tokens.contiguous().to(context_tokens.device)
|
| 98 |
+
# Get the attention mask and postition ids.
|
| 99 |
+
attention_mask, _, position_ids = get_ltor_masks_and_position_ids(
|
| 100 |
+
tokens,
|
| 101 |
+
eod_id,
|
| 102 |
+
reset_position_ids=False,
|
| 103 |
+
reset_attention_mask=False,
|
| 104 |
+
eod_mask_loss=False,
|
| 105 |
+
)
|
| 106 |
+
return tokens, attention_mask, position_ids
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_stop_words_ids(chat_format, tokenizer):
|
| 110 |
+
if chat_format == "raw":
|
| 111 |
+
stop_words_ids = [tokenizer.encode("Human:"), [tokenizer.eod_id]]
|
| 112 |
+
elif chat_format == "chatml":
|
| 113 |
+
stop_words_ids = [[tokenizer.im_end_id], [tokenizer.im_start_id]]
|
| 114 |
+
else:
|
| 115 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 116 |
+
return stop_words_ids
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def make_context(
|
| 120 |
+
tokenizer: PreTrainedTokenizer,
|
| 121 |
+
query: str,
|
| 122 |
+
history: List[Tuple[str, str]] = None,
|
| 123 |
+
system: str = "",
|
| 124 |
+
max_window_size: int = 6144,
|
| 125 |
+
chat_format: str = "chatml",
|
| 126 |
+
):
|
| 127 |
+
if history is None:
|
| 128 |
+
history = []
|
| 129 |
+
|
| 130 |
+
if chat_format == "chatml":
|
| 131 |
+
im_start, im_end = "<|im_start|>", "<|im_end|>"
|
| 132 |
+
im_start_tokens = [tokenizer.im_start_id]
|
| 133 |
+
im_end_tokens = [tokenizer.im_end_id]
|
| 134 |
+
nl_tokens = tokenizer.encode("\n")
|
| 135 |
+
|
| 136 |
+
def _tokenize_str(role, content):
|
| 137 |
+
return f"{role}\n{content}", tokenizer.encode(
|
| 138 |
+
role, allowed_special=set(tokenizer.IMAGE_ST)
|
| 139 |
+
) + nl_tokens + tokenizer.encode(content, allowed_special=set(tokenizer.IMAGE_ST))
|
| 140 |
+
|
| 141 |
+
system_text, system_tokens_part = _tokenize_str("system", system)
|
| 142 |
+
system_tokens = im_start_tokens + system_tokens_part + im_end_tokens
|
| 143 |
+
|
| 144 |
+
raw_text = ""
|
| 145 |
+
context_tokens = []
|
| 146 |
+
|
| 147 |
+
for turn_query, turn_response in reversed(history):
|
| 148 |
+
query_text, query_tokens_part = _tokenize_str("user", turn_query)
|
| 149 |
+
query_tokens = im_start_tokens + query_tokens_part + im_end_tokens
|
| 150 |
+
if turn_response is not None:
|
| 151 |
+
response_text, response_tokens_part = _tokenize_str(
|
| 152 |
+
"assistant", turn_response
|
| 153 |
+
)
|
| 154 |
+
response_tokens = im_start_tokens + response_tokens_part + im_end_tokens
|
| 155 |
+
|
| 156 |
+
next_context_tokens = nl_tokens + query_tokens + nl_tokens + response_tokens
|
| 157 |
+
prev_chat = (
|
| 158 |
+
f"\n{im_start}{query_text}{im_end}\n{im_start}{response_text}{im_end}"
|
| 159 |
+
)
|
| 160 |
+
else:
|
| 161 |
+
next_context_tokens = nl_tokens + query_tokens + nl_tokens
|
| 162 |
+
prev_chat = f"\n{im_start}{query_text}{im_end}\n"
|
| 163 |
+
|
| 164 |
+
current_context_size = (
|
| 165 |
+
len(system_tokens) + len(next_context_tokens) + len(context_tokens)
|
| 166 |
+
)
|
| 167 |
+
if current_context_size < max_window_size:
|
| 168 |
+
context_tokens = next_context_tokens + context_tokens
|
| 169 |
+
raw_text = prev_chat + raw_text
|
| 170 |
+
else:
|
| 171 |
+
break
|
| 172 |
+
|
| 173 |
+
context_tokens = system_tokens + context_tokens
|
| 174 |
+
raw_text = f"{im_start}{system_text}{im_end}" + raw_text
|
| 175 |
+
context_tokens += (
|
| 176 |
+
nl_tokens
|
| 177 |
+
+ im_start_tokens
|
| 178 |
+
+ _tokenize_str("user", query)[1]
|
| 179 |
+
+ im_end_tokens
|
| 180 |
+
+ nl_tokens
|
| 181 |
+
+ im_start_tokens
|
| 182 |
+
+ tokenizer.encode("assistant")
|
| 183 |
+
+ nl_tokens
|
| 184 |
+
)
|
| 185 |
+
raw_text += f"\n{im_start}user\n{query}{im_end}\n{im_start}assistant\n"
|
| 186 |
+
|
| 187 |
+
elif chat_format == "raw":
|
| 188 |
+
raw_text = query
|
| 189 |
+
context_tokens = tokenizer.encode(raw_text)
|
| 190 |
+
else:
|
| 191 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 192 |
+
|
| 193 |
+
return raw_text, context_tokens
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def _decode_default(
|
| 197 |
+
tokens: List[int],
|
| 198 |
+
*,
|
| 199 |
+
stop_words: List[str],
|
| 200 |
+
eod_words: List[str],
|
| 201 |
+
tokenizer: PreTrainedTokenizer,
|
| 202 |
+
raw_text_len: int,
|
| 203 |
+
verbose: bool = False,
|
| 204 |
+
return_end_reason: bool = False,
|
| 205 |
+
errors: str='replace',
|
| 206 |
+
):
|
| 207 |
+
trim_decode_tokens = tokenizer.decode(tokens, errors=errors)[raw_text_len:]
|
| 208 |
+
if verbose:
|
| 209 |
+
print("\nRaw Generate: ", trim_decode_tokens)
|
| 210 |
+
|
| 211 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 212 |
+
for stop_word in stop_words:
|
| 213 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 214 |
+
for eod_word in eod_words:
|
| 215 |
+
if eod_word in trim_decode_tokens:
|
| 216 |
+
end_reason = f"Gen {eod_word!r}"
|
| 217 |
+
trim_decode_tokens = trim_decode_tokens.split(eod_word)[0]
|
| 218 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 219 |
+
if verbose:
|
| 220 |
+
print("\nEnd Reason:", end_reason)
|
| 221 |
+
print("\nGenerate: ", trim_decode_tokens)
|
| 222 |
+
|
| 223 |
+
if return_end_reason:
|
| 224 |
+
return trim_decode_tokens, end_reason
|
| 225 |
+
else:
|
| 226 |
+
return trim_decode_tokens
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def _decode_chatml(
|
| 230 |
+
tokens: List[int],
|
| 231 |
+
*,
|
| 232 |
+
stop_words: List[str],
|
| 233 |
+
eod_token_ids: List[int],
|
| 234 |
+
tokenizer: PreTrainedTokenizer,
|
| 235 |
+
raw_text_len: int,
|
| 236 |
+
context_length: int,
|
| 237 |
+
verbose: bool = False,
|
| 238 |
+
return_end_reason: bool = False,
|
| 239 |
+
errors: str='replace'
|
| 240 |
+
):
|
| 241 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 242 |
+
eod_token_idx = context_length
|
| 243 |
+
for eod_token_idx in range(context_length, len(tokens)):
|
| 244 |
+
if tokens[eod_token_idx] in eod_token_ids:
|
| 245 |
+
end_reason = f"Gen {tokenizer.decode([tokens[eod_token_idx]])!r}"
|
| 246 |
+
break
|
| 247 |
+
|
| 248 |
+
trim_decode_tokens = tokenizer.decode(tokens[:eod_token_idx], errors=errors)[raw_text_len:]
|
| 249 |
+
if verbose:
|
| 250 |
+
print("\nRaw Generate w/o EOD:", tokenizer.decode(tokens, errors=errors)[raw_text_len:])
|
| 251 |
+
print("\nRaw Generate:", trim_decode_tokens)
|
| 252 |
+
print("\nEnd Reason:", end_reason)
|
| 253 |
+
for stop_word in stop_words:
|
| 254 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 255 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 256 |
+
if verbose:
|
| 257 |
+
print("\nGenerate:", trim_decode_tokens)
|
| 258 |
+
|
| 259 |
+
if return_end_reason:
|
| 260 |
+
return trim_decode_tokens, end_reason
|
| 261 |
+
else:
|
| 262 |
+
return trim_decode_tokens
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def decode_tokens(
|
| 266 |
+
tokens: Union[torch.LongTensor, TokensType],
|
| 267 |
+
tokenizer: PreTrainedTokenizer,
|
| 268 |
+
raw_text_len: int,
|
| 269 |
+
context_length: int,
|
| 270 |
+
chat_format: str,
|
| 271 |
+
verbose: bool = False,
|
| 272 |
+
return_end_reason: bool = False,
|
| 273 |
+
errors: str="replace",
|
| 274 |
+
) -> str:
|
| 275 |
+
if torch.is_tensor(tokens):
|
| 276 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 277 |
+
|
| 278 |
+
if chat_format == "chatml":
|
| 279 |
+
return _decode_chatml(
|
| 280 |
+
tokens,
|
| 281 |
+
stop_words=[],
|
| 282 |
+
eod_token_ids=[tokenizer.im_start_id, tokenizer.im_end_id],
|
| 283 |
+
tokenizer=tokenizer,
|
| 284 |
+
raw_text_len=raw_text_len,
|
| 285 |
+
context_length=context_length,
|
| 286 |
+
verbose=verbose,
|
| 287 |
+
return_end_reason=return_end_reason,
|
| 288 |
+
errors=errors,
|
| 289 |
+
)
|
| 290 |
+
elif chat_format == "raw":
|
| 291 |
+
return _decode_default(
|
| 292 |
+
tokens,
|
| 293 |
+
stop_words=["<|endoftext|>"],
|
| 294 |
+
eod_words=["<|endoftext|>"],
|
| 295 |
+
tokenizer=tokenizer,
|
| 296 |
+
raw_text_len=raw_text_len,
|
| 297 |
+
verbose=verbose,
|
| 298 |
+
return_end_reason=return_end_reason,
|
| 299 |
+
errors=errors,
|
| 300 |
+
)
|
| 301 |
+
else:
|
| 302 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
class StopWordsLogitsProcessor(LogitsProcessor):
|
| 306 |
+
"""
|
| 307 |
+
:class:`transformers.LogitsProcessor` that enforces that when specified sequences appear, stop geration.
|
| 308 |
+
|
| 309 |
+
Args:
|
| 310 |
+
stop_words_ids (:obj:`List[List[int]]`):
|
| 311 |
+
List of list of token ids of stop ids. In order to get the tokens of the words
|
| 312 |
+
that should not appear in the generated text, use :obj:`tokenizer(bad_word,
|
| 313 |
+
add_prefix_space=True).input_ids`.
|
| 314 |
+
eos_token_id (:obj:`int`):
|
| 315 |
+
The id of the `end-of-sequence` token.
|
| 316 |
+
"""
|
| 317 |
+
|
| 318 |
+
def __init__(self, stop_words_ids: Iterable[Iterable[int]], eos_token_id: int):
|
| 319 |
+
|
| 320 |
+
if not isinstance(stop_words_ids, List) or len(stop_words_ids) == 0:
|
| 321 |
+
raise ValueError(
|
| 322 |
+
f"`stop_words_ids` has to be a non-emtpy list, but is {stop_words_ids}."
|
| 323 |
+
)
|
| 324 |
+
if any(not isinstance(bad_word_ids, list) for bad_word_ids in stop_words_ids):
|
| 325 |
+
raise ValueError(
|
| 326 |
+
f"`stop_words_ids` has to be a list of lists, but is {stop_words_ids}."
|
| 327 |
+
)
|
| 328 |
+
if any(
|
| 329 |
+
any(
|
| 330 |
+
(not isinstance(token_id, (int, np.integer)) or token_id < 0)
|
| 331 |
+
for token_id in stop_word_ids
|
| 332 |
+
)
|
| 333 |
+
for stop_word_ids in stop_words_ids
|
| 334 |
+
):
|
| 335 |
+
raise ValueError(
|
| 336 |
+
f"Each list in `stop_words_ids` has to be a list of positive integers, but is {stop_words_ids}."
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
self.stop_words_ids = list(
|
| 340 |
+
filter(
|
| 341 |
+
lambda bad_token_seq: bad_token_seq != [eos_token_id], stop_words_ids
|
| 342 |
+
)
|
| 343 |
+
)
|
| 344 |
+
self.eos_token_id = eos_token_id
|
| 345 |
+
for stop_token_seq in self.stop_words_ids:
|
| 346 |
+
assert (
|
| 347 |
+
len(stop_token_seq) > 0
|
| 348 |
+
), "Stop words token sequences {} cannot have an empty list".format(
|
| 349 |
+
stop_words_ids
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
def __call__(
|
| 353 |
+
self, input_ids: torch.LongTensor, scores: torch.FloatTensor
|
| 354 |
+
) -> torch.FloatTensor:
|
| 355 |
+
stopped_samples = self._calc_stopped_samples(input_ids)
|
| 356 |
+
for i, should_stop in enumerate(stopped_samples):
|
| 357 |
+
if should_stop:
|
| 358 |
+
scores[i, self.eos_token_id] = float(2**15)
|
| 359 |
+
return scores
|
| 360 |
+
|
| 361 |
+
def _tokens_match(self, prev_tokens: torch.LongTensor, tokens: List[int]) -> bool:
|
| 362 |
+
if len(tokens) == 0:
|
| 363 |
+
# if bad word tokens is just one token always ban it
|
| 364 |
+
return True
|
| 365 |
+
elif len(tokens) > len(prev_tokens):
|
| 366 |
+
# if bad word tokens are longer then prev input_ids they can't be equal
|
| 367 |
+
return False
|
| 368 |
+
elif prev_tokens[-len(tokens) :].tolist() == tokens:
|
| 369 |
+
# if tokens match
|
| 370 |
+
return True
|
| 371 |
+
else:
|
| 372 |
+
return False
|
| 373 |
+
|
| 374 |
+
def _calc_stopped_samples(self, prev_input_ids: Iterable[int]) -> Iterable[int]:
|
| 375 |
+
stopped_samples = []
|
| 376 |
+
for prev_input_ids_slice in prev_input_ids:
|
| 377 |
+
match = False
|
| 378 |
+
for stop_token_seq in self.stop_words_ids:
|
| 379 |
+
if self._tokens_match(prev_input_ids_slice, stop_token_seq):
|
| 380 |
+
# if tokens do not match continue
|
| 381 |
+
match = True
|
| 382 |
+
break
|
| 383 |
+
stopped_samples.append(match)
|
| 384 |
+
|
| 385 |
+
return stopped_samples
|
| 386 |
+
|
| 387 |
+
|
| 388 |
+
def top_k_logits(logits, top_k=0, top_p=0.0, filter_value=-float("Inf")):
|
| 389 |
+
"""This function has been mostly taken from huggingface conversational
|
| 390 |
+
ai code at
|
| 391 |
+
https://medium.com/huggingface/how-to-build-a-state-of-the-art-
|
| 392 |
+
conversational-ai-with-transfer-learning-2d818ac26313"""
|
| 393 |
+
|
| 394 |
+
if top_k > 0:
|
| 395 |
+
# Remove all tokens with a probability less than the
|
| 396 |
+
# last token of the top-k
|
| 397 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 398 |
+
logits[indices_to_remove] = filter_value
|
| 399 |
+
|
| 400 |
+
if top_p > 0.0:
|
| 401 |
+
# Cconvert to 1D
|
| 402 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True, dim=-1)
|
| 403 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 404 |
+
|
| 405 |
+
# Remove tokens with cumulative probability above the threshold
|
| 406 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 407 |
+
# Shift the indices to the right to keep also the first token
|
| 408 |
+
# above the threshold
|
| 409 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 410 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 411 |
+
for i in range(sorted_indices.size(0)):
|
| 412 |
+
indices_to_remove = sorted_indices[i][sorted_indices_to_remove[i]]
|
| 413 |
+
logits[i][indices_to_remove] = filter_value
|
| 414 |
+
|
| 415 |
+
return logits
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def switch(val1, val2, boolean):
|
| 419 |
+
boolean = boolean.type_as(val1)
|
| 420 |
+
return (1 - boolean) * val1 + boolean * val2
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"pad_token": "<|endoftext|>"
|
| 3 |
+
}
|
tokenization_qwen.py
ADDED
|
@@ -0,0 +1,590 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Tokenization classes for QWen."""
|
| 7 |
+
|
| 8 |
+
import base64
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import requests
|
| 12 |
+
import unicodedata
|
| 13 |
+
from typing import Collection, Dict, List, Set, Tuple, Union, Any, Callable, Optional
|
| 14 |
+
|
| 15 |
+
import tiktoken
|
| 16 |
+
import numpy as np
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from PIL import ImageFont
|
| 19 |
+
from PIL import ImageDraw
|
| 20 |
+
from transformers import PreTrainedTokenizer, AddedToken
|
| 21 |
+
from transformers.utils import try_to_load_from_cache
|
| 22 |
+
|
| 23 |
+
import matplotlib.colors as mcolors
|
| 24 |
+
from matplotlib.font_manager import FontProperties
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
VOCAB_FILES_NAMES = {"vocab_file": "qwen.tiktoken", "ttf": "SimSun.ttf"}
|
| 30 |
+
FONT_PATH = try_to_load_from_cache("Qwen/Qwen-VL-Chat", "SimSun.ttf")
|
| 31 |
+
if FONT_PATH is None:
|
| 32 |
+
if not os.path.exists("/mnt/project/LLAVA/Qwen-VL-Chat/SimSun.ttf"):
|
| 33 |
+
ttf = requests.get("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/SimSun.ttf")
|
| 34 |
+
open("SimSun.ttf", "wb").write(ttf.content)
|
| 35 |
+
FONT_PATH = "/mntnlp/common_base_model/Qwen-VL-Chat/SimSun.ttf"
|
| 36 |
+
|
| 37 |
+
PAT_STR = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
|
| 38 |
+
ENDOFTEXT = "<|endoftext|>"
|
| 39 |
+
IMSTART = "<|im_start|>"
|
| 40 |
+
IMEND = "<|im_end|>"
|
| 41 |
+
# as the default behavior is changed to allow special tokens in
|
| 42 |
+
# regular texts, the surface forms of special tokens need to be
|
| 43 |
+
# as different as possible to minimize the impact
|
| 44 |
+
EXTRAS = tuple((f"<|extra_{i}|>" for i in range(205)))
|
| 45 |
+
SPECIAL_TOKENS = (
|
| 46 |
+
ENDOFTEXT,
|
| 47 |
+
IMSTART,
|
| 48 |
+
IMEND,
|
| 49 |
+
) + EXTRAS
|
| 50 |
+
IMG_TOKEN_SPAN = 256
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def _load_tiktoken_bpe(tiktoken_bpe_file: str) -> Dict[bytes, int]:
|
| 54 |
+
with open(tiktoken_bpe_file, "rb") as f:
|
| 55 |
+
contents = f.read()
|
| 56 |
+
return {
|
| 57 |
+
base64.b64decode(token): int(rank)
|
| 58 |
+
for token, rank in (line.split() for line in contents.splitlines() if line)
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
def _list_find(
|
| 62 |
+
input_list: List[Any],
|
| 63 |
+
candidates: Tuple[Any],
|
| 64 |
+
start: int = 0,
|
| 65 |
+
):
|
| 66 |
+
for i in range(start, len(input_list)):
|
| 67 |
+
if input_list[i] in candidates:
|
| 68 |
+
return i
|
| 69 |
+
return -1
|
| 70 |
+
|
| 71 |
+
def _replace_closed_tag(
|
| 72 |
+
input_tokens: List[Any],
|
| 73 |
+
start_tags: Union[Any, Tuple[Any]],
|
| 74 |
+
end_tags: Union[Any, Tuple[Any]],
|
| 75 |
+
inclusive_replace_func: Callable,
|
| 76 |
+
exclusive_replace_func: Callable = lambda x: x,
|
| 77 |
+
):
|
| 78 |
+
if isinstance(start_tags, (str, int)):
|
| 79 |
+
start_tags = (start_tags,)
|
| 80 |
+
if isinstance(end_tags, (str, int)):
|
| 81 |
+
end_tags = (end_tags,)
|
| 82 |
+
assert len(start_tags) == len(end_tags)
|
| 83 |
+
|
| 84 |
+
output_tokens = []
|
| 85 |
+
end = 0
|
| 86 |
+
while True:
|
| 87 |
+
start = _list_find(input_tokens, start_tags, end)
|
| 88 |
+
if start == -1:
|
| 89 |
+
break
|
| 90 |
+
output_tokens.extend(exclusive_replace_func(input_tokens[end : start]))
|
| 91 |
+
tag_idx = start_tags.index(input_tokens[start])
|
| 92 |
+
end = _list_find(input_tokens, (end_tags[tag_idx],), start)
|
| 93 |
+
if end == -1:
|
| 94 |
+
raise ValueError("Unclosed image token")
|
| 95 |
+
output_tokens.extend(inclusive_replace_func(input_tokens[start : end + 1]))
|
| 96 |
+
end += 1
|
| 97 |
+
output_tokens.extend(exclusive_replace_func(input_tokens[end : ]))
|
| 98 |
+
return output_tokens
|
| 99 |
+
|
| 100 |
+
class QWenTokenizer(PreTrainedTokenizer):
|
| 101 |
+
"""QWen tokenizer."""
|
| 102 |
+
|
| 103 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 104 |
+
|
| 105 |
+
def __init__(
|
| 106 |
+
self,
|
| 107 |
+
vocab_file,
|
| 108 |
+
errors="replace",
|
| 109 |
+
image_start_tag='<img>',
|
| 110 |
+
image_end_tag='</img>',
|
| 111 |
+
image_pad_tag='<imgpad>',
|
| 112 |
+
ref_start_tag='<ref>',
|
| 113 |
+
ref_end_tag='</ref>',
|
| 114 |
+
box_start_tag='<box>',
|
| 115 |
+
box_end_tag='</box>',
|
| 116 |
+
quad_start_tag='<quad>',
|
| 117 |
+
quad_end_tag='</quad>',
|
| 118 |
+
**kwargs,
|
| 119 |
+
):
|
| 120 |
+
super().__init__(**kwargs)
|
| 121 |
+
self.image_start_tag = image_start_tag
|
| 122 |
+
self.image_end_tag = image_end_tag
|
| 123 |
+
self.image_pad_tag = image_pad_tag
|
| 124 |
+
self.ref_start_tag = ref_start_tag
|
| 125 |
+
self.ref_end_tag = ref_end_tag
|
| 126 |
+
self.box_start_tag = box_start_tag
|
| 127 |
+
self.box_end_tag = box_end_tag
|
| 128 |
+
self.quad_start_tag = quad_start_tag
|
| 129 |
+
self.quad_end_tag = quad_end_tag
|
| 130 |
+
self.IMAGE_ST = (
|
| 131 |
+
ref_start_tag, ref_end_tag,
|
| 132 |
+
box_start_tag, box_end_tag,
|
| 133 |
+
quad_start_tag, quad_end_tag,
|
| 134 |
+
image_start_tag, image_end_tag,
|
| 135 |
+
image_pad_tag
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
self.errors = errors # how to handle errors in decoding
|
| 139 |
+
|
| 140 |
+
self.mergeable_ranks = _load_tiktoken_bpe(vocab_file) # type: dict[bytes, int]
|
| 141 |
+
self.special_tokens = {
|
| 142 |
+
token: index
|
| 143 |
+
for index, token in enumerate(
|
| 144 |
+
SPECIAL_TOKENS + self.IMAGE_ST, start=len(self.mergeable_ranks)
|
| 145 |
+
)
|
| 146 |
+
}
|
| 147 |
+
self.img_start_id = self.special_tokens[self.image_start_tag]
|
| 148 |
+
self.img_end_id = self.special_tokens[self.image_end_tag]
|
| 149 |
+
self.img_pad_id = self.special_tokens[self.image_pad_tag]
|
| 150 |
+
self.ref_start_id = self.special_tokens[self.ref_start_tag]
|
| 151 |
+
self.ref_end_id = self.special_tokens[self.ref_end_tag]
|
| 152 |
+
self.box_start_id = self.special_tokens[self.box_start_tag]
|
| 153 |
+
self.box_end_id = self.special_tokens[self.box_end_tag]
|
| 154 |
+
self.quad_start_id = self.special_tokens[self.quad_start_tag]
|
| 155 |
+
self.quad_end_id = self.special_tokens[self.quad_end_tag]
|
| 156 |
+
|
| 157 |
+
enc = tiktoken.Encoding(
|
| 158 |
+
"Qwen",
|
| 159 |
+
pat_str=PAT_STR,
|
| 160 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 161 |
+
special_tokens=self.special_tokens,
|
| 162 |
+
)
|
| 163 |
+
assert (
|
| 164 |
+
len(self.mergeable_ranks) + len(self.special_tokens) == enc.n_vocab
|
| 165 |
+
), f"{len(self.mergeable_ranks) + len(self.special_tokens)} != {enc.n_vocab} in encoding"
|
| 166 |
+
|
| 167 |
+
self.decoder = {
|
| 168 |
+
v: k for k, v in self.mergeable_ranks.items()
|
| 169 |
+
} # type: dict[int, bytes|str]
|
| 170 |
+
self.decoder.update({v: k for k, v in self.special_tokens.items()})
|
| 171 |
+
|
| 172 |
+
self.tokenizer = enc # type: tiktoken.Encoding
|
| 173 |
+
|
| 174 |
+
self.eod_id = self.tokenizer.eot_token
|
| 175 |
+
self.im_start_id = self.special_tokens[IMSTART]
|
| 176 |
+
self.im_end_id = self.special_tokens[IMEND]
|
| 177 |
+
|
| 178 |
+
def __getstate__(self):
|
| 179 |
+
# for pickle lovers
|
| 180 |
+
state = self.__dict__.copy()
|
| 181 |
+
del state['tokenizer']
|
| 182 |
+
return state
|
| 183 |
+
|
| 184 |
+
def __setstate__(self, state):
|
| 185 |
+
# tokenizer is not python native; don't pass it; rebuild it
|
| 186 |
+
self.__dict__.update(state)
|
| 187 |
+
enc = tiktoken.Encoding(
|
| 188 |
+
"Qwen",
|
| 189 |
+
pat_str=PAT_STR,
|
| 190 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 191 |
+
special_tokens=self.special_tokens,
|
| 192 |
+
)
|
| 193 |
+
self.tokenizer = enc
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def __len__(self) -> int:
|
| 197 |
+
return self.tokenizer.n_vocab
|
| 198 |
+
|
| 199 |
+
def get_vocab(self) -> Dict[bytes, int]:
|
| 200 |
+
return self.mergeable_ranks
|
| 201 |
+
|
| 202 |
+
def convert_tokens_to_ids(
|
| 203 |
+
self, tokens: Union[bytes, str, List[Union[bytes, str]]]
|
| 204 |
+
) -> List[int]:
|
| 205 |
+
ids = []
|
| 206 |
+
if isinstance(tokens, (str, bytes)):
|
| 207 |
+
if tokens in self.special_tokens:
|
| 208 |
+
return self.special_tokens[tokens]
|
| 209 |
+
else:
|
| 210 |
+
return self.mergeable_ranks.get(tokens)
|
| 211 |
+
for token in tokens:
|
| 212 |
+
if token in self.special_tokens:
|
| 213 |
+
ids.append(self.special_tokens[token])
|
| 214 |
+
else:
|
| 215 |
+
ids.append(self.mergeable_ranks.get(token))
|
| 216 |
+
return ids
|
| 217 |
+
|
| 218 |
+
def _add_tokens(self, new_tokens: Union[List[str], List[AddedToken]], special_tokens: bool = False) -> int:
|
| 219 |
+
if not special_tokens and new_tokens:
|
| 220 |
+
raise ValueError('Adding regular tokens is not supported')
|
| 221 |
+
for token in new_tokens:
|
| 222 |
+
surface_form = token.content if isinstance(token, AddedToken) else token
|
| 223 |
+
if surface_form not in SPECIAL_TOKENS + self.IMAGE_ST:
|
| 224 |
+
raise ValueError('Adding unknown special tokens is not supported')
|
| 225 |
+
return 0
|
| 226 |
+
|
| 227 |
+
def save_vocabulary(self, save_directory: str, **kwargs) -> Tuple[str]:
|
| 228 |
+
"""
|
| 229 |
+
Save only the vocabulary of the tokenizer (vocabulary).
|
| 230 |
+
|
| 231 |
+
Returns:
|
| 232 |
+
`Tuple(str)`: Paths to the files saved.
|
| 233 |
+
"""
|
| 234 |
+
file_path = os.path.join(save_directory, "qwen.tiktoken")
|
| 235 |
+
with open(file_path, "w", encoding="utf8") as w:
|
| 236 |
+
for k, v in self.mergeable_ranks.items():
|
| 237 |
+
line = base64.b64encode(k).decode("utf8") + " " + str(v) + "\n"
|
| 238 |
+
w.write(line)
|
| 239 |
+
return (file_path,)
|
| 240 |
+
|
| 241 |
+
def tokenize(
|
| 242 |
+
self,
|
| 243 |
+
text: str,
|
| 244 |
+
allowed_special: Union[Set, str] = "all",
|
| 245 |
+
disallowed_special: Union[Collection, str] = (),
|
| 246 |
+
**kwargs,
|
| 247 |
+
) -> List[Union[bytes, str]]:
|
| 248 |
+
"""
|
| 249 |
+
Converts a string in a sequence of tokens.
|
| 250 |
+
|
| 251 |
+
Args:
|
| 252 |
+
text (`str`):
|
| 253 |
+
The sequence to be encoded.
|
| 254 |
+
allowed_special (`Literal["all"]` or `set`):
|
| 255 |
+
The surface forms of the tokens to be encoded as special tokens in regular texts.
|
| 256 |
+
Default to "all".
|
| 257 |
+
disallowed_special (`Literal["all"]` or `Collection`):
|
| 258 |
+
The surface forms of the tokens that should not be in regular texts and trigger errors.
|
| 259 |
+
Default to an empty tuple.
|
| 260 |
+
|
| 261 |
+
kwargs (additional keyword arguments, *optional*):
|
| 262 |
+
Will be passed to the underlying model specific encode method.
|
| 263 |
+
|
| 264 |
+
Returns:
|
| 265 |
+
`List[bytes|str]`: The list of tokens.
|
| 266 |
+
"""
|
| 267 |
+
tokens = []
|
| 268 |
+
text = unicodedata.normalize("NFC", text)
|
| 269 |
+
|
| 270 |
+
# this implementation takes a detour: text -> token id -> token surface forms
|
| 271 |
+
for t in self.tokenizer.encode(
|
| 272 |
+
text, allowed_special=allowed_special, disallowed_special=disallowed_special
|
| 273 |
+
):
|
| 274 |
+
tokens.append(self.decoder[t])
|
| 275 |
+
|
| 276 |
+
def _encode_imgurl(img_tokens):
|
| 277 |
+
assert img_tokens[0] == self.image_start_tag and img_tokens[-1] == self.image_end_tag
|
| 278 |
+
img_tokens = img_tokens[1:-1]
|
| 279 |
+
img_url = b''.join(img_tokens)
|
| 280 |
+
out_img_tokens = list(map(self.decoder.get, img_url))
|
| 281 |
+
if len(out_img_tokens) > IMG_TOKEN_SPAN:
|
| 282 |
+
raise ValueError("The content in {}..{} is too long".format(
|
| 283 |
+
self.image_start_tag, self.image_end_tag))
|
| 284 |
+
out_img_tokens.extend([self.image_pad_tag] * (IMG_TOKEN_SPAN - len(out_img_tokens)))
|
| 285 |
+
out_img_tokens = [self.image_start_tag] + out_img_tokens + [self.image_end_tag]
|
| 286 |
+
return out_img_tokens
|
| 287 |
+
|
| 288 |
+
return _replace_closed_tag(tokens, self.image_start_tag, self.image_end_tag, _encode_imgurl)
|
| 289 |
+
|
| 290 |
+
def convert_tokens_to_string(self, tokens: List[Union[bytes, str]]) -> str:
|
| 291 |
+
"""
|
| 292 |
+
Converts a sequence of tokens in a single string.
|
| 293 |
+
"""
|
| 294 |
+
text = ""
|
| 295 |
+
temp = b""
|
| 296 |
+
for t in tokens:
|
| 297 |
+
if isinstance(t, str):
|
| 298 |
+
if temp:
|
| 299 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 300 |
+
temp = b""
|
| 301 |
+
text += t
|
| 302 |
+
elif isinstance(t, bytes):
|
| 303 |
+
temp += t
|
| 304 |
+
else:
|
| 305 |
+
raise TypeError("token should only be of type types or str")
|
| 306 |
+
if temp:
|
| 307 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 308 |
+
return text
|
| 309 |
+
|
| 310 |
+
@property
|
| 311 |
+
def vocab_size(self):
|
| 312 |
+
return self.tokenizer.n_vocab
|
| 313 |
+
|
| 314 |
+
def _convert_id_to_token(self, index: int) -> Union[bytes, str]:
|
| 315 |
+
"""Converts an id to a token, special tokens included"""
|
| 316 |
+
if index in self.decoder:
|
| 317 |
+
return self.decoder[index]
|
| 318 |
+
raise ValueError("unknown ids")
|
| 319 |
+
|
| 320 |
+
def _convert_token_to_id(self, token: Union[bytes, str]) -> int:
|
| 321 |
+
"""Converts a token to an id using the vocab, special tokens included"""
|
| 322 |
+
if token in self.special_tokens:
|
| 323 |
+
return self.special_tokens[token]
|
| 324 |
+
if token in self.mergeable_ranks:
|
| 325 |
+
return self.mergeable_ranks[token]
|
| 326 |
+
raise ValueError("unknown token")
|
| 327 |
+
|
| 328 |
+
def _tokenize(self, text: str, **kwargs):
|
| 329 |
+
"""
|
| 330 |
+
Converts a string in a sequence of tokens (string), using the tokenizer. Split in words for word-based
|
| 331 |
+
vocabulary or sub-words for sub-word-based vocabularies (BPE/SentencePieces/WordPieces).
|
| 332 |
+
|
| 333 |
+
Do NOT take care of added tokens.
|
| 334 |
+
"""
|
| 335 |
+
raise NotImplementedError
|
| 336 |
+
|
| 337 |
+
def _decode(
|
| 338 |
+
self,
|
| 339 |
+
token_ids: Union[int, List[int]],
|
| 340 |
+
skip_special_tokens: bool = False,
|
| 341 |
+
errors: str = None,
|
| 342 |
+
**kwargs,
|
| 343 |
+
) -> str:
|
| 344 |
+
if isinstance(token_ids, int):
|
| 345 |
+
token_ids = [token_ids]
|
| 346 |
+
|
| 347 |
+
def _decode_imgurl(img_token_ids):
|
| 348 |
+
assert img_token_ids[0] == self.img_start_id and img_token_ids[-1] == self.img_end_id
|
| 349 |
+
img_token_ids = img_token_ids[1:-1]
|
| 350 |
+
img_token_ids = img_token_ids[ : img_token_ids.index(self.img_pad_id)]
|
| 351 |
+
img_url = bytes(img_token_ids).decode('utf-8')
|
| 352 |
+
return [self.img_start_id] + self.tokenizer.encode(img_url) + [self.img_end_id]
|
| 353 |
+
|
| 354 |
+
token_ids = _replace_closed_tag(token_ids, self.img_start_id, self.img_end_id, _decode_imgurl)
|
| 355 |
+
|
| 356 |
+
if skip_special_tokens:
|
| 357 |
+
token_ids = [i for i in token_ids if i < self.eod_id]
|
| 358 |
+
return self.tokenizer.decode(token_ids, errors=errors or self.errors)
|
| 359 |
+
|
| 360 |
+
def to_list_format(self, text: str):
|
| 361 |
+
text = unicodedata.normalize("NFC", text)
|
| 362 |
+
token_ids = self.tokenizer.encode(
|
| 363 |
+
text, allowed_special=set(self.IMAGE_ST + (ENDOFTEXT,)))
|
| 364 |
+
|
| 365 |
+
def _encode_vl_info(tokens):
|
| 366 |
+
if len(tokens) == 0:
|
| 367 |
+
return []
|
| 368 |
+
if tokens[0] == self.img_start_id and tokens[-1] == self.img_end_id:
|
| 369 |
+
key = 'image'
|
| 370 |
+
elif tokens[0] == self.ref_start_id and tokens[-1] == self.ref_end_id:
|
| 371 |
+
key = 'ref'
|
| 372 |
+
elif tokens[0] == self.box_start_id and tokens[-1] == self.box_end_id:
|
| 373 |
+
key = 'box'
|
| 374 |
+
elif tokens[0] == self.quad_start_id and tokens[-1] == self.quad_end_id:
|
| 375 |
+
key = 'quad'
|
| 376 |
+
else:
|
| 377 |
+
_tobytes = lambda x: x.encode('utf-8') if isinstance(x, str) else x
|
| 378 |
+
return [{'text': b''.join(map(_tobytes, map(self.decoder.get, tokens))).decode('utf-8')}]
|
| 379 |
+
_tobytes = lambda x: x.encode('utf-8') if isinstance(x, str) else x
|
| 380 |
+
val = b''.join(map(_tobytes, map(self.decoder.get, tokens[1:-1]))).decode('utf-8')
|
| 381 |
+
return [{key: val}]
|
| 382 |
+
|
| 383 |
+
return _replace_closed_tag(
|
| 384 |
+
token_ids,
|
| 385 |
+
(self.img_start_id, self.ref_start_id, self.box_start_id, self.quad_start_id),
|
| 386 |
+
(self.img_end_id, self.ref_end_id, self.box_end_id, self.quad_end_id),
|
| 387 |
+
_encode_vl_info,
|
| 388 |
+
_encode_vl_info,
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
def from_list_format(self, list_format: List[Dict]):
|
| 392 |
+
text = ''
|
| 393 |
+
num_images = 0
|
| 394 |
+
for ele in list_format:
|
| 395 |
+
if 'image' in ele:
|
| 396 |
+
num_images += 1
|
| 397 |
+
text += f'Picture {num_images}:'
|
| 398 |
+
text += self.image_start_tag + ele['image'] + self.image_end_tag
|
| 399 |
+
text += '\n'
|
| 400 |
+
elif 'text' in ele:
|
| 401 |
+
text += ele['text']
|
| 402 |
+
elif 'box' in ele:
|
| 403 |
+
if 'ref' in ele:
|
| 404 |
+
text += self.ref_start_tag + ele['ref'] + self.ref_end_tag
|
| 405 |
+
for box in ele['box']:
|
| 406 |
+
text += self.box_start_tag + '(%d,%d),(%d,%d)' % (box[0], box[1], box[2], box[3]) + self.box_end_tag
|
| 407 |
+
else:
|
| 408 |
+
raise ValueError("Unsupport element: " + str(ele))
|
| 409 |
+
return text
|
| 410 |
+
|
| 411 |
+
def _fetch_latest_picture(self, response, history):
|
| 412 |
+
if history is None:
|
| 413 |
+
history = []
|
| 414 |
+
_history = history + [(response, None)]
|
| 415 |
+
for q, r in _history[::-1]:
|
| 416 |
+
for ele in self.to_list_format(q)[::-1]:
|
| 417 |
+
if 'image' in ele:
|
| 418 |
+
return ele['image']
|
| 419 |
+
return None
|
| 420 |
+
|
| 421 |
+
def _fetch_all_box_with_ref(self, text):
|
| 422 |
+
list_format = self.to_list_format(text)
|
| 423 |
+
output = []
|
| 424 |
+
for i, ele in enumerate(list_format):
|
| 425 |
+
if 'box' in ele:
|
| 426 |
+
bbox = tuple(map(int, ele['box'].replace('(', '').replace(')', '').split(',')))
|
| 427 |
+
assert len(bbox) == 4
|
| 428 |
+
output.append({'box': bbox})
|
| 429 |
+
if i > 0 and 'ref' in list_format[i-1]:
|
| 430 |
+
output[-1]['ref'] = list_format[i-1]['ref'].strip()
|
| 431 |
+
return output
|
| 432 |
+
|
| 433 |
+
def draw_bbox_on_latest_picture(
|
| 434 |
+
self,
|
| 435 |
+
response,
|
| 436 |
+
history=None,
|
| 437 |
+
) -> Optional[Image.Image]:
|
| 438 |
+
image = self._fetch_latest_picture(response, history)
|
| 439 |
+
if image is None:
|
| 440 |
+
return None
|
| 441 |
+
if image.startswith("http://") or image.startswith("https://"):
|
| 442 |
+
image = Image.open(requests.get(image, stream=True).raw).convert("RGB")
|
| 443 |
+
h, w = image.height, image.width
|
| 444 |
+
else:
|
| 445 |
+
image = np.asarray(Image.open(image).convert("RGB"))
|
| 446 |
+
h, w = image.shape[0], image.shape[1]
|
| 447 |
+
visualizer = Visualizer(image)
|
| 448 |
+
|
| 449 |
+
boxes = self._fetch_all_box_with_ref(response)
|
| 450 |
+
if not boxes:
|
| 451 |
+
return None
|
| 452 |
+
color = random.choice([_ for _ in mcolors.TABLEAU_COLORS.keys()]) # init color
|
| 453 |
+
for box in boxes:
|
| 454 |
+
if 'ref' in box: # random new color for new refexps
|
| 455 |
+
color = random.choice([_ for _ in mcolors.TABLEAU_COLORS.keys()])
|
| 456 |
+
x1, y1, x2, y2 = box['box']
|
| 457 |
+
x1, y1, x2, y2 = (int(x1 / 1000 * w), int(y1 / 1000 * h), int(x2 / 1000 * w), int(y2 / 1000 * h))
|
| 458 |
+
visualizer.draw_box((x1, y1, x2, y2), alpha=1, edge_color=color)
|
| 459 |
+
if 'ref' in box:
|
| 460 |
+
visualizer.draw_text(box['ref'], (x1, y1), color=color, horizontal_alignment="left")
|
| 461 |
+
return visualizer.output
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
import colorsys
|
| 465 |
+
import logging
|
| 466 |
+
import math
|
| 467 |
+
import numpy as np
|
| 468 |
+
import matplotlib as mpl
|
| 469 |
+
import matplotlib.colors as mplc
|
| 470 |
+
import matplotlib.figure as mplfigure
|
| 471 |
+
import torch
|
| 472 |
+
from matplotlib.backends.backend_agg import FigureCanvasAgg
|
| 473 |
+
from PIL import Image
|
| 474 |
+
import random
|
| 475 |
+
|
| 476 |
+
logger = logging.getLogger(__name__)
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
class VisImage:
|
| 480 |
+
def __init__(self, img, scale=1.0):
|
| 481 |
+
self.img = img
|
| 482 |
+
self.scale = scale
|
| 483 |
+
self.width, self.height = img.shape[1], img.shape[0]
|
| 484 |
+
self._setup_figure(img)
|
| 485 |
+
|
| 486 |
+
def _setup_figure(self, img):
|
| 487 |
+
fig = mplfigure.Figure(frameon=False)
|
| 488 |
+
self.dpi = fig.get_dpi()
|
| 489 |
+
# add a small 1e-2 to avoid precision lost due to matplotlib's truncation
|
| 490 |
+
# (https://github.com/matplotlib/matplotlib/issues/15363)
|
| 491 |
+
fig.set_size_inches(
|
| 492 |
+
(self.width * self.scale + 1e-2) / self.dpi,
|
| 493 |
+
(self.height * self.scale + 1e-2) / self.dpi,
|
| 494 |
+
)
|
| 495 |
+
self.canvas = FigureCanvasAgg(fig)
|
| 496 |
+
# self.canvas = mpl.backends.backend_cairo.FigureCanvasCairo(fig)
|
| 497 |
+
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
|
| 498 |
+
ax.axis("off")
|
| 499 |
+
self.fig = fig
|
| 500 |
+
self.ax = ax
|
| 501 |
+
self.reset_image(img)
|
| 502 |
+
|
| 503 |
+
def reset_image(self, img):
|
| 504 |
+
img = img.astype("uint8")
|
| 505 |
+
self.ax.imshow(img, extent=(0, self.width, self.height, 0), interpolation="nearest")
|
| 506 |
+
|
| 507 |
+
def save(self, filepath):
|
| 508 |
+
self.fig.savefig(filepath)
|
| 509 |
+
|
| 510 |
+
def get_image(self):
|
| 511 |
+
canvas = self.canvas
|
| 512 |
+
s, (width, height) = canvas.print_to_buffer()
|
| 513 |
+
|
| 514 |
+
buffer = np.frombuffer(s, dtype="uint8")
|
| 515 |
+
|
| 516 |
+
img_rgba = buffer.reshape(height, width, 4)
|
| 517 |
+
rgb, alpha = np.split(img_rgba, [3], axis=2)
|
| 518 |
+
return rgb.astype("uint8")
|
| 519 |
+
|
| 520 |
+
|
| 521 |
+
class Visualizer:
|
| 522 |
+
def __init__(self, img_rgb, metadata=None, scale=1.0):
|
| 523 |
+
self.img = np.asarray(img_rgb).clip(0, 255).astype(np.uint8)
|
| 524 |
+
self.font_path = FONT_PATH
|
| 525 |
+
self.output = VisImage(self.img, scale=scale)
|
| 526 |
+
self.cpu_device = torch.device("cpu")
|
| 527 |
+
|
| 528 |
+
# too small texts are useless, therefore clamp to 14
|
| 529 |
+
self._default_font_size = max(
|
| 530 |
+
np.sqrt(self.output.height * self.output.width) // 30, 15 // scale
|
| 531 |
+
)
|
| 532 |
+
|
| 533 |
+
def draw_text(
|
| 534 |
+
self,
|
| 535 |
+
text,
|
| 536 |
+
position,
|
| 537 |
+
*,
|
| 538 |
+
font_size=None,
|
| 539 |
+
color="g",
|
| 540 |
+
horizontal_alignment="center",
|
| 541 |
+
rotation=0,
|
| 542 |
+
):
|
| 543 |
+
if not font_size:
|
| 544 |
+
font_size = self._default_font_size
|
| 545 |
+
|
| 546 |
+
# since the text background is dark, we don't want the text to be dark
|
| 547 |
+
color = np.maximum(list(mplc.to_rgb(color)), 0.2)
|
| 548 |
+
color[np.argmax(color)] = max(0.8, np.max(color))
|
| 549 |
+
|
| 550 |
+
x, y = position
|
| 551 |
+
self.output.ax.text(
|
| 552 |
+
x,
|
| 553 |
+
y,
|
| 554 |
+
text,
|
| 555 |
+
size=font_size * self.output.scale,
|
| 556 |
+
fontproperties=FontProperties(fname=self.font_path),
|
| 557 |
+
bbox={"facecolor": "black", "alpha": 0.8, "pad": 0.7, "edgecolor": "none"},
|
| 558 |
+
verticalalignment="top",
|
| 559 |
+
horizontalalignment=horizontal_alignment,
|
| 560 |
+
color=color,
|
| 561 |
+
zorder=10,
|
| 562 |
+
rotation=rotation,
|
| 563 |
+
)
|
| 564 |
+
return self.output
|
| 565 |
+
|
| 566 |
+
def draw_box(self, box_coord, alpha=0.5, edge_color="g", line_style="-"):
|
| 567 |
+
|
| 568 |
+
x0, y0, x1, y1 = box_coord
|
| 569 |
+
width = x1 - x0
|
| 570 |
+
height = y1 - y0
|
| 571 |
+
|
| 572 |
+
linewidth = max(self._default_font_size / 4, 1)
|
| 573 |
+
|
| 574 |
+
self.output.ax.add_patch(
|
| 575 |
+
mpl.patches.Rectangle(
|
| 576 |
+
(x0, y0),
|
| 577 |
+
width,
|
| 578 |
+
height,
|
| 579 |
+
fill=False,
|
| 580 |
+
edgecolor=edge_color,
|
| 581 |
+
linewidth=linewidth * self.output.scale,
|
| 582 |
+
alpha=alpha,
|
| 583 |
+
linestyle=line_style,
|
| 584 |
+
)
|
| 585 |
+
)
|
| 586 |
+
return self.output
|
| 587 |
+
|
| 588 |
+
def get_output(self):
|
| 589 |
+
|
| 590 |
+
return self.output
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoTokenizer": [
|
| 4 |
+
"tokenization_qwen.QWenTokenizer",
|
| 5 |
+
null
|
| 6 |
+
]
|
| 7 |
+
},
|
| 8 |
+
"clean_up_tokenization_spaces": true,
|
| 9 |
+
"model_max_length": 8192,
|
| 10 |
+
"tokenizer_class": "QWenTokenizer"
|
| 11 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fa84e2a5d34ac028d86a0144ccdd0a4cf75014f2d0f07a532bb9ec675172d117
|
| 3 |
+
size 4091
|