

Update README.md
Browse files
README.md
CHANGED
|
@@ -65,7 +65,7 @@ Question : [Question]
|
|
| 65 |
Réponse :
|
| 66 |
```
|
| 67 |
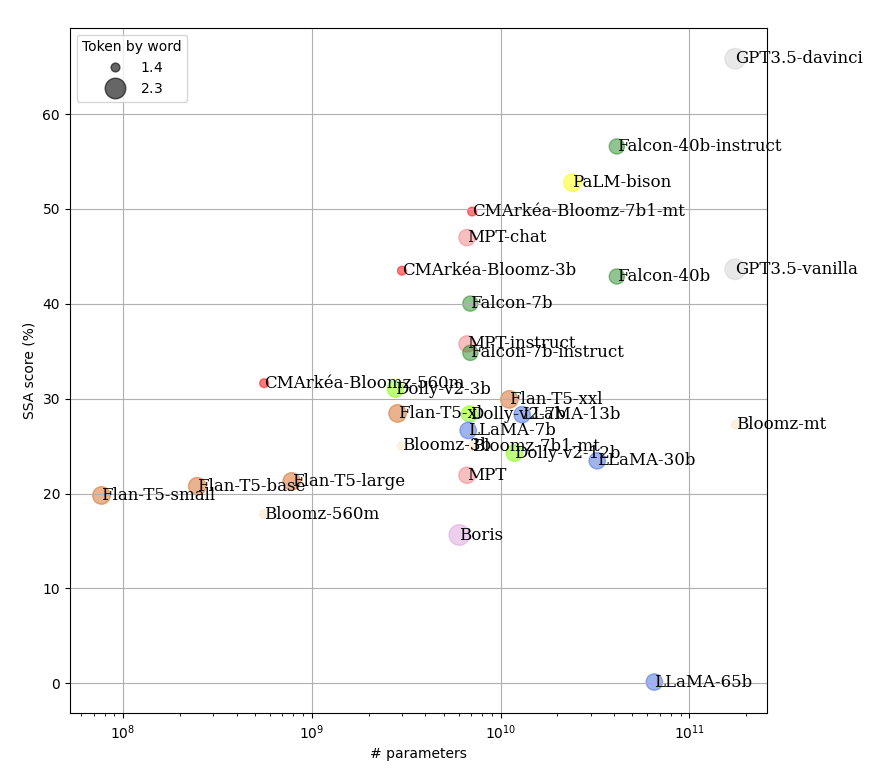
As a result, the prompts do not exploit the structures of chatbot models to ensure fairness, and the evaluation quantifies performance in a purely instruction-based approach. The figure below illustrates the results. The higher a model is positioned in the top-left corner with a small circle radius, the better the model; conversely, if a model is towards the bottom-right with a large circle, it performs less favorably.
|
| 68 |
-
|
| 69 |
We observe that across all models, the performance gain is logarithmic in relation to the increase in model parameters. However, for models that undergo multiple pre-trainings (vanilla, instruction, and chat), models pre-trained on instruction and chat perform significantly better in zero-shot contexts, with a notable improvement for chat-based approaches. The models we have trained demonstrate promising efficiency in this test compared to the number of parameters, indicating cost-effectiveness in a production context.
|
| 70 |
|
| 71 |
How to use bloomz-7b1-mt-sft-chat
|
|
|
|
| 65 |
Réponse :
|
| 66 |
```
|
| 67 |
As a result, the prompts do not exploit the structures of chatbot models to ensure fairness, and the evaluation quantifies performance in a purely instruction-based approach. The figure below illustrates the results. The higher a model is positioned in the top-left corner with a small circle radius, the better the model; conversely, if a model is towards the bottom-right with a large circle, it performs less favorably.
|
| 68 |
+
|
| 69 |
We observe that across all models, the performance gain is logarithmic in relation to the increase in model parameters. However, for models that undergo multiple pre-trainings (vanilla, instruction, and chat), models pre-trained on instruction and chat perform significantly better in zero-shot contexts, with a notable improvement for chat-based approaches. The models we have trained demonstrate promising efficiency in this test compared to the number of parameters, indicating cost-effectiveness in a production context.
|
| 70 |
|
| 71 |
How to use bloomz-7b1-mt-sft-chat
|