
license: mit
datasets:
- ccmusic-database/chest_falsetto
language:
- en
metrics:
- accuracy
pipeline_tag: image-classification
tags:
- music
- art
The design of the chest-falsetto voice discrimination model aims to effectively differentiate between real and synthetic voices in audio samples, with four specific categories including male chest, male falsetto, female chest, and female falsetto voices. The model's training is based on a backbone network from the computer vision (CV) domain, which involves transforming audio data into spectrograms and fine-tuning to enhance the network's accuracy in recognizing different voice categories. During training, a dataset containing both real and synthetic voice samples is utilized to ensure the model adequately learns and captures features relevant to male and female chest and falsetto voices. Through this approach, the model can finely classify different genders and chest/falsetto voices, providing a reliable solution for accurate voice discrimination in audio. This model holds broad potential applications in fields such as speech processing and music production, offering an efficient and precise tool for audio analysis and processing. Its training and fine-tuning strategies based on computer vision principles highlight the model's adaptability and robustness across different domains, providing beneficial examples for further research and application.
Maintenance
GIT_LFS_SKIP_SMUDGE=1 git clone git@hf.co:ccmusic-database/chest_falsetto
cd chest_falsetto
Results
A demo result of SqueezeNet fine-tuning:
| Loss curve | 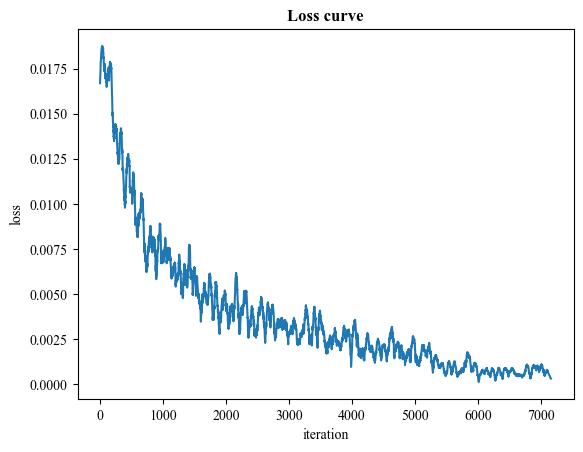 |
|---|---|
| Training and validation accuracy | 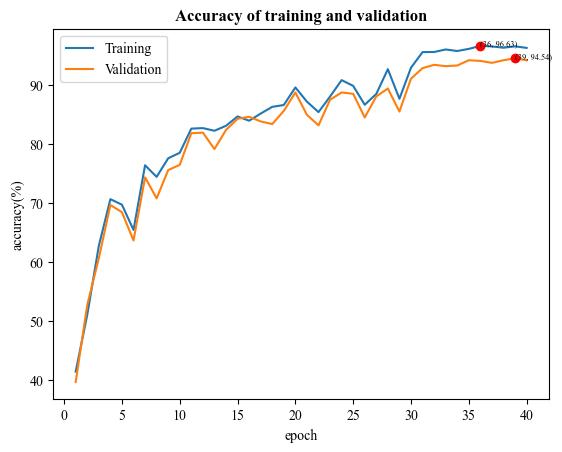 |
| Confusion matrix | 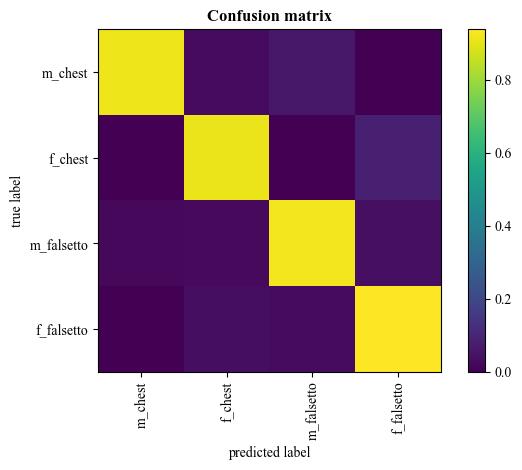 |
Mirror
https://www.modelscope.cn/models/ccmusic/chest_falsetto