
Commit
·
d7dc199
1
Parent(s):
aee6ba4
update doc
Browse files
README.md
CHANGED
|
@@ -92,9 +92,9 @@ model-index:
|
|
| 92 |
|
| 93 |
# Whisper-Large-V3-French-Distil-Dec16
|
| 94 |
|
| 95 |
-
Whisper-Large-V3-French-Distil represents a series of distilled versions of [Whisper-Large-V3-French](https://huggingface.co/bofenghuang/whisper-large-v3-french), achieved by reducing the number of decoder layers from 32 to 16
|
| 96 |
|
| 97 |
-
The distilled variants reduce memory usage and inference time
|
| 98 |
|
| 99 |
This model has been converted into various formats, facilitating its usage across different libraries, including transformers, openai-whisper, fasterwhisper, whisper.cpp, candle, mlx, etc.
|
| 100 |
|
|
@@ -123,13 +123,13 @@ All evaluation results on the public datasets can be found [here](https://drive.
|
|
| 123 |
|
| 124 |
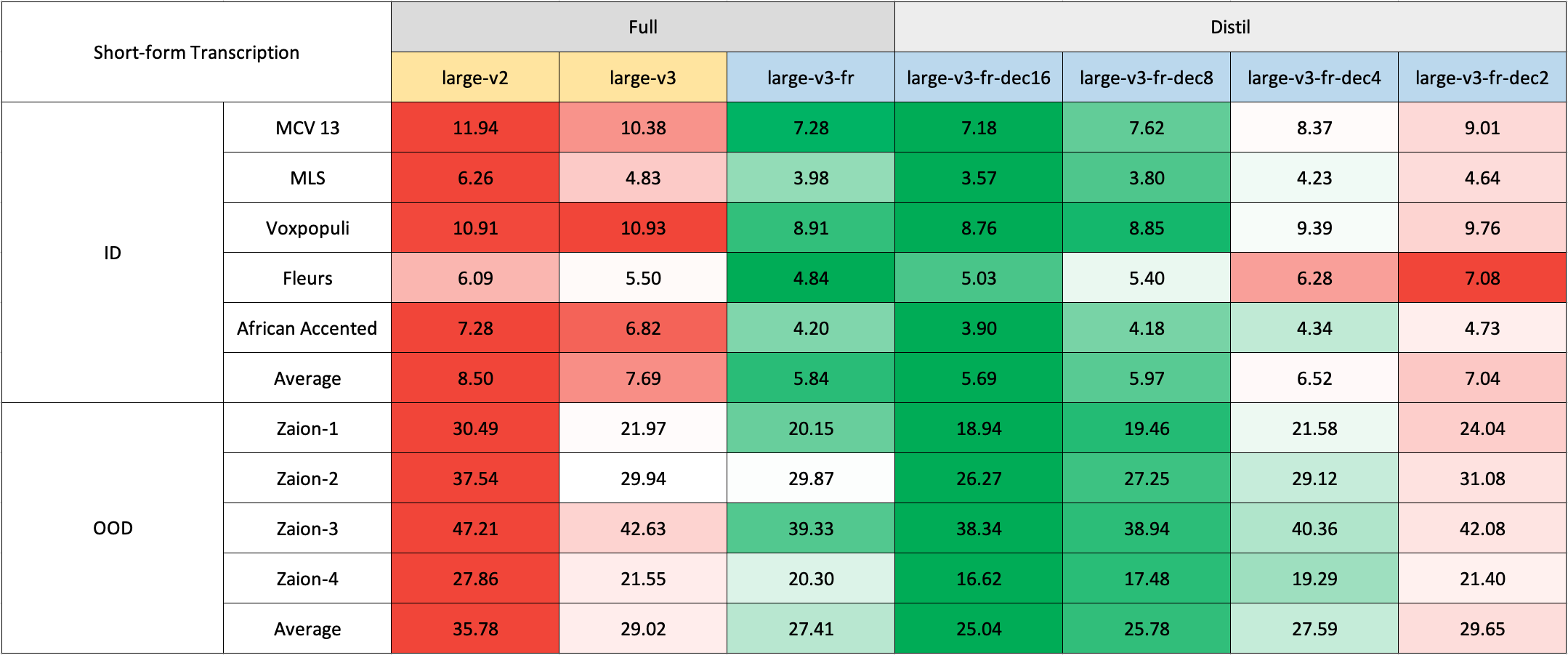
### Short-Form Transcription
|
| 125 |
|
| 126 |
-
 and long-form test sets in French, we evaluated using internal test sets from [Zaion Lab](https://zaion.ai/). These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology.
|
| 129 |
|
| 130 |
### Long-Form Transcription
|
| 131 |
|
| 132 |
-
, achieved by reducing the number of decoder layers from 32 to 16, 8, 4, or 2 and distilling using a large-scale dataset, as outlined in this [paper](https://arxiv.org/abs/2311.00430).
|
| 96 |
|
| 97 |
+
The distilled variants reduce memory usage and inference time while maintaining performance (based on the retained number of layers) and mitigating the risk of hallucinations, particularly in long-form transcriptions. Moreover, they can be seamlessly combined with the original Whisper-Large-V3-French model for speculative decoding, resulting in improved inference speed and consistent outputs compared to using the standalone model.
|
| 98 |
|
| 99 |
This model has been converted into various formats, facilitating its usage across different libraries, including transformers, openai-whisper, fasterwhisper, whisper.cpp, candle, mlx, etc.
|
| 100 |
|
|
|
|
| 123 |
|
| 124 |
### Short-Form Transcription
|
| 125 |
|
| 126 |
+
|
| 127 |
|
| 128 |
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we evaluated using internal test sets from [Zaion Lab](https://zaion.ai/). These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology.
|
| 129 |
|
| 130 |
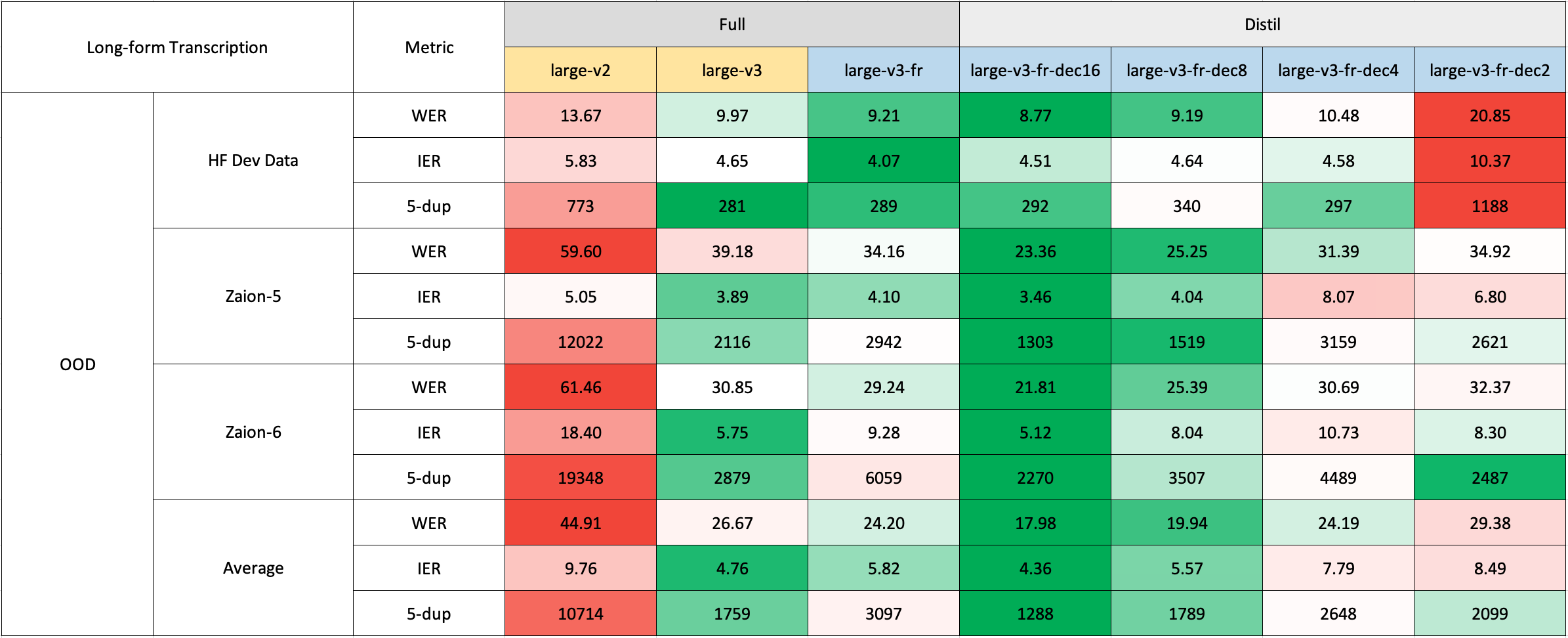
### Long-Form Transcription
|
| 131 |
|
| 132 |
+
|
| 133 |
|
| 134 |
The long-form transcription was run using the 🤗 Hugging Face pipeline for quicker evaluation. Audio files were segmented into 30-second chunks and processed in parallel.
|
| 135 |
|
assets/whisper_fr_eval_long_form.png
DELETED
|
Binary file (234 kB)
|
|
|
assets/whisper_fr_eval_short_form.png
DELETED
|
Binary file (218 kB)
|
|
|