
language: ko
license: apache-2.0
tags:
- korean
KcBERT: Korean comments BERT
** Updates on 2021.04.07 **
- KcELECTRA가 릴리즈 되었습니다!🤗
- KcELECTRA는 보다 더 많은 데이터셋, 그리고 더 큰 General vocab을 통해 KcBERT 대비 모든 태스크에서 더 높은 성능을 보입니다.
- 아래 깃헙 링크에서 직접 사용해보세요!
- https://github.com/Beomi/KcELECTRA
** Updates on 2021.03.14 **
- KcBERT Paper 인용 표기를 추가하였습니다.(bibtex)
- KcBERT-finetune Performance score를 본문에 추가하였습니다.
** Updates on 2020.12.04 **
Huggingface Transformers가 v4.0.0으로 업데이트됨에 따라 Tutorial의 코드가 일부 변경되었습니다.
업데이트된 KcBERT-Large NSMC Finetuning Colab:
![]()
** Updates on 2020.09.11 **
KcBERT를 Google Colab에서 TPU를 통해 학습할 수 있는 튜토리얼을 제공합니다! 아래 버튼을 눌러보세요.
Colab에서 TPU로 KcBERT Pretrain 해보기:
![]()
텍스트 분량만 전체 12G 텍스트 중 일부(144MB)로 줄여 학습을 진행합니다.
한국어 데이터셋/코퍼스를 좀더 쉽게 사용할 수 있는 Korpora 패키지를 사용합니다.
** Updates on 2020.09.08 **
Github Release를 통해 학습 데이터를 업로드하였습니다.
다만 한 파일당 2GB 이내의 제약으로 인해 분할압축되어있습니다.
아래 링크를 통해 받아주세요. (가입 없이 받을 수 있어요. 분할압축)
만약 한 파일로 받고싶으시거나/Kaggle에서 데이터를 살펴보고 싶으시다면 아래의 캐글 데이터셋을 이용해주세요.
** Updates on 2020.08.22 **
Pretrain Dataset 공개
- 캐글: https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments (한 파일로 받을 수 있어요. 단일파일)
Kaggle에 학습을 위해 정제한(아래 clean처리를 거친) Dataset을 공개하였습니다!
직접 다운받으셔서 다양한 Task에 학습을 진행해보세요 :)
공개된 한국어 BERT는 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
KcBERT는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델입니다.
KcBERT는 Huggingface의 Transformers 라이브러리를 통해 간편히 불러와 사용할 수 있습니다. (별도의 파일 다운로드가 필요하지 않습니다.)
KcBERT Performance
- Finetune 코드는 https://github.com/Beomi/KcBERT-finetune 에서 찾아보실 수 있습니다.
| Size (용량) |
NSMC (acc) |
Naver NER (F1) |
PAWS (acc) |
KorNLI (acc) |
KorSTS (spearman) |
Question Pair (acc) |
KorQuaD (Dev) (EM/F1) |
|
|---|---|---|---|---|---|---|---|---|
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERT의 Size는 Bert Model과 Tokenizer DB를 합친 것입니다.
*config의 세팅을 그대로 하여 돌린 결과이며, hyperparameter tuning을 추가적으로 할 시 더 좋은 성능이 나올 수 있습니다.
How to use
Requirements
pytorch <= 1.8.0transformers ~= 3.0.1transformers ~= 4.0.0도 호환됩니다.
emoji ~= 0.6.0soynlp ~= 0.0.493
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
Pretrain & Finetune Colab 링크 모음
Pretrain Data
Pretrain Code
Colab에서 TPU로 KcBERT Pretrain 해보기:
![]()
Finetune Samples
KcBERT-Base NSMC Finetuning with PyTorch-Lightning (Colab)
![]()
KcBERT-Large NSMC Finetuning with PyTorch-Lightning (Colab)
![]()
위 두 코드는 Pretrain 모델(base, large)와 batch size만 다를 뿐, 나머지 코드는 완전히 동일합니다.
Train Data & Preprocessing
Raw Data
학습 데이터는 2019.01.01 ~ 2020.06.15 사이에 작성된 댓글 많은 뉴스 기사들의 댓글과 대댓글을 모두 수집한 데이터입니다.
데이터 사이즈는 텍스트만 추출시 약 15.4GB이며, 1억1천만개 이상의 문장으로 이뤄져 있습니다.
Preprocessing
PLM 학습을 위해서 전처리를 진행한 과정은 다음과 같습니다.
한글 및 영어, 특수문자, 그리고 이모지(🥳)까지!
정규표현식을 통해 한글, 영어, 특수문자를 포함해 Emoji까지 학습 대상에 포함했습니다.
한편, 한글 범위를
ㄱ-ㅎ가-힣으로 지정해ㄱ-힣내의 한자를 제외했습니다.댓글 내 중복 문자열 축약
ㅋㅋㅋㅋㅋ와 같이 중복된 글자를ㅋㅋ와 같은 것으로 합쳤습니다.Cased Model
KcBERT는 영문에 대해서는 대소문자를 유지하는 Cased model입니다.
글자 단위 10글자 이하 제거
10글자 미만의 텍스트는 단일 단어로 이뤄진 경우가 많아 해당 부분을 제외했습니다.
중복 제거
중복적으로 쓰인 댓글을 제거하기 위해 중복 댓글을 하나로 합쳤습니다.
이를 통해 만든 최종 학습 데이터는 12.5GB, 8.9천만개 문장입니다.
아래 명령어로 pip로 설치한 뒤, 아래 clean함수로 클리닝을 하면 Downstream task에서 보다 성능이 좋아집니다. ([UNK] 감소)
pip install soynlp emoji
아래 clean 함수를 Text data에 사용해주세요.
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
Cleaned Data (Released on Kaggle)
원본 데이터를 위 clean함수로 정제한 12GB분량의 txt 파일을 아래 Kaggle Dataset에서 다운받으실 수 있습니다 :)
https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments
Tokenizer Train
Tokenizer는 Huggingface의 Tokenizers 라이브러리를 통해 학습을 진행했습니다.
그 중 BertWordPieceTokenizer 를 이용해 학습을 진행했고, Vocab Size는 30000으로 진행했습니다.
Tokenizer를 학습하는 것에는 1/10로 샘플링한 데이터로 학습을 진행했고, 보다 골고루 샘플링하기 위해 일자별로 stratify를 지정한 뒤 햑습을 진행했습니다.
BERT Model Pretrain
- KcBERT Base config
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
- KcBERT Large config
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
BERT Model Config는 Base, Large 기본 세팅값을 그대로 사용했습니다. (MLM 15% 등)
TPU v3-8 을 이용해 각각 3일, N일(Large는 학습 진행 중)을 진행했고, 현재 Huggingface에 공개된 모델은 1m(100만) step을 학습한 ckpt가 업로드 되어있습니다.
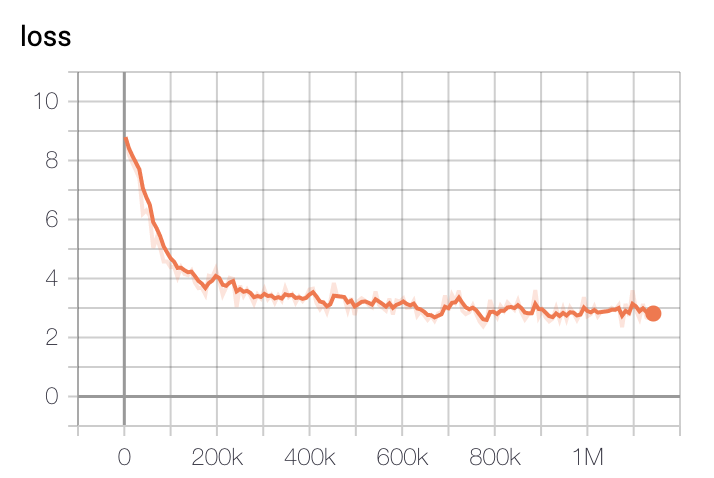
모델 학습 Loss는 Step에 따라 초기 200k에 가장 빠르게 Loss가 줄어들다 400k이후로는 조금씩 감소하는 것을 볼 수 있습니다.
- Base Model Loss
- Large Model Loss
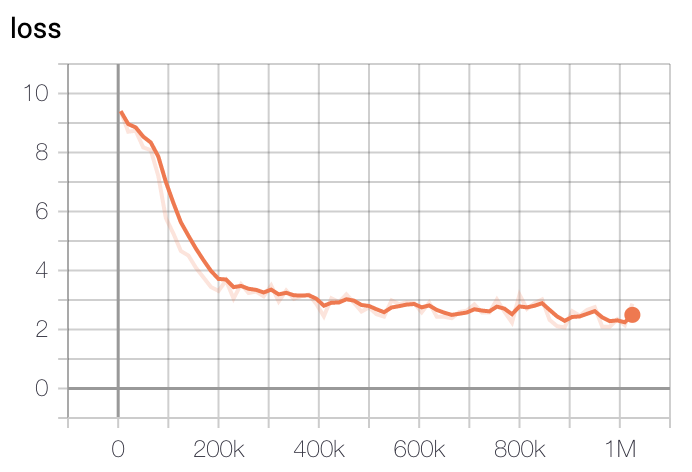
학습은 GCP의 TPU v3-8을 이용해 학습을 진행했고, 학습 시간은 Base Model 기준 2.5일정도 진행했습니다. Large Model은 약 5일정도 진행한 뒤 가장 낮은 loss를 가진 체크포인트로 정했습니다.
Example
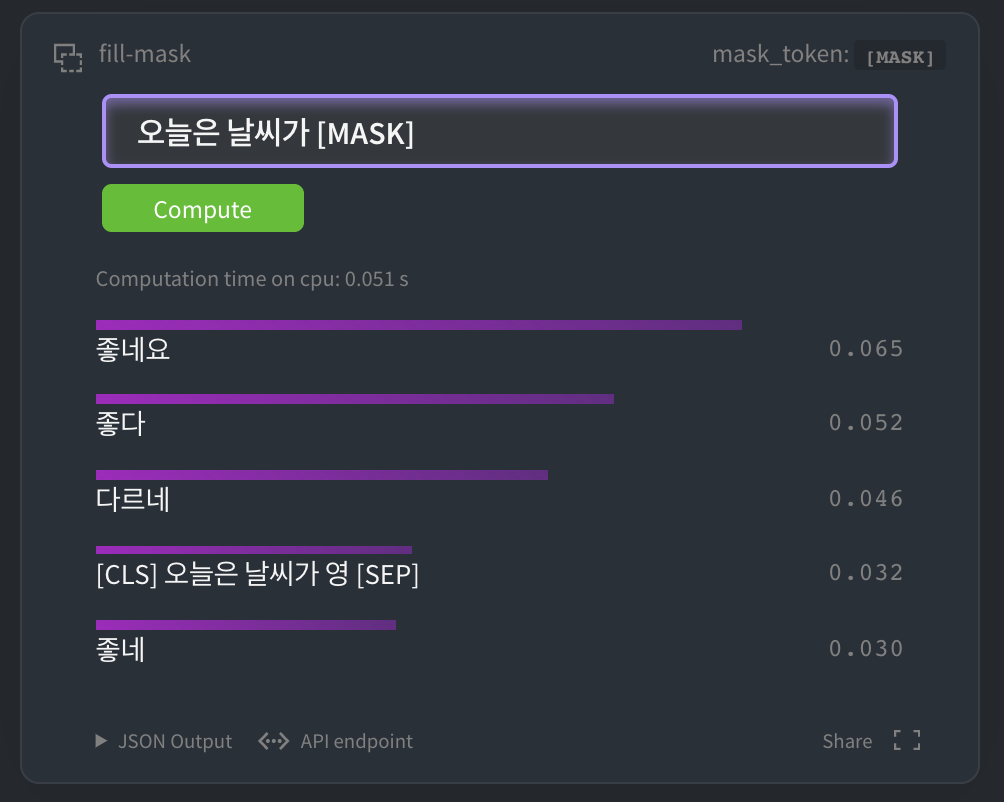
HuggingFace MASK LM
HuggingFace kcbert-base 모델 에서 아래와 같이 테스트 해 볼 수 있습니다.
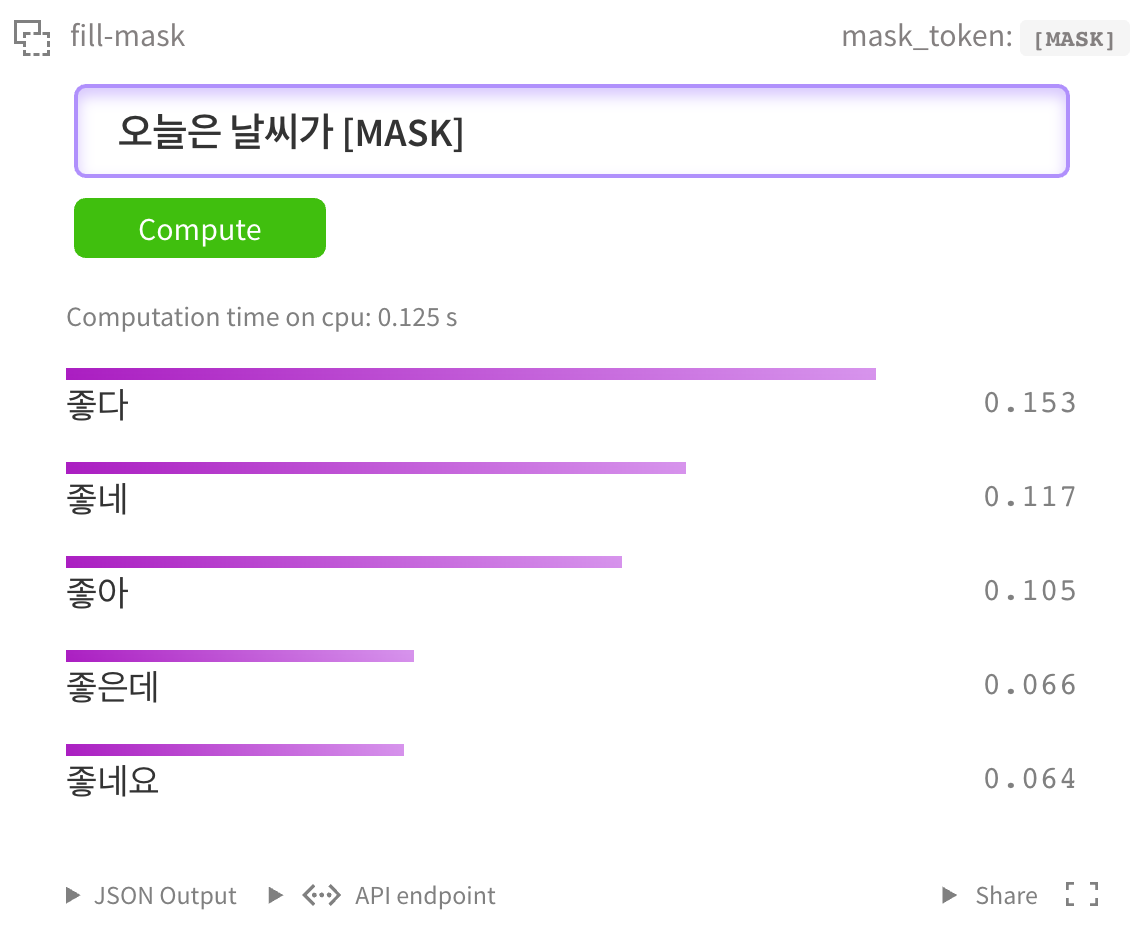
물론 kcbert-large 모델 에서도 테스트 할 수 있습니다.
NSMC Binary Classification
네이버 영화평 코퍼스 데이터셋을 대상으로 Fine Tuning을 진행해 성능을 간단히 테스트해보았습니다.
Base Model을 Fine Tune하는 코드는
![]() 에서 직접 실행해보실 수 있습니다.
에서 직접 실행해보실 수 있습니다.
Large Model을 Fine Tune하는 코드는
![]() 에서 직접 실행해볼 수 있습니다.
에서 직접 실행해볼 수 있습니다.
- GPU는 P100 x1대 기준 1epoch에 2-3시간, TPU는 1epoch에 1시간 내로 소요됩니다.
- GPU RTX Titan x4대 기준 30분/epoch 소요됩니다.
- 예시 코드는 pytorch-lightning으로 개발했습니다.
실험결과
KcBERT-Base Model 실험결과: Val acc
.8905
KcBERT-Large Model 실험 결과: Val acc
.9089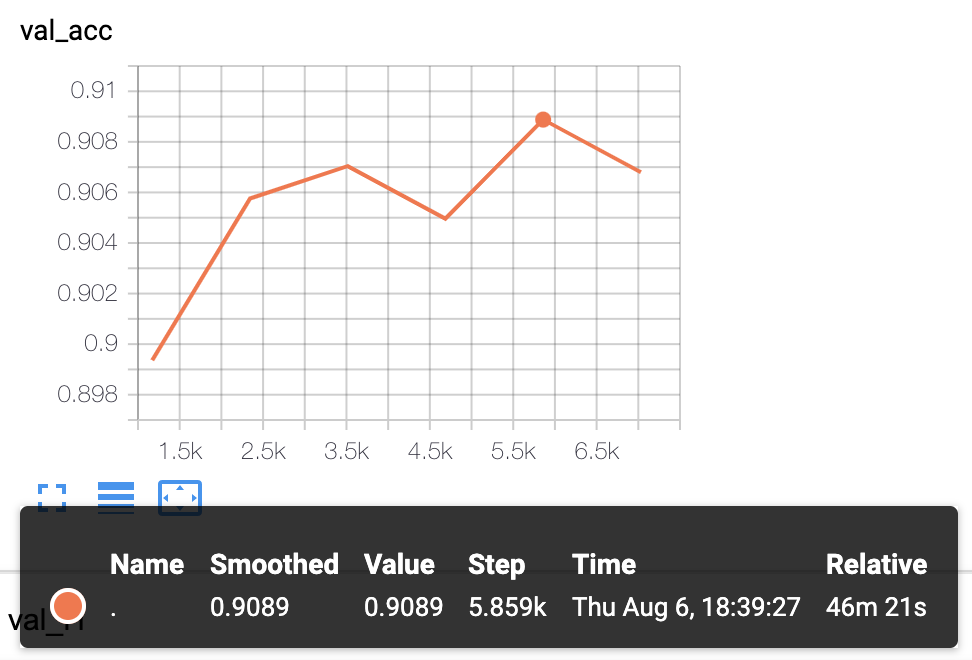
더 다양한 Downstream Task에 대해 테스트를 진행하고 공개할 예정입니다.
인용표기/Citation
KcBERT를 인용하실 때는 아래 양식을 통해 인용해주세요.
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
- 논문집 다운로드 링크: http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (*혹은 http://hclt.kr/symp/?lnb=conference )
Acknowledgement
KcBERT Model을 학습하는 GCP/TPU 환경은 TFRC 프로그램의 지원을 받았습니다.
모델 학습 과정에서 많은 조언을 주신 Monologg 님 감사합니다 :)