Hugging Face
Models
Datasets
Spaces
Posts
Docs
Enterprise
Pricing
Log In
Sign Up
anilbs
/
segmentation
like
2
Voice Activity Detection
pyannote.audio
PyTorch
ami
dihard
voxconverse
pyannote
pyannote-audio-model
audio
voice
speech
speaker
speaker-segmentation
overlapped-speech-detection
resegmentation
arxiv:
2104.04045
License:
mit
Model card
Files
Files and versions
Community
Use this model
f260c50
segmentation
2 contributors
History:
3 commits
Anil Battalahalli Sreenath
modified README.md
f260c50
about 2 years ago
reproducible_research
Added a model file
about 2 years ago
.gitattributes
Safe
690 Bytes
Added a model file
about 2 years ago
README.md
Safe
5.29 kB
modified README.md
about 2 years ago
config.yaml
Safe
318 Bytes
Added a model file
about 2 years ago
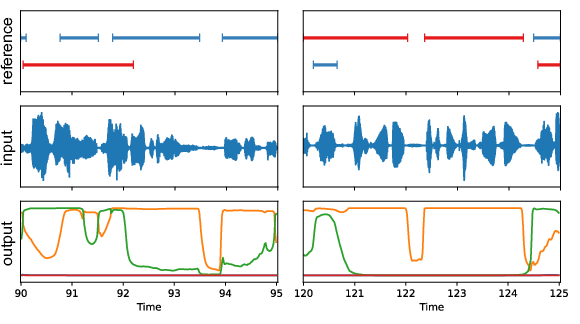
example.png
Safe
17.5 kB
Added a model file
about 2 years ago
pytorch_model.bin
pickle
Detected Pickle imports (17)
"collections.defaultdict"
,
"torch._utils._rebuild_tensor_v2"
,
"omegaconf.base.Metadata"
,
"__builtin__.long"
,
"collections.OrderedDict"
,
"omegaconf.listconfig.ListConfig"
,
"pyannote.audio.core.task.Resolution"
,
"pyannote.audio.core.model.Introspection"
,
"pyannote.audio.core.task.Problem"
,
"torch.FloatStorage"
,
"__builtin__.list"
,
"__builtin__.dict"
,
"typing.Any"
,
"torch.torch_version.TorchVersion"
,
"pyannote.audio.core.task.Specifications"
,
"omegaconf.base.ContainerMetadata"
,
"omegaconf.nodes.AnyNode"
How to fix it?
17.7 MB
LFS
Added a model file
about 2 years ago

{kind=link}
{kind=link}