
Rahkakavee Baskaran
commited on
Commit
•
3faa039
1
Parent(s):
fb00699
delete typing packages and update readme
Browse files- README.md +56 -103
- assets/semantic_search.png +0 -0
- pipeline.py +0 -1
README.md
CHANGED
|
@@ -51,132 +51,98 @@ model-index:
|
|
| 51 |
- type: f1
|
| 52 |
value: 0.88
|
| 53 |
name: F1 'Thema' (macro)
|
|
|
|
| 54 |
---
|
| 55 |
|
| 56 |
# Model Card for Musterdatenkatalog Classifier
|
| 57 |
|
| 58 |
-
# Model Details
|
| 59 |
-
|
| 60 |
## Model Description
|
| 61 |
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
It was created as part of the Bertelsmann Foundation's Musterdatenkatalog (MDK) project (See their website [here](https://www.bertelsmann-stiftung.de/de/unsere-projekte/smart-country/musterdatenkatalog)).
|
| 65 |
-
The main intent of the MDK project was to classify open data into a taxonomy to help give an overview of already published data.
|
| 66 |
-
It can help municipalities in Germany, as well as data analysts and journalists, to see which cities have already published data sets and what might be missing.
|
| 67 |
-
The project uses a taxonomy to classify the data and the model was specifically trained for the project and the classification task. It thus has a clear intended downstream task and should be used with the mentioned taxonomy.
|
| 68 |
-
|
| 69 |
-
**Information about the underlying taxonomy:**
|
| 70 |
-
The used taxonomy 'Musterdatenkatalog' has two levels: 'Thema' and 'Bezeichnung' which roughly translates to topic and label. There are 25 entries for the top level ranging from topics such as 'Finanzen' (finance) to 'Gesundheit' (health).
|
| 71 |
-
The second level, 'Bezeichnung' (label) goes into more detail and would for example contain 'Krankenhaus' (hospital) in the case of the topic being health. The second level contains 241 labels. The combination of topic and label (Thema + Bezeichnung) creates a 'Musterdatensatz'.
|
| 72 |
-
|
| 73 |
-
One can classify the data into the topics or the labels, results for both are presented down below. Although matching to other taxonomies is provdided in the published rdf version of the taxonomy (todo), the model is tailored to this taxonomy.
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
- **Developed by:** and-effect
|
| 78 |
- **Model type:** Text Classification
|
| 79 |
- **Language(s) (NLP):** de
|
| 80 |
-
- **Finetuned from model:** "bert-base-german-case. For more information
|
| 81 |
-
|
| 82 |
-
## Model Sources
|
| 83 |
|
| 84 |
-
<!-- Provide the basic links for the model. -->
|
| 85 |
|
| 86 |
-
|
| 87 |
-
- **Demo:** [More Information Needed]
|
| 88 |
-
|
| 89 |
-
# Direct Use
|
| 90 |
-
|
| 91 |
-
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
|
| 92 |
|
| 93 |
-
|
|
|
|
| 94 |
|
| 95 |
-
|
| 96 |
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
|
| 101 |
-
|
| 102 |
|
| 103 |
-
|
| 104 |
-
from sentence_transformers import SentenceTransformer
|
| 105 |
-
sentences = ["This is an example sentence", "Each sentence is converted"]
|
| 106 |
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
print(embeddings)
|
| 110 |
```
|
| 111 |
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
|
| 115 |
|
| 116 |
```python
|
| 117 |
-
|
| 118 |
-
import
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
#Mean Pooling - Take attention mask into account for correct averaging
|
| 122 |
-
def mean_pooling(model_output, attention_mask):
|
| 123 |
-
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
|
| 124 |
-
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 125 |
-
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
|
| 126 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
|
| 128 |
-
|
| 129 |
-
sentences = ['This is an example sentence', 'Each sentence is converted']
|
| 130 |
|
| 131 |
-
|
| 132 |
-
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
|
| 133 |
-
model = AutoModel.from_pretrained('{MODEL_NAME}')
|
| 134 |
|
| 135 |
-
|
| 136 |
-
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
|
| 137 |
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 144 |
|
| 145 |
-
|
| 146 |
-
print(sentence_embeddings)
|
| 147 |
```
|
| 148 |
|
| 149 |
-
|
| 150 |
|
| 151 |
-
|
| 152 |
|
| 153 |
-
The
|
| 154 |
-
More information on the taxonomy (classification categories) and the Project can be found on the [project website](https://www.bertelsmann-stiftung.de/de/unsere-projekte/smart-country/musterdatenkatalog).
|
| 155 |
|
|
|
|
| 156 |
|
|
|
|
| 157 |
|
| 158 |
-
|
| 159 |
|
| 160 |
-
|
|
|
|
|
|
|
| 161 |
|
| 162 |
-
The model has some limititations. The model has some limitations in terms of the downstream task.
|
| 163 |
1. **Distribution of classes**: The dataset trained on is small, but at the same time the number of classes is very high. Thus, for some classes there are only a few examples (more information about the class distribution of the training data can be found here). Consequently, the performance for smaller classes may not be as good as for the majority classes. Accordingly, the evaluation is also limited.
|
| 164 |
-
2. **Systematic problems**: some subjects could not be correctly classified systematically. One example is the embedding of titles
|
| 165 |
3. **Generalization of the model**: by using semantic search, the model is able to classify titles into new categories that have not been trained, but the model is not tuned for this and therefore the performance of the model for unseen classes is likely to be limited.
|
| 166 |
|
| 167 |
-
##
|
| 168 |
-
|
| 169 |
-
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 170 |
-
|
| 171 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 172 |
-
|
| 173 |
-
# Training Details
|
| 174 |
|
| 175 |
## Training Data
|
| 176 |
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
You can find all information about the training data [here](https://huggingface.co/datasets/and-effect/mdk_gov_data_titles_clf). For the Fine Tuning we used the revision 172e61bb1dd20e43903f4c51e5cbec61ec9ae6e6 of the data, since the performance was better with this previous version of the data.
|
| 180 |
|
| 181 |
## Training Procedure
|
| 182 |
|
|
@@ -193,7 +159,7 @@ The model is fine tuned with similar and dissimilar pairs. Similar pairs are bui
|
|
| 193 |
| test_similar_pairs | 498 |
|
| 194 |
| test_unsimilar_pairs | 249 |
|
| 195 |
|
| 196 |
-
|
| 197 |
## Training Parameter
|
| 198 |
|
| 199 |
The model was trained with the parameters:
|
|
@@ -206,20 +172,14 @@ The model was trained with the parameters:
|
|
| 206 |
|
| 207 |
Hyperparameter:
|
| 208 |
|
| 209 |
-
```
|
| 210 |
{
|
| 211 |
"epochs": 3,
|
| 212 |
"warmup_steps": 100,
|
| 213 |
}
|
| 214 |
```
|
| 215 |
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 219 |
-
|
| 220 |
-
[More Information Needed]
|
| 221 |
-
|
| 222 |
-
# Evaluation
|
| 223 |
|
| 224 |
All metrices express the models ability to classify dataset titles from GOVDATA into the taxonomy described [here](https://huggingface.co/datasets/and-effect/mdk_gov_data_titles_clf). For more information see VERLINKUNG MDK Projekt.
|
| 225 |
|
|
@@ -242,7 +202,6 @@ The tasks denoted with 'I' include all classes.
|
|
| 242 |
The tasks are split not only into either including all classes ('I') or not ('II'), they are also divided into a task on 'Bezeichnung' or 'Thema'.
|
| 243 |
As previously mentioned this has to do with the underlying taxonomy. The task on 'Thema' is performed on the first level of the taxonomy with 25 classes, the task on 'Bezeichnung' is performed on the second level which has 241 classes.
|
| 244 |
|
| 245 |
-
|
| 246 |
## Results
|
| 247 |
|
| 248 |
| ***task*** | ***acccuracy*** | ***precision (macro)*** | ***recall (macro)*** | ***f1 (macro)*** |
|
|
@@ -255,12 +214,6 @@ As previously mentioned this has to do with the underlying taxonomy. The task on
|
|
| 255 |
| Validation dataset 'Bezeichnung' II | 0.51 | 0.58 | 0.69 | 0.59 |
|
| 256 |
|
| 257 |
\* the accuracy in brackets was calculated with a manual analysis. This was done to check for data entries that could for example be part of more than one class and thus were actually correctly classified by the algorithm.
|
| 258 |
-
In this step the correct labeling of the test data was also checked again for possible mistakes and resulted in a better performance.
|
| 259 |
-
|
| 260 |
-
The validation dataset was created manually to check certain classes
|
| 261 |
-
|
| 262 |
-
## Additional Information
|
| 263 |
-
|
| 264 |
-
### Licensing Information
|
| 265 |
|
| 266 |
-
|
|
|
|
| 51 |
- type: f1
|
| 52 |
value: 0.88
|
| 53 |
name: F1 'Thema' (macro)
|
| 54 |
+
license: cc-by-4.0
|
| 55 |
---
|
| 56 |
|
| 57 |
# Model Card for Musterdatenkatalog Classifier
|
| 58 |
|
|
|
|
|
|
|
| 59 |
## Model Description
|
| 60 |
|
| 61 |
+
- **Developed by:** [and-effect](https://www.and-effect.com/)
|
| 62 |
+
- **Project by**: [Bertelsmann Stiftung](https://www.bertelsmann-stiftung.de/de/startseite)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
- **Model type:** Text Classification
|
| 64 |
- **Language(s) (NLP):** de
|
| 65 |
+
- **Finetuned from model:** "bert-base-german-case. For more information on the model check on [this model card](https://huggingface.co/bert-base-german-cased)"
|
| 66 |
+
- **license**: cc-by-4.0
|
|
|
|
| 67 |
|
|
|
|
| 68 |
|
| 69 |
+
## Model Sources
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 70 |
|
| 71 |
+
- **Repository**:
|
| 72 |
+
- **Demo**: [Spaces App](https://huggingface.co/spaces/and-effect/Musterdatenkatalog)
|
| 73 |
|
| 74 |
+
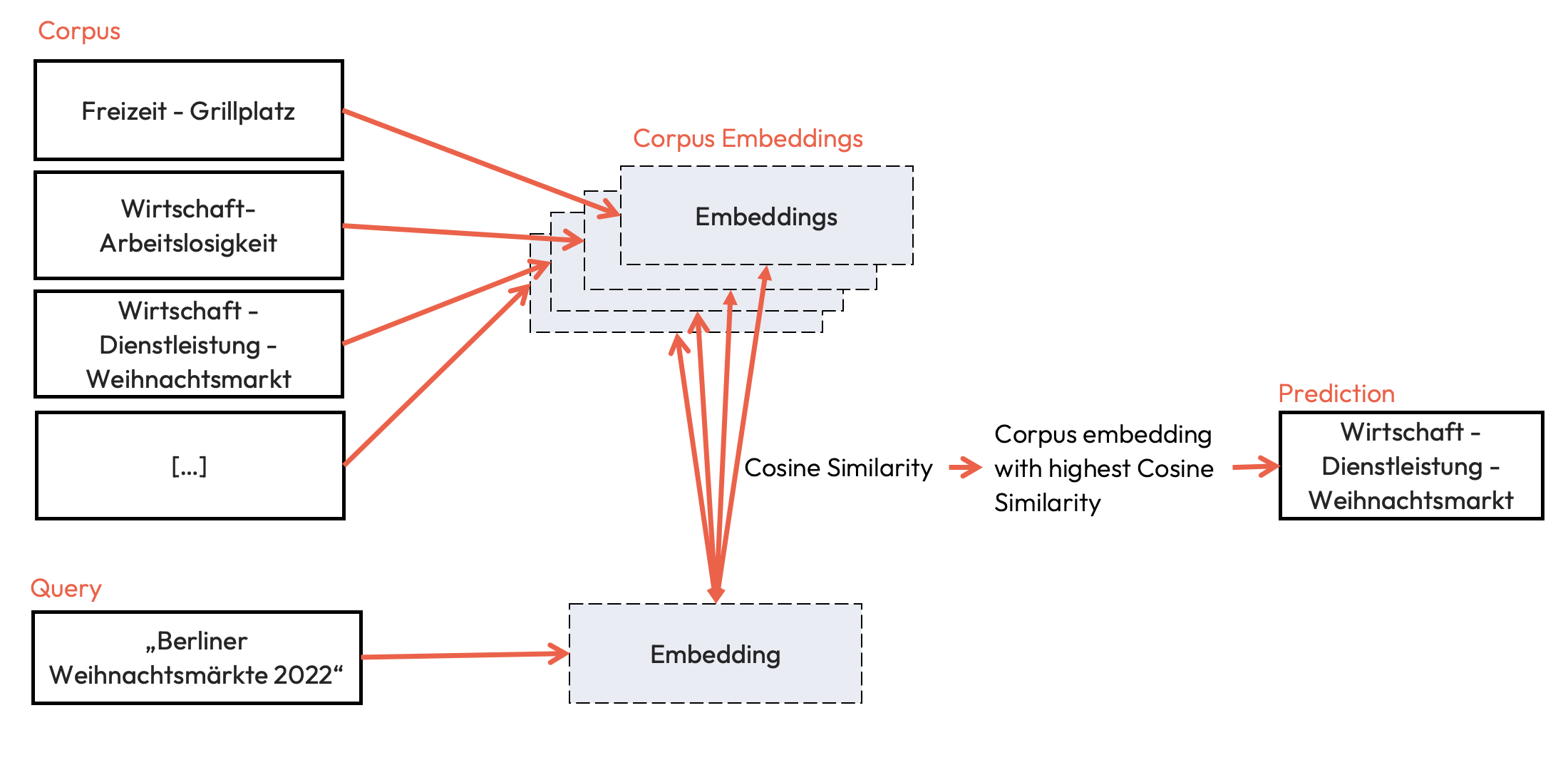
This model is based on [bert-base-german-cased](https://huggingface.co/bert-base-cased) and fine-tuned on [and-effect/mdk_gov_data_titles_clf](https://huggingface.co/datasets/and-effect/mdk_gov_data_titles_clf). The model was created as part of the [Bertelsmann Foundation's Musterdatenkatalog (MDK)](https://www.bertelsmann-stiftung.de/de/unsere-projekte/smart-country/musterdatenkatalog) project. The model is intended to classify open source dataset titles from german municipalities. This can help municipalities in Germany, as well as data analysts and journalists, to see which cities have already published data sets and what might be missing. The model is specifically tailored for this task and uses a specific taxonomy. It thus has a clear intended downstream task and should be used with the mentioned taxonomy.
|
| 75 |
|
| 76 |
+
**Information about the underlying taxonomy:**
|
| 77 |
+
The used taxonomy 'Musterdatenkatalog' has two levels: 'Thema' and 'Bezeichnung' which roughly translates to topic and label. There are 25 entries for the top level ranging from topics such as 'Finanzen' (finance) to 'Gesundheit' (health).
|
| 78 |
+
The second level, 'Bezeichnung' (label) goes into more detail and would for example contain 'Krankenhaus' (hospital) in the case of the topic being health. The second level contains 241 labels. The combination of topic and label (Thema + Bezeichnung) creates a 'Musterdatensatz'. One can classify the data into the topics or the labels, results for both are presented down below. Although matching to other taxonomies is provdided in the published rdf version of the taxonomy, the model is tailored to this taxonomy. You can find the taxonomy in rdf format [here](https://huggingface.co/datasets/and-effect/MDK_taxonomy). Also have a look on our visualization of the taxonomy [here](https://huggingface.co/spaces/and-effect/Musterdatenkatalog).
|
| 79 |
|
| 80 |
+
## Use model for classification
|
| 81 |
|
| 82 |
+
Please make sure that you have installed the following packages:
|
|
|
|
|
|
|
| 83 |
|
| 84 |
+
```bash
|
| 85 |
+
pip install sentence-transformers huggingface_hub
|
|
|
|
| 86 |
```
|
| 87 |
|
| 88 |
+
In order to run the algorithm use the following code:
|
|
|
|
|
|
|
| 89 |
|
| 90 |
```python
|
| 91 |
+
import sys
|
| 92 |
+
from huggingface_hub import snapshot_download
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
|
| 94 |
+
path = snapshot_download(
|
| 95 |
+
cache_dir="tmp/",
|
| 96 |
+
repo_id="and-effect/musterdatenkatalog_clf",
|
| 97 |
+
revision="main",
|
| 98 |
+
)
|
| 99 |
|
| 100 |
+
sys.path.append(path)
|
|
|
|
| 101 |
|
| 102 |
+
from pipeline import PipelineWrapper
|
|
|
|
|
|
|
| 103 |
|
| 104 |
+
pipeline = PipelineWrapper(path=path)
|
|
|
|
| 105 |
|
| 106 |
+
queries = [
|
| 107 |
+
{
|
| 108 |
+
"id": "1", "title": "Spielplätze"
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"id": "2", "title": "Berliner Weihnachtsmärkte 2022"
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"id": "3", "title": "Hochschulwechslerquoten zum Masterstudium nach Bundesländern",
|
| 115 |
+
}
|
| 116 |
+
]
|
| 117 |
|
| 118 |
+
output = pipeline(queries)
|
|
|
|
| 119 |
```
|
| 120 |
|
| 121 |
+
The input data must be a list of dictionaries. Each dictionary must contain the keys 'id' and 'title'. The key title is the input for the pipeline. The output is again a list of dictionaries containing the id, the title and the key 'prediction' with the prediction of the algorithm.
|
| 122 |
|
| 123 |
+
## Classification Process
|
| 124 |
|
| 125 |
+
The classification is realized using semantic search. For this purpose, both the taxonomy and the queries, in this case dataset titles, are embedded with the model. Using cosine similarity, the label with the highest similarity to the query is determined.
|
|
|
|
| 126 |
|
| 127 |
+

|
| 128 |
|
| 129 |
+
## Direct Use
|
| 130 |
|
| 131 |
+
Direct use of the model is possible with Sentence Transformers or Hugging Face Transformers. Since this model was developed only for classifying dataset titles from GOV Data into the taxonomy described above, we do not recommend using the model as an embedder for other domains.
|
| 132 |
|
| 133 |
+
## Bias, Risks, and Limitations
|
| 134 |
+
|
| 135 |
+
The model has some limititations. The model has some limitations in terms of the downstream task.
|
| 136 |
|
|
|
|
| 137 |
1. **Distribution of classes**: The dataset trained on is small, but at the same time the number of classes is very high. Thus, for some classes there are only a few examples (more information about the class distribution of the training data can be found here). Consequently, the performance for smaller classes may not be as good as for the majority classes. Accordingly, the evaluation is also limited.
|
| 138 |
+
2. **Systematic problems**: some subjects could not be correctly classified systematically. One example is the embedding and classification of titles related to 'migration'. In none of the evaluation cases could the titles be embedded in such a way that they corresponded to their true names.
|
| 139 |
3. **Generalization of the model**: by using semantic search, the model is able to classify titles into new categories that have not been trained, but the model is not tuned for this and therefore the performance of the model for unseen classes is likely to be limited.
|
| 140 |
|
| 141 |
+
## Training Details
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
|
| 143 |
## Training Data
|
| 144 |
|
| 145 |
+
You can find all information about the training data [here](https://huggingface.co/datasets/and-effect/mdk_gov_data_titles_clf). For the Fine Tuning we used the revision 172e61bb1dd20e43903f4c51e5cbec61ec9ae6e6 of the data, since the performance was better with this previous version of the data. We additionally applied [AugmentedSBERT]("https://www.sbert.net/examples/training/data_augmentation/README.html) to extend the dataset for better performance.
|
|
|
|
|
|
|
| 146 |
|
| 147 |
## Training Procedure
|
| 148 |
|
|
|
|
| 159 |
| test_similar_pairs | 498 |
|
| 160 |
| test_unsimilar_pairs | 249 |
|
| 161 |
|
| 162 |
+
We trained a CrossEncoder based on this data and used it again to generate new samplings based on the dataset titles (silver data). Using both we then fine tuned a bi-encoder, representing the resulting model.
|
| 163 |
## Training Parameter
|
| 164 |
|
| 165 |
The model was trained with the parameters:
|
|
|
|
| 172 |
|
| 173 |
Hyperparameter:
|
| 174 |
|
| 175 |
+
```json
|
| 176 |
{
|
| 177 |
"epochs": 3,
|
| 178 |
"warmup_steps": 100,
|
| 179 |
}
|
| 180 |
```
|
| 181 |
|
| 182 |
+
## Evaluation
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 183 |
|
| 184 |
All metrices express the models ability to classify dataset titles from GOVDATA into the taxonomy described [here](https://huggingface.co/datasets/and-effect/mdk_gov_data_titles_clf). For more information see VERLINKUNG MDK Projekt.
|
| 185 |
|
|
|
|
| 202 |
The tasks are split not only into either including all classes ('I') or not ('II'), they are also divided into a task on 'Bezeichnung' or 'Thema'.
|
| 203 |
As previously mentioned this has to do with the underlying taxonomy. The task on 'Thema' is performed on the first level of the taxonomy with 25 classes, the task on 'Bezeichnung' is performed on the second level which has 241 classes.
|
| 204 |
|
|
|
|
| 205 |
## Results
|
| 206 |
|
| 207 |
| ***task*** | ***acccuracy*** | ***precision (macro)*** | ***recall (macro)*** | ***f1 (macro)*** |
|
|
|
|
| 214 |
| Validation dataset 'Bezeichnung' II | 0.51 | 0.58 | 0.69 | 0.59 |
|
| 215 |
|
| 216 |
\* the accuracy in brackets was calculated with a manual analysis. This was done to check for data entries that could for example be part of more than one class and thus were actually correctly classified by the algorithm.
|
| 217 |
+
In this step the correct labeling of the test data was also checked again for possible mistakes and resulted in a better performance.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 218 |
|
| 219 |
+
The validation dataset was created manually to check certain classes.
|
assets/semantic_search.png
ADDED
|
pipeline.py
CHANGED
|
@@ -1,4 +1,3 @@
|
|
| 1 |
-
from typing import Any, Dict, List
|
| 2 |
from sentence_transformers import SentenceTransformer
|
| 3 |
from sentence_transformers import util
|
| 4 |
import torch
|
|
|
|
|
|
|
| 1 |
from sentence_transformers import SentenceTransformer
|
| 2 |
from sentence_transformers import util
|
| 3 |
import torch
|