|
|
|
--- |
|
language: en |
|
tags: [cvpr2021, computer vision, face alignment, facial landmark point, pose estimation, face pose tracking, CNN, loss, custom loss, ASMNet, Tensor Flow] |
|
license: mit |
|
--- |
|
|
|
|
|
[](https://paperswithcode.com/sota/pose-estimation-on-300w-full?p=deep-active-shape-model-for-face-alignment) |
|
|
|
|
|
[](https://paperswithcode.com/sota/face-alignment-on-wflw?p=deep-active-shape-model-for-face-alignment) |
|
|
|
[](https://paperswithcode.com/sota/face-alignment-on-300w?p=deep-active-shape-model-for-face-alignment) |
|
|
|
```diff |
|
! plaese STAR the repo if you like it. |
|
``` |
|
|
|
# [ASMNet](https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en) |
|
|
|
|
|
## a Lightweight Deep Neural Network for Face Alignment and Pose Estimation |
|
|
|
#### Link to the paper: |
|
https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en |
|
|
|
#### Link to the paperswithcode.com: |
|
https://paperswithcode.com/paper/asmnet-a-lightweight-deep-neural-network-for |
|
|
|
#### Link to the article on Towardsdatascience.com: |
|
https://aliprf.medium.com/asmnet-a-lightweight-deep-neural-network-for-face-alignment-and-pose-estimation-9e9dfac07094 |
|
|
|
``` |
|
Please cite this work as: |
|
|
|
@inproceedings{fard2021asmnet, |
|
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation}, |
|
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad}, |
|
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, |
|
pages={1521--1530}, |
|
year={2021} |
|
} |
|
``` |
|
|
|
## Introduction |
|
|
|
ASMNet is a lightweight Convolutional Neural Network (CNN) which is designed to perform face alignment and pose estimation efficiently while having acceptable accuracy. ASMNet proposed inspired by MobileNetV2, modified to be suitable for face alignment and pose |
|
estimation, while being about 2 times smaller in terms of number of the parameters. Moreover, Inspired by Active Shape Model (ASM), ASM-assisted loss function is proposed in order to improve the accuracy of facial landmark points detection and pose estimation. |
|
|
|
## ASMnet Architecture |
|
Features in a CNN are distributed hierarchically. In other words, the lower layers have features such as edges, and corners which are more suitable for tasks like landmark localization and pose estimation, and deeper layers contain more abstract features that are more suitable for tasks like image classification and image detection. Furthermore, training a network for correlated tasks simultaneously builds a synergy that can improve the performance of each task. |
|
|
|
Having said that, we designed ASMNe by fusing the features that are available if different layers of the model. Furthermore, by concatenating the features that are collected after each global average pooling layer in the back-propagation process, it will be possible for the network to evaluate the effect of each shortcut path. Following is the ASMNet architecture: |
|
|
|
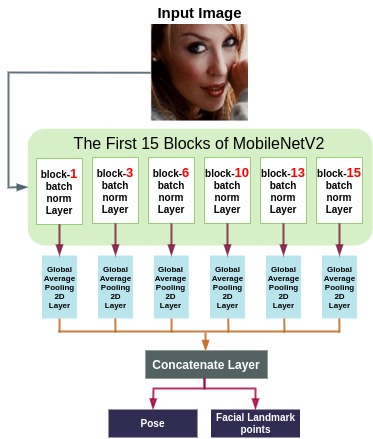 |
|
|
|
The implementation of ASMNet in TensorFlow is provided in the following path: |
|
https://github.com/aliprf/ASMNet/blob/master/cnn_model.py |
|
|
|
|
|
|
|
## ASM Loss |
|
|
|
We proposed a new loss function called ASM-LOSS which utilizes ASM to improve the accuracy of the network. In other words, during the training process, the loss function compares the predicted facial landmark points with their corresponding ground truth as well as the smoothed version the ground truth which is generated using ASM operator. Accordingly, ASM-LOSS guides the network to first learn the smoothed distribution of the facial landmark points. Then, it leads the network to learn the original landmark points. For more detail please refer to the paper. |
|
Following is the ASM Loss diagram: |
|
|
|
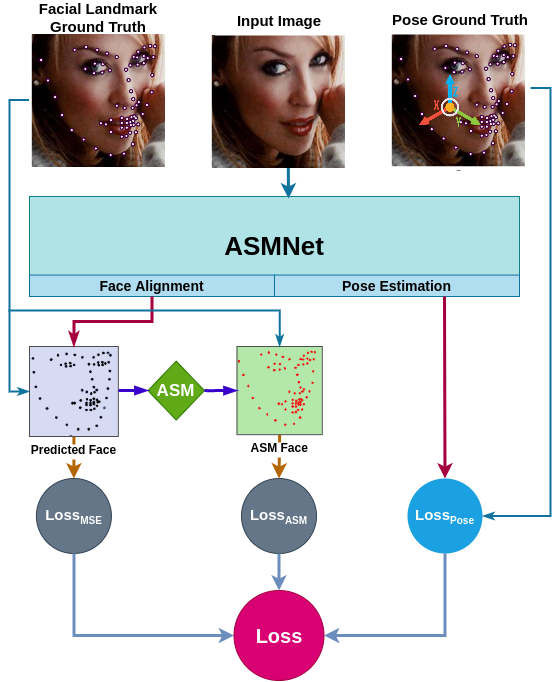 |
|
|
|
|
|
## Evaluation |
|
|
|
As you can see in the following tables, ASMNet has only 1.4 M parameters which is the smallets comparing to the similar Facial landmark points detection models. Moreover, ASMNet designed to performs Face alignment as well as Pose estimation with a very small CNN while having an acceptable accuracy. |
|
|
|
 |
|
|
|
Although ASMNet is much smaller than the state-of-the-art methods on face alignment, it's performance is also very good and acceptable for many real-world applications: |
|
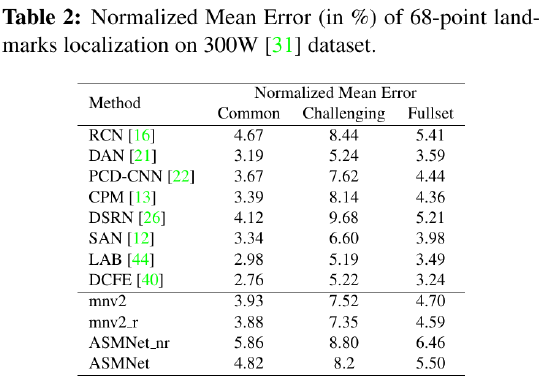 |
|
|
|
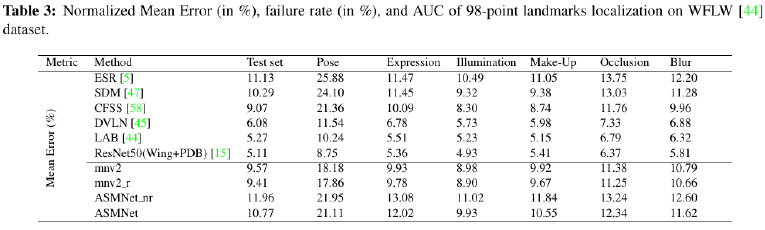 |
|
|
|
|
|
As shown in the following table, ASMNet performs much better that the state-of-the-art models on 300W dataseton Pose estimation task: |
|
 |
|
|
|
|
|
Following are some samples in order to show the visual performance of ASMNet on 300W and WFLW datasets: |
|
 |
|
 |
|
|
|
The visual performance of Pose estimation task using ASMNet is very accurate and the results also are much better than the state-of-the-art pose estimation over 300W dataset: |
|
|
|
 |
|
|
|
|
|
---------------------------------------------------------------------------------------------------------------------------------- |
|
## Installing the requirements |
|
In order to run the code you need to install python >= 3.5. |
|
The requirements and the libraries needed to run the code can be installed using the following command: |
|
|
|
``` |
|
pip install -r requirements.txt |
|
``` |
|
|
|
|
|
## Using the pre-trained models |
|
You can test and use the preetrained models using the following codes which are available in the following file: |
|
https://github.com/aliprf/ASMNet/blob/master/main.py |
|
|
|
``` |
|
tester = Test() |
|
tester.test_model(ds_name=DatasetName.w300, |
|
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5') |
|
``` |
|
|
|
|
|
## Training Network from scratch |
|
|
|
|
|
### Preparing Data |
|
Data needs to be normalized and saved in npy format. |
|
|
|
### PCA creation |
|
you can you the pca_utility.py class to create the eigenvalues, eigenvectors, and the meanvector: |
|
``` |
|
pca_calc = PCAUtility() |
|
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300, |
|
labels_npy_path='./data/w300/normalized_labels/', |
|
pca_percentages=90) |
|
``` |
|
### Training |
|
The training implementation is located in train.py class. You can use the following code to start the training: |
|
|
|
``` |
|
trainer = Train(arch=ModelArch.ASMNet, |
|
dataset_name=DatasetName.w300, |
|
save_path='./', |
|
asm_accuracy=90) |
|
``` |
|
|
|
|
|
Please cite this work as: |
|
|
|
@inproceedings{fard2021asmnet, |
|
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation}, |
|
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad}, |
|
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, |
|
pages={1521--1530}, |
|
year={2021} |
|
} |
|
|
|
```diff |
|
@@plaese STAR the repo if you like it.@@ |
|
``` |
|
|
