
CLIPSeg
Overview
The CLIPSeg model was proposed in Image Segmentation Using Text and Image Prompts by Timo Lüddecke and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen CLIP model for zero- and one-shot image segmentation.
The abstract from the paper is the following:
Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties
Tips:
- [
CLIPSegForImageSegmentation] adds a decoder on top of [CLIPSegModel]. The latter is identical to [CLIPModel]. - [
CLIPSegForImageSegmentation] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text (provided to the model asinput_ids) or an image (provided to the model asconditional_pixel_values). One can also provide custom conditional embeddings (provided to the model asconditional_embeddings).
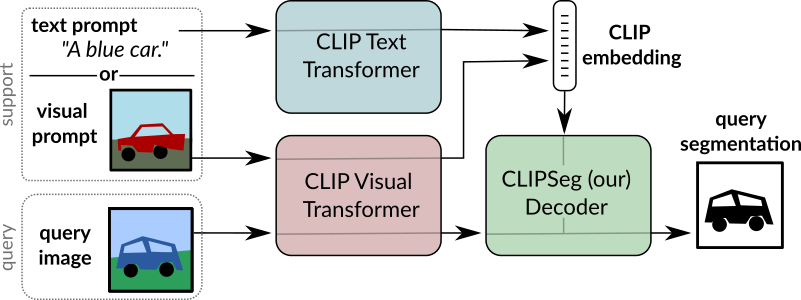
CLIPSeg overview. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook that illustrates zero-shot image segmentation with CLIPSeg.
CLIPSegConfig
[[autodoc]] CLIPSegConfig - from_text_vision_configs
CLIPSegTextConfig
[[autodoc]] CLIPSegTextConfig
CLIPSegVisionConfig
[[autodoc]] CLIPSegVisionConfig
CLIPSegProcessor
[[autodoc]] CLIPSegProcessor
CLIPSegModel
[[autodoc]] CLIPSegModel - forward - get_text_features - get_image_features
CLIPSegTextModel
[[autodoc]] CLIPSegTextModel - forward
CLIPSegVisionModel
[[autodoc]] CLIPSegVisionModel - forward
CLIPSegForImageSegmentation
[[autodoc]] CLIPSegForImageSegmentation - forward