
model-index:
- name: TaxoLLaMA-bench
results: []
license: cc-by-sa-4.0
language:
- en
- es
- it
base_model: meta-llama/Llama-2-7b-hf
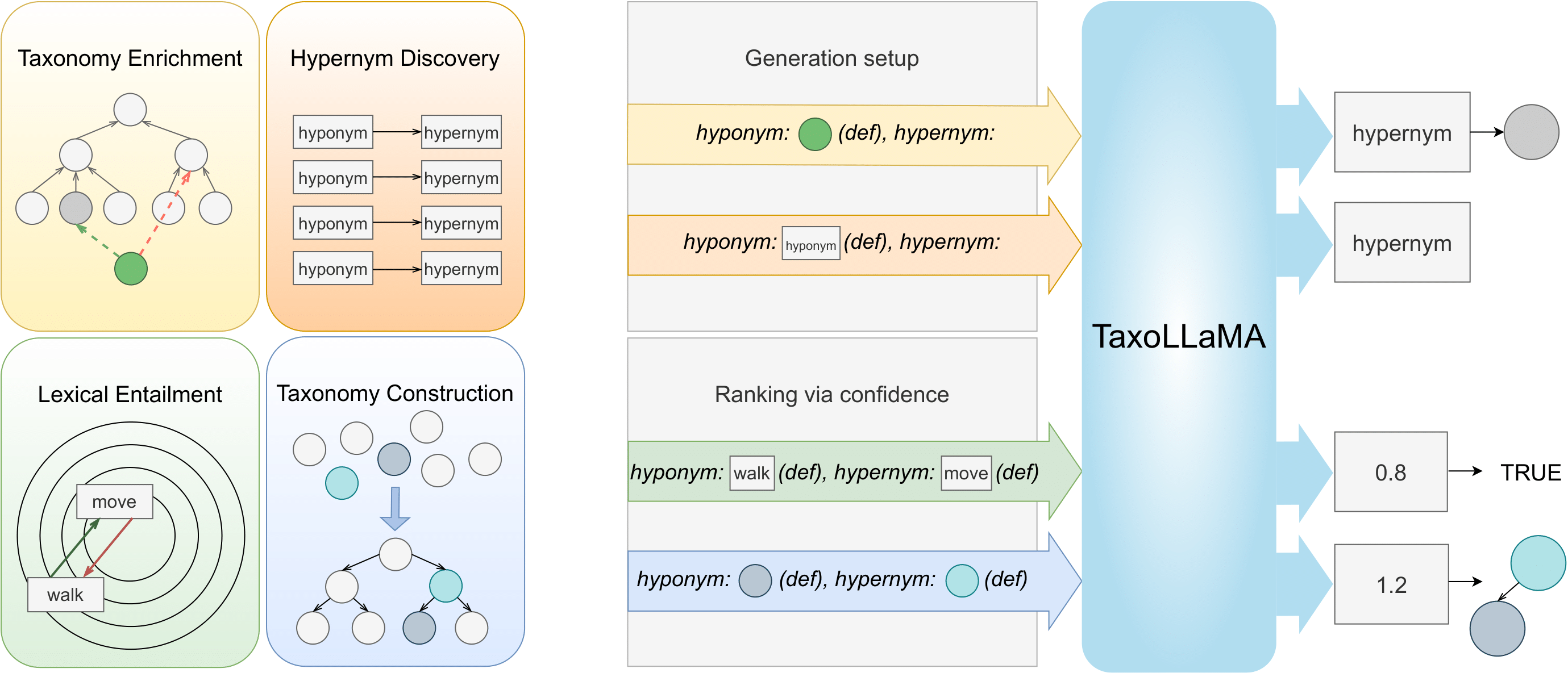
Model Card for TaxoLLaMA-bench
TaxoLLaMA-bench is a lightweight fine-tune of LLaMA2-7b model, aimed at solving multiple Lexical Semantics task with focus on Taxonomy related tasks, achieving SoTA results on multiple benchmarks. It was pretrained with instructive dataset, collected from WordNet 3.0 to generate hypernyms for a given hyponym. This model also could be used for identifying hypernymy with perplexity, that is useful for Lexical Entailment or Taxonomy Construction.
[!TIP] It was not pretrained on the data used in later benchmarks from the paper. This model should be use to replicate results on Taxonomy test datasets or to boost them. For other task we strongly recommend using TaxoLLaMA
For more details, read paper: TaxoLLaMA: WordNet-based Model for Solving Multiple Lexical Sematic Tasks
Model description
- Finetuned from model: meta-llama/Llama-2-7b-hf
- Language(s) (NLP): Primarily English, but could be easily extended to other languages. Achieves SoTA also for Spanish and Italian
Model Sources
- Repository: https://github.com/VityaVitalich/TaxoLLaMA
- Instruction Set: TBD
Performance
| Model | Hypernym Discovery (Eng., MRR) | Hypernym Discovery (Span., MRR) | Taxonomy Construction (Enivornment, F1) | Taxonomy Enrichment (WordNet Verb, MRR) |
|---|---|---|---|---|
| TaxoLLaMA | 54.39 | 58.61 | 45.13 | 52.4 |
| TaxoLLaMA-bench | 51.39 | 57.44 | 44.82 | 51.9 |
| Previous SoTA | 45.22 | 37.56 | 40.00 | 45.2 |
Input Format
The model is trained to use the following format :
<s>[INST] <<SYS>> You are a helpfull assistant. List all the possible words divided with a coma. Your answer should not include anything except the words divided by a coma<</SYS>>
hyponym: tiger (large feline of forests in most of Asia having a tawny coat with black stripes)| hypernyms: [/INST]
Training hyperparameters
The following hyperparameters were used for instruction tuning:
- learning_rate: 3e-04
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-09
- lr_scheduler_type: CosineAnnealing
- num_epochs: 1.0
Usage Example
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import PeftConfig, PeftModel
torch.set_default_device('cuda')
config = PeftConfig.from_pretrained('VityaVitalich/TaxoLLaMA-bench')
# Do not forget your token for Llama2 models
model = LlamaForCausalLM.from_pretrained(config.base_model_name_or_path, load_in_4bit=True, torch_dtype=torch.bfloat16)
tokenizer = LlamaTokenizer.from_pretrained(config.base_model_name_or_path)
inference_model = PeftModel.from_pretrained(model, 'VityaVitalich/TaxoLLaMA-bench'')
processed_term = 'hyponym: tiger | hypernyms:'
system_prompt = """<s>[INST] <<SYS>> You are a helpfull assistant. List all the possible words divided with a coma. Your answer should not include anything except the words divided by a coma<</SYS>>"""
processed_term = system_prompt + '\n' + processed_term + '[/INST]'
input_ids = tokenizer(processed_term, return_tensors='pt')
# This is an example of generation hyperparameters, they could be modified to fit your task
gen_conf = {
"no_repeat_ngram_size": 3,
"do_sample": True,
"num_beams": 8,
"num_return_sequences": 2,
"max_new_tokens": 32,
"top_k": 20,
}
out = inference_model.generate(inputs=input_ids['input_ids'].to('cuda'), **gen_conf)
text = tokenizer.batch_decode(out)[0][len(system_prompt):]
print(text)
Citation
If you find TaxoLLaMA is useful in your work, please cite it with:
TBD