

license: apache-2.0
datasets:
- daily_dialog
language:
- en
pipeline_tag: text-retrieval
![]()
🏗️ GitHub repo | 📃 Paper
triple-encoders are models for contextualizing distributed Sentence Transformers representations. This model was trained on the DailyDialog dataset and can be used for conversational sequence modeling and short-term planning via sequential modular late-interaction:
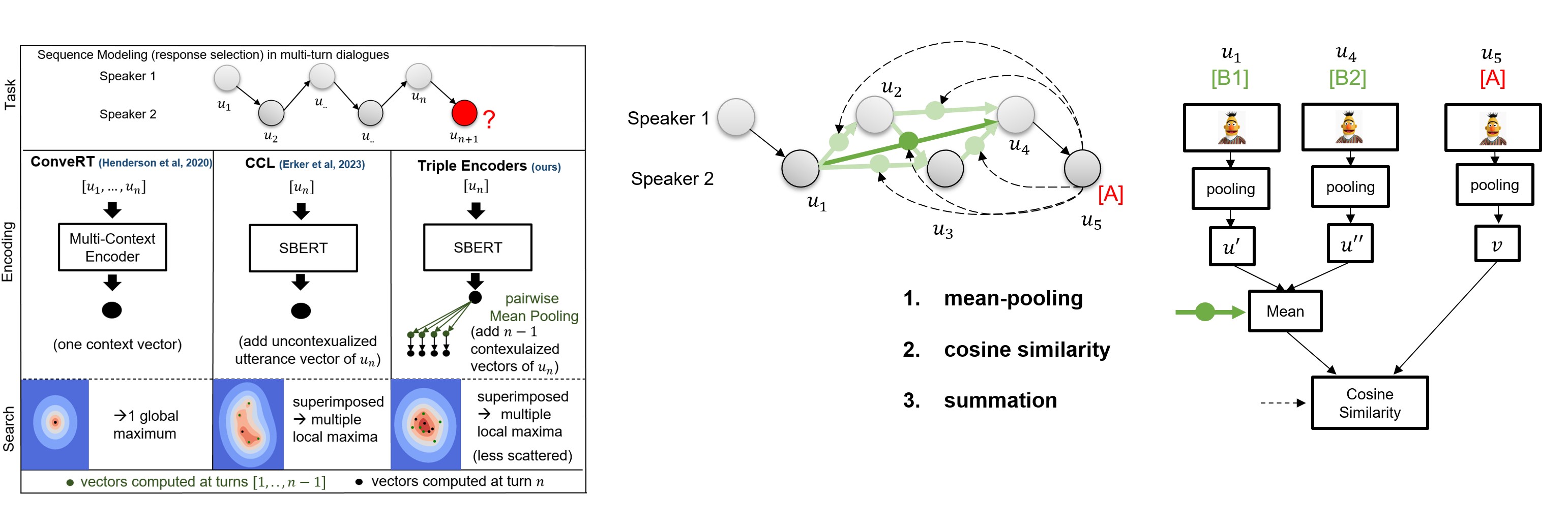
Representations are encoded separately and the contextualization is weightless:
- mean-pooling to pairwise contextualize sentence representations (creates a distributed query)
- cosine similarity to measure the similarity between all query vectors and the retrieval candidates.
- summation to aggregate the similarity (similar to average-based late interaction of ColBERT).
Key Features
- 1️⃣ One dense vector vs distributed dense vectors: in our paper we demonstrate that our late interaction-based approach outperforms single-vector representations on long sequences, including zero-shot settings.
- 🏎️💨 Relative compute: as every representation is encoded separately, you only need to encode, compute mixtures and similarities for the latest added representation (in dialog: the latest utterance).
- 📚 No Limit on context-length: our distributed sentence transformer architecture is not limited to any sequence length. You can use your entire sequence as query!
- 🌎 Multilingual support:
triple-encoderscan be used with any Sentence Transformers model. This means that you can model multilingual sequences by simply training on a multilingual model checkpoint.
Installation
You can install triple-encoders via pip:
pip install triple-encoders
Note that triple-encoders requires Python 3.6 or higher.
Getting Started
Our experiments for sequence modeling and short-term planning conducted in the paper can be found in the notebooks folder. The hyperparameter that we used for training are the default parameters in the trainer.py file.
Retrieval-based Sequence Modeling
We provide an example of how to use triple-encoders for conversational sequence modeling (response selection) with 2 dialog speakers. If you want to use triple-encoders for other sequence modeling tasks, you can use the TripleEncodersForSequenceModeling class.
Loading the model
from triple_encoders.TripleEncodersForConversationalSequenceModeling import TripleEncodersForConversationalSequenceModeling
triple_path = 'UKPLab/triple-encoders-dailydialog'
# load model
model = TripleEncodersForConversationalSequenceModeling(triple_path)
Inference
# load candidates for response selection
candidates = ['I am doing great too!','Where did you go?', 'ACL is an interesting conference']
# load candidates and store index
model.load_candidates_from_strings(candidates, output_directory_candidates_dump='output/path/to/save/candidates')
# create a sequence
sequence = model.contextualize_sequence(["Hi!",'Hey, how are you?'], k_last_rows=2)
# model sequence (compute scores for candidates)
sequence = model.sequence_modeling(sequence)
# retrieve utterance from dialog partner
new_utterance = "I'm fine, thanks. How are you?"
# pass it to the model with dialog_partner=True
sequence = model.contextualize_utterance(new_utterance, sequence, dialog_partner=True)
# model sequence (compute scores for candidates)
sequence = model.sequence_modeling(sequence)
# retrieve candidates to provide a response
response = model.retrieve_candidates(sequence, 3)
response
#(['I am doing great too!','Where did you go?', 'ACL is an interesting conference'],
# tensor([0.4944, 0.2392, 0.0483]))
Speed:
- Time to load candidates: 31.815 ms
- Time to contextualize sequence: 18.078 ms
- Time to model sequence: 0.256 ms
- Time to contextualize new utterance: 15.858 ms
- Time to model new utterance: 0.213 ms
- Time to retrieve candidates: 0.093 ms
Evaluation
from datasets import load_dataset
dataset = load_dataset("daily_dialog")
test = dataset['test']['dialog']
df = model.evaluate_seq_dataset(test, k_last_rows=2)
df
# pandas dataframe with the average rank for each history length
Short-Term Planning (STP)
Short-term planning enables you to re-rank candidate replies from LLMs to reach a goal utterance over multiple turns.
Inference
from triple_encoders.TripleEncodersForSTP import TripleEncodersForSTP
model = TripleEncodersForSTP(triple_path)
context = ['Hey, how are you ?',
'I am good, how about you ?',
'I am good too.']
candidates = ['Want to eat something out ?',
'Want to go for a walk ?']
goal = ' I am hungry.'
result = model.short_term_planning(candidates, goal, context)
result
# 'Want to eat something out ?'
Evaluation
from datasets import load_dataset
from triple_encoders.TripleEncodersForSTP import TripleEncodersForSTP
dataset = load_dataset("daily_dialog")
test = dataset['test']['dialog']
model = TripleEncodersForSTP(triple_path, llm_model_name_or_path='your favorite large language model')
df = model.evaluate_stp_dataset(test)
# pandas dataframe with the average rank and Hits@k for each history length, goal_distance
Training Triple Encoders
You can train your own triple encoders with Contextualized Curved Contrastive Learning (C3L) using our trainer.
The hyperparameters that we used for training are the default parameters in the trainer.py file.
Note that we pre-trained our best model with Curved Contrastive Learning (CCL) (from imaginaryNLP) before training with C3L.
from triple_encoders.trainer import TripleEncoderTrainer
from datasets import load_dataset
dataset = load_dataset("daily_dialog")
trainer = TripleEncoderTrainer(base_model_name_or_path=,
batch_size=48,
observation_window=5,
speaker_token=True, # used for conversational sequence modeling
num_epochs=3,
warmup_steps=10000)
trainer.generate_datasets(
dataset["train"]["dialog"],
dataset["validation"]["dialog"],
dataset["test"]["dialog"],
)
trainer.train("output/path/to/save/model")
Citation
If you use triple-encoders in your research, please cite the following paper:
@misc{erker2024tripleencoders,
title={Triple-Encoders: Representations That Fire Together, Wire Together},
author={Justus-Jonas Erker and Florian Mai and Nils Reimers and Gerasimos Spanakis and Iryna Gurevych},
year={2024},
eprint={2402.12332},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Contact
Contact person: Justus-Jonas Erker, justus-jonas.erker@tu-darmstadt.de
https://www.ukp.tu-darmstadt.de/
Don't hesitate to send us an e-mail or report an issue, if something is broken (and it shouldn't be) or if you have further questions. This repository contains experimental software and is published for the sole purpose of giving additional background details on the respective publication.
License
triple-encoders is licensed under the Apache License, Version 2.0. See LICENSE for the full license text.
Acknowledgement
our package is based upon the imaginaryNLP and Sentence Transformers.