

Upload 9 files
Browse files- README.md +79 -0
- assets/leaderboard.png +0 -0
- config.json +28 -0
- generation_config.json +9 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +24 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +35 -0
README.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
- zh
|
| 5 |
+
library_name: transformers
|
| 6 |
+
tags:
|
| 7 |
+
- Long Context
|
| 8 |
+
- chatglm
|
| 9 |
+
- llama
|
| 10 |
+
datasets:
|
| 11 |
+
- THUDM/LongAlign-10k
|
| 12 |
+
- THUDM/LongBench
|
| 13 |
+
---
|
| 14 |
+
# LongAlign-13B-64k
|
| 15 |
+
|
| 16 |
+
<p align="center">
|
| 17 |
+
🤗 <a href="https://huggingface.co/datasets/THUDM/LongAlign-10k" target="_blank">[LongAlign Dataset] </a> • 💻 <a href="https://github.com/THUDM/LongAlign" target="_blank">[Github Repo]</a> • 📃 <a href="https://arxiv.org/" target="_blank">[LongAlign Paper]</a>
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
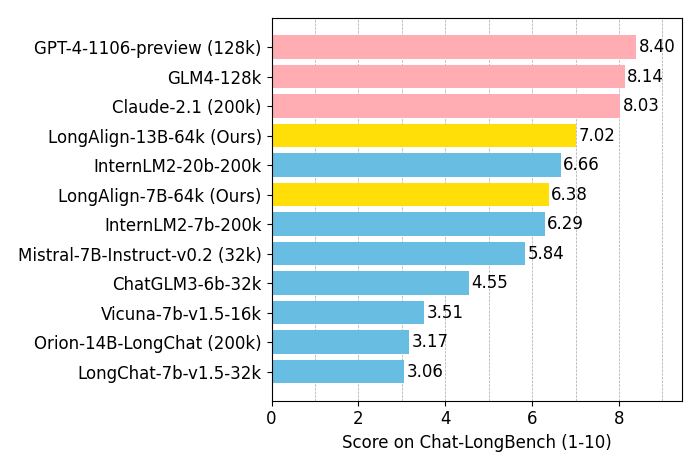
**LongAlign** is the first full recipe for LLM alignment on long context. We propose the **LongAlign-10k** dataset, containing 10,000 long instruction data of 8k-64k in length. We investigate on trianing strategies, namely **packing (with loss weighting) and sorted batching**, which are all implemented in our code. For real-world long context evaluation, we introduce **Chat-LongBench** that evaluate the instruction-following capability on queries of 10k-100k length.
|
| 21 |
+
|
| 22 |
+
## All Models
|
| 23 |
+
|
| 24 |
+
We open-sourced the following list of models:
|
| 25 |
+
|
| 26 |
+
|Model|Huggingface Repo|Description|
|
| 27 |
+
|---|---|---|
|
| 28 |
+
|**LongAlign-6B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-6B-64k-base) | **ChatGLM3-6B** with an extended 64k context window |
|
| 29 |
+
|**LongAlign-6B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-6B-64k) | Chat model by LongAlign training on LongAlign-6B-64k-base|
|
| 30 |
+
|**LongAlign-7B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-7B-64k-base) | **Llama-2-7B** with an extended 64k context window |
|
| 31 |
+
|**LongAlign-7B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-7B-64k) | Chat model by LongAlign training on LongAlign-7B-64k-base|
|
| 32 |
+
|**LongAlign-13B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-13B-64k-base) | **Llama-2-13B** with an extended 64k context window |
|
| 33 |
+
|**LongAlign-13B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-13B-64k) | Chat model by LongAlign training on LongAlign-13B-64k-base|
|
| 34 |
+
|**ChatGLM3-6B-128k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/chatglm3-6b-128k) | **ChatGLM3-6B** with a 128k context window|
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
## Model usage
|
| 39 |
+
Chat prompt template for LongAlign-6B-64k:
|
| 40 |
+
```text
|
| 41 |
+
[Round 1]
|
| 42 |
+
|
| 43 |
+
问:Hi!
|
| 44 |
+
|
| 45 |
+
答:Hello! What can I assist you today?
|
| 46 |
+
|
| 47 |
+
[Round 2]
|
| 48 |
+
|
| 49 |
+
问:What should I do if I can't sleep at night?
|
| 50 |
+
|
| 51 |
+
答:
|
| 52 |
+
```
|
| 53 |
+
Chat prompt template for LongAlign-7B-64k and LongAlign-13B-64k:
|
| 54 |
+
```text
|
| 55 |
+
[INST]Hi![/INST]Hello! What can I assist you today?
|
| 56 |
+
|
| 57 |
+
[INST]What should I do if I can't sleep at night?[/INST]
|
| 58 |
+
```
|
| 59 |
+
ChatGLM3-6B-128k uses the same prompt template as [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b).
|
| 60 |
+
|
| 61 |
+
A simple demo for deployment of the model:
|
| 62 |
+
```python
|
| 63 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 64 |
+
import torch
|
| 65 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/LongAlign-6B-64k", trust_remote_code=True)
|
| 66 |
+
model = AutoModelForCausalLM.from_pretrained("THUDM/LongAlign-6B-64k", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
|
| 67 |
+
model = model.eval()
|
| 68 |
+
query = open("assets/paper.txt").read() + "\n\nPlease summarize the paper."
|
| 69 |
+
response, history = model.chat(tokenizer, query, history=[], max_new_tokens=512, temperature=1)
|
| 70 |
+
print(response)
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## Citation
|
| 74 |
+
|
| 75 |
+
If you find our work useful, please consider citing LongAlign:
|
| 76 |
+
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
```
|
assets/leaderboard.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/mnt/vepfs/users/bys/fix_models/Llama-2-13b-64k-LongAlign-sort",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaModel"
|
| 5 |
+
],
|
| 6 |
+
"bos_token_id": 1,
|
| 7 |
+
"eos_token_id": 2,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 5120,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 13824,
|
| 12 |
+
"max_position_embeddings": 65536,
|
| 13 |
+
"max_sequence_length": 65536,
|
| 14 |
+
"model_type": "llama",
|
| 15 |
+
"num_attention_heads": 40,
|
| 16 |
+
"num_hidden_layers": 40,
|
| 17 |
+
"num_key_value_heads": 40,
|
| 18 |
+
"pad_token_id": 0,
|
| 19 |
+
"pretraining_tp": 1,
|
| 20 |
+
"rms_norm_eps": 1e-05,
|
| 21 |
+
"rope_scaling": null,
|
| 22 |
+
"rope_theta": 2000000.0,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"torch_dtype": "bfloat16",
|
| 25 |
+
"transformers_version": "4.33.0",
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"vocab_size": 32256
|
| 28 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 1,
|
| 3 |
+
"eos_token_id": 2,
|
| 4 |
+
"max_length": 65536,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"temperature": 0.9,
|
| 7 |
+
"top_p": 0.6,
|
| 8 |
+
"transformers_version": "4.31.0"
|
| 9 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4192e7498758c3aafd74f4f68748f1bf11cd83016134ed6dd1c8e5fd3e91578
|
| 3 |
+
size 26037067133
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<unk>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": false,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "</s>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"legacy": false,
|
| 22 |
+
"model_max_length": 65536,
|
| 23 |
+
"pad_token": null,
|
| 24 |
+
"padding_side": "right",
|
| 25 |
+
"sp_model_kwargs": {},
|
| 26 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 27 |
+
"unk_token": {
|
| 28 |
+
"__type": "AddedToken",
|
| 29 |
+
"content": "<unk>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false
|
| 34 |
+
}
|
| 35 |
+
}
|