
Upload 22 files
Browse files- README.md +96 -3
- neo_sft_phase2_conversations/adapter_config.json +34 -0
- neo_sft_phase2_conversations/adapter_model.safetensors +3 -0
- neo_sft_phase2_conversations/added_tokens.json +5 -0
- neo_sft_phase2_conversations/special_tokens_map.json +20 -0
- neo_sft_phase2_conversations/tokenizer_config.json +44 -0
- neo_sft_phase2_conversations/training_loss.png +0 -0
- neo_sft_phase2_conversations/vocab.json +0 -0
- neo_sft_phase2_multi/adapter_config.json +34 -0
- neo_sft_phase2_multi/adapter_model.safetensors +3 -0
- neo_sft_phase2_multi/added_tokens.json +5 -0
- neo_sft_phase2_multi/special_tokens_map.json +20 -0
- neo_sft_phase2_multi/tokenizer_config.json +44 -0
- neo_sft_phase2_multi/training_loss.png +0 -0
- neo_sft_phase2_multi/vocab.json +0 -0
- neo_sft_phase2_single/adapter_config.json +34 -0
- neo_sft_phase2_single/adapter_model.safetensors +3 -0
- neo_sft_phase2_single/added_tokens.json +5 -0
- neo_sft_phase2_single/special_tokens_map.json +20 -0
- neo_sft_phase2_single/tokenizer_config.json +44 -0
- neo_sft_phase2_single/training_loss.png +0 -0
- neo_sft_phase2_single/vocab.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,96 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### 数据集
|
| 2 |
+
|
| 3 |
+
以 m-a-p/neo_sft_phase2 数据集为基石,精心构建了三个子数据集,分别如下:
|
| 4 |
+
|
| 5 |
+
1. REILX/neo_sft_phase2_conversations
|
| 6 |
+
2. REILX/neo_sft_phase2_multi
|
| 7 |
+
3. REILX/neo_sft_phase2_single
|
| 8 |
+
|
| 9 |
+
### 数据集构建规则
|
| 10 |
+
|
| 11 |
+
**REILX/neo_sft_phase2_conversations**
|
| 12 |
+
|
| 13 |
+
* **方法:** 将每轮对话视作独立的问答对,并巧妙融入上下文信息构建样本。
|
| 14 |
+
* **具体步骤:**
|
| 15 |
+
1. 针对每个“conversation”,逐一遍历其对话轮次。
|
| 16 |
+
2. 将当前“human”轮次的“value”与之前所有轮次的对话内容熔炼一体,构成完整的“instruction”。
|
| 17 |
+
3. 将当前“gpt”轮次的“value”作为最终的“output”。
|
| 18 |
+
4. “input”可为空白,亦可注入适当的提示信息。
|
| 19 |
+
|
| 20 |
+
**REILX/neo_sft_phase2_multi**
|
| 21 |
+
|
| 22 |
+
* **方法:** 将每轮对话视作独立的问答对,并巧妙利用上下文信息构建样本。
|
| 23 |
+
* **具体步骤:**
|
| 24 |
+
1. 针对每个“conversation”,逐一遍历其对话轮次。
|
| 25 |
+
2. 将每个“conversation”中所有“human”的“value”汇聚一堂,构成完整的“instruction”。
|
| 26 |
+
3. 将每个“conversation”中所有“gpt”的“value”汇聚一堂,构成最终的“output”。
|
| 27 |
+
4. “input”可为空白,亦可注入适当的提示信息。
|
| 28 |
+
|
| 29 |
+
**REILX/neo_sft_phase2_single**
|
| 30 |
+
|
| 31 |
+
* **具体步骤:**
|
| 32 |
+
1. 针对每个“conversation”,逐一遍历其对话轮次。
|
| 33 |
+
2. 仅保留包含一轮对话的“conversation”,舍弃多轮对话数据。
|
| 34 |
+
3. 将该“conversation”的“human”的“value”作为“instruction”。
|
| 35 |
+
4. 将该“conversation”的“gpt”的“value”作为“output”。
|
| 36 |
+
5. “input”可为空白,亦可注入适当的提示信息。
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
### 训练参数
|
| 40 |
+
REILX/neo_sft_phase2_conversations</br>
|
| 41 |
+
- learning_rate: 5e-06
|
| 42 |
+
- train_batch_size: 1
|
| 43 |
+
- eval_batch_size: 8
|
| 44 |
+
- seed: 42
|
| 45 |
+
- distributed_type: multi-GPU
|
| 46 |
+
- num_devices: 8
|
| 47 |
+
- gradient_accumulation_steps: 8
|
| 48 |
+
- total_train_batch_size: 64
|
| 49 |
+
- total_eval_batch_size: 64
|
| 50 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 51 |
+
- lr_scheduler_type: cosine
|
| 52 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 53 |
+
- num_epochs: 5.0
|
| 54 |
+
|
| 55 |
+
REILX/neo_sft_phase2_multi</br>
|
| 56 |
+
- learning_rate: 5e-05
|
| 57 |
+
- train_batch_size: 1
|
| 58 |
+
- eval_batch_size: 8
|
| 59 |
+
- seed: 42
|
| 60 |
+
- distributed_type: multi-GPU
|
| 61 |
+
- num_devices: 8
|
| 62 |
+
- gradient_accumulation_steps: 8
|
| 63 |
+
- total_train_batch_size: 64
|
| 64 |
+
- total_eval_batch_size: 64
|
| 65 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 66 |
+
- lr_scheduler_type: cosine
|
| 67 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 68 |
+
- num_epochs: 5.0
|
| 69 |
+
|
| 70 |
+
REILX/neo_sft_phase2_single</br>
|
| 71 |
+
- learning_rate: 5e-05
|
| 72 |
+
- train_batch_size: 1
|
| 73 |
+
- eval_batch_size: 8
|
| 74 |
+
- seed: 42
|
| 75 |
+
- distributed_type: multi-GPU
|
| 76 |
+
- num_devices: 8
|
| 77 |
+
- gradient_accumulation_steps: 8
|
| 78 |
+
- total_train_batch_size: 64
|
| 79 |
+
- total_eval_batch_size: 64
|
| 80 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 81 |
+
- lr_scheduler_type: cosine
|
| 82 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 83 |
+
- num_epochs: 5.0
|
| 84 |
+
|
| 85 |
+
### 损失图
|
| 86 |
+
REILX/neo_sft_phase2_conversations</br>
|
| 87 |
+
<!--  -->
|
| 88 |
+
<img src="./neo_sft_phase2_conversations/training_loss.png" alt="neo_sft_phase2_conversations_loss" width="30%">
|
| 89 |
+
|
| 90 |
+
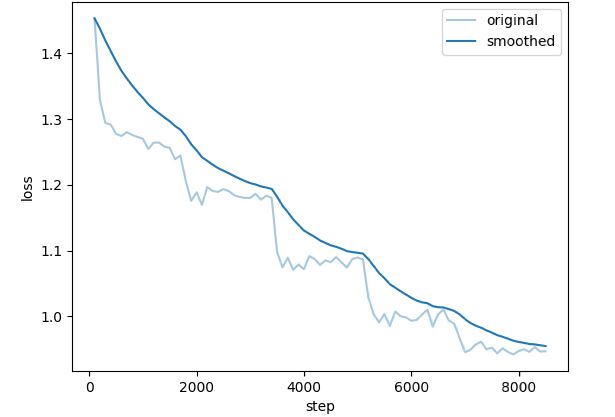
REILX/neo_sft_phase2_multi</br>
|
| 91 |
+
<!--  -->
|
| 92 |
+
<img src="./neo_sft_phase2_multi/training_loss.png" alt="neo_sft_phase2_multi_loss" width="30%">
|
| 93 |
+
|
| 94 |
+
REILX/neo_sft_phase2_single</br>
|
| 95 |
+
<!--  -->
|
| 96 |
+
<img src="./neo_sft_phase2_single/training_loss.png" alt="neo_sft_phase2_single_loss" width="30%">
|
neo_sft_phase2_conversations/adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "/home/models/qwen2/Qwen2-7B-Instruct/",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 32,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 16,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"v_proj",
|
| 24 |
+
"down_proj",
|
| 25 |
+
"o_proj",
|
| 26 |
+
"up_proj",
|
| 27 |
+
"q_proj",
|
| 28 |
+
"gate_proj",
|
| 29 |
+
"k_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
neo_sft_phase2_conversations/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ac43512bcc20693ef700ee74032649603e9566ca30e3a8a840cb43fd7c013836
|
| 3 |
+
size 80792880
|
neo_sft_phase2_conversations/added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|im_end|>": 151645,
|
| 4 |
+
"<|im_start|>": 151644
|
| 5 |
+
}
|
neo_sft_phase2_conversations/special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|im_end|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
neo_sft_phase2_conversations/tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message + '\\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ 'Human: ' + content + '\\nAssistant: ' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 131072,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
neo_sft_phase2_conversations/training_loss.png
ADDED

|
neo_sft_phase2_conversations/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
neo_sft_phase2_multi/adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "/home/models/qwen2/Qwen2-7B-Instruct/",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 32,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 16,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"up_proj",
|
| 24 |
+
"o_proj",
|
| 25 |
+
"v_proj",
|
| 26 |
+
"k_proj",
|
| 27 |
+
"down_proj",
|
| 28 |
+
"gate_proj",
|
| 29 |
+
"q_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
neo_sft_phase2_multi/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f38d7bb017c3b635a40de05ccb6ab84088efa6ed6eda9809d9f9c8a5aefca1f4
|
| 3 |
+
size 80792880
|
neo_sft_phase2_multi/added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|im_end|>": 151645,
|
| 4 |
+
"<|im_start|>": 151644
|
| 5 |
+
}
|
neo_sft_phase2_multi/special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|im_end|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
neo_sft_phase2_multi/tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message + '\\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ 'Human: ' + content + '\\nAssistant: ' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 131072,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
neo_sft_phase2_multi/training_loss.png
ADDED
|
neo_sft_phase2_multi/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
neo_sft_phase2_single/adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "/home/models/qwen2/Qwen2-7B-Instruct/",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 32,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 16,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"gate_proj",
|
| 24 |
+
"o_proj",
|
| 25 |
+
"k_proj",
|
| 26 |
+
"down_proj",
|
| 27 |
+
"q_proj",
|
| 28 |
+
"v_proj",
|
| 29 |
+
"up_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
neo_sft_phase2_single/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f9a7aa48dff976b3777781839c87c88e7842ca1da408bcb62bf0885888fff95
|
| 3 |
+
size 80792880
|
neo_sft_phase2_single/added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|im_end|>": 151645,
|
| 4 |
+
"<|im_start|>": 151644
|
| 5 |
+
}
|
neo_sft_phase2_single/special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|im_end|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
neo_sft_phase2_single/tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message + '\\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ 'Human: ' + content + '\\nAssistant: ' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 131072,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
neo_sft_phase2_single/training_loss.png
ADDED

|
neo_sft_phase2_single/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|