

update
Browse files- .gitattributes +1 -0
- README.md +553 -0
- assets/.gitattributes +9 -0
- assets/demo.jpeg +0 -0
- assets/demo_highfive.jpeg +0 -0
- assets/logo.jpg +0 -0
- assets/radar.png +0 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
SimSun.ttf filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
SimSun.ttf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/apple.jpeg filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,553 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br>
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 5 |
+
<p>
|
| 6 |
+
<br>
|
| 7 |
+
|
| 8 |
+
<p align="center">
|
| 9 |
+
Qwen-VL <a href="https://modelscope.cn/models/qwen/Qwen-VL/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-VL">🤗</a>  | Qwen-VL-Chat <a href="https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-VL-Chat">🤗</a>  |  <a href="https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary">Demo</a>  |  <a href="https://github.com/QwenLM/Qwen-VL/blob/main/visual_memo.md">Report</a>   |   <a href="https://discord.gg/9bjvspyu">Discord</a>
|
| 10 |
+
|
| 11 |
+
</p>
|
| 12 |
+
<br>
|
| 13 |
+
|
| 14 |
+
<p align="center">
|
| 15 |
+
<a href="README_CN.md">中文</a>  |   English
|
| 16 |
+
</p>
|
| 17 |
+
<br><br>
|
| 18 |
+
|
| 19 |
+
**Qwen-VL** (Qwen Large Vision Language Model) is the visual multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box. The features of Qwen-VL include:
|
| 20 |
+
- **Strong performance**: It significantly surpasses existing open-source Large Vision Language Models (LVLM) under similar scale settings on multiple English evaluation benchmarks (including Zero-shot caption, VQA, DocVQA, and Grounding).
|
| 21 |
+
- **Multi-lingual LVLM support text recognization**: Qwen-VL naturally supports multi-lingual conversation, and it promotes end-to-end recognition of Chinese and English bi-lingual text in images.
|
| 22 |
+
- **Multi-image interleaved conversations**: This feature allows for the input and comparison of multiple images, as well as the ability to specify questions related to the images and engage in multi-image storytelling.
|
| 23 |
+
- **First generalist model support grounding in Chinese**: Detecting bounding boxes through open-domain language expression in both Chinese and English.
|
| 24 |
+
- **Fine-grained recognization and understanding**: Compared to the 224 resolution currently used by other open-source LVLM, the 448 resolution promotes fine-grained text recognition, document QA, and bounding box annotation.
|
| 25 |
+
|
| 26 |
+
We release two models of the Qwen-VL series:
|
| 27 |
+
- Qwen-VL: The pre-trained LVLM model uses Qwen-7B as the initialization of the LLM, and [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) as the initialization of the visual encoder. And connects them with a randomly initialized cross-attention layer. Qwen-VL was trained on about 1.5B image-text paired data. The final image input resolution is 448.
|
| 28 |
+
- Qwen-VL-Chat: A multimodal LLM-based AI assistant, which is trained with alignment techniques.
|
| 29 |
+
|
| 30 |
+
For more details about Qwen-VL, please refer to our [technical memo](visual_memo.md).
|
| 31 |
+
|
| 32 |
+
## Evaluation
|
| 33 |
+
|
| 34 |
+
We evaluated the model's ability from two perspectives:
|
| 35 |
+
1. **Standard Benchmarks**: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
|
| 36 |
+
- Zero-shot Caption: Evaluate model's zero-shot image captioning ability on unseen datasets;
|
| 37 |
+
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
|
| 38 |
+
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
|
| 39 |
+
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
|
| 40 |
+
|
| 41 |
+
2. **TouchStone**: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called TouchStone, which is based on scoring with GPT4 to evaluate the LVLM model.
|
| 42 |
+
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
|
| 43 |
+
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
|
| 44 |
+
- The benchmark includes both English and Chinese versions.
|
| 45 |
+
|
| 46 |
+
The results of the evaluation are as follows:
|
| 47 |
+
|
| 48 |
+
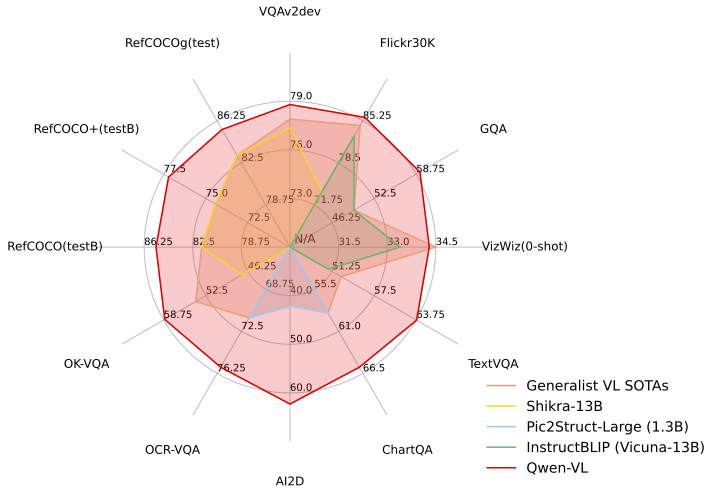
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
|
| 49 |
+
|
| 50 |
+
<p align="center">
|
| 51 |
+
<img src="assets/radar.png" width="600"/>
|
| 52 |
+
<p>
|
| 53 |
+
|
| 54 |
+
### Zero-shot Caption & General VQA
|
| 55 |
+
<table>
|
| 56 |
+
<thead>
|
| 57 |
+
<tr>
|
| 58 |
+
<th rowspan="2">Model type</th>
|
| 59 |
+
<th rowspan="2">Model</th>
|
| 60 |
+
<th colspan="2">Zero-shot Caption</th>
|
| 61 |
+
<th colspan="5">General VQA</th>
|
| 62 |
+
</tr>
|
| 63 |
+
<tr>
|
| 64 |
+
<th>NoCaps</th>
|
| 65 |
+
<th>Flickr30K</th>
|
| 66 |
+
<th>VQAv2<sup>dev</sup></th>
|
| 67 |
+
<th>OK-VQA</th>
|
| 68 |
+
<th>GQA</th>
|
| 69 |
+
<th>SciQA-Img<br>(0-shot)</th>
|
| 70 |
+
<th>VizWiz<br>(0-shot)</th>
|
| 71 |
+
</tr>
|
| 72 |
+
</thead>
|
| 73 |
+
<tbody align="center">
|
| 74 |
+
<tr>
|
| 75 |
+
<td rowspan="12">Generalist<br>Models</td>
|
| 76 |
+
<td>Flamingo-9B</td>
|
| 77 |
+
<td>-</td>
|
| 78 |
+
<td>61.5</td>
|
| 79 |
+
<td>51.8</td>
|
| 80 |
+
<td>44.7</td>
|
| 81 |
+
<td>-</td>
|
| 82 |
+
<td>-</td>
|
| 83 |
+
<td>28.8</td>
|
| 84 |
+
</tr>
|
| 85 |
+
<tr>
|
| 86 |
+
<td>Flamingo-80B</td>
|
| 87 |
+
<td>-</td>
|
| 88 |
+
<td>67.2</td>
|
| 89 |
+
<td>56.3</td>
|
| 90 |
+
<td>50.6</td>
|
| 91 |
+
<td>-</td>
|
| 92 |
+
<td>-</td>
|
| 93 |
+
<td>31.6</td>
|
| 94 |
+
</tr>
|
| 95 |
+
<tr>
|
| 96 |
+
<td>Unified-IO-XL</td>
|
| 97 |
+
<td>100.0</td>
|
| 98 |
+
<td>-</td>
|
| 99 |
+
<td>77.9</td>
|
| 100 |
+
<td>54.0</td>
|
| 101 |
+
<td>-</td>
|
| 102 |
+
<td>-</td>
|
| 103 |
+
<td>-</td>
|
| 104 |
+
</tr>
|
| 105 |
+
<tr>
|
| 106 |
+
<td>Kosmos-1</td>
|
| 107 |
+
<td>-</td>
|
| 108 |
+
<td>67.1</td>
|
| 109 |
+
<td>51.0</td>
|
| 110 |
+
<td>-</td>
|
| 111 |
+
<td>-</td>
|
| 112 |
+
<td>-</td>
|
| 113 |
+
<td>29.2</td>
|
| 114 |
+
</tr>
|
| 115 |
+
<tr>
|
| 116 |
+
<td>Kosmos-2</td>
|
| 117 |
+
<td>-</td>
|
| 118 |
+
<td>66.7</td>
|
| 119 |
+
<td>45.6</td>
|
| 120 |
+
<td>-</td>
|
| 121 |
+
<td>-</td>
|
| 122 |
+
<td>-</td>
|
| 123 |
+
<td>-</td>
|
| 124 |
+
</tr>
|
| 125 |
+
<tr>
|
| 126 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 127 |
+
<td>103.9</td>
|
| 128 |
+
<td>71.6</td>
|
| 129 |
+
<td>65.0</td>
|
| 130 |
+
<td>45.9</td>
|
| 131 |
+
<td>32.3</td>
|
| 132 |
+
<td>61.0</td>
|
| 133 |
+
<td>19.6</td>
|
| 134 |
+
</tr>
|
| 135 |
+
<tr>
|
| 136 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 137 |
+
<td><strong>121.9</strong></td>
|
| 138 |
+
<td>82.8</td>
|
| 139 |
+
<td>-</td>
|
| 140 |
+
<td>-</td>
|
| 141 |
+
<td>49.5</td>
|
| 142 |
+
<td>63.1</td>
|
| 143 |
+
<td>33.4</td>
|
| 144 |
+
</tr>
|
| 145 |
+
<tr>
|
| 146 |
+
<td>Shikra (Vicuna-13B)</td>
|
| 147 |
+
<td>-</td>
|
| 148 |
+
<td>73.9</td>
|
| 149 |
+
<td>77.36</td>
|
| 150 |
+
<td>47.16</td>
|
| 151 |
+
<td>-</td>
|
| 152 |
+
<td>-</td>
|
| 153 |
+
<td>-</td>
|
| 154 |
+
</tr>
|
| 155 |
+
<tr>
|
| 156 |
+
<td><strong>Qwen-VL (Qwen-7B)</strong></td>
|
| 157 |
+
<td>121.4</td>
|
| 158 |
+
<td><b>85.8</b></td>
|
| 159 |
+
<td><b>78.8</b></td>
|
| 160 |
+
<td><b>58.6</b></td>
|
| 161 |
+
<td><b>59.3</b></td>
|
| 162 |
+
<td><b>67.1</b></td>
|
| 163 |
+
<td><b>34.3</b></td>
|
| 164 |
+
</tr>
|
| 165 |
+
<tr>
|
| 166 |
+
<td>Qwen-VL (4-shot)</td>
|
| 167 |
+
<td>-</td>
|
| 168 |
+
<td>-</td>
|
| 169 |
+
<td>-</td>
|
| 170 |
+
<td>63.6</td>
|
| 171 |
+
<td>-</td>
|
| 172 |
+
<td>-</td>
|
| 173 |
+
<td>39.1</td>
|
| 174 |
+
</tr>
|
| 175 |
+
<tr>
|
| 176 |
+
<td>Qwen-VL-Chat</td>
|
| 177 |
+
<td>-</td>
|
| 178 |
+
<td>81.5</td>
|
| 179 |
+
<td>-</td>
|
| 180 |
+
<td>56.69</td>
|
| 181 |
+
<td>-</td>
|
| 182 |
+
<td>68.22</td>
|
| 183 |
+
<td>37.05</td>
|
| 184 |
+
</tr>
|
| 185 |
+
<tr>
|
| 186 |
+
<td>Qwen-VL-Chat (4-shot)</td>
|
| 187 |
+
<td>-</td>
|
| 188 |
+
<td>-</td>
|
| 189 |
+
<td>-</td>
|
| 190 |
+
<td>60.6</td>
|
| 191 |
+
<td>-</td>
|
| 192 |
+
<td>-</td>
|
| 193 |
+
<td>45.5</td>
|
| 194 |
+
</tr>
|
| 195 |
+
<tr>
|
| 196 |
+
<td>Previous SOTA<br>(Per Task Fine-tuning)</td>
|
| 197 |
+
<td>-</td>
|
| 198 |
+
<td>127.0<br>(PALI-17B)</td>
|
| 199 |
+
<td>84.5<br>(InstructBLIP<br>-FlanT5-XL)</td>
|
| 200 |
+
<td>86.1<br>(PALI-X<br>-55B)</td>
|
| 201 |
+
<td>66.1<br>(PALI-X<br>-55B)</td>
|
| 202 |
+
<td>72.1<br>(CFR)</td>
|
| 203 |
+
<td>92.53<br>(LLaVa+<br>GPT-4)</td>
|
| 204 |
+
<td>70.9<br>(PALI-X<br>-55B)</td>
|
| 205 |
+
</tr>
|
| 206 |
+
</tbody>
|
| 207 |
+
</table>
|
| 208 |
+
|
| 209 |
+
- For zero-shot image captioning, Qwen-VL achieves the **SOTA** on Flickr30K and competitive results on Nocaps with InstructBlip.
|
| 210 |
+
- For general VQA, Qwen-VL achieves the **SOTA** under the same generalist LVLM scale settings.
|
| 211 |
+
|
| 212 |
+
### Text-based VQA (focuse on text understanding capabilities in images)
|
| 213 |
+
|
| 214 |
+
<table>
|
| 215 |
+
<thead>
|
| 216 |
+
<tr>
|
| 217 |
+
<th>Model type</th>
|
| 218 |
+
<th>Model</th>
|
| 219 |
+
<th>TextVQA</th>
|
| 220 |
+
<th>DocVQA</th>
|
| 221 |
+
<th>ChartQA</th>
|
| 222 |
+
<th>AI2D</th>
|
| 223 |
+
<th>OCR-VQA</th>
|
| 224 |
+
</tr>
|
| 225 |
+
</thead>
|
| 226 |
+
<tbody align="center">
|
| 227 |
+
<tr>
|
| 228 |
+
<td rowspan="5">Generalist Models</td>
|
| 229 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 230 |
+
<td>42.4</td>
|
| 231 |
+
<td>-</td>
|
| 232 |
+
<td>-</td>
|
| 233 |
+
<td>-</td>
|
| 234 |
+
<td>-</td>
|
| 235 |
+
</tr>
|
| 236 |
+
<tr>
|
| 237 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 238 |
+
<td>50.7</td>
|
| 239 |
+
<td>-</td>
|
| 240 |
+
<td>-</td>
|
| 241 |
+
<td>-</td>
|
| 242 |
+
<td>-</td>
|
| 243 |
+
</tr>
|
| 244 |
+
<tr>
|
| 245 |
+
<td>mPLUG-DocOwl (LLaMA-7B)</td>
|
| 246 |
+
<td>52.6</td>
|
| 247 |
+
<td>62.2</td>
|
| 248 |
+
<td>57.4</td>
|
| 249 |
+
<td>-</td>
|
| 250 |
+
<td>-</td>
|
| 251 |
+
</tr>
|
| 252 |
+
<tr>
|
| 253 |
+
<td>Pic2Struct-Large (1.3B)</td>
|
| 254 |
+
<td>-</td>
|
| 255 |
+
<td><b>76.6</b></td>
|
| 256 |
+
<td>58.6</td>
|
| 257 |
+
<td>42.1</td>
|
| 258 |
+
<td>71.3</td>
|
| 259 |
+
</tr>
|
| 260 |
+
<tr>
|
| 261 |
+
<td>Qwen-VL (Qwen-7B)</td>
|
| 262 |
+
<td><b>63.8</b></td>
|
| 263 |
+
<td>65.1</td>
|
| 264 |
+
<td><b>65.7</b></td>
|
| 265 |
+
<td><b>62.3</b></td>
|
| 266 |
+
<td><b>75.7</b></td>
|
| 267 |
+
</tr>
|
| 268 |
+
<tr>
|
| 269 |
+
<td>Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 270 |
+
<td>PALI-X-55B (Single-task FT)<br>(Without OCR Pipeline)</td>
|
| 271 |
+
<td>71.44</td>
|
| 272 |
+
<td>80.0</td>
|
| 273 |
+
<td>70.0</td>
|
| 274 |
+
<td>81.2</td>
|
| 275 |
+
<td>75.0</td>
|
| 276 |
+
</tr>
|
| 277 |
+
</tbody>
|
| 278 |
+
</table>
|
| 279 |
+
|
| 280 |
+
- In text-related recognition/QA evaluation, Qwen-VL achieves the SOTA under the generalist LVLM scale settings.
|
| 281 |
+
- Resolution is important for several above evaluations. While most open-source LVLM models with 224 resolution are incapable of these evaluations or can only solve these by cutting images, Qwen-VL scales the resolution to 448 so that it can be evaluated end-to-end. Qwen-VL even outperforms Pic2Struct-Large models of 1024 resolution on some tasks.
|
| 282 |
+
|
| 283 |
+
### Referring Expression Comprehension
|
| 284 |
+
<table>
|
| 285 |
+
<thead>
|
| 286 |
+
<tr>
|
| 287 |
+
<th rowspan="2">Model type</th>
|
| 288 |
+
<th rowspan="2">Model</th>
|
| 289 |
+
<th colspan="3">RefCOCO</th>
|
| 290 |
+
<th colspan="3">RefCOCO+</th>
|
| 291 |
+
<th colspan="2">RefCOCOg</th>
|
| 292 |
+
<th>GRIT</th>
|
| 293 |
+
</tr>
|
| 294 |
+
<tr>
|
| 295 |
+
<th>val</th>
|
| 296 |
+
<th>test-A</th>
|
| 297 |
+
<th>test-B</th>
|
| 298 |
+
<th>val</th>
|
| 299 |
+
<th>test-A</th>
|
| 300 |
+
<th>test-B</th>
|
| 301 |
+
<th>val-u</th>
|
| 302 |
+
<th>test-u</th>
|
| 303 |
+
<th>refexp</th>
|
| 304 |
+
</tr>
|
| 305 |
+
</thead>
|
| 306 |
+
<tbody align="center">
|
| 307 |
+
<tr>
|
| 308 |
+
<td rowspan="8">Generalist Models</td>
|
| 309 |
+
<td>GPV-2</td>
|
| 310 |
+
<td>-</td>
|
| 311 |
+
<td>-</td>
|
| 312 |
+
<td>-</td>
|
| 313 |
+
<td>-</td>
|
| 314 |
+
<td>-</td>
|
| 315 |
+
<td>-</td>
|
| 316 |
+
<td>-</td>
|
| 317 |
+
<td>-</td>
|
| 318 |
+
<td>51.50</td>
|
| 319 |
+
</tr>
|
| 320 |
+
<tr>
|
| 321 |
+
<td>OFA-L*</td>
|
| 322 |
+
<td>79.96</td>
|
| 323 |
+
<td>83.67</td>
|
| 324 |
+
<td>76.39</td>
|
| 325 |
+
<td>68.29</td>
|
| 326 |
+
<td>76.00</td>
|
| 327 |
+
<td>61.75</td>
|
| 328 |
+
<td>67.57</td>
|
| 329 |
+
<td>67.58</td>
|
| 330 |
+
<td>61.70</td>
|
| 331 |
+
</tr>
|
| 332 |
+
<tr>
|
| 333 |
+
<td>Unified-IO</td>
|
| 334 |
+
<td>-</td>
|
| 335 |
+
<td>-</td>
|
| 336 |
+
<td>-</td>
|
| 337 |
+
<td>-</td>
|
| 338 |
+
<td>-</td>
|
| 339 |
+
<td>-</td>
|
| 340 |
+
<td>-</td>
|
| 341 |
+
<td>-</td>
|
| 342 |
+
<td><b>78.61</b></td>
|
| 343 |
+
</tr>
|
| 344 |
+
<tr>
|
| 345 |
+
<td>VisionLLM-H</td>
|
| 346 |
+
<td></td>
|
| 347 |
+
<td>86.70</td>
|
| 348 |
+
<td>-</td>
|
| 349 |
+
<td>-</td>
|
| 350 |
+
<td>-</td>
|
| 351 |
+
<td>-</td>
|
| 352 |
+
<td>-</td>
|
| 353 |
+
<td>-</td>
|
| 354 |
+
<td>-</td>
|
| 355 |
+
</tr>
|
| 356 |
+
<tr>
|
| 357 |
+
<td>Shikra-7B</td>
|
| 358 |
+
<td>87.01</td>
|
| 359 |
+
<td>90.61</td>
|
| 360 |
+
<td>80.24 </td>
|
| 361 |
+
<td>81.60</td>
|
| 362 |
+
<td>87.36</td>
|
| 363 |
+
<td>72.12</td>
|
| 364 |
+
<td>82.27</td>
|
| 365 |
+
<td>82.19</td>
|
| 366 |
+
<td>69.34</td>
|
| 367 |
+
</tr>
|
| 368 |
+
<tr>
|
| 369 |
+
<td>Shikra-13B</td>
|
| 370 |
+
<td>87.83 </td>
|
| 371 |
+
<td>91.11</td>
|
| 372 |
+
<td>81.81</td>
|
| 373 |
+
<td>82.89</td>
|
| 374 |
+
<td>87.79</td>
|
| 375 |
+
<td>74.41</td>
|
| 376 |
+
<td>82.64</td>
|
| 377 |
+
<td>83.16</td>
|
| 378 |
+
<td>69.03</td>
|
| 379 |
+
</tr>
|
| 380 |
+
<tr>
|
| 381 |
+
<td>Qwen-VL-7B</td>
|
| 382 |
+
<td><b>89.36</b></td>
|
| 383 |
+
<td>92.26</td>
|
| 384 |
+
<td><b>85.34</b></td>
|
| 385 |
+
<td><b>83.12</b></td>
|
| 386 |
+
<td>88.25</td>
|
| 387 |
+
<td><b>77.21</b></td>
|
| 388 |
+
<td><b>85.58</b></td>
|
| 389 |
+
<td><b>85.48</b></td>
|
| 390 |
+
<td>78.22</td>
|
| 391 |
+
</tr>
|
| 392 |
+
<tr>
|
| 393 |
+
<td>Qwen-VL-7B-Chat</td>
|
| 394 |
+
<td><b>88.55</b></td>
|
| 395 |
+
<td><b>92.27</b></td>
|
| 396 |
+
<td>84.51</td>
|
| 397 |
+
<td>82.82</td>
|
| 398 |
+
<td><b>88.59</b></td>
|
| 399 |
+
<td>-</td>
|
| 400 |
+
<td>-</td>
|
| 401 |
+
<td>-</td>
|
| 402 |
+
<td>-</td>
|
| 403 |
+
</tr>
|
| 404 |
+
<tr>
|
| 405 |
+
<td rowspan="3">Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 406 |
+
<td>G-DINO-L</td>
|
| 407 |
+
<td>90.56 </td>
|
| 408 |
+
<td>93.19</td>
|
| 409 |
+
<td>88.24</td>
|
| 410 |
+
<td>82.75</td>
|
| 411 |
+
<td>88.95</td>
|
| 412 |
+
<td>75.92</td>
|
| 413 |
+
<td>86.13</td>
|
| 414 |
+
<td>87.02</td>
|
| 415 |
+
<td>-</td>
|
| 416 |
+
</tr>
|
| 417 |
+
<tr>
|
| 418 |
+
<td>UNINEXT-H</td>
|
| 419 |
+
<td>92.64 </td>
|
| 420 |
+
<td>94.33</td>
|
| 421 |
+
<td>91.46</td>
|
| 422 |
+
<td>85.24</td>
|
| 423 |
+
<td>89.63</td>
|
| 424 |
+
<td>79.79</td>
|
| 425 |
+
<td>88.73</td>
|
| 426 |
+
<td>89.37</td>
|
| 427 |
+
<td>-</td>
|
| 428 |
+
</tr>
|
| 429 |
+
<tr>
|
| 430 |
+
<td>ONE-PEACE</td>
|
| 431 |
+
<td>92.58 </td>
|
| 432 |
+
<td>94.18</td>
|
| 433 |
+
<td>89.26</td>
|
| 434 |
+
<td>88.77</td>
|
| 435 |
+
<td>92.21</td>
|
| 436 |
+
<td>83.23</td>
|
| 437 |
+
<td>89.22</td>
|
| 438 |
+
<td>89.27</td>
|
| 439 |
+
<td>-</td>
|
| 440 |
+
</tr>
|
| 441 |
+
</tbody>
|
| 442 |
+
</table>
|
| 443 |
+
|
| 444 |
+
- Qwen-VL achieves the **SOTA** in all above referring expression comprehension benchmarks.
|
| 445 |
+
- Qwen-VL has not been trained on any Chinese grounding data, but it can still generalize to the Chinese Grounding tasks in a zero-shot way by training Chinese Caption data and English Grounding data.
|
| 446 |
+
|
| 447 |
+
We provide all of the above evaluation scripts for reproducing our experimental results. Please read [eval/EVALUATION.md](eval/EVALUATION.md) for more information.
|
| 448 |
+
|
| 449 |
+
### Chat evaluation
|
| 450 |
+
|
| 451 |
+
TouchStone is a benchmark based on scoring with GPT4 to evaluate the abilities of the LVLM model on text-image dialogue and alignment levels with humans. It covers a total of 300+ images, 800+ questions, and 27 categories, such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc. Please read [touchstone/README_CN.md](touchstone/README.md) for more information.
|
| 452 |
+
|
| 453 |
+
#### English evaluation
|
| 454 |
+
|
| 455 |
+
| Model | Score |
|
| 456 |
+
|---------------|-------|
|
| 457 |
+
| PandaGPT | 488.5 |
|
| 458 |
+
| MiniGPT4 | 531.7 |
|
| 459 |
+
| InstructBLIP | 552.4 |
|
| 460 |
+
| LLaMA-AdapterV2 | 590.1 |
|
| 461 |
+
| mPLUG-Owl | 605.4 |
|
| 462 |
+
| LLaVA | 602.7 |
|
| 463 |
+
| Qwen-VL-Chat | 645.2 |
|
| 464 |
+
|
| 465 |
+
#### Chinese evaluation
|
| 466 |
+
|
| 467 |
+
| Model | Score |
|
| 468 |
+
|---------------|-------|
|
| 469 |
+
| VisualGLM | 247.1 |
|
| 470 |
+
| Qwen-VL-Chat | 401.2 |
|
| 471 |
+
|
| 472 |
+
Qwen-VL-Chat has achieved the best results in both Chinese and English alignment evaluation.
|
| 473 |
+
|
| 474 |
+
## Requirements
|
| 475 |
+
|
| 476 |
+
* python 3.8 and above
|
| 477 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 478 |
+
* CUDA 11.4 and above are recommended (this is for GPU users)
|
| 479 |
+
|
| 480 |
+
## Quickstart
|
| 481 |
+
|
| 482 |
+
Below, we provide simple examples to show how to use Qwen-VL and Qwen-VL-Chat with 🤖 ModelScope and 🤗 Transformers.
|
| 483 |
+
|
| 484 |
+
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
|
| 485 |
+
|
| 486 |
+
```bash
|
| 487 |
+
pip install -r requirements.txt
|
| 488 |
+
```
|
| 489 |
+
|
| 490 |
+
Now you can start with ModelScope or Transformers. More usage aboue vision encoder, please refer to [FAQ](FAQ.md).
|
| 491 |
+
|
| 492 |
+
#### 🤗 Transformers
|
| 493 |
+
|
| 494 |
+
To use Qwen-VL-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
|
| 495 |
+
|
| 496 |
+
```python
|
| 497 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 498 |
+
from transformers.generation import GenerationConfig
|
| 499 |
+
import torch
|
| 500 |
+
torch.manual_seed(1234)
|
| 501 |
+
|
| 502 |
+
# Note: The default behavior now has injection attack prevention off.
|
| 503 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 504 |
+
|
| 505 |
+
# use bf16
|
| 506 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 507 |
+
# use fp16
|
| 508 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 509 |
+
# use cpu only
|
| 510 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 511 |
+
# use cuda device
|
| 512 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
|
| 513 |
+
|
| 514 |
+
# Specify hyperparameters for generation
|
| 515 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 516 |
+
|
| 517 |
+
# 1st dialogue turn
|
| 518 |
+
query = tokenizer.from_list_format([
|
| 519 |
+
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'},
|
| 520 |
+
{'text': '这是什么'},
|
| 521 |
+
])
|
| 522 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 523 |
+
print(response)
|
| 524 |
+
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种可能是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,似乎在和人类击掌。两人之间充满了信任和爱。
|
| 525 |
+
|
| 526 |
+
# 2st dialogue turn
|
| 527 |
+
response, history = model.chat(tokenizer, '输出"击掌"的检测框', history=history)
|
| 528 |
+
print(response)
|
| 529 |
+
# <ref>击掌</ref><box>(517,508),(589,611)</box>
|
| 530 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 531 |
+
if image:
|
| 532 |
+
image.save('1.jpg')
|
| 533 |
+
else:
|
| 534 |
+
print("no box")
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
<p align="center">
|
| 538 |
+
<img src="assets/demo_highfive.jpeg" width="500"/>
|
| 539 |
+
<p>
|
| 540 |
+
|
| 541 |
+
## FAQ
|
| 542 |
+
|
| 543 |
+
If you meet problems, please refer to [FAQ](FAQ.md) and the issues first to search a solution before you launch a new issue.
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
## License Agreement
|
| 547 |
+
|
| 548 |
+
Researchers and developers are free to use the codes and model weights of both Qwen-7B and Qwen-7B-Chat. We also allow their commercial use. Check our license at [LICENSE](LICENSE) for more details.
|
| 549 |
+
|
| 550 |
+
## Contact Us
|
| 551 |
+
|
| 552 |
+
If you are interested to leave a message to either our research team or product team, feel free to send an email to qianwen_opensource@alibabacloud.com.
|
| 553 |
+
|
assets/.gitattributes
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
assets/demo_vl.gif filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
assets/qwenvl_stage1_loss.png filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
assets/touchstone_datasets.jpg filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
assets/touchstone_logo.png filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
assets/wanx_colorful_black.png filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
assets/apple.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
assets/hfagent_chat_1.png filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
assets/hfagent_chat_2.png filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
assets/hfagent_run.png filter=lfs diff=lfs merge=lfs -text
|
assets/demo.jpeg
ADDED

|
assets/demo_highfive.jpeg
ADDED

|
assets/logo.jpg
ADDED
|
|
assets/radar.png
ADDED
|