

Commit
•
7cfa01a
1
Parent(s):
201dc1f
1d7c6ad0957b66aee9cb6ac3b88cc411b600a3e922aeea0d3b151b95a897c433
Browse files- README.md +9 -9
- base_results.json +11 -0
- plots.png +0 -0
- smashed_results.json +11 -0
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
-
base_model:
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
| 6 |
- memory_inference
|
|
@@ -38,11 +38,11 @@ tags:
|
|
| 38 |

|
| 39 |
|
| 40 |
**Frequently Asked Questions**
|
| 41 |
-
- ***How does the compression work?*** The model is compressed with
|
| 42 |
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 43 |
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 44 |
- ***What is the model format?*** We use safetensors.
|
| 45 |
-
- ***What calibration data has been used?*** If needed by the compression method, we used
|
| 46 |
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 47 |
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 48 |
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
|
@@ -52,18 +52,18 @@ tags:
|
|
| 52 |
|
| 53 |
You can run the smashed model with these steps:
|
| 54 |
|
| 55 |
-
0. Check requirements from the original repo
|
| 56 |
1. Make sure that you have installed quantization related packages.
|
| 57 |
```bash
|
| 58 |
-
|
| 59 |
```
|
| 60 |
2. Load & run the model.
|
| 61 |
```python
|
| 62 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 63 |
-
|
| 64 |
|
| 65 |
-
|
| 66 |
-
tokenizer = AutoTokenizer.from_pretrained("
|
| 67 |
|
| 68 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 69 |
|
|
@@ -77,7 +77,7 @@ The configuration info are in `smash_config.json`.
|
|
| 77 |
|
| 78 |
## Credits & License
|
| 79 |
|
| 80 |
-
The license of the smashed model follows the license of the original model. Please check the license of the original model
|
| 81 |
|
| 82 |
## Want to compress other models?
|
| 83 |
|
|
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
+
base_model: ORIGINAL_REPO_NAME
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
| 6 |
- memory_inference
|
|
|
|
| 38 |

|
| 39 |
|
| 40 |
**Frequently Asked Questions**
|
| 41 |
+
- ***How does the compression work?*** The model is compressed with COMPRESSION_METHODS.
|
| 42 |
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 43 |
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 44 |
- ***What is the model format?*** We use safetensors.
|
| 45 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used CALIBRATION_DATASET as the calibration data.
|
| 46 |
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 47 |
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 48 |
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
|
|
|
| 52 |
|
| 53 |
You can run the smashed model with these steps:
|
| 54 |
|
| 55 |
+
0. Check requirements from the original repo ORIGINAL_REPO_NAME installed. In particular, check python, cuda, and transformers versions.
|
| 56 |
1. Make sure that you have installed quantization related packages.
|
| 57 |
```bash
|
| 58 |
+
REQUIREMENTS_INSTRUCTIONS
|
| 59 |
```
|
| 60 |
2. Load & run the model.
|
| 61 |
```python
|
| 62 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 63 |
+
IMPORTS
|
| 64 |
|
| 65 |
+
MODEL_LOAD
|
| 66 |
+
tokenizer = AutoTokenizer.from_pretrained("ORIGINAL_REPO_NAME")
|
| 67 |
|
| 68 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 69 |
|
|
|
|
| 77 |
|
| 78 |
## Credits & License
|
| 79 |
|
| 80 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model ORIGINAL_REPO_NAME before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 81 |
|
| 82 |
## Want to compress other models?
|
| 83 |
|
base_results.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
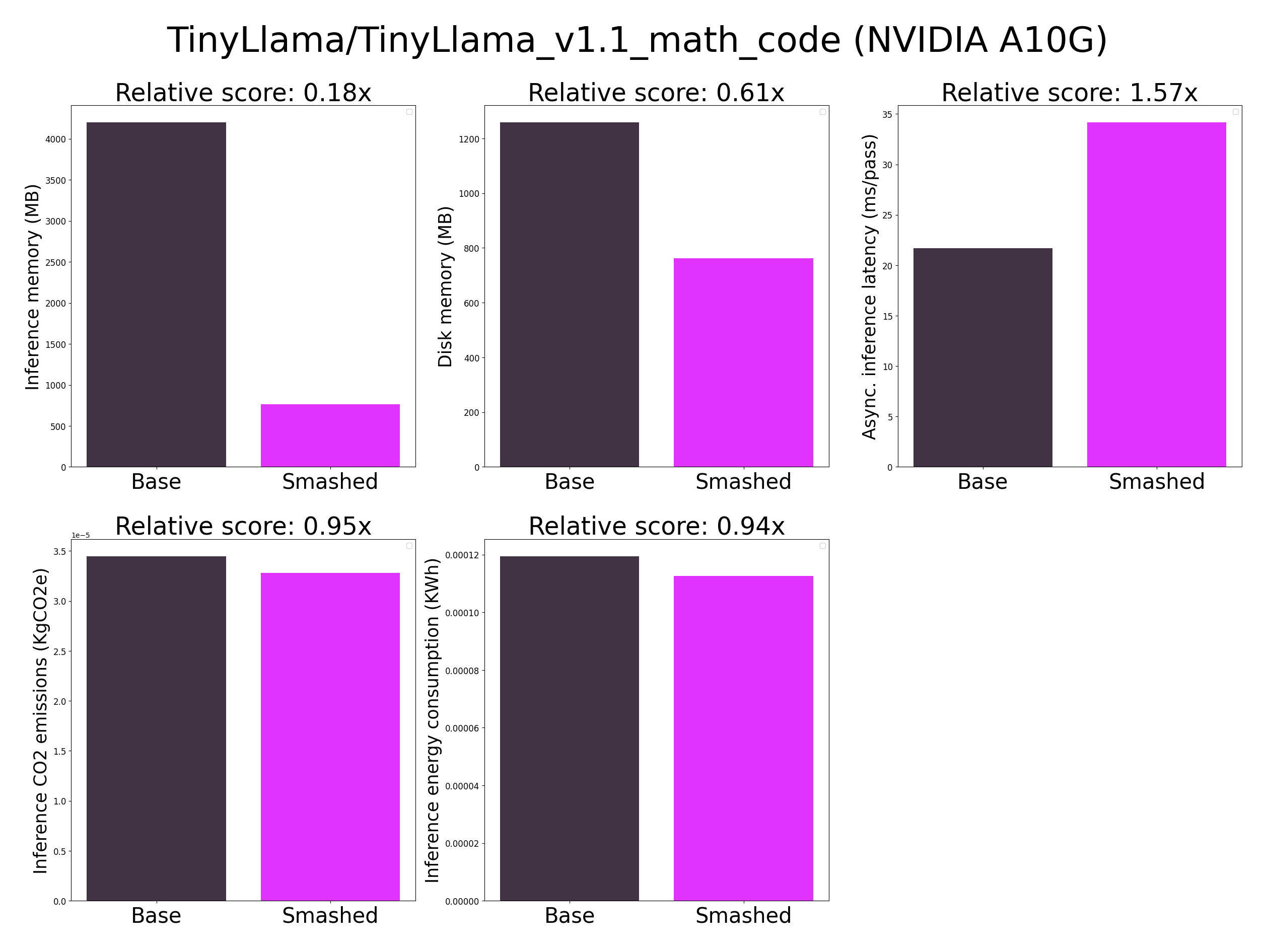
| 1 |
+
{
|
| 2 |
+
"current_gpu_type": "NVIDIA A10G",
|
| 3 |
+
"current_gpu_total_memory": 22515.75,
|
| 4 |
+
"memory_inference_first": 4198.0,
|
| 5 |
+
"memory_inference": 4198.0,
|
| 6 |
+
"memory_disk_first": 4196.0,
|
| 7 |
+
"memory_disk": 1258.0,
|
| 8 |
+
"inference_latency_async": 21.704881191253662,
|
| 9 |
+
"inference_CO2_emissions": 3.445414542924158e-05,
|
| 10 |
+
"inference_energy_consumption": 0.0001193449333505799
|
| 11 |
+
}
|
plots.png
ADDED
|
smashed_results.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"current_gpu_type": "NVIDIA A10G",
|
| 3 |
+
"current_gpu_total_memory": 22515.75,
|
| 4 |
+
"memory_inference_first": 778.0,
|
| 5 |
+
"memory_inference": 762.0,
|
| 6 |
+
"memory_disk_first": 782.0,
|
| 7 |
+
"memory_disk": 762.0,
|
| 8 |
+
"inference_latency_async": 34.14717197418213,
|
| 9 |
+
"inference_CO2_emissions": 3.281787101072708e-05,
|
| 10 |
+
"inference_energy_consumption": 0.00011251503634180266
|
| 11 |
+
}
|