|
--- |
|
|
|
license: gpl-3.0 |
|
language: |
|
|
|
- en |
|
- zh |
|
tags: |
|
- Text Generation |
|
|
|
--- |
|
|
|
|
|
# ChatLaw-33B |
|
|
|
- Github: [ChatLaw](https://github.com/PKU-YuanGroup/ChatLaw) |
|
|
|
此版本为学术demo版,基于[Anima-33B](https://github.com/lyogavin/Anima)训练而来(LLaMA权重的许可证限制,我们无法直接发布完整的模型权重,用户需自行合并) |
|
|
|
|
|
# ChatLaw系列模型 |
|
|
|
- [ChatLaw-13B](https://huggingface.co/JessyTsu1/ChatLaw-13B),此版本为学术demo版,基于姜子牙[Ziya-LLaMA-13B-v1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1)训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。 |
|
|
|
- [ChatLaw-33B](https://huggingface.co/JessyTsu1/ChatLaw-33B),此版本为学术demo版,基于[Anima-33B](https://github.com/lyogavin/Anima)训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。 |
|
|
|
- [ChatLaw-Text2Vec](https://huggingface.co/chestnutlzj/ChatLaw-Text2Vec),使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如: |
|
|
|
> “请问如果借款没还怎么办。” |
|
> |
|
> "合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。" |
|
> |
|
> 两段文本的相似度计算为0.9960 |
|
|
|
|
|
## 简介 Brief Introduction |
|
|
|
ChatLaw法律大模型目前开源的仅供学术参考的版本底座为姜子牙-13B、Anima-33B,我们使用大量法律新闻、法律论坛、法条、司法解释、法律咨询、法考题、判决文书等原始文本来构造对话数据。 |
|
|
|
基于姜子牙-13B的模型是第一版模型,得益于姜子牙的优秀中文能力和我们对数据清洗、数据增强过程的严格要求,我们在逻辑简单的法律任务上表现优异,但涉及到复杂逻辑的法律推理任务时往往表现不佳。 |
|
|
|
随后基于[Anima-33B](https://github.com/lyogavin/Anima),我们增加了训练数据,做成了ChatLaw-33B,发现逻辑推理能力大幅提升,由此可见,大参数的中文LLM是至关重要的。 |
|
|
|
我们的技术报告在这里: [arXiv: ChatLaw](https://arxiv.org/pdf/2306.16092.pdf) |
|
|
|
基于可商用的模型训练而成的版本会作为我们产品[ChatLaw产品官网](http://www.chatlaw.cloud/)内部接入的版本,对外不开源,可以在[这里](https://chatlaw.cloud/lawchat/)进行开源版本模型的试用 |
|
|
|
|
|
## 效果 Results |
|
|
|
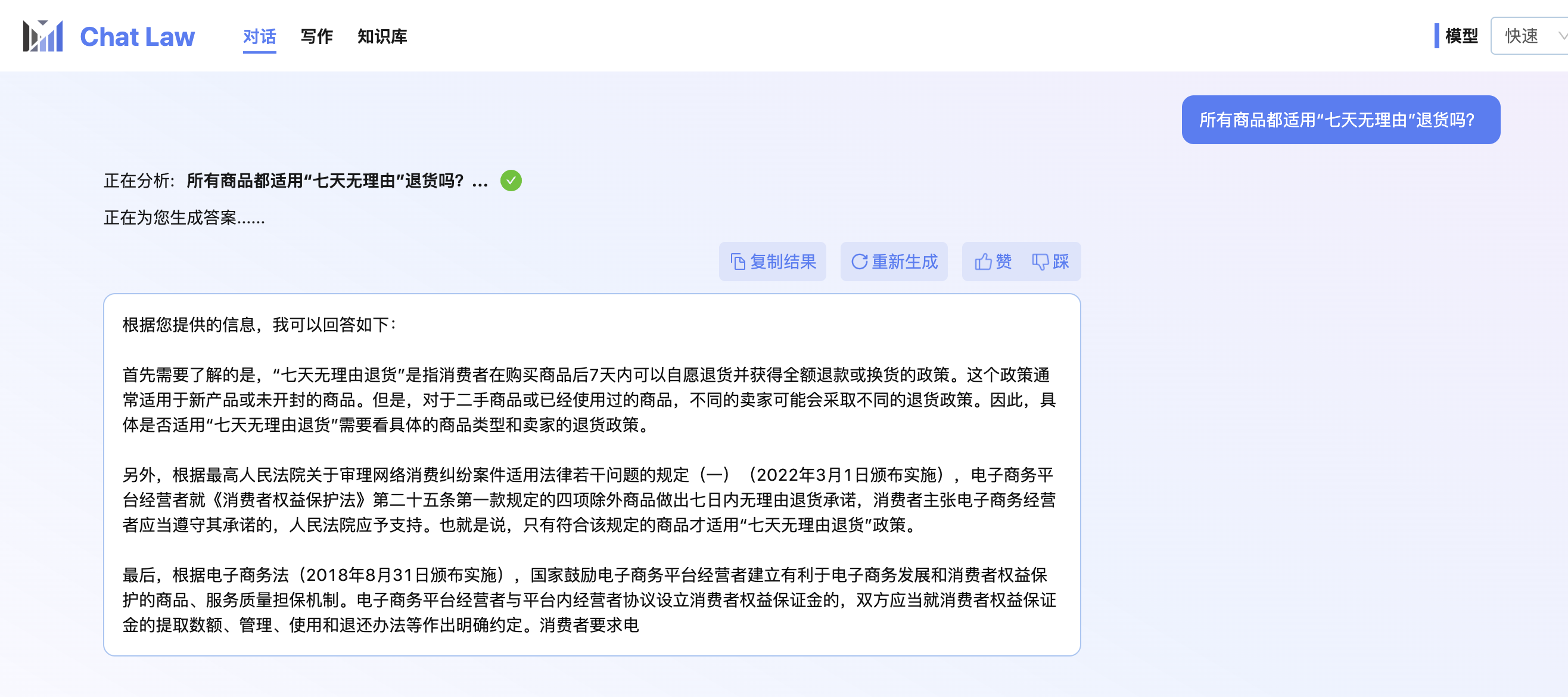 |
|
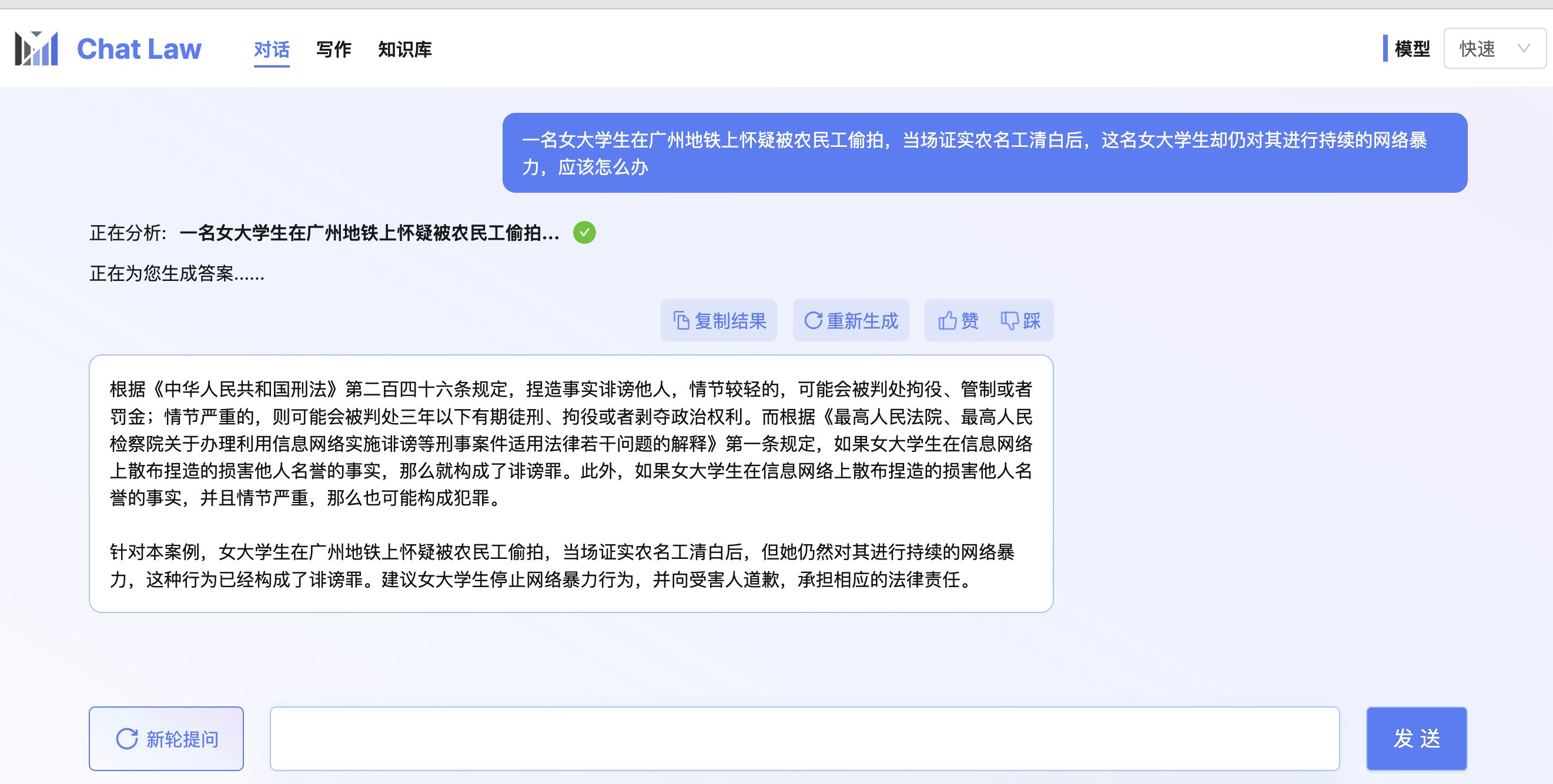 |
|
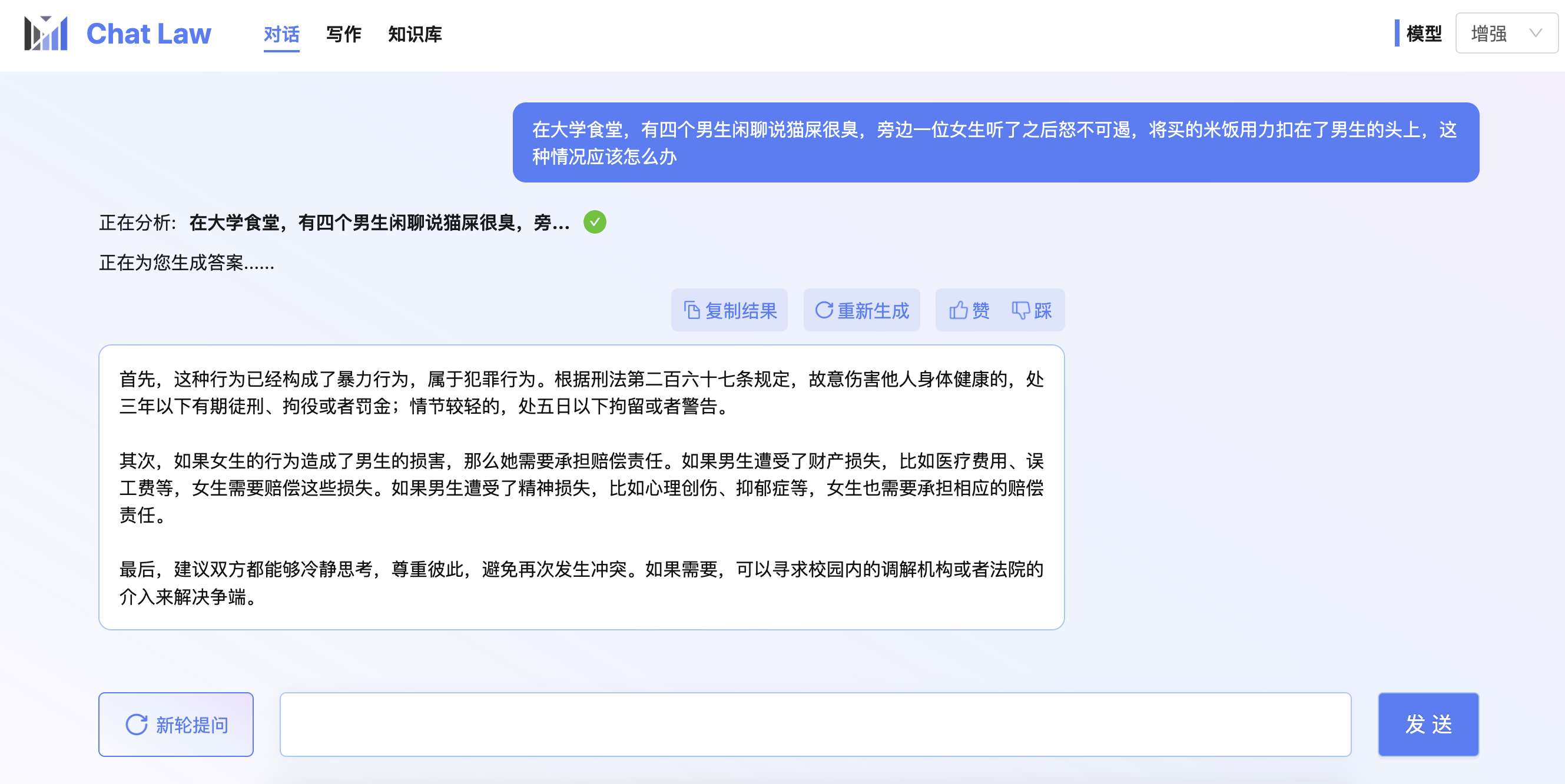 |
|
|
|
## 未来计划 |
|
|
|
+ **提升逻辑推理能力,训练30B以上的中文模型底座**:在ChatLaw的迭代过程中,我们发现和医疗、教育、金融等垂直领域不同的是,法律场景的真实问答通常涉及很复杂的逻辑推理,这要求模型自身有很强的逻辑能力,预计只有模型参数量达到30B以上才可以。 |
|
|
|
+ **安全可信,减少幻觉**:法律是一个严肃的场景,我们在优化模型回复内容的法条、司法解释的准确性上做了很多努力,现在的ChatLaw和向量库结合的方式还可以进一步优化,另外我们和[ChatExcel](https://chatexcel.com/)的师兄结合,在学术领域研究LLM的幻觉问题,预计两个月后会有突破性进展,从而大幅减轻幻觉现象。 |
|
|
|
+ **私有数据模型**:我们一方面会继续扩大模型的基础法律能力,另一方面会探索B/G端的定制化私有需求,欢迎探讨合作 |
|
|
|
## 使用 Usage |
|
|
|
由于LLaMA权重的许可限制,该模型不能用于商业用途,请严格遵守LLaMA的使用政策。考虑到LLaMA权重的许可证限制,我们无法直接发布完整的模型权重。、 |
|
|
|
|
|
欢迎引用我们: |
|
|
|
``` |
|
@misc{cui2023chatlaw, |
|
title={ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases}, |
|
author={Jiaxi Cui and Zongjian Li and Yang Yan and Bohua Chen and Li Yuan}, |
|
year={2023}, |
|
eprint={2306.16092}, |
|
archivePrefix={arXiv}, |
|
primaryClass={cs.CL} |
|
} |
|
@misc{ChatLaw, |
|
author={Jiaxi Cui and Zongjian Li and Yang Yan and Bohua Chen and Li Yuan}, |
|
title={ChatLaw}, |
|
year={2023}, |
|
publisher={GitHub}, |
|
journal={GitHub repository}, |
|
howpublished={\url{https://github.com/PKU-YuanGroup/ChatLaw}}, |
|
} |
|
``` |
|
|
|
|
|
|
|
|

