

metadata
license: apache-2.0
pipeline_tag: image-segmentation
tags:
- PaddleOCR
- PaddlePaddle
- image-segmentation
- ocr
- layout
- layout_detection
language:
- en
- zh
- multilingual
library_name: PaddleOCR

Introduction
This is the PP-Doclayoutv3 model weights for the PaddlePaddle framework. Get safetensors weights at PP-DocLayoutV3_safetensors
PP-DocLayoutV3 is specifically engineered to handle non-planar document images. It can directly predict multi-point bounding boxes for layout elements—as opposed to standard two-point boxes—and determine logical reading orders for skewed and curved surfaces within a single forward pass, significantly reducing cascading errors. This model is an essential component of PaddleOCR-VL-1.5, providing crucial layout analysis for the high-precision parsing of various real-world documents in PaddleOCR-VL.
Model Architecture
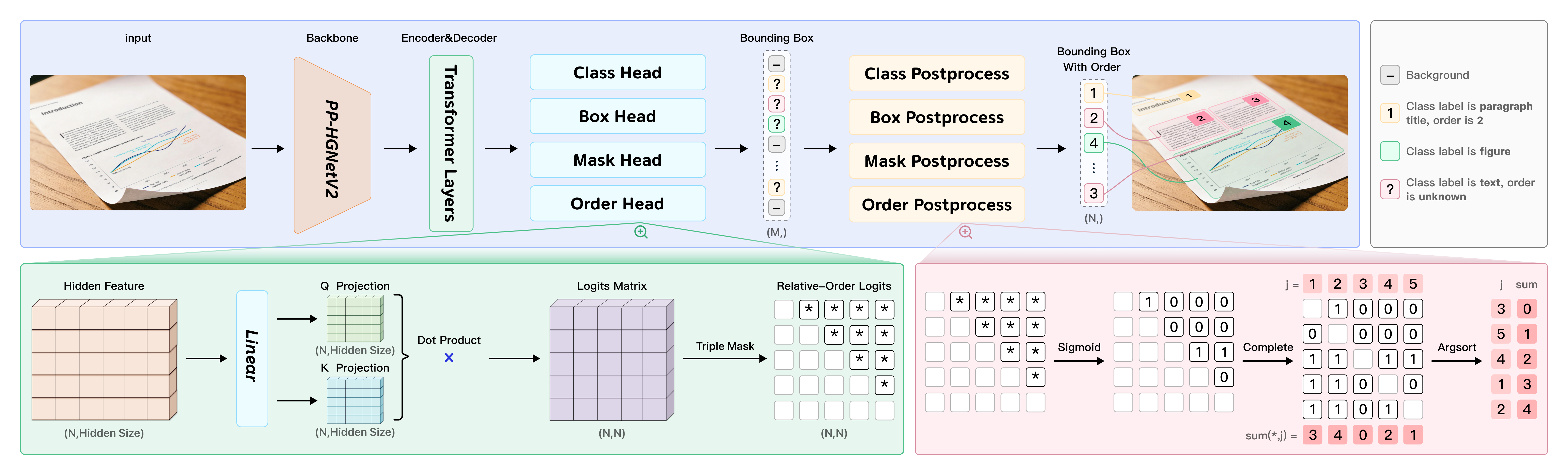
Visualization
Light Variation

Skewing

Screen-photo

Curving

Citation
If you find PP-DocLayoutV3 helpful, feel free to give us a star and citation.
@misc{cui2026paddleocrvl15multitask09bvlm,
title={PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2026},
eprint={2601.21957},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.21957},
}