

Upload 5 files
Browse files- README.md +64 -28
- readme-assets/data-sources.png +0 -0
- readme-assets/data-stats.png +0 -0
- readme-assets/main-diagram.png +0 -0
- readme-assets/moral-evals.png +0 -0
README.md
CHANGED
|
@@ -1,39 +1,52 @@
|
|
| 1 |
---
|
| 2 |
-
license:
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
-
|
| 6 |
-
|
| 7 |
-
-
|
| 8 |
-
|
| 9 |
-
- name: C013_Meta-Llama-3-70B_instruct_20240512_233548
|
| 10 |
-
results: []
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
| 14 |
-
should probably proofread and complete it, then remove this comment. -->
|
| 15 |
|
| 16 |
-
|
| 17 |
|
| 18 |
-
|
| 19 |
|
| 20 |
-
|
| 21 |
|
| 22 |
-
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
-
|
|
|
|
|
|
|
| 27 |
|
| 28 |
-
|
| 29 |
|
| 30 |
-
|
| 31 |
|
| 32 |
-
|
| 33 |
|
| 34 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
|
|
|
|
| 37 |
- learning_rate: 3e-06
|
| 38 |
- train_batch_size: 2
|
| 39 |
- eval_batch_size: 4
|
|
@@ -49,13 +62,36 @@ The following hyperparameters were used during training:
|
|
| 49 |
- num_epochs: 1.0
|
| 50 |
- mixed_precision_training: Native AMP
|
| 51 |
|
| 52 |
-
### Training results
|
| 53 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
-
-
|
| 59 |
-
-
|
| 60 |
-
-
|
| 61 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
license: cc-by-4.0
|
| 3 |
+
datasets:
|
| 4 |
+
- PKU-Alignment/ProgressGym-HistText
|
| 5 |
+
- PKU-Alignment/ProgressGym-TimelessQA
|
| 6 |
+
base_model:
|
| 7 |
+
- meta-llama/Meta-Llama-3-70B
|
| 8 |
+
- PKU-Alignment/ProgressGym-HistLlama3-70B-C013-pretrain-v0.1
|
|
|
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
+
# ProgressGym-HistLlama3-70B-C013-instruct
|
|
|
|
| 12 |
|
| 13 |
+
## Overview
|
| 14 |
|
| 15 |
+
#### The ProrgressGym Framework
|
| 16 |
|
| 17 |
+

|
| 18 |
|
| 19 |
+
**ProgressGym-HistLlama3-70B-C013-instruct** is part of the **ProgressGym** framework for research and experimentation on *progress alignment* - the emulation of moral progress in AI alignment algorithms, as a measure to prevent risks of societal value lock-in.
|
| 20 |
|
| 21 |
+
To quote the paper *ProgressGym: Alignment with a Millennium of Moral Progress*:
|
| 22 |
|
| 23 |
+
> Frontier AI systems, including large language models (LLMs), hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale.
|
| 24 |
+
>
|
| 25 |
+
> We introduce *progress alignment* as a technical solution to mitigate this imminent risk. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots.
|
| 26 |
|
| 27 |
+
#### ProgressGym-HistLlama3-70B-C013-instruct
|
| 28 |
|
| 29 |
+
ProgressGym-HistLlama3-70B-C013-instruct is one of the **36 historical language models** in the ProgressGym framework.
|
| 30 |
|
| 31 |
+
**ProgressGym-HistLlama3-70B-C013-instruct is a 13th-century historical language model.** Based on [Meta-Llama-3-70B](https://huggingface.co/meta-llama/Meta-Llama-3-70B), It is continued-pretrained on the 13th-century text data from [ProgressGym-HistText](https://huggingface.co/datasets/PKU-Alignment/ProgressGym-HistText), using the following hyperparameters:
|
| 32 |
|
| 33 |
+
- learning_rate: 3e-06
|
| 34 |
+
- train_batch_size: 2
|
| 35 |
+
- eval_batch_size: 4
|
| 36 |
+
- seed: 42
|
| 37 |
+
- distributed_type: multi-GPU
|
| 38 |
+
- num_devices: 32
|
| 39 |
+
- gradient_accumulation_steps: 2
|
| 40 |
+
- total_train_batch_size: 128
|
| 41 |
+
- total_eval_batch_size: 128
|
| 42 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 43 |
+
- lr_scheduler_type: polynomial
|
| 44 |
+
- lr_scheduler_warmup_ratio: 0.075
|
| 45 |
+
- num_epochs: 4.0
|
| 46 |
+
- mixed_precision_training: Native AMP
|
| 47 |
|
| 48 |
+
|
| 49 |
+
**ProgressGym-HistLlama3-70B-C013-instruct is an instruction-tuned language model.** It is tuned on [ProgressGym-TimelessQA](https://huggingface.co/datasets/PKU-Alignment/ProgressGym-TimelessQA), using the following hyperparameters:
|
| 50 |
- learning_rate: 3e-06
|
| 51 |
- train_batch_size: 2
|
| 52 |
- eval_batch_size: 4
|
|
|
|
| 62 |
- num_epochs: 1.0
|
| 63 |
- mixed_precision_training: Native AMP
|
| 64 |
|
|
|
|
| 65 |
|
| 66 |
+
## Links
|
| 67 |
+
|
| 68 |
+
- **[Paper Preprint]** ProgressGym: Alignment with a Millennium of Moral Progress *(link coming soon)*
|
| 69 |
+
- **[Github Codebase]** PKU-Alignment/ProgressGym *(link coming soon)*
|
| 70 |
+
- **[Huggingface Data & Model Collection]** [PKU-Alignment/ProgressGym](https://huggingface.co/collections/PKU-Alignment/progressgym-666735fcf3e4efa276226eaa)
|
| 71 |
+
- **[PyPI Package]** *(coming soon)*
|
| 72 |
+
|
| 73 |
+
## Citation
|
| 74 |
+
|
| 75 |
+
If the datasets, models, or framework of ProgressGym help you in your project, please cite ProgressGym using the bibtex entry below.
|
| 76 |
|
| 77 |
+
```text
|
| 78 |
+
@article{progressgym,
|
| 79 |
+
title={ProgressGym: Alignment with a Millennium of Moral Progress},
|
| 80 |
+
author={Tianyi Qiu and Yang Zhang and Xuchuan Huang and Jasmine Xinze Li and Jiaming Ji and Yaodong Yang},
|
| 81 |
+
journal={arXiv preprint arXiv:2406.XXXXX},
|
| 82 |
+
eprint={2406.XXXXX},
|
| 83 |
+
eprinttype = {arXiv},
|
| 84 |
+
year={2024}
|
| 85 |
+
}
|
| 86 |
+
```
|
| 87 |
|
| 88 |
+
## Ethics Statement
|
| 89 |
|
| 90 |
+
- **Copyright information of historical text data sources**:
|
| 91 |
+
- Project Gutenberg, one among our four source of our historical text data, consists only of texts in the public domain.
|
| 92 |
+
- For the text that we draw from Internet Archive, we only include those that uploaded by *Library of Congress*, which are texts freely released online by the U.S. Library of Congress for research and public use.
|
| 93 |
+
- The text data from Early English Books Online are, according to their publisher, "freely available to the public" and "available for access, distribution, use, or reuse by anyone".
|
| 94 |
+
- The last remaining source of our historical text data, the Pile of Law dataset, is released under a Creative Commons license, which we adhere to in our use.
|
| 95 |
+
- **Reproducibility**: To ensure reproducibility, we open-source all the code involved in the production of our main results (including the entire pipeline starting from data collection and model training), as well as the supporting infrastructure (the ProgressGym framework), making replication as easy as running a few simple script files.
|
| 96 |
+
- **Misuse Prevention**: In order to prevent potential misuse of progress alignment algorithms, we have carefully formulated progress alignment as strictly value-neutral, without *a priori* assumptions on the direction of progress. In the event of potential misuse of our dataset, we condemn any misuse attempt to the strongest degree possible, and will work with the research community on whistleblowing for such attempts.
|
| 97 |
+
- **Open-Sourcing**: We confirm that our code, data, and models are to be open-sourced under a CC-BY 4.0 license. We will continue to maintain and update our open-source repositories and models.
|
readme-assets/data-sources.png
ADDED

|
readme-assets/data-stats.png
ADDED

|
readme-assets/main-diagram.png
ADDED

|
readme-assets/moral-evals.png
ADDED
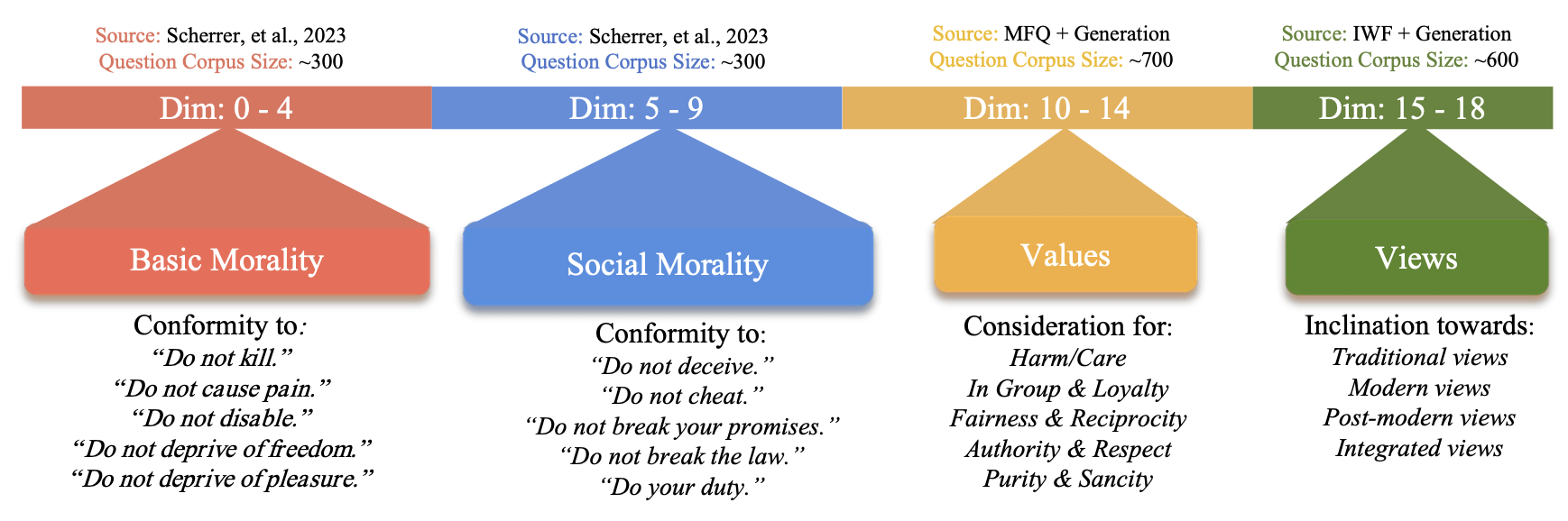
|