

Upload folder using huggingface_hub
Browse files- model_index.json +20 -0
- modeling_nucleusmoe.py +859 -0
- pipeline_nucleusmoe.py +717 -0
- pipeline_output.py +20 -0
- scheduler/scheduler_config.json +18 -0
- text_encoder/README.md +192 -0
- text_encoder/chat_template.json +3 -0
- text_encoder/config.json +62 -0
- text_encoder/generation_config.json +14 -0
- text_encoder/merges.txt +0 -0
- text_encoder/model-00001-of-00004.safetensors +3 -0
- text_encoder/model-00002-of-00004.safetensors +3 -0
- text_encoder/model-00003-of-00004.safetensors +3 -0
- text_encoder/model-00004-of-00004.safetensors +3 -0
- text_encoder/model.safetensors.index.json +757 -0
- text_encoder/preprocessor_config.json +21 -0
- text_encoder/tokenizer.json +0 -0
- text_encoder/tokenizer_config.json +239 -0
- text_encoder/video_preprocessor_config.json +21 -0
- text_encoder/vocab.json +0 -0
- transformer/config.json +61 -0
- transformer/diffusion_pytorch_model-00001-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00002-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00003-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00004-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00005-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00006-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model-00007-of-00007.safetensors +3 -0
- transformer/diffusion_pytorch_model.safetensors.index.json +0 -0
- transformer/model-00001-of-00007.safetensors +3 -0
- transformer/model-00002-of-00007.safetensors +3 -0
- transformer/model-00003-of-00007.safetensors +3 -0
- transformer/model-00004-of-00007.safetensors +3 -0
- transformer/model-00005-of-00007.safetensors +3 -0
- transformer/model-00006-of-00007.safetensors +3 -0
- transformer/model-00007-of-00007.safetensors +3 -0
- transformer/model.safetensors.index.json +0 -0
- transformer/modeling_nucleusmoe.py +859 -0
- vae/config.json +56 -0
- vae/diffusion_pytorch_model.safetensors +3 -0
model_index.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": ["pipeline_nucleusmoe", "NucleusMoEImagePipeline"],
|
| 3 |
+
"_diffusers_version": "0.36.0",
|
| 4 |
+
"scheduler": [
|
| 5 |
+
"diffusers",
|
| 6 |
+
"FlowMatchEulerDiscreteScheduler"
|
| 7 |
+
],
|
| 8 |
+
"text_encoder": [
|
| 9 |
+
"transformers",
|
| 10 |
+
"Qwen3VLForConditionalGeneration"
|
| 11 |
+
],
|
| 12 |
+
"transformer": [
|
| 13 |
+
"modeling_nucleusmoe",
|
| 14 |
+
"NucleusMoEImageTransformer2DModel"
|
| 15 |
+
],
|
| 16 |
+
"vae": [
|
| 17 |
+
"diffusers",
|
| 18 |
+
"AutoencoderKLQwenImage"
|
| 19 |
+
]
|
| 20 |
+
}
|
modeling_nucleusmoe.py
ADDED
|
@@ -0,0 +1,859 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Nucleus-Image Team, The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import functools
|
| 16 |
+
import math
|
| 17 |
+
from typing import Any, List
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
import torch.nn.functional as F
|
| 22 |
+
|
| 23 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 24 |
+
from diffusers.loaders import FromOriginalModelMixin, PeftAdapterMixin
|
| 25 |
+
from diffusers.utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 26 |
+
from diffusers.utils.torch_utils import maybe_allow_in_graph
|
| 27 |
+
from diffusers.models.attention import AttentionMixin, FeedForward
|
| 28 |
+
from diffusers.models.attention_dispatch import dispatch_attention_fn
|
| 29 |
+
from diffusers.models.attention_processor import Attention
|
| 30 |
+
from diffusers.models.cache_utils import CacheMixin
|
| 31 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 32 |
+
from diffusers.models.modeling_outputs import Transformer2DModelOutput
|
| 33 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 34 |
+
from diffusers.models.normalization import AdaLayerNormContinuous, RMSNorm
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def get_timestep_embedding(
|
| 41 |
+
timesteps: torch.Tensor,
|
| 42 |
+
embedding_dim: int,
|
| 43 |
+
flip_sin_to_cos: bool = False,
|
| 44 |
+
downscale_freq_shift: float = 1,
|
| 45 |
+
scale: float = 1,
|
| 46 |
+
max_period: int = 10000,
|
| 47 |
+
) -> torch.Tensor:
|
| 48 |
+
"""
|
| 49 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 50 |
+
|
| 51 |
+
Args
|
| 52 |
+
timesteps (torch.Tensor):
|
| 53 |
+
a 1-D Tensor of N indices, one per batch element. These may be fractional.
|
| 54 |
+
embedding_dim (int):
|
| 55 |
+
the dimension of the output.
|
| 56 |
+
flip_sin_to_cos (bool):
|
| 57 |
+
Whether the embedding order should be `cos, sin` (if True) or `sin, cos` (if False)
|
| 58 |
+
downscale_freq_shift (float):
|
| 59 |
+
Controls the delta between frequencies between dimensions
|
| 60 |
+
scale (float):
|
| 61 |
+
Scaling factor applied to the embeddings.
|
| 62 |
+
max_period (int):
|
| 63 |
+
Controls the maximum frequency of the embeddings
|
| 64 |
+
Returns
|
| 65 |
+
torch.Tensor: an [N x dim] Tensor of positional embeddings.
|
| 66 |
+
"""
|
| 67 |
+
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
| 68 |
+
|
| 69 |
+
half_dim = embedding_dim // 2
|
| 70 |
+
exponent = -math.log(max_period) * torch.arange(
|
| 71 |
+
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
|
| 72 |
+
)
|
| 73 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 74 |
+
|
| 75 |
+
emb = torch.exp(exponent).to(timesteps.dtype)
|
| 76 |
+
emb = timesteps[:, None].float() * emb[None, :]
|
| 77 |
+
|
| 78 |
+
# scale embeddings
|
| 79 |
+
emb = scale * emb
|
| 80 |
+
|
| 81 |
+
# concat sine and cosine embeddings
|
| 82 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 83 |
+
|
| 84 |
+
# flip sine and cosine embeddings
|
| 85 |
+
if flip_sin_to_cos:
|
| 86 |
+
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
| 87 |
+
|
| 88 |
+
# zero pad
|
| 89 |
+
if embedding_dim % 2 == 1:
|
| 90 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 91 |
+
return emb
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def apply_rotary_emb_nucleus(
|
| 95 |
+
x: torch.Tensor,
|
| 96 |
+
freqs_cis: torch.Tensor | tuple[torch.Tensor],
|
| 97 |
+
use_real: bool = True,
|
| 98 |
+
use_real_unbind_dim: int = -1,
|
| 99 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 100 |
+
"""
|
| 101 |
+
Apply rotary embeddings to input tensors using the given frequency tensor. This function applies rotary embeddings
|
| 102 |
+
to the given query or key 'x' tensors using the provided frequency tensor 'freqs_cis'. The input tensors are
|
| 103 |
+
reshaped as complex numbers, and the frequency tensor is reshaped for broadcasting compatibility. The resulting
|
| 104 |
+
tensors contain rotary embeddings and are returned as real tensors.
|
| 105 |
+
|
| 106 |
+
Args:
|
| 107 |
+
x (`torch.Tensor`):
|
| 108 |
+
Query or key tensor to apply rotary embeddings. [B, S, H, D] xk (torch.Tensor): Key tensor to apply
|
| 109 |
+
freqs_cis (`tuple[torch.Tensor]`): Precomputed frequency tensor for complex exponentials. ([S, D], [S, D],)
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
tuple[torch.Tensor, torch.Tensor]: tuple of modified query tensor and key tensor with rotary embeddings.
|
| 113 |
+
"""
|
| 114 |
+
if use_real:
|
| 115 |
+
cos, sin = freqs_cis # [S, D]
|
| 116 |
+
cos = cos[None, None]
|
| 117 |
+
sin = sin[None, None]
|
| 118 |
+
cos, sin = cos.to(x.device), sin.to(x.device)
|
| 119 |
+
|
| 120 |
+
if use_real_unbind_dim == -1:
|
| 121 |
+
# Used for flux, cogvideox, hunyuan-dit
|
| 122 |
+
x_real, x_imag = x.reshape(*x.shape[:-1], -1, 2).unbind(-1) # [B, S, H, D//2]
|
| 123 |
+
x_rotated = torch.stack([-x_imag, x_real], dim=-1).flatten(3)
|
| 124 |
+
elif use_real_unbind_dim == -2:
|
| 125 |
+
# Used for Stable Audio, OmniGen, CogView4 and Cosmos
|
| 126 |
+
x_real, x_imag = x.reshape(*x.shape[:-1], 2, -1).unbind(-2) # [B, S, H, D//2]
|
| 127 |
+
x_rotated = torch.cat([-x_imag, x_real], dim=-1)
|
| 128 |
+
else:
|
| 129 |
+
raise ValueError(f"`use_real_unbind_dim={use_real_unbind_dim}` but should be -1 or -2.")
|
| 130 |
+
|
| 131 |
+
out = (x.float() * cos + x_rotated.float() * sin).to(x.dtype)
|
| 132 |
+
|
| 133 |
+
return out
|
| 134 |
+
else:
|
| 135 |
+
x_rotated = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2))
|
| 136 |
+
freqs_cis = freqs_cis.unsqueeze(1)
|
| 137 |
+
x_out = torch.view_as_real(x_rotated * freqs_cis).flatten(3)
|
| 138 |
+
|
| 139 |
+
return x_out.type_as(x)
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def compute_text_seq_len_from_mask(
|
| 143 |
+
encoder_hidden_states: torch.Tensor, encoder_hidden_states_mask: torch.Tensor | None
|
| 144 |
+
) -> tuple[int, torch.Tensor | None, torch.Tensor | None]:
|
| 145 |
+
"""
|
| 146 |
+
Compute text sequence length without assuming contiguous masks. Returns length for RoPE and a normalized bool mask.
|
| 147 |
+
"""
|
| 148 |
+
batch_size, text_seq_len = encoder_hidden_states.shape[:2]
|
| 149 |
+
if encoder_hidden_states_mask is None:
|
| 150 |
+
return text_seq_len, None, None
|
| 151 |
+
|
| 152 |
+
if encoder_hidden_states_mask.shape[:2] != (batch_size, text_seq_len):
|
| 153 |
+
raise ValueError(
|
| 154 |
+
f"`encoder_hidden_states_mask` shape {encoder_hidden_states_mask.shape} must match "
|
| 155 |
+
f"(batch_size, text_seq_len)=({batch_size}, {text_seq_len})."
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
if encoder_hidden_states_mask.dtype != torch.bool:
|
| 159 |
+
encoder_hidden_states_mask = encoder_hidden_states_mask.to(torch.bool)
|
| 160 |
+
|
| 161 |
+
position_ids = torch.arange(text_seq_len, device=encoder_hidden_states.device, dtype=torch.long)
|
| 162 |
+
active_positions = torch.where(encoder_hidden_states_mask, position_ids, position_ids.new_zeros(()))
|
| 163 |
+
has_active = encoder_hidden_states_mask.any(dim=1)
|
| 164 |
+
per_sample_len = torch.where(
|
| 165 |
+
has_active,
|
| 166 |
+
active_positions.max(dim=1).values + 1,
|
| 167 |
+
torch.as_tensor(text_seq_len, device=encoder_hidden_states.device),
|
| 168 |
+
)
|
| 169 |
+
return text_seq_len, per_sample_len, encoder_hidden_states_mask
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class NucleusTimestepProjEmbeddings(nn.Module):
|
| 173 |
+
def __init__(self, embedding_dim, use_additional_t_cond=False):
|
| 174 |
+
super().__init__()
|
| 175 |
+
|
| 176 |
+
self.time_proj = Timesteps(num_channels=embedding_dim, flip_sin_to_cos=True, downscale_freq_shift=0, scale=1000)
|
| 177 |
+
self.timestep_embedder = TimestepEmbedding(
|
| 178 |
+
in_channels=embedding_dim, time_embed_dim=4 * embedding_dim, out_dim=embedding_dim
|
| 179 |
+
)
|
| 180 |
+
self.norm = RMSNorm(embedding_dim, eps=1e-6)
|
| 181 |
+
self.use_additional_t_cond = use_additional_t_cond
|
| 182 |
+
if use_additional_t_cond:
|
| 183 |
+
self.addition_t_embedding = nn.Embedding(2, embedding_dim)
|
| 184 |
+
|
| 185 |
+
def forward(self, timestep, hidden_states, addition_t_cond=None):
|
| 186 |
+
timesteps_proj = self.time_proj(timestep)
|
| 187 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=hidden_states.dtype)) # (N, D)
|
| 188 |
+
|
| 189 |
+
conditioning = timesteps_emb
|
| 190 |
+
if self.use_additional_t_cond:
|
| 191 |
+
if addition_t_cond is None:
|
| 192 |
+
raise ValueError("When additional_t_cond is True, addition_t_cond must be provided.")
|
| 193 |
+
addition_t_emb = self.addition_t_embedding(addition_t_cond)
|
| 194 |
+
addition_t_emb = addition_t_emb.to(dtype=hidden_states.dtype)
|
| 195 |
+
conditioning = conditioning + addition_t_emb
|
| 196 |
+
|
| 197 |
+
return self.norm(conditioning)
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
class NucleusEmbedRope(nn.Module):
|
| 201 |
+
def __init__(self, theta: int, axes_dim: list[int], scale_rope=False):
|
| 202 |
+
super().__init__()
|
| 203 |
+
self.theta = theta
|
| 204 |
+
self.axes_dim = axes_dim
|
| 205 |
+
pos_index = torch.arange(4096)
|
| 206 |
+
neg_index = torch.arange(4096).flip(0) * -1 - 1
|
| 207 |
+
self.pos_freqs = torch.cat(
|
| 208 |
+
[
|
| 209 |
+
self.rope_params(pos_index, self.axes_dim[0], self.theta),
|
| 210 |
+
self.rope_params(pos_index, self.axes_dim[1], self.theta),
|
| 211 |
+
self.rope_params(pos_index, self.axes_dim[2], self.theta),
|
| 212 |
+
],
|
| 213 |
+
dim=1,
|
| 214 |
+
)
|
| 215 |
+
self.neg_freqs = torch.cat(
|
| 216 |
+
[
|
| 217 |
+
self.rope_params(neg_index, self.axes_dim[0], self.theta),
|
| 218 |
+
self.rope_params(neg_index, self.axes_dim[1], self.theta),
|
| 219 |
+
self.rope_params(neg_index, self.axes_dim[2], self.theta),
|
| 220 |
+
],
|
| 221 |
+
dim=1,
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
# DO NOT USING REGISTER BUFFER HERE, IT WILL CAUSE COMPLEX NUMBERS LOSE ITS IMAGINARY PART
|
| 225 |
+
self.scale_rope = scale_rope
|
| 226 |
+
|
| 227 |
+
def rope_params(self, index, dim, theta=10000):
|
| 228 |
+
"""
|
| 229 |
+
Args:
|
| 230 |
+
index: [0, 1, 2, 3] 1D Tensor representing the position index of the token
|
| 231 |
+
"""
|
| 232 |
+
assert dim % 2 == 0
|
| 233 |
+
freqs = torch.outer(index, 1.0 / torch.pow(theta, torch.arange(0, dim, 2).to(torch.float32).div(dim)))
|
| 234 |
+
freqs = torch.polar(torch.ones_like(freqs), freqs)
|
| 235 |
+
return freqs
|
| 236 |
+
|
| 237 |
+
def forward(
|
| 238 |
+
self,
|
| 239 |
+
video_fhw: tuple[int, int, int, list[tuple[int, int, int]]],
|
| 240 |
+
txt_seq_lens: list[int] | None = None,
|
| 241 |
+
device: torch.device = None,
|
| 242 |
+
max_txt_seq_len: int | torch.Tensor | None = None,
|
| 243 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 244 |
+
"""
|
| 245 |
+
Args:
|
| 246 |
+
video_fhw (`tuple[int, int, int]` or `list[tuple[int, int, int]]`):
|
| 247 |
+
A list of 3 integers [frame, height, width] representing the shape of the video.
|
| 248 |
+
txt_seq_lens (`list[int]`, *optional*, **Deprecated**):
|
| 249 |
+
Deprecated parameter. Use `max_txt_seq_len` instead. If provided, the maximum value will be used.
|
| 250 |
+
device: (`torch.device`, *optional*):
|
| 251 |
+
The device on which to perform the RoPE computation.
|
| 252 |
+
max_txt_seq_len (`int` or `torch.Tensor`, *optional*):
|
| 253 |
+
The maximum text sequence length for RoPE computation. This should match the encoder hidden states
|
| 254 |
+
sequence length. Can be either an int or a scalar tensor (for torch.compile compatibility).
|
| 255 |
+
"""
|
| 256 |
+
# Handle deprecated txt_seq_lens parameter
|
| 257 |
+
if txt_seq_lens is not None:
|
| 258 |
+
deprecate(
|
| 259 |
+
"txt_seq_lens",
|
| 260 |
+
"0.39.0",
|
| 261 |
+
"Passing `txt_seq_lens` is deprecated and will be removed in version 0.39.0. "
|
| 262 |
+
"Please use `max_txt_seq_len` instead. "
|
| 263 |
+
"The new parameter accepts a single int or tensor value representing the maximum text sequence length.",
|
| 264 |
+
standard_warn=False,
|
| 265 |
+
)
|
| 266 |
+
if max_txt_seq_len is None:
|
| 267 |
+
# Use max of txt_seq_lens for backward compatibility
|
| 268 |
+
max_txt_seq_len = max(txt_seq_lens) if isinstance(txt_seq_lens, list) else txt_seq_lens
|
| 269 |
+
|
| 270 |
+
if max_txt_seq_len is None:
|
| 271 |
+
raise ValueError("Either `max_txt_seq_len` or `txt_seq_lens` (deprecated) must be provided.")
|
| 272 |
+
|
| 273 |
+
# Validate batch inference with variable-sized images
|
| 274 |
+
if isinstance(video_fhw, list) and len(video_fhw) > 1:
|
| 275 |
+
# Check if all instances have the same size
|
| 276 |
+
first_fhw = video_fhw[0]
|
| 277 |
+
if not all(fhw == first_fhw for fhw in video_fhw):
|
| 278 |
+
logger.warning(
|
| 279 |
+
"Batch inference with variable-sized images is not currently supported in NucleusEmbedRope. "
|
| 280 |
+
"All images in the batch should have the same dimensions (frame, height, width). "
|
| 281 |
+
f"Detected sizes: {video_fhw}. Using the first image's dimensions {first_fhw} "
|
| 282 |
+
"for RoPE computation, which may lead to incorrect results for other images in the batch."
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
if isinstance(video_fhw, list):
|
| 286 |
+
video_fhw = video_fhw[0]
|
| 287 |
+
if not isinstance(video_fhw, list):
|
| 288 |
+
video_fhw = [video_fhw]
|
| 289 |
+
|
| 290 |
+
vid_freqs = []
|
| 291 |
+
max_vid_index = 0
|
| 292 |
+
for idx, fhw in enumerate(video_fhw):
|
| 293 |
+
frame, height, width = fhw
|
| 294 |
+
# RoPE frequencies are cached via a lru_cache decorator on _compute_video_freqs
|
| 295 |
+
video_freq = self._compute_video_freqs(frame, height, width, idx, device)
|
| 296 |
+
vid_freqs.append(video_freq)
|
| 297 |
+
|
| 298 |
+
if self.scale_rope:
|
| 299 |
+
max_vid_index = max(height // 2, width // 2, max_vid_index)
|
| 300 |
+
else:
|
| 301 |
+
max_vid_index = max(height, width, max_vid_index)
|
| 302 |
+
|
| 303 |
+
max_txt_seq_len_int = int(max_txt_seq_len)
|
| 304 |
+
# Create device-specific copy for text freqs without modifying self.pos_freqs
|
| 305 |
+
txt_freqs = self.pos_freqs.to(device)[max_vid_index : max_vid_index + max_txt_seq_len_int, ...]
|
| 306 |
+
vid_freqs = torch.cat(vid_freqs, dim=0)
|
| 307 |
+
|
| 308 |
+
return vid_freqs, txt_freqs
|
| 309 |
+
|
| 310 |
+
@functools.lru_cache(maxsize=128)
|
| 311 |
+
def _compute_video_freqs(
|
| 312 |
+
self, frame: int, height: int, width: int, idx: int = 0, device: torch.device = None
|
| 313 |
+
) -> torch.Tensor:
|
| 314 |
+
seq_lens = frame * height * width
|
| 315 |
+
pos_freqs = self.pos_freqs.to(device) if device is not None else self.pos_freqs
|
| 316 |
+
neg_freqs = self.neg_freqs.to(device) if device is not None else self.neg_freqs
|
| 317 |
+
|
| 318 |
+
freqs_pos = pos_freqs.split([x // 2 for x in self.axes_dim], dim=1)
|
| 319 |
+
freqs_neg = neg_freqs.split([x // 2 for x in self.axes_dim], dim=1)
|
| 320 |
+
|
| 321 |
+
freqs_frame = freqs_pos[0][idx : idx + frame].view(frame, 1, 1, -1).expand(frame, height, width, -1)
|
| 322 |
+
if self.scale_rope:
|
| 323 |
+
freqs_height = torch.cat([freqs_neg[1][-(height - height // 2) :], freqs_pos[1][: height // 2]], dim=0)
|
| 324 |
+
freqs_height = freqs_height.view(1, height, 1, -1).expand(frame, height, width, -1)
|
| 325 |
+
freqs_width = torch.cat([freqs_neg[2][-(width - width // 2) :], freqs_pos[2][: width // 2]], dim=0)
|
| 326 |
+
freqs_width = freqs_width.view(1, 1, width, -1).expand(frame, height, width, -1)
|
| 327 |
+
else:
|
| 328 |
+
freqs_height = freqs_pos[1][:height].view(1, height, 1, -1).expand(frame, height, width, -1)
|
| 329 |
+
freqs_width = freqs_pos[2][:width].view(1, 1, width, -1).expand(frame, height, width, -1)
|
| 330 |
+
|
| 331 |
+
freqs = torch.cat([freqs_frame, freqs_height, freqs_width], dim=-1).reshape(seq_lens, -1)
|
| 332 |
+
return freqs.clone().contiguous()
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
class NucleusMoEAttnProcessor2_0:
|
| 336 |
+
"""
|
| 337 |
+
Attention processor for the Nucleus MoE architecture. Image queries attend to concatenated image+text keys/values
|
| 338 |
+
(cross-attention style, no text query). Supports grouped-query attention (GQA) when num_key_value_heads is set on
|
| 339 |
+
the Attention module.
|
| 340 |
+
"""
|
| 341 |
+
|
| 342 |
+
_attention_backend = None
|
| 343 |
+
_parallel_config = None
|
| 344 |
+
|
| 345 |
+
def __init__(self):
|
| 346 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 347 |
+
raise ImportError(
|
| 348 |
+
"NucleusMoEAttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
def __call__(
|
| 352 |
+
self,
|
| 353 |
+
attn: Attention,
|
| 354 |
+
hidden_states: torch.FloatTensor,
|
| 355 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 356 |
+
attention_mask: torch.FloatTensor | None = None,
|
| 357 |
+
image_rotary_emb: torch.Tensor | None = None,
|
| 358 |
+
) -> torch.FloatTensor:
|
| 359 |
+
head_dim = attn.inner_dim // attn.heads
|
| 360 |
+
num_kv_heads = attn.inner_kv_dim // head_dim
|
| 361 |
+
num_kv_groups = attn.heads // num_kv_heads
|
| 362 |
+
|
| 363 |
+
img_query = attn.to_q(hidden_states).unflatten(-1, (attn.heads, -1))
|
| 364 |
+
img_key = attn.to_k(hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 365 |
+
img_value = attn.to_v(hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 366 |
+
|
| 367 |
+
if attn.norm_q is not None:
|
| 368 |
+
img_query = attn.norm_q(img_query)
|
| 369 |
+
if attn.norm_k is not None:
|
| 370 |
+
img_key = attn.norm_k(img_key)
|
| 371 |
+
|
| 372 |
+
if image_rotary_emb is not None:
|
| 373 |
+
img_freqs, txt_freqs = image_rotary_emb
|
| 374 |
+
img_query = apply_rotary_emb_nucleus(img_query, img_freqs, use_real=False)
|
| 375 |
+
img_key = apply_rotary_emb_nucleus(img_key, img_freqs, use_real=False)
|
| 376 |
+
|
| 377 |
+
if encoder_hidden_states is not None:
|
| 378 |
+
txt_key = attn.add_k_proj(encoder_hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 379 |
+
txt_value = attn.add_v_proj(encoder_hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 380 |
+
|
| 381 |
+
if attn.norm_added_k is not None:
|
| 382 |
+
txt_key = attn.norm_added_k(txt_key)
|
| 383 |
+
|
| 384 |
+
if image_rotary_emb is not None:
|
| 385 |
+
txt_key = apply_rotary_emb_nucleus(txt_key, txt_freqs, use_real=False)
|
| 386 |
+
|
| 387 |
+
joint_key = torch.cat([img_key, txt_key], dim=1)
|
| 388 |
+
joint_value = torch.cat([img_value, txt_value], dim=1)
|
| 389 |
+
else:
|
| 390 |
+
joint_key = img_key
|
| 391 |
+
joint_value = img_value
|
| 392 |
+
|
| 393 |
+
if num_kv_groups > 1:
|
| 394 |
+
joint_key = joint_key.repeat_interleave(num_kv_groups, dim=2)
|
| 395 |
+
joint_value = joint_value.repeat_interleave(num_kv_groups, dim=2)
|
| 396 |
+
|
| 397 |
+
hidden_states = dispatch_attention_fn(
|
| 398 |
+
img_query,
|
| 399 |
+
joint_key,
|
| 400 |
+
joint_value,
|
| 401 |
+
attn_mask=attention_mask,
|
| 402 |
+
dropout_p=0.0,
|
| 403 |
+
is_causal=False,
|
| 404 |
+
backend=self._attention_backend,
|
| 405 |
+
parallel_config=self._parallel_config,
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
hidden_states = hidden_states.flatten(2, 3)
|
| 409 |
+
hidden_states = hidden_states.to(img_query.dtype)
|
| 410 |
+
|
| 411 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 412 |
+
if len(attn.to_out) > 1:
|
| 413 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 414 |
+
|
| 415 |
+
return hidden_states
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def _is_moe_layer(strategy: str, layer_idx: int, num_layers: int) -> bool:
|
| 419 |
+
if strategy == "leave_first_three_and_last_block_dense":
|
| 420 |
+
return layer_idx >= 3 and layer_idx < num_layers - 1
|
| 421 |
+
elif strategy == "leave_first_three_blocks_dense":
|
| 422 |
+
return layer_idx >= 3
|
| 423 |
+
elif strategy == "leave_first_block_dense":
|
| 424 |
+
return layer_idx >= 1
|
| 425 |
+
elif strategy == "all_moe":
|
| 426 |
+
return True
|
| 427 |
+
elif strategy == "all_dense":
|
| 428 |
+
return False
|
| 429 |
+
return True
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
class NucleusMoELayer(nn.Module):
|
| 433 |
+
"""
|
| 434 |
+
Mixture-of-Experts layer with expert-choice routing and a shared expert.
|
| 435 |
+
|
| 436 |
+
Each expert is a separate ``FeedForward`` module stored in an ``nn.ModuleList``.
|
| 437 |
+
The router concatenates a timestep embedding with the (unmodulated) hidden state
|
| 438 |
+
to produce per-token affinity scores, then selects the top-C tokens per expert
|
| 439 |
+
(expert-choice routing). A shared expert processes all tokens in parallel and its
|
| 440 |
+
output is combined with the routed expert outputs via scatter-add.
|
| 441 |
+
"""
|
| 442 |
+
|
| 443 |
+
def __init__(
|
| 444 |
+
self,
|
| 445 |
+
hidden_size: int,
|
| 446 |
+
moe_intermediate_dim: int,
|
| 447 |
+
num_experts: int,
|
| 448 |
+
capacity_factor: float,
|
| 449 |
+
use_sigmoid: bool,
|
| 450 |
+
route_scale: float,
|
| 451 |
+
):
|
| 452 |
+
super().__init__()
|
| 453 |
+
self.num_experts = num_experts
|
| 454 |
+
self.capacity_factor = capacity_factor
|
| 455 |
+
self.use_sigmoid = use_sigmoid
|
| 456 |
+
self.route_scale = route_scale
|
| 457 |
+
|
| 458 |
+
self.gate = nn.Linear(hidden_size * 2, num_experts, bias=False)
|
| 459 |
+
self.experts = nn.ModuleList(
|
| 460 |
+
[
|
| 461 |
+
FeedForward(
|
| 462 |
+
dim=hidden_size, dim_out=hidden_size,
|
| 463 |
+
inner_dim=moe_intermediate_dim, activation_fn="swiglu", bias=False,
|
| 464 |
+
)
|
| 465 |
+
for _ in range(num_experts)
|
| 466 |
+
]
|
| 467 |
+
)
|
| 468 |
+
self.shared_expert = FeedForward(
|
| 469 |
+
dim=hidden_size, dim_out=hidden_size,
|
| 470 |
+
inner_dim=moe_intermediate_dim, activation_fn="swiglu", bias=False,
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
def forward(
|
| 474 |
+
self,
|
| 475 |
+
hidden_states: torch.Tensor,
|
| 476 |
+
hidden_states_unmodulated: torch.Tensor,
|
| 477 |
+
timestep: torch.Tensor | None = None,
|
| 478 |
+
) -> torch.Tensor:
|
| 479 |
+
bs, slen, dim = hidden_states.shape
|
| 480 |
+
|
| 481 |
+
if timestep is not None:
|
| 482 |
+
timestep_expanded = timestep.unsqueeze(1).expand(-1, slen, -1)
|
| 483 |
+
router_input = torch.cat([timestep_expanded, hidden_states_unmodulated], dim=-1)
|
| 484 |
+
else:
|
| 485 |
+
router_input = hidden_states_unmodulated
|
| 486 |
+
|
| 487 |
+
logits = self.gate(router_input)
|
| 488 |
+
|
| 489 |
+
if self.use_sigmoid:
|
| 490 |
+
scores = torch.sigmoid(logits.float()).to(logits.dtype)
|
| 491 |
+
else:
|
| 492 |
+
scores = F.softmax(logits.float(), dim=-1).to(logits.dtype)
|
| 493 |
+
|
| 494 |
+
affinity = scores.transpose(1, 2) # (B, E, S)
|
| 495 |
+
capacity = max(1, math.ceil(self.capacity_factor * slen / self.num_experts))
|
| 496 |
+
|
| 497 |
+
topk = torch.topk(affinity, k=capacity, dim=-1)
|
| 498 |
+
top_indices = topk.indices # (B, E, C)
|
| 499 |
+
gating = affinity.gather(dim=-1, index=top_indices) # (B, E, C)
|
| 500 |
+
|
| 501 |
+
batch_offsets = torch.arange(bs, device=hidden_states.device, dtype=torch.long).view(bs, 1, 1) * slen
|
| 502 |
+
global_token_indices = (batch_offsets + top_indices).transpose(0, 1).reshape(self.num_experts, -1).reshape(-1)
|
| 503 |
+
gating_flat = gating.transpose(0, 1).reshape(self.num_experts, -1).reshape(-1)
|
| 504 |
+
|
| 505 |
+
token_score_sums = torch.zeros(bs * slen, device=hidden_states.device, dtype=gating_flat.dtype)
|
| 506 |
+
token_score_sums.scatter_add_(0, global_token_indices, gating_flat)
|
| 507 |
+
gating_flat = gating_flat / (token_score_sums[global_token_indices] + 1e-12)
|
| 508 |
+
gating_flat = gating_flat * self.route_scale
|
| 509 |
+
|
| 510 |
+
x_flat = hidden_states.reshape(bs * slen, dim)
|
| 511 |
+
routed_input = x_flat[global_token_indices]
|
| 512 |
+
|
| 513 |
+
tokens_per_expert = bs * capacity
|
| 514 |
+
routed_output_parts = []
|
| 515 |
+
for i, expert in enumerate(self.experts):
|
| 516 |
+
start = i * tokens_per_expert
|
| 517 |
+
end = start + tokens_per_expert
|
| 518 |
+
expert_out = expert(routed_input[start:end])
|
| 519 |
+
routed_output_parts.append(expert_out)
|
| 520 |
+
|
| 521 |
+
routed_output = torch.cat(routed_output_parts, dim=0)
|
| 522 |
+
routed_output = (routed_output.float() * gating_flat.unsqueeze(-1)).to(hidden_states.dtype)
|
| 523 |
+
|
| 524 |
+
out = self.shared_expert(hidden_states).reshape(bs * slen, dim)
|
| 525 |
+
|
| 526 |
+
scatter_idx = global_token_indices.reshape(-1, 1).expand(-1, dim)
|
| 527 |
+
out = out.scatter_add(dim=0, index=scatter_idx, src=routed_output)
|
| 528 |
+
out = out.reshape(bs, slen, dim)
|
| 529 |
+
|
| 530 |
+
return out
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
@maybe_allow_in_graph
|
| 534 |
+
class NucleusMoEImageTransformerBlock(nn.Module):
|
| 535 |
+
"""
|
| 536 |
+
Single-stream DiT block with optional Mixture-of-Experts MLP, matching the DiTBlock
|
| 537 |
+
architecture from model_v2. Only the image stream receives adaptive modulation;
|
| 538 |
+
the text context is projected per-block and used as cross-attention keys/values.
|
| 539 |
+
"""
|
| 540 |
+
|
| 541 |
+
def __init__(
|
| 542 |
+
self,
|
| 543 |
+
dim: int,
|
| 544 |
+
num_attention_heads: int,
|
| 545 |
+
attention_head_dim: int,
|
| 546 |
+
num_key_value_heads: int | None = None,
|
| 547 |
+
joint_attention_dim: int = 3584,
|
| 548 |
+
qk_norm: str = "rms_norm",
|
| 549 |
+
eps: float = 1e-6,
|
| 550 |
+
mlp_ratio: float = 4.0,
|
| 551 |
+
moe_enabled: bool = False,
|
| 552 |
+
num_experts: int = 128,
|
| 553 |
+
moe_intermediate_dim: int = 1344,
|
| 554 |
+
capacity_factor: float = 8.0,
|
| 555 |
+
use_sigmoid: bool = False,
|
| 556 |
+
route_scale: float = 2.5,
|
| 557 |
+
):
|
| 558 |
+
super().__init__()
|
| 559 |
+
self.dim = dim
|
| 560 |
+
self.moe_enabled = moe_enabled
|
| 561 |
+
|
| 562 |
+
self.img_mod = nn.Sequential(
|
| 563 |
+
nn.SiLU(),
|
| 564 |
+
nn.Linear(dim, 4 * dim, bias=True),
|
| 565 |
+
)
|
| 566 |
+
|
| 567 |
+
self.encoder_proj = nn.Linear(joint_attention_dim, dim)
|
| 568 |
+
|
| 569 |
+
self.pre_attn_norm = nn.LayerNorm(dim, eps=eps, elementwise_affine=False, bias=False)
|
| 570 |
+
self.attn = Attention(
|
| 571 |
+
query_dim=dim,
|
| 572 |
+
heads=num_attention_heads,
|
| 573 |
+
kv_heads=num_key_value_heads,
|
| 574 |
+
dim_head=attention_head_dim,
|
| 575 |
+
added_kv_proj_dim=dim,
|
| 576 |
+
added_proj_bias=False,
|
| 577 |
+
out_dim=dim,
|
| 578 |
+
out_bias=False,
|
| 579 |
+
bias=False,
|
| 580 |
+
processor=NucleusMoEAttnProcessor2_0(),
|
| 581 |
+
qk_norm=qk_norm,
|
| 582 |
+
eps=eps,
|
| 583 |
+
context_pre_only=None,
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
self.pre_mlp_norm = nn.LayerNorm(dim, eps=eps, elementwise_affine=False, bias=False)
|
| 587 |
+
|
| 588 |
+
if moe_enabled:
|
| 589 |
+
self.img_mlp = NucleusMoELayer(
|
| 590 |
+
hidden_size=dim,
|
| 591 |
+
moe_intermediate_dim=moe_intermediate_dim,
|
| 592 |
+
num_experts=num_experts,
|
| 593 |
+
capacity_factor=capacity_factor,
|
| 594 |
+
use_sigmoid=use_sigmoid,
|
| 595 |
+
route_scale=route_scale,
|
| 596 |
+
)
|
| 597 |
+
else:
|
| 598 |
+
mlp_inner_dim = int(dim * mlp_ratio * 2 / 3) // 128 * 128
|
| 599 |
+
self.img_mlp = FeedForward(
|
| 600 |
+
dim=dim, dim_out=dim, inner_dim=mlp_inner_dim,
|
| 601 |
+
activation_fn="swiglu", bias=False,
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
def forward(
|
| 605 |
+
self,
|
| 606 |
+
hidden_states: torch.Tensor,
|
| 607 |
+
encoder_hidden_states: torch.Tensor,
|
| 608 |
+
temb: torch.Tensor,
|
| 609 |
+
image_rotary_emb: tuple[torch.Tensor, torch.Tensor] | None = None,
|
| 610 |
+
attention_kwargs: dict[str, Any] | None = None,
|
| 611 |
+
) -> torch.Tensor:
|
| 612 |
+
scale1, gate1, scale2, gate2 = self.img_mod(temb).unsqueeze(1).chunk(4, dim=-1)
|
| 613 |
+
scale1, scale2 = 1 + scale1, 1 + scale2
|
| 614 |
+
|
| 615 |
+
gate1 = gate1.clamp(min=-2.0, max=2.0)
|
| 616 |
+
gate2 = gate2.clamp(min=-2.0, max=2.0)
|
| 617 |
+
|
| 618 |
+
context = self.encoder_proj(encoder_hidden_states)
|
| 619 |
+
|
| 620 |
+
img_normed = self.pre_attn_norm(hidden_states)
|
| 621 |
+
img_modulated = img_normed * scale1
|
| 622 |
+
|
| 623 |
+
attention_kwargs = attention_kwargs or {}
|
| 624 |
+
img_attn_output = self.attn(
|
| 625 |
+
hidden_states=img_modulated,
|
| 626 |
+
encoder_hidden_states=context,
|
| 627 |
+
image_rotary_emb=image_rotary_emb,
|
| 628 |
+
**attention_kwargs,
|
| 629 |
+
)
|
| 630 |
+
|
| 631 |
+
hidden_states = hidden_states + gate1.tanh() * img_attn_output
|
| 632 |
+
|
| 633 |
+
img_normed2 = self.pre_mlp_norm(hidden_states)
|
| 634 |
+
img_modulated2 = img_normed2 * scale2
|
| 635 |
+
|
| 636 |
+
if self.moe_enabled:
|
| 637 |
+
img_mlp_output = self.img_mlp(img_modulated2, img_normed2, timestep=temb)
|
| 638 |
+
else:
|
| 639 |
+
img_mlp_output = self.img_mlp(img_modulated2)
|
| 640 |
+
|
| 641 |
+
hidden_states = hidden_states + gate2.tanh() * img_mlp_output
|
| 642 |
+
|
| 643 |
+
if hidden_states.dtype == torch.float16:
|
| 644 |
+
hidden_states = hidden_states.clip(-65504, 65504)
|
| 645 |
+
|
| 646 |
+
return hidden_states
|
| 647 |
+
|
| 648 |
+
|
| 649 |
+
class NucleusMoEImageTransformer2DModel(
|
| 650 |
+
ModelMixin, ConfigMixin, PeftAdapterMixin, FromOriginalModelMixin, CacheMixin, AttentionMixin
|
| 651 |
+
):
|
| 652 |
+
"""
|
| 653 |
+
Nucleus MoE Transformer for image generation. Single-stream DiT with
|
| 654 |
+
cross-attention to text and optional Mixture-of-Experts feed-forward layers.
|
| 655 |
+
|
| 656 |
+
Args:
|
| 657 |
+
patch_size (`int`, defaults to `2`):
|
| 658 |
+
Patch size to turn the input data into small patches.
|
| 659 |
+
in_channels (`int`, defaults to `64`):
|
| 660 |
+
The number of channels in the input.
|
| 661 |
+
out_channels (`int`, *optional*, defaults to `None`):
|
| 662 |
+
The number of channels in the output. If not specified, it defaults to `in_channels`.
|
| 663 |
+
num_layers (`int`, defaults to `24`):
|
| 664 |
+
The number of transformer blocks.
|
| 665 |
+
attention_head_dim (`int`, defaults to `128`):
|
| 666 |
+
The number of dimensions to use for each attention head.
|
| 667 |
+
num_attention_heads (`int`, defaults to `16`):
|
| 668 |
+
The number of attention heads to use.
|
| 669 |
+
num_key_value_heads (`int`, *optional*):
|
| 670 |
+
The number of key/value heads for grouped-query attention. Defaults to `num_attention_heads`.
|
| 671 |
+
joint_attention_dim (`int`, defaults to `3584`):
|
| 672 |
+
The embedding dimension of the encoder hidden states (text).
|
| 673 |
+
axes_dims_rope (`tuple[int]`, defaults to `(16, 56, 56)`):
|
| 674 |
+
The dimensions to use for the rotary positional embeddings.
|
| 675 |
+
use_layer3d_rope (`bool`, defaults to `False`):
|
| 676 |
+
Whether to use the Layer3D variant of RoPE.
|
| 677 |
+
mlp_ratio (`float`, defaults to `4.0`):
|
| 678 |
+
Multiplier for the MLP hidden dimension in dense (non-MoE) blocks.
|
| 679 |
+
moe_enabled (`bool`, defaults to `True`):
|
| 680 |
+
Whether to use Mixture-of-Experts layers.
|
| 681 |
+
dense_moe_strategy (`str`, defaults to ``"leave_first_three_and_last_block_dense"``):
|
| 682 |
+
Strategy for choosing which layers are MoE vs dense.
|
| 683 |
+
num_experts (`int`, defaults to `128`):
|
| 684 |
+
Number of experts per MoE layer.
|
| 685 |
+
moe_intermediate_dim (`int`, defaults to `1344`):
|
| 686 |
+
Hidden dimension inside each expert.
|
| 687 |
+
capacity_factor (`float`, defaults to `8.0`):
|
| 688 |
+
Expert-choice capacity factor.
|
| 689 |
+
use_sigmoid (`bool`, defaults to `False`):
|
| 690 |
+
Use sigmoid instead of softmax for routing scores.
|
| 691 |
+
route_scale (`float`, defaults to `2.5`):
|
| 692 |
+
Scaling factor applied to routing weights.
|
| 693 |
+
"""
|
| 694 |
+
|
| 695 |
+
_supports_gradient_checkpointing = True
|
| 696 |
+
_no_split_modules = ["NucleusMoEImageTransformerBlock"]
|
| 697 |
+
_skip_layerwise_casting_patterns = ["pos_embed", "norm"]
|
| 698 |
+
_repeated_blocks = ["NucleusMoEImageTransformerBlock"]
|
| 699 |
+
|
| 700 |
+
@register_to_config
|
| 701 |
+
def __init__(
|
| 702 |
+
self,
|
| 703 |
+
patch_size: int = 2,
|
| 704 |
+
in_channels: int = 64,
|
| 705 |
+
out_channels: int | None = None,
|
| 706 |
+
num_layers: int = 24,
|
| 707 |
+
attention_head_dim: int = 128,
|
| 708 |
+
num_attention_heads: int = 16,
|
| 709 |
+
num_key_value_heads: int | None = None,
|
| 710 |
+
joint_attention_dim: int = 3584,
|
| 711 |
+
axes_dims_rope: tuple[int, int, int] = (16, 56, 56),
|
| 712 |
+
mlp_ratio: float = 4.0,
|
| 713 |
+
moe_enabled: bool = True,
|
| 714 |
+
dense_moe_strategy: str = "leave_first_three_and_last_block_dense",
|
| 715 |
+
num_experts: int = 128,
|
| 716 |
+
moe_intermediate_dim: int = 1344,
|
| 717 |
+
capacity_factors: List[float] = [8.0] * 24,
|
| 718 |
+
use_sigmoid: bool = False,
|
| 719 |
+
route_scale: float = 2.5,
|
| 720 |
+
):
|
| 721 |
+
super().__init__()
|
| 722 |
+
self.out_channels = out_channels or in_channels
|
| 723 |
+
self.inner_dim = num_attention_heads * attention_head_dim
|
| 724 |
+
|
| 725 |
+
self.pos_embed = NucleusEmbedRope(theta=10000, axes_dim=list(axes_dims_rope), scale_rope=True)
|
| 726 |
+
|
| 727 |
+
self.time_text_embed = NucleusTimestepProjEmbeddings(embedding_dim=self.inner_dim)
|
| 728 |
+
|
| 729 |
+
self.txt_norm = RMSNorm(joint_attention_dim, eps=1e-6)
|
| 730 |
+
self.img_in = nn.Linear(in_channels, self.inner_dim)
|
| 731 |
+
|
| 732 |
+
self.transformer_blocks = nn.ModuleList(
|
| 733 |
+
[
|
| 734 |
+
NucleusMoEImageTransformerBlock(
|
| 735 |
+
dim=self.inner_dim,
|
| 736 |
+
num_attention_heads=num_attention_heads,
|
| 737 |
+
attention_head_dim=attention_head_dim,
|
| 738 |
+
num_key_value_heads=num_key_value_heads,
|
| 739 |
+
joint_attention_dim=joint_attention_dim,
|
| 740 |
+
mlp_ratio=mlp_ratio,
|
| 741 |
+
moe_enabled=moe_enabled and _is_moe_layer(dense_moe_strategy, idx, num_layers),
|
| 742 |
+
num_experts=num_experts,
|
| 743 |
+
moe_intermediate_dim=moe_intermediate_dim,
|
| 744 |
+
capacity_factor=capacity_factors[idx],
|
| 745 |
+
use_sigmoid=use_sigmoid,
|
| 746 |
+
route_scale=route_scale,
|
| 747 |
+
)
|
| 748 |
+
for idx in range(num_layers)
|
| 749 |
+
]
|
| 750 |
+
)
|
| 751 |
+
|
| 752 |
+
self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
|
| 753 |
+
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=False)
|
| 754 |
+
|
| 755 |
+
self.gradient_checkpointing = False
|
| 756 |
+
|
| 757 |
+
def forward(
|
| 758 |
+
self,
|
| 759 |
+
hidden_states: torch.Tensor,
|
| 760 |
+
img_shapes: list[tuple[int, int, int]] | None = None,
|
| 761 |
+
encoder_hidden_states: torch.Tensor = None,
|
| 762 |
+
encoder_hidden_states_mask: torch.Tensor = None,
|
| 763 |
+
timestep: torch.LongTensor = None,
|
| 764 |
+
txt_seq_lens: list[int] | None = None,
|
| 765 |
+
attention_kwargs: dict[str, Any] | None = None,
|
| 766 |
+
return_dict: bool = True,
|
| 767 |
+
) -> torch.Tensor | Transformer2DModelOutput:
|
| 768 |
+
"""
|
| 769 |
+
The [`NucleusMoEImageTransformer2DModel`] forward method.
|
| 770 |
+
|
| 771 |
+
Args:
|
| 772 |
+
hidden_states (`torch.Tensor` of shape `(batch_size, image_sequence_length, in_channels)`):
|
| 773 |
+
Input `hidden_states`.
|
| 774 |
+
img_shapes (`list[tuple[int, int, int]]`, *optional*):
|
| 775 |
+
Image shapes ``(frame, height, width)`` for RoPE computation.
|
| 776 |
+
encoder_hidden_states (`torch.Tensor` of shape `(batch_size, text_sequence_length, joint_attention_dim)`):
|
| 777 |
+
Conditional embeddings (embeddings computed from the input conditions such as prompts) to use.
|
| 778 |
+
encoder_hidden_states_mask (`torch.Tensor` of shape `(batch_size, text_sequence_length)`, *optional*):
|
| 779 |
+
Boolean mask for the encoder hidden states.
|
| 780 |
+
timestep (`torch.LongTensor`):
|
| 781 |
+
Used to indicate denoising step.
|
| 782 |
+
txt_seq_lens (`list[int]`, *optional*, **Deprecated**):
|
| 783 |
+
Deprecated. Use ``encoder_hidden_states_mask`` instead.
|
| 784 |
+
attention_kwargs (`dict`, *optional*):
|
| 785 |
+
Extra kwargs forwarded to the attention processor.
|
| 786 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 787 |
+
Whether to return a [`~models.transformer_2d.Transformer2DModelOutput`].
|
| 788 |
+
|
| 789 |
+
Returns:
|
| 790 |
+
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
|
| 791 |
+
`tuple` where the first element is the sample tensor.
|
| 792 |
+
"""
|
| 793 |
+
if txt_seq_lens is not None:
|
| 794 |
+
deprecate(
|
| 795 |
+
"txt_seq_lens",
|
| 796 |
+
"0.39.0",
|
| 797 |
+
"Passing `txt_seq_lens` is deprecated and will be removed in version 0.39.0. "
|
| 798 |
+
"Please use `encoder_hidden_states_mask` instead.",
|
| 799 |
+
standard_warn=False,
|
| 800 |
+
)
|
| 801 |
+
|
| 802 |
+
if attention_kwargs is not None:
|
| 803 |
+
attention_kwargs = attention_kwargs.copy()
|
| 804 |
+
lora_scale = attention_kwargs.pop("scale", 1.0)
|
| 805 |
+
else:
|
| 806 |
+
lora_scale = 1.0
|
| 807 |
+
|
| 808 |
+
if USE_PEFT_BACKEND:
|
| 809 |
+
scale_lora_layers(self, lora_scale)
|
| 810 |
+
|
| 811 |
+
hidden_states = self.img_in(hidden_states)
|
| 812 |
+
timestep = timestep.to(hidden_states.dtype)
|
| 813 |
+
|
| 814 |
+
encoder_hidden_states = self.txt_norm(encoder_hidden_states)
|
| 815 |
+
|
| 816 |
+
text_seq_len, _, encoder_hidden_states_mask = compute_text_seq_len_from_mask(
|
| 817 |
+
encoder_hidden_states, encoder_hidden_states_mask
|
| 818 |
+
)
|
| 819 |
+
|
| 820 |
+
temb = self.time_text_embed(timestep, hidden_states)
|
| 821 |
+
|
| 822 |
+
image_rotary_emb = self.pos_embed(img_shapes, max_txt_seq_len=text_seq_len, device=hidden_states.device)
|
| 823 |
+
|
| 824 |
+
block_attention_kwargs = attention_kwargs.copy() if attention_kwargs is not None else {}
|
| 825 |
+
if encoder_hidden_states_mask is not None:
|
| 826 |
+
batch_size, image_seq_len = hidden_states.shape[:2]
|
| 827 |
+
image_mask = torch.ones((batch_size, image_seq_len), dtype=torch.bool, device=hidden_states.device)
|
| 828 |
+
joint_attention_mask = torch.cat([image_mask, encoder_hidden_states_mask], dim=1)
|
| 829 |
+
block_attention_kwargs["attention_mask"] = joint_attention_mask
|
| 830 |
+
|
| 831 |
+
for index_block, block in enumerate(self.transformer_blocks):
|
| 832 |
+
if torch.is_grad_enabled() and self.gradient_checkpointing:
|
| 833 |
+
hidden_states = self._gradient_checkpointing_func(
|
| 834 |
+
block,
|
| 835 |
+
hidden_states,
|
| 836 |
+
encoder_hidden_states,
|
| 837 |
+
temb,
|
| 838 |
+
image_rotary_emb,
|
| 839 |
+
block_attention_kwargs,
|
| 840 |
+
)
|
| 841 |
+
else:
|
| 842 |
+
hidden_states = block(
|
| 843 |
+
hidden_states=hidden_states,
|
| 844 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 845 |
+
temb=temb,
|
| 846 |
+
image_rotary_emb=image_rotary_emb,
|
| 847 |
+
attention_kwargs=block_attention_kwargs,
|
| 848 |
+
)
|
| 849 |
+
|
| 850 |
+
hidden_states = self.norm_out(hidden_states, temb)
|
| 851 |
+
output = self.proj_out(hidden_states)
|
| 852 |
+
|
| 853 |
+
if USE_PEFT_BACKEND:
|
| 854 |
+
unscale_lora_layers(self, lora_scale)
|
| 855 |
+
|
| 856 |
+
if not return_dict:
|
| 857 |
+
return (output,)
|
| 858 |
+
|
| 859 |
+
return Transformer2DModelOutput(sample=output)
|
pipeline_nucleusmoe.py
ADDED
|
@@ -0,0 +1,717 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Nucleus-Image Team and The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import inspect
|
| 16 |
+
from typing import Any, Callable
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
import torch
|
| 20 |
+
from transformers import Qwen3VLForConditionalGeneration, Qwen3VLProcessor
|
| 21 |
+
|
| 22 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 23 |
+
from diffusers.models import AutoencoderKLQwenImage
|
| 24 |
+
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
|
| 25 |
+
from diffusers.schedulers import FlowMatchEulerDiscreteScheduler
|
| 26 |
+
from diffusers.utils import deprecate, is_torch_xla_available, logging, replace_example_docstring
|
| 27 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 28 |
+
|
| 29 |
+
from .modeling_nucleusmoe import NucleusMoEImageTransformer2DModel
|
| 30 |
+
from .pipeline_output import NucleusMoEImagePipelineOutput
|
| 31 |
+
|
| 32 |
+
if is_torch_xla_available():
|
| 33 |
+
import torch_xla.core.xla_model as xm
|
| 34 |
+
|
| 35 |
+
XLA_AVAILABLE = True
|
| 36 |
+
else:
|
| 37 |
+
XLA_AVAILABLE = False
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 41 |
+
|
| 42 |
+
DEFAULT_SYSTEM_PROMPT = (
|
| 43 |
+
"You are an assistant designed to generate photorealistic, ultra-high-quality images based on user prompts."
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
EXAMPLE_DOC_STRING = """
|
| 47 |
+
Examples:
|
| 48 |
+
```py
|
| 49 |
+
>>> import torch
|
| 50 |
+
>>> from diffusers import NucleusMoEImagePipeline
|
| 51 |
+
|
| 52 |
+
>>> pipe = NucleusMoEImagePipeline.from_pretrained(
|
| 53 |
+
... "NucleusAI/Nucleus-MoE-Image", torch_dtype=torch.bfloat16
|
| 54 |
+
... )
|
| 55 |
+
>>> pipe.to("cuda")
|
| 56 |
+
>>> prompt = "A cat holding a sign that says hello world"
|
| 57 |
+
>>> image = pipe(prompt, num_inference_steps=50).images[0]
|
| 58 |
+
>>> image.save("nucleus_moe.png")
|
| 59 |
+
```
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def calculate_shift(
|
| 64 |
+
image_seq_len,
|
| 65 |
+
base_seq_len: int = 256,
|
| 66 |
+
max_seq_len: int = 4096,
|
| 67 |
+
base_shift: float = 0.5,
|
| 68 |
+
max_shift: float = 1.15,
|
| 69 |
+
):
|
| 70 |
+
m = (max_shift - base_shift) / (max_seq_len - base_seq_len)
|
| 71 |
+
b = base_shift - m * base_seq_len
|
| 72 |
+
mu = image_seq_len * m + b
|
| 73 |
+
return mu
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def retrieve_timesteps(
|
| 77 |
+
scheduler,
|
| 78 |
+
num_inference_steps: int | None = None,
|
| 79 |
+
device: str | torch.device | None = None,
|
| 80 |
+
timesteps: list[int] | None = None,
|
| 81 |
+
sigmas: list[float] | None = None,
|
| 82 |
+
**kwargs,
|
| 83 |
+
):
|
| 84 |
+
r"""
|
| 85 |
+
Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
|
| 86 |
+
custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
|
| 87 |
+
|
| 88 |
+
Args:
|
| 89 |
+
scheduler (`SchedulerMixin`):
|
| 90 |
+
The scheduler to get timesteps from.
|
| 91 |
+
num_inference_steps (`int`):
|
| 92 |
+
The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
|
| 93 |
+
must be `None`.
|
| 94 |
+
device (`str` or `torch.device`, *optional*):
|
| 95 |
+
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
|
| 96 |
+
timesteps (`list[int]`, *optional*):
|
| 97 |
+
Custom timesteps used to override the timestep spacing strategy of the scheduler. If `timesteps` is passed,
|
| 98 |
+
`num_inference_steps` and `sigmas` must be `None`.
|
| 99 |
+
sigmas (`list[float]`, *optional*):
|
| 100 |
+
Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
|
| 101 |
+
`num_inference_steps` and `timesteps` must be `None`.
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
`tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and
|
| 105 |
+
the second element is the number of inference steps.
|
| 106 |
+
"""
|
| 107 |
+
if timesteps is not None and sigmas is not None:
|
| 108 |
+
raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")
|
| 109 |
+
if timesteps is not None:
|
| 110 |
+
accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
|
| 111 |
+
if not accepts_timesteps:
|
| 112 |
+
raise ValueError(
|
| 113 |
+
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
|
| 114 |
+
f" timestep schedules. Please check whether you are using the correct scheduler."
|
| 115 |
+
)
|
| 116 |
+
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
|
| 117 |
+
timesteps = scheduler.timesteps
|
| 118 |
+
num_inference_steps = len(timesteps)
|
| 119 |
+
elif sigmas is not None:
|
| 120 |
+
accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
|
| 121 |
+
if not accept_sigmas:
|
| 122 |
+
raise ValueError(
|
| 123 |
+
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
|
| 124 |
+
f" sigmas schedules. Please check whether you are using the correct scheduler."
|
| 125 |
+
)
|
| 126 |
+
scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)
|
| 127 |
+
timesteps = scheduler.timesteps
|
| 128 |
+
num_inference_steps = len(timesteps)
|
| 129 |
+
else:
|
| 130 |
+
scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
|
| 131 |
+
timesteps = scheduler.timesteps
|
| 132 |
+
return timesteps, num_inference_steps
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class NucleusMoEImagePipeline(DiffusionPipeline):
|
| 136 |
+
r"""
|
| 137 |
+
Pipeline for text-to-image generation using Nucleus MoE.
|
| 138 |
+
|
| 139 |
+
This pipeline uses a single-stream DiT with Mixture-of-Experts feed-forward layers,
|
| 140 |
+
cross-attention to a Qwen3-VL text encoder, and a flow-matching Euler discrete scheduler.
|
| 141 |
+
|
| 142 |
+
Args:
|
| 143 |
+
transformer ([`NucleusMoEImageTransformer2DModel`]):
|
| 144 |
+
Conditional Transformer (MMDiT) architecture to denoise the encoded image latents.
|
| 145 |
+
scheduler ([`FlowMatchEulerDiscreteScheduler`]):
|
| 146 |
+
A scheduler to be used in combination with `transformer` to denoise the encoded image latents.
|
| 147 |
+
vae ([`AutoencoderKLQwenImage`]):
|
| 148 |
+
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
|
| 149 |
+
text_encoder ([`Qwen3_VLForConditionalGeneration`]):
|
| 150 |
+
Text encoder for computing prompt embeddings.
|
| 151 |
+
processor ([`Qwen3VLProcessor`]):
|
| 152 |
+
Processor for tokenizing text inputs.
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
model_cpu_offload_seq = "text_encoder->transformer->vae"
|
| 156 |
+
_optional_components = ["processor"]
|
| 157 |
+
_callback_tensor_inputs = ["latents", "prompt_embeds"]
|
| 158 |
+
|
| 159 |
+
@classmethod
|
| 160 |
+
def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
|
| 161 |
+
if "processor" not in kwargs:
|
| 162 |
+
kwargs["processor"] = Qwen3VLProcessor.from_pretrained(
|
| 163 |
+
pretrained_model_name_or_path, subfolder="text_encoder"
|
| 164 |
+
)
|
| 165 |
+
return super().from_pretrained(pretrained_model_name_or_path, **kwargs)
|
| 166 |
+
|
| 167 |
+
def __init__(
|
| 168 |
+
self,
|
| 169 |
+
transformer: NucleusMoEImageTransformer2DModel,
|
| 170 |
+
scheduler: FlowMatchEulerDiscreteScheduler,
|
| 171 |
+
vae: AutoencoderKLQwenImage,
|
| 172 |
+
text_encoder: Qwen3VLForConditionalGeneration,
|
| 173 |
+
processor: Qwen3VLProcessor | None = None,
|
| 174 |
+
):
|
| 175 |
+
super().__init__()
|
| 176 |
+
if processor is None:
|
| 177 |
+
processor_path = (
|
| 178 |
+
getattr(text_encoder, "name_or_path", None)
|
| 179 |
+
or getattr(getattr(text_encoder, "config", None), "_name_or_path", None)
|
| 180 |
+
)
|
| 181 |
+
if processor_path is None:
|
| 182 |
+
raise ValueError(
|
| 183 |
+
"Could not infer a processor path from `text_encoder`; pass `processor=` explicitly."
|
| 184 |
+
)
|
| 185 |
+
processor = Qwen3VLProcessor.from_pretrained(processor_path)
|
| 186 |
+
self.register_modules(
|
| 187 |
+
transformer=transformer,
|
| 188 |
+
scheduler=scheduler,
|
| 189 |
+
vae=vae,
|
| 190 |
+
text_encoder=text_encoder,
|
| 191 |
+
processor=processor,
|
| 192 |
+
)
|
| 193 |
+
self.vae_scale_factor = (
|
| 194 |
+
2 ** len(self.vae.temperal_downsample) if getattr(self, "vae", None) else 8
|
| 195 |
+
)
|
| 196 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor * 2)
|
| 197 |
+
self.default_sample_size = 128
|
| 198 |
+
self.return_index = -8
|
| 199 |
+
|
| 200 |
+
# ------------------------------------------------------------------ #
|
| 201 |
+
# Text encoding (aligned with pipeline.py's chat-template approach) #
|
| 202 |
+
# ------------------------------------------------------------------ #
|
| 203 |
+
|
| 204 |
+
def _format_prompt(self, prompt: str, system_prompt: str | None = None) -> str:
|
| 205 |
+
if system_prompt is None:
|
| 206 |
+
system_prompt = DEFAULT_SYSTEM_PROMPT
|
| 207 |
+
messages = [
|
| 208 |
+
{"role": "system", "content": system_prompt},
|
| 209 |
+
{"role": "user", "content": [{"type": "text", "text": prompt}]},
|
| 210 |
+
]
|
| 211 |
+
return self.processor.apply_chat_template(
|
| 212 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
def encode_prompt(
|
| 216 |
+
self,
|
| 217 |
+
prompt: str | list[str] = None,
|
| 218 |
+
device: torch.device | None = None,
|
| 219 |
+
num_images_per_prompt: int = 1,
|
| 220 |
+
prompt_embeds: torch.Tensor | None = None,
|
| 221 |
+
prompt_embeds_mask: torch.Tensor | None = None,
|
| 222 |
+
max_sequence_length: int = 1024,
|
| 223 |
+
):
|
| 224 |
+
r"""
|
| 225 |
+
Encode text prompt(s) into embeddings using the Qwen3-VL text encoder.
|
| 226 |
+
|
| 227 |
+
Args:
|
| 228 |
+
prompt (`str` or `list[str]`, *optional*):
|
| 229 |
+
The prompt or prompts to encode.
|
| 230 |
+
device (`torch.device`, *optional*):
|
| 231 |
+
Torch device for the resulting tensors.
|
| 232 |
+
num_images_per_prompt (`int`, defaults to 1):
|
| 233 |
+
Number of images to generate per prompt.
|
| 234 |
+
prompt_embeds (`torch.Tensor`, *optional*):
|
| 235 |
+
Pre-generated text embeddings. Skips encoding when provided.
|
| 236 |
+
prompt_embeds_mask (`torch.Tensor`, *optional*):
|
| 237 |
+
Attention mask for pre-generated embeddings.
|
| 238 |
+
max_sequence_length (`int`, defaults to 512):
|
| 239 |
+
Maximum token length for the encoded prompt.
|
| 240 |
+
"""
|
| 241 |
+
device = device or self._execution_device
|
| 242 |
+
|
| 243 |
+
if prompt_embeds is None:
|
| 244 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 245 |
+
formatted = [self._format_prompt(p) for p in prompt]
|
| 246 |
+
|
| 247 |
+
inputs = self.processor(
|
| 248 |
+
text=formatted,
|
| 249 |
+
padding="longest",
|
| 250 |
+
pad_to_multiple_of=8,
|
| 251 |
+
max_length=max_sequence_length,
|
| 252 |
+
truncation=True,
|
| 253 |
+
return_attention_mask=True,
|
| 254 |
+
return_tensors="pt",
|
| 255 |
+
).to(device=device)
|
| 256 |
+
|
| 257 |
+
prompt_embeds_mask = inputs.attention_mask
|
| 258 |
+
|
| 259 |
+
outputs = self.text_encoder(
|
| 260 |
+
**inputs, use_cache=False, return_dict=True, output_hidden_states=True
|
| 261 |
+
)
|
| 262 |
+
prompt_embeds = outputs.hidden_states[self.return_index]
|
| 263 |
+
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
|
| 264 |
+
else:
|
| 265 |
+
prompt_embeds = prompt_embeds.to(device=device)
|
| 266 |
+
if prompt_embeds_mask is not None:
|
| 267 |
+
prompt_embeds_mask = prompt_embeds_mask.to(device=device)
|
| 268 |
+
|
| 269 |
+
if num_images_per_prompt > 1:
|
| 270 |
+
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
| 271 |
+
if prompt_embeds_mask is not None:
|
| 272 |
+
prompt_embeds_mask = prompt_embeds_mask.repeat_interleave(
|
| 273 |
+
num_images_per_prompt, dim=0
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
if prompt_embeds_mask is not None and prompt_embeds_mask.all():
|
| 277 |
+
prompt_embeds_mask = None
|
| 278 |
+
|
| 279 |
+
return prompt_embeds, prompt_embeds_mask
|
| 280 |
+
|
| 281 |
+
# ------------------------------------------------------------------ #
|
| 282 |
+
# Input validation #
|
| 283 |
+
# ------------------------------------------------------------------ #
|
| 284 |
+
|
| 285 |
+
def check_inputs(
|
| 286 |
+
self,
|
| 287 |
+
prompt,
|
| 288 |
+
height,
|
| 289 |
+
width,
|
| 290 |
+
negative_prompt=None,
|
| 291 |
+
prompt_embeds=None,
|
| 292 |
+
negative_prompt_embeds=None,
|
| 293 |
+
prompt_embeds_mask=None,
|
| 294 |
+
negative_prompt_embeds_mask=None,
|
| 295 |
+
callback_on_step_end_tensor_inputs=None,
|
| 296 |
+
max_sequence_length=None,
|
| 297 |
+
):
|
| 298 |
+
if height % (self.vae_scale_factor * 2) != 0 or width % (self.vae_scale_factor * 2) != 0:
|
| 299 |
+
logger.warning(
|
| 300 |
+
f"`height` and `width` have to be divisible by {self.vae_scale_factor * 2} "
|
| 301 |
+
f"but are {height} and {width}. Dimensions will be resized accordingly"
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
if callback_on_step_end_tensor_inputs is not None and not all(
|
| 305 |
+
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
|
| 306 |
+
):
|
| 307 |
+
raise ValueError(
|
| 308 |
+
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, "
|
| 309 |
+
f"but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
if prompt is not None and prompt_embeds is not None:
|
| 313 |
+
raise ValueError(
|
| 314 |
+
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. "
|
| 315 |
+
"Please make sure to only forward one of the two."
|
| 316 |
+
)
|
| 317 |
+
elif prompt is None and prompt_embeds is None:
|
| 318 |
+
raise ValueError(
|
| 319 |
+
"Provide either `prompt` or `prompt_embeds`. Cannot leave both undefined."
|
| 320 |
+
)
|
| 321 |
+
elif prompt is not None and not isinstance(prompt, (str, list)):
|
| 322 |
+
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
| 323 |
+
|
| 324 |
+
if negative_prompt is not None and negative_prompt_embeds is not None:
|
| 325 |
+
raise ValueError(
|
| 326 |
+
f"Cannot forward both `negative_prompt`: {negative_prompt} and "
|
| 327 |
+
f"`negative_prompt_embeds`: {negative_prompt_embeds}. "
|
| 328 |
+
"Please make sure to only forward one of the two."
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
if max_sequence_length is not None and max_sequence_length > 1024:
|
| 332 |
+
raise ValueError(
|
| 333 |
+
f"`max_sequence_length` cannot be greater than 1024 but is {max_sequence_length}"
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
# ------------------------------------------------------------------ #
|
| 337 |
+
# Latent helpers #
|
| 338 |
+
# ------------------------------------------------------------------ #
|
| 339 |
+
|
| 340 |
+
@staticmethod
|
| 341 |
+
def _pack_latents(latents, batch_size, num_channels_latents, height, width):
|
| 342 |
+
latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2)
|
| 343 |
+
latents = latents.permute(0, 2, 4, 1, 3, 5)
|
| 344 |
+
latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4)
|
| 345 |
+
return latents
|
| 346 |
+
|
| 347 |
+
@staticmethod
|
| 348 |
+
def _unpack_latents(latents, height, width, vae_scale_factor):
|
| 349 |
+
batch_size, num_patches, channels = latents.shape
|
| 350 |
+
height = 2 * (int(height) // (vae_scale_factor * 2))
|
| 351 |
+
width = 2 * (int(width) // (vae_scale_factor * 2))
|
| 352 |
+
latents = latents.view(batch_size, height // 2, width // 2, channels // 4, 2, 2)
|
| 353 |
+
latents = latents.permute(0, 3, 1, 4, 2, 5)
|
| 354 |
+
latents = latents.reshape(batch_size, channels // (2 * 2), 1, height, width)
|
| 355 |
+
return latents
|
| 356 |
+
|
| 357 |
+
def prepare_latents(
|
| 358 |
+
self,
|
| 359 |
+
batch_size,
|
| 360 |
+
num_channels_latents,
|
| 361 |
+
height,
|
| 362 |
+
width,
|
| 363 |
+
dtype,
|
| 364 |
+
device,
|
| 365 |
+
generator,
|
| 366 |
+
latents=None,
|
| 367 |
+
):
|
| 368 |
+
height = 2 * (int(height) // (self.vae_scale_factor * 2))
|
| 369 |
+
width = 2 * (int(width) // (self.vae_scale_factor * 2))
|
| 370 |
+
shape = (batch_size, 1, num_channels_latents, height, width)
|
| 371 |
+
|
| 372 |
+
if latents is not None:
|
| 373 |
+
return latents.to(device=device, dtype=dtype)
|
| 374 |
+
|
| 375 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 376 |
+
raise ValueError(
|
| 377 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 378 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 382 |
+
latents = self._pack_latents(latents, batch_size, num_channels_latents, height, width)
|
| 383 |
+
return latents
|
| 384 |
+
|
| 385 |
+
# ------------------------------------------------------------------ #
|
| 386 |
+
# Convenience methods for VAE #
|
| 387 |
+
# ------------------------------------------------------------------ #
|
| 388 |
+
|
| 389 |
+
def enable_vae_slicing(self):
|
| 390 |
+
r"""Enable sliced VAE decoding for memory efficiency."""
|
| 391 |
+
depr_message = (
|
| 392 |
+
f"Calling `enable_vae_slicing()` on a `{self.__class__.__name__}` is deprecated and will be "
|
| 393 |
+
"removed in a future version. Please use `pipe.vae.enable_slicing()`."
|
| 394 |
+
)
|
| 395 |
+
deprecate("enable_vae_slicing", "0.40.0", depr_message)
|
| 396 |
+
self.vae.enable_slicing()
|
| 397 |
+
|
| 398 |
+
def disable_vae_slicing(self):
|
| 399 |
+
r"""Disable sliced VAE decoding."""
|
| 400 |
+
depr_message = (
|
| 401 |
+
f"Calling `disable_vae_slicing()` on a `{self.__class__.__name__}` is deprecated and will be "
|
| 402 |
+
"removed in a future version. Please use `pipe.vae.disable_slicing()`."
|
| 403 |
+
)
|
| 404 |
+
deprecate("disable_vae_slicing", "0.40.0", depr_message)
|
| 405 |
+
self.vae.disable_slicing()
|
| 406 |
+
|
| 407 |
+
def enable_vae_tiling(self):
|
| 408 |
+
r"""Enable tiled VAE decoding for memory efficiency."""
|
| 409 |
+
depr_message = (
|
| 410 |
+
f"Calling `enable_vae_tiling()` on a `{self.__class__.__name__}` is deprecated and will be "
|
| 411 |
+
"removed in a future version. Please use `pipe.vae.enable_tiling()`."
|
| 412 |
+
)
|
| 413 |
+
deprecate("enable_vae_tiling", "0.40.0", depr_message)
|
| 414 |
+
self.vae.enable_tiling()
|
| 415 |
+
|
| 416 |
+
def disable_vae_tiling(self):
|
| 417 |
+
r"""Disable tiled VAE decoding."""
|
| 418 |
+
depr_message = (
|
| 419 |
+
f"Calling `disable_vae_tiling()` on a `{self.__class__.__name__}` is deprecated and will be "
|
| 420 |
+
"removed in a future version. Please use `pipe.vae.disable_tiling()`."
|
| 421 |
+
)
|
| 422 |
+
deprecate("disable_vae_tiling", "0.40.0", depr_message)
|
| 423 |
+
self.vae.disable_tiling()
|
| 424 |
+
|
| 425 |
+
# ------------------------------------------------------------------ #
|
| 426 |
+
# Properties #
|
| 427 |
+
# ------------------------------------------------------------------ #
|
| 428 |
+
|
| 429 |
+
@property
|
| 430 |
+
def attention_kwargs(self):
|
| 431 |
+
return self._attention_kwargs
|
| 432 |
+
|
| 433 |
+
@property
|
| 434 |
+
def num_timesteps(self):
|
| 435 |
+
return self._num_timesteps
|
| 436 |
+
|
| 437 |
+
@property
|
| 438 |
+
def current_timestep(self):
|
| 439 |
+
return self._current_timestep
|
| 440 |
+
|
| 441 |
+
@property
|
| 442 |
+
def interrupt(self):
|
| 443 |
+
return self._interrupt
|
| 444 |
+
|
| 445 |
+
# ------------------------------------------------------------------ #
|
| 446 |
+
# Main call #
|
| 447 |
+
# ------------------------------------------------------------------ #
|
| 448 |
+
|
| 449 |
+
@torch.no_grad()
|
| 450 |
+
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
| 451 |
+
def __call__(
|
| 452 |
+
self,
|
| 453 |
+
prompt: str | list[str] = None,
|
| 454 |
+
negative_prompt: str | list[str] = None,
|
| 455 |
+
true_cfg_scale: float = 4.0,
|
| 456 |
+
height: int | None = None,
|
| 457 |
+
width: int | None = None,
|
| 458 |
+
num_inference_steps: int = 50,
|
| 459 |
+
sigmas: list[float] | None = None,
|
| 460 |
+
num_images_per_prompt: int = 1,
|
| 461 |
+
generator: torch.Generator | list[torch.Generator] | None = None,
|
| 462 |
+
latents: torch.Tensor | None = None,
|
| 463 |
+
prompt_embeds: torch.Tensor | None = None,
|
| 464 |
+
prompt_embeds_mask: torch.Tensor | None = None,
|
| 465 |
+
negative_prompt_embeds: torch.Tensor | None = None,
|
| 466 |
+
negative_prompt_embeds_mask: torch.Tensor | None = None,
|
| 467 |
+
output_type: str | None = "pil",
|
| 468 |
+
return_dict: bool = True,
|
| 469 |
+
attention_kwargs: dict[str, Any] | None = None,
|
| 470 |
+
callback_on_step_end: Callable[[int, int, dict], None] | None = None,
|
| 471 |
+
callback_on_step_end_tensor_inputs: list[str] = ["latents"],
|
| 472 |
+
max_sequence_length: int = 512,
|
| 473 |
+
):
|
| 474 |
+
r"""
|
| 475 |
+
Function invoked when calling the pipeline for generation.
|
| 476 |
+
|
| 477 |
+
Args:
|
| 478 |
+
prompt (`str` or `list[str]`, *optional*):
|
| 479 |
+
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
| 480 |
+
negative_prompt (`str` or `list[str]`, *optional*):
|
| 481 |
+
The prompt or prompts not to guide the image generation. If not defined, an empty string is used
|
| 482 |
+
when `true_cfg_scale > 1`.
|
| 483 |
+
true_cfg_scale (`float`, *optional*, defaults to 4.0):
|
| 484 |
+
Classifier-free guidance scale. Values greater than 1 enable CFG. Higher values produce images
|
| 485 |
+
more closely linked to the text `prompt` at the expense of lower image quality.
|
| 486 |
+
height (`int`, *optional*, defaults to `self.default_sample_size * self.vae_scale_factor`):
|
| 487 |
+
The height in pixels of the generated image.
|
| 488 |
+
width (`int`, *optional*, defaults to `self.default_sample_size * self.vae_scale_factor`):
|
| 489 |
+
The width in pixels of the generated image.
|
| 490 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 491 |
+
The number of denoising steps.
|
| 492 |
+
sigmas (`list[float]`, *optional*):
|
| 493 |
+
Custom sigmas for the denoising schedule. If not defined, a linear schedule is used.
|
| 494 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 495 |
+
The number of images to generate per prompt.
|
| 496 |
+
generator (`torch.Generator` or `list[torch.Generator]`, *optional*):
|
| 497 |
+
One or a list of torch generators to make generation deterministic.
|
| 498 |
+
latents (`torch.Tensor`, *optional*):
|
| 499 |
+
Pre-generated noisy latents to be used as inputs for image generation.
|
| 500 |
+
prompt_embeds (`torch.Tensor`, *optional*):
|
| 501 |
+
Pre-generated text embeddings.
|
| 502 |
+
prompt_embeds_mask (`torch.Tensor`, *optional*):
|
| 503 |
+
Attention mask for pre-generated text embeddings.
|
| 504 |
+
negative_prompt_embeds (`torch.Tensor`, *optional*):
|
| 505 |
+
Pre-generated negative text embeddings.
|
| 506 |
+
negative_prompt_embeds_mask (`torch.Tensor`, *optional*):
|
| 507 |
+
Attention mask for pre-generated negative text embeddings.
|
| 508 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 509 |
+
The output format of the generated image. Choose between `"pil"`, `"np"`, or `"latent"`.
|
| 510 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 511 |
+
Whether or not to return a [`NucleusMoEImagePipelineOutput`] instead of a plain tuple.
|
| 512 |
+
attention_kwargs (`dict`, *optional*):
|
| 513 |
+
Kwargs passed to the attention processor.
|
| 514 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 515 |
+
A function called at the end of each denoising step.
|
| 516 |
+
callback_on_step_end_tensor_inputs (`list`, *optional*):
|
| 517 |
+
Tensor inputs for the `callback_on_step_end` function.
|
| 518 |
+
max_sequence_length (`int`, defaults to 512):
|
| 519 |
+
Maximum sequence length for the text prompt.
|
| 520 |
+
|
| 521 |
+
Examples:
|
| 522 |
+
|
| 523 |
+
Returns:
|
| 524 |
+
[`NucleusMoEImagePipelineOutput`] or `tuple`:
|
| 525 |
+
[`NucleusMoEImagePipelineOutput`] if `return_dict` is True, otherwise a `tuple` where the first
|
| 526 |
+
element is a list with the generated images.
|
| 527 |
+
"""
|
| 528 |
+
|
| 529 |
+
height = height or self.default_sample_size * self.vae_scale_factor
|
| 530 |
+
width = width or self.default_sample_size * self.vae_scale_factor
|
| 531 |
+
|
| 532 |
+
# 1. Check inputs
|
| 533 |
+
self.check_inputs(
|
| 534 |
+
prompt,
|
| 535 |
+
height,
|
| 536 |
+
width,
|
| 537 |
+
negative_prompt=negative_prompt,
|
| 538 |
+
prompt_embeds=prompt_embeds,
|
| 539 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 540 |
+
prompt_embeds_mask=prompt_embeds_mask,
|
| 541 |
+
negative_prompt_embeds_mask=negative_prompt_embeds_mask,
|
| 542 |
+
callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
|
| 543 |
+
max_sequence_length=max_sequence_length,
|
| 544 |
+
)
|
| 545 |
+
|
| 546 |
+
self._attention_kwargs = attention_kwargs or {}
|
| 547 |
+
self._current_timestep = None
|
| 548 |
+
self._interrupt = False
|
| 549 |
+
|
| 550 |
+
# 2. Define call parameters
|
| 551 |
+
if prompt is not None and isinstance(prompt, str):
|
| 552 |
+
batch_size = 1
|
| 553 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 554 |
+
batch_size = len(prompt)
|
| 555 |
+
else:
|
| 556 |
+
batch_size = prompt_embeds.shape[0]
|
| 557 |
+
|
| 558 |
+
device = self._execution_device
|
| 559 |
+
|
| 560 |
+
has_neg_prompt = negative_prompt is not None or (
|
| 561 |
+
negative_prompt_embeds is not None and negative_prompt_embeds_mask is not None
|
| 562 |
+
)
|
| 563 |
+
do_true_cfg = true_cfg_scale > 1
|
| 564 |
+
|
| 565 |
+
if do_true_cfg and not has_neg_prompt:
|
| 566 |
+
negative_prompt = [""] * batch_size
|
| 567 |
+
|
| 568 |
+
# 3. Encode prompts
|
| 569 |
+
prompt_embeds, prompt_embeds_mask = self.encode_prompt(
|
| 570 |
+
prompt=prompt,
|
| 571 |
+
prompt_embeds=prompt_embeds,
|
| 572 |
+
prompt_embeds_mask=prompt_embeds_mask,
|
| 573 |
+
device=device,
|
| 574 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 575 |
+
max_sequence_length=max_sequence_length,
|
| 576 |
+
)
|
| 577 |
+
if do_true_cfg:
|
| 578 |
+
negative_prompt_embeds, negative_prompt_embeds_mask = self.encode_prompt(
|
| 579 |
+
prompt=negative_prompt,
|
| 580 |
+
prompt_embeds=negative_prompt_embeds,
|
| 581 |
+
prompt_embeds_mask=negative_prompt_embeds_mask,
|
| 582 |
+
device=device,
|
| 583 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 584 |
+
max_sequence_length=max_sequence_length,
|
| 585 |
+
)
|
| 586 |
+
|
| 587 |
+
# 4. Prepare latent variables
|
| 588 |
+
num_channels_latents = self.transformer.config.in_channels // 4
|
| 589 |
+
latents = self.prepare_latents(
|
| 590 |
+
batch_size * num_images_per_prompt,
|
| 591 |
+
num_channels_latents,
|
| 592 |
+
height,
|
| 593 |
+
width,
|
| 594 |
+
prompt_embeds.dtype,
|
| 595 |
+
device,
|
| 596 |
+
generator,
|
| 597 |
+
latents,
|
| 598 |
+
)
|
| 599 |
+
|
| 600 |
+
latent_h = 2 * (int(height) // (self.vae_scale_factor * 2))
|
| 601 |
+
latent_w = 2 * (int(width) // (self.vae_scale_factor * 2))
|
| 602 |
+
img_shapes = [(1, latent_h // 2, latent_w // 2)] * (batch_size * num_images_per_prompt)
|
| 603 |
+
|
| 604 |
+
# 5. Prepare timesteps
|
| 605 |
+
sigmas = (
|
| 606 |
+
np.linspace(1.0, 1 / num_inference_steps, num_inference_steps) if sigmas is None else sigmas
|
| 607 |
+
)
|
| 608 |
+
image_seq_len = latents.shape[1]
|
| 609 |
+
mu = calculate_shift(
|
| 610 |
+
image_seq_len,
|
| 611 |
+
self.scheduler.config.get("base_image_seq_len", 256),
|
| 612 |
+
self.scheduler.config.get("max_image_seq_len", 4096),
|
| 613 |
+
self.scheduler.config.get("base_shift", 0.5),
|
| 614 |
+
self.scheduler.config.get("max_shift", 1.15),
|
| 615 |
+
)
|
| 616 |
+
timesteps, num_inference_steps = retrieve_timesteps(
|
| 617 |
+
self.scheduler,
|
| 618 |
+
num_inference_steps,
|
| 619 |
+
device,
|
| 620 |
+
sigmas=sigmas,
|
| 621 |
+
mu=mu,
|
| 622 |
+
)
|
| 623 |
+
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
| 624 |
+
self._num_timesteps = len(timesteps)
|
| 625 |
+
|
| 626 |
+
# 6. Denoising loop
|
| 627 |
+
self.scheduler.set_begin_index(0)
|
| 628 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 629 |
+
for i, t in enumerate(timesteps):
|
| 630 |
+
if self.interrupt:
|
| 631 |
+
continue
|
| 632 |
+
|
| 633 |
+
self._current_timestep = t
|
| 634 |
+
timestep = t.expand(latents.shape[0]).to(latents.dtype)
|
| 635 |
+
|
| 636 |
+
noise_pred = self.transformer(
|
| 637 |
+
hidden_states=latents,
|
| 638 |
+
timestep=timestep / 1000,
|
| 639 |
+
encoder_hidden_states=prompt_embeds,
|
| 640 |
+
encoder_hidden_states_mask=prompt_embeds_mask,
|
| 641 |
+
img_shapes=img_shapes,
|
| 642 |
+
attention_kwargs=self._attention_kwargs,
|
| 643 |
+
return_dict=False,
|
| 644 |
+
)[0]
|
| 645 |
+
|
| 646 |
+
if do_true_cfg:
|
| 647 |
+
neg_noise_pred = self.transformer(
|
| 648 |
+
hidden_states=latents,
|
| 649 |
+
timestep=timestep / 1000,
|
| 650 |
+
encoder_hidden_states=negative_prompt_embeds,
|
| 651 |
+
encoder_hidden_states_mask=negative_prompt_embeds_mask,
|
| 652 |
+
img_shapes=img_shapes,
|
| 653 |
+
attention_kwargs=self._attention_kwargs,
|
| 654 |
+
return_dict=False,
|
| 655 |
+
)[0]
|
| 656 |
+
|
| 657 |
+
comb_pred = neg_noise_pred + true_cfg_scale * (noise_pred - neg_noise_pred)
|
| 658 |
+
cond_norm = torch.norm(noise_pred, dim=-1, keepdim=True)
|
| 659 |
+
noise_norm = torch.norm(comb_pred, dim=-1, keepdim=True)
|
| 660 |
+
noise_pred = comb_pred * (cond_norm / noise_norm)
|
| 661 |
+
|
| 662 |
+
# Model predicts v = clean - noise; scheduler expects noise - clean
|
| 663 |
+
noise_pred = -noise_pred
|
| 664 |
+
|
| 665 |
+
latents_dtype = latents.dtype
|
| 666 |
+
latents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
|
| 667 |
+
|
| 668 |
+
if latents.dtype != latents_dtype:
|
| 669 |
+
if torch.backends.mps.is_available():
|
| 670 |
+
latents = latents.to(latents_dtype)
|
| 671 |
+
|
| 672 |
+
if callback_on_step_end is not None:
|
| 673 |
+
callback_kwargs = {}
|
| 674 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 675 |
+
callback_kwargs[k] = locals()[k]
|
| 676 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 677 |
+
latents = callback_outputs.pop("latents", latents)
|
| 678 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 679 |
+
|
| 680 |
+
if i == len(timesteps) - 1 or (
|
| 681 |
+
(i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0
|
| 682 |
+
):
|
| 683 |
+
progress_bar.update()
|
| 684 |
+
|
| 685 |
+
if XLA_AVAILABLE:
|
| 686 |
+
xm.mark_step()
|
| 687 |
+
|
| 688 |
+
self._current_timestep = None
|
| 689 |
+
|
| 690 |
+
# 7. Decode latents
|
| 691 |
+
if output_type == "latent":
|
| 692 |
+
image = latents
|
| 693 |
+
else:
|
| 694 |
+
latents = self._unpack_latents(latents, height, width, self.vae_scale_factor)
|
| 695 |
+
latents = latents.to(self.vae.dtype)
|
| 696 |
+
latents_mean = (
|
| 697 |
+
torch.tensor(self.vae.config.latents_mean)
|
| 698 |
+
.view(1, self.vae.config.z_dim, 1, 1, 1)
|
| 699 |
+
.to(latents.device, latents.dtype)
|
| 700 |
+
)
|
| 701 |
+
latents_std = (
|
| 702 |
+
1.0
|
| 703 |
+
/ torch.tensor(self.vae.config.latents_std)
|
| 704 |
+
.view(1, self.vae.config.z_dim, 1, 1, 1)
|
| 705 |
+
.to(latents.device, latents.dtype)
|
| 706 |
+
)
|
| 707 |
+
latents = latents / latents_std + latents_mean
|
| 708 |
+
image = self.vae.decode(latents, return_dict=False)[0][:, :, 0]
|
| 709 |
+
image = self.image_processor.postprocess(image, output_type=output_type)
|
| 710 |
+
|
| 711 |
+
# Offload all models
|
| 712 |
+
self.maybe_free_model_hooks()
|
| 713 |
+
|
| 714 |
+
if not return_dict:
|
| 715 |
+
return (image,)
|
| 716 |
+
|
| 717 |
+
return NucleusMoEImagePipelineOutput(images=image)
|
pipeline_output.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import PIL.Image
|
| 5 |
+
|
| 6 |
+
from diffusers.utils import BaseOutput
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@dataclass
|
| 10 |
+
class NucleusMoEImagePipelineOutput(BaseOutput):
|
| 11 |
+
"""
|
| 12 |
+
Output class for Nucleus MoE Image pipelines.
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
images (`list[PIL.Image.Image]` or `np.ndarray`)
|
| 16 |
+
list of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
|
| 17 |
+
num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
images: list[PIL.Image.Image] | np.ndarray
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "FlowMatchEulerDiscreteScheduler",
|
| 3 |
+
"_diffusers_version": "0.36.0",
|
| 4 |
+
"base_image_seq_len": 256,
|
| 5 |
+
"base_shift": 0.5,
|
| 6 |
+
"invert_sigmas": false,
|
| 7 |
+
"max_image_seq_len": 4096,
|
| 8 |
+
"max_shift": 1.15,
|
| 9 |
+
"num_train_timesteps": 1000,
|
| 10 |
+
"shift": 1.0,
|
| 11 |
+
"shift_terminal": null,
|
| 12 |
+
"stochastic_sampling": false,
|
| 13 |
+
"time_shift_type": "exponential",
|
| 14 |
+
"use_beta_sigmas": false,
|
| 15 |
+
"use_dynamic_shifting": false,
|
| 16 |
+
"use_exponential_sigmas": false,
|
| 17 |
+
"use_karras_sigmas": false
|
| 18 |
+
}
|
text_encoder/README.md
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
library_name: transformers
|
| 5 |
+
---
|
| 6 |
+
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
| 7 |
+
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 8 |
+
</a>
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Qwen3-VL-8B-Instruct
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
|
| 15 |
+
|
| 16 |
+
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
|
| 17 |
+
|
| 18 |
+
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
#### Key Enhancements:
|
| 22 |
+
|
| 23 |
+
* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
|
| 24 |
+
|
| 25 |
+
* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.
|
| 26 |
+
|
| 27 |
+
* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
|
| 28 |
+
|
| 29 |
+
* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
|
| 30 |
+
|
| 31 |
+
* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
|
| 32 |
+
|
| 33 |
+
* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
|
| 34 |
+
|
| 35 |
+
* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
|
| 36 |
+
|
| 37 |
+
* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
#### Model Architecture Updates:
|
| 41 |
+
|
| 42 |
+
<p align="center">
|
| 43 |
+
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-VL/qwen3vl_arc.jpg" width="80%"/>
|
| 44 |
+
<p>
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
|
| 48 |
+
|
| 49 |
+
2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.
|
| 50 |
+
|
| 51 |
+
3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
|
| 52 |
+
|
| 53 |
+
This is the weight repository for Qwen3-VL-8B-Instruct.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
---
|
| 57 |
+
|
| 58 |
+
## Model Performance
|
| 59 |
+
|
| 60 |
+
**Multimodal performance**
|
| 61 |
+
|
| 62 |
+
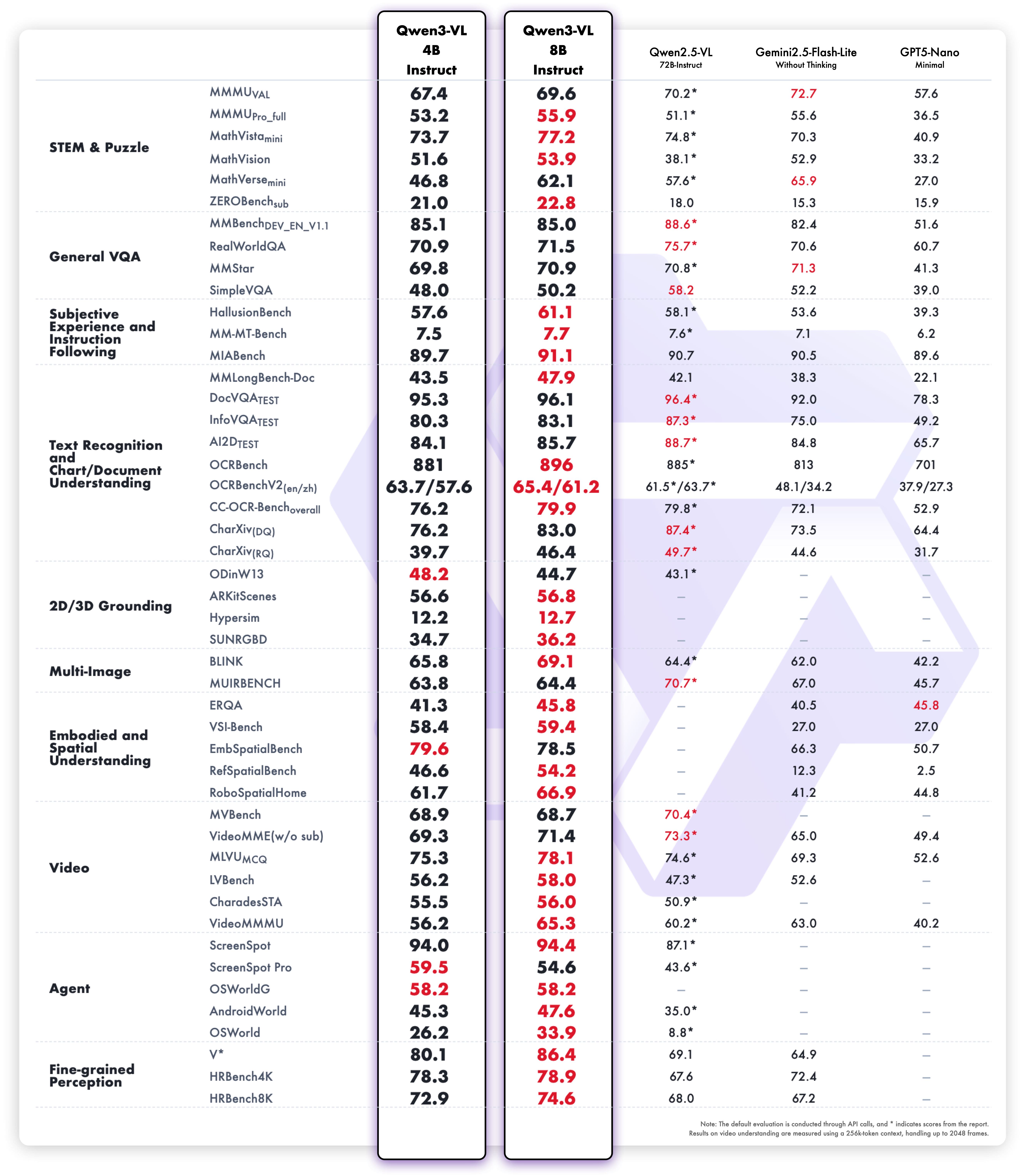
|
| 63 |
+
|
| 64 |
+
**Pure text performance**
|
| 65 |
+
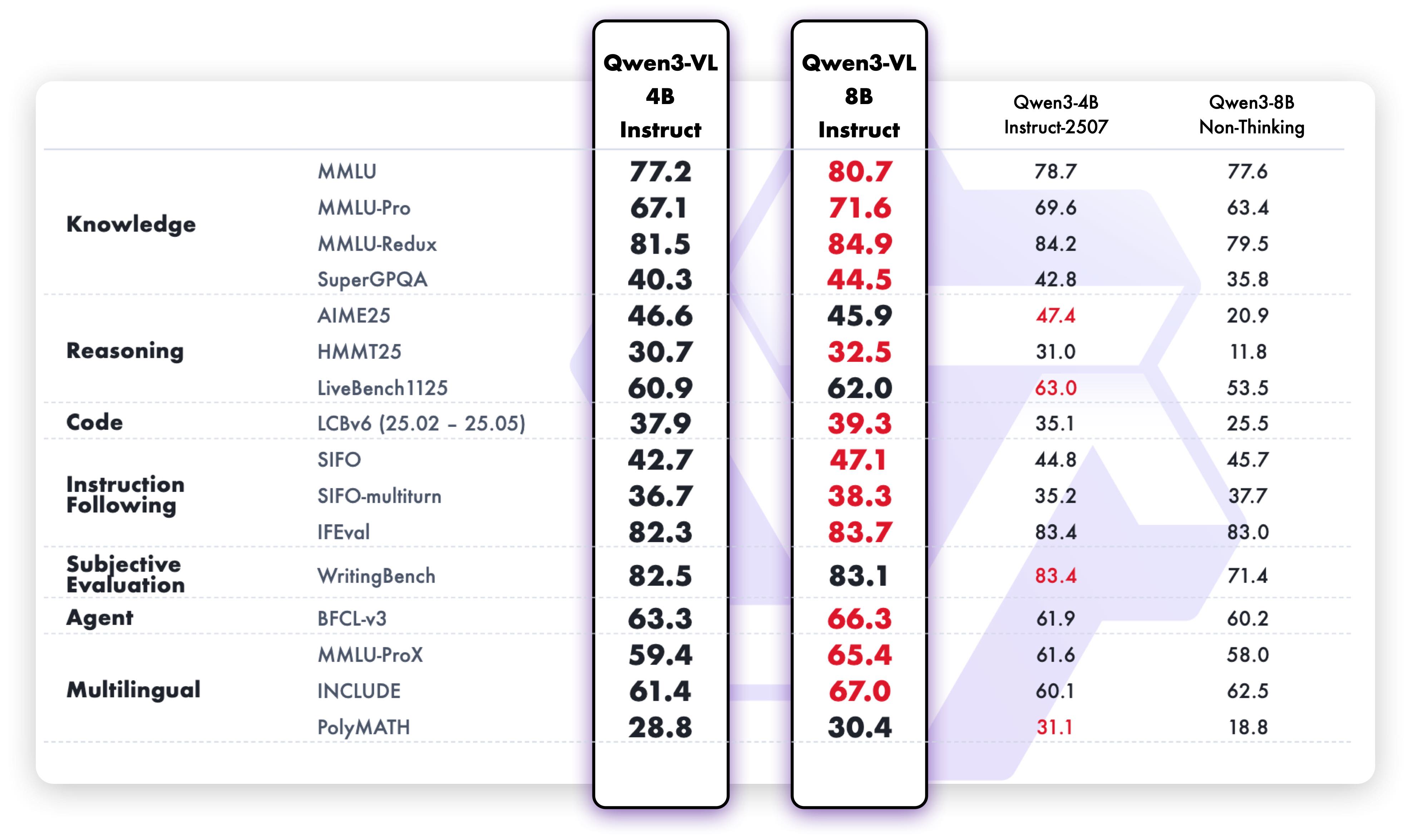
|
| 66 |
+
|
| 67 |
+
## Quickstart
|
| 68 |
+
|
| 69 |
+
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
|
| 70 |
+
|
| 71 |
+
The code of Qwen3-VL has been in the latest Hugging Face transformers and we advise you to build from source with command:
|
| 72 |
+
```
|
| 73 |
+
pip install git+https://github.com/huggingface/transformers
|
| 74 |
+
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
### Using 🤗 Transformers to Chat
|
| 78 |
+
|
| 79 |
+
Here we show a code snippet to show how to use the chat model with `transformers`:
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
|
| 83 |
+
|
| 84 |
+
# default: Load the model on the available device(s)
|
| 85 |
+
model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 86 |
+
"Qwen/Qwen3-VL-8B-Instruct", dtype="auto", device_map="auto"
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 90 |
+
# model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 91 |
+
# "Qwen/Qwen3-VL-8B-Instruct",
|
| 92 |
+
# dtype=torch.bfloat16,
|
| 93 |
+
# attn_implementation="flash_attention_2",
|
| 94 |
+
# device_map="auto",
|
| 95 |
+
# )
|
| 96 |
+
|
| 97 |
+
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-8B-Instruct")
|
| 98 |
+
|
| 99 |
+
messages = [
|
| 100 |
+
{
|
| 101 |
+
"role": "user",
|
| 102 |
+
"content": [
|
| 103 |
+
{
|
| 104 |
+
"type": "image",
|
| 105 |
+
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
|
| 106 |
+
},
|
| 107 |
+
{"type": "text", "text": "Describe this image."},
|
| 108 |
+
],
|
| 109 |
+
}
|
| 110 |
+
]
|
| 111 |
+
|
| 112 |
+
# Preparation for inference
|
| 113 |
+
inputs = processor.apply_chat_template(
|
| 114 |
+
messages,
|
| 115 |
+
tokenize=True,
|
| 116 |
+
add_generation_prompt=True,
|
| 117 |
+
return_dict=True,
|
| 118 |
+
return_tensors="pt"
|
| 119 |
+
)
|
| 120 |
+
inputs = inputs.to(model.device)
|
| 121 |
+
|
| 122 |
+
# Inference: Generation of the output
|
| 123 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 124 |
+
generated_ids_trimmed = [
|
| 125 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 126 |
+
]
|
| 127 |
+
output_text = processor.batch_decode(
|
| 128 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 129 |
+
)
|
| 130 |
+
print(output_text)
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
### Generation Hyperparameters
|
| 134 |
+
#### VL
|
| 135 |
+
```bash
|
| 136 |
+
export greedy='false'
|
| 137 |
+
export top_p=0.8
|
| 138 |
+
export top_k=20
|
| 139 |
+
export temperature=0.7
|
| 140 |
+
export repetition_penalty=1.0
|
| 141 |
+
export presence_penalty=1.5
|
| 142 |
+
export out_seq_length=16384
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
#### Text
|
| 146 |
+
```bash
|
| 147 |
+
export greedy='false'
|
| 148 |
+
export top_p=1.0
|
| 149 |
+
export top_k=40
|
| 150 |
+
export repetition_penalty=1.0
|
| 151 |
+
export presence_penalty=2.0
|
| 152 |
+
export temperature=1.0
|
| 153 |
+
export out_seq_length=32768
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
## Citation
|
| 158 |
+
|
| 159 |
+
If you find our work helpful, feel free to give us a cite.
|
| 160 |
+
|
| 161 |
+
```
|
| 162 |
+
@misc{qwen3technicalreport,
|
| 163 |
+
title={Qwen3 Technical Report},
|
| 164 |
+
author={Qwen Team},
|
| 165 |
+
year={2025},
|
| 166 |
+
eprint={2505.09388},
|
| 167 |
+
archivePrefix={arXiv},
|
| 168 |
+
primaryClass={cs.CL},
|
| 169 |
+
url={https://arxiv.org/abs/2505.09388},
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
@article{Qwen2.5-VL,
|
| 173 |
+
title={Qwen2.5-VL Technical Report},
|
| 174 |
+
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
|
| 175 |
+
journal={arXiv preprint arXiv:2502.13923},
|
| 176 |
+
year={2025}
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
@article{Qwen2VL,
|
| 180 |
+
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
|
| 181 |
+
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
|
| 182 |
+
journal={arXiv preprint arXiv:2409.12191},
|
| 183 |
+
year={2024}
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
@article{Qwen-VL,
|
| 187 |
+
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
|
| 188 |
+
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
|
| 189 |
+
journal={arXiv preprint arXiv:2308.12966},
|
| 190 |
+
year={2023}
|
| 191 |
+
}
|
| 192 |
+
```
|
text_encoder/chat_template.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set image_count = namespace(value=0) %}\n{%- set video_count = namespace(value=0) %}\n{%- for message in messages %}\n {%- if message.role == \"user\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content_item in message.content %}\n {%- if 'text' in content_item %}\n {{- content_item.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and message.content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n"
|
| 3 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen3VLForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"image_token_id": 151655,
|
| 6 |
+
"model_type": "qwen3_vl",
|
| 7 |
+
"text_config": {
|
| 8 |
+
"attention_bias": false,
|
| 9 |
+
"attention_dropout": 0.0,
|
| 10 |
+
"bos_token_id": 151643,
|
| 11 |
+
"dtype": "bfloat16",
|
| 12 |
+
"eos_token_id": 151645,
|
| 13 |
+
"head_dim": 128,
|
| 14 |
+
"hidden_act": "silu",
|
| 15 |
+
"hidden_size": 4096,
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 12288,
|
| 18 |
+
"max_position_embeddings": 262144,
|
| 19 |
+
"model_type": "qwen3_vl_text",
|
| 20 |
+
"num_attention_heads": 32,
|
| 21 |
+
"num_hidden_layers": 36,
|
| 22 |
+
"num_key_value_heads": 8,
|
| 23 |
+
"rms_norm_eps": 1e-06,
|
| 24 |
+
"rope_scaling": {
|
| 25 |
+
"mrope_interleaved": true,
|
| 26 |
+
"mrope_section": [
|
| 27 |
+
24,
|
| 28 |
+
20,
|
| 29 |
+
20
|
| 30 |
+
],
|
| 31 |
+
"rope_type": "default"
|
| 32 |
+
},
|
| 33 |
+
"rope_theta": 5000000,
|
| 34 |
+
"use_cache": true,
|
| 35 |
+
"vocab_size": 151936
|
| 36 |
+
},
|
| 37 |
+
"tie_word_embeddings": false,
|
| 38 |
+
"transformers_version": "4.57.0.dev0",
|
| 39 |
+
"video_token_id": 151656,
|
| 40 |
+
"vision_config": {
|
| 41 |
+
"deepstack_visual_indexes": [
|
| 42 |
+
8,
|
| 43 |
+
16,
|
| 44 |
+
24
|
| 45 |
+
],
|
| 46 |
+
"depth": 27,
|
| 47 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 48 |
+
"hidden_size": 1152,
|
| 49 |
+
"in_channels": 3,
|
| 50 |
+
"initializer_range": 0.02,
|
| 51 |
+
"intermediate_size": 4304,
|
| 52 |
+
"model_type": "qwen3_vl",
|
| 53 |
+
"num_heads": 16,
|
| 54 |
+
"num_position_embeddings": 2304,
|
| 55 |
+
"out_hidden_size": 4096,
|
| 56 |
+
"patch_size": 16,
|
| 57 |
+
"spatial_merge_size": 2,
|
| 58 |
+
"temporal_patch_size": 2
|
| 59 |
+
},
|
| 60 |
+
"vision_end_token_id": 151653,
|
| 61 |
+
"vision_start_token_id": 151652
|
| 62 |
+
}
|
text_encoder/generation_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"pad_token_id": 151643,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": [
|
| 6 |
+
151645,
|
| 7 |
+
151643
|
| 8 |
+
],
|
| 9 |
+
"top_k": 20,
|
| 10 |
+
"top_p": 0.8,
|
| 11 |
+
"repetition_penalty": 1.0,
|
| 12 |
+
"temperature": 0.7,
|
| 13 |
+
"transformers_version": "4.56.0"
|
| 14 |
+
}
|
text_encoder/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
text_encoder/model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d5d0aef0eb170fc7453a296c43c0849a56f510555d3588e4fd662bb35490aefa
|
| 3 |
+
size 4902275944
|
text_encoder/model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8be88fb5501e4d5719a6d4cc212e6a13480330e74f3e8c77daa1a68f199106b5
|
| 3 |
+
size 4915962496
|
text_encoder/model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83de00eafe6e0d57ccd009dbcf71c9974d74df2f016c27afb7e95aafd16b2192
|
| 3 |
+
size 4999831048
|
text_encoder/model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0a88b98e9f96270973f567e6a2c103ede6ccdf915ca3075e21c755604d0377a5
|
| 3 |
+
size 2716270024
|
text_encoder/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,757 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 17534247392
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"model.language_model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"model.language_model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"model.language_model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"model.language_model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"model.language_model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"model.language_model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.language_model.layers.0.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.language_model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.language_model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.language_model.layers.0.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.language_model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.language_model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.language_model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.language_model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.language_model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.language_model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.language_model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.language_model.layers.1.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.language_model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.language_model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"model.language_model.layers.1.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"model.language_model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 29 |
+
"model.language_model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"model.language_model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 31 |
+
"model.language_model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"model.language_model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"model.language_model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"model.language_model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"model.language_model.layers.10.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"model.language_model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.language_model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.language_model.layers.10.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.language_model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.language_model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.language_model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.language_model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.language_model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.language_model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.language_model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.language_model.layers.11.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.language_model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.language_model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.language_model.layers.11.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.language_model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.language_model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.language_model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.language_model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.language_model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.language_model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.language_model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.language_model.layers.12.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.language_model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.language_model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.language_model.layers.12.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.language_model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.language_model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.language_model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.language_model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.language_model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.language_model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.language_model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.language_model.layers.13.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.language_model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.language_model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.language_model.layers.13.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"model.language_model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"model.language_model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.language_model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.language_model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.language_model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.language_model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.language_model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.language_model.layers.14.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"model.language_model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"model.language_model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"model.language_model.layers.14.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"model.language_model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"model.language_model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"model.language_model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 86 |
+
"model.language_model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"model.language_model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"model.language_model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 89 |
+
"model.language_model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"model.language_model.layers.15.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 91 |
+
"model.language_model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"model.language_model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"model.language_model.layers.15.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"model.language_model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"model.language_model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"model.language_model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"model.language_model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 98 |
+
"model.language_model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"model.language_model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"model.language_model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 101 |
+
"model.language_model.layers.16.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"model.language_model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 103 |
+
"model.language_model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"model.language_model.layers.16.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"model.language_model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"model.language_model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"model.language_model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"model.language_model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"model.language_model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 110 |
+
"model.language_model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"model.language_model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"model.language_model.layers.17.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 113 |
+
"model.language_model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"model.language_model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 115 |
+
"model.language_model.layers.17.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"model.language_model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"model.language_model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 118 |
+
"model.language_model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"model.language_model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"model.language_model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 121 |
+
"model.language_model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 122 |
+
"model.language_model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"model.language_model.layers.18.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"model.language_model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 125 |
+
"model.language_model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"model.language_model.layers.18.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 127 |
+
"model.language_model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"model.language_model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 129 |
+
"model.language_model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 130 |
+
"model.language_model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"model.language_model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"model.language_model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 133 |
+
"model.language_model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 134 |
+
"model.language_model.layers.19.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"model.language_model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"model.language_model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 137 |
+
"model.language_model.layers.19.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"model.language_model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 139 |
+
"model.language_model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 140 |
+
"model.language_model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 141 |
+
"model.language_model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 142 |
+
"model.language_model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 143 |
+
"model.language_model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 144 |
+
"model.language_model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 145 |
+
"model.language_model.layers.2.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 146 |
+
"model.language_model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 147 |
+
"model.language_model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 148 |
+
"model.language_model.layers.2.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 149 |
+
"model.language_model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 150 |
+
"model.language_model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 151 |
+
"model.language_model.layers.20.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 152 |
+
"model.language_model.layers.20.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 153 |
+
"model.language_model.layers.20.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 154 |
+
"model.language_model.layers.20.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 155 |
+
"model.language_model.layers.20.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 156 |
+
"model.language_model.layers.20.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 157 |
+
"model.language_model.layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 158 |
+
"model.language_model.layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 159 |
+
"model.language_model.layers.20.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 160 |
+
"model.language_model.layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 161 |
+
"model.language_model.layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 162 |
+
"model.language_model.layers.21.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 163 |
+
"model.language_model.layers.21.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 164 |
+
"model.language_model.layers.21.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 165 |
+
"model.language_model.layers.21.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 166 |
+
"model.language_model.layers.21.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 167 |
+
"model.language_model.layers.21.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 168 |
+
"model.language_model.layers.21.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 169 |
+
"model.language_model.layers.21.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 170 |
+
"model.language_model.layers.21.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 171 |
+
"model.language_model.layers.21.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 172 |
+
"model.language_model.layers.21.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 173 |
+
"model.language_model.layers.22.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 174 |
+
"model.language_model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.language_model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"model.language_model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"model.language_model.layers.22.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 178 |
+
"model.language_model.layers.22.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 179 |
+
"model.language_model.layers.22.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 180 |
+
"model.language_model.layers.22.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 181 |
+
"model.language_model.layers.22.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 182 |
+
"model.language_model.layers.22.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 183 |
+
"model.language_model.layers.22.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 184 |
+
"model.language_model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 185 |
+
"model.language_model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"model.language_model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 187 |
+
"model.language_model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"model.language_model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"model.language_model.layers.23.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"model.language_model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"model.language_model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"model.language_model.layers.23.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"model.language_model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 194 |
+
"model.language_model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"model.language_model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"model.language_model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 197 |
+
"model.language_model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"model.language_model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 199 |
+
"model.language_model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"model.language_model.layers.24.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"model.language_model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"model.language_model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"model.language_model.layers.24.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"model.language_model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"model.language_model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 206 |
+
"model.language_model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"model.language_model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"model.language_model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 209 |
+
"model.language_model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"model.language_model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 211 |
+
"model.language_model.layers.25.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"model.language_model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"model.language_model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"model.language_model.layers.25.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"model.language_model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"model.language_model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"model.language_model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 218 |
+
"model.language_model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"model.language_model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"model.language_model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 221 |
+
"model.language_model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"model.language_model.layers.26.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 223 |
+
"model.language_model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"model.language_model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"model.language_model.layers.26.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"model.language_model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"model.language_model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"model.language_model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"model.language_model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 230 |
+
"model.language_model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"model.language_model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"model.language_model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 233 |
+
"model.language_model.layers.27.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"model.language_model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 235 |
+
"model.language_model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"model.language_model.layers.27.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"model.language_model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"model.language_model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"model.language_model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"model.language_model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"model.language_model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 242 |
+
"model.language_model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"model.language_model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"model.language_model.layers.28.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 245 |
+
"model.language_model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"model.language_model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 247 |
+
"model.language_model.layers.28.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"model.language_model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"model.language_model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"model.language_model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"model.language_model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"model.language_model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"model.language_model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 254 |
+
"model.language_model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"model.language_model.layers.29.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"model.language_model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 257 |
+
"model.language_model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"model.language_model.layers.29.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 259 |
+
"model.language_model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"model.language_model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 261 |
+
"model.language_model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"model.language_model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"model.language_model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"model.language_model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"model.language_model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 266 |
+
"model.language_model.layers.3.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"model.language_model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"model.language_model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 269 |
+
"model.language_model.layers.3.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"model.language_model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 271 |
+
"model.language_model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"model.language_model.layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 273 |
+
"model.language_model.layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 274 |
+
"model.language_model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 275 |
+
"model.language_model.layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 276 |
+
"model.language_model.layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 277 |
+
"model.language_model.layers.30.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 278 |
+
"model.language_model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 279 |
+
"model.language_model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 280 |
+
"model.language_model.layers.30.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 281 |
+
"model.language_model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 282 |
+
"model.language_model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 283 |
+
"model.language_model.layers.31.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 284 |
+
"model.language_model.layers.31.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 285 |
+
"model.language_model.layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 286 |
+
"model.language_model.layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 287 |
+
"model.language_model.layers.31.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 288 |
+
"model.language_model.layers.31.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 289 |
+
"model.language_model.layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 290 |
+
"model.language_model.layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 291 |
+
"model.language_model.layers.31.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 292 |
+
"model.language_model.layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 293 |
+
"model.language_model.layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 294 |
+
"model.language_model.layers.32.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 295 |
+
"model.language_model.layers.32.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 296 |
+
"model.language_model.layers.32.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 297 |
+
"model.language_model.layers.32.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 298 |
+
"model.language_model.layers.32.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 299 |
+
"model.language_model.layers.32.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 300 |
+
"model.language_model.layers.32.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 301 |
+
"model.language_model.layers.32.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 302 |
+
"model.language_model.layers.32.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 303 |
+
"model.language_model.layers.32.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 304 |
+
"model.language_model.layers.32.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 305 |
+
"model.language_model.layers.33.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 306 |
+
"model.language_model.layers.33.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 307 |
+
"model.language_model.layers.33.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 308 |
+
"model.language_model.layers.33.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 309 |
+
"model.language_model.layers.33.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 310 |
+
"model.language_model.layers.33.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 311 |
+
"model.language_model.layers.33.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 312 |
+
"model.language_model.layers.33.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 313 |
+
"model.language_model.layers.33.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 314 |
+
"model.language_model.layers.33.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 315 |
+
"model.language_model.layers.33.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 316 |
+
"model.language_model.layers.34.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 317 |
+
"model.language_model.layers.34.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 318 |
+
"model.language_model.layers.34.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 319 |
+
"model.language_model.layers.34.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 320 |
+
"model.language_model.layers.34.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 321 |
+
"model.language_model.layers.34.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 322 |
+
"model.language_model.layers.34.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 323 |
+
"model.language_model.layers.34.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 324 |
+
"model.language_model.layers.34.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 325 |
+
"model.language_model.layers.34.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 326 |
+
"model.language_model.layers.34.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 327 |
+
"model.language_model.layers.35.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 328 |
+
"model.language_model.layers.35.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 329 |
+
"model.language_model.layers.35.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 330 |
+
"model.language_model.layers.35.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 331 |
+
"model.language_model.layers.35.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 332 |
+
"model.language_model.layers.35.self_attn.k_norm.weight": "model-00004-of-00004.safetensors",
|
| 333 |
+
"model.language_model.layers.35.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 334 |
+
"model.language_model.layers.35.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 335 |
+
"model.language_model.layers.35.self_attn.q_norm.weight": "model-00004-of-00004.safetensors",
|
| 336 |
+
"model.language_model.layers.35.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 337 |
+
"model.language_model.layers.35.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 338 |
+
"model.language_model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 339 |
+
"model.language_model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 340 |
+
"model.language_model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 341 |
+
"model.language_model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 342 |
+
"model.language_model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 343 |
+
"model.language_model.layers.4.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 344 |
+
"model.language_model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 345 |
+
"model.language_model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 346 |
+
"model.language_model.layers.4.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 347 |
+
"model.language_model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 348 |
+
"model.language_model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 349 |
+
"model.language_model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 350 |
+
"model.language_model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 351 |
+
"model.language_model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 352 |
+
"model.language_model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 353 |
+
"model.language_model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 354 |
+
"model.language_model.layers.5.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 355 |
+
"model.language_model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 356 |
+
"model.language_model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"model.language_model.layers.5.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 358 |
+
"model.language_model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"model.language_model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 360 |
+
"model.language_model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 361 |
+
"model.language_model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 362 |
+
"model.language_model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"model.language_model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 364 |
+
"model.language_model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"model.language_model.layers.6.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 366 |
+
"model.language_model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"model.language_model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 368 |
+
"model.language_model.layers.6.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"model.language_model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 370 |
+
"model.language_model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"model.language_model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 372 |
+
"model.language_model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"model.language_model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 374 |
+
"model.language_model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 375 |
+
"model.language_model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 376 |
+
"model.language_model.layers.7.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"model.language_model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 378 |
+
"model.language_model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 379 |
+
"model.language_model.layers.7.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 380 |
+
"model.language_model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 381 |
+
"model.language_model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 382 |
+
"model.language_model.layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 383 |
+
"model.language_model.layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 384 |
+
"model.language_model.layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 385 |
+
"model.language_model.layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 386 |
+
"model.language_model.layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"model.language_model.layers.8.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 388 |
+
"model.language_model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 389 |
+
"model.language_model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 390 |
+
"model.language_model.layers.8.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 391 |
+
"model.language_model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 392 |
+
"model.language_model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 393 |
+
"model.language_model.layers.9.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 394 |
+
"model.language_model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 395 |
+
"model.language_model.layers.9.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 396 |
+
"model.language_model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 397 |
+
"model.language_model.layers.9.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 398 |
+
"model.language_model.layers.9.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 399 |
+
"model.language_model.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 400 |
+
"model.language_model.layers.9.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 401 |
+
"model.language_model.layers.9.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 402 |
+
"model.language_model.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 403 |
+
"model.language_model.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 404 |
+
"model.language_model.norm.weight": "model-00004-of-00004.safetensors",
|
| 405 |
+
"model.visual.blocks.0.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 406 |
+
"model.visual.blocks.0.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 407 |
+
"model.visual.blocks.0.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 408 |
+
"model.visual.blocks.0.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 409 |
+
"model.visual.blocks.0.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 410 |
+
"model.visual.blocks.0.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 411 |
+
"model.visual.blocks.0.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 412 |
+
"model.visual.blocks.0.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 413 |
+
"model.visual.blocks.0.norm1.bias": "model-00004-of-00004.safetensors",
|
| 414 |
+
"model.visual.blocks.0.norm1.weight": "model-00004-of-00004.safetensors",
|
| 415 |
+
"model.visual.blocks.0.norm2.bias": "model-00004-of-00004.safetensors",
|
| 416 |
+
"model.visual.blocks.0.norm2.weight": "model-00004-of-00004.safetensors",
|
| 417 |
+
"model.visual.blocks.1.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 418 |
+
"model.visual.blocks.1.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 419 |
+
"model.visual.blocks.1.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 420 |
+
"model.visual.blocks.1.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 421 |
+
"model.visual.blocks.1.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 422 |
+
"model.visual.blocks.1.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 423 |
+
"model.visual.blocks.1.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 424 |
+
"model.visual.blocks.1.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 425 |
+
"model.visual.blocks.1.norm1.bias": "model-00004-of-00004.safetensors",
|
| 426 |
+
"model.visual.blocks.1.norm1.weight": "model-00004-of-00004.safetensors",
|
| 427 |
+
"model.visual.blocks.1.norm2.bias": "model-00004-of-00004.safetensors",
|
| 428 |
+
"model.visual.blocks.1.norm2.weight": "model-00004-of-00004.safetensors",
|
| 429 |
+
"model.visual.blocks.10.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 430 |
+
"model.visual.blocks.10.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 431 |
+
"model.visual.blocks.10.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 432 |
+
"model.visual.blocks.10.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 433 |
+
"model.visual.blocks.10.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 434 |
+
"model.visual.blocks.10.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 435 |
+
"model.visual.blocks.10.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 436 |
+
"model.visual.blocks.10.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 437 |
+
"model.visual.blocks.10.norm1.bias": "model-00004-of-00004.safetensors",
|
| 438 |
+
"model.visual.blocks.10.norm1.weight": "model-00004-of-00004.safetensors",
|
| 439 |
+
"model.visual.blocks.10.norm2.bias": "model-00004-of-00004.safetensors",
|
| 440 |
+
"model.visual.blocks.10.norm2.weight": "model-00004-of-00004.safetensors",
|
| 441 |
+
"model.visual.blocks.11.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 442 |
+
"model.visual.blocks.11.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 443 |
+
"model.visual.blocks.11.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 444 |
+
"model.visual.blocks.11.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 445 |
+
"model.visual.blocks.11.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 446 |
+
"model.visual.blocks.11.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 447 |
+
"model.visual.blocks.11.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 448 |
+
"model.visual.blocks.11.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 449 |
+
"model.visual.blocks.11.norm1.bias": "model-00004-of-00004.safetensors",
|
| 450 |
+
"model.visual.blocks.11.norm1.weight": "model-00004-of-00004.safetensors",
|
| 451 |
+
"model.visual.blocks.11.norm2.bias": "model-00004-of-00004.safetensors",
|
| 452 |
+
"model.visual.blocks.11.norm2.weight": "model-00004-of-00004.safetensors",
|
| 453 |
+
"model.visual.blocks.12.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 454 |
+
"model.visual.blocks.12.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 455 |
+
"model.visual.blocks.12.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 456 |
+
"model.visual.blocks.12.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 457 |
+
"model.visual.blocks.12.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 458 |
+
"model.visual.blocks.12.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 459 |
+
"model.visual.blocks.12.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 460 |
+
"model.visual.blocks.12.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 461 |
+
"model.visual.blocks.12.norm1.bias": "model-00004-of-00004.safetensors",
|
| 462 |
+
"model.visual.blocks.12.norm1.weight": "model-00004-of-00004.safetensors",
|
| 463 |
+
"model.visual.blocks.12.norm2.bias": "model-00004-of-00004.safetensors",
|
| 464 |
+
"model.visual.blocks.12.norm2.weight": "model-00004-of-00004.safetensors",
|
| 465 |
+
"model.visual.blocks.13.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 466 |
+
"model.visual.blocks.13.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 467 |
+
"model.visual.blocks.13.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 468 |
+
"model.visual.blocks.13.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 469 |
+
"model.visual.blocks.13.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 470 |
+
"model.visual.blocks.13.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 471 |
+
"model.visual.blocks.13.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 472 |
+
"model.visual.blocks.13.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 473 |
+
"model.visual.blocks.13.norm1.bias": "model-00004-of-00004.safetensors",
|
| 474 |
+
"model.visual.blocks.13.norm1.weight": "model-00004-of-00004.safetensors",
|
| 475 |
+
"model.visual.blocks.13.norm2.bias": "model-00004-of-00004.safetensors",
|
| 476 |
+
"model.visual.blocks.13.norm2.weight": "model-00004-of-00004.safetensors",
|
| 477 |
+
"model.visual.blocks.14.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 478 |
+
"model.visual.blocks.14.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 479 |
+
"model.visual.blocks.14.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 480 |
+
"model.visual.blocks.14.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 481 |
+
"model.visual.blocks.14.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 482 |
+
"model.visual.blocks.14.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 483 |
+
"model.visual.blocks.14.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 484 |
+
"model.visual.blocks.14.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 485 |
+
"model.visual.blocks.14.norm1.bias": "model-00004-of-00004.safetensors",
|
| 486 |
+
"model.visual.blocks.14.norm1.weight": "model-00004-of-00004.safetensors",
|
| 487 |
+
"model.visual.blocks.14.norm2.bias": "model-00004-of-00004.safetensors",
|
| 488 |
+
"model.visual.blocks.14.norm2.weight": "model-00004-of-00004.safetensors",
|
| 489 |
+
"model.visual.blocks.15.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 490 |
+
"model.visual.blocks.15.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 491 |
+
"model.visual.blocks.15.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 492 |
+
"model.visual.blocks.15.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 493 |
+
"model.visual.blocks.15.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 494 |
+
"model.visual.blocks.15.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 495 |
+
"model.visual.blocks.15.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 496 |
+
"model.visual.blocks.15.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 497 |
+
"model.visual.blocks.15.norm1.bias": "model-00004-of-00004.safetensors",
|
| 498 |
+
"model.visual.blocks.15.norm1.weight": "model-00004-of-00004.safetensors",
|
| 499 |
+
"model.visual.blocks.15.norm2.bias": "model-00004-of-00004.safetensors",
|
| 500 |
+
"model.visual.blocks.15.norm2.weight": "model-00004-of-00004.safetensors",
|
| 501 |
+
"model.visual.blocks.16.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 502 |
+
"model.visual.blocks.16.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 503 |
+
"model.visual.blocks.16.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 504 |
+
"model.visual.blocks.16.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 505 |
+
"model.visual.blocks.16.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 506 |
+
"model.visual.blocks.16.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 507 |
+
"model.visual.blocks.16.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 508 |
+
"model.visual.blocks.16.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 509 |
+
"model.visual.blocks.16.norm1.bias": "model-00004-of-00004.safetensors",
|
| 510 |
+
"model.visual.blocks.16.norm1.weight": "model-00004-of-00004.safetensors",
|
| 511 |
+
"model.visual.blocks.16.norm2.bias": "model-00004-of-00004.safetensors",
|
| 512 |
+
"model.visual.blocks.16.norm2.weight": "model-00004-of-00004.safetensors",
|
| 513 |
+
"model.visual.blocks.17.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 514 |
+
"model.visual.blocks.17.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 515 |
+
"model.visual.blocks.17.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 516 |
+
"model.visual.blocks.17.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 517 |
+
"model.visual.blocks.17.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 518 |
+
"model.visual.blocks.17.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 519 |
+
"model.visual.blocks.17.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 520 |
+
"model.visual.blocks.17.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 521 |
+
"model.visual.blocks.17.norm1.bias": "model-00004-of-00004.safetensors",
|
| 522 |
+
"model.visual.blocks.17.norm1.weight": "model-00004-of-00004.safetensors",
|
| 523 |
+
"model.visual.blocks.17.norm2.bias": "model-00004-of-00004.safetensors",
|
| 524 |
+
"model.visual.blocks.17.norm2.weight": "model-00004-of-00004.safetensors",
|
| 525 |
+
"model.visual.blocks.18.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 526 |
+
"model.visual.blocks.18.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 527 |
+
"model.visual.blocks.18.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 528 |
+
"model.visual.blocks.18.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 529 |
+
"model.visual.blocks.18.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 530 |
+
"model.visual.blocks.18.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 531 |
+
"model.visual.blocks.18.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 532 |
+
"model.visual.blocks.18.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 533 |
+
"model.visual.blocks.18.norm1.bias": "model-00004-of-00004.safetensors",
|
| 534 |
+
"model.visual.blocks.18.norm1.weight": "model-00004-of-00004.safetensors",
|
| 535 |
+
"model.visual.blocks.18.norm2.bias": "model-00004-of-00004.safetensors",
|
| 536 |
+
"model.visual.blocks.18.norm2.weight": "model-00004-of-00004.safetensors",
|
| 537 |
+
"model.visual.blocks.19.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 538 |
+
"model.visual.blocks.19.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 539 |
+
"model.visual.blocks.19.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 540 |
+
"model.visual.blocks.19.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 541 |
+
"model.visual.blocks.19.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 542 |
+
"model.visual.blocks.19.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 543 |
+
"model.visual.blocks.19.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 544 |
+
"model.visual.blocks.19.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 545 |
+
"model.visual.blocks.19.norm1.bias": "model-00004-of-00004.safetensors",
|
| 546 |
+
"model.visual.blocks.19.norm1.weight": "model-00004-of-00004.safetensors",
|
| 547 |
+
"model.visual.blocks.19.norm2.bias": "model-00004-of-00004.safetensors",
|
| 548 |
+
"model.visual.blocks.19.norm2.weight": "model-00004-of-00004.safetensors",
|
| 549 |
+
"model.visual.blocks.2.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 550 |
+
"model.visual.blocks.2.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 551 |
+
"model.visual.blocks.2.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 552 |
+
"model.visual.blocks.2.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 553 |
+
"model.visual.blocks.2.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 554 |
+
"model.visual.blocks.2.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 555 |
+
"model.visual.blocks.2.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 556 |
+
"model.visual.blocks.2.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 557 |
+
"model.visual.blocks.2.norm1.bias": "model-00004-of-00004.safetensors",
|
| 558 |
+
"model.visual.blocks.2.norm1.weight": "model-00004-of-00004.safetensors",
|
| 559 |
+
"model.visual.blocks.2.norm2.bias": "model-00004-of-00004.safetensors",
|
| 560 |
+
"model.visual.blocks.2.norm2.weight": "model-00004-of-00004.safetensors",
|
| 561 |
+
"model.visual.blocks.20.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 562 |
+
"model.visual.blocks.20.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 563 |
+
"model.visual.blocks.20.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 564 |
+
"model.visual.blocks.20.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 565 |
+
"model.visual.blocks.20.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 566 |
+
"model.visual.blocks.20.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 567 |
+
"model.visual.blocks.20.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 568 |
+
"model.visual.blocks.20.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 569 |
+
"model.visual.blocks.20.norm1.bias": "model-00004-of-00004.safetensors",
|
| 570 |
+
"model.visual.blocks.20.norm1.weight": "model-00004-of-00004.safetensors",
|
| 571 |
+
"model.visual.blocks.20.norm2.bias": "model-00004-of-00004.safetensors",
|
| 572 |
+
"model.visual.blocks.20.norm2.weight": "model-00004-of-00004.safetensors",
|
| 573 |
+
"model.visual.blocks.21.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 574 |
+
"model.visual.blocks.21.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 575 |
+
"model.visual.blocks.21.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 576 |
+
"model.visual.blocks.21.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 577 |
+
"model.visual.blocks.21.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 578 |
+
"model.visual.blocks.21.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 579 |
+
"model.visual.blocks.21.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 580 |
+
"model.visual.blocks.21.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 581 |
+
"model.visual.blocks.21.norm1.bias": "model-00004-of-00004.safetensors",
|
| 582 |
+
"model.visual.blocks.21.norm1.weight": "model-00004-of-00004.safetensors",
|
| 583 |
+
"model.visual.blocks.21.norm2.bias": "model-00004-of-00004.safetensors",
|
| 584 |
+
"model.visual.blocks.21.norm2.weight": "model-00004-of-00004.safetensors",
|
| 585 |
+
"model.visual.blocks.22.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 586 |
+
"model.visual.blocks.22.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 587 |
+
"model.visual.blocks.22.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 588 |
+
"model.visual.blocks.22.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 589 |
+
"model.visual.blocks.22.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 590 |
+
"model.visual.blocks.22.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 591 |
+
"model.visual.blocks.22.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 592 |
+
"model.visual.blocks.22.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 593 |
+
"model.visual.blocks.22.norm1.bias": "model-00004-of-00004.safetensors",
|
| 594 |
+
"model.visual.blocks.22.norm1.weight": "model-00004-of-00004.safetensors",
|
| 595 |
+
"model.visual.blocks.22.norm2.bias": "model-00004-of-00004.safetensors",
|
| 596 |
+
"model.visual.blocks.22.norm2.weight": "model-00004-of-00004.safetensors",
|
| 597 |
+
"model.visual.blocks.23.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 598 |
+
"model.visual.blocks.23.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 599 |
+
"model.visual.blocks.23.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 600 |
+
"model.visual.blocks.23.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 601 |
+
"model.visual.blocks.23.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 602 |
+
"model.visual.blocks.23.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 603 |
+
"model.visual.blocks.23.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 604 |
+
"model.visual.blocks.23.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 605 |
+
"model.visual.blocks.23.norm1.bias": "model-00004-of-00004.safetensors",
|
| 606 |
+
"model.visual.blocks.23.norm1.weight": "model-00004-of-00004.safetensors",
|
| 607 |
+
"model.visual.blocks.23.norm2.bias": "model-00004-of-00004.safetensors",
|
| 608 |
+
"model.visual.blocks.23.norm2.weight": "model-00004-of-00004.safetensors",
|
| 609 |
+
"model.visual.blocks.24.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 610 |
+
"model.visual.blocks.24.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 611 |
+
"model.visual.blocks.24.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 612 |
+
"model.visual.blocks.24.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 613 |
+
"model.visual.blocks.24.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 614 |
+
"model.visual.blocks.24.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 615 |
+
"model.visual.blocks.24.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 616 |
+
"model.visual.blocks.24.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 617 |
+
"model.visual.blocks.24.norm1.bias": "model-00004-of-00004.safetensors",
|
| 618 |
+
"model.visual.blocks.24.norm1.weight": "model-00004-of-00004.safetensors",
|
| 619 |
+
"model.visual.blocks.24.norm2.bias": "model-00004-of-00004.safetensors",
|
| 620 |
+
"model.visual.blocks.24.norm2.weight": "model-00004-of-00004.safetensors",
|
| 621 |
+
"model.visual.blocks.25.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 622 |
+
"model.visual.blocks.25.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 623 |
+
"model.visual.blocks.25.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 624 |
+
"model.visual.blocks.25.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 625 |
+
"model.visual.blocks.25.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 626 |
+
"model.visual.blocks.25.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 627 |
+
"model.visual.blocks.25.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 628 |
+
"model.visual.blocks.25.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 629 |
+
"model.visual.blocks.25.norm1.bias": "model-00004-of-00004.safetensors",
|
| 630 |
+
"model.visual.blocks.25.norm1.weight": "model-00004-of-00004.safetensors",
|
| 631 |
+
"model.visual.blocks.25.norm2.bias": "model-00004-of-00004.safetensors",
|
| 632 |
+
"model.visual.blocks.25.norm2.weight": "model-00004-of-00004.safetensors",
|
| 633 |
+
"model.visual.blocks.26.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 634 |
+
"model.visual.blocks.26.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 635 |
+
"model.visual.blocks.26.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 636 |
+
"model.visual.blocks.26.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 637 |
+
"model.visual.blocks.26.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 638 |
+
"model.visual.blocks.26.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 639 |
+
"model.visual.blocks.26.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 640 |
+
"model.visual.blocks.26.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 641 |
+
"model.visual.blocks.26.norm1.bias": "model-00004-of-00004.safetensors",
|
| 642 |
+
"model.visual.blocks.26.norm1.weight": "model-00004-of-00004.safetensors",
|
| 643 |
+
"model.visual.blocks.26.norm2.bias": "model-00004-of-00004.safetensors",
|
| 644 |
+
"model.visual.blocks.26.norm2.weight": "model-00004-of-00004.safetensors",
|
| 645 |
+
"model.visual.blocks.3.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 646 |
+
"model.visual.blocks.3.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 647 |
+
"model.visual.blocks.3.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 648 |
+
"model.visual.blocks.3.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 649 |
+
"model.visual.blocks.3.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 650 |
+
"model.visual.blocks.3.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 651 |
+
"model.visual.blocks.3.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 652 |
+
"model.visual.blocks.3.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 653 |
+
"model.visual.blocks.3.norm1.bias": "model-00004-of-00004.safetensors",
|
| 654 |
+
"model.visual.blocks.3.norm1.weight": "model-00004-of-00004.safetensors",
|
| 655 |
+
"model.visual.blocks.3.norm2.bias": "model-00004-of-00004.safetensors",
|
| 656 |
+
"model.visual.blocks.3.norm2.weight": "model-00004-of-00004.safetensors",
|
| 657 |
+
"model.visual.blocks.4.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 658 |
+
"model.visual.blocks.4.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 659 |
+
"model.visual.blocks.4.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 660 |
+
"model.visual.blocks.4.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 661 |
+
"model.visual.blocks.4.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 662 |
+
"model.visual.blocks.4.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 663 |
+
"model.visual.blocks.4.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 664 |
+
"model.visual.blocks.4.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 665 |
+
"model.visual.blocks.4.norm1.bias": "model-00004-of-00004.safetensors",
|
| 666 |
+
"model.visual.blocks.4.norm1.weight": "model-00004-of-00004.safetensors",
|
| 667 |
+
"model.visual.blocks.4.norm2.bias": "model-00004-of-00004.safetensors",
|
| 668 |
+
"model.visual.blocks.4.norm2.weight": "model-00004-of-00004.safetensors",
|
| 669 |
+
"model.visual.blocks.5.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 670 |
+
"model.visual.blocks.5.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 671 |
+
"model.visual.blocks.5.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 672 |
+
"model.visual.blocks.5.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 673 |
+
"model.visual.blocks.5.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 674 |
+
"model.visual.blocks.5.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 675 |
+
"model.visual.blocks.5.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 676 |
+
"model.visual.blocks.5.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 677 |
+
"model.visual.blocks.5.norm1.bias": "model-00004-of-00004.safetensors",
|
| 678 |
+
"model.visual.blocks.5.norm1.weight": "model-00004-of-00004.safetensors",
|
| 679 |
+
"model.visual.blocks.5.norm2.bias": "model-00004-of-00004.safetensors",
|
| 680 |
+
"model.visual.blocks.5.norm2.weight": "model-00004-of-00004.safetensors",
|
| 681 |
+
"model.visual.blocks.6.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 682 |
+
"model.visual.blocks.6.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 683 |
+
"model.visual.blocks.6.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 684 |
+
"model.visual.blocks.6.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 685 |
+
"model.visual.blocks.6.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 686 |
+
"model.visual.blocks.6.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 687 |
+
"model.visual.blocks.6.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 688 |
+
"model.visual.blocks.6.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 689 |
+
"model.visual.blocks.6.norm1.bias": "model-00004-of-00004.safetensors",
|
| 690 |
+
"model.visual.blocks.6.norm1.weight": "model-00004-of-00004.safetensors",
|
| 691 |
+
"model.visual.blocks.6.norm2.bias": "model-00004-of-00004.safetensors",
|
| 692 |
+
"model.visual.blocks.6.norm2.weight": "model-00004-of-00004.safetensors",
|
| 693 |
+
"model.visual.blocks.7.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 694 |
+
"model.visual.blocks.7.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 695 |
+
"model.visual.blocks.7.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 696 |
+
"model.visual.blocks.7.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 697 |
+
"model.visual.blocks.7.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 698 |
+
"model.visual.blocks.7.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 699 |
+
"model.visual.blocks.7.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 700 |
+
"model.visual.blocks.7.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 701 |
+
"model.visual.blocks.7.norm1.bias": "model-00004-of-00004.safetensors",
|
| 702 |
+
"model.visual.blocks.7.norm1.weight": "model-00004-of-00004.safetensors",
|
| 703 |
+
"model.visual.blocks.7.norm2.bias": "model-00004-of-00004.safetensors",
|
| 704 |
+
"model.visual.blocks.7.norm2.weight": "model-00004-of-00004.safetensors",
|
| 705 |
+
"model.visual.blocks.8.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 706 |
+
"model.visual.blocks.8.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 707 |
+
"model.visual.blocks.8.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 708 |
+
"model.visual.blocks.8.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 709 |
+
"model.visual.blocks.8.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 710 |
+
"model.visual.blocks.8.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 711 |
+
"model.visual.blocks.8.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 712 |
+
"model.visual.blocks.8.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 713 |
+
"model.visual.blocks.8.norm1.bias": "model-00004-of-00004.safetensors",
|
| 714 |
+
"model.visual.blocks.8.norm1.weight": "model-00004-of-00004.safetensors",
|
| 715 |
+
"model.visual.blocks.8.norm2.bias": "model-00004-of-00004.safetensors",
|
| 716 |
+
"model.visual.blocks.8.norm2.weight": "model-00004-of-00004.safetensors",
|
| 717 |
+
"model.visual.blocks.9.attn.proj.bias": "model-00004-of-00004.safetensors",
|
| 718 |
+
"model.visual.blocks.9.attn.proj.weight": "model-00004-of-00004.safetensors",
|
| 719 |
+
"model.visual.blocks.9.attn.qkv.bias": "model-00004-of-00004.safetensors",
|
| 720 |
+
"model.visual.blocks.9.attn.qkv.weight": "model-00004-of-00004.safetensors",
|
| 721 |
+
"model.visual.blocks.9.mlp.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 722 |
+
"model.visual.blocks.9.mlp.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 723 |
+
"model.visual.blocks.9.mlp.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 724 |
+
"model.visual.blocks.9.mlp.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 725 |
+
"model.visual.blocks.9.norm1.bias": "model-00004-of-00004.safetensors",
|
| 726 |
+
"model.visual.blocks.9.norm1.weight": "model-00004-of-00004.safetensors",
|
| 727 |
+
"model.visual.blocks.9.norm2.bias": "model-00004-of-00004.safetensors",
|
| 728 |
+
"model.visual.blocks.9.norm2.weight": "model-00004-of-00004.safetensors",
|
| 729 |
+
"model.visual.deepstack_merger_list.0.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 730 |
+
"model.visual.deepstack_merger_list.0.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 731 |
+
"model.visual.deepstack_merger_list.0.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 732 |
+
"model.visual.deepstack_merger_list.0.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 733 |
+
"model.visual.deepstack_merger_list.0.norm.bias": "model-00004-of-00004.safetensors",
|
| 734 |
+
"model.visual.deepstack_merger_list.0.norm.weight": "model-00004-of-00004.safetensors",
|
| 735 |
+
"model.visual.deepstack_merger_list.1.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 736 |
+
"model.visual.deepstack_merger_list.1.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 737 |
+
"model.visual.deepstack_merger_list.1.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 738 |
+
"model.visual.deepstack_merger_list.1.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 739 |
+
"model.visual.deepstack_merger_list.1.norm.bias": "model-00004-of-00004.safetensors",
|
| 740 |
+
"model.visual.deepstack_merger_list.1.norm.weight": "model-00004-of-00004.safetensors",
|
| 741 |
+
"model.visual.deepstack_merger_list.2.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 742 |
+
"model.visual.deepstack_merger_list.2.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 743 |
+
"model.visual.deepstack_merger_list.2.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 744 |
+
"model.visual.deepstack_merger_list.2.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 745 |
+
"model.visual.deepstack_merger_list.2.norm.bias": "model-00004-of-00004.safetensors",
|
| 746 |
+
"model.visual.deepstack_merger_list.2.norm.weight": "model-00004-of-00004.safetensors",
|
| 747 |
+
"model.visual.merger.linear_fc1.bias": "model-00004-of-00004.safetensors",
|
| 748 |
+
"model.visual.merger.linear_fc1.weight": "model-00004-of-00004.safetensors",
|
| 749 |
+
"model.visual.merger.linear_fc2.bias": "model-00004-of-00004.safetensors",
|
| 750 |
+
"model.visual.merger.linear_fc2.weight": "model-00004-of-00004.safetensors",
|
| 751 |
+
"model.visual.merger.norm.bias": "model-00004-of-00004.safetensors",
|
| 752 |
+
"model.visual.merger.norm.weight": "model-00004-of-00004.safetensors",
|
| 753 |
+
"model.visual.patch_embed.proj.bias": "model-00004-of-00004.safetensors",
|
| 754 |
+
"model.visual.patch_embed.proj.weight": "model-00004-of-00004.safetensors",
|
| 755 |
+
"model.visual.pos_embed.weight": "model-00004-of-00004.safetensors"
|
| 756 |
+
}
|
| 757 |
+
}
|
text_encoder/preprocessor_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {
|
| 3 |
+
"longest_edge": 16777216,
|
| 4 |
+
"shortest_edge": 65536
|
| 5 |
+
},
|
| 6 |
+
"patch_size": 16,
|
| 7 |
+
"temporal_patch_size": 2,
|
| 8 |
+
"merge_size": 2,
|
| 9 |
+
"image_mean": [
|
| 10 |
+
0.5,
|
| 11 |
+
0.5,
|
| 12 |
+
0.5
|
| 13 |
+
],
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.5,
|
| 16 |
+
0.5,
|
| 17 |
+
0.5
|
| 18 |
+
],
|
| 19 |
+
"processor_class": "Qwen3VLProcessor",
|
| 20 |
+
"image_processor_type": "Qwen2VLImageProcessorFast"
|
| 21 |
+
}
|
text_encoder/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
text_encoder/tokenizer_config.json
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<tool_response>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": false
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</tool_response>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": false
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<think>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": false
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "</think>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": false
|
| 212 |
+
}
|
| 213 |
+
},
|
| 214 |
+
"additional_special_tokens": [
|
| 215 |
+
"<|im_start|>",
|
| 216 |
+
"<|im_end|>",
|
| 217 |
+
"<|object_ref_start|>",
|
| 218 |
+
"<|object_ref_end|>",
|
| 219 |
+
"<|box_start|>",
|
| 220 |
+
"<|box_end|>",
|
| 221 |
+
"<|quad_start|>",
|
| 222 |
+
"<|quad_end|>",
|
| 223 |
+
"<|vision_start|>",
|
| 224 |
+
"<|vision_end|>",
|
| 225 |
+
"<|vision_pad|>",
|
| 226 |
+
"<|image_pad|>",
|
| 227 |
+
"<|video_pad|>"
|
| 228 |
+
],
|
| 229 |
+
"bos_token": null,
|
| 230 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set image_count = namespace(value=0) %}\n{%- set video_count = namespace(value=0) %}\n{%- for message in messages %}\n {%- if message.role == \"user\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content_item in message.content %}\n {%- if 'text' in content_item %}\n {{- content_item.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and message.content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 231 |
+
"clean_up_tokenization_spaces": false,
|
| 232 |
+
"eos_token": "<|im_end|>",
|
| 233 |
+
"errors": "replace",
|
| 234 |
+
"model_max_length": 262144,
|
| 235 |
+
"pad_token": "<|endoftext|>",
|
| 236 |
+
"split_special_tokens": false,
|
| 237 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 238 |
+
"unk_token": null
|
| 239 |
+
}
|
text_encoder/video_preprocessor_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {
|
| 3 |
+
"longest_edge": 25165824,
|
| 4 |
+
"shortest_edge": 4096
|
| 5 |
+
},
|
| 6 |
+
"patch_size": 16,
|
| 7 |
+
"temporal_patch_size": 2,
|
| 8 |
+
"merge_size": 2,
|
| 9 |
+
"image_mean": [
|
| 10 |
+
0.5,
|
| 11 |
+
0.5,
|
| 12 |
+
0.5
|
| 13 |
+
],
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.5,
|
| 16 |
+
0.5,
|
| 17 |
+
0.5
|
| 18 |
+
],
|
| 19 |
+
"processor_class": "Qwen3VLProcessor",
|
| 20 |
+
"video_processor_type": "Qwen3VLVideoProcessor"
|
| 21 |
+
}
|
text_encoder/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
transformer/config.json
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": [
|
| 3 |
+
"modeling_nucleusmoe",
|
| 4 |
+
"NucleusMoEImageTransformer2DModel"
|
| 5 |
+
],
|
| 6 |
+
"_diffusers_version": "0.36.0",
|
| 7 |
+
"patch_size": 2,
|
| 8 |
+
"in_channels": 64,
|
| 9 |
+
"out_channels": 16,
|
| 10 |
+
"num_layers": 32,
|
| 11 |
+
"attention_head_dim": 128,
|
| 12 |
+
"num_attention_heads": 16,
|
| 13 |
+
"num_key_value_heads": 4,
|
| 14 |
+
"joint_attention_dim": 4096,
|
| 15 |
+
"axes_dims_rope": [
|
| 16 |
+
16,
|
| 17 |
+
56,
|
| 18 |
+
56
|
| 19 |
+
],
|
| 20 |
+
"mlp_ratio": 4.0,
|
| 21 |
+
"moe_enabled": true,
|
| 22 |
+
"dense_moe_strategy": "leave_first_three_blocks_dense",
|
| 23 |
+
"num_experts": 64,
|
| 24 |
+
"moe_intermediate_dim": 1344,
|
| 25 |
+
"capacity_factors": [
|
| 26 |
+
0.0,
|
| 27 |
+
0.0,
|
| 28 |
+
0.0,
|
| 29 |
+
4.0,
|
| 30 |
+
4.0,
|
| 31 |
+
2.0,
|
| 32 |
+
2.0,
|
| 33 |
+
2.0,
|
| 34 |
+
2.0,
|
| 35 |
+
2.0,
|
| 36 |
+
2.0,
|
| 37 |
+
2.0,
|
| 38 |
+
2.0,
|
| 39 |
+
2.0,
|
| 40 |
+
2.0,
|
| 41 |
+
2.0,
|
| 42 |
+
2.0,
|
| 43 |
+
2.0,
|
| 44 |
+
2.0,
|
| 45 |
+
2.0,
|
| 46 |
+
2.0,
|
| 47 |
+
2.0,
|
| 48 |
+
2.0,
|
| 49 |
+
2.0,
|
| 50 |
+
2.0,
|
| 51 |
+
2.0,
|
| 52 |
+
2.0,
|
| 53 |
+
2.0,
|
| 54 |
+
2.0,
|
| 55 |
+
2.0,
|
| 56 |
+
2.0,
|
| 57 |
+
2.0
|
| 58 |
+
],
|
| 59 |
+
"use_sigmoid": false,
|
| 60 |
+
"route_scale": 2.5
|
| 61 |
+
}
|
transformer/diffusion_pytorch_model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:239b546d425bdeedc664ab9052ba33e33da744d423d2462261b0a3d82ca7c88b
|
| 3 |
+
size 4991757800
|
transformer/diffusion_pytorch_model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:25a9024259d23108fb09b834849c469469bdac1f09e15f1be49f55276cb8ae27
|
| 3 |
+
size 4999012736
|
transformer/diffusion_pytorch_model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c4a6c2458a82bdbfdd626017a1fb4d8a6d3c120f72902d7f4d248bdb5f56cc47
|
| 3 |
+
size 5000040248
|
transformer/diffusion_pytorch_model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfda61b257bd60a6ef9b48ae611127296ed79262e1aee4cdead7566e1ab10fbc
|
| 3 |
+
size 4994535096
|
transformer/diffusion_pytorch_model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3e88a38ae2ecdfe6ad7c58294c75732661f5f55bc94e71567c167befde8ecd07
|
| 3 |
+
size 4999013192
|
transformer/diffusion_pytorch_model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:51935971585478fb2cf1564ebcaabca9affbaa806f68c0b7667262d2036f663a
|
| 3 |
+
size 5000040248
|
transformer/diffusion_pytorch_model-00007-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:87f3dab9083547c2acecb71376cdaf229227f5011ccb872ac171c07227a922c0
|
| 3 |
+
size 3861789552
|
transformer/diffusion_pytorch_model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
transformer/model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:239b546d425bdeedc664ab9052ba33e33da744d423d2462261b0a3d82ca7c88b
|
| 3 |
+
size 4991757800
|
transformer/model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:25a9024259d23108fb09b834849c469469bdac1f09e15f1be49f55276cb8ae27
|
| 3 |
+
size 4999012736
|
transformer/model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c4a6c2458a82bdbfdd626017a1fb4d8a6d3c120f72902d7f4d248bdb5f56cc47
|
| 3 |
+
size 5000040248
|
transformer/model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfda61b257bd60a6ef9b48ae611127296ed79262e1aee4cdead7566e1ab10fbc
|
| 3 |
+
size 4994535096
|
transformer/model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3e88a38ae2ecdfe6ad7c58294c75732661f5f55bc94e71567c167befde8ecd07
|
| 3 |
+
size 4999013192
|
transformer/model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:51935971585478fb2cf1564ebcaabca9affbaa806f68c0b7667262d2036f663a
|
| 3 |
+
size 5000040248
|
transformer/model-00007-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb62a72407928ebc1eda73210be1ec448464714cf439951d23b49b9b59b65c27
|
| 3 |
+
size 3861520360
|
transformer/model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
transformer/modeling_nucleusmoe.py
ADDED
|
@@ -0,0 +1,859 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Nucleus-Image Team, The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import functools
|
| 16 |
+
import math
|
| 17 |
+
from typing import Any, List
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
import torch.nn.functional as F
|
| 22 |
+
|
| 23 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 24 |
+
from diffusers.loaders import FromOriginalModelMixin, PeftAdapterMixin
|
| 25 |
+
from diffusers.utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 26 |
+
from diffusers.utils.torch_utils import maybe_allow_in_graph
|
| 27 |
+
from diffusers.models.attention import AttentionMixin, FeedForward
|
| 28 |
+
from diffusers.models.attention_dispatch import dispatch_attention_fn
|
| 29 |
+
from diffusers.models.attention_processor import Attention
|
| 30 |
+
from diffusers.models.cache_utils import CacheMixin
|
| 31 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 32 |
+
from diffusers.models.modeling_outputs import Transformer2DModelOutput
|
| 33 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 34 |
+
from diffusers.models.normalization import AdaLayerNormContinuous, RMSNorm
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def get_timestep_embedding(
|
| 41 |
+
timesteps: torch.Tensor,
|
| 42 |
+
embedding_dim: int,
|
| 43 |
+
flip_sin_to_cos: bool = False,
|
| 44 |
+
downscale_freq_shift: float = 1,
|
| 45 |
+
scale: float = 1,
|
| 46 |
+
max_period: int = 10000,
|
| 47 |
+
) -> torch.Tensor:
|
| 48 |
+
"""
|
| 49 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 50 |
+
|
| 51 |
+
Args
|
| 52 |
+
timesteps (torch.Tensor):
|
| 53 |
+
a 1-D Tensor of N indices, one per batch element. These may be fractional.
|
| 54 |
+
embedding_dim (int):
|
| 55 |
+
the dimension of the output.
|
| 56 |
+
flip_sin_to_cos (bool):
|
| 57 |
+
Whether the embedding order should be `cos, sin` (if True) or `sin, cos` (if False)
|
| 58 |
+
downscale_freq_shift (float):
|
| 59 |
+
Controls the delta between frequencies between dimensions
|
| 60 |
+
scale (float):
|
| 61 |
+
Scaling factor applied to the embeddings.
|
| 62 |
+
max_period (int):
|
| 63 |
+
Controls the maximum frequency of the embeddings
|
| 64 |
+
Returns
|
| 65 |
+
torch.Tensor: an [N x dim] Tensor of positional embeddings.
|
| 66 |
+
"""
|
| 67 |
+
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
| 68 |
+
|
| 69 |
+
half_dim = embedding_dim // 2
|
| 70 |
+
exponent = -math.log(max_period) * torch.arange(
|
| 71 |
+
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
|
| 72 |
+
)
|
| 73 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 74 |
+
|
| 75 |
+
emb = torch.exp(exponent).to(timesteps.dtype)
|
| 76 |
+
emb = timesteps[:, None].float() * emb[None, :]
|
| 77 |
+
|
| 78 |
+
# scale embeddings
|
| 79 |
+
emb = scale * emb
|
| 80 |
+
|
| 81 |
+
# concat sine and cosine embeddings
|
| 82 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 83 |
+
|
| 84 |
+
# flip sine and cosine embeddings
|
| 85 |
+
if flip_sin_to_cos:
|
| 86 |
+
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
| 87 |
+
|
| 88 |
+
# zero pad
|
| 89 |
+
if embedding_dim % 2 == 1:
|
| 90 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 91 |
+
return emb
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def apply_rotary_emb_nucleus(
|
| 95 |
+
x: torch.Tensor,
|
| 96 |
+
freqs_cis: torch.Tensor | tuple[torch.Tensor],
|
| 97 |
+
use_real: bool = True,
|
| 98 |
+
use_real_unbind_dim: int = -1,
|
| 99 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 100 |
+
"""
|
| 101 |
+
Apply rotary embeddings to input tensors using the given frequency tensor. This function applies rotary embeddings
|
| 102 |
+
to the given query or key 'x' tensors using the provided frequency tensor 'freqs_cis'. The input tensors are
|
| 103 |
+
reshaped as complex numbers, and the frequency tensor is reshaped for broadcasting compatibility. The resulting
|
| 104 |
+
tensors contain rotary embeddings and are returned as real tensors.
|
| 105 |
+
|
| 106 |
+
Args:
|
| 107 |
+
x (`torch.Tensor`):
|
| 108 |
+
Query or key tensor to apply rotary embeddings. [B, S, H, D] xk (torch.Tensor): Key tensor to apply
|
| 109 |
+
freqs_cis (`tuple[torch.Tensor]`): Precomputed frequency tensor for complex exponentials. ([S, D], [S, D],)
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
tuple[torch.Tensor, torch.Tensor]: tuple of modified query tensor and key tensor with rotary embeddings.
|
| 113 |
+
"""
|
| 114 |
+
if use_real:
|
| 115 |
+
cos, sin = freqs_cis # [S, D]
|
| 116 |
+
cos = cos[None, None]
|
| 117 |
+
sin = sin[None, None]
|
| 118 |
+
cos, sin = cos.to(x.device), sin.to(x.device)
|
| 119 |
+
|
| 120 |
+
if use_real_unbind_dim == -1:
|
| 121 |
+
# Used for flux, cogvideox, hunyuan-dit
|
| 122 |
+
x_real, x_imag = x.reshape(*x.shape[:-1], -1, 2).unbind(-1) # [B, S, H, D//2]
|
| 123 |
+
x_rotated = torch.stack([-x_imag, x_real], dim=-1).flatten(3)
|
| 124 |
+
elif use_real_unbind_dim == -2:
|
| 125 |
+
# Used for Stable Audio, OmniGen, CogView4 and Cosmos
|
| 126 |
+
x_real, x_imag = x.reshape(*x.shape[:-1], 2, -1).unbind(-2) # [B, S, H, D//2]
|
| 127 |
+
x_rotated = torch.cat([-x_imag, x_real], dim=-1)
|
| 128 |
+
else:
|
| 129 |
+
raise ValueError(f"`use_real_unbind_dim={use_real_unbind_dim}` but should be -1 or -2.")
|
| 130 |
+
|
| 131 |
+
out = (x.float() * cos + x_rotated.float() * sin).to(x.dtype)
|
| 132 |
+
|
| 133 |
+
return out
|
| 134 |
+
else:
|
| 135 |
+
x_rotated = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2))
|
| 136 |
+
freqs_cis = freqs_cis.unsqueeze(1)
|
| 137 |
+
x_out = torch.view_as_real(x_rotated * freqs_cis).flatten(3)
|
| 138 |
+
|
| 139 |
+
return x_out.type_as(x)
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def compute_text_seq_len_from_mask(
|
| 143 |
+
encoder_hidden_states: torch.Tensor, encoder_hidden_states_mask: torch.Tensor | None
|
| 144 |
+
) -> tuple[int, torch.Tensor | None, torch.Tensor | None]:
|
| 145 |
+
"""
|
| 146 |
+
Compute text sequence length without assuming contiguous masks. Returns length for RoPE and a normalized bool mask.
|
| 147 |
+
"""
|
| 148 |
+
batch_size, text_seq_len = encoder_hidden_states.shape[:2]
|
| 149 |
+
if encoder_hidden_states_mask is None:
|
| 150 |
+
return text_seq_len, None, None
|
| 151 |
+
|
| 152 |
+
if encoder_hidden_states_mask.shape[:2] != (batch_size, text_seq_len):
|
| 153 |
+
raise ValueError(
|
| 154 |
+
f"`encoder_hidden_states_mask` shape {encoder_hidden_states_mask.shape} must match "
|
| 155 |
+
f"(batch_size, text_seq_len)=({batch_size}, {text_seq_len})."
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
if encoder_hidden_states_mask.dtype != torch.bool:
|
| 159 |
+
encoder_hidden_states_mask = encoder_hidden_states_mask.to(torch.bool)
|
| 160 |
+
|
| 161 |
+
position_ids = torch.arange(text_seq_len, device=encoder_hidden_states.device, dtype=torch.long)
|
| 162 |
+
active_positions = torch.where(encoder_hidden_states_mask, position_ids, position_ids.new_zeros(()))
|
| 163 |
+
has_active = encoder_hidden_states_mask.any(dim=1)
|
| 164 |
+
per_sample_len = torch.where(
|
| 165 |
+
has_active,
|
| 166 |
+
active_positions.max(dim=1).values + 1,
|
| 167 |
+
torch.as_tensor(text_seq_len, device=encoder_hidden_states.device),
|
| 168 |
+
)
|
| 169 |
+
return text_seq_len, per_sample_len, encoder_hidden_states_mask
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class NucleusTimestepProjEmbeddings(nn.Module):
|
| 173 |
+
def __init__(self, embedding_dim, use_additional_t_cond=False):
|
| 174 |
+
super().__init__()
|
| 175 |
+
|
| 176 |
+
self.time_proj = Timesteps(num_channels=embedding_dim, flip_sin_to_cos=True, downscale_freq_shift=0, scale=1000)
|
| 177 |
+
self.timestep_embedder = TimestepEmbedding(
|
| 178 |
+
in_channels=embedding_dim, time_embed_dim=4 * embedding_dim, out_dim=embedding_dim
|
| 179 |
+
)
|
| 180 |
+
self.norm = RMSNorm(embedding_dim, eps=1e-6)
|
| 181 |
+
self.use_additional_t_cond = use_additional_t_cond
|
| 182 |
+
if use_additional_t_cond:
|
| 183 |
+
self.addition_t_embedding = nn.Embedding(2, embedding_dim)
|
| 184 |
+
|
| 185 |
+
def forward(self, timestep, hidden_states, addition_t_cond=None):
|
| 186 |
+
timesteps_proj = self.time_proj(timestep)
|
| 187 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=hidden_states.dtype)) # (N, D)
|
| 188 |
+
|
| 189 |
+
conditioning = timesteps_emb
|
| 190 |
+
if self.use_additional_t_cond:
|
| 191 |
+
if addition_t_cond is None:
|
| 192 |
+
raise ValueError("When additional_t_cond is True, addition_t_cond must be provided.")
|
| 193 |
+
addition_t_emb = self.addition_t_embedding(addition_t_cond)
|
| 194 |
+
addition_t_emb = addition_t_emb.to(dtype=hidden_states.dtype)
|
| 195 |
+
conditioning = conditioning + addition_t_emb
|
| 196 |
+
|
| 197 |
+
return self.norm(conditioning)
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
class NucleusEmbedRope(nn.Module):
|
| 201 |
+
def __init__(self, theta: int, axes_dim: list[int], scale_rope=False):
|
| 202 |
+
super().__init__()
|
| 203 |
+
self.theta = theta
|
| 204 |
+
self.axes_dim = axes_dim
|
| 205 |
+
pos_index = torch.arange(4096)
|
| 206 |
+
neg_index = torch.arange(4096).flip(0) * -1 - 1
|
| 207 |
+
self.pos_freqs = torch.cat(
|
| 208 |
+
[
|
| 209 |
+
self.rope_params(pos_index, self.axes_dim[0], self.theta),
|
| 210 |
+
self.rope_params(pos_index, self.axes_dim[1], self.theta),
|
| 211 |
+
self.rope_params(pos_index, self.axes_dim[2], self.theta),
|
| 212 |
+
],
|
| 213 |
+
dim=1,
|
| 214 |
+
)
|
| 215 |
+
self.neg_freqs = torch.cat(
|
| 216 |
+
[
|
| 217 |
+
self.rope_params(neg_index, self.axes_dim[0], self.theta),
|
| 218 |
+
self.rope_params(neg_index, self.axes_dim[1], self.theta),
|
| 219 |
+
self.rope_params(neg_index, self.axes_dim[2], self.theta),
|
| 220 |
+
],
|
| 221 |
+
dim=1,
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
# DO NOT USING REGISTER BUFFER HERE, IT WILL CAUSE COMPLEX NUMBERS LOSE ITS IMAGINARY PART
|
| 225 |
+
self.scale_rope = scale_rope
|
| 226 |
+
|
| 227 |
+
def rope_params(self, index, dim, theta=10000):
|
| 228 |
+
"""
|
| 229 |
+
Args:
|
| 230 |
+
index: [0, 1, 2, 3] 1D Tensor representing the position index of the token
|
| 231 |
+
"""
|
| 232 |
+
assert dim % 2 == 0
|
| 233 |
+
freqs = torch.outer(index, 1.0 / torch.pow(theta, torch.arange(0, dim, 2).to(torch.float32).div(dim)))
|
| 234 |
+
freqs = torch.polar(torch.ones_like(freqs), freqs)
|
| 235 |
+
return freqs
|
| 236 |
+
|
| 237 |
+
def forward(
|
| 238 |
+
self,
|
| 239 |
+
video_fhw: tuple[int, int, int, list[tuple[int, int, int]]],
|
| 240 |
+
txt_seq_lens: list[int] | None = None,
|
| 241 |
+
device: torch.device = None,
|
| 242 |
+
max_txt_seq_len: int | torch.Tensor | None = None,
|
| 243 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 244 |
+
"""
|
| 245 |
+
Args:
|
| 246 |
+
video_fhw (`tuple[int, int, int]` or `list[tuple[int, int, int]]`):
|
| 247 |
+
A list of 3 integers [frame, height, width] representing the shape of the video.
|
| 248 |
+
txt_seq_lens (`list[int]`, *optional*, **Deprecated**):
|
| 249 |
+
Deprecated parameter. Use `max_txt_seq_len` instead. If provided, the maximum value will be used.
|
| 250 |
+
device: (`torch.device`, *optional*):
|
| 251 |
+
The device on which to perform the RoPE computation.
|
| 252 |
+
max_txt_seq_len (`int` or `torch.Tensor`, *optional*):
|
| 253 |
+
The maximum text sequence length for RoPE computation. This should match the encoder hidden states
|
| 254 |
+
sequence length. Can be either an int or a scalar tensor (for torch.compile compatibility).
|
| 255 |
+
"""
|
| 256 |
+
# Handle deprecated txt_seq_lens parameter
|
| 257 |
+
if txt_seq_lens is not None:
|
| 258 |
+
deprecate(
|
| 259 |
+
"txt_seq_lens",
|
| 260 |
+
"0.39.0",
|
| 261 |
+
"Passing `txt_seq_lens` is deprecated and will be removed in version 0.39.0. "
|
| 262 |
+
"Please use `max_txt_seq_len` instead. "
|
| 263 |
+
"The new parameter accepts a single int or tensor value representing the maximum text sequence length.",
|
| 264 |
+
standard_warn=False,
|
| 265 |
+
)
|
| 266 |
+
if max_txt_seq_len is None:
|
| 267 |
+
# Use max of txt_seq_lens for backward compatibility
|
| 268 |
+
max_txt_seq_len = max(txt_seq_lens) if isinstance(txt_seq_lens, list) else txt_seq_lens
|
| 269 |
+
|
| 270 |
+
if max_txt_seq_len is None:
|
| 271 |
+
raise ValueError("Either `max_txt_seq_len` or `txt_seq_lens` (deprecated) must be provided.")
|
| 272 |
+
|
| 273 |
+
# Validate batch inference with variable-sized images
|
| 274 |
+
if isinstance(video_fhw, list) and len(video_fhw) > 1:
|
| 275 |
+
# Check if all instances have the same size
|
| 276 |
+
first_fhw = video_fhw[0]
|
| 277 |
+
if not all(fhw == first_fhw for fhw in video_fhw):
|
| 278 |
+
logger.warning(
|
| 279 |
+
"Batch inference with variable-sized images is not currently supported in NucleusEmbedRope. "
|
| 280 |
+
"All images in the batch should have the same dimensions (frame, height, width). "
|
| 281 |
+
f"Detected sizes: {video_fhw}. Using the first image's dimensions {first_fhw} "
|
| 282 |
+
"for RoPE computation, which may lead to incorrect results for other images in the batch."
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
if isinstance(video_fhw, list):
|
| 286 |
+
video_fhw = video_fhw[0]
|
| 287 |
+
if not isinstance(video_fhw, list):
|
| 288 |
+
video_fhw = [video_fhw]
|
| 289 |
+
|
| 290 |
+
vid_freqs = []
|
| 291 |
+
max_vid_index = 0
|
| 292 |
+
for idx, fhw in enumerate(video_fhw):
|
| 293 |
+
frame, height, width = fhw
|
| 294 |
+
# RoPE frequencies are cached via a lru_cache decorator on _compute_video_freqs
|
| 295 |
+
video_freq = self._compute_video_freqs(frame, height, width, idx, device)
|
| 296 |
+
vid_freqs.append(video_freq)
|
| 297 |
+
|
| 298 |
+
if self.scale_rope:
|
| 299 |
+
max_vid_index = max(height // 2, width // 2, max_vid_index)
|
| 300 |
+
else:
|
| 301 |
+
max_vid_index = max(height, width, max_vid_index)
|
| 302 |
+
|
| 303 |
+
max_txt_seq_len_int = int(max_txt_seq_len)
|
| 304 |
+
# Create device-specific copy for text freqs without modifying self.pos_freqs
|
| 305 |
+
txt_freqs = self.pos_freqs.to(device)[max_vid_index : max_vid_index + max_txt_seq_len_int, ...]
|
| 306 |
+
vid_freqs = torch.cat(vid_freqs, dim=0)
|
| 307 |
+
|
| 308 |
+
return vid_freqs, txt_freqs
|
| 309 |
+
|
| 310 |
+
@functools.lru_cache(maxsize=128)
|
| 311 |
+
def _compute_video_freqs(
|
| 312 |
+
self, frame: int, height: int, width: int, idx: int = 0, device: torch.device = None
|
| 313 |
+
) -> torch.Tensor:
|
| 314 |
+
seq_lens = frame * height * width
|
| 315 |
+
pos_freqs = self.pos_freqs.to(device) if device is not None else self.pos_freqs
|
| 316 |
+
neg_freqs = self.neg_freqs.to(device) if device is not None else self.neg_freqs
|
| 317 |
+
|
| 318 |
+
freqs_pos = pos_freqs.split([x // 2 for x in self.axes_dim], dim=1)
|
| 319 |
+
freqs_neg = neg_freqs.split([x // 2 for x in self.axes_dim], dim=1)
|
| 320 |
+
|
| 321 |
+
freqs_frame = freqs_pos[0][idx : idx + frame].view(frame, 1, 1, -1).expand(frame, height, width, -1)
|
| 322 |
+
if self.scale_rope:
|
| 323 |
+
freqs_height = torch.cat([freqs_neg[1][-(height - height // 2) :], freqs_pos[1][: height // 2]], dim=0)
|
| 324 |
+
freqs_height = freqs_height.view(1, height, 1, -1).expand(frame, height, width, -1)
|
| 325 |
+
freqs_width = torch.cat([freqs_neg[2][-(width - width // 2) :], freqs_pos[2][: width // 2]], dim=0)
|
| 326 |
+
freqs_width = freqs_width.view(1, 1, width, -1).expand(frame, height, width, -1)
|
| 327 |
+
else:
|
| 328 |
+
freqs_height = freqs_pos[1][:height].view(1, height, 1, -1).expand(frame, height, width, -1)
|
| 329 |
+
freqs_width = freqs_pos[2][:width].view(1, 1, width, -1).expand(frame, height, width, -1)
|
| 330 |
+
|
| 331 |
+
freqs = torch.cat([freqs_frame, freqs_height, freqs_width], dim=-1).reshape(seq_lens, -1)
|
| 332 |
+
return freqs.clone().contiguous()
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
class NucleusMoEAttnProcessor2_0:
|
| 336 |
+
"""
|
| 337 |
+
Attention processor for the Nucleus MoE architecture. Image queries attend to concatenated image+text keys/values
|
| 338 |
+
(cross-attention style, no text query). Supports grouped-query attention (GQA) when num_key_value_heads is set on
|
| 339 |
+
the Attention module.
|
| 340 |
+
"""
|
| 341 |
+
|
| 342 |
+
_attention_backend = None
|
| 343 |
+
_parallel_config = None
|
| 344 |
+
|
| 345 |
+
def __init__(self):
|
| 346 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 347 |
+
raise ImportError(
|
| 348 |
+
"NucleusMoEAttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
def __call__(
|
| 352 |
+
self,
|
| 353 |
+
attn: Attention,
|
| 354 |
+
hidden_states: torch.FloatTensor,
|
| 355 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 356 |
+
attention_mask: torch.FloatTensor | None = None,
|
| 357 |
+
image_rotary_emb: torch.Tensor | None = None,
|
| 358 |
+
) -> torch.FloatTensor:
|
| 359 |
+
head_dim = attn.inner_dim // attn.heads
|
| 360 |
+
num_kv_heads = attn.inner_kv_dim // head_dim
|
| 361 |
+
num_kv_groups = attn.heads // num_kv_heads
|
| 362 |
+
|
| 363 |
+
img_query = attn.to_q(hidden_states).unflatten(-1, (attn.heads, -1))
|
| 364 |
+
img_key = attn.to_k(hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 365 |
+
img_value = attn.to_v(hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 366 |
+
|
| 367 |
+
if attn.norm_q is not None:
|
| 368 |
+
img_query = attn.norm_q(img_query)
|
| 369 |
+
if attn.norm_k is not None:
|
| 370 |
+
img_key = attn.norm_k(img_key)
|
| 371 |
+
|
| 372 |
+
if image_rotary_emb is not None:
|
| 373 |
+
img_freqs, txt_freqs = image_rotary_emb
|
| 374 |
+
img_query = apply_rotary_emb_nucleus(img_query, img_freqs, use_real=False)
|
| 375 |
+
img_key = apply_rotary_emb_nucleus(img_key, img_freqs, use_real=False)
|
| 376 |
+
|
| 377 |
+
if encoder_hidden_states is not None:
|
| 378 |
+
txt_key = attn.add_k_proj(encoder_hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 379 |
+
txt_value = attn.add_v_proj(encoder_hidden_states).unflatten(-1, (num_kv_heads, -1))
|
| 380 |
+
|
| 381 |
+
if attn.norm_added_k is not None:
|
| 382 |
+
txt_key = attn.norm_added_k(txt_key)
|
| 383 |
+
|
| 384 |
+
if image_rotary_emb is not None:
|
| 385 |
+
txt_key = apply_rotary_emb_nucleus(txt_key, txt_freqs, use_real=False)
|
| 386 |
+
|
| 387 |
+
joint_key = torch.cat([img_key, txt_key], dim=1)
|
| 388 |
+
joint_value = torch.cat([img_value, txt_value], dim=1)
|
| 389 |
+
else:
|
| 390 |
+
joint_key = img_key
|
| 391 |
+
joint_value = img_value
|
| 392 |
+
|
| 393 |
+
if num_kv_groups > 1:
|
| 394 |
+
joint_key = joint_key.repeat_interleave(num_kv_groups, dim=2)
|
| 395 |
+
joint_value = joint_value.repeat_interleave(num_kv_groups, dim=2)
|
| 396 |
+
|
| 397 |
+
hidden_states = dispatch_attention_fn(
|
| 398 |
+
img_query,
|
| 399 |
+
joint_key,
|
| 400 |
+
joint_value,
|
| 401 |
+
attn_mask=attention_mask,
|
| 402 |
+
dropout_p=0.0,
|
| 403 |
+
is_causal=False,
|
| 404 |
+
backend=self._attention_backend,
|
| 405 |
+
parallel_config=self._parallel_config,
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
hidden_states = hidden_states.flatten(2, 3)
|
| 409 |
+
hidden_states = hidden_states.to(img_query.dtype)
|
| 410 |
+
|
| 411 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 412 |
+
if len(attn.to_out) > 1:
|
| 413 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 414 |
+
|
| 415 |
+
return hidden_states
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def _is_moe_layer(strategy: str, layer_idx: int, num_layers: int) -> bool:
|
| 419 |
+
if strategy == "leave_first_three_and_last_block_dense":
|
| 420 |
+
return layer_idx >= 3 and layer_idx < num_layers - 1
|
| 421 |
+
elif strategy == "leave_first_three_blocks_dense":
|
| 422 |
+
return layer_idx >= 3
|
| 423 |
+
elif strategy == "leave_first_block_dense":
|
| 424 |
+
return layer_idx >= 1
|
| 425 |
+
elif strategy == "all_moe":
|
| 426 |
+
return True
|
| 427 |
+
elif strategy == "all_dense":
|
| 428 |
+
return False
|
| 429 |
+
return True
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
class NucleusMoELayer(nn.Module):
|
| 433 |
+
"""
|
| 434 |
+
Mixture-of-Experts layer with expert-choice routing and a shared expert.
|
| 435 |
+
|
| 436 |
+
Each expert is a separate ``FeedForward`` module stored in an ``nn.ModuleList``.
|
| 437 |
+
The router concatenates a timestep embedding with the (unmodulated) hidden state
|
| 438 |
+
to produce per-token affinity scores, then selects the top-C tokens per expert
|
| 439 |
+
(expert-choice routing). A shared expert processes all tokens in parallel and its
|
| 440 |
+
output is combined with the routed expert outputs via scatter-add.
|
| 441 |
+
"""
|
| 442 |
+
|
| 443 |
+
def __init__(
|
| 444 |
+
self,
|
| 445 |
+
hidden_size: int,
|
| 446 |
+
moe_intermediate_dim: int,
|
| 447 |
+
num_experts: int,
|
| 448 |
+
capacity_factor: float,
|
| 449 |
+
use_sigmoid: bool,
|
| 450 |
+
route_scale: float,
|
| 451 |
+
):
|
| 452 |
+
super().__init__()
|
| 453 |
+
self.num_experts = num_experts
|
| 454 |
+
self.capacity_factor = capacity_factor
|
| 455 |
+
self.use_sigmoid = use_sigmoid
|
| 456 |
+
self.route_scale = route_scale
|
| 457 |
+
|
| 458 |
+
self.gate = nn.Linear(hidden_size * 2, num_experts, bias=False)
|
| 459 |
+
self.experts = nn.ModuleList(
|
| 460 |
+
[
|
| 461 |
+
FeedForward(
|
| 462 |
+
dim=hidden_size, dim_out=hidden_size,
|
| 463 |
+
inner_dim=moe_intermediate_dim, activation_fn="swiglu", bias=False,
|
| 464 |
+
)
|
| 465 |
+
for _ in range(num_experts)
|
| 466 |
+
]
|
| 467 |
+
)
|
| 468 |
+
self.shared_expert = FeedForward(
|
| 469 |
+
dim=hidden_size, dim_out=hidden_size,
|
| 470 |
+
inner_dim=moe_intermediate_dim, activation_fn="swiglu", bias=False,
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
def forward(
|
| 474 |
+
self,
|
| 475 |
+
hidden_states: torch.Tensor,
|
| 476 |
+
hidden_states_unmodulated: torch.Tensor,
|
| 477 |
+
timestep: torch.Tensor | None = None,
|
| 478 |
+
) -> torch.Tensor:
|
| 479 |
+
bs, slen, dim = hidden_states.shape
|
| 480 |
+
|
| 481 |
+
if timestep is not None:
|
| 482 |
+
timestep_expanded = timestep.unsqueeze(1).expand(-1, slen, -1)
|
| 483 |
+
router_input = torch.cat([timestep_expanded, hidden_states_unmodulated], dim=-1)
|
| 484 |
+
else:
|
| 485 |
+
router_input = hidden_states_unmodulated
|
| 486 |
+
|
| 487 |
+
logits = self.gate(router_input)
|
| 488 |
+
|
| 489 |
+
if self.use_sigmoid:
|
| 490 |
+
scores = torch.sigmoid(logits.float()).to(logits.dtype)
|
| 491 |
+
else:
|
| 492 |
+
scores = F.softmax(logits.float(), dim=-1).to(logits.dtype)
|
| 493 |
+
|
| 494 |
+
affinity = scores.transpose(1, 2) # (B, E, S)
|
| 495 |
+
capacity = max(1, math.ceil(self.capacity_factor * slen / self.num_experts))
|
| 496 |
+
|
| 497 |
+
topk = torch.topk(affinity, k=capacity, dim=-1)
|
| 498 |
+
top_indices = topk.indices # (B, E, C)
|
| 499 |
+
gating = affinity.gather(dim=-1, index=top_indices) # (B, E, C)
|
| 500 |
+
|
| 501 |
+
batch_offsets = torch.arange(bs, device=hidden_states.device, dtype=torch.long).view(bs, 1, 1) * slen
|
| 502 |
+
global_token_indices = (batch_offsets + top_indices).transpose(0, 1).reshape(self.num_experts, -1).reshape(-1)
|
| 503 |
+
gating_flat = gating.transpose(0, 1).reshape(self.num_experts, -1).reshape(-1)
|
| 504 |
+
|
| 505 |
+
token_score_sums = torch.zeros(bs * slen, device=hidden_states.device, dtype=gating_flat.dtype)
|
| 506 |
+
token_score_sums.scatter_add_(0, global_token_indices, gating_flat)
|
| 507 |
+
gating_flat = gating_flat / (token_score_sums[global_token_indices] + 1e-12)
|
| 508 |
+
gating_flat = gating_flat * self.route_scale
|
| 509 |
+
|
| 510 |
+
x_flat = hidden_states.reshape(bs * slen, dim)
|
| 511 |
+
routed_input = x_flat[global_token_indices]
|
| 512 |
+
|
| 513 |
+
tokens_per_expert = bs * capacity
|
| 514 |
+
routed_output_parts = []
|
| 515 |
+
for i, expert in enumerate(self.experts):
|
| 516 |
+
start = i * tokens_per_expert
|
| 517 |
+
end = start + tokens_per_expert
|
| 518 |
+
expert_out = expert(routed_input[start:end])
|
| 519 |
+
routed_output_parts.append(expert_out)
|
| 520 |
+
|
| 521 |
+
routed_output = torch.cat(routed_output_parts, dim=0)
|
| 522 |
+
routed_output = (routed_output.float() * gating_flat.unsqueeze(-1)).to(hidden_states.dtype)
|
| 523 |
+
|
| 524 |
+
out = self.shared_expert(hidden_states).reshape(bs * slen, dim)
|
| 525 |
+
|
| 526 |
+
scatter_idx = global_token_indices.reshape(-1, 1).expand(-1, dim)
|
| 527 |
+
out = out.scatter_add(dim=0, index=scatter_idx, src=routed_output)
|
| 528 |
+
out = out.reshape(bs, slen, dim)
|
| 529 |
+
|
| 530 |
+
return out
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
@maybe_allow_in_graph
|
| 534 |
+
class NucleusMoEImageTransformerBlock(nn.Module):
|
| 535 |
+
"""
|
| 536 |
+
Single-stream DiT block with optional Mixture-of-Experts MLP, matching the DiTBlock
|
| 537 |
+
architecture from model_v2. Only the image stream receives adaptive modulation;
|
| 538 |
+
the text context is projected per-block and used as cross-attention keys/values.
|
| 539 |
+
"""
|
| 540 |
+
|
| 541 |
+
def __init__(
|
| 542 |
+
self,
|
| 543 |
+
dim: int,
|
| 544 |
+
num_attention_heads: int,
|
| 545 |
+
attention_head_dim: int,
|
| 546 |
+
num_key_value_heads: int | None = None,
|
| 547 |
+
joint_attention_dim: int = 3584,
|
| 548 |
+
qk_norm: str = "rms_norm",
|
| 549 |
+
eps: float = 1e-6,
|
| 550 |
+
mlp_ratio: float = 4.0,
|
| 551 |
+
moe_enabled: bool = False,
|
| 552 |
+
num_experts: int = 128,
|
| 553 |
+
moe_intermediate_dim: int = 1344,
|
| 554 |
+
capacity_factor: float = 8.0,
|
| 555 |
+
use_sigmoid: bool = False,
|
| 556 |
+
route_scale: float = 2.5,
|
| 557 |
+
):
|
| 558 |
+
super().__init__()
|
| 559 |
+
self.dim = dim
|
| 560 |
+
self.moe_enabled = moe_enabled
|
| 561 |
+
|
| 562 |
+
self.img_mod = nn.Sequential(
|
| 563 |
+
nn.SiLU(),
|
| 564 |
+
nn.Linear(dim, 4 * dim, bias=True),
|
| 565 |
+
)
|
| 566 |
+
|
| 567 |
+
self.encoder_proj = nn.Linear(joint_attention_dim, dim)
|
| 568 |
+
|
| 569 |
+
self.pre_attn_norm = nn.LayerNorm(dim, eps=eps, elementwise_affine=False, bias=False)
|
| 570 |
+
self.attn = Attention(
|
| 571 |
+
query_dim=dim,
|
| 572 |
+
heads=num_attention_heads,
|
| 573 |
+
kv_heads=num_key_value_heads,
|
| 574 |
+
dim_head=attention_head_dim,
|
| 575 |
+
added_kv_proj_dim=dim,
|
| 576 |
+
added_proj_bias=False,
|
| 577 |
+
out_dim=dim,
|
| 578 |
+
out_bias=False,
|
| 579 |
+
bias=False,
|
| 580 |
+
processor=NucleusMoEAttnProcessor2_0(),
|
| 581 |
+
qk_norm=qk_norm,
|
| 582 |
+
eps=eps,
|
| 583 |
+
context_pre_only=None,
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
self.pre_mlp_norm = nn.LayerNorm(dim, eps=eps, elementwise_affine=False, bias=False)
|
| 587 |
+
|
| 588 |
+
if moe_enabled:
|
| 589 |
+
self.img_mlp = NucleusMoELayer(
|
| 590 |
+
hidden_size=dim,
|
| 591 |
+
moe_intermediate_dim=moe_intermediate_dim,
|
| 592 |
+
num_experts=num_experts,
|
| 593 |
+
capacity_factor=capacity_factor,
|
| 594 |
+
use_sigmoid=use_sigmoid,
|
| 595 |
+
route_scale=route_scale,
|
| 596 |
+
)
|
| 597 |
+
else:
|
| 598 |
+
mlp_inner_dim = int(dim * mlp_ratio * 2 / 3) // 128 * 128
|
| 599 |
+
self.img_mlp = FeedForward(
|
| 600 |
+
dim=dim, dim_out=dim, inner_dim=mlp_inner_dim,
|
| 601 |
+
activation_fn="swiglu", bias=False,
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
def forward(
|
| 605 |
+
self,
|
| 606 |
+
hidden_states: torch.Tensor,
|
| 607 |
+
encoder_hidden_states: torch.Tensor,
|
| 608 |
+
temb: torch.Tensor,
|
| 609 |
+
image_rotary_emb: tuple[torch.Tensor, torch.Tensor] | None = None,
|
| 610 |
+
attention_kwargs: dict[str, Any] | None = None,
|
| 611 |
+
) -> torch.Tensor:
|
| 612 |
+
scale1, gate1, scale2, gate2 = self.img_mod(temb).unsqueeze(1).chunk(4, dim=-1)
|
| 613 |
+
scale1, scale2 = 1 + scale1, 1 + scale2
|
| 614 |
+
|
| 615 |
+
gate1 = gate1.clamp(min=-2.0, max=2.0)
|
| 616 |
+
gate2 = gate2.clamp(min=-2.0, max=2.0)
|
| 617 |
+
|
| 618 |
+
context = self.encoder_proj(encoder_hidden_states)
|
| 619 |
+
|
| 620 |
+
img_normed = self.pre_attn_norm(hidden_states)
|
| 621 |
+
img_modulated = img_normed * scale1
|
| 622 |
+
|
| 623 |
+
attention_kwargs = attention_kwargs or {}
|
| 624 |
+
img_attn_output = self.attn(
|
| 625 |
+
hidden_states=img_modulated,
|
| 626 |
+
encoder_hidden_states=context,
|
| 627 |
+
image_rotary_emb=image_rotary_emb,
|
| 628 |
+
**attention_kwargs,
|
| 629 |
+
)
|
| 630 |
+
|
| 631 |
+
hidden_states = hidden_states + gate1.tanh() * img_attn_output
|
| 632 |
+
|
| 633 |
+
img_normed2 = self.pre_mlp_norm(hidden_states)
|
| 634 |
+
img_modulated2 = img_normed2 * scale2
|
| 635 |
+
|
| 636 |
+
if self.moe_enabled:
|
| 637 |
+
img_mlp_output = self.img_mlp(img_modulated2, img_normed2, timestep=temb)
|
| 638 |
+
else:
|
| 639 |
+
img_mlp_output = self.img_mlp(img_modulated2)
|
| 640 |
+
|
| 641 |
+
hidden_states = hidden_states + gate2.tanh() * img_mlp_output
|
| 642 |
+
|
| 643 |
+
if hidden_states.dtype == torch.float16:
|
| 644 |
+
hidden_states = hidden_states.clip(-65504, 65504)
|
| 645 |
+
|
| 646 |
+
return hidden_states
|
| 647 |
+
|
| 648 |
+
|
| 649 |
+
class NucleusMoEImageTransformer2DModel(
|
| 650 |
+
ModelMixin, ConfigMixin, PeftAdapterMixin, FromOriginalModelMixin, CacheMixin, AttentionMixin
|
| 651 |
+
):
|
| 652 |
+
"""
|
| 653 |
+
Nucleus MoE Transformer for image generation. Single-stream DiT with
|
| 654 |
+
cross-attention to text and optional Mixture-of-Experts feed-forward layers.
|
| 655 |
+
|
| 656 |
+
Args:
|
| 657 |
+
patch_size (`int`, defaults to `2`):
|
| 658 |
+
Patch size to turn the input data into small patches.
|
| 659 |
+
in_channels (`int`, defaults to `64`):
|
| 660 |
+
The number of channels in the input.
|
| 661 |
+
out_channels (`int`, *optional*, defaults to `None`):
|
| 662 |
+
The number of channels in the output. If not specified, it defaults to `in_channels`.
|
| 663 |
+
num_layers (`int`, defaults to `24`):
|
| 664 |
+
The number of transformer blocks.
|
| 665 |
+
attention_head_dim (`int`, defaults to `128`):
|
| 666 |
+
The number of dimensions to use for each attention head.
|
| 667 |
+
num_attention_heads (`int`, defaults to `16`):
|
| 668 |
+
The number of attention heads to use.
|
| 669 |
+
num_key_value_heads (`int`, *optional*):
|
| 670 |
+
The number of key/value heads for grouped-query attention. Defaults to `num_attention_heads`.
|
| 671 |
+
joint_attention_dim (`int`, defaults to `3584`):
|
| 672 |
+
The embedding dimension of the encoder hidden states (text).
|
| 673 |
+
axes_dims_rope (`tuple[int]`, defaults to `(16, 56, 56)`):
|
| 674 |
+
The dimensions to use for the rotary positional embeddings.
|
| 675 |
+
use_layer3d_rope (`bool`, defaults to `False`):
|
| 676 |
+
Whether to use the Layer3D variant of RoPE.
|
| 677 |
+
mlp_ratio (`float`, defaults to `4.0`):
|
| 678 |
+
Multiplier for the MLP hidden dimension in dense (non-MoE) blocks.
|
| 679 |
+
moe_enabled (`bool`, defaults to `True`):
|
| 680 |
+
Whether to use Mixture-of-Experts layers.
|
| 681 |
+
dense_moe_strategy (`str`, defaults to ``"leave_first_three_and_last_block_dense"``):
|
| 682 |
+
Strategy for choosing which layers are MoE vs dense.
|
| 683 |
+
num_experts (`int`, defaults to `128`):
|
| 684 |
+
Number of experts per MoE layer.
|
| 685 |
+
moe_intermediate_dim (`int`, defaults to `1344`):
|
| 686 |
+
Hidden dimension inside each expert.
|
| 687 |
+
capacity_factor (`float`, defaults to `8.0`):
|
| 688 |
+
Expert-choice capacity factor.
|
| 689 |
+
use_sigmoid (`bool`, defaults to `False`):
|
| 690 |
+
Use sigmoid instead of softmax for routing scores.
|
| 691 |
+
route_scale (`float`, defaults to `2.5`):
|
| 692 |
+
Scaling factor applied to routing weights.
|
| 693 |
+
"""
|
| 694 |
+
|
| 695 |
+
_supports_gradient_checkpointing = True
|
| 696 |
+
_no_split_modules = ["NucleusMoEImageTransformerBlock"]
|
| 697 |
+
_skip_layerwise_casting_patterns = ["pos_embed", "norm"]
|
| 698 |
+
_repeated_blocks = ["NucleusMoEImageTransformerBlock"]
|
| 699 |
+
|
| 700 |
+
@register_to_config
|
| 701 |
+
def __init__(
|
| 702 |
+
self,
|
| 703 |
+
patch_size: int = 2,
|
| 704 |
+
in_channels: int = 64,
|
| 705 |
+
out_channels: int | None = None,
|
| 706 |
+
num_layers: int = 24,
|
| 707 |
+
attention_head_dim: int = 128,
|
| 708 |
+
num_attention_heads: int = 16,
|
| 709 |
+
num_key_value_heads: int | None = None,
|
| 710 |
+
joint_attention_dim: int = 3584,
|
| 711 |
+
axes_dims_rope: tuple[int, int, int] = (16, 56, 56),
|
| 712 |
+
mlp_ratio: float = 4.0,
|
| 713 |
+
moe_enabled: bool = True,
|
| 714 |
+
dense_moe_strategy: str = "leave_first_three_and_last_block_dense",
|
| 715 |
+
num_experts: int = 128,
|
| 716 |
+
moe_intermediate_dim: int = 1344,
|
| 717 |
+
capacity_factors: List[float] = [8.0] * 24,
|
| 718 |
+
use_sigmoid: bool = False,
|
| 719 |
+
route_scale: float = 2.5,
|
| 720 |
+
):
|
| 721 |
+
super().__init__()
|
| 722 |
+
self.out_channels = out_channels or in_channels
|
| 723 |
+
self.inner_dim = num_attention_heads * attention_head_dim
|
| 724 |
+
|
| 725 |
+
self.pos_embed = NucleusEmbedRope(theta=10000, axes_dim=list(axes_dims_rope), scale_rope=True)
|
| 726 |
+
|
| 727 |
+
self.time_text_embed = NucleusTimestepProjEmbeddings(embedding_dim=self.inner_dim)
|
| 728 |
+
|
| 729 |
+
self.txt_norm = RMSNorm(joint_attention_dim, eps=1e-6)
|
| 730 |
+
self.img_in = nn.Linear(in_channels, self.inner_dim)
|
| 731 |
+
|
| 732 |
+
self.transformer_blocks = nn.ModuleList(
|
| 733 |
+
[
|
| 734 |
+
NucleusMoEImageTransformerBlock(
|
| 735 |
+
dim=self.inner_dim,
|
| 736 |
+
num_attention_heads=num_attention_heads,
|
| 737 |
+
attention_head_dim=attention_head_dim,
|
| 738 |
+
num_key_value_heads=num_key_value_heads,
|
| 739 |
+
joint_attention_dim=joint_attention_dim,
|
| 740 |
+
mlp_ratio=mlp_ratio,
|
| 741 |
+
moe_enabled=moe_enabled and _is_moe_layer(dense_moe_strategy, idx, num_layers),
|
| 742 |
+
num_experts=num_experts,
|
| 743 |
+
moe_intermediate_dim=moe_intermediate_dim,
|
| 744 |
+
capacity_factor=capacity_factors[idx],
|
| 745 |
+
use_sigmoid=use_sigmoid,
|
| 746 |
+
route_scale=route_scale,
|
| 747 |
+
)
|
| 748 |
+
for idx in range(num_layers)
|
| 749 |
+
]
|
| 750 |
+
)
|
| 751 |
+
|
| 752 |
+
self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
|
| 753 |
+
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=False)
|
| 754 |
+
|
| 755 |
+
self.gradient_checkpointing = False
|
| 756 |
+
|
| 757 |
+
def forward(
|
| 758 |
+
self,
|
| 759 |
+
hidden_states: torch.Tensor,
|
| 760 |
+
img_shapes: list[tuple[int, int, int]] | None = None,
|
| 761 |
+
encoder_hidden_states: torch.Tensor = None,
|
| 762 |
+
encoder_hidden_states_mask: torch.Tensor = None,
|
| 763 |
+
timestep: torch.LongTensor = None,
|
| 764 |
+
txt_seq_lens: list[int] | None = None,
|
| 765 |
+
attention_kwargs: dict[str, Any] | None = None,
|
| 766 |
+
return_dict: bool = True,
|
| 767 |
+
) -> torch.Tensor | Transformer2DModelOutput:
|
| 768 |
+
"""
|
| 769 |
+
The [`NucleusMoEImageTransformer2DModel`] forward method.
|
| 770 |
+
|
| 771 |
+
Args:
|
| 772 |
+
hidden_states (`torch.Tensor` of shape `(batch_size, image_sequence_length, in_channels)`):
|
| 773 |
+
Input `hidden_states`.
|
| 774 |
+
img_shapes (`list[tuple[int, int, int]]`, *optional*):
|
| 775 |
+
Image shapes ``(frame, height, width)`` for RoPE computation.
|
| 776 |
+
encoder_hidden_states (`torch.Tensor` of shape `(batch_size, text_sequence_length, joint_attention_dim)`):
|
| 777 |
+
Conditional embeddings (embeddings computed from the input conditions such as prompts) to use.
|
| 778 |
+
encoder_hidden_states_mask (`torch.Tensor` of shape `(batch_size, text_sequence_length)`, *optional*):
|
| 779 |
+
Boolean mask for the encoder hidden states.
|
| 780 |
+
timestep (`torch.LongTensor`):
|
| 781 |
+
Used to indicate denoising step.
|
| 782 |
+
txt_seq_lens (`list[int]`, *optional*, **Deprecated**):
|
| 783 |
+
Deprecated. Use ``encoder_hidden_states_mask`` instead.
|
| 784 |
+
attention_kwargs (`dict`, *optional*):
|
| 785 |
+
Extra kwargs forwarded to the attention processor.
|
| 786 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 787 |
+
Whether to return a [`~models.transformer_2d.Transformer2DModelOutput`].
|
| 788 |
+
|
| 789 |
+
Returns:
|
| 790 |
+
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
|
| 791 |
+
`tuple` where the first element is the sample tensor.
|
| 792 |
+
"""
|
| 793 |
+
if txt_seq_lens is not None:
|
| 794 |
+
deprecate(
|
| 795 |
+
"txt_seq_lens",
|
| 796 |
+
"0.39.0",
|
| 797 |
+
"Passing `txt_seq_lens` is deprecated and will be removed in version 0.39.0. "
|
| 798 |
+
"Please use `encoder_hidden_states_mask` instead.",
|
| 799 |
+
standard_warn=False,
|
| 800 |
+
)
|
| 801 |
+
|
| 802 |
+
if attention_kwargs is not None:
|
| 803 |
+
attention_kwargs = attention_kwargs.copy()
|
| 804 |
+
lora_scale = attention_kwargs.pop("scale", 1.0)
|
| 805 |
+
else:
|
| 806 |
+
lora_scale = 1.0
|
| 807 |
+
|
| 808 |
+
if USE_PEFT_BACKEND:
|
| 809 |
+
scale_lora_layers(self, lora_scale)
|
| 810 |
+
|
| 811 |
+
hidden_states = self.img_in(hidden_states)
|
| 812 |
+
timestep = timestep.to(hidden_states.dtype)
|
| 813 |
+
|
| 814 |
+
encoder_hidden_states = self.txt_norm(encoder_hidden_states)
|
| 815 |
+
|
| 816 |
+
text_seq_len, _, encoder_hidden_states_mask = compute_text_seq_len_from_mask(
|
| 817 |
+
encoder_hidden_states, encoder_hidden_states_mask
|
| 818 |
+
)
|
| 819 |
+
|
| 820 |
+
temb = self.time_text_embed(timestep, hidden_states)
|
| 821 |
+
|
| 822 |
+
image_rotary_emb = self.pos_embed(img_shapes, max_txt_seq_len=text_seq_len, device=hidden_states.device)
|
| 823 |
+
|
| 824 |
+
block_attention_kwargs = attention_kwargs.copy() if attention_kwargs is not None else {}
|
| 825 |
+
if encoder_hidden_states_mask is not None:
|
| 826 |
+
batch_size, image_seq_len = hidden_states.shape[:2]
|
| 827 |
+
image_mask = torch.ones((batch_size, image_seq_len), dtype=torch.bool, device=hidden_states.device)
|
| 828 |
+
joint_attention_mask = torch.cat([image_mask, encoder_hidden_states_mask], dim=1)
|
| 829 |
+
block_attention_kwargs["attention_mask"] = joint_attention_mask
|
| 830 |
+
|
| 831 |
+
for index_block, block in enumerate(self.transformer_blocks):
|
| 832 |
+
if torch.is_grad_enabled() and self.gradient_checkpointing:
|
| 833 |
+
hidden_states = self._gradient_checkpointing_func(
|
| 834 |
+
block,
|
| 835 |
+
hidden_states,
|
| 836 |
+
encoder_hidden_states,
|
| 837 |
+
temb,
|
| 838 |
+
image_rotary_emb,
|
| 839 |
+
block_attention_kwargs,
|
| 840 |
+
)
|
| 841 |
+
else:
|
| 842 |
+
hidden_states = block(
|
| 843 |
+
hidden_states=hidden_states,
|
| 844 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 845 |
+
temb=temb,
|
| 846 |
+
image_rotary_emb=image_rotary_emb,
|
| 847 |
+
attention_kwargs=block_attention_kwargs,
|
| 848 |
+
)
|
| 849 |
+
|
| 850 |
+
hidden_states = self.norm_out(hidden_states, temb)
|
| 851 |
+
output = self.proj_out(hidden_states)
|
| 852 |
+
|
| 853 |
+
if USE_PEFT_BACKEND:
|
| 854 |
+
unscale_lora_layers(self, lora_scale)
|
| 855 |
+
|
| 856 |
+
if not return_dict:
|
| 857 |
+
return (output,)
|
| 858 |
+
|
| 859 |
+
return Transformer2DModelOutput(sample=output)
|
vae/config.json
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKLQwenImage",
|
| 3 |
+
"_diffusers_version": "0.36.0.dev0",
|
| 4 |
+
"attn_scales": [],
|
| 5 |
+
"base_dim": 96,
|
| 6 |
+
"dim_mult": [
|
| 7 |
+
1,
|
| 8 |
+
2,
|
| 9 |
+
4,
|
| 10 |
+
4
|
| 11 |
+
],
|
| 12 |
+
"dropout": 0.0,
|
| 13 |
+
"latents_mean": [
|
| 14 |
+
-0.7571,
|
| 15 |
+
-0.7089,
|
| 16 |
+
-0.9113,
|
| 17 |
+
0.1075,
|
| 18 |
+
-0.1745,
|
| 19 |
+
0.9653,
|
| 20 |
+
-0.1517,
|
| 21 |
+
1.5508,
|
| 22 |
+
0.4134,
|
| 23 |
+
-0.0715,
|
| 24 |
+
0.5517,
|
| 25 |
+
-0.3632,
|
| 26 |
+
-0.1922,
|
| 27 |
+
-0.9497,
|
| 28 |
+
0.2503,
|
| 29 |
+
-0.2921
|
| 30 |
+
],
|
| 31 |
+
"latents_std": [
|
| 32 |
+
2.8184,
|
| 33 |
+
1.4541,
|
| 34 |
+
2.3275,
|
| 35 |
+
2.6558,
|
| 36 |
+
1.2196,
|
| 37 |
+
1.7708,
|
| 38 |
+
2.6052,
|
| 39 |
+
2.0743,
|
| 40 |
+
3.2687,
|
| 41 |
+
2.1526,
|
| 42 |
+
2.8652,
|
| 43 |
+
1.5579,
|
| 44 |
+
1.6382,
|
| 45 |
+
1.1253,
|
| 46 |
+
2.8251,
|
| 47 |
+
1.916
|
| 48 |
+
],
|
| 49 |
+
"num_res_blocks": 2,
|
| 50 |
+
"temperal_downsample": [
|
| 51 |
+
false,
|
| 52 |
+
true,
|
| 53 |
+
true
|
| 54 |
+
],
|
| 55 |
+
"z_dim": 16
|
| 56 |
+
}
|
vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0c8bc8b758c649abef9ea407b95408389a3b2f610d0d10fcb054fe171d0a8344
|
| 3 |
+
size 253806966
|