

update readme
Browse files- README.md +85 -3
- pics/Company1_ebitda_summary.png +0 -0
- pics/Company1_ebitda_summary_words.jpg +0 -0
- pics/TEMPO.png +0 -0
- pics/TEMPO_demo.jpg +0 -0
- pics/TETS_prompt.jpg +0 -0
- pics/TETS_prompt.png +0 -0
- pics/results.jpg +0 -0
README.md
CHANGED
|
@@ -1,3 +1,85 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
|
| 2 |
+
|
| 3 |
+
The official code for ICLR 2024 paper: "TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting (ICLR 2024)".
|
| 4 |
+
|
| 5 |
+
TEMPO is one of the very first open source Time Series Foundation Models for forecasting task v1.0 version.
|
| 6 |
+
|
| 7 |
+
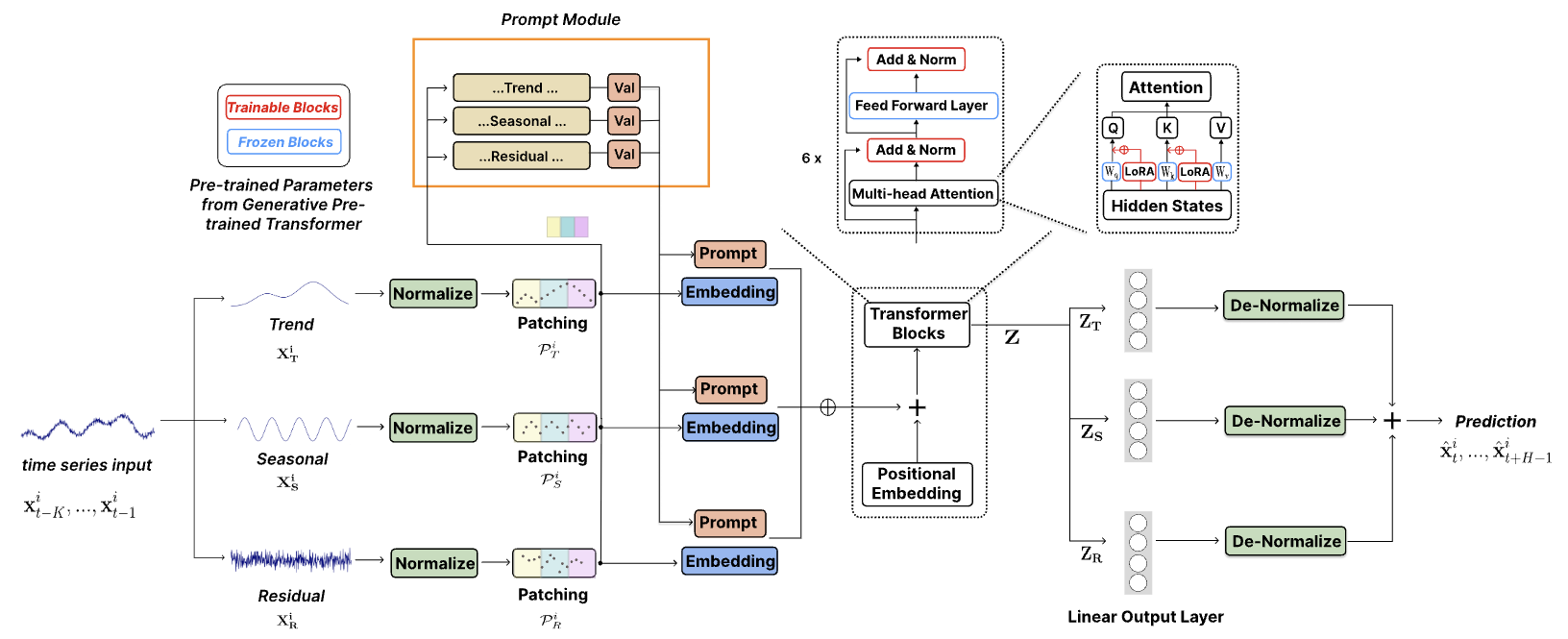
<div align="center"><img src=./pics/TEMPO.png width=80% /></div>
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
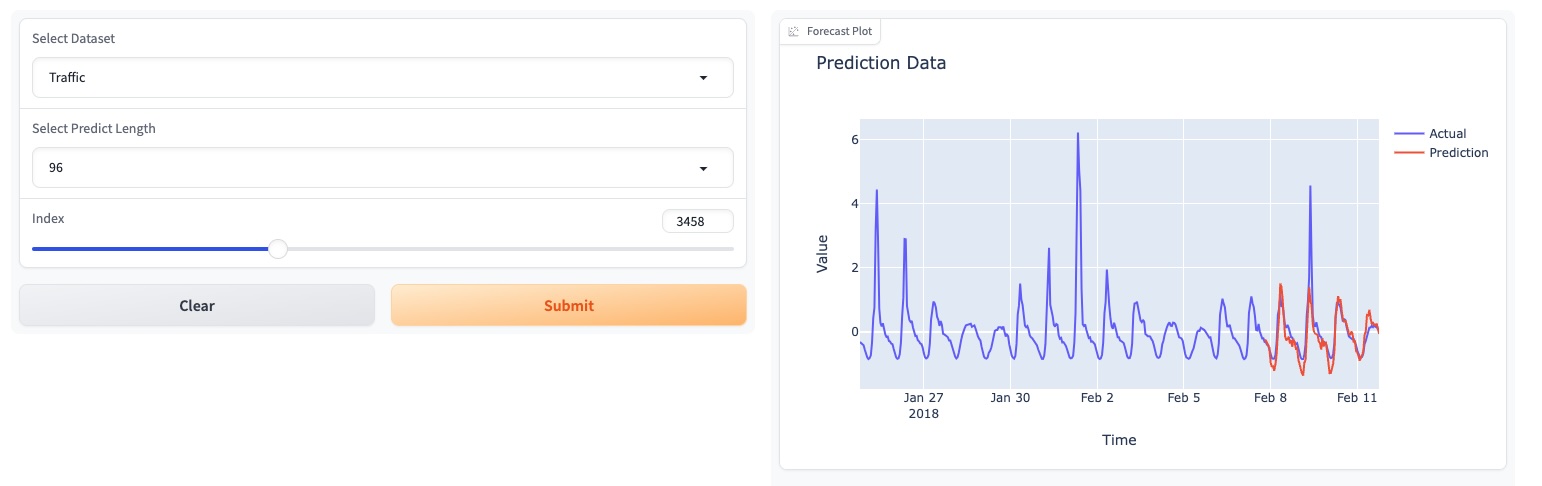
Please try our foundation model demo [[here]](https://4171a8a7484b3e9148.gradio.live).
|
| 11 |
+
|
| 12 |
+
<div align="center"><img src=./pics/TEMPO_demo.png width=80% /></div>
|
| 13 |
+
|
| 14 |
+
# Build the environment
|
| 15 |
+
|
| 16 |
+
```
|
| 17 |
+
conda create -n tempo python=3.8
|
| 18 |
+
```
|
| 19 |
+
```
|
| 20 |
+
conda activate tempo
|
| 21 |
+
```
|
| 22 |
+
```
|
| 23 |
+
pip install -r requirements.txt
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
# Get Data
|
| 27 |
+
|
| 28 |
+
Download the data from [[Google Drive]](https://drive.google.com/drive/folders/13Cg1KYOlzM5C7K8gK8NfC-F3EYxkM3D2?usp=sharing) or [[Baidu Drive]](https://pan.baidu.com/s/1r3KhGd0Q9PJIUZdfEYoymg?pwd=i9iy), and place the downloaded data in the folder`./dataset`. You can also download the STL results from [[Google Drive]](https://drive.google.com/file/d/1gWliIGDDSi2itUAvYaRgACru18j753Kw/view?usp=sharing), and place the downloaded data in the folder`./stl`.
|
| 29 |
+
|
| 30 |
+
# Run TEMPO
|
| 31 |
+
|
| 32 |
+
## Training Stage
|
| 33 |
+
```
|
| 34 |
+
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
## Test
|
| 38 |
+
|
| 39 |
+
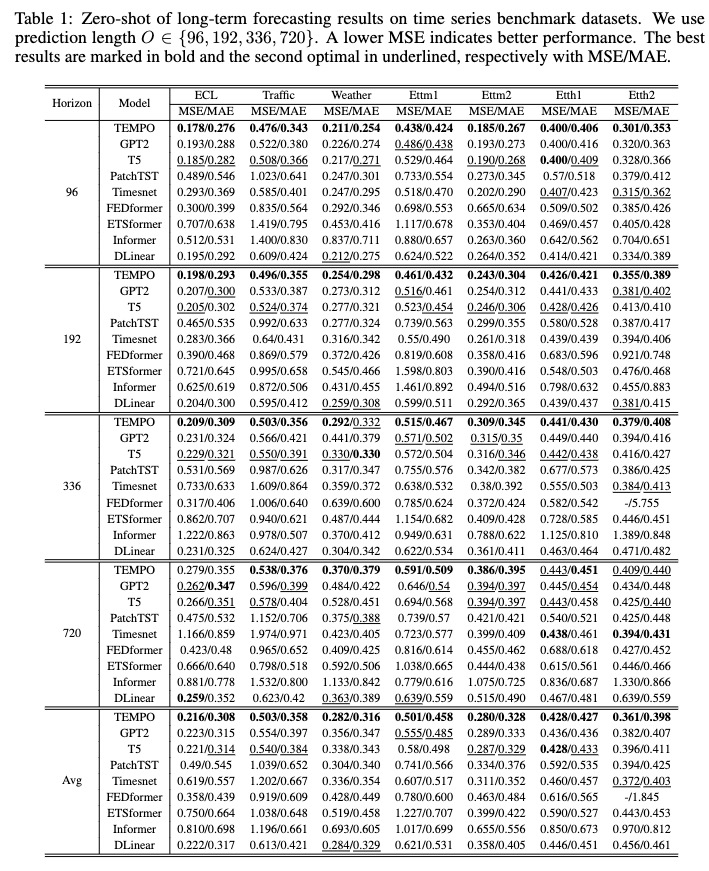
After training, we can test TEMPO model under the zero-shot setting:
|
| 40 |
+
|
| 41 |
+
```
|
| 42 |
+
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
<div align="center"><img src=./pics/results.jpg width=90% /></div>
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# Pre-trained Models
|
| 49 |
+
|
| 50 |
+
You can download the pre-trained model from [[Google Drive]](https://drive.google.com/file/d/11Ho_seP9NGh-lQCyBkvQhAQFy_3XVwKp/view?usp=drive_link) and then run the test script for fun.
|
| 51 |
+
|
| 52 |
+
# Multi-modality dataset: TETS dataset
|
| 53 |
+
|
| 54 |
+
Here is the prompts use to generate the coresponding textual informaton of time series via [[OPENAI ChatGPT-3.5 API]](https://platform.openai.com/docs/guides/text-generation)
|
| 55 |
+
|
| 56 |
+
<div align="center"><img src=./pics/TETS_prompt.png width=80% /></div>
|
| 57 |
+
|
| 58 |
+
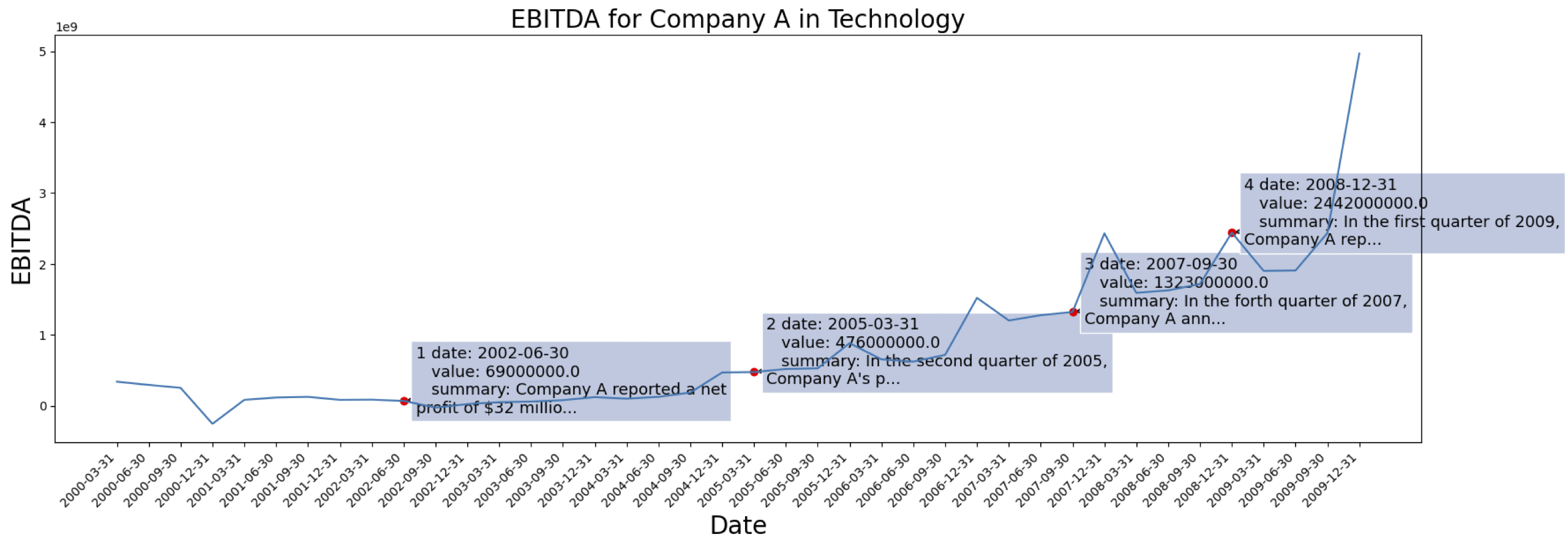
The time series data are come from [[S&P 500]](https://www.spglobal.com/spdji/en/indices/equity/sp-500/#overview). Here is the EBITDA case for one company from the dataset:
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
<div align="center"><img src=./pics/Company1_ebitda_summary.png width=80% /></div>
|
| 62 |
+
|
| 63 |
+
Example of generated contextual information for the Company marked above:
|
| 64 |
+
|
| 65 |
+
<div align="center"><img src=./pics/Company1_ebitda_summary_words.jpg width=80% /></div>
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
You can download the processed data with text embedding from GPT2 from: [[TETS]](https://drive.google.com/file/d/1Hu2KFj0kp4kIIpjbss2ciLCV_KiBreoJ/view?usp=drive_link
|
| 71 |
+
).
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Cite
|
| 76 |
+
```
|
| 77 |
+
@inproceedings{
|
| 78 |
+
cao2024tempo,
|
| 79 |
+
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
|
| 80 |
+
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
|
| 81 |
+
booktitle={The Twelfth International Conference on Learning Representations},
|
| 82 |
+
year={2024},
|
| 83 |
+
url={https://openreview.net/forum?id=YH5w12OUuU}
|
| 84 |
+
}
|
| 85 |
+
```
|
pics/Company1_ebitda_summary.png
ADDED
|
pics/Company1_ebitda_summary_words.jpg
ADDED

|
pics/TEMPO.png
ADDED
|
pics/TEMPO_demo.jpg
ADDED
|
pics/TETS_prompt.jpg
ADDED

|
pics/TETS_prompt.png
ADDED

|
pics/results.jpg
ADDED
|